Pranshu Saxena![]() | Sanjay Kumar Singh
| Sanjay Kumar Singh![]() | Mamoon Rashid*
| Mamoon Rashid*![]() | Sultan S. Alshamrani
| Sultan S. Alshamrani![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Neuroblastoma (NB) is a childhood malignancy associated with high cancer-related mortality and disability, remaining a persistent challenge in paediatric oncology. High-risk NB tumours often metastasize, resulting in survival rates below 50%. Early detection and accurate risk stratification are thus essential for improving patient prognosis and therapeutic outcomes. In recent years, computational approaches, including machine learning (ML) and deep learning (DL), have been extensively applied to extract meaningful clinical and biological insights from multi-modal NB datasets. This review systematically synthesizes literature applying ML, DL, and statistical methods to analyze multi-omics profiles, histopathological images, and medical imaging for diagnostic and prognostic modeling in NB. It evaluates various computational methodologies for tumour classification, risk group stratification, and outcome prediction. Special attention is given to emerging advancements such as Vision Transformers (ViTs) for histopathology, self-explainable AI (S-XAI), counterfactual interpretability, and federated learning (FL) frameworks (e.g., Swarm Learning, SplitFed), which support transparency, privacy, and decentralized collaboration. Furthermore, this study highlights the clinical potential of integrating computational models into real-time decision-making workflows and emphasizes the importance of ethical fairness, multi-institutional validation, and personalized treatment strategies. By addressing these challenges, AI-driven tools are poised to significantly improve NB diagnosis, risk stratification, and outcome prediction in paediatric oncology.
Neuroblastoma, machine learning, deep learning, histopathological images, pattern extraction
NB is the most common extracranial solid tumour in paediatric patients, originating from embryonic neural crest cells known as neuroblasts. Typically, these immature cells differentiate into functional nerve cells. Still, in NB, they undergo uncontrolled proliferation, leading to tumour formation primarily in the adrenal glands, which regulate hormone production, blood pressure, and other vital functions [1]. However, NB can also develop in different regions of the sympathetic nervous system, including the abdomen, chest, and neck. In its early stages, NB may be asymptomatic, making early detection challenging. As the disease progresses, tumour metastasis occurs through hematogenous and lymphatic spread, affecting distant organs such as the bones, liver, lungs, and bone marrow, significantly complicating prognosis [1, 2]. The heterogeneous nature of NB leads to widely varying clinical outcomes, ranging from spontaneous regression in low-risk cases to aggressive, treatment-resistant tumours in high-risk patients.
NB predominantly affects infants and children under the age of five, accounting for 15% of paediatric cancer-related deaths. Prognosis is influenced by age at diagnosis, tumour stage, MYCN amplification status, and histopathological classification. Despite advancements in molecular profiling and targeted therapy, early and accurate diagnosis remains a significant challenge due to overlapping clinical features with other paediatric malignancies [3].
To address these challenges, computational approaches, including ML and deep learning DL, have emerged as powerful tools for NB detection, risk stratification, and treatment prediction. This review explores state-of-the-art computational methodologies integrating multi-omics, histopathological imaging, and clinical data to enhance early diagnosis, prognosis, and personalized treatment strategies.
1.1 Statistical study of Neuroblastoma
NB is the predominant tumour affecting the sympathetic nervous system, accounting for 97% of cases. It is also the most prevalent form of cancer among infants, with an average diagnosis age of 17 months [1]. It constitutes 15% of all paediatric cancer-related deaths [2]. The yearly occurrence of NB in the United States is approximately 650 cases, translating to an incidence rate of 10.2 cases per million children (or 65 cases per million infants). This rate has remained stable over time, with a negligible variation of 0.4% [3]. Despite a general decrease in the five-year mortality rate from 1975 to 2005, subgroup-specific mortality trends indicate significant variation in survival outcomes.
Globally, variations in detection rates exist due to differences in screening programs and healthcare infrastructure. For example, urinary catecholamine screening in Japan has led to earlier NB detection, potentially reducing mortality rates in high-risk cases. However, standardization challenges prevent the widespread adoption of such programs worldwide [4]. A graphical representation comparing incidence rates, survival trends, and regional variations can provide additional insight into how NB is managed across different populations.
1.2 Pathophysiological behaviour of Neuroblastoma
NB arises due to genetic and molecular alterations in neural crest cells, leading to aberrant cellular proliferation and differentiation failure. Several key biochemical and molecular markers have been identified in its pathophysiology:
● MYCN Amplification: In ~25% of cases, MYCN amplification is associated with rapid tumour progression and poor prognosis [4]. Patients with MYCN-amplified tumours often exhibit aggressive disease, early metastasis, and chemotherapy resistance.
● ALK Mutations: Anaplastic lymphoma kinase (ALK) mutations have been implicated in NB pathogenesis and represent a target for novel therapies.
● NTRK-1 & CD-44 Expression: While NTRK-1 expression is linked to low-risk tumours, CD-44 absence correlates with poor prognosis.
● DNA Index (Ploidy Status): Tumours with a high DNA index (hyperdiploidy) respond better to chemotherapy, whereas near-diploid tumours have a worse prognosis.
● Serum Biochemical Markers: Elevated levels of LDH, serum ferritin, and neuron-specific enolase (NSE) indicate a higher tumour burden and worse outcomes [5].
Approximately 90% of patients show increased urinary vanillylmandelic acid (VMA) and homovanillic acid (HVA) levels, aiding in biochemical screening and diagnosis. The heterogeneity of NB makes risk stratification essential for personalized treatment planning.
1.3 Developmental stages of Neuroblastoma
Assessing the tumour stage is a critical factor in determining the risk category and treatment strategy. Two primary staging systems are used.
1.3.1 International Neuroblastoma Staging System (INSS)
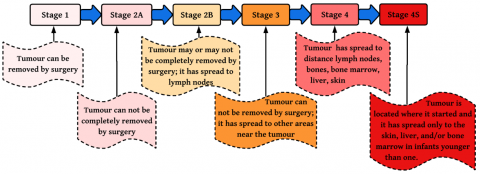
Introduced in 1986, the INSS relies on post-surgical tumour assessment (Figure 1). This staging method depends on the extent of surgical tumour resection, making it less applicable for children who are inoperable at diagnosis.
● Stage 1: Localized tumour, completely resected, no lymph node involvement.
● Stage 2A: Localized tumour, incomplete resection, no lymph node involvement.
● Stage 2B: Localized tumour with regional lymph node involvement.
● Stage 3: Tumour crosses the midline or involves contralateral lymph nodes.
● Stage 4: Distant metastases present.
● Stage 4S: Metastases limited to liver, skin, and bone marrow in infants under one year, associated with better prognosis.
Figure 1 visually represents the INSS staging criteria, showing how tumour progression correlates with surgical removal feasibility and metastasis.
1.3.2 International Neuroblastoma Risk Group Staging System (INRGSS)
The INRGSS, established in 2005, is based on pre-treatment imaging (CT, MRI, and MIBG scans) rather than surgical outcomes. This approach enables risk stratification before surgical intervention.
● L1: Localized tumour, no Image-Defined Risk Factors (IDRFs).
● L2: Tumour with IDRFs but without distant spread.
● M: Distant metastases present.
● MS: Metastases limited to skin, liver, or bone marrow, often seen in infants under 18 months.
