Ali Berkan Ural*![]() | Mehmet Can Çalım
| Mehmet Can Çalım![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This study primarily aims at the pre-diagnosis and prediction of specific brain tumors by applying traditional and popular segmentation methods with deep learning models and also investigates the comparative performance between Artificial Intelligence (AI) and Deep Learning (DL) methods and models. The diagnostic methods currently used are generally subjective, time-consuming, and require highly specialized knowledge in detail. To determine and overcome these limitations, we propose the well-developed implementation of two deep learning segmentation methods capable of accurately and efficiently analyzing brain tumor based Magnetic Resonance Imaging (MRI) and Computerized Tomography (CT) radiological imaging data. These models were the Support Vector Machine (SVM) for the traditional AI model and ResNet50 and InceptionV3 for the popular DL model architectures, and these were used for diagnosing specific important brain conditions, including ischemic stroke, low-grade glioma (LGG), and normal (tumor-free) cases. In addition, in the medical field, ischemic stroke and LGG images could not be well determined, and misdiagnosing could occur. Because of these reasons, by using these deep learning models, the problems and limitations were overcome. The initial phase involved the meticulous collection and pre-processing of a large open-source/public dataset of MRI and CT images, carefully distinguishing those from ischemic stroke and LGG patients and healthy individuals. The models underwent rigorous training using the pre-processed image dataset and were assessed using various accuracy metrics. While traditional methods utilizing Support Vector Machines (SVM) achieved an accuracy of 77%, deep learning architectures exhibited significant advancements, with ResNet50 and InceptionV3 achieving accuracies of approximately 97%. The InceptionV3 model's lightweight architecture, integrated with effective data augmentation and transfer learning strategies, demonstrated exceptional diagnostic efficiency and accuracy. These results underscore the immense potential of deep learning in revolutionizing brain tumor/lesion diagnosis.
brain anomaly, pre-diagnosis, brain tumor, stroke, AI, deep learning
Low-Grade Gliomas (LGGs) are primary brain tumors originating from glial cells and represent a less aggressive form of brain cancer. Despite their slow growth, LGGs can cause significant neurological symptoms such as seizures, cognitive disorders, and headaches, as they can be located in critical areas of the brain. Timely detection and monitoring of these tumors are crucial for patient health, given the potential for untreated cases to progress to high-grade malignancies. Brain imaging techniques such as Magnetic Resonance Imaging (MRI) play a fundamental role in diagnosing and monitoring LGGs. However, the manual segmentation of these tumors from image data can be time-consuming, variable among radiologists, and prone to human error [1].
On the other hand, ischemic stroke occurs when blood flow to the brain is interrupted, leading to tissue damage due to a lack of oxygen and nutrients. As one of the leading causes of death and long-term disability worldwide, early diagnosis and treatment are vital for minimizing brain damage and improving patient outcomes. The primary diagnostic tools for ischemic stroke include computed tomography (CT) and MRI scans, which allow doctors to identify affected areas of the brain. Similar to brain tumors, the manual segmentation of ischemic stroke regions is a labor-intensive process that can lead to inconsistencies in diagnosis. These challenges underscore the need for automated systems to assist in detection and segmentation processes [2].
Recent advances in Artificial Intelligence (AI) and machine learning have opened new possibilities for medical image analysis. Image processing algorithms, particularly those supported by deep learning models, have shown remarkable potential for automating complex diagnostic tasks. For instance, Convolutional Neural Networks (CNNs) can learn to identify and segment brain abnormalities from imaging data with high accuracy [3]. Traditional methods like Support Vector Machines (SVM) rely on handcrafted feature extraction and classification, which often struggle to capture the complex patterns inherent in brain imaging data. This limitation has led to the adoption of more advanced architectures like ResNet50 and InceptionV3, which can automatically learn relevant features from raw data and improve diagnostic accuracy [4, 5].
The InceptionV3 architecture offers an efficient and lightweight design, making it ideal for environments with limited computational resources. It employs separable separable convolutions to lower computational demands while maintaining strong performance. Additionally, InceptionV3 supports transfer learning, enabling the use of pre-trained weights for specialized tasks like medical imaging with minimal adjustments. This flexibility is essential for creating reliable diagnostic systems that perform well across varied datasets [6].
The integration of deep learning techniques with medical imaging helps overcome the limitations of traditional methods, providing faster, more consistent, and more accurate results. Various studies have explored this potential, with Zhang et al. achieving over 90% accuracy in tumor segmentation using CNNs [7], and Li et al. reporting significant improvements in stroke detection through deep learning algorithms [8]. Furthermore, InceptionV3 has demonstrated its potential in mobile health applications, where its efficiency and high performance make it a strong candidate for real-time diagnostic systems [9].
