Yang Zhou![]() | Chuang Cao*
| Chuang Cao*![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Image segmentation and registration are the premise of ultrasonic image analysis. The key of computer-aided clinical diagnosis of fetal development is to improve the accuracy and speed of ultrasound image segmentation and registration, which is worth further discussion. As for the existing research results, problems still remain in the accuracy and effect of segmentation and registration. Therefore, this paper studied the fetal development ultrasound image segmentation and registration based on deep learning. In Chapter 2, the paper designed a convolution module, dividing the feature information generation process into two steps. The introduced self-tuning lightweight segmentation module and channel attention module were used to enhance the expression ability of features and improve the segmentation performance of the Convolutional Neural Network (CNN), respectively. In Chapter 3, this paper constructed a full-CNN model based on joint training to perform non-rigid registration of fetal development ultrasound images, which reduced the computational complexity of the model. The experimental results verified the effectiveness of the model.
deep learning, fetal development, ultrasonic image, image segmentation, image registration
In the clinical diagnosis of fetal development during pregnancy, ultrasound images help doctors better understand the situation, and provide sufficient basis for the judgment whether the fetal development meets the standard or is abnormal [1-6]. In order to make an in-depth analysis of the target in the uterus, it is necessary to segment the target from the ultrasound image [7-12]. In order to compare the changes of fetal growth index in different periods, it is also necessary to register the fetal development ultrasound images in different periods, even if the corresponding structures of different ultrasound images are consistent in space [13-16]. Therefore, image segmentation and registration are the premise of ultrasonic image analysis. Improving the accuracy and speed of ultrasound image segmentation and registration is the key of computer-aided clinical diagnosis of fetal development, which can be further discussed.
Ultrasound image segmentation of thyroid nodules is the key technology of thyroid computer-aided diagnosis. How to achieve accurate segmentation of nodules has always been a hot issue in the field of medical image segmentation. In order to solve the problem of the traditional model being sensitive to the background area when segmenting the low-contrast ultrasound image, Deng et al. [17] proposed a thyroid nodule ultrasound image segmentation algorithm based on the Delay Pulse Coupled Neural Network (DPCNN). First, the algorithm roughly located the suspicious regions in the optimal segmented image output by the DPCNN iteration, and determined the diseased region by using the comprehensive judgment criteria of maximum variance and covariance of local region. In order to accurately segment thyroid nodules from ultrasound images, Chen et al. [18] improved the U-Net++ network. Then based on the U-Net++ network, EfficientDet was used as the encoder, and CSSE blocks were combined in the encoder and decoder to improve performance. The improved algorithm is of great significance for the application of automatic segmentation of thyroid nodule ultrasound image in practical clinical medicine. Peng et al. [19] proposed a coder-decoder network with weighted skip connection, and the idea of resolution ratio, such as delamination manually controlling the receptive field. The proposed method was evaluated by comparing data sets of 1,850 annotated images with various classical networks.
Wei et al. [20] proposed a method of ultrasonic image clustering and registration based on the Gaussian Mixture Model (GMM) to suppress interference in arterial wall displacement estimation. Firstly, the GMM was used to cluster carotid artery ultrasound images to obtain clustering image sequence. Secondly, the shift of distant tissues representing external interference was extracted from the clustering image sequence. Finally, the pulsation displacement of the arterial wall was estimated according to the registered clustering image sequence. In order to achieve accurate registration accuracy in medical treatment, Wang [21] proposed a medical image registration algorithm based on automatic feature points. Firstly, the Scale Invariant Feature Transform (SIFT) algorithm and shape factor were used to generate landmarks. Secondly, these landmarks were used to build a primary data set, including local and global feature vectors. Finally, the data set was registered through thin plate spline interpolation. Based on the correlation of the FFT (Fast Fourier Transform), Wu et al. [22] studied the ultrasonic Time of Flight Diffraction (TOFD) image registration algorithm. In addition, the principle of template matching algorithm was used to make the detection images clear and the defect features obvious. The algorithm is simple and accurate. The subsequent sub-pixel image registration algorithm of TOFD will improve the registration accuracy to sub-pixel level. Further improvement of the TOFD image registration algorithm is more conducive to subsequent image processing.
