Zhuo Yao
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Most computer vision applications demand input images to meet their specific requirements. To complete different vision tasks, e.g., object detection, object recognition, and object retrieval, low-light images must be enhanced by different methods to achieve different processing effects. The existing image enhancement methods, which are based on non-physical imaging models, and image generation methods, which are based on deep learning, are not ideal for low-light image processing. To solve the problem, this paper explores low-light image enhancement and target detection based on deep learning. Firstly, a simplified expression was constructed for the optical imaging model of low-light images, and a Haze-line was proposed for color correction of low-light images, which can effectively enhance low-light images based on the global background light and medium transmission rate of the optical imaging model of such images. Next, network framework adopted by the proposed low-light image enhancement model was introduced in detail: the framework includes two deep domain adaptation modules that realize domain transformation and image enhancement, respectively, and the loss functions of the model were presented. To detect targets based on the output enhanced image, a joint enhancement and target detection method was proposed for low-light images. The effectiveness of the constructed model was demonstrated through experiments.
computer vision, low-light images, color correction, image enhancement, object detection
Most computer vision applications demand input images to meet their specific requirements [1-8]. Take tax detection for example, the input image must be clear and complete. Otherwise, the corresponding algorithm cannot complete the target detection task. The image data under fog, special weather, and lighting are usually not clear enough to be used directly. Further processing is required to obtain the expected visual quality of the images [9-17]. At present, many computer vision systems are installed in outdoor environments and low-temperature water environments. Their performance is easily affected by light distribution [18-24]. To complete different vision tasks, e.g., object detection, object recognition, and object retrieval, low-light images must be enhanced by different methods to achieve different processing effects.
Inspired by image-to-curve transform and multi-exposure fusion, Wang et al. [25] proposed a new method to treat the low-light image enhancement task as an extended problem with multiple virtual exposures, using nonlinear intensity mapping. Considering the difficulty for existing image-to-curve methods to obtain the desired detail and recover the expected brightness in any one iteration without relying on any ground truth, a virtual multi-exposure fusion strategy was proposed to merge the outputs of these different iterations. Global structure and local texture have different effects on image enhancement tasks. Xu et al. [26] proposed a structured texture awareness network (STANet), which successfully exploits the structure and texture features of low-light images to improve perceptual quality. A fusion sub-network with attention mechanism was used to explore the intrinsic correlation between global and local features. Furthermore, a color loss function was introduced to alleviate the color distortion in the enhanced images, thus optimizing the proposed STANet model. Lu and Gan [27] studied low-light face recognition and authentication based on image enhancement. Light processing and Gaussian filtering were employed to suppress and eliminate the low-light effect of such images. Then, the basic framework and objective functions of existing generative adversarial networks (GANs) were modified. By learning the mapping of side and front faces in multi-pose face images in the image space, a cross-pose GAN was built to convert faces of different poses into front faces. Experimental results show that their model is effective. The low-light images captured in non-uniformly light environments typically degrade with scene depth and corresponding ambient lighting. This degradation can lead to severe loss of target information in the degraded image morphology, making the detection of salient targets more challenging due to low-contrast properties and the effects of artificial light. Xu et al. [28] put forward an image enhancement method to facilitate the detection of salient objects in low-light images. This model directly embeds a physical illumination model into a deep neural network to describe the degradation of low-light images, where ambient light is treated as a point-wise variable, which varies with local content.
Currently, low-light images are mainly processed by image enhancement based on non-physical imaging model. These methods boast the advantages of low computational complexity and fast processing speed, but cannot effectively restore the original details of the image and cannot solve the problem of image blur. The image generation based on deep learning can generate clear images containing a lot of details and information. But this approach must be supported by enough image samples and powerful machine computing power. Thus, the use conditions are relatively harsh, and the ideal processing effect cannot be obtained when the environment changes. To solve the problem, this paper explores low-light image enhancement and target detection based on deep learning. Section 2 constructs a simplified expression for the optical imaging model of low-light images, and proposes a Haze-line for color correction of low-light images, which can effectively enhance low-light images based on the global background light and medium transmission rate of the optical imaging model of such images. Section 3 details the network framework adopted by the proposed low-light image enhancement model: the framework includes two deep domain adaptation modules that realize domain transformation and image enhancement, respectively, and presents the loss functions of the model. To detect targets based on the output enhanced image, a joint enhancement and target detection method was proposed for low-light images. The effectiveness of the constructed model was demonstrated through experiments.
