Hassan A. Alshamrani![]() | Khalaf Alshamrani
| Khalaf Alshamrani![]() | Mamoon Rashid*
| Mamoon Rashid*![]() | Sultan S. Alshamrani
| Sultan S. Alshamrani![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The epidemic had a significant and extensive effect on the worldwide health systems. Computed Tomography (CT) imaging has become a crucial tool to detect COVID-19, as it provides high-quality lung images that reveal the specific characteristic features of the disease. However, manual interpretations of CT images are prone to human errors, highlighting the need for more efficient methods to analyze medical images. In this paper, the authors proposed a federated learning approach to identify COVID-19 efficiently and securely from CT images. Our approach involves training a neural network on the local datasets from various hospitals, while the weights of the model are updated in a privacy-preserving manner through a centralized server. In our federated learning approach, the privacy-preserving update of model weights is a key feature. Each participating hospital trains the model locally on its dataset, ensuring that sensitive patient data does not leave its premises. Only the model weights, devoid of direct patient data, are sent to a central server for aggregation. This server updates the global model by averaging the weights received from all clients, thus improving the model without compromising individual data privacy. This method effectively addresses the critical need for data confidentiality in healthcare. The suggested approach addresses the challenge of data heterogeneity and data privacy, which are commonly encountered in medical image analysis. In our study, we have inferred a remarkable accuracy of 97.34% in identifying COVID-19 from CT images using our federated learning approach, significantly surpassing traditional methods with 90% accuracy. This substantial improvement in accuracy underscores not only the effectiveness of our approach but also highlights the potential for federated learning to revolutionize medical image analysis, offering a more secure and efficient alternative to conventional methods. Our federated learning approach, with its high accuracy and focus on data privacy, has significant implications for medical image analysis. Our strategy allows for collaboration among many healthcare institutions in model training, while ensuring that confidential patient data is not shared. This enables more comprehensive and varied data analysis, which is essential during a global health crisis. This approach not only advances the field by introducing a more secure and efficient way to handle medical data but also helps towards the global efforts in managing the pandemic by providing an accurate patient privacy.
COVID-19, privacy-preserving, data heterogeneity, CT images, federated learning, medical image analysis
COVID-19 outbreak has presented numerous challenges to healthcare infrastructure globally. Among these challenges, the timely and accurate identification of COVID-19 illness has emerged as a significant obstacle for healthcare practitioners, crucial for effective management and containment of the virus [1, 2]. Reverse transcription-polymerase chain reaction (RT-PCR) evaluation is the main technique used to identify COVID-19. Nevertheless, this method faces obstacles such as the potential for inaccurate negative outcomes caused by mishandling of patient specimens and a lack of excellent instruments for performing testing [3]. Computed Tomography (CT) scans have been a significant technique for identifying and diagnosing COVID-19. CT scans are capable of identifying distinctive ground-glass transparency and aggregation in the lungs of individuals with COVID-19, which assists healthcare workers in promptly detecting the condition [4, 5]. Several studies, such as [6, 7], have demonstrated that CT images are more effective for early COVID-19 identification in contrast to X-rays. CT images offer greater specificity and sensitivity, providing detailed insights into lung features crucial for accurate COVID-19 identification. Hence, we favored CT scans over X-rays in our study. However, manual analysis of lung CT scan images is both expensive and labor-intensive, posing a significant limitation and rendering it unsuitable for emergency cases [8]. To expedite the detection process, automated detection using machine learning (ML) and deep learning (DL) methods has been given [9-11]. Nevertheless, these techniques raise concerns regarding patient data privacy and security in COVID-19 detection [12]. Thus, there is a pressing need to develop effective tools and techniques for COVID-19 detection. ML and DL techniques have recently proven successful in detecting various life-threatening diseases, including COVID-19, through medical image analysis [13]. However, developing ML and DL techniques using centralized medical data faces challenges like data security, privacy, distribution, and heterogeneity, limiting scalability and generalizability [14]. To address these challenges, federated learning (FL) has emerged as a potential solution, leading to collaborative model training with multiple medical centers without sharing sensitive patient data [15, 16].
This paper proposes an FL technique for finding COVID-19 from chest CT images. Through this technique, we aim not only to address privacy concerns but also to develop a highly precise method for COVID-19 identification. The proposed approach will allow numerous medical centers to contribute to FL model training while ensuring data security and privacy. The paper outlines three stages: CT image pre-processing, feature extraction, and FL model development, to establish an effective approach for COVID-19 detection. In this work, the primary aim is to develop a FL technique, meticulously crafted for the identification of COVID-19 via CT scans. This innovative approach aims to revolutionize the field by not only ensuring unparalleled accuracy in disease detection but also by meticulously safeguarding patient data privacy and security, which are main concerns in today’s healthcare landscape. Our federated learning model is designed to facilitate a synergistic collaboration among various medical centers, allowing them to collectively train and refine the model keeping the confidentiality of patient data intact. This collaborative approach is pivotal in rapidly adapting to the evolving characteristics of COVID-19, making the detection process more robust and reliable. Furthermore, by leveraging the strengths of diverse datasets across multiple centers, our technique promises to enhance the generalizability and effectiveness of COVID-19 identification.
In our study, the methodology is segmented into three detailed phases, each integral to the identification of COVID-19 using CT scans. The first phase, data preprocessing, involves collecting a diverse and substantial dataset of CT scans. This step is crucial to ensure that our FL model can effectively diagnose COVID-19. We apply various preprocessing techniques, including standardization and normalization, to harmonize data from different sources. This process is critical for the consistent and accurate analysis of the images. The second phase, feature extraction, is foundational to the quality of our FL model. Utilizing a pre-trained VGG16 model, we extract meaningful features from the CT scans, focusing on lung characteristics indicative of COVID-19. This step is important for enhancing the model's tendency to contrast between infected and non-infected scans accurately. Lastly, the federated learning model is developed, leveraging the preprocessed data, and extracted features. This model allows for collaborative learning across multiple medical centers, ensuring data privacy and security while improving the model's accuracy and generalizability. This comprehensive methodology underpins our innovative approach to COVID-19 detection, combining technological sophistication with ethical data practices.
The layout of the paper is as follows. Current work in the field of ML and DL to detect COVID-19 is described in Section 2. The suggested approach is highlighted in Section 3. The results obtained from the proposed approach are mentioned in Section 4 along with a review of the findings, and Section 5 concludes the paper with a brief overview of the future scope of the work.
With the outbreak of COVID-19, there has been a growing interest in utilizing automated methods such as ML and DL to detect diseases from medical images such as X-rays and CT scans. These automated techniques are described under several subsections.
2.1 Transfer learning approaches
The authors [17] focused on a transfer learning (TL) method to identify and classify lung infections, including COVID-19, using chest X-rays. The researchers employed a pipeline-based transfer learning method, which allowed for the adaptation of pre-existing neural network architectures to the specific task of lung infection classification. This approach resulted in a reported accuracy of 96.8%. The strength of this study lies in its innovative use of existing models, which reduces the requirement for rigorous data gathering and training time. However, a potential limitation is the dependency oriented towards the quality and relevance of the source model's training data. In the study [18], the authors developed a TL-based approach for identifying COVID-19 from chest CT images. They tested their model on a dataset containing over 2000 images, achieving an accuracy of 98.91%. The high accuracy of this method demonstrates the efficacy of transfer learning in handling complex imaging data. The advantage here is the ability to leverage sophisticated, pre-trained models to achieve high precision. However, this method might struggle in scenarios with limited or non-representative training data. This research [19] employed various deep learning algorithms as base models in a deep TL framework to identify COVID-19. They reported an accuracy of 98%. The study showcases the versatility of transfer learning in adapting different algorithms for specific medical imaging tasks. The significant benefit is the model's adaptability and accuracy. Yet, similar to the other studies, the challenge lies in ensuring the model's applicability across diverse datasets and real-world scenarios.
The role of TL in COVID-19 identification, as highlighted in studies [17-19], reflects a paradigm shift in medical imaging and diagnostics. This technique, primarily characterized by its efficiency, harnesses the power of pre-trained models, drastically decreasing the time and computational resources needed for model training. In the face of a pandemic, where time is of the essence, such efficiency is invaluable. Pre-trained models, having been exposed to a wide array of data, develop a nuanced understanding of intricate patterns, an aspect crucial for medical imaging where subtle differences can be diagnostically significant. This pre-training allows for a more refined analysis of new datasets, making these models particularly suited for finding COVID-19 features in chest X-rays and CT scans. For instance, a study [17] utilized this approach to contrast COVID-19 from other lung infections, achieving a notable accuracy of 96.8%. A study [18] further exemplifies this, achieving 98.91% accuracy in COVID-19 identification from chest CT images, a testament to the precision that transfer learning can bring to medical diagnostics. Study [19] expands on this, employing various deep learning algorithms in a transfer learning framework, achieving an impressive 98% accuracy. This versatility in adapting different algorithms to the specific task of COVID-19 identification underlines the flexibility of TL, making it a powerful tool in the direction of medical imaging. However, the application of TL in medical imaging, especially for COVID-19 identification, is not without challenges. One of the most significant is ensuring the generalizability of these models across diverse datasets and real-world scenarios. The efficacy of these models may differ based on the demographic attributes of the population, the quality of imaging devices, and the methodologies used for data collecting. Thus, while these models can achieve high accuracy rates in controlled settings, their effectiveness in varied clinical environments may differ. Ensuring consistent performance across different demographics and imaging types is crucial for the practical application of these models. This requires continuous refinement and testing in varied clinical settings, a process that can be resource-intensive. Additionally, while transfer learning models are efficient in training, they require large and diverse datasets for initial training, which may not always be readily available, especially in less-resourced healthcare settings. Another challenge is the interpretability of these models. In clinical settings, understanding the rationale behind a model's decision is as important as the decision itself. However, transfer learning models, especially DL-based ones, often act as 'black boxes,' making it difficult to discern the exact features used for predictions. In conclusion, while transfer learning presents a promising avenue for fast and precise identification of COVID-19 through medical imaging, it needs careful involvement of the model’s compatibility with diverse datasets, continuous evaluation of their performance in real-world scenarios, and efforts to enhance their interpretability. The studies [17-19] collectively demonstrate the potential of this approach but also underline the need for ongoing research in universal healthcare applications.
