Praveen Kumar Yechuri* | Suguna Ramadass
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The advent of social networking and the internet has resulted in a huge shift in how consumers express their loyalty and where firms acquire a reputation. Customers and businesses frequently leave comments, and entrepreneurs do the same. These write-ups may be useful to those with the ability to analyse them. However, analysing textual content without the use of computers and the associated tools is time-consuming and difficult. The goal of Sentiment Analysis (SA) is to discover client feedback, points of view, or complaints that describe the product in a more negative or optimistic light. You can expect this to be a result based on this data if you merely read and assess feedback or examine ratings. There was a time when only the use of standard techniques, such as linear regression and Support Vector Machines (SVM), was effective for the task of automatically discovering knowledge from written explanations, but the older approaches have now been mostly replaced by deep neural networks, and deep learning has gotten the job done. Convolution and compressing RNNs are useful for tasks like machine translation, caption creation, and language modelling, however they suffer from gradient disappearance or explosion issues with large words. This research uses a deep learning RNN for movie review sentiment prediction that is quite comparable to Long Short-Term Memory networks. A LSTM model was well suited for modelling long sequential data. Generally, sentence vectorization approaches are used to overcome the inconsistency of sentence form. We made an attempt to look into the effect of hyper parameters like dropout of layers, activation functions and we also tested the model with different neural network settings and showed results that have been presented in the various ways to take the data into account. IMDB is the official movie database which serves as the basis for all of the experimental studies in the proposed model.
LSTM, IMDB, Sentiment Analysis (SA), Natural Language Processing (NLP)
The sentiment analysis extracts the work of text and mood extraction for users, revealing users' ideas on issues, but it may also capture people's thoughts on themes [1]. Nowadays, expressing specific emotions or experiences about a specific product, presenting a product, or communicating with people about a specific individual is extremely simple and quick [2]. To express the "don't steal" or "don't cheat" have a significant impact on internet such as message boards, social media such as Facebook, utilised as an instrument for transmitting these thoughts [3].
Many people are still inquisitive about the existence of a product consumer before they cast their votes [4]. Rather than language parts, in fact. Natural language processing (or NLP) is concerned with text segment processing. An NLP is used to process the text in order to generate an Abstract in Expanded format [5]. The artificial intelligence process takes a large amount of knowledge provided by NLP [6] and then applies various mathematical formulas to determine whether or not there is anything to uncover the perspective of a given issue using natural language tools such as article text mining and search engine technology [7]. Modes of machine learning that place little or no focus on dependability or scalability are rarely used. Sentiment analysis is one type of natural language processing that focuses on how people feel about something or someone [8].
The researchers discovered that by mining consumer opinions, a corporation may also watch how customers interact with the service or product and determine how their attitude toward it has evolved. includes the branch of computational linguistics known as opinion mining, which is concerned with the examination of online media for the extraction, appraisal, and comprehension of opinions expressed in that type of media opinions [9], approaches, methodically explores for people's views [10], works to uncover problems, methodically studies and how people react to topics or personalities, and then records what is learned [11]. Because we behave based on what we believe to be right and wrong judgments about others, our behaviours are significant.
Several sorts of input sentence assessment approaches for distinguishing between sentences in natural languages that were intended to determine whether they were personal feelings or rational impressions were published [12]. Sentiment analysis aids in the collection of data on both positive and negative aspects in all circumstances. It is advised to the consumer to purchase from a source that will only supply consumers with positive comments about the goods as well as an individual and his services. to gain or increase revenues through perception mining [13].
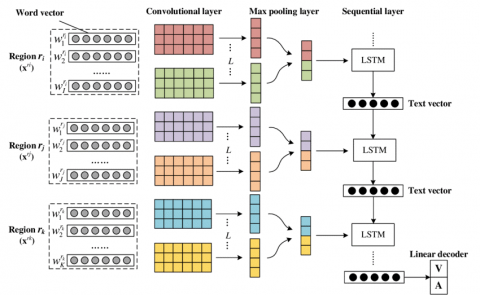
Sentiment research is very useful in business because it helps to determine how people feel about goods and services, as well as the company's goodwill [14]. Despite the fact that product features are given in the handbook, determining the root reasons of low profitability is dependent on consumers focusing on the evaluation process that goes on specific components. Furthermore, firms can analyse client sentiments to determine the types of expansion and product changes that may occur in the future. The Figure 1 represents the LSTM model on IMDB dataset.
Figure 1. LSTM on IMDB dataset
Usage studies in social media usually focus on detecting thoughts, affects, emotions, and subjectivities in text, while they often look at other factors such as the numbers of subjects or online audiences [15]. These earlier techniques include searching for the characteristics of a commodity and then analysing the sentiments of the customers who bought it. To state that no to increased political involvement or generalize to be, however, several other fields besides the political participation are connected to feelings and biases, for instance the usage of sentiment polarity in finance [16].
