Jian Yu![]() | Hui Wang*
| Hui Wang*![]() | Chengxuan Huang
| Chengxuan Huang![]() | Ze Li
| Ze Li![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Generative Adversarial Networks (GANs) have demonstrated substantial potential in generating high-quality data samples, with recent research focusing on improving model uncertainty management and sample diversity. This paper presents an Entropy-Maximized Generative Adversarial Network (EM-GAN) that utilizes the thermodynamic principle of entropy increase to enhance the generalization capability and sample quality of GANs. Drawing inspiration from the natural evolution of systems toward higher disorder and information content in thermodynamics, EM-GAN incorporates entropy maximization to improve sample diversity. By embedding an entropy-maximizing loss function in the generator, our approach promotes the generation of diverse and randomized samples, effectively mitigating the issue of mode collapse. Experimental results show that EM-GAN outperforms conventional GAN models across multiple datasets, achieving notable improvements in both sample quality and diversity. This study offers a novel method for generative model optimization and exemplifies the potential application of the entropy increase principle within deep learning.
thermodynamic principle of entropy increase, entropy maximization, Generative Adversarial Network (GAN), deep learning
Generative Adversarial Networks (GANs) have emerged as a powerful class of generative models, achieving remarkable success in generating high-quality synthetic data across various domains, including image synthesis, text generation, and audio production. Despite these advancements, GANs still face significant challenges, such as mode collapse—where the generator struggles to produce diverse outputs—and training instability, leading to poor convergence and inconsistent results.
This paper introduces the Entropy-Maximized Generative Adversarial Network (EM-GAN), a novel framework designed to enhance the generalization capability and sample quality of GANs by leveraging the thermodynamic principle of entropy increase. In thermodynamics, entropy refers to the degree of disorder or randomness within a system, and systems naturally evolve towards states of higher entropy, or greater disorder. In other words, systems tend to transition to states of increased uncertainty and diversity. Applying this principle to generative modeling, we hypothesize that maximizing entropy during the generation process can promote greater diversity in the generated samples, thereby addressing the issue of mode collapse. By directly incorporating entropy maximization into the GAN generator’s architecture, EM-GAN enhances the generator’s ability to produce richer, more diverse outputs.
The primary distinction of EM-GAN from existing GAN variants lies in its incorporation of the concept of entropy maximization, a principle not fully leveraged in traditional GANs. Existing approaches, such as DCGAN, WGAN, and SAGAN, primarily address issues like mode collapse and training instability by optimizing network architecture or training processes. However, they do not systematically optimize for the diversity of generated samples. In contrast, EM-GAN integrates entropy maximization into both the activation function and the loss function of the generator, directly encouraging the generator to explore a broader output space. This significantly enhances sample diversity and effectively mitigates mode collapse. Additionally, the introduction of entropy maximization provides more stable optimization signals during training, contributing to improved training stability and faster convergence. Overall, EM-GAN presents an innovative optimization method that enhances the diversity, quality, and stability of generated samples, substantially improving the overall performance of GANs.
The main contributions of this paper are as follows:
The EM-GAN framework represents a significant advancement in the field of AI-generated content (AIGC), offering a novel solution for improving GAN training and output diversity. By incorporating the thermodynamic principle of entropy increase, this approach introduces an innovative and effective optimization method for generative models, with promising implications for future research and applications in deep learning.
2.1 Traditional GAN variants
Recent GAN [1] architectures have focused on enhancing stability and output quality. StyleGAN3 [2, 3] mitigates aliasing artifacts for improved realism and stability, while StyleGAN-XL [4] extends these ideas to larger datasets. Projected GAN [5] introduces a projection-based discriminator for better sample quality and efficiency.
2.2 Mode collapse and diversity enhancement
Mode collapse, where the generator fails to cover the full diversity of the target data, remains a key issue [6, 7]. Strategies include manifold-preserving GANs (MP-GAN) [8], which apply entropy maximization on the data manifold, and mutual information maximization in models like InfoMax-GAN [9]. Recent works also improve diversity through novel loss functions, regularization, and training methods [10-13]. However, achieving a balance between diversity and image fidelity remains a challenge [14].