This study compares the performance of traditional segmentation methods with the ResNet50 and InceptionV3 architectures. Our dataset consists of three categories: ischemic stroke, low-grade gliomas (LGG), and normal (tumor-free) images. For the traditional method, SVM was trained on 380 images and tested on 156. In contrast, both ResNet50 and InceptionV3 models were trained on 534 images, with 70% allocated for training and 30% for testing. This research contributes to the existing literature by evaluating the accuracy of traditional and deep learning methods, emphasizing the importance of advanced technologies in improving diagnostic performance.
2.1 Dataset description
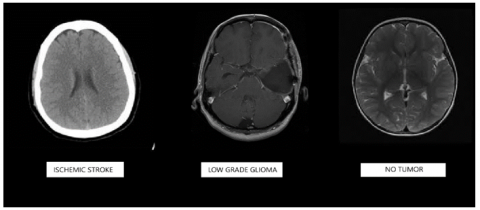
The dataset used in this study consists of medical images categorized into three groups: ischemic stroke, low-grade glioma (LGG), and normal (tumor-free) cases. A total of 534 images (178 ischemic; 178 LGG and 178 no tumor) were collected for the deep learning models, ResNet50 and InceptionV3, while for the traditional method, 380 images were allocated for training and 156 images for testing. Indeed, these images were selected from the open source database randomly between CT and MRI sequences. Since a publicly open-access dataset was used, ethical committee approval was not required for this study in detail. The images were obtained from the Kaggle platform [7, 8]. The normal (tumor-free) and ischemic stroke images are the same, while the glioma (LGG) images were obtained from a separate dataset. These images were given in Figure 1.
Figure 1. Image samples used in the dataset for the study
2.2 Proposed system
In this chapter, the details of the proposed system were given in detail.
2.2.1 Image pre-processing
To ensure the effectiveness of segmentation and classification, the images underwent several preprocessing steps, including normalization, resizing, and data augmentation.
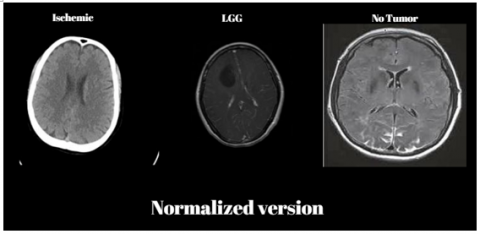
Normalization was the process of converting all images to a uniform intensity range. This step was crucial as it helps in eliminating variations caused by differences in image acquisition methods and settings. Without normalization, the model could misinterpret these variations as significant features, leading to inaccuracies in the analysis. Normalized images were available and given in Figure 2.
Resizing each image to a standard dimension suitable for the input requirements of the ResNet50 and Inception models was the next step. Standard dimensions such as 224×224 pixels were commonly used in deep learning models because they balanced the need for detailed feature extraction with computational efficiency. Resizing ensured that all images are compatible with the model's architecture, facilitating more consistent and reliable training and testing. Resized images were given in Figure 3.
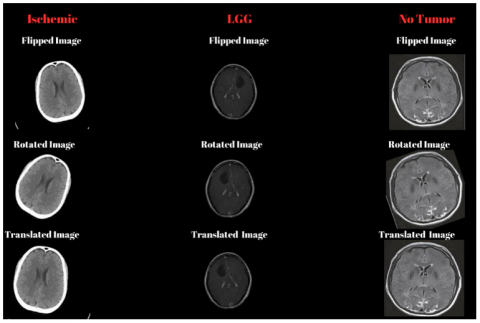
Data augmentation techniques such as rotation, scaling, and flipping were applied to increase the variability of the training dataset. Specifically, horizontal reflection flipped the images horizontally, aiding the model in recognizing features invariant to left-right orientation. Random rotation within -20 to 20 degrees helped the model handle variations in image angles. Random X-axis and Y-axis translations, shifting images horizontally and vertically by -10 to 10 pixels, ensured the model for detecting objects in different positions within the image. These augmentations improved the model's robustness and generalization capabilities by teaching it to recognize patterns under various conditions, making it more resilient to real-world data variations [9-12]. An example image of this process was given in Figure 4.
Figure 2. Normalization process results of the specific input brain images
Figure 3. Resizing process results of the specific input brain images
Figure 4. Data augmentation process results of the specific input brain images
2.2.2 Traditional segmentation and feature extraction processes
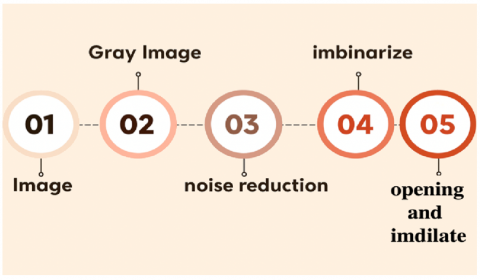
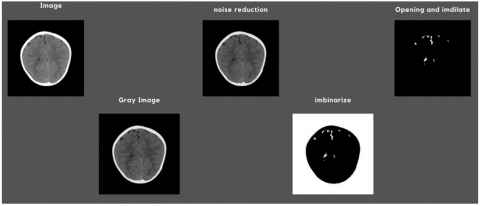
The traditional method for image analysis in medical imaging involved a systematic process of segmenting the images using morphological operations, followed by detailed feature extraction. Morphological operations—erosion, dilation, opening, and closing—were applied to the images using a 3×3 structuring element to enhance significant regions while suppressing noise. These operations played a fundamental role in medical image processing as they refined the boundaries of regions of interest, making it easier to isolate and analyze specific areas such as tumors, lesions, or other pathological regions. Erosion, for example, helped in shrinking objects by removing pixels on object boundaries, while dilation expands these objects, filling small gaps and holes. When combined, opening (erosion followed by dilation) and closing (dilation followed by erosion) enabled the effective removal of small noise particles and the smoothing of region boundaries without significantly altering their shape [13, 14]. The flowchart of the section was given in Figure 5.