SA is concerned with analysing text containing statements that are geared toward particular actions or the words that show subjective or emotional intent with specific words or merely through adding positive or negative ones to its already known words [17]. In its scope, sentiment description includes a multitude of activities, features, even those that range from basic to difficult, features to masterful, a variety of applications, and stuff. Many classification tasks may be used to analyse the sentiment of text data including examining its separation or variation [18]. There are two basic classes of people: those who care deeply and those who hardly give a basic feedback.
To register attitudes, SA first assesses a writer's knowledge of a subject as well as the user's state of mind on that issue. People's decisions are influenced not only by what they believe and say, but also by what they feel and how they feel [19]. In social theory, differences such as phrase, paper, and so on. The graphic shows two types of emotional states of sentiments: "happy" and "sad." The overarching goal of opinion mining is to detect and mark separation [20]. Depending on the degree of separation, this piece of writing could state a single point of view or two conflicting points of view and be interpreted as two separate things [21].
Chomsky proposes two primary ideas regarding how language is classified in the mind: one that involves idea detectors looking for characteristics or structural dimensions, and the other that focuses on syntactic and semantic dimensions [22, 23]. The consideration sets of text documents for agreement identification of specificity determine whether they can be considered the same or separate [24]. After determining the separation, the computer may categorise [positives and negatives] on a scale of plus to minus. Classifiers, which classify multimedia resources based on their mood and emotional information for the goals of human-machine engagement, troll-cutting, and cyber-suppression, such as feeling and impact on products [25], are another important role in Natural Language Processing. Once the positive and negative characteristics have been determined, an overall summary is created. Design elements, distinguishing ingredients, and other product qualities are examples of features.
Information is available in a variety of formats, including compact data, streaming data, and enormous data. Natural language is a rich and challenging language to discover, making it difficult to get knowledge from bits and requiring a user to decide if it can be interpreted favourably or negatively, knowing that words can have either a positive or negative emotion [26]. It is common practise to separate common written language using the emotion lexicon. When researching/considering, an adjective is more essential because it contains more detail and meaning [27]. One should look at the challenges from a different aspect and from a different object's approach or perspective. Furthermore, issues should be identified on an entity and approach [28].
The grammar of a sentence can be discovered by breaking it down into constituent terms and analysing the relationship between these words [29]. This is an important study for NLP as well as extensive analysis studies are underway to discover the solution to this results that may be miserable if the same classifier is used in another domain [30]. If the content can have a specific place in one or more domains, the sentiment is conveyed in various ways [31]. Sentiment research is very much related to the sphere of language learning [32]. If a topic is to be addressed is a classifier that is capable of storing and processing text effectively, it has to do all of these things. The algorithm used in this paper is an LSTM model. Additionally, on IMDB dataset, the model is modelled. For the rest of the document, the structure is laid out as follows as is Section-2 presents a literature review, section-3 highlights the suggested model, section-4 discusses the implications and conclusion is the end of the article.
Ye et al. [1] used a comprehensive approach to online user-generated content in addition to a quantitative analysis. Customer ratings were decomposed into five components using emotion analysis by the author to measure the quality of hotel service. The impact on users' overall assessment and content generating behaviour was examined using econometric models. The FRN method for emotion classification in online reviews was developed and applied by Duan et al. [3]. Blogs and social media have been pioneered by the author in their use to gather viewpoints.
Emotion polarity may be identified, among other things, using machine learning approaches combined with linguistic information. Since this method may be used to analyse sentiment in any type of online data, it's widely useful. According to the author, the role of subjective and emotion classification at the aspect stage could benefit from the application of more recent and nuanced natural language processing (NLP) principles.
Research was carried out by Hemalatha et al. [4] on the information infrastructure recently installed as a real innovation in a leading Swedish mountain tourism destination. Using big data analysis in the tourist business, his research focuses on the processes that occur before and after a trip. Marrese-Taylor et al. [5] focused on algorithms for extracting and mining product feedback opinions using supervised learning. He describes phrase-level opinion mining in his research. He used highly precise supervised learning algorithms to determine the emotional orientation of each piece of customer input. The emphasis has been on examining the aspects of products that matter to customers.
A study by Fuchs et al. [6] looked into how nostalgic reviews may be classified using machine learning approaches. The data was classified using the Naive Bayes and Support Vector Machine techniques. The author used the polarity movie dataset to train and evaluate a model, and the results were compared for a thorough study. At the review step, a negative binomial regression model was proposed by Jeyapriya and Selvi [7] to study the outcomes of real feedback. He did not, however, go into detail about how he retrieved new data over multiple time intervals using a fixed impact model. In this study, two conclusions were found to be of primary value: the perceived utility of feedback, and the importance of evaluations that convey strong feelings.