Although some research achievements have been made in ultrasonic image segmentation and registration technology in recent years, problems still remain in the accuracy and effect of segmentation and registration. The existing image segmentation technology cannot adapt to the real samples with different sizes, random positions and low contrast. The existing image registration criteria have difficulty in fully capturing the complex deformation information between the corresponding structures of two ultrasonic images. In addition, it is also difficult to extract the discriminative features, which are more discriminative than the structural displacement information in the image. Therefore, this paper studied the deep learning-based fetal development ultrasound image segmentation and registration. In the second chapter, a convolution module was designed, dividing the feature information generation process into two steps. After being introduced, the self-tuning lightweight segmentation module and the channel attention module were used to enhance the expression ability of features and improve the segmentation performance of the CNN, respectively. In the third chapter, a full-CNN model was constructed based on joint training in order for non-rigid registration of the fetal development ultrasound images, which reduced the computational complexity of the model. Results of the experiment verified the effectiveness of the model.
In order to improve the ability of image segmentation model to capture image feature information, the traditional model structure improvement algorithm generally adds new modules or connection layers on the original basis, which greatly increases the complexity of the model. On the basis of maintaining the original model structure, this paper enhanced the feature information conversion process in the convolution by using self-tuning convolution operation, thus obtaining higher model segmentation performance. In this paper, the feature information of fetal development ultrasound images was redundant by default. Therefore, a convolution module was designed, which split the feature information generation process into two steps. Two modules were introduced, the self-tuning lightweight segmentation module and the channel attention module, which enhanced the expression ability of features and improved the segmentation performance of the CNN. The structure and principle of the introduced modules are described in detail below.
Let D be the number of channels for the input feature of the fetal development ultrasound image sample, F and Q be the height and width of the input feature image, g be the convolution operation, b∈RM×F×Q be the output result of the feature map generated by the common convolution layer, M be the number of channels of the output feature map, and F and Q be the height and width of the output feature map. Let a∈RD×F×Q be the input fetal development ultrasound image sample data, then the expression of feature map generation process from ordinary convolution layer was:
$b=g * a$ (1)
According to the above formula, if the size of the convolution kernel was expressed by l, the number of parameters required by the model was M×D×l×l. Since the value M of the CNN is usually large, the number of the model parameters M×D×l×l is also large. Therefore, this paper designed a lightweight convolution module by starting with the feature map generation process. Figure 1 shows the architecture of self-tuning lightweight segmentation module.
Figure 1. Architecture of the self-tuning lightweight segmentation module
The new convolution module divided the output feature map into two features: the essential feature and the phantom feature. That is, for the input fetal development ultrasound image feature map a, its essential feature generated through convolution operation had the same number of channels M/2, as its phantom feature generated through mapping function. Let GJ be the convolution operation, Ψ be the mapping function and ⊗ be the splicing operation, then there were:
$b=G J(a) \otimes \Psi(G J(a))$ (2)
The mapping function required different scales of receptive fields to provide richer and more accurate feature information. In order to avoid the increase in the number of parameters caused by the design of convolution kernels with different sizes, this paper used the self-tuning module, which integrated the spatial information of different scales, as the mapping function. In order to maintain the passing parameters unchanged, the convolution kernel grouping operation was used to enhance the conversion process of feature information in the convolution.