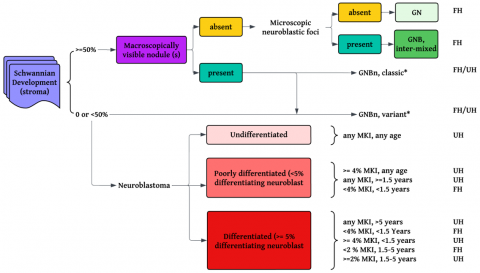
Figure 2 provides a detailed overview of the developmental stages of NB using the INRGSS framework. It also integrates MYCN amplification status and histopathological differentiation, which are key determinants of risk stratification in NB patients [1].
Figure 1. INSS staging criterion to access NB
Figure 2. Developmental stages of Neuroblastoma with risk associates
Table 1. Comparision on staging system on the basis of certain criterion
|
Criteria |
INSS |
INRGSS |
|
Basis of Staging |
Post-surgical tumour evaluation |
Pre-treatment tumour evaluation |
|
Assessment Method |
Histopathological examination after tumour resection |
Imaging-based (CT, MRI, MIBG scans) |
|
Lymph Node Involvement |
Considered in staging |
Not a determinant factor |
|
Distant Metastasis |
Considered in advanced stages |
Used to classify metastatic disease |
|
Surgical Consideration |
Surgery is required for staging determination |
No surgery required for staging |
|
Stages |
Stages 1-4S |
L1, L2, M, MS |
Table 1 provides a comparative summary of INSS vs. INRGSS, highlighting key differences in staging criteria, surgical requirements, and risk classification.
1.3.3 Shimada classification system for Neuroblastoma
The Shimada Classification System, developed by the International NB Pathology Committee, categorizes NB tumours based on histopathological differentiation and stromal composition. It is a key determinant of prognosis, particularly in distinguishing between favorable and unfavorable histology (UH).
● Favorable Histology (FH): Characterized by well-differentiated ganglion cells and abundant Schwannian stroma. More common in younger children and associated with a better prognosis.
● UH: Poorly differentiated or undifferentiated tumour cells with high mitosis-karyorrhexis index (MKI), typically observed in older children with aggressive disease.
Key criteria in the Shimada system include:
● Schwannian stroma content (stroma-rich vs. stroma-poor tumours).
● Differentiation level (differentiating, poorly differentiated, or undifferentiated NB).
● MKI (low, intermediate, or high).
● Age of the patient (critical in determining prognosis in conjunction with histology).
The Shimada classification is essential in risk stratification, guiding treatment decisions alongside INSS and INRGSS.
Figure 3 illustrates the Shimada classification standard, showcasing its role in predicting patient outcomes based on tumour histology [6].
1.4 Clinical strategies to deal with Neuroblastoma
The management of NB requires a multidisciplinary approach, integrating surgery, chemotherapy, radiation therapy, immunotherapy, and emerging AI-driven diagnostic and treatment strategies. Treatment choice depends on tumour staging, molecular characteristics, and patient-specific risk factors [7].
Surgical intervention is the first-line treatment for localized NB. In low-risk cases, complete surgical resection can be curative. However, for high-risk or advanced-stage tumours, surgery is often complemented by chemotherapy and radiation therapy. Chemotherapy is used in two key phases: Induction therapy, where high-dose chemotherapy is administered before surgery to shrink tumours, and consolidation therapy, which follows surgery to eradicate any remaining cancer cells and prevent relapse. Radiotherapy has an essential function in NB management for high-risk, especially with tumours that cannot be resected entirely. External Beam Radiotherapy (EBRT) treats the residual areas of the tumour, whereas MIBG treatment, a type of targeted radiotherapy with radioiodinated metaiodobenzylguanidine (MIBG), is utilized with high metastatic disease.
Emerging advances in immunotherapy and targeted therapy have revolutionized the management of NB. Dinutuximab, a monoclonal anti-GD2 antibody, increases survival among high-risk patients by targeting NB cells while sparing normal cells. ALK inhibitors like Crizotinib and Lorlatinib are novel targeted treatments for patients with ALK-mutated NB. Retinoic acid differentiation therapy is also utilized to trigger the maturation of NB cells and eliminate recurrence [8].
AI and ML are revolutionizing NB diagnosis and treatment planning. AI-based models combine tumour genomics, imaging biomarkers, and clinical information to enhance risk stratification, outcome prediction, and personalized therapy choice. AI-aided radiomics improves MRI and CT image analysis, enabling more accurate tumour detection and classification. DL-based histopathological models are also being investigated to detect molecular subtypes and predict therapeutic response, thereby propelling the field of precision oncology [8, 9].
Figure 3. Shimada classification standard [6]
In spite of these developments, there are challenges in the universal adoption of AI-based and computational approaches. Data bias, interpretability of AI models, regulatory clearances, and computational complexity are some of the areas that require resolution. FL strategies, where AI models are trained on multi-institutional data without violating patient privacy, should be the focus of future research. The incorporation of AI models into current clinical practices is required to guarantee that the technologies augment human intelligence in NB diagnosis and treatment planning instead of substituting it.
The future of NB therapy is in the synergistic combination of conventional therapeutic modalities with AI and computational technologies. Through the application of ML, DL, and precision medicine strategies, clinicians can enhance diagnostic accuracy, maximize treatment regimens, and ultimately improve patient outcomes. The subsequent paper is structured in the following manner: in section 2, a presented systematic is presented. Presented in the following section 3 is the inference that can be drawn from the review of the literature as well as the reason behind the study and discussion. Sections 4 and 5 contain open issues and further direction and conclusion, respectively.
A systematic review of ML applications in NB is presented to provide insights into how computational approaches are enhancing diagnosis, prognosis, and treatment planning. The review concerns multiple datasets utilized in current research, as well as the segmentation, feature extraction, and feature selection methods utilized to design ideal feature vectors. These features are then handled through diverse ML and DL architectures to identify NB cases based on established grading criteria. Comparison of evaluation metrics between studies facilitates the identification of the most efficient algorithms and the determination of the appropriateness of these for each dataset. The results of the systematic review assist in knowing the ML models that exhibit the highest accuracy, strength, and transferability in NB prediction and classification tasks.
Beyond accuracy metrics, the clinical acceptance of machine learning models in NB critically depends on their interpretability. In several reviewed studies, explainable AI (XAI) techniques have been implemented to make predictions more transparent. For instance, in image-based models using histopathological whole slide images, Grad-CAM has been applied to highlight regions of high diagnostic relevance—such as mitosis-rich or necrotic areas—thereby validating the model’s decision-making process from a pathological standpoint. In omics-based models, SHAP values have been used to quantify the contribution of individual genes or radiomic features to survival predictions or MYCN amplification classification. These tools not only improve clinician trust in AI systems but also reveal biologically meaningful patterns that may aid in biomarker discovery and clinical reasoning
Systematic review is provided in Table 2 that lists various datasets utilized in recent state-of-the-art research, as well as segmentation, feature extraction, and feature selection criteria used to create optimal feature vectors. These features are further utilized in multiple ML and DL architectures for classification under various NB grading standards. The performance measures of these models are compared to select the best-performing algorithms and their appropriateness for the datasets considered in existing research.
