Vallamchetty Sreenivasulu* | Mohammed Abdul Wajeed
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Spam emails based on images readily evade text-based spam email filters. More and more spammers are adopting the technology. The essence of email is necessary in order to recognize image content. Web-based social networking is a method of communication between the information owner and end users for online exchanges that use social network data in the form of images and text. Nowadays, information is passed on to users in shorter time using social networks, and the spread of fraudulent material on social networks has become a major issue. It is critical to assess and decide which features the filters require to combat spammers. Spammers also insert text into photographs, causing text filters to fail. The detection of visual garbage material has become a hotspot study on spam filters on the Internet. The suggested approach includes a supplementary detection engine that uses visuals as well as text input. This paper proposed a system for the assessment of information, the detection of information on fraud-based mails and the avoidance of distribution to end users for the purpose of enhancing data protection and preventing safety problems. The proposed model utilizes Machine Learning and Convolutional Neural Network (CNN) methods to recognize and prevent fraud information being transmitted to end users.
image spam data, text spam data, internet sources, fake emails, fake information, image classification, text classification, security
Millions of people are linked to the current situation in the world using electronic devices and large volumes of data. The popular application used today for transferring of data is electronic mail. Email is really cheap, and don't take time, users can send and receive data in real time, delete problems from distance and it is better for official communications, limiting time-zone and so on. With the evolution of the Internet, there are various methods for spreading spam to users to target their systems [1]. The rise and growth of social networking platforms, which provides more ways of transmitting spam, has become apparent. Spam is very harmful to users, because when logged in and new identification connexions are opened up, several spam messages are transmitted to the device [2].
Figure 1. Detection of text and image spam
Social media spam has often been used for “spamdexing” which is a word derived from “spam” and “indexing,” refers to the practice of search engine spamming by maliciously boosting the search engine ranking of a website by raising the amount of other pages connected to it, and by disseminating irrelevant information, also referred to as fake news [3]. It is therefore of complex significance to ensure that users do not face issues with hidden spam data. The process of the image and text spam detection is depicted in Figure 1.
The problem with the image classification can be categorised as real-time spam filtering. Convolution's neural network has become a popular model for addressing the image classification issue and has broken the records of a number of competitions for image recognition. In accordance with the proposed time, these well-known models and the results of the models are improved over time. The above spanning results cannot, on the one hand, be isolated from the basic model, but also from the advanced algorithms [4].
Experiments are built with the factors such that only selected independent variables are changed on various levels by creating an experimental control system. Independent variables are self-sufficient variables and do not require users for updates [5]. The separate variables selected are regulated absolutely. In the course of the experiment, researchers usually choose independent variables, whether they affect dependent variables. These variables may be influenced by forces from outside [6]. The proposed research focuses on the systematic study of social media spam using two methods: survey and observation for accurate prediction.
Spam attackers are continually developing novel strategies for interfering with the efficiency of spam filtering systems. There are several disguises [7] such as animated multi-frame GIFs, hand-written graphics, geometrical variations, and brilliant visuals. Forgings, cartoon colours, forgings, template-derived information, patching typefaces, and randomising are the most recent advances in visual data spamming [8]. The fundamental challenge that classifier systems confront is a lack of diverse datasets, which can aid modelling in efficiently classifying text spam and image spam [9].
The experiment provides a controlled method of collecting real world information on factors that disturb user tendencies to interact with social media spam [10]. Factors studied in the proposed work are the messages sent to the social media platform (e.g. Facebook, Twitter, and LinkedIn), the similarity between spam sending process and the content of messages users send, the matching of spam content to recipients' interests, and the type of content included in spam messages are analysed [11]. In this paper a machine learning mechanism with CNN is used for classification of the features in an effective way with CNN classifier for identification of image and text spam.