2.2 Ensemble and deep learning approaches
This section represents a significant stride in the application of advanced ML techniques for COVID-19 detection, covering the studies [20, 21]. Study [19] is particularly notable for its integration of the Internet of Things (IoT) into the ensemble DL model, covering a novel approach that significantly enhances diagnostic capabilities. This model's performance, with an accuracy rate of 98.5%, underscores the effectiveness of combining multiple learning algorithms and IoT technology, offering a more robust and comprehensive analysis of medical images. The use of ensemble methods in this context effectively addresses some of the common limitations of single-model approaches, such as overfitting and bias. By aggregating the insights from multiple models, the ensemble approach in study [21] provides a more reliable and accurate diagnostic tool. The integration of IoT technology further elevates the model's utility, making for real-time data accumulation and analysis, which is crucial in a rapidly evolving pandemic situation. The study [20] explores an explainable DL technique, achieving an accuracy of 95%. The significance of this study lies in its focus on model transparency, a crucial element in clinical decision-making. Explainable AI (XAI) in healthcare offers practitioners insights into how the model arrives at its conclusions, increasing trust and allowing for more informed decisions. This is particularly important in a clinical setting, where understanding the rationale behind a diagnosis is as important as the diagnosis itself. However, while these advanced models show high accuracy and offer substantial improvements over traditional methods, they are not without challenges. The complexity of these models can make them computationally intensive, requiring significant processing power and data storage capacity, which might not be feasible in all healthcare settings. Additionally, the sophistication of these models can sometimes lead to a lack of transparency, making it difficult for practitioners to fully understand or trust their decision-making process. Although the study [20] makes significant strides in this area with its explainable model. In summary, the studies [20, 21] highlight the evolving landscape of medical imaging and diagnostics through the application of ensemble and DL models. Their integration of IoT and focus on explainability represents crucial advancements in the field, offering more accurate, robust, and transparent tools for COVID-19 identification. However, the complexities and computational demands of these advanced models pose challenges that need to be taken care on priority.
2.3 Comprehensive ML applications in COVID-19 research
This section covering studies [22-26], presents a wide-ranging exploration of ML and DL applications towards the COVID-19. The research presented in study [22] demonstrates the effective use of pre-trained DL models for the identification of COVID-19 using chest X-ray pictures, achieving an impressive 99.6% accuracy. This underscores the potential of leveraging existing AI frameworks in rapid disease identification. The study [23] ventures into drug discovery, employing ML-based QSAR models to identify potential compounds for COVID-19 treatment, demonstrating ML's potential in accelerating pharmaceutical research. The research conducted in study [24] demonstrates significant progress in using DL techniques for medical imaging. By employing a feature recycle residual blocking and depth-wise inflated convolutional neural network, the study achieves an exceptionally high level of accuracy in detecting COVID-19 from both chest CT scans and X-rays. This innovation marks a significant step in enhancing diagnostic precision. The RADIC tool, discussed in study [25], integrates time-frequency data with radiomics information, enhancing the COVID-19 identification process and achieving a high accuracy of 99.4%. This tool exemplifies the integration of multiple data types to boost diagnostic capabilities. The study [26], introduces the CORODET algorithm, a DL-based classification system for distinguishing among COVID-19 infected and healthy patients. Tested on a dataset with chest X-rays and CT images, it found accuracies of up to 99.1%, showcasing the effectiveness of specialized algorithms in medical diagnostics.
These studies highlight the transformative impact of ML along with DL in various aspects of COVID-19 research and response. They illustrate the versatility of these technologies in handling diverse challenges, from early detection and diagnosis to treatment and pandemic management. However, the requirement for extensive training data and computational resources remains a persistent challenge in the wider adoption of these techniques.
Our federated learning approach is designed to address certain limitations found in conventional ML and DL techniques, especially in the context of COVID-19 research. By utilizing a decentralized model, where data is sourced from a diverse array of medical centers, we enhance the representativeness and reduce the biases typically associated with centralized datasets. This diversity in data sources significantly bolsters the accuracy and reliability of our models across various patient demographics and clinical scenarios. Additionally, a key advantage of our approach is its emphasis on maintaining patient data privacy, a critical concern in healthcare research.
An overview of the challenges in the existing literature is summarized in Table 1.
Table 1. Summary of the limitations of the work
|
Study |
Work Description |
Limitations |
|
[17] |
Developed a transfer learning approach for detecting lung infections including COVID-19, with up to 96.8% accuracy. |
Dependence on large, diverse datasets. |
|
[18] |
Created a TL approach for COVID-19 detection from CT images, achieving 98.91% accuracy. |
Potential for model bias, reliance on pre-trained models. |
|
[19] |
Created a deep TL model for COVID-19 identification, achieving 98% accuracy. |
Model's adaptability to diverse clinical scenarios. |
|
[20] |
Created an explainable DL technique for COVID-19 detection from CT images with 95% accuracy. |
Need for model transparency and interpretability. |
|
[21] |
Presented an ensemble DL model integrated with IoT for COVID-19 detection, 98.5% accuracy. |
Complexity in model integration and data processing. |
|
[22] |
Evaluated pre-trained DL models for identifying COVID-19 using chest X-rays, achieving 99.6% accuracy. |
Limited annotated datasets, model bias. |
|
[23] |
Developed an ML-based QSAR model for identifying drug targets for COVID-19 treatment. |
Need for extensive, varied data for model training. |
|
[24] |
Suggested a CNN for COVID-19 identification from CT and X-ray images, reporting 99.84%-100% accuracy. |
Generalizability of the model across different datasets. |
|
[25] |
Designed RADIC tool for COVID-19 detection using time-frequency data, achieving 99.4% accuracy. |
Challenges in integrating diverse data types. |
|
[26] |
Developed ‘CORODET’, a DL classification algorithm, with up to 99.1% accuracy. |
Balancing accuracy with computational efficiency. |
These studies have explored the potential of several ML and DL methods to help in the detection of COVID-19 and have shown promising results in early detection. However, there are some challenges which have been left unexplored including biasness in ML and DL models, which can lead to inaccurate detection. Also, there is a scarcity of annotated datasets for training ML and DL models. Using FL can help in addressing these challenges by enabling the training of these models without sharing data, thereby pre-serving patient privacy and security. The proposed approach in this research work aims to contribute to this growing body of literature by developing an efficient federated DL method to find COVID-19 from chest CT images.
There is an urgent necessity to create more effective approaches to meet the issues presented by the COVID-19 pandemic, particularly the development of strong instruments and methodologies for COVID-19 identification. Currently, chest CT scan and x-ray are used to identify COVID-19 [27]. This study suggests and investigates a FL technique to find COVID-19 from CT images. A FL model allows multiple institutions to collaborate and share their data without compromising the data privacy [28]. The suggested approach involves data collection and preprocessing, feature extraction from CT scan images using a pretrained DL model, FL model development and evaluation and visualizing the outcomes of the developed model using GradCAM technique [29]. The pre-trained DL model used in the paper for feature extraction is found to be good in enhancing the performance of our FL model and the visualization technique followed helped us to get an in-depth analysis of the predictions. The overall methodology followed is explained in the upcoming subsections.
3.1 Data collection and preprocessing
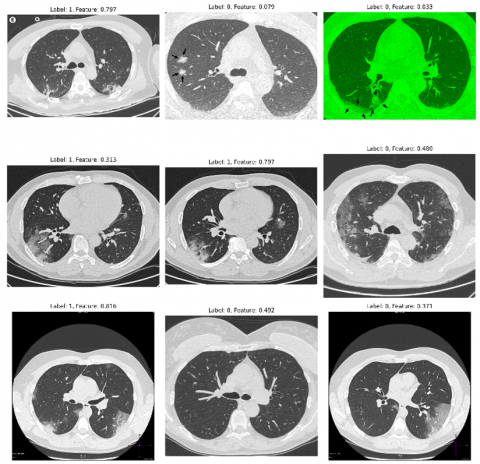
In the current work, we correlate datasets from studies [30-38] and ensured that each source provides a diverse set of data points, which would help us capture the variations of the disease. The dataset we collected having 5000+ CT scans of individuals infected with COVID-19 and 3000+ CT scans of uninfected individuals. This extensive dataset will aid in ensuring that the federated learning (FL) model can effectively diagnose COVID-19. Subsequently, image preprocessing is applied to prepare the data for input into our FL model. Image preprocessing techniques may include standardizing the data format and normalizing pixel values to ensure consistency across different sources. This is crucial as CT scan images may be acquired using different machines or protocols, leading to variations in data format and quality. Normalization is also vital to ensure that pixel values fall within a consistent range and are not skewed towards one end of the spectrum. This can facilitate more effective learning by the model and prevent it from being influenced excessively by outliers in the data. Besides standardizing and normalizing the data, other preprocessing techniques may be employed, such as resizing picture to a standard size, cropping or padding them to remove or add unnecessary background information, and applying filters to eliminate noise or enhance image features. The preprocessing techniques applied to our dataset are outlined in algorithm 1, and the outcomes produced by preprocessing are depicted in Figure 1.