The application of ML in NB research has been widely explored across various domains, including histopathology, radiomics, gene expression profiling, and clinical data modeling. Numerous studies have employed diverse datasets, segmentation techniques, and classification models to improve diagnostic accuracy, prognostic assessment, and therapeutic stratification in NB patients.
Across computational studies, model validation protocols differ significantly. Most employ k-fold cross-validation (typically k=5 or 10) to prevent overfitting, especially when working with small datasets [8], while leave-one-out cross-validation (LOOCV) remains prevalent in gene expression analysis. Hyperparameter tuning is commonly performed through grid or random search, with tuning of dropout rates, learning rates, and kernel parameters shown to improve classification performance [6, 8]. Although accuracy remains a standard metric, newer studies emphasize AUC, F1-score, precision, and specificity, particularly for high-risk stratification in histopathological image analysis, studies like [10-14] utilized whole-slide images (WSI) with segmentation techniques such as SIFT, texture analysis, and region-based clustering. These studies implemented classifiers like kNN, SVM, and deep neural networks, achieving classification accuracies ranging from 84.6% to 90%. Recent advances have expanded this domain using ViTs, which employ self-attention mechanisms for global context capture in histology-based classification tasks.
Radiomics and imaging-based ML approaches have demonstrated value in tasks like MYCN gene amplification prediction and bone marrow metastasis detection, with AUC values reaching 0.90 [15]. Traditional classifiers such as CNNs, logistic regression, and random forests continue to be utilized in these modalities. Multi-omics and gene expression studies have employed dimensionality reduction techniques like PCA, chi-square selection, and data mining [16-19]. Models including XGBoost, random forests, and ensemble classifiers have identified molecular signatures linked to outcome, with AUC values exceeding 91%. Newer works have employed deep learning on multi-omics fusion models, enabling integrative survival prediction and stratification.
Table 2. Review of ML and DL approaches in NB
|
References |
Data Set |
Segmentation Approaches |
Classification Approaches |
Classification Category |
Performance Evaluation |
|
[10] |
A total of 45 WSIs from the Nationwide Children’s Hospital were used, each scanned at 40× magnification with a spatial resolution of 100,000 × 120,000 pixels. |
A feature selection phase is performed offline throughout the training process to select optimal features at different magnification. |
A revised kNN classifier is employed to ascertain the level of confidence in the categorization. |
Classification of stroma-rich versus stroma-poor NB based on Schwannian stromal development. |
The overall accuracy of the proposed system is 88.4%. |
|
[11] |
The dataset comprises 1043 H&E-stained histologic images obtained from The Children's Hospital at Westmead in Sydney, Australia. |
The proposed approach utilizes a fusion of Scale Invariant Feature Transform (SIFT) and a feature encoding algorithm to extract highly discriminative features. |
Then these features are fed to classify with a support vector machine (histogram intersection) |
Classification among Differentiating Neuroblastoma (DN), Ganglioneuroma (GGN), GanglioNeuroblastoma (GGNB), Poorly Differentiated Neuroblastoma (PDN), and Undifferentiated Neuroblastoma (UDN). |
With 100X magnification, image's maximum accuracy is achieved at 87.25% with 2.51 latency. |
|
[12] |
The dataset comprises 1043 H&E-stained histologic images obtained from The Children's Hospital at Westmead in Sydney, Australia. |
Deep neural-based segmentation algorithm with optimized feature engineering techniques. |
A convolved deep belief network known as CDBN, followed by a feature encoding algorithm. |
Classification among DN, GGN, GGNB, PDN, and UDN. |
86.01% of the average weighted F1 score is achieved. |
|
[13] |
The dataset comprises 1043 H&E-stained histologic images obtained from The Children's Hospital at Westmead in Sydney, Australia. |
Techniques used to segment and extract the features are SIFT, followed by Bag of Visual Words (BOVW). |
SVM is used for classification purposes. |
Classification among DN, GGN, GGNB, PDN, and UDN. |
The model can achieve 90% accuracy. This research saves computational time and vital image information better than [11]. |
|
[14] |
27,400 images were collected from nationwide children's hospitals under IRB with 40X magnification. 512×512 pixel ratio, and H&E Staining. |
A noble technique is introduced to isolate five salient components (nuclei, cytoplasm, neuropil, red blood cells, and background), and this info is used to construct a feature space vector. |
Various ML classifiers are tested, like KNN, LDA, CORRLDA, Bayesian, and SVM. |
Classification among DN, PDN, and UDN. |
For classifying WSI, 87.88% accuracy is achieved. |
|
[15] |
A dataset containing 65 CT images. |
A trained CNN is used to slice the image, followed by 105 radiomics are extracted by pyradiomics. |
6 ML techniques (Radiomics-based NN, lasso regression, elastic regression, LR, RF, and SVM). |
To predict mortality, presence and absence of metastases, ND, MKI, presence and absence of MYCN gene, and presence of IDRF. |
ROC results: Primary outcome 0.76, Mortality 0.79, presence of metastases 0.77, grade of neuroblastic differentiation 0.71, secondary outcome 0.63, presence of IDRF 0.74. |
|
[16] |
Two datasets are used: GSE49710 and E-MTAB-8248. |
Features are selected using the chi-square test, and 172 features are extracted, followed by the K-means clustering method to partition patients and genes. |
Encoders and decoders are used to predict the survival. |
Understanding the molecular mechanism of Neuroblastoma. |
The time-dependent ROC curve reaches 0.968 and 0.979 in the training set. |
|
[17] |
182 patients of NB are taken. |
572 radiomic features are extracted from MRI images; among these, 41 significant features are selected using the t-test. |
Thirteen different ML algorithms are deployed, and among these, the three best performers are chosen. |
Metastatic diagnosis and formulation of personalized healthcare strategies in clinics. |
AUC achieved is 0.90, and F2-Score was 0.82. sensitivity was 0.76. |
|
[18] |
The TARGET dataset, which is known as Therapeutically Applicable Research to generate Effective treatments, is used in this research. |
Heterogeneous ensemble learning method. |
ML approaches (Decision Tree, extreme gradient boosting algorithm, RF, genetic algorithm, and SVM). |
Predicting Neuroblastoma survival and extracting decision rules from the suggested technique to help doctors make decisions. |
AUC of 91.35% is achieved. |
|
[19] |
RNA-seq data from GDC. |
Mscore is calculated based on calculating Gene abundance, and random forestSRC for predicting the survival time. |
The chi-square test and Cox regression are used. |
COG risk stratification. |
Matrix-like, the Chi-square test and Cox proportional hazards regression coefficient are calculated. |
|
[20] |
Digital Hologram frames are extracted, and also COCO data set is also used. |
In total, 10 features from each image (Morphological and textural features) are extracted. |
Feature-based ML (MLP, LR) and DL (LeNet) algorithms are used, |
Differentiate two Neuroblastoma cell lines. |
MLP and LR (on binary mask inputs) achieve 92.2% and 95.5% classification accuracy on the test set, respectively. Mask-R-CNN outputs paired with LeNet-like CNN-based classification achieve 100% accuracy. |
|
[21] |
The expression data of 59 genes are meticulously collected from 579 patients: 30 for training, 313 for testing, and 236 for validation. |