Parikh et al. [2] proposed a spam detection technique for effective spam content identification. Work in this frame defines models, such as the profile model, message model, and web page form. They investigate cross-social business classification and partnership classification. The suggested bi-gram Term Frequency-Inverse Document Frequency (TF-IDF) system will detect spammers who are not real. A positive rate of 0.6 percent is reached, with a false negative rate of 3.7 percent. The technique must be as effective as detecting spam as Spam Detection. This algorithm's simulation is carried out in the MAT lab. The proposed technique has been successfully established. 99.1% of spammers and 99.9% of spammers are incorrect.
Hochreiter and Schmidhuber [3] examined 30 million URLs from 230 million public tweets gathered over the course of a month. In the analysis, 10 million tweets were labelled as spam. 5 million URLs are classified spam (80% of them were malware and phishing, with the remaining 80% aimed at users Scams), accounting for 7% of all crawling unique URLs. Despite this, 27 percent of the URLs are directed to spam after a manual review of the sampled dataset. This indicates that the blacklisting performance was poor. The URLs in spam communications will be blocked for a period of 5 to 30 days. Despite this, 80 percent of the victims visited the spam URLs within two days of publishing the link. As a result, the lag time of the blacklists is too long to prevent victims from visiting spam URLs [4]. Furthermore, researchers concluded that only 23% of spam accounts possessed spam messages. 74% are compromised accounts and 74% are bogus accounts. Based on the results of a spam campaign click survey conducted by Twitter, it is clear that spam is far more dangerous than email spam, with a clickthrough rate of 0.25 percent. In comparison, email spam has a somewhat lower average (0.009 percent – 0.0158 percent).
Shu et al. [5] demonstrated that the Recurrent Neural Network (RNN) model outperforms earlier functional learning models. RNN has been used to predict weather, whereas tweets are rumours. Tweets were grouped as sequential data. There has also been work on a number of more sophisticated approaches: By assessing features, Gilda [6] shown a better outcome of the Long Short-Term Memory (LSTM) model. The main concept of the mechanism that is focused on during natural language processing is a smooth collection of word order depending on their significance [7]. The LSTM model properly detects about 56% of very small spam messages. The LSTM model has a false account detection rate of 0.068 [8].
Regular spam message detection learning can be used to distinguish audit spam by classifying insulation surveys [9] into two categories: spam and non-spam audits. The primary specialists appear to have examined the use of controlled learning, as proposed by Potthast et al. [10], for appealing spam data assumption. They examine the progress of sense mining, namely the use of Natural Language Processing (NLP) to eliminate or minimise feelings from their contents. The material properties of the content prior to its commitment were not expected to show aberrant workouts, such as the audit Spam outcomes [11]. Class-spam surveys were classified into three sorts by the developers: untruthful thinking, basic audits, and non-control. Detection of spam employing general public audits and surveys; in the considered model, 90 percent of spam account verifications are accomplished. The model has a low true positive rate of 0.3 and a high false positive rate of 0.7.
Ma et al. [12] to take into account both spam filtering images and user preferences. BMCF provides the 2-stage rating: binary philtres and multi-label user-driven ratings. Filter-driven. BMCF Framework was tested on the personal data sets of the public. Experimental results show that the system is able to identify spam images with the average accuracy of 74.25 percent and to classify spam images as predefined topics with t Spam images with an average accuracy of 67.59 percent. Metadata features include imagery size, distance, height, bit depth, and form of imagery, and colour characteristics such as colour number, variation, colour appearing mostly, primary colour and colour saturation, texture characteristic [13].
Thorne et al. [14] suggested a low-level feature-based extraction approach that includes metadata and graphics. According to the experimental results, the detection rate for varied datasets is 95%. Rashkin et al. [15] proposed a comprehensive picture spam detection method to efficiently decrease image spam on both the server and the customer side. On the server side, a non-negative sparsity test for clusters analysis of spam images is utilised to filter spammers' attack operations and readily track the spam source [16]. On the customer side, the technology employs the active learning approach [17], in which students guide the user to mark as few photos as possible while optimising categorization accuracy [18]. The results demonstrated that the regular variations [19] of the output quantity of the proposed approach are lower than that of competitive technology [20], implying that the proposed method is more powerful. The SVM achieved an 85 percent consumer accuracy.