In order to reduce the resolution of the feature map of fetal development ultrasound image, av, half of the essential feature generated after the convolution operation was DS( ), down-sampled in the first self-tuning branch, and the size of the feature map was adjusted to M/4×M/4×Q/2:
$G_1=D S\left(a_v\right)$ (3)
After obtaining the feature map that contained only the context information around the spatial location, the correction operation on it was performed, and the corrected output feature was represented by a'v. At the same time, aw, the other half of the essential feature, output the feature a'w through the conventional convolution operation. Let $\oplus$ and ⊗ be element-by-element addition and multiplication, respectively, there was the following correction process expression:
$a_v^{\prime}=G J 3\left\{\operatorname{sigmoid}\left\{U S\left(G J 1\left(G_1\right)\right) \oplus a_v\right\} \otimes G J 2\left(a_v\right)\right\}$ (4)
Features a'v and a'w spliced the phantom feature according to the channel dimension, with the size of M/2×F×Q. Let au be the overall essential feature, the final output feature of the convolution module was obtained by splicing the essential and the phantom feature:
$a_T=a_v^{\prime} \otimes G J 3\left(a_w\right) \otimes a_u$ (5)
In order to effectively reduce the number of parameters in the model, each convolution group was also decomposed in the form of asymmetric convolution, because the essential feature of fetal development ultrasound image only adopted 1×1 convolution kernel. Let l be the convolution kernel size, D be the number of input channels, and M be the number of output channels, the following formula gave the calculation formula of the number of parameters in the model using ordinary convolution layer:
$D R_1=l \times l \times D \times M$ (6)
Analogically, the following gave the calculation formula of the number of parameters in the new convolution module without considering the normalization layer and other parameters:
$D R_2=1 \times 1 \times D \times \frac{M}{2}+\left[\frac{M}{4} \times \frac{M}{4} \times(l \times l)\right] \times 4$ (7)
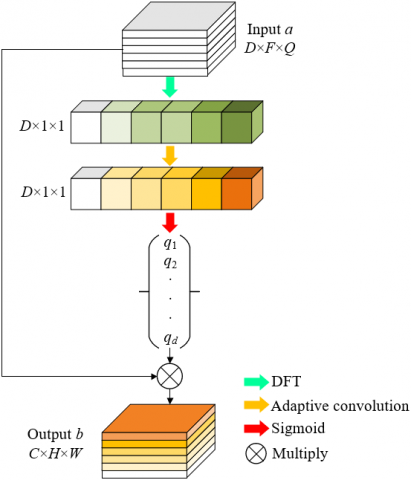
The dimensionality reduction of the features of fetal development ultrasound images will lead to the loss of feature information and affect the information acquisition efficiency between different channels. Therefore, this paper introduced the channel attention module and replaced the self-adapting one-dimensional convolution kernel with the reduced-dimension fully connected layer, which effectively reduced the information loss between different channels caused by the reduced-dimension layer, and realized the efficient interaction of fetal development ultrasound image feature information between different channels after global average pooling. Figure 2 shows the architecture of the channel attention module. Let D be the number of channels, and Ω be the results rounded down, then the formula for calculating the size of adaptive one-dimensional convolution kernel was:
$A D G J S=\left|\frac{1+\log _2 D}{2}\right|_{\Omega}$ (8)
Let Γ be the global average pooling operation, then the expression of the working process of the channel attention module was:
$b=\operatorname{sigmoid}\{A D G J(\Gamma(a))\} * a$ (9)
Finally, based on the Discrete Fourier Transformation (DFT), this paper improved the compression method of the channel attention module, transforming the feature map of the fetal development ultrasound images from the spatial domain to the frequency domain. Let F and Q be the spatial resolution of the two-dimensional feature map, a and h be the position of the spatial domain of the feature map, a∈[0,Q-1] and b∈[0,F-1], g(a,b) be the pixel value on the spatial location, and G(h,k) be the value of the DFT, the image feature was represented by a series of frequency components below:
$G(h, k)=\frac{1}{F Q} \sum_{a=0}^{Q-1} \sum_{b=0}^{F-1} g(a, b) p^{-2 j \pi\left(\frac{h a}{Q}+\frac{k b}{F}\right)}$ (10)
The zero-frequency component of the DFT was:
$G(0,0)=\frac{1}{F Q} \sum_{a=0}^{Q-1} \sum_{b=0}^{F-1} g(a, b)$ (11)
It can be seen from the above formula that G(0,0) is exactly the global average of the image pixels. Replacement of the compression operation in the channel attention module with the frequency component of the DFT realized the representation of the global information of fetal development ultrasound image.