Data mining techniques are used to extract information, multivariate regression. |
Spearman's rank correlation clustering, top-ranking univariate Cox and logistic regression studies, and the rank product approach. |
build and validate a gene expression profile for better outcome prediction. |
The signature accurately distinguishes patients based on overall and progression-free survival (p<0.0001). |
|
[22] |
H&E-stained 387 cropped image tiles obtained from 3-WSI images. |
Textural features are extracted, and optimized features are selected. |
SVM is used at different resolution levels (1,2,3, and 4) and extracts different counts of features 3, 6, 10, and 5 features to classify NB histology. |
NB histological classification: undifferentiated, differentiated, and poorly differentiated. |
The accuracies obtained are 90%, 84.62%, and 90%, respectively. |
|
[23] |
In totality, 47 microsamples were used in the study, extracted from 2 different datasets (Dataset 1: having 23 tumours of NB, while Dataset 2 contains 30 NB tumours, with 101 samples reserved for validation. |
4 different clusters are identified by using PCA. |
Unsupervised hierarchical clustering is used for validation. |
Subgrouping based on discrimination of gene profiling. |
4-subgroup is identified by 6 different gene expressions (MYCN, NTRK1, ALK, PHOX2B, BIRCS, and CCND1). |
|
[24] |
The data collection contains 96 samples' real-time gene expression. Real-time PCR and microarray studies include 362 patients. |
Initially, gene expression is normalized using z-transformation, and gene set combination is analyzed using PCA. |
Cox regression models are used to test the models |
The model segregates patients into 2 groups based on 3 identified genes (namely, PAFAH1B1, CHD5, and NME1). |
Two groups with different OS and EFS were identified from the 352 validation samples. |
|
[25] |
The TARGET matrix data portal collected 126 samples: 45 with MYCN gene amplification and 81 without. |
The feature space is built using differential methylation analysis, clustering, and recursive feature elimination |
Cox regression, ML, and Kaplan–Meier estimates were used to classify MYCN amplification and non-amplified groups. |
Grouping is performed between the amplified MYCN gene cluster vs non-MYCN amplified cluster. |
The CpG score and patient survival were correlated with the MYCN amplification status (OS: HR = 5.11, EFS: HR = 4.84). |
|
[26] |
Human methylation 450K dataset |
PCA is used for feature selection. |
Random forest is used as a classification approach. |
Clustering is performed based on MYCN genes. In total, 4 groups are formed. |
G1: is the MYCN amplified group, G2 is without MYCN amplification, G3 is those patients with the INSS-4 group, and G4 is stage I-III without MYCN. |
|
[27] |
From 107 patents in total, 563 WSI were obtained in the study. The data set is divided into two groups first is FH (67), another is UH (40). |
ML algorithms are utilized for segmenting and extracting characteristics. |
Only instance segmentation is performed. |
Classification between favorable vs. UH. |
With 98.62% recall and 98.65% precision, 3408 nuclei and 46 false positives were found. Clinicopathological parameters: AUC 0.946 in training and testing datasets. |
|
[28] |
The TARGET dataset contains 407 NB samples, of which 217 samples provide gene expression data. |
Deep learning algorithms and auto-encoders are used to integrate multi-omics data. |
k-means clustering, various ML algorithms including DNN, Cox-regression, SVM, naïve Bayes, LR, and XGboost were employed to distinguish two subtypes exhibiting notable survival variations. |
Divided the data into two subgroups. |
The P-value is calculated as P < 0.0001, indicating significant survival stratification. |
|
[29] |
The dataset comprises microarrays from 182 patients. The database is derived from 4 cohorts, consisting of 100 samples for training and 82 samples for testing. |
Artificial neural network and leave-one-out method, along with Kaplan-Meier plots and log-rank tests. |
MLP is trained on 62 62-probe set consisting of NB hypo signature genes. |
To determine the hypoxic state using NB-hypo signature genes. |
There are two prognosis groups categorized as good and bad based on separate overall survival (OS) and event-free survival (EFS). |
|
[30] |
Data is collected from the Cooperative Human Tissue Network (Ohio), the German Cancer Research Center, and the Children's Hospital at Westmead (Australia). |
Quality for filtering followed by PCA, 48 samples for training, leaving one sample out for testing, and Kaplan–Meier analysis. |
Artificial neural network. |
Partitioning the High-risk NB subtypes often metastasize in patients. |
ANN portioned high-risk patients on 39,920 clones, achieved p p-value of 0.006, and 19 ANN-ranked genes were achieved. |
|
[31] |
Histopathology (multi-center WSIs). |
Patch-based region extraction |
Vision Transformer (ViT) |
NB subtype classification. |
Accuracy = 91.3%, AUC = 0.93 |
|
[32] |
Simulated/benchmark datasets. |
Not applicable |
Self-eXplainable Neural Network. |
General disease prediction (XAI validation) |
Explanation fidelity, transparency score. |
|
[33] |
Clinical tabular data (COVID-19). |
Not applicable |
Swarm Learning (FL + Blockchain) |
Risk group prediction (cross-site) |
AUC = 0.81–0.91, cross-site agreement. |
|
[34] |
Simulated med datasets |
Not applicable |
SplitFed (CNN + FL) |
Distributed classification |
Accuracy = 87.5%, latency reduction. |
|
[35] |
Neuroblastoma (multi-omics). |
Feature fusion |
Deep survival model (multi-omics DL) |
Risk stratification & prognosis. |
Concordance index = 0.82, p < 0.001. |
|
[36] |
GDPR-focused decision frameworks. |
Not applicable |
Counterfactual Explanation Generator |
Legal audit of an AI decision. |
Interpretability validated qualitatively |
|
[37] |
ImageNet + medical variants. |
Not applicable |
Transformer explainability extension |
Class-level visual justification. |
IOU-based attention attribution. |
|
[38] |
Public ML datasets. |
Not applicable |
XAI-enabled ensemble models |
General interpretability framework. |
Case-study-based metrics. |
|
[39] |
ChestX-ray14 |
Bounding box pre-filter. |
DenseNet121 (CheXNet). |
Pneumonia detection. |
AUC = 0.94 (Radiologist-level). |
Several papers [18, 19, 23] have also applied ML to individualized risk scoring using Kaplan-Meier curves, Cox regression, and decision trees, helping separate low- and high-risk cohorts and tailoring clinical treatment planning. Deep learning architectures including CNNs and FCNNs have been applied to WSI classification and survival prediction, with some models reporting near-perfect classification metrics [12, 20, 29]. With growing adoption of ML in clinical research, interpretability has become a major concern. Classical post-hoc explainers like SHAP and Grad-CAM are increasingly being supplemented by S-XAI and counterfactual models, which offer embedded interpretability [32-33]. Similarly, FL frameworks such as Swarm Learning and SplitFed enable privacy-preserving model training across decentralized NB cohorts [31, 33]. These frameworks are especially suited to cross-institutional training environments where centralization of sensitive patient data is not permissible.
In summary, ML methods have substantially enhanced NB classification, prognosis, and therapeutic guidance. Yet, limitations related to dataset heterogeneity, generalizability, and model explainability remain. Future studies must increasingly incorporate multi-institutional and multi-modal data, emphasize explainable model architectures, and explore privacy-first federated learning paradigms. These developments are poised to accelerate the safe clinical adoption of AI in paediatric oncology.