In real scenes, noise and illumination changes are the main reasons for image degradation. Hence, it is possible to construct the following simplified expression for the optical imaging model of low-light images. Let a be a point in a low-light scene; Φ be the wavelengths of the red, green, and blue color channels; ZLΦ(a)eΦ(a) be the direct luminance component, which depicts the attenuation of scene light in the low-light environment; XΦ be the global background light; ZLΦ(a) be the radiance of the scene at point a. Then, the degraded low-light image TXΦ(a) captured by the computer vision system can be expressed as:
$\begin{align} & T{{X}_{\Phi }}\left( a \right)=Z{{L}_{\Phi }}\left( a \right){{e}_{\Phi }}\left( a \right)+{{X}_{\Phi }}\left( a \right)\left( 1-{{e}_{\Phi }}\left( a \right) \right),\Phi \in \left\{ s,h,y \right\} \\ \end{align}$ (1)
Let γΦ be the wavelength-dependent medium attenuation coefficient; δ(a) be the distance from the computer vision system to the surface of the target to be detected. Then, the medium transmission rate eΦ(a) can be defined as the energy ratio of medium ZLΦ(a) reflected from point a to the computer vision system in the scene:
${{e}_{\Phi }}\left( a \right)=\exp \left( -{{\gamma }_{\Phi }}\delta \left( a \right) \right)$ (2)
eΦ(a) characterizes the effect of light on the color and contrast of a low-light image, as it propagates in a low-light environment. In formula (1), XΦ(1-eΦ(a)) characterizes the illumination backscattering component of the low-light environment. Therefore, the effective enhancement of low-light images aims to estimate XΦ and eΦ(a), two key parameters for the effective enhancement of low-light images.
In the traditional sense, Haze-line cannot adequately account for the attenuation of light from different wavelengths in low-light images. This paper proposes a Haze-line for color correction of low-light images, which can effectively enhance low-light images based on the global background light and medium transmittance of the optical imaging model of low-light images.
The edge map of the scene is first generated, and then thresholded to obtain the mean color of the background light pixels of the largest connected component of the low-light image, that is, the global background light of the low-light image.
The size of the medium transmission rate eΦ(a) depends on δ(a) and γΦ. To ensure that the red, green and blue color channels have different attenuation coefficients, this paper first estimates the attenuation ratio of the blue and green color channels and that of the blue and red color channels:
${{\gamma }_{ys}}={{\gamma }_{y}}/{{\gamma }_{s}},{{\gamma }_{yh}}={{\gamma }_{y}}/{{\gamma }_{h}}$ (3)
The three color channels can be expressed by combining formulas (1) and (2):
$\begin{align} & T{{X}_{s}}-{{X}_{s}}=\text{exp}\left( -{{\gamma }_{s}}p \right)\cdot \left( Z{{L}_{s}}-{{X}_{s}} \right) \\ & T{{X}_{h}}-{{X}_{h}}=\text{exp}\left( -{{\gamma }_{h}}p \right)t\cdot \left( Z{{L}_{h}}-{{X}_{h}} \right) \\ & T{{X}_{y}}-{{X}_{y}}=\text{exp}\left( -{{\gamma }_{y}}p \right)t\cdot \left( Z{{L}_{y}}-{{X}_{y}} \right) \\ \end{align}$ (4)
The powers of the red and green channels are increased to γy/γs and γy/γh, respectively:
$\begin{align} & {{\left( T{{X}_{s}}-{{X}_{s}} \right)}^{\frac{{{\gamma }_{y}}}{{{\gamma }_{s}}}}}= \text{exp}\left( -{{\gamma }_{s}}p\frac{{{\gamma }_{y}}}{{{\gamma }_{s}}} \right)\cdot {{\left( Z{{L}_{s}}-{{X}_{s}} \right)}^{\frac{{{\gamma }_{y}}}{{{\gamma }_{s}}}}} ={{e}_{y}}\cdot {{\left( T{{X}_{s}}-{{X}_{s}} \right)}^{\frac{{{\gamma }_{y}}}{{{\gamma }_{s}}}}} \\ & {{\left( T{{X}_{h}}-{{X}_{h}} \right)}^{\frac{{{\gamma }_{y}}}{{{\gamma }_{h}}}}}= \text{exp}\left( -{{\gamma }_{h}}p\frac{{{\gamma }_{y}}}{{{\gamma }_{h}}} \right)\cdot {{\left( Z{{L}_{h}}-{{X}_{h}} \right)}^{\frac{{{\gamma }_{y}}}{{{\gamma }_{h}}}}} ={{e}_{y}}\cdot {{\left( T{{X}_{h}}-{{X}_{h}} \right)}^{^{\frac{{{\gamma }_{y}}}{{{\gamma }_{h}}}}}} \\ \end{align}$ (5)
Let ey(a) be the unknown medium transmission rate of each pixel of the low-light image. Combining formula (5) with formula (3), we have:
$\left[\begin{array}{l}\left(T X_s(a)-X_s\right)^{\gamma_{y s}} \\ \left(T X_h(a)-X_h\right)^{\gamma_{y h}} \\ \left(T X_y(a)-X_y\right)\end{array}\right]=e_y(a)\left[\begin{array}{l}\left(Z L_s(a)-X_s\right)^{\gamma_{y s}} \\ \left(Z L_h(a)-X_h\right)^{\gamma_{y h}} \\ \left(Z L_y(a)-X_y\right)\end{array}\right]$ (6)
The formula of Haze-line is similar to the above formula. Thus, the initial transmission rate and estimation can be completed by clustering pixels into the Haze-line. After estimating XΦ and eΦ(a), ZL(a) can be further enhanced by:
$\begin{align} & ZL\left( a \right)={{X}_{\Phi }}+\frac{TX\left( a \right)-{{X}_{\Phi }}}{\text{exp}\left( -{{\gamma }_{\Phi }}p\left( a \right) \right)} ={{X}_{\Phi }}+\frac{TX\left( a \right)-{{X}_{\Phi }}}{\text{exp}\left( {{\gamma }_{d}}/{{\gamma }_{y}} \right)} \\ \end{align}$ (7)
According to the features of different low-light ambient light sources, multiple effective enhancements of low-light images are selected based on different attenuation coefficients. Next, the low-light image with the smallest difference between the average values of red, green, and blue channels is selected as the effective enhancement result, i.e., the final output.