Figure 1. Pre-processed CT scan images
Algorithm 1: Data pre-processing applied to CT scan dataset
Input: chest CT scan images from the dataset
Output: Pre-processed CT scan images
return pre-processed images
The CT scan images used for pre-processing according to algorithm 1 were of size 512×512. The first step in the algorithm was image normalization, where the mean (μ) and standard deviation (σ) of pixel values were calculated across entire dataset. The mean μ was found to be 0.05 and the standard deviation σ was found to be 0.23. The pixel values of each picture were normalized using these values to achieve a zero mean and unit variance, which is crucial for optimal performance of ML models. The next step was image resizing, where the images were resized to a new height H of 256 and a new width W of 256. This was done to reduce the computational complexity of subsequent steps, as well as to standardize the size of the images for analysis. Image augmentation was then performed, which involved randomly rotating each image by an angle θ between -10 and 10 degrees and randomly shifting the image horizontally and vertically by a distance (Sx) and (Sy) between -0.1 and 0.1 times the image width and height, respectively. This contributed to the enlargement and variety of the dataset, perhaps improving the efficiency of ML models. The fourth step was image filtering, where a median filter with a kernel size K of 3x3 was applied to each image to remove noise and artifacts. Additionally, a linear transformation was applied to each image using a scaling factor α of 1.2 and a shift factor β of 10. This helped to increase the contrast of the images, which can improve the visibility of important features. Next, image segmentation was performed using a threshold of 0.5 to create a binary mask for each image. This helped to isolate image region that correspond to the COVID-19 infection, which can aid in the identification and diagnosis of the disease. A morphological erosion operation using a kernel size K of 3x3 was then executed on the binary masks to remove any gaps in the mask. Finally, image registration was performed using a reference image and transformation parameters for each image I. This helped to align the images with respect to a common coordinate system, which can aid in the comparison and analysis of multiple images. Once the images are pre-processed, feature extraction is performed, which is explained further.
3.2 Feature extraction
As the quality of our federated learning (FL) model's outputs partly depends on the features we extract, this step is crucial. It is used to extract meaningful information in medical imaging; in our case, from raw CT scans [39], which can be further used as an input to our FL model. To effectively identify COVID-19 from CT scans, we performed feature extraction to eliminate irrelevant or redundant information that could pose difficulties for our FL model in interpretation. By extracting relevant features, such as areas of inflammation or consolidation in the lungs, the FL model can be trained to recognize patterns specific to COVID-19, thereby enhancing the accuracy of identification. In our study, we have used a pretrained VGG16 model [40] for feature extraction. Initially, directories for training and testing data are defined, along with specifications for image size, batch size, and the count of epochs. Data generator objects are then created using the Image Data Generator from Keras, which applies image normalization to the data [40]. The pretrained VGG16 model [39-41] is loaded, and its layers are frozen to prevent them from being trained further. Additionally, a new model is created for feature extraction by combining VGG16 with a flatten layer as the first two layers. Subsequently, an initial dense layer is followed by an additional dense layer of 256 units and a ReLU layer. Finally, another dense layer of 1 unit with sigmoid activation is created, and its rate is set to 0.5. After defining the model network architecture, it is compiled with a loss defined by 'binary cross-entropy' and an optimizer defined as 'Adam'. The model is ready for training, and its effectiveness is evaluated using loss and accuracy plots. The model architecture generated for performing feature extraction is shown in Figure 2.
Figure 2. Generated model architecture for feature extraction
3.3 FL model development
Using FL, several team members can train a single learning model without disclosing their own data [42, 43], which is particularly useful in identifying COVID-19 from CT images. FL is employed to develop a collaborative learning model where data is collected from multiple clients such as hospitals, without the need for a centralized server for data sharing, thus mitigating the risk of cyber-attacks. To develop our FL model, we have established a network where clients share multiple parameters of the model, including the gradient, while keeping the data private. The three crucial stages in the creation of an effective FL model are defined as [42-47].
Client training stage: This stage involves a local training of learning models by each participating site on the dataset consisting of CT images including an optimization algorithm to minimize the loss function. Consider a site K with a local model with parameters WK that can minimize the loss function defined as LK(WK), where LK is consider as the loss function for the site K. The local model is trained using a mini-batch stochastic gradient descent algorithm. At each iteration t, the local model parameters are updated as per Eq. (1).
$W_K^{(t+1)}=W_K^{(t)}-\eta * {grad}\left(L_K\left(W_K^{(t)}\right.\right.$, $minibatch$ $\left.)\right)$ (1)
where, η is defined as the learning rate and ${grad}\ (L_K(W_K^{(t)}$, $minibatch$$))$ is defined as the gradient of loss function w.r.t its parameters, along with parameter WK, which is evaluated on a randomly sampled minibatch of data. To prevent overfitting, the local models are also regularized using techniques such as L1 or L2 regularization. This can be mathematically expressed as shown in Eq. (2):
$\begin{gathered}L_K\left(W_K\right)=\frac{1}{N} * {sum}_i=1^N I\left(y_i, f\left(W_K, x_i\right)\right)+\lambda * R\left(W_K\right)\end{gathered}$ (2)
where, N=count of site samples K, $I\left(y_i, f\left(W_K, x_i\right)\right)$=loss function for sample i, yi=true label of sample, xi=input data, f(WK, xi)=output of the local model on input xi, λ=regulization strength, and R(WK)=regularization term. We performed client training to optimize the parameters of the local models on each participating site and ovoid any overfitting of the models. Following client training, the revised local models are transmitted to a central server for the purpose of 'aggregation' and the creation of a global model.
Parameter exchange stage: This stage performs the aggregation of the several updated local models from each participating site on the centralized server for creating a global model. This can be further expressed as, consider be the local model parameters on site i after t iterations of training. The main server computes the weighted average of the local model parameters across all sites to obtain the global model parameters as shown in Eq. (3):
$W^{(t+1)}={sum}_i=1^m\left(\frac{N_i}{N}\right) * W_i^t$ (3)
where, m is the count of participating sites, Ni is the count of instances in site i, N is the aggregate count of instances across all sites. In addition, after receiving the global model parameters, each site adjusts its local model parameters to reflect the new values as shown in Eq. (4):
$W_i^{(t+1)}=\alpha * W_i^t+(1-\alpha) * W^{(t+1)}$ (4)
where, α is a momentum variable that affects the ratio of old to new local model parameters.
Aggregation stage: The aggregation step is the last phase of the FL process, in which the revised model parameters are combined from the clients involved and used to modify the unified model. It may be executed by a variety of techniques, including weighted averaging, median calculation, or trimmed mean calculation. In the weighted averaging method, each client's contribution is weighted by its importance factor, which is typically based on the count of samples available at the client or the client's computational capacity. The global model is updated as:
$W^{t+1}=\sum_{i=1}^K \frac{n_i}{n} w_i^{t+1}$ (5)
where, K=count of participating clients, n=total count of instances in the dataset, ni is the count of samples available at client i, and $W^{t+1}=\sum_{i=1}^K \frac{n_i}{n} w_i^{t+1}$ is the updated model parameters at client i at iteration t+1. In the median and trimmed mean methods, the global model is expressed by taking the median or the trimmed mean of the model parameters from the participating sites, respectively. The median method is robust to outliers and can be used when some clients have noisy or corrupted data. The trimmed mean method can be used to handle the heterogeneity of the participating sites and to reduce the impact of sites with extreme parameter updates. Aggregation stage helps in providing the additional privacy and security measures. Based on these concepts, we have defined our federated learning model to find COVID-19 through CT images. Our model is summarized via algorithm 2.
Algorithm 2: FL for COVID-19 detection
Input: CT images, count of sites, learning rate=α, initial global model parameter=θ0.
Output: global model parameter=θg, CT scan images classified as covid and non-covid.
for i=1 to n:
θi→θ0
for t=1 to Ti:
θi→θi - α∇Li(θi) //∇=convergence
for i=1 to n:
θi→θ0
for t=1 to Ti:
θi→θi-α∇Li(θi)
end
Algorithm 2 involves multiple participating sites, each having a dataset of CT scan images. The goal is to create a global model that can accurately identify COVID-19 from these images while preserving the privacy of each site's data, as explained by studies [42-47]. The algorithm starts with initialization, where the global model parameters are randomly initialized, and the participating sites are identified. Then, in the client training step, using stochastic gradient descent or similar optimization approach, local models are trained at each location to minimize the loss function using their dataset of chest CT scan pictures. The local models are regularized to prevent overfitting, and each site trains its model for a fixed count of epochs or until convergence is reached. Each site's local model data is sent to a centralized database. By utilizing a federated averaging process, the server aggregates the local models into a global one. Each site receives the updated global model and incorporates its new parameters into its own local model. The local models may be further fine-tuned using additional data or training epochs. Ultimately, the efficacy of the ultimate model is assessed using an independent dataset of lung CT scan pictures using diverse performance criteria.