For e-commerce suggestion, Tripathy et al. [8] looked at the application of emotion analysis to examine online product ratings. In order to make this information more widely available, the author has added a new product to the mix. The investigation shows that the Naive Bayes classifier outperforms other classification algorithms by using an effective strategy. SAAS online feedback mood was predicted using controlled machine learning approaches by Fang et al. [9]. The author conducted research into how customers feel about cloud storage services. As a result of this research, models were developed to predict the mood of customer reviews of SaaS products. To predict the attitude of SaaS reviews, he used five methods: the support vector machine, the Naive Bayes, the Navie Bayes(kernel), the k-nearest neighbours, and the decision tree algorithms were all proposed.
Mali et al. [10] mentioned and explored utilizing machine learning techniques, the online feedback of customers on Twitter about electronic goods such as cell phones, laptops, and so on. The author made an attempt to approximate Twitter messages, retrieved smartphone tweets from Twitter, and pre-processed the tweets. The likelihood of optimistic tweets was estimated using naive Bayes and SVM. Alkalbani et al. [11] discovered a correlation between consumer opinion and hotel online customer reviews. A study was conducted to determine the consistency of consumer reviews and real customer feelings between hotels classified as luxury or budget. As opposed to luxury hotels, the author discovered that personnel morale and hotel facilities can increase, and additional variables such as consumer review duration and review title sentiment may be analyzed.
Nave Bayes and Decision Tree methods based on emotion analysis of flipkart customer comments were proposed by Upadhyay and Singh [12]. Flipkart's retailers and product review feedback have been the key focus, and this illustrates both the buyer's pessimistic and optimist views. The semantic content of customer feedback was studied empirically to make a distinction between the two. The author proposed a hybrid approach that used a decision tree and a naive bayes algorithm to classify the replies. Kaur and Singla [13] looked examined the difficulties of utilising sentiment analysis to examine hospitality and tourism outcomes. Significant contradictions in the hotel industry's image have been uncovered by the author.
The study by Xiang et al. [14] found negative remarks and attitudes about tourism in tourists' internet reviews. For post hoc research to determine why visitors have bad feelings about transportation services, he focused on one form of transportation and noted a low degree of service efficiency. Reminiscent research was used by Kim et al. [15] to examine how customers rank hotels on the internet. A correlation study was done to see if there was a link between online input from customers and hotel customer ratings. Consumer sentiment has been polarised into two categories: premium and budget. This polarity explains a large amount of variation in customer ratings. As demonstrated in this work, the naïve Bayes algorithm fails to detect concealed emotion.
In his dissertation, Geetha et al. [16] studied sentiment analysis methodologies and instruments. In writing obtained on social networking sites and at www., the author expressed both positive and negative thoughts, feelings, and evaluations. The algorithms used machine learning and vocabulary-based semantic algorithms. Consequently, an investigation into the different sentiment analysis methods and equipment was carried out. Ensemble techniques to deep learning sentiment analysis in social applications were described by Kumari et al. [17]. The author looked into mixing deep learning tactics with more traditional surface methods that rely on manually acquired features in order to increase the efficiency of the former.
Using attribute level research, Araque et al. [18] predict client purchasing intentions for long-lasting commodities. In order to provide customers with the best e-commerce platform, the company developed an attribute-level decision support prediction model. A regression analysis suitable for and attribute has been defined by the author in order to forecast the most relevant product characteristics. Customers will be able to get their desired sturdy products in an adorable shape thanks to this research, which will help vendors selling e-commerce goods. Using machine learning and semantic emotion analysis-based methods, Birjali et al. [20] forecast suicidal emotions in social networks.
The research is focused on a difficult background, namely on the sentiments associated with suicidal ideation. Experiments show that this approach, which is built on a machine learning algorithm and semantic sentiment analysis, is capable of extracting predictions of suicidal ideations from Twitter info. Elmurngi and Gherbi [21] discussed the reputations framework and the reasons that adversely affect consumers' and vendors' perceptions of the reputations system. The author conducted a study of online movie reviews utilizing emotion analysis techniques in order to identify false reviews.
Fan et al. [22] examined the concept of commodity revenue forecasting in detail, using online feedback and historical sales results. The author accomplished this goal by the usage of the Bass model and emotion analysis. For the purpose of predicting product prices, sales statistics and online review data are compiled. Soumya [23] addressed consumer opinions online by using product reviews data from the Hadoop platform. The data are gathered from amazon.com and consists of both text and emoticons. Although sentiment analysis often considers just text, the author included both in this article. Wankhede and Kumar [24] summarized different perspectives on web goods and organizations. He addressed output accuracy by conducting an online survey to elicit users' feelings and viewpoints, and he also shed some light on sentiment analysis in today's networking and social sectors.