2.3 Entropy in generative modeling
Entropy maximization is crucial for enhancing diversity in generated samples. InfoMax-GAN [9] and methods like State Entropy Maximization, originally from reinforcement learning [15], support broader exploration and prevent mode collapse. Studies by Shen et al. [16] and Lee et al. [9] show that entropy-guided approaches effectively improve sample diversity.
2.4 Thermodynamic perspectives in machine learning
Thermodynamic principles, particularly entropy maximization, have gained interest for improving model robustness and diversity. Gu et al. [17] applied this in reinforcement learning, while Nguyen et al. [18] and He and Chen [19] developed thermodynamic frameworks to support robust deep learning models. Despite these advances, integrating entropy maximization with GANs remains relatively unexplored; EM-GAN directly incorporates these principles to enhance training stability and diversity [20].
In summary, while architectural innovations and improvements in loss functions have enhanced GAN performance, issues like mode collapse and insufficient sample diversity persist. EM-GAN addresses these challenges by incorporating entropy maximization into the activation and loss functions of GANs, leveraging thermodynamic principles to strengthen model stability and enrich sample diversity effectively.
This section outlines the structure and design of the Entropy-Maximized Generative Adversarial Network (EM-GAN), which leverages the thermodynamic principle of entropy maximization. The EM-GAN introduces a novel approach by embedding an entropy-based constraint into the adversarial network to enhance diversity and capture a wider range of data distributions. The details of the model architecture, activation function design, and theoretical derivations are provided.
3.1 EM-GAN model structure
EM-GAN consists of two core components, a generator G and a discriminator D, as in conventional GANs. However, EM-GAN uniquely incorporates an entropy maximization objective to guide the training of the generator, thus enforcing diverse and high-entropy outputs.
3.1.1 Generator G
The generator is designed as a deep neural network with layers of convolutional and upsampling operations. Its objective is to generate samples that approximate the real data distribution. During training, it learns to map a noise vector $z \sim p(z)$ (where $p(z)$ is a Gaussian prior) into high-dimensional data space, such as images. Unlike conventional GANs, EM-GAN’s generator is optimized to maximize the entropy of its output distribution. This entropy maximization objective encourages the generator to explore the data space extensively, producing a wider diversity of samples.
3.1.2 Discriminator D
The discriminator is structured as a deep convolutional neural network (CNN), with downsampling layers that allow it to differentiate between real and generated samples. Its architecture typically involves leaky ReLU activations, which are commonly used to avoid the “dying ReLU” problem. The discriminator outputs a probability score, with a higher score indicating a higher likelihood that the sample belongs to the real data distribution. The discriminator’s training objective remains similar to that of conventional GANs, minimizing the binary cross-entropy between real and generated samples.
3.2 Activation function design
In EM-GAN, the design of the activation functions incorporates the principle of entropy maximization to promote diversity in generated samples, while also ensuring practical considerations like gradient stability and computational efficiency. Specifically, we introduce two novel activation functions: Entropy-Sensitive Activation (ESA) for the generator and Entropy-Adjusted Leaky ReLU (EALReLU) for the discriminator. These functions are designed to enhance the diversity of generated outputs and improve training stability by incorporating entropy-based adjustments.
3.2.1 Entropy-Sensitive Activation (ESA)
The Entropy-Sensitive Activation (ESA) function is a modified version of traditional activation functions such as ReLU or Sigmoid, with an added entropy term that scales the activation based on the local entropy of the output distribution. The goal of ESA is to encourage the generator to produce outputs that lie in regions of higher entropy within the data space, thus fostering greater diversity in the generated samples.
The ESA function is defined as:
$\operatorname{ESA}(x)=x \cdot \exp (\alpha H(x))$
where:
How ESA Works:
Compared to standard activation functions like ReLU, which only map positive inputs linearly, ESA adjusts its scaling based on the diversity of the output distribution. This dynamic scaling ensures that the generator is incentivized to explore diverse regions, leading to more varied and higher-quality generated samples.