Furthermore, to ensure convergence in our federated learning model, we implemented specific checks within our algorithm. These include monitoring changes in loss and accuracy metrics over successive iterations. If changes fall below a pre-defined threshold, we consider the model to have converged. This pragmatic approach balances the need for model stability with computational efficiency. Regarding network latency, our strategy involves streamlined data transmission protocols. We employ data compression techniques to reduce the payload size, ensuring faster and more efficient communication between distributed nodes. This method minimizes delays without over-complicating the system. They increase the model's reliability and deployment in diverse medical settings, maintaining a balance between sophistication and practical usability.
3.4 GradCAM visualization
GradCAM is a visualization technique that is used for understanding characteristics of an image that aids in enhancing the prediction capabilities of a learning model [29]. It is widely used in the medical imaging domain where the interpretation of the performance of a ML or a DL model is crucial for accurate detection. Generally, the decision-making capability of a ML or a DL model is considered as a ‘black box’ which makes it challenging to understand why a model made that decision [48, 49]. In GradCAM, we generate heatmaps to identify the region of interest that mostly contributes to the decision made by a ML or a DL model. The heatmap is generated as [29, 48, 49]:
$\operatorname{GradCAM}(y, c)=\operatorname{ReLU}\left(\right.$ $sum_K$$\left. \alpha_K^c A^K\right)$ (6)
where, (y,c)=predicted class, AK=the kth feature map, $\alpha_K^c$=the weight of the kth feature map for the predicted class c. these weights are calculated by taking the global average pooling of the gradients of the predicted class c w.r.t each feature map AK, given by studies [48, 49] as:
$\alpha_K^c=\frac{1}{Z} \sum_i \sum_j\left(\frac{\partial y_c}{\partial A_{i j}^K}\right)$ (7)
where, Z is the normalization constant. The resultant heatmap produced by the GradCAM algorithm illuminates the specific areas of the picture that are of utmost importance for the model's determination. GradCAM has the advantage of enhancing interpretability and openness in medical imaging. This enables medical professionals to evaluate the decisions made by the learning models and enhance the accuracy of diagnoses [50, 51]. For instance, in COVID-19 diagnosis from chest CT-scans, GradCAM was additionally utilized to see the specific regions in the lungs that the model focuses on in order to classify a patient as either COVID-19 positive or negative. Algorithm 3 provides a summary of how the GradCAM algorithm [29] is used to display chest CT scan images for both COVID-19 afflicted and non-COVID-19 infected individuals.
Algorithm 3: GradCAM visualization for detection of COVID-19
Input: image i, class index c and a trained neural network model
Output: heatmap, H
where, $A \in R^{(D)}$ is the vector of the weighted feature maps.
where, f = bilinear interpolation
end
Algorithm 3 is used for visualizing the areas in the chest CT scan images that are most relevant for predicting whether the patient has COVID-19 or not. Grad-CAM estimates the slope of the final score with reference to the activation maps of the model's final convolutional layer. The gradients are next used to provide weights to the activation maps, which represent the significant areas in the picture. Algorithm 3 may be used in context of COVID-19 identification to pinpoint the regions in chest CT scan pictures that exhibit the highest level of correlation with COVID-19 infection. Algorithm 3 may identify and emphasize regions of ground-glass opacities and aggregation, which are typical characteristics of COVID-19 infection in CT images. This may assist radiologists in achieving more accurate identification of COVID-19 using chest CT images. Algorithm 3 may enhance the efficacy of the COVID-19 detection model by highlighting crucial characteristics in chest CT images. By training the model to prioritize these crucial characteristics, the model may enhance its predictive accuracy and minimize both false positives and false negatives. This has the potential to enhance the health of patients by facilitating prompt and precise diagnosis of COVID-19.
After preprocessing chest CT scan images, we have shown the results of our work on identifying COVID-19 using FL. Here, we discuss how well our FL model did on the testing dataset and how it compares against more conventional ML and DL models. Furthermore, we examine the impact of several hyper parameters on the effectiveness of the model, providing detailed analysis on the efficiency and reliability of our proposed approach. The findings presented illustrate the capacity of FL to assist in the diagnosis of COVID-19, hence opening the path for the development of more sophisticated and precise diagnostic instruments in the future. After preprocessing the dataset, we performed the feature extraction on the chest CT scan images to extract and represent the most relevant and discriminative information from the images. In order to extract features, a deep learning model is necessary. In our study, we used the VGG16 model [41] to identify and extract the most important visual characteristics of the images. These collected characteristics may then serve as inputs to a classification algorithm for predicting if the CT scan picture is suggestive of COVID-19.
In COVID-19 identification, feature extraction is especially essential since it may improve the reliability and accuracy of the classification model's predictions. By isolating the most significant characteristics from the images, the model emphasizes on the most relevant aspects of the images that are indicative of COVID-19, while ignoring irrelevant or misleading information. This can help to reduce false positives (FP) and false negatives (FN), improving the overall performance of the model. Using the Keras ImageDataGenerator, the chest CT scan pictures are preprocessed and scaled to a constant resolution (224×224) before the extraction of features begins. High-level features are extracted from the pictures using convolutional layers, which are processed by the pre-trained VGG16 model. When the features have been retrieved, they are compressed before being fed into a fully linked layer that is activated using ReLU. Overfitting may be avoided by including a dropout layer before the final output layer, which uses a sigmoid activation function to create binary predictions. In order to reduce the likelihood of excessive fitting in our model, we used a comprehensive strategy. In addition to the dropout layer stated, which has a rate of 0.5 and randomly disables neurons to avoid the model from relying too heavily on certain characteristics, we also used approaches such as regularization. Regularization imposes a penalty on the level of complexity of the model, so inhibiting it from overfitting to noise present in the training data. Furthermore, we took into account the concept of early stopping, which involves ending the training process when the outcome on a validation set no longer improves. This helps minimize overfitting caused by excessively long training epochs. By using these integrated approaches, we guarantee the resilience and applicability of our strategy. The architecture of the pre-trained model dictates the specific traits that are taken away through the feature process of extraction.
In the case of the VGG16 model, the initial few layers collect low-level characteristics like edges and corners, whereas the latter layers collect more complicated features like forms and patterns. The existence or lack of COVID-19 in chest CT scan images may then be predicted based on these high-level properties. Several hyperparameters have been applied to improve the model's efficiency. A summary of these hyperparameters along with their importance to the model is described in Table 2.
Table 2. Summary of hyperparameters and their contribution in model training
|
Hyper Parameters |
Values |
Importance |
|
No. of Epochs |
30 |
The model will run through the whole training dataset a given number of times, where that number is determined by the epoch’s parameter. Overfitting occurs when there are too few epochs, while underfitting occurs when there are too many. Selecting the optimal number of epochs is critical for achieving the best possible model results. |
|
Batch Size |
16 |
The number of samples utilized to revise the model's weights at each cycle is dependent on the batch size. While a bigger batch size can yield a more consistent gradient estimate, a lower batch size can result in more frequent updates and faster convergence. However, using a larger batch size may require more memory and slower training. |
|
Image Size |
(224, 224) |
The dimensions of the input photos to the model are determined by the image size. Reducing the size of photos may expedite the training process, whilst increasing the size of images can provide more intricate information. Nevertheless, the use of bigger pictures may need a greater amount of memory and result in a slower training process. |
|
Learning Rate |
1e-5 |
The learning rate determines the step size used to update the model weights during training. A smaller learning rate can lead to more precise updates and better convergence, while a larger learning rate can provide faster convergence. When the learning rate is set too high, the model may diverge and fail to converge. |
|
Dropout Rate |
0.5 |
The dropout rate determines the percentage of neurons in the model that are randomly dropped out during training. As a result, the model is compelled to learn more robust characteristics, which aids in preventing overfitting. While a lower dropout rate can yield a more complicated model with better accuracy on the training data, a higher dropout rate can result to more robust features and better generalization. |
|
Optimizer |
Adam |
In order to enhance the network's capacity of obtaining features from CT scan images, the Adam optimizer is used to compute the weights of the layers that are completely linked that are added on the top of the pre-trained neural network model. |
The performance of the feature extraction is evaluated using accuracy and loss. The plots for the same are depicted by Figure 3 and Figure 4 respectively. The overall accuracy of feature extraction was reported to be 80%, with a loss value of 0.6890. The goal of the model used for COVID-19 feature extraction from chest CT scan pictures is to determine which characteristics to extract from the input images to reliably identify positive and negative COVID-19 cases. An 80% feature extraction rate indicates that the model successfully identified the relevant features in 80% of the test photos. This suggests that the model is skilled at recognizing significant patterns or traits in the images that differentiate between COVID-19 positive and negative instances. The observation that both the training and validation accuracy are increasing over time in Figure 3 is a promising indication that the model is acquiring the ability to accurately classify CT scan images as either positive or negative for COVID-19. The validation accuracy is particularly important since it assesses the model's capacity to generalize to novel, unseen inputs. A progressively rising validation accuracy indicates that the model is not excessively conforming to the training data, leading to a high level of accuracy. Similarly, in Figure 4, the decreasing trend of both the training and validation loss over time indicates that the model is effectively learning to categorize the CT scan pictures with accuracy.
The loss compares the projected and observed labels of images, with a smaller loss indicating greater performance. As the model improves in its ability to predict correct labels, the training loss and validation loss will both decrease. The output generated from feature extraction is shown in Figure 5.