Figure 2. Architecture of the channel attention module
Because the calculation complexity of the ultrasound image registration model based on deep learning is also large, the training efficiency of the model is low, and the fast prediction of the ultrasound image cannot be realized. Therefore, this paper chose to construct a full-CNN model based on joint training for non-rigid registration of fetal development ultrasound images. The model is composed of three miniaturized subnetworks. The training process was also carried out in groups, which greatly reduced the computational complexity of the model. Figure 3 shows the architecture of fetal development ultrasound image registration model.
Figure 3. Architecture of fetal development ultrasound image registration model
Figure 4. Subnetwork architecture
The model was divided into three modules. Module 1 connected G, the fixed image the paired fetal development ultrasound images, with Q, the floating images participating in the comparison, on the channel dimension, and completed the downsampling based on the global pooling layer. Then the downsampling results were input into the first miniaturized subnetwork for low-scale deformation vector field estimation. Let ψ1 be the initial deformation vector field model obtained by scale 1 and Q2 be the deformation image, ψ1 was downsampled to the resolution state of the original ultrasonic image and Q was input to ψ'1 to obtain Q2. Finally, G and G1 were introduced into the joint loss function in order to optimize the miniaturized subnetwork of scale 1.
The miniaturized subnetwork of module 2 was mainly used to register the residual deformation vector field between G and Q2. That is, downsampling of G and Q was completed based on the global pooling layer. Then the downsampling results were input into the miniaturized subnetwork of scale 2. Let ψ2 be the obtained estimated deformation vector field model, ψ2 was upsampled to the resolution state of the original ultrasonic image. ψ'2, the final deformation vector field model of scale 2, was obtained by adding the upsampling results to ψ1. Then G was input into ψ'2 to obtain the deformation image Q2. In order to optimize the miniaturized subnetwork of scale 2, G and Q2 were input into the joint loss function as follows:
$\psi_2^{\prime}=\psi_2+\psi_1$ (12)
The miniaturized subnetwork in module 3 was mainly used to register the residual deformation vector field between G and Q2. The connection results of G and Q2 at this scale were input into the miniaturized subnetwork of scale 3, let ψ3 be the output residual deformation vector field model, then ψ'3, the deformation vector field model of scale 3, was obtained by adding ψ3 and ψ2. The final dense deformation vector field output by the registration model was obtained by inputting G and G3 into the joint loss function:
$\psi_3^{\prime}=\psi_3+\psi_2$ (13)
Due to the shallow depth of the miniaturized subnetwork in this model, in order to reduce the feature information loss rate of the original fetal development ultrasound images, this paper selected the LeakyRelu function as the activation function and the expression was given by the following formula:
$L R(a)=\max (0, a)+\beta^* \min (0, a)$ (14)
Figure 4 shows the subnetwork architecture. The three miniaturized subnetworks included in the full CNN model constructed in this paper need to be jointly trained at the multi-scale level, that is, the multi-scale compound loss of the three subnetworks should be minimized in order to achieve the best end-to-end fetal development ultrasound image registration performance of the model on the whole. Let λ1, λ2 and λ3 be the weighting factors of the scale 1, scale 2 and scale 3 models when calculating the difference measurement, then the weighted sum of multi-scale compound loss of the subnetworks was given below:
$\begin{aligned} & \operatorname{LOSS}=\lambda_1 * C\left(\psi_1^{\prime} \cdot N, G\right)+\lambda_2 * C\left(\psi_2^{\prime} \cdot N, G\right)+\lambda_3 * C\left(\psi_3^{\prime} \cdot N, G\right)\end{aligned}$ (15)
In order to match the large deformation error of the fetus in the fetal development ultrasound images in different periods, the model built in this paper first trained the initial deformation vector field estimation of the model, and then trained the scale 2 model in order to correct the fetal residual deformation error in the fetal development ultrasound images. At the same time, the scale 3 model was trained by fixing the network weights of the scale 1 and scale 2 models to fine-tune the deformation vector field.