Figure 5. Image process main flowchart
The next part of the progress was segmentation. This step was crucial, especially in medical applications, where the precision of boundaries could significantly influence the subsequent analysis. Accurate boundary detection helped in clearly defining pathological regions, ensuring that only relevant areas were considered for further analysis. Such precision was vital in cases where even a small miscalculation could lead to incorrect diagnosis or treatment planning. The sample processing stages of a specific brain image was given in Figure 6.
Figure 6. Results of special image processing steps for a specific brain image
Following segmentation, feature extraction was performed to derive quantitative metrics from the segmented regions. This study focused on computing various specific features, including area, perimeter, variance, standard deviation, kurtosis, and skewness. These features provided essential insights into the geometric and intensity characteristics of the regions, which were critical for accurate classification. For instance, the area and perimeter of a region give information about its size and shape, which could be indicative of the type and stage of a tumor. Irregular shapes and large perimeters, compared to their area, could suggest malignancy.
Variance and standard deviation were calculated to assess the intensity distribution within the regions. These metrics provided a measure of how much pixel intensities deviate from the mean intensity value, offering insights into the texture and heterogeneity of the region. High variance could indicate a heterogeneous region, often associated with complex tissue structures or pathological changes. On the other hand, regions with low variance typically represented more uniform textures, which could correspond to healthy or less complex tissue structures [15, 16].
Kurtosis and skewness were also included to analyze the distribution shape of the pixel values within the regions. Kurtosis generally measures the "tailedness" of the distribution, indicating whether the intensity values are prone to extreme deviations from the mean. High kurtosis might suggest regions with sharp intensity variations, while low kurtosis indicates more evenly distributed intensities. Skewness, which generally measures the asymmetry of the intensity distribution, helped in distinguishing between regions with a predominantly high or low pixel intensity. This could be particularly useful in identifying abnormalities, as different types of tissues or pathological states may exhibit distinct skewness values. For example, a positively skewed distribution could indicate bright regions, such as calcifications, while a negatively skewed one could correspond to darker regions like fluid-filled spaces or necrotic tissues [17, 18]. Sample image property value tables were shown in Figure 7 in detail.
While traditional segmentation and feature extraction provided valuable insights, they were inherently limited by their dependence on manual intervention and predefined features. To address these limitations, advanced deep learning architectures like ResNet50 and InceptionV3 were explored in this study. These models utilized convolutional neural networks to automatically learn hierarchical features from raw image data, eliminating the need for handcrafted features and enhancing classification accuracy.
Figure 7. Sample image property value tables of three groups
2.2.3 Analysis of AI based machine learning models
The traditional AI-based Support Vector Machine (SVM) classification model has long been recognized for its effectiveness in tackling classification tasks, especially within the realm of medical image analysis. In this research, features extracted from pre-processed images were used to train an SVM classifier, renowned for its resilience and capability in handling high-dimensional datasets. A dataset comprising 380 carefully curated images was utilized during training, ensuring coverage of a wide range of medical cases and conditions.
The training process incorporated a radial basis function (RBF) kernel, a widely used form of Gaussian kernel in SVMs. This kernel maps input data into a higher-dimensional space, allowing the classifier to define a linear decision boundary in that space—corresponding to a non-linear boundary in the original domain. This transformation is especially beneficial in medical imaging, where relationships between features such as texture, intensity, and structure can be subtle yet critical for accurate classification, such as identifying disease types or anatomical difference.
The RBF kernel’s ability to detect these complex patterns enhances the SVM’s precision in distinguishing between closely related classes, making it highly suitable for sensitive medical applications where accuracy is essential. Furthermore, the kernel’s gamma parameter controls the influence of each training example. By fine-tuning gamma alongside the SVM’s regularization parameter, the model achieves an optimal balance between overfitting and generalization, ensuring reliable performance on unseen data.