Figure 3. Training and validation accuracy
Figure 4. Training and validation loss
Figure 5. Extracted features from chest CT scan images
Once the feature extraction process is done, we designed a federated learning model as described by algorithm 2 to find COVID-19 from chest CT scan images. After collection of the dataset, preprocessing, and feature extraction of the data, we developed our FL model to find COVID-19 from chest CT scan images. We start by splitting our dataset into two sets: a local dataset for each client and a global dataset for the server. This is a crucial part of FL since it enables each client to train its model on its own local dataset before being aggregated by the server into a single, more accurate model for the whole network, while maintaining its privacy and security.
By splitting the dataset into local datasets for each client, we can train models that are tailored to the specific data characteristics of each client's dataset. This is important because different hospitals or clinics may have different populations of patients, which may have unique features or characteristics related to COVID-19. By training models on local datasets, we can capture these unique features and increase the accuracy of the final model. The splitting procedure in FL is distinctive in that it enables model training on dispersed datasets without moving the data to a centralized location. This removes the requirement for extensive data moves, which may incur significant expenses and consume time, while additionally decreasing the likelihood of security breaches or illegal entry, a critical consideration in medical applications wherein patient privacy must be preserved.
In the next step, we define the architecture for our FL model. The model architecture is defined using the Keras Sequential API and consists of several layers of Conv2D and MaxPooling2D layers, followed by Flatten and Dense layers. The Conv2D layers are utilized to infer features from the input images, while the MaxPooling2D layers down sample the feature maps to reduce their dimensionality. When the convolutional layers have completed processing their input, the Flatten layer is used to transform the 2D vector into a 1D vector that may be categorized by the fully connected Dense layers. The last Dense layer consists of a solitary neuron that utilizes a sigmoid activation function. This function produces a value ranging from 0 to 1, indicating the likelihood of the input picture becoming positive for COVID-19.
The training process, detailed in algorithm 2, involves initializing global model parameters and preparing client sites for local model training. Each client site updates its local model parameters θi from the initial global parameters θ0, using a specified learning rate α and optimizing the local model based on its dataset. This process is iterative, with each site contributing to model learning while maintaining data privacy. Subsequently, model aggregation occurs, where the server combines the individual models' parameters θi from all client sites, forming an updated global model θg. This federated averaging ensures that each site's learnings contribute to the overall model's performance. The updated global model undergoes further training cycles with the aggregated weights. This iterative process of local training, parameter updating, and global aggregation continues until the model shows stable performance, ensuring robustness and reliability. Finally, validation and testing are performed to assess the model's accuracy and generalizability. The combination of local and global training, alongside meticulous validation, makes our model not only innovative but also practical and efficient for real-world application in the medical field. The specific architecture chosen here is important as it strikes a balance between model complexity and training time. A complex model may take a long time to train on the distributed datasets, while too simple of a model may not capture all the necessary features for accurate classification. Further, we have used the aggregation of models as described by algorithm 2, which is used by the server to aggregate the weights of the models trained by the clients. In the context of COVID-19 detection from chest CT scan images, this function is important because it allows the server to combine the knowledge learned by each client to improve the overall model's accuracy. Through the process of combining the weights of the multiple models, the server may generate a more resilient and precise model that is capable of effectively categorizing chest CT scan pictures as either COVID-19 positive or negative. Once the client models have undergone local training and have been combined at the server, the global model is then trained on the global dataset using the federated training function. During the training process, the global model adjusts its weights by taking into account the global dataset, using the preset learning rate and the total amount of epochs. The global model is then updated by using the combined weights from the client models, hence improving the accuracy and resilience of the model. Here, the model is trained for 10 rounds with each having 8 clients and the results are shown in Figure 6 and recorded in Table 3.
Figure 6. Comparison between overall accuracy vs. overall loss of the federated model after 10 rounds
Table 3. Results reported for all clients in a federated network in various rounds
|
No. of Clients (Round-1) |
Loss |
Accuracy |
|
0 |
0.4924 |
0.8492 |
|
1 |
0.4619 |
0.8648 |
|
2 |
0.517 |
0.8429 |
|
3 |
0.4868 |
0.8512 |
|
4 |
0.5135 |
0.8422 |
|
5 |
0.5079 |
0.8495 |
|
6 |
0.4973 |
0.8515 |
|
7 |
0.4514 |
0.8677 |
|
No. of Clients (Round-2) |
|
|
|
0 |
0.2938 |
0.9151 |
|
1 |
0.2929 |
0.9139 |
|
2 |
0.3038 |
0.9122 |
|
3 |
0.2979 |
0.9095 |
|
4 |
0.3139 |
0.91 |
|
5 |
0.3247 |
0.9053 |
|
6 |
0.3024 |
0.9139 |
|
7 |
0.2776 |
0.9206 |
|
No. of Clients (Round-3) |
|
|
|
0 |
0.2066 |
0.9408 |
|
1 |
0.2104 |
0.9416 |
|
2 |
0.22 |
0.9381 |
|
3 |
0.2119 |
0.9367 |
|
4 |
0.2256 |
0.9398 |
|
5 |
0.2038 |
0.933 |
|
6 |
0.217 |
0.9389 |
|
7 |
0.2031 |
0.9411 |
|
No. of Clients (Round-4) |
|
|
|
0 |
0.1612 |
0.9539 |
|
1 |
0.1641 |
0.9537 |
|
2 |
0.171 |
0.9533 |
|
3 |
0.1659 |
0.9514 |
|
4 |
0.1762 |
0.9515 |
|
5 |
0.1774 |
0.9475 |
|
6 |
0.1704 |
0.9521 |
|
7 |
0.1523 |
0.9569 |
|
No. of Clients (Round-5) |
|
|
|
0 |
0.1325 |
0.9622 |
|
1 |
0.1345 |
0.9623 |
|
2 |
0.1425 |
0.962 |
|
3 |
0.1351 |
0.9615 |
|
4 |
0.1454 |
0.9608 |
|
5 |
0.1462 |
0.9567 |
|
6 |
0.1397 |
0.9618 |
|
7 |
0.1246 |
0.9647 |
|
No. of Clients (Round-6) |
|
|
|
0 |
0.1143 |
0.9674 |
|
1 |
0.1154 |
0.9674 |
|
2 |
0.1227 |
0.9652 |
|
3 |
0.1183 |
0.9659 |
|
4 |
0.1289 |
0.9643 |
|
5 |
0.1237 |
0.965 |
|
6 |
0.1219 |
0.966 |
|
7 |
0.1069 |
0.971 |
|
No. of Clients (Round-7) |
|
|
|
0 |
0.1009 |
0.9702 |
|
1 |
0.1022 |
0.9712 |
|
2 |
0.1087 |
0.9715 |
|
3 |
0.1024 |
0.9694 |
|
4 |
0.1145 |
0.9683 |
|
5 |
0.1105 |
0.9681 |
|
6 |
0.108 |
0.9711 |
|
7 |
0.093 |
0.9753 |
|
No. of Clients (Round-8) |
|
|
|
0 |
0.0899 |
0.9745 |
|
1 |
0.0913 |
0.9737 |
|
2 |
0.0965 |
0.9725 |
|
3 |
0.0935 |
0.9733 |
|
4 |
0.1016 |
0.9709 |
|
5 |
0.0993 |
0.9714 |
|
6 |
0.0976 |
0.9739 |
|
7 |
0.0863 |
0.977 |
|
No. of Clients (Round-9) |
|
|
|
0 |
0.0823 |
0.9769 |
|
1 |
0.0854 |
0.9762 |
|
2 |
0.0897 |
0.9749 |
|
3 |
0.0864 |
0.9738 |
|
4 |
0.0944 |
0.9728 |
|
5 |
0.0909 |
0.9738 |
|
6 |
0.0889 |
0.9763 |
|
7 |
0.0762 |
0.979 |
|
No. of Clients (Round-10) |
|
|
|
0 |
0.0755 |
0.9787 |
|
1 |
0.0793 |
0.9797 |
|
2 |
0.0825 |
0.977 |
|
3 |
0.0789 |
0.9756 |
|
4 |
0.0886 |
0.9746 |
|
5 |
0.0831 |
0.9757 |
|
6 |
0.0833 |
0.9767 |
|
7 |
0.0708 |
0.9818 |
From Table 3, it is evident that with each round of FL, the clients can improve their model's accuracy and reduce the loss. This is expected, as while utilizing FL, clients work in collaboration to train a model by feeding in their own data and training it locally. By doing so, the clients can capture the nuances of their local data better, leading to more accurate models. As the training advances, the model's precision on the creation set also improves, suggesting that the model is getting more proficient at extrapolating to unfamiliar data.