The LSTM would be able to discover dependencies that are kept over large term periods of time. The dynamic LSTM/LBU device fixes the gradient issues. A LSTM model contains less nodes, but is functionally similar to larger networks that are arranged in a specific fashion. Constant error mode is called a Constant Error Carousel (CEC) if its errors are inter-linked with the other mechanism's weight. When you increase or decrease the width of the interval of your period, you will move forward or fall behind your target times. The phasing in of the CEC has two roles: first is the introduction of the recollection for past experience and the identity of the mental condition that leads to it and second one is multiplicative unit. Standard LSTMs have shown to be able to be better at modelling long-term dependencies than Recurrent Neural Networks (LSTMs) (Figure 2).
Figure 2. LSTM
Because the network becomes unmanageable, the LSTM will have no idea where it began or where it will end up. When it comes to deciphering the results' cycles or sequences, a model will struggle. To avoid having to reset the LSTM, the input sequences should be sorted and matched with the associated state sequences. When the LSTM reaches the end of a sequence, it should automatically update its contents and begin working on a new one until its mechanisms fail. Modern solutions like LSTMs have been introduced as a result of this to help solve the issue.
As well as new designs that lead to comparable conclusions [21], numerous more LSTM design alterations have been proposed [22]. Because we need to use LSTMs in this project, the LSTM expanders are the preferable choice. We'll be able to delve more into this after learning more about the overall design. The Gates must be forgotten. Vectors connect the incoming data to each neuron, making this possible. This LSTM's major properties include combining an input vector (xt) with the previous output vector (h1t-1a) to form a new output vector (ht1) that is then denoted by the time denotations h1t-1a. When the weighted inputs are multiplied and then transferred via the tanh activation, the result is provided by Zt activation.
$z_{t}=\tan h\left(W^{z} x_{t}+R^{z} h_{t-1}+b_{z}\right)$ (1)
When you read from the weight-expanded registers, you'll get results that are mapped to x and -1 rather than the unweighted ones. A sigma activation value is derived from these. Input to the memory is provided as an additional task as part of the job's output through compounding.
$i_{t}=\sigma\left(W^{i} x_{t}+R^{z_{i}} h_{t-1}+b^{i}\right)$ (2)
Forgetfulness is the task that an LSTM goes through to accomplish while keeping memory contents that are no longer relevant and which results in being unable to keep the LSTM active. this may be anything like, for example, the network is only about to go online with a new set of broadcasts the forget gate processes x'th, which inactivates weighted inputs using a sigmoidal cross-activation. When the contents no longer need to be retained, the brain capacity, or cell age is compounded by the original size, i.e.g., one (i.e.i. 1), and hence one may expand or contract while the other shrinks.
$f_{t}=\sigma\left(W^{f} x_{t}+R^{f} h_{t-1}+b_{f}\right)$ (3)
CED is constructed from continuous epidermal cell layer cells that has a weight and edge frequency of one-time repetition for the present cell condition, we don't need to concern ourselves about details that have already passed, and concentrate on only on crucial knowledge that is occurring at the moment.
Xt and1 times the amount of long-short time memory units out of the LSTM's state, HTM and labelling each unit with a specific performance probability in a weighted xt and computes an LSTM with each state.
$o_{t}=\sigma\left(W^{o} x_{t}+R^{o} h_{t-1}+b^{o}\right)$ (4)
Performance of the LSTM unit (ht) is calculated by passing the cell state (st) through a tanh and multiplying it by the LSTM unit's output gate. The following set of equations can be used to derive an LSTM unit's function expression.
$s_{t}=z_{t} \odot i_{t}+s_{t-1} \odot f_{t}$ (5)
$h_{t}=\tan h\left(s_{t}\right) \odot o_{t}$ (6)
The network's core design in this study is split into three layers: an input layer, a secret (LSTM) layer, and an output layer. In the secret layer and the output layer, additional layers such as a completely linked layer and a collapse layer may be used. Depending on the assignment and the data, two separate target coding systems, a normal and a probabilistic target coding scheme, are implemented and enforced.