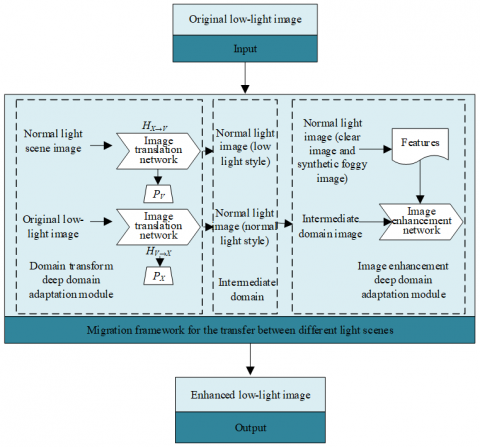
This section details the network framework (Figure 1) of the proposed low-light image enhancement model. The framework realizes the transfer of different light scenes, and includes two depth domain adaptation modules that realize domain transform and image enhancement, respectively. Besides, the authors also introduced the loss functions used by the model.
In the low-light image enhancement model, the domain transform module is to transform the original low-light image into the style of the normal light scene image, while ensuring the structure, the content and other semantic information of the low-light image. Let A be the sample set of low-light images degraded in the real scene; B be the corresponding sample set of normal light images. A and B are imported to the domain transform module. Firstly, the coarse-grained similarity between the low-light images and the normal light images is calculated based on the maximum average deviation distance. Then, the highly similar images are selected and imported to the image translation network. Let Γ( ) be the mapping of the original variable to the regenerated kernel Hilbert space. Then, the maximum average deviation distance can be calculated by:
${{\Omega }^{2}}\left( A,B \right)=\left\| \sum\limits_{i=1}^{{{m}_{1}}}{\Gamma \left( {{a}_{i}} \right)}-\sum\limits_{j=1}^{{{m}_{2}}}{\Gamma \left( {{b}_{i}} \right)} \right\|_{F}^{2}$ (8)
The selected color-enhanced image is input into the image translation network H for domain transform, and the output image is represented by B*. Another image translation network G performs the reverse transform, which converts the translated image A* back to the low-light image B*. In addition, two adversarial discriminators PB and PA are introduced to the low-light image enhancement model. This paper correlates the domain transform of H and G with PB and PA. PB encourages H to convert A to B*, minimizing the difference between B* and B, while PA exerts the opposite effect on G.
The domain transform module can convert the original low-light image A into B*, and the low-light scene style can be changed into the color style of the image in the normal scene while ensuring its basic properties. Y* can be regarded as a normal scene image with the original low-light image content and structure. In Y*, the color shift of the low-light scene is eliminated by the domain transform module, but there is still the problem of poor image visibility due to light scattering. To effectively enhance the clear details of the image, an image enhancement module is set up.
Figure 1. Framework of low-light image enhancement model
The framework of the image enhancement network draws on the dehazing network structure, that is, the traditional encoder-decoder network. Specifically, the synthetic foggy image Bhc and the clear image NSI are constructed in the normal scene. Then, B*, Bhc and NSI are used to train the constructed network. The domain difference between Y* and Bhc must be eliminated to allow the model trained on the Bhc sample set adaptable for low-light image enhancement. This problem is solved by introducing a domain adaptation mechanism, that is, introducing Y* into the training sample set in an unsupervised manner.
In the training of the low-light image enhancement model, two loss functions, the domain transform loss function and the image enhancement loss function, are employed. The domain transformation module includes the adversarial discriminant networks PX and PV, and the corresponding generation networks HV→X and HX→V. The adversarial loss function of HV→X can be expressed as:
$\begin{align} & S{{V}_{GAN}}\left( {{H}_{V\to X}},{{P}_{X}},{{A}_{V}},{{A}_{X}} \right) \\ & ={{T}_{{{a}_{x}}\tilde{\ }{{o}_{data}}\left( {{a}_{x}} \right)}}\left[ \log {{P}_{X}}\left( {{a}_{x}} \right) \right] \\ & +{{T}_{{{a}_{v}}\tilde{\ }{{o}_{data}}\left( {{a}_{v}} \right)}}\left[ log\left( 1-{{P}_{X}}\left( {{H}_{V\to X}}\left( {{a}_{v}} \right) \right) \right) \right] \\ \end{align}$ (9)
HV→X tries to learn to transform the image aq from the low-light scene AV to the intermediate domain AX with the color style of the normal scene image, thereby generating the low-light image av→x. Thus, PX is unable to distinguish av→x from the normal scene image ax. For HX→V,, a similar adversarial loss function SVGAN(HX→V, PV, AX, AV) can be constructed.