Grier et al. [21] proposed a methodology that uses a large amount of named data to consistently apply marks to unlabeled data. The model trains two classifiers for the extraction of important and irrelevant features and adds to the preparation set the examples that are unquestionably marked by each classifier. This successfully allows for the creation and use of large datasets for characterization, reducing the need to physically provide marked preparatory occurrences. Their dataset was produced with the assistance of interns who physically named 6000 surveys taken from Epinions.com, 1394 of which were labelled as audit spam. There were four groups of survey-driven highlights created: content, assumption, item, and metadata. Another two collections of commentator-driven highlights have been created: profile and social. With 10-crease cross approval, tests were run using Nave Bayes, Logistic Regression, and SVM, and it was revealed that Nave Bayes was the best model, therefore all extra work was done with Nave Bayes. It is discovered that by using the co-preparing semi supervised technique, an F-Score of 60.9 is obtained, which is greater than the 0.583 obtained when removing any unlabelled data. Furthermore, it was discovered that using the proposed model raises the F-scores to 0.631. The results appear to demonstrate that this type of semi-supervised learning can definitely help in the area of survey for spam identification and warrants further exploration with more datasets.
Wang [22] proposed a model that utilize distinctive datasets for semi-directed learning for survey spam discovery, results obtained using this methodology are promising and with extra research, yields preferred execution over regulated learning while at the same time diminishing the need to create huge named datasets. Commentator driven survey spam identification audits are significant in the process of identification of survey spam data. Utilizing commentator driven highlights in mix with survey driven highlights might be favoured over an audit driven methodology for spam discovery. Furthermore, gathering conduct proof of spammers is simpler than recognizing audit spam.
Also, it is observed that utilizing the irregular social features (i.e., higher level of positive surveys, high number of audits, normal audit length, and so forth.) yields preferable outcomes over the n-gram includes in these reasonable datasets. The aftereffects of a 5-overlay cross approval try different things with a SVM classifier utilizing bigram and POS highlights brought about an exactness of 68.1% for this present reality counterfeit audits. This is far lower than the 90% revealed by Wu et al. [23] while assessing their model on artificial information. From this, apparently that utilizing AMT, one can't viably create counterfeit audits reliable with genuine phony surveys, or if nothing else steady with the kinds of audits that Yelp channels. The expansion of social highlights builds their precision to 86.1% on Yelp's separated audits dataset.
CNN models allow the clear assumption that users' sources of knowledge are picture / writing. Taking an information picture / message and offering a class is entrusted as a picture / content order [24]. At the point where PC takes a picture / message as input, a variety of pixel values are generated. This cluster relies upon the goals and size of the picture/content. Suppose if a shading picture/content is considered and its size is 480 x 480. The delegate exhibit will be 480 x 480 x 3 [25].
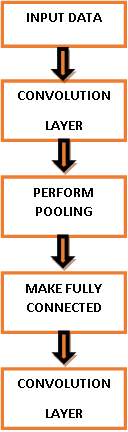
The number three alludes to RGB values. Every one of these numbers is given an incentive from 0 to 255 [26] which depicts the pixel force by then. These numbers are the main information sources accessible to the PC. The key idea is that if input is provided to the framework [27], it has to yield the likelihood of the picture/content being a supervised class. Utilizing customary neural systems for true picture/content arrangement [28] is illogical for the proposed model: consider a similar shading picture/content referenced previously. The Figure 2 represents the CNN architecture.