3.1 Input layer
The LSTM networks, as other DL methods, obtain raw word values as data; the text may be sentence or words, texts are used as input here. The input may be a single word (n = 1) or a window (n > 1). When the input is a single word, each iteration would have a very long series of whole words to remember. In the worst-case scenario, LSTM would bear the contextual knowledge of whole words in order to learn dependencies. Though the problem of long-term dependencies is alleviated in LSTM (when opposed to RNNs), Hoch Reiter discovered that LSTM can only learn to bridge across 1000 distinct measures [HBFS01]. Since adjacent words in a text, particularly those with a high vocabulary, appear to have similar values, dependencies within the words may be redundant. Based on this theory, the window-input is used depending on the mission and the text quality. Each window can be thought of as a super-word. This super-word-input incorporates the local similarity of the words while maintaining the text's global coherence.
As texts of high resolution and accuracy are available, the window-input integrates the local background and decreases the total distinct input measures. It aids in both localizing the region and maintaining long-term dependencies without sacrificing global meaning. Furthermore, the window-input accelerates the inference mechanism. Since specific positioning is not needed as an output for classification, the window-input is successful regardless of the text resolution. The window-input at the top, on the other hand, influences the scale of the segmentation's final output1. This problem is easily solved by upscaling using an interpolation process, such as cubic interpolation.
As a consequence, the problem has no impact on the final figures. However, if the overall input size is small enough, word-level input is always preferable since it offers more accurate output location than interpolation output. Another problem with window-input in segmentation is that in a standard error computation, one window-input with several words is contrasted to one target mark, implying that a single label from these words should be chosen. To address this problem, text is broken into a line, which can be thought of as non-overlapping windows, to receive windows from the input. Initially, both overlapping and non-overlapping window-input were checked, and it was discovered that the latter worked almost as well as the former, but faster.
3.2 Unnoticed layer
LSTM memory blocks are the primary components of opaque layers. In addition, completely linked layers may be added as an alternative for deeper networks.
3.3 Layer LSTM
The final parts go into the specifics of an LSTM layer (mainly in Section 3.2and 3.3). Each LSTM memory block is computed in both directions until the output activations are compiled into a single final output for transmission to the next sheet. This layer may be stacked hierarchically to create a more complex model.
3.4 Layer fully connected
This layer is completely connected to a nonlinear activation mechanism. The hyperbolic tangent combines and squashes the performance of the relations (tanh). According to Graves [Gra12], this layer aids in controlling the amount of weights for the next layer. It also monitors (primarily increases) the number of features in the LSTM layer results and offers a better knowledge flow to the next layer. This layer is particularly useful when dealing with complicated input and deeper networks.
3.5 Collapse layers in output layers
This class of classification methods is at the text stage of the text. The key idea originator is Graves [Gra84], but this concept has not been applied until now. A word has its own estimate. A single class text is needed. Because of this, all of these forecasts can be lumped together as belonging to a common class. mainly used for incorporating all of the input words or windows' projections into one output. This appears at the same time as the secret layer and the classifier. Both activations are applied to the topmost sheet. Any of the resulting texts would be the number of all the word values (input).
$n=\sum_{t=1}^{T} P_{t}$ (7)
where, T denotes the input length, p denotes the secret layer output, and denotes the final activation vector.
3.6 SoftMax layer
Finally, the activations from the last sheet, which are provided as activities, are fed to a SoftMax layer Pr(wi, c), Pr(cl|c1|3) =SoftMax, Pr(1|c2|c,wi) =SoftMax, Pr(2|1|c,wi)=Infinity (M).
This layer would have an output that has been determined by the SoftMax normalization.
$E=-\sum_{c=1}^{c} Z_{c} \ln \operatorname{Pr}\left(c \mid w_{i}\right)$ (8)
L is the class of which a wi is being mapped, wi is the predefined goal range, and a (underneath) is the data. For text-level classification, it is an input text, while for word-level classification, it is a word/window. The layers of the LSTM model are represented in Figure 3.
We want to find the most effective methods for all our trainings. objective functions (such as the cross-entropy function or the squared error function) may be used to measure failure in subsequent parts, the cross-entropy function would be used extensively.
$E=-\sum_{c=1}^{c} \frac{f_{c}}{n X n_{i}} \ln \operatorname{Pr}\left(c \mid w_{i}\right)$ (9)
[0,1] is a real, z is an integer in the classification space corresponding to the target class the accurate goal vector is created by taking 1 as the likelihood for the target class, and all others as 0. Fc is the unit's incidence as a fraction in all classes. Creative goal coding: Products as a standard target Since the Pr(c|wi) probabilities can be transformed into desired classifications or classifications equal to the error threshold, class conditional likelihood (A1-of-of-K) is also used. the positive values set to 1 and all the negative values set to 0.
Figure 3. Proposed model layers
Certain features and rules are used to test the effectiveness of machine learning, and even semi-supervised algorithms, although a well-known combination of features or tool called the confusion matrix or contingency table can also assist in this. The two groups that receive different tests would be described according to “True Positive,”, “False,” or “False,” identification (diagnostic tests provide answers.” in favor of “Class results,” for example: TP, Negative and “answers.