2.2.4 Analysis of deep learning models
The initial deep learning model based on InceptionV3 marked a significant leap forward compared to traditional approaches, thanks to its streamlined and efficient architecture. By utilizing depthwise separable convolutions, InceptionV3 significantly reduced computational load while maintaining high accuracy—an advantage especially valuable in resource-limited settings like mobile health tools or real-time diagnostic platforms. The model was fine-tuned through transfer learning, where pre-trained weights were adapted to the specific task of brain tumor classification [19-21].
To improve model generalization, various advanced data augmentation techniques were employed, including random rotations, scaling, translations, and brightness adjustments. These strategies increased training data diversity, helping the model perform well on previously unseen data. Additionally, the architecture’s use of inverted residual blocks allowed for the effective learning of complex image features, capturing the subtle distinctions necessary for precise medical diagnoses [22-24].
InceptionV3's design also integrated linear bottlenecks and inverted residuals, allowing the network to retain rich, high-level features while keeping the model compact. These enhancements made it particularly suitable for medical imaging tasks where both speed and accuracy are critical. In this study, the model was fine-tuned by replacing the original top layers with a custom configuration: a fully connected layer, a softmax activation function, and an output layer tailored for a three-class classification problem related to brain conditions.
Among all tested models, InceptionV3 achieved the highest accuracy—97.87%—outperforming the traditional SVM approach and slightly surpassing ResNet50. Its excellent accuracy, combined with its lightweight and efficient design, makes it an ideal solution for deployment in clinical settings, particularly in mobile or edge computing environments where real-time decision-making is essential [25-30].
The second deep learning model used in this study was ResNet50, a 50-layer convolutional neural network designed to automatically learn meaningful features from input images. Its architecture comprises convolutional layers, batch normalization, and fully connected layers.
Convolutional layers were responsible for extracting key features from the images. This process was mathematically represented by Eq. (1):
$Y=f(X * W+b)$ (1)
According to this equation;
These layers were designed to identify visual elements like edges, textures, and patterns at various abstraction levels, enabling the network to capture detailed image features.
A core component of ResNet50 was its residual blocks, which included skip connections to ease the training of very deep networks. The functioning of a residual block was described by Eq. (2):
$Y=f(X+F(X))$ (2)
According to this equation;
These residual connections helped mitigate the vanishing gradient problem, allowing deeper networks to train more effectively—a key advantage when analyzing medical images, where minor differences could have diagnostic significance.
Finally, fully connected layers handled the classification task. This operation was captured in Eq. (3).
$\mathrm{Z}=\sigma(\mathrm{W} * \mathrm{Y}+\mathrm{b})$ (3)
According to this equation;
These layers aggregate the features learned by earlier layers and produce the final, detailed classification result for the input image.
After the training phase, the model's effectiveness was thoroughly assessed using a separate test dataset containing 156 images. This evaluation aimed to determine how well the trained SVM classifier could apply its learned decision boundaries to new, unseen data. The classifier’s accuracy was calculated using the formula shown in Eq. (4):
$\begin{gathered}\text { Accuracy }=(\text { Number of Correct Predictions } / \text { Total } \text { Number of Test Images }) \times 100 \%\end{gathered}$ (4)
This metric offers a clear and intuitive indication of the model’s performance by expressing the percentage of test images correctly classified. A high accuracy score reflects the model’s ability to capture critical features in the data, allowing it to make precise predictions on unfamiliar inputs. In the context of medical imaging, such accuracy is vital, as it directly impacts the model’s reliability in clinical applications. Accurate classification supports early diagnosis, better treatment planning, and improved patient outcomes.
3.1 Training and evaluation
The dataset was split into training and testing subsets, with 70% allocated for training and the remaining 30% reserved for testing. Both the ResNet50 and InceptionV3 models were fine-tuned using the training set and evaluated on the test set to assess their performance. To improve generalization and robustness, data augmentation techniques were applied to the training data, introducing greater variability and helping the models perform better on unseen images.
The input image size for InceptionV3 was standardized to 224×224 pixels, in alignment with its design requirements. Various data augmentation techniques—such as random rotations, translations, and scaling—were applied to increase the models’ ability to handle diverse real-world image variations, ultimately enhancing their generalization performance.
Each model was trained using an optimizer suited to its specific architecture. ResNet50 was optimized using Stochastic Gradient Descent (SGD), which updates model weights iteratively to reduce prediction errors and incorporates a dynamic learning rate scheduler for efficient convergence. In contrast, InceptionV3 used the Adam optimizer, chosen for its adaptive learning rate mechanism, making it particularly effective for lightweight networks.
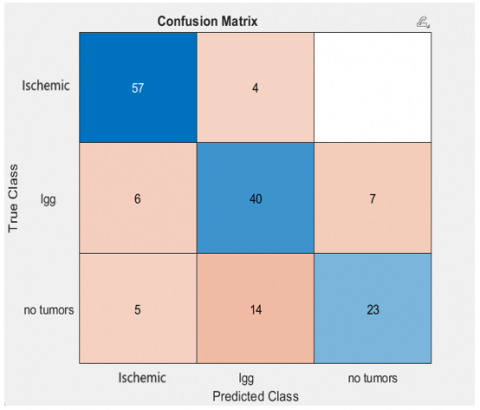
The results of this study underscore the importance of feature extraction and kernel choice in SVM classification. By leveraging the RBF kernel's strengths, the model was able to handle the non-linearities inherent in medical image data, delivering high classification accuracy and demonstrating its potential for real-world clinical applications. The SVM confusion matrix is shown in Figure 8.