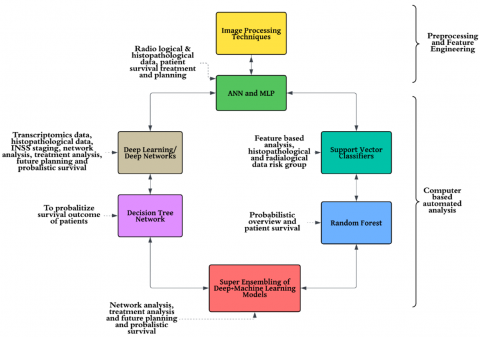
ML has emerged as a transformative tool in NB analysis, enabling computational evaluation of disease progression, therapeutic response, and survival outcomes. The integration of image processing, artificial neural networks (ANNs), multilayer perceptrons (MLPs), support vector machines (SVMs), deep learning models, decision trees, and random forest classifiers has substantially advanced diagnostic accuracy and risk stratification [10, 23]. These algorithms enable automatic feature extraction and classification of histopathological and radiological data, thereby facilitating robust risk prediction.
Figure 4 illustrates the synergistic interaction among these models. The process typically begins with image preprocessing techniques that enhance raw histological and radiological inputs for computational analysis. ANNs and MLPs are used to identify intricate patterns within these data, informing prognosis and treatment pathways [20]. Extracted features are then analyzed using SVMs and random forest classifiers to classify NB into risk categories based on histological grade and imaging biomarkers [12].
Deep learning models extend this capability by integrating transcriptomic, histological, and clinical staging information (such as the INSS and MYCN amplification status), offering deeper insights into tumour biology and enabling patient stratification [15]. Decision tree-based models provide interpretable probabilistic predictions of survival outcomes, aiding oncologists in clinical decision-making. More recently, ensemble methods combining ML and DL frameworks have been shown to improve prediction accuracy by leveraging the strengths of multiple algorithms simultaneously [29].
Despite these achievements, substantial methodological limitations hinder the generalizability and clinical translation of current approaches. Many reviewed studies are based on datasets with limited sample sizes or single-institution sourcing, which restrict population diversity and elevate the risk of overfitting. For instance, studies using fewer than 100 patient samples or isolated histopathological slides often report high accuracy, but these findings may not hold when tested on external datasets. This restricts their use in real-world settings where demographic variability is substantial.
In addition, dataset heterogeneity is a major barrier to reproducibility. Imaging studies vary significantly in magnification levels (e.g., 40× vs. 100×), staining protocols, and scanner calibration. Likewise, omics-based studies differ in gene normalization techniques, sequencing platforms, and preprocessing strategies. Without standardized pipelines, comparisons across models remain confounded by technical artifacts rather than true algorithmic performance. Annotation inconsistencies, particularly in differentiating poorly differentiated NB or stroma-poor subtypes, further impact the reliability of training labels and supervised learning outputs. Another critical concern is the lack of external validation. Most studies rely on random train-test splits or k-fold cross-validation within the same dataset, which does not simulate real-world variability. True external validation using independent cohorts—across institutions and acquisition protocols—is rarely performed. As a result, models trained on homogenous data frequently underperform when exposed to broader populations. This issue calls for more rigorous benchmarking using public datasets and community-driven ML challenges.
To address these limitations, we advocate for the integration of multi-institutional and demographically diverse datasets in future model training. Standardization of preprocessing workflows—such as using stain normalization methods (e.g., Macenko normalization for H&E slides) and unified gene normalization techniques—would reduce variability and improve reproducibility. Model evaluation protocols must incorporate nested cross-validation and independent test sets. Furthermore, open benchmarking platforms should be developed to facilitate fair and transparent algorithm comparisons.
Parallel to these limitations, interpretability remains a significant barrier to clinical adoption. The "black-box" nature of deep learning models hinders transparency and trust. Clinicians are often reluctant to rely on predictions that lack explanatory depth. To counter this, explainable AI (XAI) techniques such as Shapley Additive Explanations (SHAP) and Gradient-weighted Class Activation Mapping (Grad-CAM) have been introduced to visualize and interpret model decisions [21, 40, 41]. SHAP provides feature-level contribution scores, while Grad-CAM enables localization of salient image regions influencing decisions. Such tools can bridge the gap between algorithmic output and clinical reasoning [42, 43].
Ethical considerations are equally paramount in paediatric oncology. Ensuring patient confidentiality in training data—especially under frameworks such as the General Data Protection Regulation (GDPR) and Health Insurance Portability and Accountability Act (HIPAA)—is non-negotiable. In addition, biases in training data arising from underrepresentation of specific ethnic or socioeconomic groups can lead to inequitable outcomes [25]. Addressing this requires both adversarial debiasing strategies and deliberate inclusion of diverse cohorts during data acquisition.
Beyond algorithmic accuracy and interpretability, ethical considerations and data fairness are critical in deploying ML models for NB care. One prominent concern is training data bias, particularly when datasets are derived from a single geographic or institutional cohort. Such models may fail to generalize across populations with different genetic, socioeconomic, or ethnic profiles, leading to unintended disparities in diagnostic performance. For instance, underrepresentation of certain risk groups or age demographics could lead to overfitting in well-represented cohorts while underperforming for others [20, 25].
To mitigate this, several strategies have emerged. The inclusion of demographically diverse, multi-institutional datasets is fundamental to reduce institutional bias. Additionally, adversarial debiasing techniques—which train the model to reduce correlation with sensitive attributes (e.g., age, ethnicity, institution)—have shown promise in ensuring equitable predictions [44, 45]. Another emerging practice is the stratified sampling of training and validation cohorts, ensuring balanced representation during both model development and evaluation phases.
Furthermore, ethical compliance with data protection standards such as the GDPR and HIPAA is essential. FL, as discussed later, offers a privacy-preserving alternative by training models across multiple institutions without centralizing data. For equitable deployment, future frameworks must also include bias auditing, ensuring models are assessed across subpopulations and flagged when disproportionate error rates are observed.
One promising solution is the development of FL frameworks, which allow decentralized training across multiple institutions without the need to pool sensitive patient data. This approach not only preserves privacy but also enhances model robustness by incorporating heterogeneous sources. Future research should also focus on integrating multi-modal models that combine histopathology, radiomics, genomics, and clinical records for comprehensive NB risk estimation.
Recent advancements in FL have extended beyond conventional FL algorithms. For instance, Swarm Learning integrates blockchain with federated architectures to coordinate learning across untrusted medical institutions, ensuring both data privacy and verifiable contributions [33]. Similarly, SplitFed merges split learning and FL, enabling scalable training across resource-limited nodes by sharing only intermediary activations rather than raw data [34]. Such frameworks are especially suited to paediatric NB, where institutional silos and ethical restrictions make centralized data pooling unfeasible. Real-world validation, such as FL deployment across 20 hospitals for COVID-19 outcomes [44], demonstrates the viability of such methods in clinical environments. In addition to imaging and histopathological data, the integration of multi-omics layers (e.g., transcriptomics, methylation, proteomics) using deep learning has proven effective in refining risk prediction. A recent study by Dayan et al. [35] utilized a deep survival model on integrated omics datasets to identify complex molecular subtypes in NB, achieving superior predictive performance compared to unimodal models. These strategies support a shift toward biologically grounded stratification and could guide personalized therapeutic interventions by identifying latent prognostic features not visible in single-data domains. Histopathology analysis has also evolved with the application of ViTs, which surpass CNNs in modeling long-range tissue dependencies via self-attention mechanisms. ViTs have demonstrated improved classification accuracy in whole-slide image tasks across oncology domains [31]. To complement this, transformer-specific interpretability tools, such as Layer-wise Relevance Propagation (LRP) and attention rollout methods, enhance transparency by attributing decisions to spatially resolved features [37]. When combined with counterfactual explainability [36], these methods can offer actionable clinical insights while maintaining model trust and compliance with interpretability mandates.