Likewise, a lower loss shows that the model is becoming more in sync with the input data. In any case, keep in mind that the model should not be overfitting the training data, since it might lead to poor results with novel data. In the given results, we can see that the accuracy on the development set improves with each round of training, reaching an accuracy of 0.9818 at round 10. Similarly, the loss on the development set reduces with each round of training, reaching a loss of 0.0708 at round 10. This indicates that the model has learned to generalize well and is not overfitting to the training data. Furthermore, from Figure 6, it is shown that our federated learning model is improving over the course of training. The final losses are decreasing with each round, that is from 0.4076 in round-1 to 0.0891 in round-10, indicating that the model is getting better at minimizing its errors. The final overall accuracy also increased from 88.33% after round-1 to 97.34% after round -10, which means that the model can correctly classify most CT scans in the validation set. Our model was evaluated using a split ratio of 80% training and 20% validation, ensuring that the validation set is representative of the broader dataset. This method ensures that the validation set mirrors the complexity of the wider dataset, thus providing a reliable estimate of the model's performance. We will elucidate on the calculated metrics of specificity and sensitivity, which stand at 80% and 98.9% respectively, underscoring the model's adeptness at accurately identifying true positive cases of COVID-19. The fitted and empiric ROC areas, 0.99 and 0.97, further reflect the model's excellent discriminatory power. To prevent overfitting, we implemented cross-validation and regularization strategies, which are designed to promote model generalization. Cross-validation is a technique that entails partitioning the dataset into numerous segments, retraining the model on some of these segments, and then verifying it on the other segments in an iterative manner. Regularization approaches, however, impose a penalty on complexity, so inhibiting the model from overfitting the noise present in the training data. The steady increase in accuracy over multiple rounds of training, rather than abrupt jumps, is indicative of a robust learning process rather than overfitting. This gradual progression reaffirms that the model is learning general patterns applicable to unseen data, bolstering our confidence in its external validity.
This suggests that the model might be a useful tool for aiding the finding of COVID-19 using CT scans. These results confirm the idea that the FL approach is beneficial for identifying COVID-19 on chest CT images. By training the model collaboratively across numerous clients, the model can use a bigger and more diversified dataset, resulting in enhanced precision and generalization. To further evaluate the effectiveness of our model, metrics such as specificity, sensitivity and ROC score have been calculated. For calculating the ROC score, we have used an online tool available at study [52] for our model. The results are depicted in Table 4.
Table 4. Model evaluation parameters
|
Specificity |
Sensitivity |
Fitted_ROC Area |
Empiric_ROC Area |
|
80% |
98.9% |
0.99 |
0.97 |
The specificity and sensitivity measures provide insights into the accuracy of the model in correctly identifying positive and negative cases of COVID-19. Specificity measures how well the model can identify non-COVID-19 cases. For the case, where the specificity of 80% means that out of 100 patients who do not have COVID-19, the model correctly identified 80 of them as non-COVID-19 patients, while it misclassified the remaining 20 patients as COVID-19 positive. Sensitivity refers to the proportion of patients who are correctly identified as positive for COVID-19 by the model among all the patients who have COVID-19. In other words, it measures how well the model can identify COVID-19 cases. In this case, the sensitivity of 98.9 means that out of 100 COVID-19 patients, the model correctly identified 98.9 (approximately 99) of them as COVID-19 positive, while it misclassified the remaining 1.1 (approximately 1) patients as non-COVID-19. ROC tells us about the relationship between the TP rate and FP rate for a classification model. For our model, the empirical ROC of 0.97 means that it performs very well in classifying between COVID-19 and non-COVID-19 patients. The model has a ROC area of 0.99, indicating that it is likely to outperform the present data it was trained on when applied to fresh data.
Overall, these metrics suggest that the model has high accuracy in diagnosing COVID-19 from chest CT scan images, with a relatively low rate of false positives (patients incorrectly diagnosed with COVID-19) and a very high rate of true positives (COVID-19 patients correctly diagnosed). To visualize our model's predictions, we have used the technique explained by algorithm 3 and is shown in Figure 7.
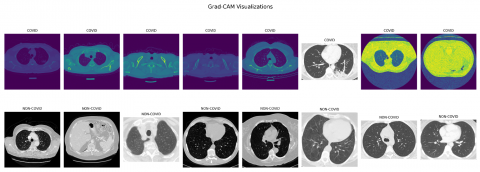
Figure 7. Grad-CAM visualizations for the predictions
The GradCAM display facilitates the identification of the most crucial areas in a CT scan towards prediction by the model. By visualizing these regions, we can gain insights into what features of the CT scan are most indicative of COVID-19, and potentially use this information to refine your model or develop new diagnostic tools. To further elucidate the capabilities of our GradCAM visualizations, we intend to integrate a detailed analysis of specific instances where our model precisely highlights the CT scan features characteristic of COVID-19.
Figure 7 demonstrates the model's focus, denoted by warmer colours, on regions known to be affected by the virus, such as areas showing ground-glass opacities and pulmonary consolidation. These visual cues are crucial for clinicians as they offer a non-intrusive means to understand the AI's reasoning, thereby making the model's predictions more transparent and trustworthy. By meticulously correlating the highlighted regions with actual symptoms and anomalies associated with COVID-19, we not only verify the model's diagnostic accuracy but also underline its potential as an assistive tool for medical professionals. This endeavour will bridge the current divide between automated diagnostic systems and their real-world clinical application, ensuring that our FL model is not just a black box but a supporter in healthcare decision-making.
In order to assess the effectiveness of our FL model in identifying COVID-19 from chest CT scan pictures, we will do a comparison study with previous research. This research will include a comparison between our model's outcomes and those of other cutting-edge models, using regulated test data. By doing this analysis, we will be able to assess the strengths and shortcomings of our model and pinpoint specific areas that need further improvement. Our evaluation of the model will prioritize accuracy percentage and security factors in order to assess its performance relative to other models. The summary comparison may be seen in Table 5.
Table 5. Comparative analysis between various studies
|
Study |
Methodology |
Results |
Shared Data |
Security & Privacy |
|
[53] |
The self-developed CTnet-10 model and additional models such as ResNet-50, InceptionV3, and VGG-19 |
CTnet-10: 82.1% accuracy; VGG-19: 94.52% |
× |
× |
|
[54] |
Transfer learning from various CNN models, optimized VGG19 for X-Ray, Ultrasound, and CT scan images |
Up to 100% accuracy for Ultrasound; 86% for X-Ray; 84% for CT scans |
× |
× |
|
[55] |
Deep network architectures, transfer learning strategy with custom-sized inputs |
SARS-CoV-2 dataset: Avg. 99.4% accuracy; COVID19-CT dataset: Avg. 92.9% accuracy |
× |
× |
|
[56] |
Customized skip connection-based network (SCovNet) for CXR images |
Kaggle dataset: High performance; GitHub database: 98.67% accuracy |
× |
× |
|
[57] |
Pre-processing of grayscale images using HE and CLAHE, tested with models like InceptionV3, MobileNet, ResNet50 |
InceptionV3: 99.60% accuracy; Significant improvement in classification |
× |
× |
|
[58] |
Various CNN architectures (VGG16, DenseNet121, etc.) on CT scan images |
VGG16: 97.68% accuracy; DenseNet121: 97.53%; MobileNet: 96.38% |
× |
× |
|
[59] |
Deep transfer learning with ResNet50, InceptionV3, VGGNet-19, Xception using CT and CXR images |
VGG-19: 90.5% accuracy; Xception: 98% precision using CXR images |
× |
× |
|
[60] |
Four pre-trained deep neural networks on chest X-Rays |
AlexNet: 97.6% accuracy; Precision, recall, F1 score around 0.98 |
× |
× |
|
Our work |
Federated learning |
97.34% |
$\checkmark$ |
$\checkmark$ |
The comparative analysis of our work with other studies in Table 4 illuminates our model's distinct approach and performance. For instance, studies [53, 59] utilized self-developed models and traditional CNN architectures like VGG-19, achieving accuracies up to 94.52%. Their methodologies focused on conventional deep learning techniques without federated learning's privacy considerations. Study [54] applied transfer learning to various image types, achieving different accuracies, reflecting the model's adaptability but again lacking in privacy considerations. Studies [55, 57] emphasized advanced deep learning techniques and image preprocessing, achieving high accuracies, yet they did not address data privacy and security. In contrast, our model, with 97.34% accuracy, not only provides competitive performance but also prioritizes data security and privacy through federated learning, a key differentiator in healthcare applications. In contrast to the other studies, we also considered shared data and security/privacy concerns by using FL, which allowed us to train our model on data from multiple sources while keeping the data secure and private. In our comparative analysis, each study presents unique methodologies and challenges in COVID-19 detection using CT scans. Study [53], for instance, used CTnet-10 and VGG-19 models, achieving high accuracy but not addressing data privacy. Study [54] showed versatility with transfer learning across different imaging modalities yet lacked in privacy measures. Advanced deep learning techniques in studies [55, 57] led to high accuracies but again, without a focus on data security. Our federated learning approach, with a 97.34% accuracy, stands out for ensuring data security and privacy, a crucial aspect in healthcare. This distinction is critical in demonstrating our model's practicality and ethical compliance in medical applications, highlighting the balance between performance and data protection. Furthermore, inside our FL framework, the structure itself naturally upholds confidentiality and security—this is a fundamental advantage of using this method. The raw data stays stored at its original location, and only changes to the model, rather than the raw data itself, are sent among the clients and the central server. Therefore, by design, our model reduces the risk of data breaches. In the healthcare industry, where patient confidentiality is of great importance, this is an essential factor to consider. Additionally, our model is explainable, which means it can provide insights into how it arrived at a particular decision, making it more interpretable for healthcare professionals. our model is explainable, which means that we can interpret and understand how the model is making predictions. This is achieved using Grad-CAM heatmaps, which specify the regions of the image that are most important in the model's decision-making process. This provides transparency and allows medical experts to understand and validate the model's predictions and makes our model better than other models. Despite of the advantages, the challenge of our study lies in the inherent complexities of federated learning, particularly the computational demands and the intricacies of training across diverse and distributed datasets. These datasets not identically distributed—referred to as non-IID data—can lead to model performance discrepancies. Additionally, the dependency on robust network connectivity for the communication of model updates presents potential latency issues. Future work will be dedicated to optimizing the federated learning process, addressing non-IID challenges, and enhancing network communication to ensure a seamless and efficient learning experience. We also plan to explore lightweight cryptographic techniques to further secure the federated learning pipeline.