To normalize the training of the image translation network, the cycle consistency loss function can be constructed as:
$\begin{align} & S{{V}_{cyc}}\left( {{H}_{V\to X}},{{H}_{X}}_{\to V} \right) \\ & ={{T}_{{{a}_{v}}\tilde{\ }{{o}_{dana}}\left( {{a}_{v}} \right)}}\left[ {{\left\| {{H}_{X\to V}}\left( {{H}_{V\to X}}\left( {{a}_{v}} \right) \right)-{{a}_{v}} \right\|}_{1}} \right] \\ & +{{T}_{{{a}_{x}}\tilde{\ }{{o}_{dana}}\left( {{a}_{x}} \right)}}\left[ {{\left\| {{H}_{V\to X}}\left( {{H}_{X\to V}}\left( {{a}_{x}} \right) \right)-{{a}_{x}} \right\|}_{1}} \right] \\ \end{align}$ (10)
The above formula completes the L1-norm constraint of au and HX→V(HV→X(av)), as well as ax and HV→X(HX→V(ax)). Let av→av→x→ax→v and ax→ax→v→av→x be the forward translation cycle and the reverse translation cycle, respectively. For image av in domain Av, av can be returned to the original low-light image by av→av→x→ax→v; ax can be returned to the original normal scene image by ax→ax→v→av→x.
To effectively enhance all texture information from low-light images, this paper introduces a cycle-aware consistency loss, which combines the extracted high and low features that ensure the original image structure. Let || ||2 be the standard L2-norm; ψ be the feature extractor. Then, we have:
$\begin{align} & S{{V}_{perceptual}}\left( {{H}_{V\to X}},{{H}_{X\to V}} \right) \\ & =\left\| \psi \left( {{a}_{v}} \right)-\psi \left( {{H}_{X\to V}}\left( {{H}_{V\to X}}\left( {{a}_{v}} \right) \right) \right) \right\|_{2}^{2} \\ & +\left\| \psi \left( {{a}_{x}} \right)-\psi \left( {{H}_{V\to X}}\left( {{H}_{X\to V}}\left( {{a}_{x}} \right) \right) \right) \right\|_{2}^{2} \\ \end{align}$ (11)
Further, to ensure the content and structure information between the input and output images of HV→X and HX→V, the following authentication loss function can be adopted:
$\begin{align} & S{{V}_{identity}}\left( {{H}_{V\to X}},{{H}_{X}}\to V \right) \\ & ={{T}_{{{a}_{x}}\tilde{\ }{{o}_{dana}}\left( {{a}_{x}} \right)}}\left[ {{\left\| {{H}_{V\to X}}\left( {{a}_{x}} \right)-{{a}_{x}} \right\|}_{1}} \right] \\ & +{{T}_{{{a}_{v}}\tilde{\ }{{o}_{dana}}\left( {{a}_{v}} \right)}}\left[ {{\left\| {{H}_{X\to V}}\left( {{a}_{v}} \right)-{{a}_{v}} \right\|}_{1}} \right] \\ \end{align}$ (12)
Let μ1 and μ2 be the weights of the component loss functions. The overall loss function of the domain transform module can be given by:
$\begin{align} & S{{V}_{style}}\left( {{H}_{V\to X}},{{H}_{X\to V}} \right) \\ & =S{{V}_{GAN}}\left( {{H}_{V\to X}},{{P}_{X}},{{A}_{V}},{{A}_{X}} \right) \\ & +S{{V}_{GAN}}\left( {{H}_{X\to V}},{{P}_{V}},{{A}_{X}},{{A}_{V}} \right) \\ & +S{{V}_{cyc}}\left( {{H}_{V\to X}},{{H}_{X\to V}} \right) \\ & +{{\Phi }_{1}}S{{V}_{perceptual}}\left( {{H}_{V\to X}},{{H}_{X\to V}} \right) \\ & +{{\Phi }_{\text{2}}}S{{V}_{identity}}\left( {{H}_{V\to X}},{{H}_{X\to V}} \right) \\ \end{align}$ (13)
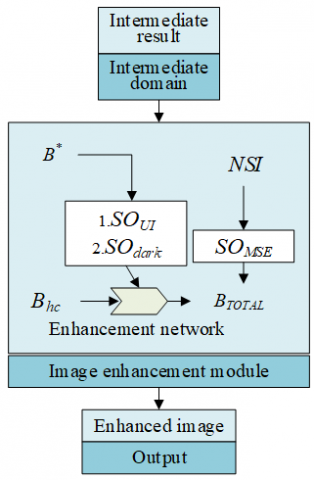
The proposed low-light image enhancement model is trained by a new sample set composed of the enhanced low-light images generated by the domain transform module, and a sample set composed of the synthetic foggy and clear images. For the image enhancement loss function, the standard mean squared error loss function in the supervised branch of the image enhancement model is adopted to minimize the difference between the final output images PKX and BX:
$S{{O}_{MSE}}=\left\| P{{K}_{X}}-{{B}_{X}} \right\|_{2}^{2}$ (14)
To generate enhanced low-light images with the same features as clear images in normal scenes, it is necessary to constrain the dehazing network module in the unsupervised branch of the image enhancement model, which can be achieved by total variational loss and dark channel loss. The total variational loss can be expressed as:
$S{{O}_{UI}}={{\left\| {{\nabla }_{f}}P{{K}_{V\to X}} \right\|}_{1}}+{{\left\| {{\nabla }_{u}}P{{K}_{V\to X}} \right\|}_{1}}$ (15)
Let $\nabla_f$ and $\nabla_u$ be the horizontal gradient operator and the vertical gradient operator, respectively; PKV→X be the translated low-light image; a and b be the coordinates of the low-light image; DCP be the dark channel; DR be the color channel; Θ(a) be the local block centering at a. Then, the dark channel prior can be expressed as:
$DCP\left( a \right)=\underset{d\in s,h,y}{\mathop{min}}\,\left( \underset{b\in \Theta \left( a \right)}{\mathop{min}}\,\left( DR\left( b \right) \right) \right)$ (16)
The dark channel loss function that can achieve regularization of the enhanced low-light image can be expressed as:
$S{{O}_{dark}}={{\left\| DR\left( P{{K}_{V\to X}} \right) \right\|}_{1}}$ (17)
Let μ1 and μ2 be the weights of the component loss functions, respectively. Combining the domain transform loss function and image enhancement loss function, the complete loss function expression of the image enhancement module can be expressed as:
$S{{O}_{TOTAL}}=S{{O}_{MSE}}+{{\mu }_{1}}S{{O}_{UI}}+{{\mu }_{2}}S{{O}_{DCP}}$ (18)
Figure 2 intuitively shows the combined use scheme of the loss functions of the image enhancement module.
Figure 2. Combinatory use of loss functions of image enhancement module
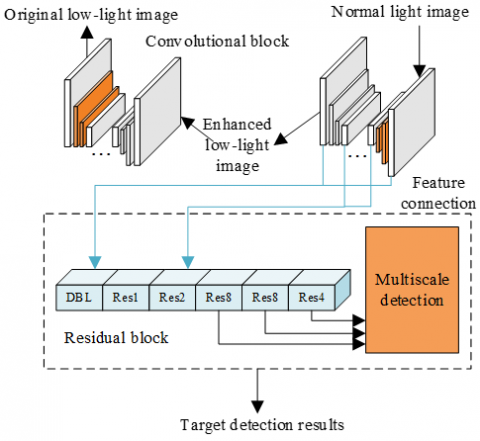
Figure 3. Framework of low-light image joint enhancement and target detection
To realize the target detection based on the output enhanced image, this paper proposes a joint enhancement and target detection method for low-light images. The framework of the method is shown in Figure 3. To effectively improve the accuracy of target detection, the model generates an enhanced low-light image that is beneficial to target detection based on the feature correlation between low-light image enhancement and target detection. The specific process is as follows: input the original low-light image, enhance it through the image enhancement module, and then detect the target in the enhanced low-light image through the low-light image target detection module in the dotted frame in Figure 3, and finally output the detected target.
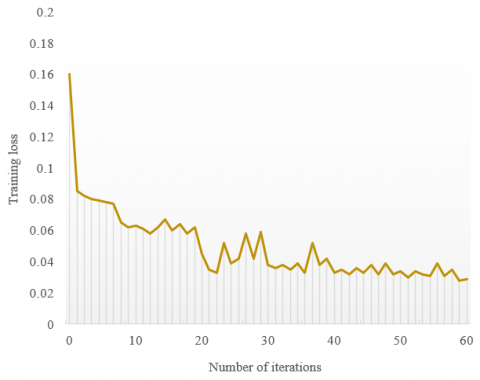
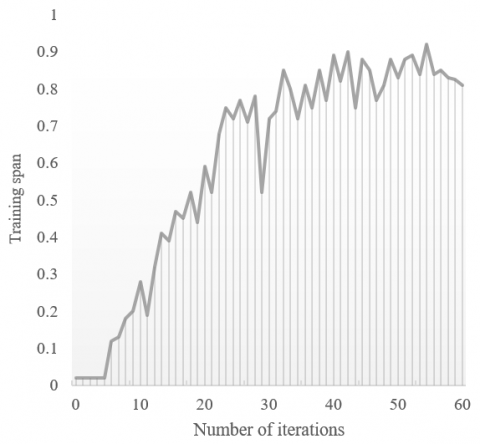
Figure 4. Training loss curve of the low-light image enhancement model
Figure 4 presents the training loss curve of the low-light image enhancement model. It can be seen that the joint loss of the model, which is based on domain transform loss and image enhancement loss, continued to drop from the very beginning of model training, and dropped below 0.03 and gradually tended to be stable, when the number of iterations surpassed 60.