Table 1 lists the comparison of different ultrasound image segmentation models corresponding to different evaluation indexes, and the time consumed by different models for segmenting fetal development ultrasound images. According to Table 1, the average values of three parameters, IoU, Precision and Recall, obtained by this model from the original image sample set and the expanded sample set, are the highest compared with the S-U-Net model and the DRNet model. This verified that the model in this paper had obvious advantages in segmentation performance of fetal development ultrasound images in terms of each evaluation index value. At the same time, compared with the S-U-Net model and the DRNet model, the average error value obtained by the proposed model on the original image sample set and the expanded sample set was also the smallest, which also showed that the image segmentation results output by the model in this paper were more consistent with the actual situation. It can be seen from Table 2 that the Jaccard similarity value of the constructed model is more ideal, which verified that the model effectively worked on the segmentation task of fetal development ultrasound images.
Table 1. Performance comparison results of different ultrasonic image segmentation models
|
|
IoU |
Precision |
Recall |
RMSE |
Time(s) |
||||
|
Mean |
Std |
Mean |
Std |
Mean |
Std |
Mean |
Std |
||
|
Skip CNN |
64.13 |
8.56 |
78.27 |
10.06 |
78.45 |
8.32 |
2.56 |
0.68 |
0.32 |
|
LadderNet |
68.64 |
7.82 |
81.43 |
8.13 |
81.72 |
8.01 |
2.34 |
0.63 |
0.56 |
|
DEU-Net |
70.65 |
7.82 |
82.94 |
8.02 |
82.89 |
7.43 |
2.26 |
0.63 |
0.67 |
|
S-U-Net |
66.85 |
8.65 |
78.76 |
8.95 |
81.96 |
8.36 |
2.37 |
0.68 |
0.32 |
|
DRNet |
70.34 |
7.67 |
82.13 |
8.45 |
83.44 |
7.49 |
2.25 |
0.62 |
0.58 |
|
The model in this paper |
71.42 |
7.86 |
83.21 |
8.13 |
83.75 |
7.43 |
2.23 |
0.63 |
0.70 |
Table 2. Comparison of similarity with other ultrasound image segmentation models
|
Models |
Dataset |
DSC |
Jaccard |
Protocol |
|
Skip CNN |
41-S |
77.28±6.26 |
59.9±8.13 |
QE-7 |
|
LadderNet |
41-S |
76.35±5.67 |
61.26±8.21 |
QE-7 |
|
DEU-Net |
41-S |
78.6±6.8 |
65.7±9.02 |
QE-7 |
|
S-U-Net |
41-S |
79.47±6.24 |
59.2±8.26 |
QE-7 |
|
DRNet |
41-S |
80.51±4.96 |
59.7±7.36 |
QE-7 |
|
The model in this paper |
41-S |
76.34±5.75 |
69.36±7.69 |
QE-7 |
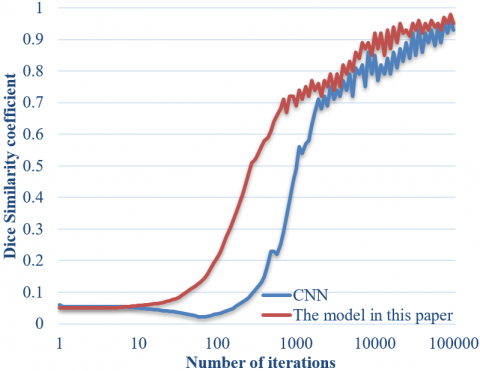
Figure 5. Change curve of Dice similarity coefficient in the model training
Figure 5 shows the change curve of Dice similarity coefficient corresponding to the traditional full-CNN model in the training stage and the fetal development ultrasound image registration model proposed in this paper on the original image sample set and the expanded sample set. According to the figure, compared with the traditional full-CNN model, the model built in this paper reaches the convergence state faster and the overall level of the obtained Dice similarity coefficient is also in a better state.