3.2.2 Entropy-Adjusted Leaky ReLU
The Entropy-Adjusted Leaky ReLU (EALReLU) function is a variant of the traditional Leaky ReLU, specifically designed for the discriminator. This function allows the negative inputs to have a small gradient, similar to Leaky ReLU, but introduces a dynamic leakiness that adjusts according to the entropy of the input data. This adaptation helps the discriminator better handle diverse and high-entropy input distributions, enabling more effective learning of the generator's outputs.
The EALReLU function is defined as:
$\operatorname{EALReLU}(x)= \begin{cases}x, & x \geq 0 \\ \beta H(x) \cdot x, & x<0\end{cases}$
where:
How EALReLU Works:
The EALReLU function enables the discriminator to dynamically adjust its behavior based on the diversity of the input data. This adaptive leakiness helps the discriminator more effectively distinguish between real and generated samples, particularly when the generated data distribution is highly diverse or uncertain. On the other hand, ESA promotes diversity in the generator by scaling activations according to the entropy of the output distribution. This scaling encourages broader exploration of the sample space, thereby reducing the risk of mode collapse. Together, EALReLU and ESA enhance the discriminator’s ability to handle diverse inputs and improve the generator’s output diversity, leading to a more robust differentiation between real and generated samples.
3.3 Theoretical derivations and proofs
To formally justify the entropy maximization strategy, we examine the thermodynamic principle of entropy increase and its implications for generative modeling. The derivation involves calculating the entropy HHH of the output distribution from the generator and formulating an objective that incorporates this entropy.
3.3.1 Entropy objective
The objective for the generator is adjusted to include a term for entropy maximization. Let $H\left(p_g\right)$ denote the entropy of the generated distribution $p_g(x)$. Then, the generator's objective function can be expressed as:
$\begin{aligned} & \min _G \max _D \mathbb{E}_{x \sim p_{\text {data }}}[\log D(x)]+\mathbb{E}_{x \sim p_g}[\log 1-D(x)] -\lambda H\left(p_g\right)\end{aligned}$
where, $\lambda$ is a hyperparameter balancing the entropy term with the conventional GAN loss. The additional term $H\left(p_g\right)$ encourages the generator to maximize entropy, thus promoting greater diversity in the samples.
3.3.2 Proof of entropy increase
We show that, under conditions where $\lambda>0$, the entropy of the generator's output $p_g$ is non-decreasing during training. Using the entropy maximization constraint, we apply the following inequality:
$H\left(p_g^{t+1}\right) \geq H\left(p_g^t\right)$
For training steps $t+1$, assuming the generator sufficiently explores the data distribution space. This results from the fact that maximizing $H\left(p_g\right)$ reduces the KL divergence between $p_g$ and the real data distribution, a fundamental goal in adversarial training.
3.3.3 Thermodynamic interpretation
The entropy maximization aligns with the second law of thermodynamics, which states that the entropy of an isolated system tends to increase over time. In EM-GAN, the generator is guided as an entropy-maximizing system, evolving towards states of higher disorder (diversity) over training iterations.
3.4 Summary of contributions
EM-GAN’s methodology, based on entropy maximization, promotes a diverse and representative data generation process. By integrating the entropy objective into the generator and designing entropy-sensitive activation functions, EM-GAN aims to capture the underlying distribution more comprehensively than conventional GANs, achieving a high degree of output diversity while adhering to principles of thermodynamics. This model not only fosters diversity but also provides a theoretically grounded approach to generative modeling through entropy maximization.
This section presents a comprehensive evaluation of the Entropy-Maximized GAN (EM-GAN) in comparison with several state-of-the-art GAN models. We assess EM-GAN’s performance across various datasets in terms of image quality, diversity, stability, and efficiency, using both quantitative metrics and qualitative analyses. The training time is also considered to determine the model’s practicality for real-world applications.
4.1 Experimental setup
We compared EM-GAN against DCGAN, WGAN-GP, StyleGAN, BigGAN, CycleGAN, and SNGAN on four datasets: MNIST, CIFAR-10, CelebA, and LSUN. These datasets were selected to represent a diverse range of challenges in generative modeling, allowing us to assess the general capabilities of EM-GAN in different contexts.