Figure 8. Confusion matrix of SVM traditional model
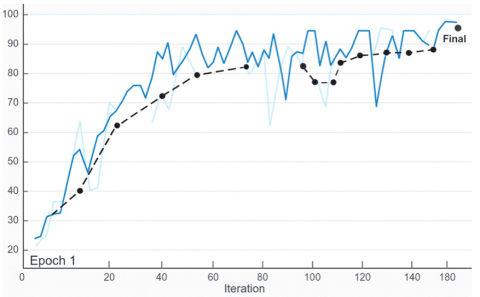
Indeed, ResNet50 achieved an accuracy of 97%, showcasing its ability to handle complex patterns and relationships in the dataset. InceptionV3, designed for efficiency, achieved an impressive accuracy of 97.89%, slightly surpassing ResNet50. The performance gap highlights the lightweight model’s ability to deliver high accuracy while maintaining computational efficiency of ResNet50 and detailed accuracy and loss graph is as Figure 9.
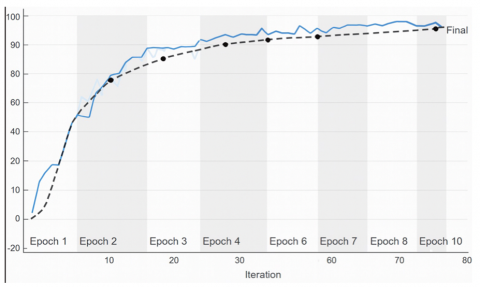
One significant advantage of InceptionV3 is its computational efficiency. The model required approximately half the training time compared to ResNet50 due to its streamlined architecture and depthwise separable convolutions. This makes InceptionV3 a suitable choice for applications requiring real-time predictions or deployment on devices with limited computational resource and detailed accuracy graph of InceptionV3 is as Figure 10.
Figure 9. Performance results of the popular DL model-ResNet50
Figure 10. Performance results of the popular DL model of InceptionV3
In the traditional approach, the Support Vector Machine (SVM) classifier was applied following several preprocessing steps, including normalization, resizing, and morphological operations. These preprocessing techniques enhanced relevant image features and minimized noise, contributing to improved SVM performance. However, due to the complexity of brain images and the limitations of manual feature extraction, this method yielded lower accuracy compared to deep learning models.
In contrast, the ResNet50 model utilized its deep architecture to automatically extract features directly from raw images. Its convolutional layers captured features at multiple levels of abstraction, while residual blocks enabled efficient training of the deep network by addressing issues like vanishing gradients. This allowed the model to learn intricate patterns within the data, leading to high classification accuracy.
InceptionV3 further improved performance by employing a more efficient architecture, using depthwise separable convolutions to maintain computational efficiency without sacrificing accuracy. As a result, it achieved slightly better accuracy than ResNet50, demonstrating strong feature extraction and generalization capabilities. Both models also benefited from data augmentation, which introduced more variability into the training set, enhancing their robustness and ability to generalize to new, unseen data.
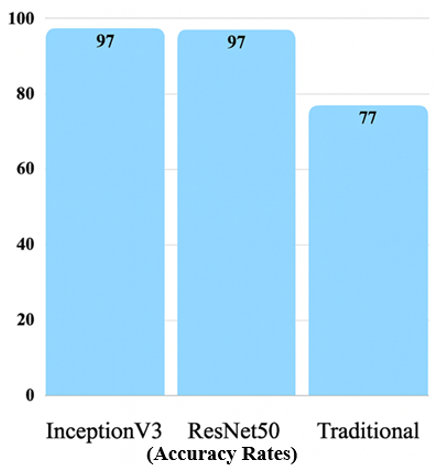
The findings of this study highlight the effectiveness and superiority of deep learning models like ResNet50 and InceptionV3 compared to traditional segmentation techniques. InceptionV3, in particular, achieved an impressive accuracy of 97.39%, coupled with high computational efficiency—making it a strong candidate for integration into medical diagnostic systems. Unlike conventional approaches that depend on manual feature extraction, these deep learning models automatically learn and extract meaningful features from raw input data. This capability enables them to detect intricate patterns that might be challenging to identify through manual analysis. The performance results are illustrated in Figure 11.
Figure 11. Result rates of the three models used in this study
To expand on this, ResNet50 utilizes convolutional layers to extract features across multiple levels of abstraction. These layers identify elements such as edges, textures, and patterns at varying scales and orientations, creating a layered and detailed representation of the input images. A key component of ResNet50’s architecture is the use of residual blocks, which incorporate shortcut connections that skip over one or more layers. These shortcuts help mitigate the vanishing gradient issue by enabling smoother gradient flow during training, thus facilitating the effective learning of very deep neural networks.