Based on this study, we have deduced that chest CT scan pictures may be used for COVID-19 identification via the implementation of secure federated learning (FL). We have shown that our FL model attains a precision rate of 97.34%. Additionally, we have effectively tackled privacy and security apprehensions by ensuring that the data remains inside the local environment and encrypted throughout the training procedure. Furthermore, our approach has the quality of being explainable, which increases transparency and promotes confidence in the system. We employed GradCAM to visualize the regions of the images most relevant for the model’s predictions, providing intuitive explanations for the diagnosis. By using GradCAM on the model we have, we can identify the specific regions of the chest CT scan pictures that are suggestive of COVID-19 infection. This data is then used by the model to make decisions. This facilitates understanding of the model’s behavior, validation of its correctness, and identification of potential errors or biases. Our work opens several avenues for future research. Firstly, we plan to explore the use of more advanced DL architectures, such as transformer networks, to further enhance the accuracy of our model. Secondly, we aim to investigate the use of more diverse datasets from various regions worldwide to increase the generalizability of our model. Finally, we intend to explore the application of federated TL to leverage pre-trained models and further enhance the efficiency of our FL system. Overall, we believe our study has significant implications for the monitoring and control of COVID-19, and we hope our results will inspire further studies in this direction.
[1] Harapan, H., Itoh, N., Yufika, A., Winardi, W., Keam, S., Te, H., Megawati, D., Hayati, Z., Wagner, A.L., Mudatsir, M. (2020). Coronavirus disease 2019 (COVID-19): A literature review. Journal of Infection and Public Health, 13(5): 667-673. https://doi.org/10.1016/j.jiph.2020.03.019
[2] Adams, H.J., Kwee, T.C., Yakar, D., Hope, M.D., Kwee, R.M. (2020). Chest CT imaging signature of coronavirus disease 2019 infection: In pursuit of the scientific evidence. Chest, 158(5): 1885-1895. https://doi.org/10.1016/j.chest.2020.06.025
[3] Kumar, S., Nagar, R., Bhatnagar, S., Vaddi, R., Gupta, S. K., Rashid, M., Alkhalifah, T. (2022). Chest X ray and cough sample based deep learning framework for accurate diagnosis of COVID-19. Computers and Electrical Engineering, 103: 108391. https://doi.org/10.1016/j.compeleceng.2022.108391
[4] Nguyen, D.C., Pham, Q.V., Pathirana, P.N., Ding, M., Seneviratne, A., Lin, Z., Dobre, O., Hwang, W.J. (2022). Federated learning for smart healthcare: A survey. ACM Computing Surveys (CSUR), 55(3): 1-37. https://doi.org/10.1145/3501296
[5] Axiaq, A., Almohtadi, A., Massias, S.A., Ngemoh, D., Harky, A. (2021). The role of computed tomography scan in the diagnosis of COVID-19 pneumonia. Current Opinion in Pulmonary Medicine, 27(3): 163-168. https://doi.org/10.1097/MCP.0000000000000765
[6] Liu, M., Zeng, W., Wen, Y., Zheng, Y., Lv, F., Xiao, K. (2020). COVID-19 pneumonia: CT findings of 122 patients and differentiation from influenza pneumonia. European Radiology, 30: 5463-5469. https://doi.org/10.1007/s00330-020-06928-0
[7] Ghayvat, H., Awais, M., Bashir, A.K., Pandya, S., Zuhair, M., Rashid, M., Nebhen, J. (2022). AI-enabled radiologist in the loop: Novel AI-based framework to augment radiologist performance for COVID-19 chest CT medical image annotation and classification from pneumonia. Neural Computing and Applications, 35: 14591-14609. https://doi.org/10.1007/s00521-022-07055-1
[8] Ilyas, M., Rehman, H., Naït-Ali, A. (2020). Detection of COVID-19 from chest x-ray images using artificial intelligence: An early review. arXiv preprint arXiv:2004.05436. https://doi.org/10.48550/arXiv.2004.05436
[9] Kumar, I., Alshamrani, S.S., Kumar, A., Rawat, J., Singh, K.U., Rashid, M., AlGhamdi, A.S. (2021). Deep learning approach for analysis and characterization of COVID-19. Computers, Materials and Continua, 70(1): 451-468.
[10] Vinod, D.N., Prabaharan, S.R.S. (2023). COVID-19 -The role of artificial intelligence, machine learning, and deep learning: A newfangled. Archives of Computational Methods in Engineering, 30: 2667-2682. https://doi.org/10.1007/s11831-023-09882-4
[11] Aslani, S., Jacob, J. (2023). Utilisation of deep learning for COVID-19 diagnosis. Clinical Radiology, 78(2): 150-157. https://doi.org/10.1016/j.crad.2022.11.006
[12] Chiruvella, V., Guddati, A.K. (2021). Ethical issues in patient data ownership. Interactive Journal of Medical Research, 10(2): e22269. https://doi.org/10.2196/22269
[13] Puttagunta, M., Ravi, S. (2021). Medical image analysis based on deep learning approach. Multimedia Tools and Applications, 80: 24365-24398. https://doi.org/10.1007/s11042-021-10707-4
[14] Miotto, R., Wang, F., Wang, S., Jiang, X., Dudley, J.T. (2018). Deep learning for healthcare: review, opportunities, and challenges. Briefings in Bioinformatics, 19(6): 1236-1246. https://doi.org/10.1093/bib/bbx044
[15] Rieke, N., Hancox, J., Li, W., Milletari, F., Roth, H.R., Albarqouni, S., Bakas, S., Galtier, M.N., Landman, B.A., Maier-Hein, K., Ourselin, S., Sheller, M., Summers, R.M., Trask, A., Xu, D., Baust, M., Cardoso, M.J. (2020). The future of digital health with federated learning. NPJ Digital Medicine, 3(1): 119. https://doi.org/10.1038/s41746-020-00323-1
[16] Antunes, R.S., André da Costa, C., Küderle, A., Yari, I.A., Eskofier, B. (2022). Federated learning for healthcare: Systematic review and architecture proposal. ACM Transactions on Intelligent Systems and Technology (TIST), 13(4): 1-23. https://doi.org/10.1145/3501813
[17] Zebin, T., Rezvy, S. (2021). COVID-19 detection and disease progression visualization: Deep learning on chest X-rays for classification and coarse localization. Applied Intelligence, 51: 1010-1021. https://doi.org/10.1007/s10489-020-01867-1
[18] Gupta, K., Bajaj, V. (2023). Deep learning models-based CT-scan image classification for automated screening of COVID-19. Biomedical Signal Processing and Control, 80: 104268. https://doi.org/10.1016/j.bspc.2022.104268
[19] Kathamuthu, N.D., Subramaniam, S., Le, Q.H., Muthusamy, S., Panchal, H., Sundararajan, S.C.M., Alrubaie, A.J., Zahra, M.M.A. (2023). A deep transfer learning-based convolution neural network model for COVID-19 detection using computed tomography scan images for medical applications. Advances in Engineering Software, 175: 103317. https://doi.org/10.1016/j.advengsoft.2022.103317
[20] Mercaldo, F., Belfiore, M.P., Reginelli, A., Brunese, L., Santone, A. (2023). Coronavirus COVID-19 detection by means of explainable deep learning. Scientific Reports, 13(1): 462. https://doi.org/10.1038/s41598-023-27697-y
[21] Kini, A.S., Gopal Reddy, A.N., Kaur, M., Satheesh, S., Singh, J., Martinetz, T., Alshazly, H. (2022). Ensemble deep learning and internet of things-based automated COVID-19 diagnosis framework. Contrast Media & Molecular Imaging, 2022: 7377502. https://doi.org/10.1155/2022/7377502
[22] Gouda, W., Almurafeh, M., Humayun, M., Jhanjhi, N.Z. (2022). Detection of COVID-19 based on chest X-rays using deep learning. Healthcare, 10(2): 343. https://doi.org/10.3390/healthcare10020343
[23] Jha, N., Prashar, D., Rashid, M., Shafiq, M., Khan, R., Pruncu, C.I., Siddiqui, S.T., Saravana Kumar, M. (2021). Deep learning approach for discovery of in silico drugs for combating COVID-19. Journal of Healthcare Engineering, 2021: 1-13. https://doi.org/10.1155/2021/6668985
[24] Celik, G. (2023). Detection of COVID-19 and other pneumonia cases from CT and X-ray chest images using deep learning based on feature reuse residual block and depthwise dilated convolutions neural network. Applied Soft Computing, 133: 109906. https://doi.org/10.1016/j.asoc.2022.109906
[25] Attallah, O. (2023). RADIC: A tool for diagnosing COVID-19 from chest CT and X-ray scans using deep learning and quad-radiomics. Chemometrics and Intelligent Laboratory Systems, 230: 104750. https://doi.org/10.1016/j.chemolab.2022.104750
[26] Aliim, M.S., Fadli, A., Ramadhani, Y., Kurniawan, Y.I., Purnomo, W.H. (2023). Design a simple COVID-19 detection using corodet: A deep learning-based classification. AIP Conference Proceedings, 2482(1): 030003. https://doi.org/10.1063/5.0110764
[27] Xu, X., Jiang, X., Ma, C., Du, P., Li, X., Lv, S., Lu, L., Ni, Q., Chen, Y., Su, J., Lang, G., Li, Y., Zhao, H., Liu, J., Xu, K., Ruan, L., Sheng, J., Qiu, Y., Wu, W., Liang, T., Li, L. (2020). A deep learning system to screen novel coronavirus disease 2019 pneumonia. Engineering, 6(10): 1122-1129. https://doi.org/10.1016/j.eng.2020.04.010
[28] McMahan, B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A. (2017). Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics, PMLR, pp. 1273-1282.