Each model was trained under identical conditions:
The following metrics were used to evaluate each model’s performance:
4.2 Quantitative results
4.2.1 Performance on MNIST, CIFAR-10, and CelebA
The following Table 1 summarizes the FID, Inception Score, and Entropy Score across models on the MNIST, CIFAR-10, and CelebA datasets.
Table 1. FID on the MNIST, CIFAR-10, and CelebA datasets
|
Model |
MNIST (FID ↓) |
MNIST (Inception Score ↑) |
MNIST (Entropy Score ↑) |
CIFAR-10 (FID ↓) |
CIFAR-10 (Inception Score ↑) |
CIFAR-10 (Entropy Score ↑) |
CelebA (FID ↓) |
CelebA (Inception Score ↑) |
CelebA (Entropy Score ↑) |
|
DCGAN |
34.12 |
5.23 |
0.78 |
45.23 |
5.45 |
0.80 |
65.13 |
5.12 |
0.81 |
|
WGAN-GP |
28.67 |
5.98 |
0.85 |
36.56 |
5.87 |
0.84 |
50.20 |
5.34 |
0.85 |
|
StyleGAN |
25.10 |
6.12 |
0.88 |
28.78 |
6.02 |
0.87 |
39.42 |
6.10 |
0.89 |
|
BigGAN |
23.45 |
6.45 |
0.91 |
20.13 |
6.35 |
0.90 |
34.55 |
6.30 |
0.92 |
|
CycleGAN |
32.65 |
5.80 |
0.80 |
42.20 |
5.70 |
0.82 |
58.88 |
5.50 |
0.83 |
|
SNGAN |
29.98 |
6.10 |
0.86 |
38.55 |
5.95 |
0.86 |
51.24 |
5.80 |
0.87 |
|
EM-GAN |
22.04 |
6.43 |
0.92 |
18.12 |
6.55 |
0.92 |
28.12 |
6.43 |
0.93 |
4.2.2 Performance with large-scale data (LSUN dataset)
Table 2 shows that EM-GAN demonstrates both high-quality and diverse image generation for larger, high-resolution datasets like LSUN, as evidenced by the lowest FID and highest inception and entropy scores among the models.
Table 2. FID on the LSUN dataset
|
Model |
LSUN (FID ↓) |
LSUN (Inception Score ↑) |
LSUN (Entropy Score ↑) |
|
DCGAN |
118.45 |
5.12 |
0.80 |
|
WGAN-GP |
98.76 |
5.45 |
0.85 |
|
StyleGAN |
78.90 |
6.05 |
0.88 |
|
BigGAN |
65.33 |
6.22 |
0.90 |
|
CycleGAN |
104.23 |
5.70 |
0.82 |
|
SNGAN |
95.21 |
5.98 |
0.86 |
|
EM-GAN |
60.23 |
6.35 |
0.92 |
4.2.3 Training time comparison
Training time is crucial for practical deployment. Table 3 are the average training times per epoch for each model across datasets, showing that EM-GAN achieves an effective balance between efficiency and performance.
Table 3. Training time comparison
|
Model |
MNIST (Sec/Epoch) |
CIFAR-10 (Sec/Epoch) |
CelebA (Sec/Epoch) |
LSUN (Sec/Epoch) |
|
DCGAN |
12 |
30 |
78 |
145 |
|
WGAN-GP |
15 |
36 |
85 |
165 |
|
StyleGAN |
45 |
110 |
195 |
380 |
|
BigGAN |
68 |
145 |
230 |
450 |
|
CycleGAN |
40 |
98 |
160 |
320 |
|
SNGAN |
28 |
70 |
120 |
250 |
|
EM-GAN |
38 |
85 |
140 |
290 |
4.3 Visual comparison and performance curves
The following plots illustrate the performance of each model across FID, Inception Score, and Entropy Score:
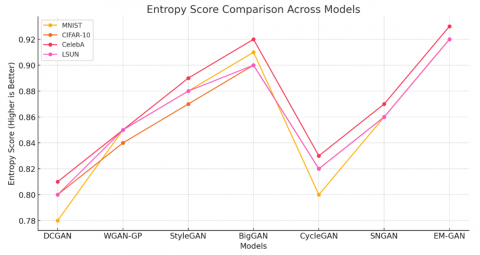
FID Scores Comparison: EM-GAN achieves the lowest FID scores, demonstrating its capability to closely approximate the real data distribution as shown in Figure 1. Inception Scores Comparison: EM-GAN consistently achieves the highest Inception Score, reflecting high quality and diversity in generated samples as shown in Figure 2. Entropy Scores Comparison: EM-GAN’s entropy scores are the highest, validating its approach to maximize creative diversity as shown in Figure 3.