Finally, prospective clinical validation is a critical next step. While most existing studies rely on retrospective data, the true utility of ML models lies in their performance in real-time clinical workflows. Future research must prioritize clinical trials and longitudinal evaluations of AI-driven models in real hospital settings.
While retrospective studies provide a foundational understanding of ML performance in NB diagnosis and prognosis, real-world clinical validation remains critically underexplored. Most of the cited works rely on previously collected datasets—often highly curated—lacking the complexity, noise, and variability of live clinical workflows. Prospective clinical trials are necessary to evaluate how these models perform in routine diagnostics, under diverse patient conditions, institutional workflows, and imaging modalities [11, 13].
Figure 4. NB analysis: With image processing with ML approaches
The future of ML in NB research and clinical application depends on advancing beyond current limitations toward robust, interpretable, and ethically deployable systems. One of the foremost priorities is to resolve the biological and technical heterogeneity inherent in NB datasets. This includes not only expanding cohort size but also incorporating multi-modal and multi-omics data integration, such as combining genomic (e.g., MYCN amplification), transcriptomic, methylation, proteomic, and radiomics data within unified prediction pipelines. Recent studies have shown that deep survival models leveraging multi-omics data can outperform unimodal predictors, enabling finer patient stratification and risk modeling [35]. Additionally, the use of multi-task learning architectures may support concurrent predictions (e.g., risk classification, therapy response, survival outcomes) using shared features extracted across data modalities.
A second key priority is enhancing model interpretability for clinical adoption. While techniques such as SHAP and Grad-CAM are currently used, future approaches should incorporate advanced XAI mechanisms. These include not only attention-based visualization modules in transformer networks, but also S-XAI frameworks that embed interpretability directly during model training [32]. Moreover, counterfactual explanation techniques offer an intuitive mechanism for clinicians to understand “why not” predictions—by illustrating the minimal changes needed to alter an outcome [36]. Tools like Layer-wise Relevance Propagation (LRP) and attention rollout further enable tracing decision paths in deep learning models, especially in complex visual contexts like histopathology. Embedding such explainability into diagnostic pipelines will increase clinician trust and assist regulatory compliance. Addressing data privacy and institutional silos is equally crucial. FL has emerged as a viable solution to train models collaboratively without requiring direct data sharing. Beyond standard approaches such as Federated Averaging (FedAvg), newer FL variants like SplitFed, FedProx, and Swarm Learning support personalized modeling, asynchronous updates, and decentralized governance, respectively. Swarm Learning, for example, leverages blockchain consensus to manage collaborative model training across untrusted environments [33], while SplitFed partitions model layers across edge and central servers to improve scalability and privacy [34]. These techniques have already demonstrated real-world clinical potential, including federated deployment across 20 hospitals for COVID-19 outcome prediction [44], and hold similar promise for paediatric oncology. Importantly, clinical translation will require structured prospective validation trials. Unlike retrospective studies, these must be conducted under routine diagnostic conditions using real-time data streams and involve cross-disciplinary collaborations among oncologists, radiologists, pathologists, data scientists, and regulatory stakeholders. Deployment should be guided by adaptive AI protocols, incorporating performance monitoring, clinician feedback loops, and post-deployment audit mechanisms. Alignment with frameworks such as AI regulatory sandboxes or hospital-based digital innovation hubs can streamline the pathway from bench to bedside.
Finally, ethical robustness must be built into every stage of ML model development. This involves deliberate inclusion of underrepresented populations during data collection, use of bias-detection and fairness auditing tools during training, and subgroup performance evaluation post-deployment [46]. Models should not only be accurate but also equitable across demographic boundaries. Transparent reporting of training data composition, validation protocols, and subgroup performance metrics should become standard practice in NB ML publications. Given the high stakes of paediatric oncology, aligning AI systems with ethical, legal, and clinical standards is not optional but foundational.
ML and AI have emerged as transformative paradigms in NB research, enabling breakthroughs in diagnosis, molecular risk stratification, and treatment optimization. By integrating multi-modal data—such as genomics, transcriptomics, radiological imaging, and histopathological features—computational approaches are now capable of generating robust predictive models that enhance clinical decision-making across stages of care. This review synthesizes the evolving landscape of ML methodologies applied to NB, highlighting their utility in classifying tumour subtypes, forecasting therapeutic response, and estimating survival probabilities with increasing accuracy.
Nonetheless, critical limitations persist in terms of data heterogeneity, lack of external validation, model interpretability, and ethical oversight. The reviewed literature reveals a predominant reliance on retrospective datasets and single-institution studies, underscoring the urgent need for prospective, multi-institutional clinical trials under real-world diagnostic settings. Furthermore, the “black-box” nature of many deep learning models continues to hinder clinical trust and adoption. However, the emergence of explainable AI frameworks—such as self-explaining networks and counterfactual reasoning—alongside federated learning techniques like Swarm Learning and SplitFed, offers new paths toward transparency, privacy, and equitable AI deployment.
Moving ahead, meaningful progress in NB care will require not only algorithmic innovation but also interdisciplinary collaboration, regulatory alignment, and intentional fairness auditing. Integrating bias-detection mechanisms, multi-omics fusion pipelines, and privacy-preserving modeling frameworks can ensure that ML evolves from research-centric experimentation to clinically embedded, trustworthy decision support systems. By addressing these multidimensional challenges, AI-driven solutions hold immense potential to improve diagnostic precision, personalize treatments, and enhance survival outcomes for children affected by NB.
This research was funded by Taif University, Saudi Arabia (Project No.: TU-DSPP-2024-52).