In contrast, InceptionV3 features a streamlined architecture specifically designed for both efficiency and high performance. A major innovation in this model is the use of depthwise separable convolutions, which drastically lower the number of parameters and reduce computational load compared to traditional convolution operations. This technique breaks the convolution process into two stages: depthwise convolution, which applies a separate filter to each input channel, and pointwise convolution, which uses a 1×1 filter to combine the outputs from the depthwise step.
Integrating deep learning models into clinical practice offers numerous benefits. Their high accuracy can greatly improve diagnostic precision, easing the workload of radiologists and ensuring consistent results. In medical diagnostics, where even small errors can lead to misdiagnoses and incorrect treatments, accuracy is crucial. The exceptional accuracy of 97.89% achieved by InceptionV3, along with its efficiency, highlights its potential as a reliable and scalable tool for medical diagnosis. Early and precise diagnoses are vital for effective treatment planning and improving patient outcomes. For example, in the case of brain tumors or strokes, early detection enables timely interventions that can significantly reduce morbidity and mortality.
Although robust, traditional methods like Support Vector Machine (SVM) classifiers fall short when compared to the generalization and accuracy capabilities of deep learning approaches. In this study, the SVM classifier was trained on predefined features, such as area and intensity distribution, extracted from the images. While SVM achieved an accuracy of 77%, its performance depended heavily on the quality of the feature extraction process. Manual feature extraction can be error-prone and may not capture all the relevant patterns in the data. On the other hand, InceptionV3’s automated feature learning surpasses this performance by using hierarchical feature extraction. This method allows the model to better handle data variability and complexity by learning features at multiple levels—starting with simple edges and textures at lower layers and progressing to more complex patterns in higher layers.
In conclusion, the efficiency and accuracy of deep learning models like ResNet50 and InceptionV3 make them ideal for medical diagnostic applications. Their ability to automatically learn and extract relevant features from raw data enables them to capture complex patterns that manual methods might miss. Data augmentation further strengthens their robustness, enabling better generalization to new data. The high accuracy achieved by these models can enhance diagnostic precision, reduce the workload of radiologists, and ensure consistent results. As deep learning models continue to advance, their integration into clinical workflows is poised to revolutionize medical diagnostics and improve patient outcomes.
4.1 Comparison with other related studies
Comparing the findings of this study with other research in the field offers valuable insight into the effectiveness of deep learning models for medical imaging. While there are only a few studies closely related to this one, they provide useful context. For example, Li et al. [31] used a CNN architecture and reported a 90% accuracy for stroke detection using deep learning algorithms. In contrast, the ResNet50 model in this study achieved an accuracy of 97%, with the InceptionV3 model slightly outperforming it at 97.89%. These results highlight the superior ability of these models to capture complex patterns and relationships in brain images. The success can be attributed to the use of a comprehensive dataset and advanced image processing techniques, both of which played a critical role in enhancing performance. The quality of the dataset and the models’ ability to learn from augmented data were key factors in achieving such high accuracy.
4.2 Limitations of the study
Despite achieving high accuracy, this study has several limitations that should be addressed to further enhance its findings and applicability. Firstly, the dataset size, while sufficient for this research, is relatively small compared to the large-scale datasets typically used in deep learning applications. The limited size may affect the model's ability to generalize to new, unseen data. Expanding the dataset would introduce greater variability, allowing the models to learn from a wider range of examples.
Another important limitation is the focus on only two deep learning models: ResNet50 and InceptionV3. Although these models performed well in brain tumor and stroke classification tasks, other architectures may offer even more effective solutions. For example, EfficientNet provides a scalable architecture that balances accuracy and computational efficiency. DenseNet, with its densely connected convolutional layers, can improve feature propagation and alleviate the vanishing gradient issue.
Furthermore, the study primarily utilized basic data augmentation techniques such as rotation, scaling, and flipping to improve model performance. While these methods help increase the variability of the training data, more advanced augmentation strategies could be employed. For example, Generative Adversarial Networks (GANs) can generate synthetic data that closely mirrors the original dataset. GANs create new instances that retain the characteristics of the original data, enriching the dataset and providing a more diverse range of training examples. This could help address the issue of limited data and enhance the model's ability to handle out-of-distribution data, ensuring that the models perform well in the face of new and unexpected data variations.
In conclusion, while this study has shown the effectiveness of deep learning models like ResNet50 and InceptionV3 in diagnosing brain tumors and strokes, it is limited by the small dataset size, the narrow focus on only two architectures, and reliance on basic data augmentation techniques. Addressing these limitations by increasing the dataset size, exploring additional model architectures, and incorporating advanced data augmentation methods could significantly improve the robustness, generalization, and overall performance of the models, making them more reliable and effective for clinical applications.