Table 1. Enhancement performance of different models on low-light images with gray cast
|
Model |
Chroma |
Sharpness |
Contrast |
Overall |
|
Original image |
-72.6152 |
6.8574 |
0.7852 |
2.6147 |
|
AHE |
-23.6597 |
7.1529 |
0.8296 |
4.6295 |
|
DCP |
-0.4185 |
6.3825 |
0.8471 |
5.3628 |
|
MSR |
-16.2954 |
6.3417 |
0.8629 |
4.3715 |
|
UWCNN |
-51.3026 |
6.9285 |
0.7142 |
3.1928 |
|
URCNN |
-59.6824 |
6.1054 |
0.7568 |
2.5474 |
|
UWGAN |
1.3052 |
7.6291 |
0.8417 |
4.6281 |
|
MCycleGAN |
-16.3295 |
7.5184 |
0.8962 |
4.0269 |
|
DenseGAN |
-11.2351 |
6.3192 |
0.8136 |
4.1857 |
|
Our model |
0.3958 |
7.5846 |
0.8374 |
5.5961 |
In objective experiments, this paper selects the chromaticity, sharpness, contrast and the comprehensive metric of the three to evaluate the enhancement performance of our model and other typical image enhancement models. Table 1 compares the enhancement performance of different models on low-light images with gray cast. There are 8 reference models, including AHE, DCP, MSR, UWCNN, URCNN, UWGAN, MCycleGAN and DenseGAN. It can be seen from the table that the comprehensive metric of our model was 5.5961, which is higher than that of all reference models. Thus, our model is more competitive than other models in enhancing low-light images with gray cast.
Table 2 compares the enhancement performance of different models on low-light foggy images. It can be seen that the comprehensive metric of our model was 5.6291, which is higher than that of all reference models. Thus, our model is superior to other models in enhancing low-light foggy images.
Table 2. Enhancement performance of different models on foggy images with gray cast
|
Model |
Chroma |
Sharpness |
Contrast |
Overall |
|
Original image |
-31.2547 |
7.4196 |
0.7362 |
3.4127 |
|
AHE |
-12.6025 |
7.3825 |
0.8357 |
4.6285 |
|
DCP |
-1.9583 |
7.1024 |
0.8162 |
5.3291 |
|
MSR |
-14.6589 |
7.6912 |
0.8574 |
4.3172 |
|
UWCNN |
-13.9142 |
7.6384 |
0.8162 |
4.6258 |
|
URCNN |
-11.6029 |
6.2749 |
0.8629 |
4.3182 |
|
UWGAN |
0.6174 |
7.4196 |
0.8475 |
5.1024 |
|
MCycleGAN |
-13.9281 |
7.3281 |
0.8137 |
4.3629 |
|
DenseGAN |
-2.4169 |
7.6129 |
0.8475 |
5.0274 |
|
Our model |
0.8374 |
7.3853 |
0.8927 |
5.6291 |
Table 3. Enhancement accuracy of different models
|
Model |
Mean absolute error (MAE) |
Peak signal-to-noise ratio (PSNR) |
Structural similarity (SSIM) |
|
Original image |
44.6281 |
12.5024 |
0.6152 |
|
AHE |
43.6298 |
11.3629 |
0.7139 |
|
DCP |
45.2741 |
18.3527 |
0.6857 |
|
MSR |
39.6285 |
11.5241 |
0.7152 |
|
UWCNN |
37.5182 |
16.3295 |
0.7269 |
|
URCNN |
41.2057 |
18.5372 |
0.6127 |
|
UWGAN |
33.6985 |
19.4285 |
0.6845 |
|
MCycleGAN |
42.5172 |
16.9472 |
0.6392 |
|
DenseGAN |
49.6157 |
14.3629 |
0.6184 |
|
Our model |
26.9284 |
20.3262 |
0.8247 |
Table 3 compares the enhancement accuracy of different models, using MAE, PSNR and SSIM. It is clear that our model achieved the lowest MAE, and highest PSNR and SSIN. The results further demonstrate the effectiveness and accuracy of our model in image enhancement.
Figure 5 compares the enhancement effects of four models on low-light image samples. The four models are the CNN model based on non-physical model, the CNN model based on physical model, the model based on GAN, and our model. The experimental results correspond to Figures 5-(2), (3), (4), and (5), while Figure 5-(1) is the original low-light image. It can be seen that the CNN based on non-physical model improved the image contrast, but did not solve the image cast well. The CNN model based on the physical model produced artifacts and failed to restore image details well. The image enhanced by the GAN-based model corrected color deviations effectively, but had low contrast and saturation. Compared with these models, our model boasted high sharpness, achieved good overall visibility, and corrected color deviation excellently.