The machine's True Positive Feedback reflects the amount of positive feedbacks and False Feedback whereas the Negative Feedback is the number of classifications considered as positive. In this instance, the "True Negative" reviews reflect the ones that were already known to be negative, while "False negative" reflects those that did not already have the expected negative results, i.e.e. "non-negative" reviews.
Dataset of IMDB movie reviews contains binary ratings for 50,000 reviews from IMDB (Internet Movie Database) and is categorised as either positive or negative. There is an equal amount of favourable and unfavourable evaluations in the database. Unlabelled data can be found in the dataset as well. The polarity dataset contains 12,500 positive and 12,500 critical film feedback from the site film data base, each document containing an average of 30 sentences. The precision rate of the proposed model is calculated as
Precision = TruePositives / (TruePositives + FalsePositives)
Precision is described as the number of true positives divided by the total number of true positives and false positives in an imbalanced classification problem of two groups. Precision equals (True positives + False Positives) / (True Positives + False Positives). Here Figure 4 describes precession between LSTM model and TF-IDE models. The graph drawn between number of ephos on x-axis and precession is taken on y-axis. And the graph describes that proposed LSTM model performs better compared to TF-IDF model clearly. Almost LSTM produces more than 0.98 precession where as TF-IDE model produces around 0.95. The recall of the model is calculated as
Recall = TruePositives / (TruePositives + FalseNegatives)
Figure 4. Precision
Figure 5. Recall
Recall is a statistic that quantifies the proportion of accurate positive predictions produced out of all possible positive predictions. In contrast to accuracy, which only considers the right positive predictions out of all positive predictions, recall considers missing positive predictions. In this manner, recollection gives some indication of the optimistic class's coverage. Recall is measured as the number of true positives separated by the overall number of true positives and false negatives in an imbalanced grouping issue of two groups. TruePositives / (TruePositives + FalseNegatives) = Recall. Here Figure 5 represents the recall between existing TF-IDF model and proposed LSTM model. The graph drawn between number of ephos on x-axis and recall is taken on y-axis. And the graph describes that proposed LSTM model performs better compared to TF-IDF model clearly. Almost LSTM produces more than 0.92 recall where as TF-IDE model produces around 0.89.
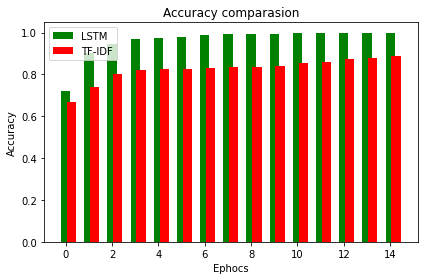
Figure 6. Accuracy
Accuracy is a measure that can be used to evaluate classification models. Informally, accuracy refers to the percentage of correct predictions made by our model. Accuracy is described as follows: Accuracy=number of correct predictions/total number of predictions. Here Figure 6 represents the accuracy between existing TF-IDF model and proposed LSTM model. The graph drawn between number of ephos on x-axis and accuracy is taken on y-axis. And the graph describes that proposed LSTM model performs better compared to TF-IDF model clearly. Almost LSTM produces more than 0.98 accuracy whereas TF-IDE model produces around 0.88.
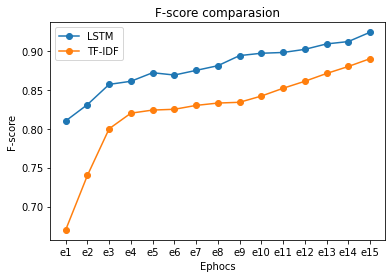
Figure 7. F-score
Classification accuracy is commonly used since it is a standardized metric for evaluating model results. F-Measure enables the simultaneous measurement of accuracy and recall in a single measure. Neither accuracy nor recollection, by themselves, say the whole tale. We may have outstanding accuracy but poor memory, or vice versa. The F-measure enables the expression of all issues with a single ranking. After calculating precision and recall for a binary or multiclass classification query, the two scores may be used to determine the F-Measure. The conventional F value is as follows: F-Measure = (Precision + Recall) / (2 * Precision * Recall). Here Figure 7 represents the F-score between existing TF-IDF model and proposed LSTM model. The graph drawn between number of ephos on x-axis and f-score is taken on y-axis. And the graph describes that proposed LSTM model performs better compared to TF-IDF model clearly. Almost LSTM produces more than 0.98 f-score whereas TF-IDE model produces around 0.89.