This study compared traditional SVM-based segmentation methods with deep learning models, specifically ResNet50 and InceptionV3, for diagnosing brain conditions. Both deep learning models significantly outperformed the traditional SVM approach, with InceptionV3 achieving the highest accuracy of 97.89%, followed closely by ResNet50 at 97%, and SVM at 77%. These results highlight the transformative potential of deep learning in medical imaging, particularly in tasks such as brain tumor and stroke classification.
The superior performance of these models emphasizes their ability to automatically learn hierarchical features directly from raw data, making them more effective and adaptable than traditional methods that rely on manual feature extraction. InceptionV3’s lightweight design and computational efficiency make it an appealing choice for resource-limited environments, such as real-time or mobile health applications.
The dataset used in this study had unique characteristics that significantly contributed to the findings. It consisted of open-access data from Kaggle, incorporating ischemic stroke, LGG, and tumor-free cases to provide a comprehensive representation of diagnostic scenarios. The integration of separate datasets for glioma and ischemic stroke cases added variability, which enhanced the robustness of model training. By focusing on real-world scenarios where early and accurate diagnosis is crucial, this study highlights the transformative potential of deep learning in medical diagnostics, setting the stage for scalable, efficient, and highly accurate healthcare solutions.
Looking ahead, future work should focus on expanding datasets, exploring a variety of model architectures, and considering ensemble approaches to further improve performance. Additionally, integrating these models into clinical workflows and validating their effectiveness in real-world settings are essential next steps. The ongoing advancement of AI technologies has the potential to revolutionize diagnostic practices, improving accuracy, efficiency, and ultimately enhancing patient outcomes in healthcare.
[1] Zhang, Y., Yang, G., Bhatia, K. (2018). Deep learning in medical imaging: A review. Artificial Intelligence in Medicine, 98: 101-113. https://doi.org/10.5772/intechopen.111686
[2] Xie, X., Niu, J., Liu, X., Chen, Z., Tang, S., Yu, S. (2021). A survey on incorporating domain knowledge into deep learning for medical image analysis. Medical Image Analysis, 69: 101985. https://doi.org/10.1016/j.media.2021.101985
[3] Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861. https://doi.org/10.48550/arXiv.1704.04861
[4] Krizhevsky, A., Sutskever, I., Hinton, G.E. (2012). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6): 84-90. https://doi.org/10.1145/3065386
[5] Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., Fei-Fei, L. (2009). ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, pp. 248-255. https://doi.org/10.1109/cvprw.2009.5206848
[6] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C. (2018). MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, pp. 4510-4520. https://doi.org/10.1109/cvpr.2018.00474
[7] Kaggle Datasets, Brain Stroke CT Image Dataset, Kaggle, 2019. https://www.kaggle.com/datasets/afridirahman/brain-stroke-ct-image-dataset, accessed on January 2025.
[8] Kaggle Datasets, LGG MRI Segmentation Dataset, 2018. https://www.kaggle.com/datasets/mateuszbuda/lgg-mri-segmentation, accessed on January 2025.
[9] Huang, T. Y., Chen, Y.R., Wu, S.M. (2018). Analysis the impedance of power delivery network to design a decoupling capacitor network. In 2018 20th International Conference on Electronic Materials and Packaging (EMAP), Hong Kong, China, pp. 1-4. https://doi.org/10.1109/emap.2018.8660852
[10] Taylor, L., Nitschke, G. (2018). Improving deep learning with generic data augmentation. In 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, pp. 1542-1547. https://doi.org/10.1109/ssci.2018.8628742
[11] Matsumoto, M., Saito, N., Ogawa, T., Haseyama, M. (2019). Chronic gastritis detection from gastric X-ray images via deep autoencoding Gaussian mixture models. In 2019 IEEE 1st Global Conference on Life Sciences and Technologies (LifeTech), Osaka, Japan, pp. 231-232. https://doi.org/10.1109/lifetech.2019.8884074
[12] Casula, G.A., Mazzarella, G. (2019). A numerical study on the robustness of ultrawide band wearable antennas with respect to the human body proximity. In 2019 PhotonIcs & Electromagnetics Research Symposium-Spring (PIERS-Spring), Rome, Italy, pp. 212-218. https://doi.org/10.1109/PIERS-Spring46901.2019.9017461
[13] Reinhold, J.C., Dewey, B.E., Carass, A., Prince, J.L. (2019). Evaluating the impact of intensity normalization on MR image synthesis. In Proceedings of SPIE, Medical Imaging 2019: Image Processing, California, United States, pp. 109493H. https://doi.org/10.1117/12.2513089
[14] Peregrina, M.A., Poveda, A.R. (2018). Design and development of an open antropomorphic robotic hand development system. In 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, pp. 592-596. https://doi.org/10.1109/cbs.2018.8612147
[15] Vani Kumari, S., Usha Rani, K. (2020). Analysis on various feature extraction methods for medical image classification. In Advances in Computational and Bio-Engineering: Proceeding of the International Conference on Computational and Bio Engineering, pp. 19-31. https://doi.org/10.1007/978-3-030-46943-6_3
[16] Guido, R., Ferrisi, S., Lofaro, D., Conforti, D. (2024). An overview on the advancements of Support Vector Machine models in healthcare applications: A review. Information, 15(4): 235. https://doi.org/10.3390/info15040235
[17] Shawe-Taylor, J., Sun, S. (2011). A review of optimization methodologies in Support Vector Machines. Neurocomputing, 74(17): 3609-3618. https://doi.org/10.1016/j.neucom.2011.06.026
[18] He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, pp. 770-778. https://doi.org/10.1109/cvpr.2016.90
[19] Shah, F.M., Hossain, T., Ashraf, M., Shishir, F.S., Al Nasim, M.A., Kabir, M.H. (2019). Brain tumor segmentation techniques on medical images-A review. International Journal of Scientific & Engineering Research, 10(2): 1514-1525.