Figure 6 shows the curve of target detection accuracy of our model. It can be seen that the detection accuracy increased with the number of iterations. The accuracy was 0.8 when the target detection module was trained for 30 times, and stabilized at around 0.9 when the module was trained for 55 times. To verify the effectiveness of our joint enhancement and target detection method for low-light images, this paper designs a comparative experiment of target detection performance, using precision, recall and mAP. Table 4 compares the detection performance of different models for fixed targets. It can be seen that most modules can complete the detection task of fixed targets. Our model had clear advantages over the other models in precision, recall, and mAP. The results show that our model can facilitate the target detection in low-light state.
Figure 5. Enhancement effect of four models on low-light images
Figure 6. Curve of target detection accuracy
Table 4. Detection performance of different models for fixed targets
|
Model |
Precision |
Recall |
mAP |
|
Original image |
0.7158 |
0.1968 |
0.7158 |
|
AHE |
0.7036 |
0.1741 |
0.7293 |
|
DCP |
0.7158 |
0.2637 |
0.8274 |
|
MSR |
0.7362 |
0.1495 |
0.7169 |
|
UWCNN |
0.7859 |
0.1131 |
0.7362 |
|
URCNN |
0.7125 |
0.1748 |
0.7519 |
|
UWGAN |
0.7692 |
0.1629 |
0.7865 |
|
MCycleGAN |
0.7185 |
0.1392 |
0.7924 |
|
DenseGAN |
0.7362 |
0.1247 |
0.7368 |
|
AHE |
0.7591 |
0.1495 |
0.7162 |
|
DCP |
0.8358 |
0.2387 |
0.8926 |
|
MSR |
0.8263 |
0.1471 |
0.8674 |
|
Our model |
0.8475 |
0.2519 |
0.8126 |
This paper explores low-light image enhancement and target detection based on deep learning. Firstly, a simplified expression was constructed for the optical imaging model of low-light images, and a Haze-line was proposed for color correction of low-light images, which can effectively enhance low-light images based on the global background light and medium transmission rate of the optical imaging model of such images. Next, network framework adopted by the proposed low-light image enhancement model was introduced in detail: the framework includes two deep domain adaptation modules that realize domain transformation and image enhancement, respectively, and the loss functions of the model were presented. To detect targets based on the output enhanced image, a joint enhancement and target detection method was proposed for low-light images. Through experiments, the authors displayed the training loss curve of the proposed model in training, compared the enhancement performance of different models on low-light images with grey cast, and low-light foggy images, contrasted the enhancement accuracy of different models. The comparisons reflect the effectiveness and accuracy of low-light image enhancement of our model. Further, the enhancement effects of four models on low-light images were compared, revealing that compared with the other models, our model boasted high sharpness, achieved good overall visibility, and corrected color deviation excellently. Finally, the authors obtained the curve of target detection accuracy of our model, and compared the detection performance of different models for fixed targets. The results show that our model can facilitate the target detection in low-light state.
[1] Mangaonkar, S.M., Khandelwal, R., Shaikh, S., Chandaliya, S., Ganguli, S. (2022). Fruit harvesting robot using computer vision. In 2022 International Conference for Advancement in Technology (ICONAT), pp. 1-6. https://doi.org/10.1109/ICONAT53423.2022.9726126
[2] Thiruvathukal, G.K., Lu, Y.H. (2022). Efficient computer vision for embedded systems. Computer, 55(4): 15-19. https://doi.org/10.1109/MC.2022.3145677
[3] Liao, Z., Samuel, R., Krishnamoorthy, S. (2022). Computer vision for facial analysis using human–computer interaction models. International Journal of Speech Technology, 25: 379-389. https://doi.org/10.1007/s10772-021-09953-6
[4] Carpenter, C. (2022). Computer Vision analytics enables determination of rig state. Journal of Petroleum Technology, 74(01): 96-98. https://doi.org/10.2118/0122-0096-JPT
[5] Tang, Y., Qiu, J., Gao, M. (2022). Fuzzy medical computer vision image restoration and visual application. Computational and Mathematical Methods in Medicine, 2022: Article ID 6454550. https://doi.org/10.1155/2022/6454550
[6] Alam, A., Jaffery, Z.A., Sharma, H. (2022). A cost-effective computer vision-based vehicle detection system. Concurrent Engineering, 30(2): 148-158. https://doi.org/10.1177/1063293X211069193
[7] Shukla, R., Kaur, H. (2022). Rural electrification using computer vision and wireless sensor networks. In 2022 2nd International Conference on Intelligent Technologies (CONIT), pp. 1-5. https://doi.org/10.1109/CONIT55038.2022.9848404
[8] Kuang, D., Duan, L.F. (2022). Global patent analysis on computer vision powered crop phenotyping. 12th International Workshop on Computer Science and Engineering, WCSE, pp. 34-39.