[1] Abel, F., Dalevi, D., Nethander, M., Jörnsten, R., De Preter, K., Vermeulen, J., Stallings, R., Kogner, P., Maris, J., Nilsson, S. (2011). A 6-gene signature identifies four molecular subgroups of Neuroblastoma. Cancer Cell International, 11(1): 9. https://doi.org/10.1186/1475-2867-11-9
[2] Althoff, K., Beckers, A., Bell, E., Nortmeyer, M., Thor, T., Sprüssel, A., Lindner, S., De Preter, K., Florin, A., Heukamp, L.C., Klein-Hitpass, L., Astrahantseff, K., Kumps, C., Speleman, F., Eggert, A., Westermann, F., Schramm, A., Schulte, J.H. (2015). A Cre-conditional MYCN-driven Neuroblastoma mouse model as an improved tool for preclinical studies. Oncogene, 34(26): 3357-3368. https://doi.org/10.1038/onc.2014.269
[3] Cangelosi, D., Pelassa, S., Morini, M., Conte, M., Bosco, M.C., Eva, A., Sementa, A.R., Varesio, L. (2016). Artificial neural network classifier predicts Neuroblastoma patients’ outcome. BMC Bioinformatics, 17(S12): 347. https://doi.org/10.1186/s12859-016-1194-3
[4] Cecchetto, G., Mosseri, V., De Bernardi, B., Helardot, P., Monclair, T., Costa, E., Horcher, E., Neuenschwander, S., Tomà, P., Rizzo, A., Michon, J., Holmes, K. (2005). Surgical risk factors in primary surgery for localized Neuroblastoma: The LNESG1 study of the European International Society of Paediatric Oncology Neuroblastoma Group. Journal of Clinical Oncology, 23(33): 8483-8489. https://doi.org/10.1200/JCO.2005.02.4661
[5] Colon, N.C., Chung, D.H. (2011). Neuroblastoma. Advances in Pediatrics, 58(1): 297-311. https://doi.org/10.1016/j.yapd.2011.03.011
[6] Peuchmaur, M., D’Amore, E.S.G., Joshi, V.V., Hata, J.I., Roald, B., Dehner, L.P., Gerbing, R.B., Stram, D.O., Lukens, J.N., Matthay, K.K., Shimada, H. (2003). Revision of the International Neuroblastoma Pathology Classification: Confirmation of favorable and unfavorable prognostic subsets in ganglioNeuroblastoma, nodular. Cancer, 98(10): 2274-2281. https://doi.org/10.1002/cncr.11773
[7] Saxena, P., Goyal, A. (2019). Study of computerized segmentation & classification techniques: An application to histopathological imagery. Informatica, 43(4): 561-572. https://doi.org/10.31449/inf.v43i4.2142
[8] Feng, Y., Wang, X., Zhang, J. (2022). A heterogeneous ensemble learning method for Neuroblastoma survival prediction. IEEE Journal of Biomedical and Health Informatics, 26(4): 1472-1483. https://doi.org/10.1109/JBHI.2021.3073056
[9] Singh, S.K., Rashid, M., Alshamrani, S.S., Alnfiai, M.M., Saxena, P., Khamparia, A. (2024). Efficient transfer learning approach for acute lymphoblastic leukemia diagnosis: Classification of lymphocytes and lymphoblastic cells. Traitement du Signal, 41(4): 1749-1761. https://doi.org/10.18280/ts.410409
[10] Gheisari, S., Catchpoole, D., Charlton, A., Kennedy, P. (2018). Convolutional deep belief network with feature encoding for classification of Neuroblastoma histological images. Journal of Pathology Informatics, 9(1): 17. https://doi.org/10.4103/jpi.jpi_73_17
[11] Gheisari, S., Catchpoole, D.R., Charlton, A., Melegh, Z., Gradhand, E., Kennedy, P.J. (2018). Computer aided classification of Neuroblastoma histological images using scale invariant feature transform with feature encoding. Diagnostics, 8(3): 56. https://doi.org/10.3390/diagnostics8030056
[12] Giwa, A., Rossouw, S.C., Fatai, A., Gamieldien, J., Christoffels, A., Bendou, H. (2021). Predicting amplification of MYCN using CpG methylation biomarkers in Neuroblastoma. Future Oncology, 17(34): 4769-4783. https://doi.org/10.2217/fon-2021-0522
[13] Irwin, M.S., Naranjo, A., Zhang, F.F., Cohn, S.L., London, W.B., Gastier-Foster, J.M., Ramirez, N.C., Pfau, R., Reshmi, S., Wagner, E., Nuchtern, J., Asgharzadeh, S., Shimada, H., Maris, J.M., Bagatell, R., Park, J.R., Hogarty, M.D. (2021). Revised Neuroblastoma risk classification system: A report from the Children’s Oncology Group. Journal of Clinical Oncology, 39(29): 3229-3241. https://doi.org/10.1200/JCO.21.00278
[14] Kong, J., Sertel, O., Shimada, H., Boyer, K.L., Saltz, J.H., Gurcan, M.N. (2009). Computer-aided evaluation of Neuroblastoma on whole-slide histology images: Classifying grade of neuroblastic differentiation. Pattern Recognition, 42(6): 1080-1092. https://doi.org/10.1016/j.patcog.2008.10.035
[15] Liu, T., Lv, Z., Xu, W., Liu, J., Sheng, Q. (2020). Role of image-defined risk factors in predicting surgical complications of localized Neuroblastoma. Pediatric Surgery International, 36: 1167-1172. https://doi.org/10.1007/s00383-020-04731-y
[16] Li, X., Wang, X., Huang, R., Stucky, A., Chen, X., Sun, L., Wen, Q., Zeng, Y., Fletcher, H., Wang, C., Xu, Y., Cao, H., Sun, F., Li, S., Zhang, X., Zhong, J. (2022). The machine-learning-mediated interface of microbiome and genetic risk stratification in Neuroblastoma reveals molecular pathways related to patient survival. Cancers, 14(12): 2874. https://doi.org/10.3390/cancers14122874
[17] Liu, Y., Jia, Y., Hou, C., Li, N., Zhang, N., Yan, X., Yang, L., Guo, Y., Chen, H., Li, J., Hao, Y., Liu, J. (2022). Pathological prognosis classification of patients with Neuroblastoma using computational pathology analysis. Computers in Biology and Medicine, 149: 105980. https://doi.org/10.1016/j.compbiomed.2022.105980
[18] London, W.B., Castleberry, R.P., Matthay, K.K., Look, A.T., Seeger, R.C., Shimada, H., Thorner, P., Brodeur, G., Maris, J.M., Reynolds, C.P., Cohn, S.L. (2005). Evidence for an age cutoff greater than 365 days for Neuroblastoma risk group stratification in the Children’s Oncology Group. Journal of Clinical Oncology, 23(27): 6459–6465. https://doi.org/10.1200/JCO.2005.05.571
[19] Lv, L., Zhang, Z., Zhang, D., Chen, Q., Liu, Y., Qiu, Y., Fu, W., Yin, X., Chen, X. (2023). Machine-learning radiomics to predict bone marrow metastasis of Neuroblastoma using magnetic resonance imaging. Cancer Innovation, 2(5): 405-415. https://doi.org/10.1002/cai2.92
[20] Maris, J.M. (2010). Recent advances in Neuroblastoma. New England Journal of Medicine, 362(23): 2202-2211. https://doi.org/10.1056/NEJMra0804577
[21] Monclair, T., Brodeur, G.M., Ambros, P.F., Brisse, H.J., Cecchetto, G., Holmes, K., Kaneko, M., London, W.B., Matthay, K.K., Nuchtern, J.G., von Schweinitz, D., Simon, T., Cohn, S.L., Pearson, A.D.J. (2009). The International Neuroblastoma Risk Group (INRG) staging system: An INRG Task Force Report. Journal of Clinical Oncology, 27(2): 298-303. https://doi.org/10.1200/JCO.2008.16.6876