Table 3 shows the quantitative analysis results of different image registration models on the same original image sample set and the expanded sample set. The models involved in the comparison include the Syn-ANTs model, the SimpleElastix model, the DIRNet model, the VoxelMorph model, the DLIR model and the Li-Net model. The quantitative analysis indexes include the values of DSC, ASD and HD of the registered images, and the standard deviation of Jacobian determinant values and the average number of registration pixels corresponding to the image registration domains output by the model.
Table 3. Quantitative analysis results of different image registration models
|
Methods |
DSC |
ASD |
HD |
Number of registration pixels |
Standard deviation of Jacobian determinant values |
|
Before registration |
0.78±0.21 |
3.88±3.65 |
13.59±5.23 |
- |
- |
|
SyN-ANTs |
0.88±0.19 |
1.16±1.34 |
8.97±4.58 |
65.88±95.55 |
0.16±0.07 |
|
SimpleElastix |
0.88±0.19 |
1.17±1.28 |
8.89±4.15 |
45.79±65.42 |
0.16±0.09 |
|
DIRNet |
0.87±0.18 |
0.94±1.07 |
8.14±5.41 |
36.08±55.94 |
0.12±0.05 |
|
VoxelMorph |
0.87±0.16 |
0.93±0.98 |
8.21±5.65 |
37.06±46.38 |
0.12±0.06 |
|
DLIR |
0.91±0.20 |
0.88±0.96 |
8.07±5.39 |
32.05±31.53 |
0.11±0.04 |
|
Li-Net |
0.91±0.19 |
0.87±0.98 |
8.03±5.18 |
26.37±30.54 |
0.11±0.04 |
|
The model in this paper |
0.93±0.19 |
0.87±0.95 |
8.06±4.94 |
24.66±24.45 |
0.11±0.04 |
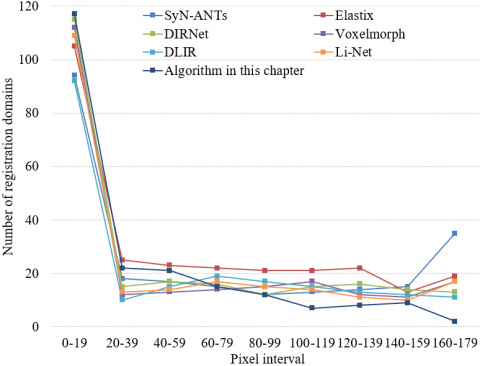
Figure 6 shows the change curve of the number of registration domains for different image registration models. According to the figure, the DSC average value of fetal development ultrasound images registered by the proposed full-CNN model based on joint training is higher than that of registration images of other contrast models, and lower ASD and HD values have been obtained. Specifically, among all the test samples of the original image sample set and the expanded sample set, the DSC value increased by 3%~6%, the ASD value reduced by 6%~25% and the HD value reduced by 1%~10% in the model proposed in this paper, compared with other models involved in the comparison. This verified that the model proposed in this paper achieved better registration accuracy for fetal development ultrasound images. At the same time, compared with other models involved in the comparison, the standard deviation of the Jacobian determinant value and the number of registration pixels output by this model were significantly lower. Specifically, the standard deviation of the Jacobian determinant value decreased by 9%~34%, and the number of registration pixels decreased by 34%~60%, which verified that the model proposed in this paper had more advantages in the quality of registration domains and higher registration reliability obtained in the process of registration of fetal development ultrasound images, compared with other models involved in the comparison.
Figure 6. Change curve of the number of registration domains of different image registration models
This paper studied the deep learning-based fetal development ultrasound image segmentation and registration. A convolution module was designed in the second chapter of the paper, which divided the feature information generation process into two steps. The self-tuning lightweight segmentation module and the channel attention module were introduced and used to enhance the expression ability of features and improve the segmentation performance of the CNN, respectively. A full-CNN model based on joint training was constructed in the third chapter for non-rigid registration of fetal development ultrasound images, which reduced the computational complexity of the model.