Figure 8. Loss
Figure 9. Image classification accuracy
Mean Squared Error (MSE) is somewhat close to Mean Absolute Error (MAE), with the exception that MSE is calculated by averaging the square of the discrepancy between the initial and expected values. The benefit of MSE is that it is simpler to calculate the gradient than Mean Absolute Error, which uses complex linear programming methods. As we take the square of the mistake, the impact of larger errors becomes more pronounced than the effect of smaller errors, and therefore the model will now place a greater emphasis on larger errors. Here Figure 8 represents the loss or error between existing TF-IDF model and proposed LSTM model. The graph drawn between number of ephos on x-axis and loss is taken on y-axis. And the graph describes that proposed LSTM model has very little bit of loss value compared to TF-IDF model clearly. Almost LSTM is at 0.01 loss whereas TF-IDE model produces around 1.2. The image classification accuracy levels of the proposed and traditional models are represented in Figure 9.
Since sentiments greatly affect our lives, it is likely to hear what other people think so that we will be in situations in which we are expected to make choices. To work with that kind of data sequential models are required that store words in RNN-based methods that include recurrent-taught models, such as texts that can be memorize. In this article, we demonstrated the value of deep learning based LSTM model on text data. To conduct sentiment analysis, storing of vocabulary plays important role, LSTM is one such model to make text classification in a far better than existing model. Experimental results show that proposed LSTM model performed better than state of art models.
[1] Ye, Q., Zhang, Z., Law, R. (2009). Sentiment classification of online reviews to travel destinations by supervised machine learning approaches. Expert Systems with Applications, 36(3): 6527-6535. https://doi.org/10.1016/j.eswa.2008.07.035
[2] Guzmán de Núñez, X.M., Núñez-Valdez, E.R., Pascual Espada, J., González Crespo, R., García-Díaz, V. (2018). A proposal for sentiment analysis on twitter for tourism-based applications. In New Trends in Intelligent Software Methodologies, Tools and Techniques, pp. 713-722. https://doi.org/10.3233/978-1-61499-900-3-713
[3] Duan, W., Cao, Q., Yu, Y., Levy, S. (2013). Mining online user-generated content: Using sentiment analysis technique to study hotel service quality. In 2013 46th Hawaii International Conference on System Sciences, pp. 3119-3128. https://doi.org/10.1109/HICSS.2013.400
[4] Hemalatha, I., Varma, G.S., Govardhan, A. (2013). Sentiment classification in online reviews using FRN algorithm. IET Chennai Fourth International Conference on Sustainable Energy and Intelligent Systems (SEISCON 2013), pp. 357-362. https://doi.org/10.1049/ic.2013.0338
[5] Marrese-Taylor, E., Velásquez, J.D., Bravo-Marquez, F. (2014). A novel deterministic approach for aspect-based opinion mining in tourism products reviews. Expert Systems with Applications, 41(17): 7764-7775. https://doi.org/10.1016/j.eswa.2014.05.045
[6] Fuchs, M., Höpken, W., Lexhagen, M. (2014). Big data analytics for knowledge generation in tourism destinations–a case from Sweden. Journal of Destination Marketing & Management, 3(4): 198-209. https://doi.org/10.1016/j.jdmm.2014.08.002
[7] Jeyapriya, A., Selvi, C.K. (2015). Extracting aspects and mining opinions in product reviews using supervised learning algorithm. In 2015 2nd International Conference on Electronics and Communication Systems (ICECS), pp. 548-552. https://doi.org/10.1109/ECS.2015.7124967
[8] Tripathy, A., Agrawal, A., Rath, S.K. (2015). Classification of sentimental reviews using machine learning techniques. Procedia Computer Science, 57: 821-829. https://doi.org/10.1016/j.procs.2015.07.523
[9] Fang, B., Ye, Q., Kucukusta, D., Law, R. (2016). Analysis of the perceived value of online tourism reviews: Influence of readability and reviewer characteristics. Tourism Management, 52: 498-506. https://doi.org/10.1016/j.tourman.2015.07.018
[10] Mali, D., Abhyankar, M., Bhavarthi, P., Gaidhar, K., Bangare, M. (2016). Sentiment analysis of product reviews for E-commerce recommendation. International Journal of Management and Applied Science, 2(1): 127-130.
[11] Alkalbani, A.M., Ghamry, A.M., Hussain, F.K., Hussain, O.K. (2016). Predicting the sentiment of SaaS online reviews using supervised machine learning techniques. In 2016 International Joint Conference on Neural Networks (IJCNN), pp. 1547-1553. https://doi.org/10.1109/IJCNN.2016.7727382
[12] Upadhyay, N., Singh, A. (2016). Sentiment analysis on twitter by using machine learning technique. Int. J. Res. Appl. Sci. Eng. Technol.(IJRASET), 4(5): 488-494.