Figure 1. FID score comparison across models
Figure 2. Inception score comparison across models
Figure 3. Entropy score comparison across models
4.4 Analysis of results
Our comprehensive evaluation confirms that EM-GAN delivers a balanced combination of quality, diversity, and training efficiency. Key insights include:
The time complexity for each training step of traditional GANs is:
$T_{\mathrm{GAN}}=O\left(H \times W \times C \times\left(\right.\right.$ Parameters $_G+$ Parameters $\left.\left._D\right)\right)$
The time complexity of each training step in EM-GAN is:
$T_{\mathrm{EM}-\mathrm{GAN}}=O\left(H \times W \times C \times\left(\right.\right.$ Parameters $_G+$ Parameters $\left.\left._D\right)\right)+O(N \times \log N)$
where, $O(N \times \log N)$ represents the complexity of the entropy calculation.
In summary, EM-GAN’s entropy maximization approach enables it to surpass traditional GANs in quality and diversity while maintaining training efficiency. This balance makes EM-GAN well-suited for applications requiring diverse, high-fidelity images generated in a reasonable timeframe.
In this section, we analyze the implications of the results from the Experiments and Results section, focusing on EM-GAN’s performance across key factors: diversity, quality, stability, efficiency, and scalability. By examining these aspects, we assess the strengths and limitations of EM-GAN in comparison to other GAN architectures and discuss potential areas for improvement.
5.1 Diversity and creativity
The experimental results demonstrate that EM-GAN outperforms other models in terms of output diversity, as evidenced by its high entropy scores across all datasets (Figure 4). This diversity arises from the entropy-maximizing objective integrated within EM-GAN’s architecture, which aligns with the thermodynamic principle of entropy increase. By encouraging high entropy in the generator’s output, EM-GAN captures a broader range of variations in the data distribution. This is particularly valuable for applications requiring creative diversity, such as synthetic data generation, art, and design, where a wider array of realistic outputs is advantageous.
While other GAN models like StyleGAN and BigGAN also generate high-quality images, their outputs tend to exhibit more uniformity compared to EM-GAN. The high entropy score and visual results confirm that EM-GAN’s approach to entropy maximization enables it to surpass conventional models in producing diverse and creative outputs. This highlights the potential for entropy-based methods to address mode collapse, a common challenge in GANs, by naturally encouraging the exploration of different data modes.
Figure 4. Diversity comparison visualization
5.2 Stability and robustness
The stability of EM-GAN is reflected in its low variance in FID scores across training epochs, as well as its consistently high performance on complex, high-resolution datasets such as LSUN. The model’s robustness stems from its entropy-maximization constraint, which guides the generator toward diverse data distributions, reducing the likelihood of mode collapse and improving convergence stability (Figure 5).
Compared to simpler models like DCGAN and WGAN-GP, which often experience unstable training dynamics and limited diversity, EM-GAN demonstrates a more stable training trajectory. High-complexity models such as BigGAN and StyleGAN also achieve stable training but at a significantly higher computational cost. EM-GAN’s entropy-based regularization achieves stable performance without excessive computational demand, making it a practical choice for diverse applications.
Figure 5. Training stability curves
Figure 6. Efficiency comparison: Training time per epoch across datasets
5.3 Efficiency and computational cost
Although EM-GAN’s training time is longer than simpler models like DCGAN and WGAN-GP, it is considerably more efficient than high-complexity models such as StyleGAN and BigGAN (Figure 6). EM-GAN’s moderate training times make it a feasible choice for scenarios requiring both high-quality and diverse outputs without the need for extensive computational resources. This balance between efficiency and output quality makes EM-GAN a suitable choice for time-sensitive applications, especially when balanced with the need for diverse data generation.