Combined with the experiment, this paper listed the comparison of different ultrasound image segmentation models corresponding to different evaluation indexes, and the time consumption of different models for segmenting fetal development ultrasound images. This paper compared the similarity with other ultrasound image segmentation models, which verified that the average error value of the model in this paper obtained on the original image sample set and the expanded sample set was the smallest, and the constructed model effectively worked on the segmentation task of the fetal development ultrasound images. In addition, this paper drew the change curve of the Dice similarity coefficient corresponding to the traditional full-CNN model at the training stage and the fetal development ultrasound image registration model proposed in this paper on the original image sample set and the expanded sample set, gave the quantitative analysis results of different image registration models, and drew the change curve of the number of registration domains of different image registration models. This verified that the model in this paper had more advantages in the quality of registration domains and higher registration reliability obtained in the process of registration of fetal development ultrasound images, compared with other models involved in the comparison.
[1] Zhang, S., Pei, C., Sun, D., Wang, J., Liu, W. (2022). Ultrasonic image optimization based on double constraint algorithm. Journal of Imaging Science & Technology, 66: 040414. http://dx.doi.org/10.2352/J.ImagingSci.Technol.2022.66.4.040414
[2] Rymarczyk, T., Kania, K., Gołąbek, M., Sikora, J., Maj, M., Adamkiewicz, P. (2021). Image reconstruction by solving the inverse problem in ultrasonic transmission tomography system. COMPEL-The international journal for computation and mathematics in electrical and electronic engineering, 40(2): 238-266. https://doi.org/10.1108/COMPEL-01-2020-0045
[3] Souza, R., Freitas, M.A., Kubrusly, A.C., von der Weid, J.P. (2020). Improvement of ultrasonic image by a combination of correlation-based image processing and virtual sources applied to non-destructive evaluation. In 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, pp. 205-210. https://doi.org/10.1109/IWSSIP48289.2020.9145248
[4] Yuan, M., Li, J., Liu, Y., Gao, X. (2019). Automatic recognition and positioning of wheel defects in ultrasonic B-Scan image using artificial neural network and image processing. Journal of Testing and Evaluation, 48(1): 308-322. https://doi.org/10.1520/JTE20180545
[5] Vienneau, E.P., Ozgun, K.A., Byram, B.C. (2022). Spatiotemporal coherence to quantify sources of image degradation in ultrasonic imaging. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, 69(4): 1337-1352. https://doi.org/10.1109/TUFFC.2022.3152717
[6] Souza, R.M., Alvarenga, A.V., Petrella, L.I., Costa-Felix, R.P. (2020). Metrological assessment of image quality in ultrasonic medical diagnostic equipment. Research on Biomedical Engineering, 36: 379-397. https://doi.org/10.1007/s42600-020-00078-4
[7] Long, Z., Zhang, X., Li, C., Niu, J., Wu, X., Li, Z. (2020). Segmentation and classification of knee joint ultrasonic image via deep learning. Applied Soft Computing, 97: 106765. http://dx.doi.org/10.1016/j.asoc.2020.106765
[8] Yao, R., Yao, P., Gao, Y. (2017). Precision analysis of level set segmentation in phased array ultrasonic testing image. Boletin Tecnico/Technical Bulletin, 55(3): 307-312.
[9] Liu, Y., Zhang, Y., Huang, J. (2017). A adaptive segmentation algorithm of ultrasonic image based on simplified PCNN. In 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Xiamen, China, pp. 784-788. https://doi.org/10.1109/ISPACS.2017.8266582
[10] Guo, Z., Zhou, J., Zhao, D. (2020). Thyroid nodule ultrasonic imaging segmentation based on a deep learning model and data augmentation. In 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, pp. 549-554. https://doi.org/10.1109/ITNEC48623.2020.9085093
[11] Hasanian, M., Ramezani, M.G., Golchinfar, B., Saboonchi, H. (2020). Automatic segmentation of ultrasonic TFM phased array images: The use of neural networks for defect recognition. Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2020, 11379: 66-76. https://doi.org/10.1117/12.2558975
[12] Ni, B., He, F., Yuan, Z., Cai, X., Zhou, Y., Chen, X., Zhang, D. (2013). Fibroid segmentation in ultrasonic image for constructing statistical deformation model from MRI. Journal of Computer-Aided Design and Computer Graphics, 25(6): 817-822.