[13] Kaur, G., Singla, A. (2016). Sentimental analysis of Flipkart reviews using Naïve Bayes and decision tree algorithm. International Journal of Advanced Research in Computer Engineering & Technology, 5(1): 148-153.
[14] Xiang, Z., Du, Q., Ma, Y., Fan, W. (2017). A comparative analysis of major online review platforms: Implications for social media analytics in hospitality and tourism. Tourism Management, 58: 51-65. https://doi.org/10.1016/j.tourman.2016.10.001
[15] Kim, K., Park, O.J., Yun, S., Yun, H. (2017). What makes tourists feel negatively about tourism destinations? Application of hybrid text mining methodology to smart destination management. Technological Forecasting and Social Change, 123: 362-369. https://doi.org/10.1016/j.techfore.2017.01.001
[16] Geetha, M., Singha, P., Sinha, S. (2017). Relationship between customer sentiment and online customer ratings for hotels-An empirical analysis. Tourism Management, 61: 43-54. https://doi.org/10.1016/j.tourman.2016.12.022
[17] Kumari, U., Soni, D., Sharma, A. (2017). A cognitive study of sentiment analysis techniques and tools: a survey. International Journal of Computer Science and Technology, 8(1): 58-62.
[18] Araque, O., Corcuera-Platas, I., Sánchez-Rada, J.F., Iglesias, C.A. (2017). Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Systems with Applications, 77: 236-246. https://doi.org/10.1016/j.eswa.2017.02.002
[19] Bag, S., Tiwari, M.K., Chan, F.T. (2019). Predicting the consumer's purchase intention of durable goods: An attribute-level analysis. Journal of Business Research, 94: 408-419. https://doi.org/10.1016/j.jbusres.2017.11.031
[20] Birjali, M., Beni-Hssane, A., Erritali, M. (2017). Machine learning and semantic sentiment analysis based algorithms for suicide sentiment prediction in social networks. Procedia Computer Science, 113: 65-72. https://doi.org/10.1016/j.procs.2017.08.290
[21] Elmurngi, E., Gherbi, A. (2017). An empirical study on detecting fake reviews using machine learning techniques. In 2017 Seventh International Conference on Innovative Computing Technology (INTECH), pp. 107-114. https://doi.org/10.1109/INTECH.2017.8102442
[22] Fan, Z.P., Che, Y.J., Chen, Z.Y. (2017). Product sales forecasting using online reviews and historical sales data: A method combining the Bass model and sentiment analysis. Journal of Business Research, 74: 90-100. https://doi.org/10.1016/j.jbusres.2017.01.010
[23] Soumya, P. (2017). Sentiment analysis of customers using product feedback data under Hadoop framework. International Journal of Computational Intelligence Research.
[24] Wankhede, R., Kumar, R. (2018). An approach to sentiment analysis. International Journal of Scientific Research in Science and Technology.
[25] Rehman, A.U., Malik, A.K., Raza, B., Ali, W. (2019). A hybrid CNN-LSTM model for improving accuracy of movie reviews sentiment analysis. Multimedia Tools and Applications, 78(18): 26597-26613. https://doi.org/10.1007/s11042-019-07788-7
[26] Luan, Y., Lin, S. (2019). Research on text classification based on CNN and LSTM. In 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), pp. 352-355. https://doi.org/10.1109/ICAICA.2019.8873454
[27] Wang, J., Yu, L.C., Lai, K.R., Zhang, X. (2019). Tree-structured regional CNN-LSTM model for dimensional sentiment analysis. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28: 581-591. https://doi.org/10.1109/TASLP.2019.2959251
[28] She, X., Zhang, D. (2018). Text classification based on hybrid CNN-LSTM hybrid model. In 2018 11th International Symposium on Computational Intelligence and Design (ISCID), 2: 185-189. https://doi.org/10.1109/ISCID.2018.10144
[29] Salur, M.U., Aydin, I. (2020). A novel hybrid deep learning model for sentiment classification. IEEE Access, 8: 58080-58093. https://doi.org/10.1109/ACCESS.2020.2982538
[30] Zhang, J., Li, Y., Tian, J., Li, T. (2018). LSTM-CNN hybrid model for text classification. In 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), pp. 1675-1680. https://doi.org/10.1109/IAEAC.2018.8577620
[31] Dong, Y., Liu, P., Zhu, Z., Wang, Q., Zhang, Q. (2019). A fusion model-based label embedding and self-interaction attention for text classification. IEEE Access, 8: 30548-30559. https://doi.org/10.1109/ACCESS.2019.2954985
[32] Devlin, J., Chang, M.W., Lee, K., Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.