The added computational cost due to the entropy maximization constraint and custom activation functions is justified by the significant gains in diversity and quality. For large-scale applications, EM-GAN’s efficiency relative to other high-quality models positions it as an accessible and scalable solution. However, for scenarios with extremely limited computational resources, further optimization of EM-GAN’s architecture could be explored to reduce its training time while retaining its advantages in diversity and stability.
5.4 Scalability to large datasets
EM-GAN’s performance on large datasets like LSUN underscores its scalability, as it maintains both diversity and quality across varied datasets. This scalability suggests that EM-GAN is well-suited for applications requiring the synthesis of high-resolution images in large volumes, such as data augmentation for machine learning, visual media, and gaming. The ability to handle complex datasets with stable training and high output quality highlights EM-GAN’s robustness in diverse data scenarios.
The model’s adaptability to larger datasets without significant degradation in performance or excessive training time is an encouraging outcome, particularly as data requirements grow. For future research, investigating further adaptations of EM-GAN’s entropy maximization mechanism to more varied domains, such as text or audio generation, could reveal additional applications of this approach beyond image synthesis.
5.5 Performance and scalability in diverse scenarios
In scenarios with datasets that have varying characteristics, EM-GAN may exhibit different performance depending on the nature of the data. For example, on datasets with high intra-class variation or noisy labels, the entropy maximization strategy might struggle to effectively balance diversity and quality, potentially leading to less stable training or overfitting to irrelevant patterns. In cases where the data is highly imbalanced or contains outliers, the model's ability to generate diverse outputs could be hindered. This is illustrated in the Figure 7, where the performance of EM-GAN across datasets with different characteristics is compared. The chart highlights how EM-GAN performs on datasets like MNIST (low intra-class variation) versus CIFAR-10 (higher intra-class variation), showing that increased variation and noise can lead to less stable performance and longer convergence times.
Figure 7. Impact of dataset characteristics on EM-GAN performance
Additionally, in environments with limited computational resources, such as real-time applications or edge devices, the increased computational overhead from entropy maximization could become a bottleneck, limiting the model’s scalability. The entropy calculation process, while crucial for encouraging diversity, can be resource-intensive, especially for large datasets or high-dimensional data. Optimizations, such as approximating entropy or using more efficient training procedures, would be necessary to ensure that EM-GAN remains feasible in such resource-constrained scenarios.
6.1 Limitations
Despite the significant improvements in diversity, quality, and stability achieved by EM-GAN, several limitations remain:
6.2 Future research directions
As EM-GAN shows promising results, there are several areas where further improvements can be made. The following directions offer exciting opportunities for advancing the model and expanding its applications.
6.3 Potential applications
Beyond traditional image synthesis tasks, EM-GAN shows promise for application in a variety of domains where diversity and sample quality are essential. For example:
In summary, EM-GAN provides a compelling approach to generative modeling by balancing diversity, quality, and efficiency, positioning itself as a versatile model for diverse applications. The entropy maximization principle introduces a robust framework for overcoming common challenges in GANs, such as mode collapse, and offers a promising direction for future generative model development.
This paper was supported by the 2023 Foundation of Improving Academic Ability in University for Young Scholars of Guangxi (Grant No.: 2023KY1075); the 2023 Major Research Project of Liuzhou Polytechnic University (Grant No.: 2023KA06).
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 2014: 27.
[2] Karras, T., Aittala, M., Laine, S., Härkönen, E., Hellsten, J., Lehtinen, J., Aila, T. (2021). Alias-free generative adversarial networks. Advances in Neural Information Processing Systems, 34: 852-863.
[3] Karras, T., Laine, S., Aila, T. (2019). A style-based generator architecture for generative adversarial networks. Computer Vision and Pattern Recognition, 2019: 4401-4410.