[13] Ohnishi, T., Kashio, S., Ito, K., Makhanov, S.S., Yamaguchi, T., Iwadate, Y., Haneishi, H. (2018). Image feature conversion of pathological image for registration with ultrasonic image. In 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, pp. 1-2. https://doi.org/10.1109/IWAIT.2018.8369800
[14] Duan, J., Luo, L., Gao, X., Peng, J., Li, J. (2018). Multiframe ultrasonic TOFD weld inspection imaging based on wavelet transform and image registration. Journal of Sensors, 2018: 9545832. https://doi.org/10.1155/2018/9545832
[15] Duan, J.X., Luo, L., Gao, X.R., Peng, J.P., Li, J.L. (2018). Hybrid ultrasonic TOFD imaging of weld flaws using wavelet transforms and image registration. Journal of Nondestructive Evaluation, 37: 23. https://doi.org/10.1007/s10921-018-0476-2
[16] Duan, J.X., Luo, L., Gao, X.R., Peng, J.P., Li, J.L. (2017). Ultrasonic TOFD imaging of weld flaws using wavelet transforms and image registration. In 2017 Far East NDT New Technology & Application Forum (FENDT), Xi'an, China, pp. 111-116. https://doi.org/10.1109/FENDT.2017.8584589
[17] Deng, X., Zhang, H., Yang, Y. (2022). Ultrasonic image segmentation algorithm of thyroid nodules based on DPCNN. In Proceedings of 2021 International Conference on Medical Imaging and Computer-Aided Diagnosis (MICAD 2021) Medical Imaging and Computer-Aided Diagnosis, Birmingham, United Kingdom, pp. 163-174. https://doi.org/10.1007/978-981-16-3880-0_18
[18] Chen, C., Xu, B., Wu, Y., Wu, K., Tan, C. (2022). Research on ultrasonic image segmentation of thyroid nodules based on improved U-net++. In 2022 2nd International Conference on Bioinformatics and Intelligent Computing, Harbin, China, pp. 532-536. https://doi.org/10.1145/3523286.3524603
[19] Peng, H., Guan, Y., Li, J., et al. (2021). MwUnet: A semantic segmentation deep learning method for the ultrasonic image of hydronephrosis in children. In 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, pp. 1894-1899. https://doi.org/10.1109/SMC52423.2021.9658930
[20] Wei, Q., He, B., Zhang, Y., Li, Z., Lu, J., Wang, Z. (2022). Arotid Artery Wall Pulsation Displacement Interference Suppression Based on Ultrasonic Images Clustered Registration with Gaussian Mixture Model. In 2022 the 5th International Conference on Image and Graphics Processing (ICIGP), Beijing China, pp. 183-188. https://doi.org/10.1145/3512388.3512415
[21] Wang, X. (2014). Non-rigid registration of ultrasonic image based on matching corresponding landmarks. In Proceedings of the 2012 International Conference on Cybernetics and Informatics, pp. 309-313. https://doi.org/10.1007/978-1-4614-3872-4_40
[22] Wu, Y.Y., Gao, X.R., Guo, J.Q., Wang, Z.Y., Zhao, Q.K., Shen, Y. (2014). Ultrasonic TOFD image registration algorithm of sub-pixel accuracy based on DFT. In 2014 IEEE Far East Forum on Nondestructive Evaluation/Testing, Chengdu, China, pp. 84-88. https://doi.org/10.1109/FENDT.2014.6928238