[29] Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D. (2017). Grad-CAM: Visual explanations from deep networks via gradient-based localization. In 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, pp. 618-626. https://doi.org/10.1109/ICCV.2017.74
[30] Covid 19 CT Scan Dataset. (2023). https://www.kaggle.com/datasets/drsurabhithorat/COVID-19-ct-scan-dataset, accessed on 1 March 2023.
[31] Rahimzadeh, M., Attar, A., Sakhaei, S.M. (2021). A fully automated deep learning-based network for detecting COVID-19 from a new and large lung CT scan dataset. Biomedical Signal Processing and Control, 68: 102588. https://doi.org/10.1016/j.bspc.2021.102588
[32] Maftouni, M., Law, A.C.C., Shen, B., Grado, Z.J.K., Zhou, Y., Yazdi, N.A. (2021). A robust ensemble-deep learning model for COVID-19 diagnosis based on an integrated CT scan images database. In Proceedings of the 2021 IISE Annual Conference, pp. 632-637.
[33] Paiva, O. (2020). Helping radiologists to help people in more than 100 countries! Coronavirus Cases. https://coronacases.org/.
[34] Glick, Y. (2020). Viewing playlist: COVID-19 pneumonia. https://radiopaedia.org/.
[35] Jun, M., Cheng, G., Wang, Y., et al. (2020). COVID-19 CT Lung and Infection Segmentation Dataset. Zenodo, Ed., Verson 1.0 ed.
[36] Ning, W., Lei, S., Yang, J., Cao, Y., Jiang, P., Yang, Q., Zhang, J., Wang, X., Chen, F., Geng, Z., Xiong, L., Zhou, H., Guo, Y., Zeng, Y., Shi, H., Wang, L., Xue, Y., Wang, Z. (2020). iCTCF: An integrative resource of chest computed tomography images and clinical features of patients with COVID-19 pneumonia. https://doi.org/10.21203/rs.3.rs-21834/v1
[37] Gunraj, H., Wang, L., Wong, A. (2020). Covidnet-CT: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest CT images. Frontiers in Medicine, 7: 608525. https://doi.org/10.3389/fmed.2020.608525
[38] Gunraj, H., Sabri, A., Koff, D., Wong, A. (2022). COVID-Net CT-2: Enhanced deep neural networks for detection of COVID-19 from chest CT images through bigger, more diverse learning. Frontiers in Medicine, 8: 3126. https://doi.org/10.3389/fmed.2021.729287
[39] Salau, A.O., Jain, S. (2019). Feature extraction: a survey of the types, techniques, applications. In 2019 International Conference on Signal Processing and Communication (ICSC), NOIDA, India, pp. 158-164. https://doi.org/10.1109/ICSC45622.2019.8938371
[40] Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/arXiv.1409.1556
[41] Prasad, K.S., Pasupathy, S., Chinnasamy, P., Kalaiarasi, A. (2022). An approach to detect COVID-19 disease from CT scan images using CNN-VGG16 model. In 2022 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, pp. 1-5. https://doi.org/10.1109/ICCCI54379.2022.9741050
[42] Kumar, R., Khan, A.A., Kumar, J., Golilarz, N.A., Zhang, S., Ting, Y., Zheng, C., Wang, W. (2021). Blockchain-federated-learning and deep learning models for COVID-19 detection using CT imaging. IEEE Sensors Journal, 21(14): 16301-16314. https://doi.org/10.1109/JSEN.2021.3076767
[43] Yang, Q., Liu, Y., Chen, T., Tong, Y. (2019). Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2): 1-19. https://doi.org/10.1145/3298981
[44] Xu, J., Glicksberg, B.S., Su, C., Walker, P., Bian, J., Wang, F. (2021). Federated learning for healthcare informatics. Journal of Healthcare Informatics Research, 5: 1-19. https://doi.org/10.1007/s41666-020-00082-4
[45] Zhang, C., Xie, Y., Bai, H., Yu, B., Li, W., Gao, Y. (2021). A survey on federated learning. Knowledge-Based Systems, 216: 106775. https://doi.org/10.1016/j.knosys.2021.106775
[46] Kairouz, P., McMahan, H.B., Avent, B., et al. (2021). Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1-2): 1-210. http://doi.org/10.1561/2200000083
[47] Li, T., Sahu, A.K., Zaheer, M., Sanjabi, M., Talwalkar, A., Smith, V. (2020). Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems, 2: 429-450.
[48] Panwar, H., Gupta, P.K., Siddiqui, M.K., Morales-Menendez, R., Bhardwaj, P., Singh, V. (2020). A deep learning and grad-CAM based color visualization approach for fast detection of COVID-19 cases using chest X-ray and CT-Scan images. Chaos, Solitons & Fractals, 140: 110190. https://doi.org/10.1016/j.chaos.2020.110190
[49] Moujahid, H., Cherradi, B., Al-Sarem, M., Bahatti, L., Eljialy, A.B.A.M.Y., Alsaeedi, A., Saeed, F. (2022). Combining CNN and grad-cam for COVID-19 disease prediction and visual explanation. Intelligent Automation & Soft Computing, 32(2): 723-745. http://doi.org/10.32604/iasc.2022.022179
[50] Hamza, A., Attique Khan, M., Wang, S.H., Alhaisoni, M., Alharbi, M., Hussein, H.S., Alshazly, H., Kim, Y.J., Cha, J. (2022). COVID-19 classification using chest X-ray images based on fusion-assisted deep Bayesian optimization and Grad-CAM visualization. Frontiers in Public Health, 10: 1-17. https://doi.org/10.3389/fpubh.2022.1046296
[51] Ahamed, M., Uddin, K., Islam, M.M., Uddin, M., Akhter, A., Acharjee, U.K., Paul, B.K., Moni, M.A. (2023). DTLCx: An improved ResNet architecture to classify normal and conventional pneumonia cases from COVID-19 instances with Grad-CAM-based superimposed visualization utilizing chest X-ray images. Diagnostics, 13(3): 551. https://doi.org/10.3390/diagnostics13030551
[52] Eng, J. (2017). ROC Analysis: Web-Based Calculator for ROC Curves. Baltimore: Johns Hopkins University.
[53] Shah, V., Keniya, R., Shridharani, A., Punjabi, M., Shah, J., Mehendale, N. (2021). Diagnosis of COVID-19 using CT scan images and deep learning techniques. Emergency Radiology, 28: 497-505. https://doi.org/10.1007/s10140-020-01886-y
[54] Horry, M.J., Chakraborty, S., Paul, M., Ulhaq, A., Pradhan, B., Saha, M., Shukla, N. (2020). COVID-19 detection through transfer learning using multimodal imaging data. IEEE Access, 8: 149808-149824. https://doi.org/10.1109/ACCESS.2020.3016780
[55] Alshazly, H., Linse, C., Barth, E., Martinetz, T. (2021). Explainable COVID-19 detection using chest CT scans and deep learning. Sensors, 21(2): 455. https://doi.org/10.3390/s21020455
[56] Patro, K.K., Prakash, A.J., Hammad, M., Tadeusiewicz, R., Pławiak, P. (2023). SCovNet: A skip connection-based feature union deep learning technique with statistical approach analysis for the detection of COVID-19. Biocybernetics and Biomedical Engineering, 43(1): 352-368. https://doi.org/10.1016/j.bbe.2023.01.005
[57] Sufian, M.M., Moung, E.G., Hijazi, M.H.A., Yahya, F., Dargham, J.A., Farzamnia, A., Sia, F., Mohd Naim, N.F. (2023). COVID-19 classification through deep learning models with three-channel grayscale CT images. Big Data and Cognitive Computing, 7(1): 36. https://doi.org/10.3390/bdcc7010036
[58] Kogilavani, S.V., Prabhu, J., Sandhiya, R., Kumar, M.S., Subramaniam, U., Karthick, A., Muhibbullah, M., Imam, S.B.S. (2022). COVID-19 detection based on lung CT scan using deep learning techniques. Computational and Mathematical Methods in Medicine, 2022: 7672196. https://doi.org/10.1155/2022/7672196
[59] Chouat, I., Echtioui, A., Khemakhem, R., Zouch, W., Ghorbel, M., Hamida, A.B. (2022). COVID-19 detection in CT and CXR images using deep learning models. Biogerontology, 23(1): 65-84. https://doi.org/10.1007/s10522-021-09946-7
[60] Gupta, V., Jain, N., Sachdeva, J., Gupta, M., Mohan, S., Bajuri, M.Y., Ahmadian, A. (2022). Improved COVID-19 detection with chest x-ray images using deep learning. Multimedia Tools and Applications, 81(26): 37657-37680. https://doi.org/10.1007/s11042-022-13509-4