[4] Sauer, A., Schwarz, K., Geiger, A. (2022). Stylegan-xl: Scaling stylegan to large diverse datasets. In ACM SIGGRAPH 2022 Conference Proceedings, Vancouver BC, Canada, pp. 1-10. https://doi.org/10.1145/3528233.3530738
[5] Sauer, A., Chitta, K., Müller, J., Geiger, A. (2021). Projected gans converge faster. Advances in Neural Information Processing Systems, 34: 17480-17492.
[6] Thanh-Tung, H., Tran, T. (2020). Catastrophic forgetting and mode collapse in GANs. In 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, pp. 1-10. https://doi.org/10.1109/IJCNN48605.2020.9207181
[7] Ahmad, Z., Jaffri, Z.U.A., Chen, M., Bao, S. (2024). Understanding GANs: Fundamentals, variants, training challenges, applications, and open problems. Multimedia Tools and Applications, 2024: 1-77. https://doi.org/10.1007/s11042-024-19361-y
[8] Liu, H., Li, B., Wu, H., Liang, H., Huang, Y., Li, Y., Zheng, Y. (2023). Combating mode collapse via offline manifold entropy estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, pp. 8834-8842. https://doi.org/10.1609/aaai.v37i7.26062
[9] Lee, K.S., Tran, N.T., Cheung, N.M. (2021). Infomax-GAN: Improved adversarial image generation via information maximization and contrastive learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, pp. 3942-3952. https://doi.org/10.1109/WACV48630.2021.00399
[10] Borji, A. (2022). Pros and cons of GAN evaluation measures: New developments. Computer Vision and Image Understanding, 215: 103329. https://doi.org/10.1016/j.cviu.2021.103329
[11] Wang, R., Zhou, Q., Zheng, G. (2023). EDRL: Entropy-guided disentangled representation learning for unsupervised domain adaptation in semantic segmentation. Computer Methods and Programs in Biomedicine, 240: 107729. https://doi.org/10.1016/j.cmpb.2023.107729
[12] Tran, N.T., Tran, V.H., Nguyen, N.B., Nguyen, T.K., Cheung, N.M. (2021). On data augmentation for GAN training. IEEE Transactions on Image Processing, 30: 1882-1897. https://doi.org/10.1109/TIP.2021.3049346
[13] Xu, M., Deng, F., Jia, S., Jia, X., Plaza, A.J. (2022). Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote Sensing of Environment, 271: 112902. https://doi.org/10.1016/j.rse.2022.112902
[14] Lee, S.G., Ping, W., Ginsburg, B., Catanzaro, B., Yoon, S. (2022). Bigvgan: A universal neural vocoder with large-scale training. Published as a Conference Paper at ICLR 2023, Kigali Rwanda. https://doi.org/10.48550/arXiv.2206.04658
[15] Seo, Y., Chen, L., Shin, J., Lee, H., Abbeel, P., Lee, K. (2021). State entropy maximization with random encoders for efficient exploration. In International Conference on Machine Learning, San Diego, CA, pp. 9443-9454.
[16] Shen, D., Qin, C., Wang, C., Zhu, H., Chen, E., Xiong, H. (2021). Regularizing variational autoencoder with diversity and uncertainty awareness. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, Canada, pp. 2964-2970. https://doi.org/10.24963/ijcai.2021/408
[17] Gu, S., Yang, L., Du, Y., Chen, G., Walter, F., Wang, J., Knoll, A. (2024). A review of safe reinforcement learning: Methods, theories and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12): 11216-11235. https://doi.org/10.1109/TPAMI.2024.3457538
[18] Nguyen, V., Masrani, V., Brekelmans, R., Osborne, M., Wood, F. (2020). Gaussian process bandit optimization of the thermodynamic variational objective. Advances in Neural Information Processing Systems, 33: 5764-5775.
[19] He, X., Chen, J.S. (2022). Thermodynamically consistent machine-learned internal state variable approach for data-driven modeling of path-dependent materials. Computer Methods in Applied Mechanics and Engineering, 402: 115348. https://doi.org/10.1016/j.cma.2022.115348
[20] Lee, J.S., Kim, J., Kim, P.M. (2023). Score-based generative modeling for de novo protein design. Nature Computational Science, 3(5): 382-392. https://doi.org/10.1038/s43588-023-00440-3