[9] Madhusudana, P.C., Birkbeck, N., Wang, Y., Adsumilli, B., Bovik, A.C. (2022). Image quality assessment using synthetic images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 93-102.
[10] Kiruthika, S., Masilamani, V. (2022). Goal oriented image quality assessment. IET Image Processing, 16(4): 1054-1066. https://doi.org/10.1049/ipr2.12209
[11] Palta, H., Karakaya, M. (2022). Image quality assessment of smartphone-based retinal imaging systems. In Smart Biomedical and Physiological Sensor Technology XIV, 12123: 1212302. https://doi.org/10.1117/12.2618834
[12] Yang, X., Wang, T., Ji, G. (2022). Image quality assessment via multiple features. Multimedia Tools and Applications, 81(4): 5459-5483. https://doi.org/10.1007/s11042-021-11788-x
[13] Sim, K., Yang, J., Lu, W., Gao, X. (2021). Blind stereoscopic image quality evaluator based on binocular semantic and quality channels. IEEE Transactions on Multimedia, 24: 1389-1398. https://doi.org/10.1109/TMM.2021.3064240
[14] Wang, G., Wang, Z., Huang, B., Jiang, K., He, Z., Zhu, H., Tian, X. (2022). Two-stage unsupervised facial image quality measurement. Information Sciences, 611: 432-445. https://doi.org/10.1016/j.ins.2022.08.064
[15] Hofbauer, H., Autrusseau, F., Uhl, A. (2022). Low quality and recognition of image content. IEEE Transactions on Multimedia, 24: 3595-3610. https://doi.org/10.1109/TMM.2021.3103394
[16] Jeon, G.L., Kim, H.J., Yeo, E., Kang, J.W. (2022). CNN Based multi-view image quality enhancement. In 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), pp. 372-375. https://doi.org/10.1109/ICUFN55119.2022.9829639
[17] Jin, C., Zhao, X., Xiong, Q., Guo, Y. (2022). Blind image quality assessment for multiple distortion image. Circuits, Systems, and Signal Processing, 1-20. https://doi.org/10.1007/s00034-022-02055-x
[18] Zhao, B., Gong, X., Wang, J., Zhao, L. (2022). Low-light image enhancement based on normal-light image degradation. Signal, Image and Video Processing, 16(5): 1409-1416. https://doi.org/10.1007/s11760-021-02093-z
[19] Panguluri, S.K., Mohan, L. (2021). A DWT based novel multimodal image fusion method. Traitement du Signal, 38(3): 607-617. https://doi.org/10.18280/ts.380308
[20] Kim, W. (2022). Low-light image enhancement: A comparative review and prospects. IEEE Access, 10: 84535-84557. https://doi.org/10.1109/ACCESS.2022.3197629
[21] Prakash, S.J., Chetty, M.S.R., Aravapalli, J. (2022). Swarm based optimization for image dehazing from noise filtering perspective. Ingénierie des Systèmes d’Information, 27(4): 653-658. https://doi.org/10.18280/isi.270416
[22] Nie, X., Song, Z., Zhou, B., Wei, Y. (2022). LESN: Low-light image enhancement via siamese network. In The International Conference on Image, Vision and Intelligent Systems (ICIVIS 2021), pp. 183-194. https://doi.org/10.1007/978-981-16-6963-7_17
[23] Wang, TM., Shen, H.W., Xue, Y.J., Hu, Z.K. (2020). A traffic signal recognition algorithm based on self-paced learning and deep learning. Ingénierie des Systèmes d’Information, 25(2): 239-244. https://doi.org/10.18280/isi.250211
[24] Vrtagić, S., Softić, E., Ponjavić, M., Stević, Ž., Subotić, M., Gmanjunath, A., Kevric, J. (2020). Video data extraction and processing for investigation of vehicles’ impact on the asphalt deformation through the prism of computational algorithms. Traitement du Signal, 37(6): 899-906. https://doi.org/10.18280/ts.370603
[25] Wang, X., Hu, R., Xu, X. (2022). Single low-light image brightening using learning-based intensity mapping. Neurocomputing, 508: 315-323. https://doi.org/10.1016/j.neucom.2022.08.042
[26] Xu, K., Chen, H., Xu, C., Jin, Y., Zhu, C. (2022). Structure-Texture aware network for low-light image enhancement. IEEE Transactions on Circuits and Systems for Video Technology, 32(8): 4983-4996. https://doi.org/10.1109/TCSVT.2022.3141578
[27] Lu, Q., Gan, P. (2022). Low-light face recognition and identity verification based on image enhancement. Traitement du Signal, 39(2): 513-519. https://doi.org/10.18280/ts.390213
[28] Xu, X., Wang, S., Wang, Z., Zhang, X., Hu, R. (2021). Exploring image enhancement for salient object detection in low light images. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 17(1s): 1-19. https://doi.org/10.1145/3414839