[22] Saxena, P., Goyal, A. (2023). Accurate demarcation of a biased nucleus from H&E-stained follicular lymphoma tissues samples. The Imaging Science Journal, 71(8): 715-727. https://doi.org/10.1080/13682199.2023.2192550
[23] Park, A., Nam, S. (2019). Deep learning for stage prediction in Neuroblastoma using gene expression data. Genomics & Informatics, 17(3): e30. https://doi.org/10.5808/GI.2019.17.3.e30
[24] Sertel, O., Kong, J., Shimada, H., Catalyurek, U.V., Saltz, J.H., Gurcan, M.N. (2009). Computer-aided prognosis of Neuroblastoma on whole-slide images: Classification of stromal development. Pattern Recognition, 42(6): 1093-1103. https://doi.org/10.1016/j.patcog.2008.08.027
[25] Shimada, H., Ambros, I.M., Dehner, L.P., Hata, J., Joshi, V.V., Roald, B., Stram, D.O., Gerbing, R.B., Lukens, J.N., Matthay, K.K., Castleberry, R.P. (1999). International Neuroblastoma Pathology Classification (the Shimada system). Cancer, 86(2): 364-372. https://doi.org/10.1002/(SICI)1097-0142(19990715)86:2<364::AID-CNCR21>3.0.CO;2-7
[26] Shimada, H., Umehara, S., Monobe, Y., Hachitanda, Y., Nakagawa, A., Goto, S., Gerbing, R.B., Stram, D.O., Lukens, J.N., Matthay, K.K. (2001). International Neuroblastoma pathology classification for prognostic evaluation of patients with peripheral neuroblastic tumors: A report from the Children’s Cancer Group. Cancer, 92(9): 2451-2461. https://doi.org/10.1002/1097-0142(20011101)92:9<2451::aid-cncr1595>3.0.co;2-s
[27] Sugino, R.P., Ohira, M., Mansai, S.P., Kamijo, T. (2022). Comparative epigenomics by machine learning approach for Neuroblastoma. BMC Genomics, 23(1): 852. https://doi.org/10.1186/s12864-022-09061-y
[28] Vermeulen, J., De Preter, K., Naranjo, A., Vercruysse, L., et al. (2009). Predicting outcomes for children with Neuroblastoma using a multigene-expression signature: A retrospective SIOPEN/COG/GPOH study. The Lancet Oncology, 10(7): 663-671. https://doi.org/10.1016/S1470-2045(09)70154-8
[29] Nguyen, T.D., Tran, N., Ryu, S.S., Kim, M., Kim, H., Yoon, J. (2023). Vision transformers for histopathological image classification: A comprehensive review. Cancers, 15(10): 2715. https://doi.org/10.3390/cancers15102715
[30] Tjoa, M., Guan, C. (2021). Self-explaining AI as an alternative to post-hoc interpretability. Neural Computation, 33(9): 2443-2471. https://doi.org/10.1162/neco_a_01430
[31] Wachter, S., Mittelstadt, B., Russell, C. (2018). Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law & Technology, 31(2): 841–887. https://doi.org/10.2139/ssrn.3063289
[32] Chefer, H., Gur, S., Wolf, L. (2021). Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, pp. 782-791. https://doi.org/10.1109/CVPR46437.2021.00085
[33] Boehmke, B., Greenwell, B.M. (2019). Hands-On Machine Learning with R (1st ed.). Chapman and Hall/CRC. https://doi.org/10.1201/9780367816377
[34] Rajpurkar, P., Irvin, J., Chen, R.L., Wong, B., Dunnmon, J., Beyer, D., Ng, A.Y. (2017). CheXNet: Radiologist level pneumonia detection on chest X rays with deep learning. arXiv preprint arXiv:1711.05225. https://doi.org/10.48550/arXiv.1711.05225
[35] Dayan, I., Roth, H.R., Zhong, A., Harouni, A., et al. (2021). Federated learning for predicting clinical outcomes in COVID-19. Nature Medicine, 27: 1735-1743. https://doi.org/10.1038/s41591-021-01506-3
[36] Feng, C., Xiang, T., Yi, Z., Meng, X., Chu, X., Huang, G., Zhao, X., Chen, F., Xiong, B., Feng, J. (2021). A deep-learning model with the attention mechanism could rigorously predict survivals in Neuroblastoma. Frontiers in Oncology, 11: 653863. https://doi.org/10.3389/fonc.2021.653863
[37] Garcia, I., Mayol, G., Ríos, J., Domenech, G., Cheung, N.K.V., Oberthuer, A., Fischer, M., Maris, J.M., Brodeur, G.M., Hero, B., Rodríguez, E., Suñol, M., Galvan, P., de Torres, C., Mora, J., Lavarino, C. (2012). A three-gene expression signature model for risk stratification of patients with Neuroblastoma. Clinical Cancer Research, 18(7): 2012-2023. https://doi.org/10.1158/1078-0432.CCR-11-2483
[38] Wei, J.S., Greer, B.T., Westermann, F., Steinberg, S.M., Son, C.G., Chen, Q.R., Whiteford, C.C., Bilke, S., Krasnoselsky, A.L., Cenacchi, N., Catchpoole, D., Berthold, F., Schwab, M., Khan, J. (2004). Prediction of clinical outcome using gene expression profiling and artificial neural networks for patients with Neuroblastoma. Cancer Research, 64(19): 6883-6891. https://doi.org/10.1158/0008-5472.CAN-04-0695
[39] Saxena, P., Sinha, A., Singh, S.K. (2025). Computer-assisted interpretation, in-depth exploration and single cell type annotation of RNA sequence data using k-means clustering algorithm. Computer Methods in Biomechanics and Biomedical Engineering, 28(5): 668-678. https://doi.org/10.1080/10255842.2023.2300685
[40] Delli Priscoli, M., Memmolo, P., Ciaparrone, G., Bianco, V., Merola, F., Miccio, L., Bardozzo, F., Pirone, D., Mugnano, M., Cimmino, F., Capasso, M., Iolascon, A., Ferraro, P., Tagliaferri, R. (2021). Neuroblastoma cells classification through learning approaches by direct analysis of digital holograms. IEEE Journal of Selected Topics in Quantum Electronics, 27(5): 1-9. https://doi.org/10.1109/JSTQE.2021.3059532
[41] Hussein, R., Abou Shanab, A.M., Badr, E. (2024). A multi omics approach for biomarker discovery in Neuroblastoma: A network based framework. NPJ Systems Biology and Applications, 10: 52. https://doi.org/10.1038/s41540-024-00371-3
[42] Warnat-Herresthal, M., Schultze, F., Manamohan, S., Mukherjee, S., et al. (2021). Swarm learning for decentralized and confidential clinical machine learning. Nature, 594: 265-270. https://doi.org/10.1038/s41586-021-03583-3
[43] Gupta, P., Shah, R.R. (2022). SplitFed: When federated learning meets split learning. Pattern Recognition Letters, 154: 104-110. https://doi.org/10.1016/j.patrec.2021.11.011
[44] Zhang, L., Lv, C., Jin, Y., Cheng, G., Fu, Y., Yuan, D., Tao, Y., Guo, Y., Ni, X., Shi, T. (2018). Deep learning-based multi-omics data integration reveals two prognostic subtypes in high-risk Neuroblastoma. Frontiers in Genetics, 9: 477. https://doi.org/10.3389/fgene.2018.00477
[45] Saxena, P., Aggarwal, S.K., Sinha, A., Saxena, S., Singh, A.K. (2024). Review of computer-assisted diagnosis model to classify follicular lymphoma histology. Cell Biochemistry and Function, 42(5): e4088. https://doi.org/10.1002/cbf.4088
[46] Gichoya, G.K., Banerjee, J., Bhimireddy, A., et al. (2022). AI recognition of patient race in medical imaging: A modelling study. The Lancet Digital Health, 4(7): e406-e414. https://doi.org/10.1016/S2589-7500(22)00063-2