[20] Yang, P., Shang, Z., Liu, C., Peng, Y., Zhu, Z., Chen, Z. (2020). A three-state dual-inductance bi-directional converter and its control in pulse-loaded three-port converters. CSEE Journal of Power and Energy Systems, 6(2): 291-297. https://doi.org/10.17775/cseejpes.2019.02480
[21] Liu, Y., Wang, Y., Zhang, N., Lu, D., Kang, C. (2019). A data-driven approach to linearize power flow equations considering measurement noise. IEEE Transactions on Smart Grid, 11(3): 2576-2587. https://doi.org/10.1109/tsg.2019.2957799
[22] Sarker, I.H. (2021). Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Computer Science, 2(6): 1-20. https://doi.org/10.1007/s42979-021-00815-1
[23] Ekmekyapar, T., Taşcı, B. (2023). Exemplar InceptionV3-based Artificial Intelligence for robust and accurate diagnosis of multiple sclerosis. Diagnostics, 13(19): 3030. https://doi.org/10.3390/diagnostics13193030
[24] Arias-Garcia, J., Mafra, A., Gade, L., Coelho, F., Castro, C., Torres, L., Braga, A. (2020). Enhancing performance of gabriel graph-based classifiers by a hardware co-processor for embedded system applications. IEEE Transactions on Industrial Informatics, 17(2): 1186-1196. https://doi.org/10.1109/tii.2020.2987329
[25] Iqbal, S., Khan, T.M., Naqvi, S.S., Naveed, A., Usman, M., Khan, H.A., Razzak, I. (2023). LDMRes-Net: A lightweight neural network for efficient medical image segmentation on IoT and edge devices. IEEE Journal of Biomedical and Health Informatics, 28(7): 3860-3871. https://doi.org/10.1109/jbhi.2023.3331278
[26] Alnaggar, O.A.M.F., Jagadale, B.N., Saif, M.A.N., Ghaleb, O.A., Ahmed, A.A., Aqlan, H.A.A., Al-Ariki, H.D.E. (2024). Efficient Artificial Intelligence approaches for medical image processing in healthcare: Comprehensive review, taxonomy, and analysis. Artificial Intelligence Review, 57(8): 221. https://doi.org/10.1007/s10462-024-10814-2
[27] Alomar, K., Aysel, H.I., Cai, X. (2023). Data augmentation in classification and segmentation: A survey and new strategies. Journal of Imaging, 9(2): 46. https://doi.org/10.3390/jimaging9020046
[28] Valverde, J.M., Imani, V., Abdollahzadeh, A., De Feo, R., Prakash, M., Ciszek, R., Tohka, J. (2021). Transfer learning in magnetic resonance brain imaging: A systematic review. Journal of Imaging, 7(4): 66. https://doi.org/10.3390/jimaging7040066
[29] Borisov, V., Leemann, T., Seßler, K., Haug, J., Pawelczyk, M., Kasneci, G. (2022). Deep neural networks and tabular data: A survey. IEEE Transactions on Neural Networks and Learning Systems, 35(6): 7499-7519. https://doi.org/10.1109/tnnls.2022.3229161
[30] Thomas, L.B., Mastorides, S.M., Viswanadhan, N.A., Jakey, C.E., Borkowski, A.A. (2021). Artificial Intelligence: Review of current and future applications in medicine. Federal Practitioner, 38(11): 527. https://doi.org/10.12788/fp.0174
[31] Li, L., Wei, M., Liu, B.O., Atchaneeyasakul, K., Zhou, F., Pan, Z., Kumar, S.A., Zhang, J.Y., Pu, Y., Liebeskind, D.S., Scalzo, F. (2020). Deep learning for hemorrhagic lesion detection and segmentation on brain CT images. IEEE Journal of Biomedical and Health Informatics, 25(5): 1646-1659. https://doi.org/10.1109/jbhi.2020.3028243