Figure 2. CNN architecture
The quantity of information hubs is above 600.000 (480X480X3). This number would increase rapidly by including shrouded layers with various hubs. Suppose the primary concealed layer has 20 hubs then the size of the network of information loads would be 12 million. On the off chance that the quantity of layers’ increases, the number expands more quickly. In addition, vectorising a picture/message totally overlooks the complex 2D spatial structure of the picture/content [29]. A CNN comprises of an information and a resultant layer, just as numerous concealed layers [30]. The shrouded layers of a CNN ordinarily comprise of unproven convolutional layers, hidden layers [31], pooling layers and completely associated layers [32]. The various layers will be disclosed by a direct framework with picture/content with 32 x 32 pixels size. The Figure 3 represents the CNN pixel processing architecture.
Figure 3. CNN pixel processing architecture
The convolution layer is the main layer that operates continuously as a coevolutionary layer. It's the central concept of CNN. The prediction of a sparkling spotlight on the super left of the model image / content is made [33]. The spotlight is a 5 x 5 pixel space. In the wake of the sparkling super-left territory, the spotlight shifts with the final goal of slipping through all the information picture / content territories [34]. This spotlight is known as a platform or part of CNN [35]. The area protected by the channel is known as the open field. The channel pixels have also a variety of qualities, just like the PC sees the model image / message as a variety of pixel values. The projection over the channel is in the upper left corner. It improves the efficiency of the channel by estimating the pixels in the image / content that it occupies, called component-savvy duplication. These duplications are summarized into a solitary number. This procedure is rehashed for each area of the model picture/message by sliding the channel to one side by s units where s is called walk. In the wake of sliding the channel over all areas, the outcome is a 28 x 28 cluster of single numbers. This cluster is known as the enactment or highlight map. The explanation that the feature map is littler than the information picture/content is on the grounds that there is a constrained measure of areas where a 5 x 5 channel can reach.
The more the channels, the more noteworthy the profundity of the initiation map, and the more data that is considered about the information volume. We could for instance utilize 10 channels with a 5 x 5 pixel zone with various pixel esteems. Convolutional systems abuse spatially nearby relationship by implementing a neighbourhood network design between neurons of contiguous layers where every neuron is associated with the open field of the considered picture/content.
The hidden layers and Pooling layers after a convolutional layer is usual to apply a nonlinear layer with the reason to embed non-linearity. The component insightful augmentations and summations were simply straight tasks and hidden layer embeds non-linearity which assists with reducing the disappearing slope issue. The disappearing inclination issue would cause the lower layers of the system to prepare gradually on the grounds that the angle diminishes exponentially. The hidden layer applies a capacity that changes all the negative initiations to 0. This builds the nonlinear properties of the model. After at least one initiation and additionally convolutional layers can be chosen to apply a pooling layer. The capacity of pooling layers is to continuously diminish the spatial size of the model to lessen the measure of parameters and calculation in the system. Max-pooling is the most considered pooling layer in the proposed model. It takes a channel, ordinarily of size 2 x 2 that moves over the information volume. It yields the most extreme number for the field it covers.
The considered images for spam detection in social media is performed for classification of images spam and text spam. The considered spam image is converted into an array of pixels that is depicted as P * Q with relevant text embedded in it and the process is performed as
$\begin{gathered}
\operatorname{Im}(P, Q)=\cup_{i=0}^{p-1} \text { fitness }(\mathrm{P}, \mathrm{Q}) U_{j=0}^{q-0} \frac{f(P, Q)}{f_{\max }}+\mathrm{Th} \\
+\operatorname{Contrast}(\mathrm{P})+\operatorname{Contrast}(\mathrm{Q})
\end{gathered}$ (1)
Apply filter using CNN based method ‘β’ for noise removal that is performed as
$\beta_{\text {med }}^{n}=\frac{T(i, j)}{n^{2}(p)} \approx \frac{\mathrm{p} * \pi_{i}^{2} * \mathrm{q}}{n(I)+\frac{\pi}{2}-1}$ (2)
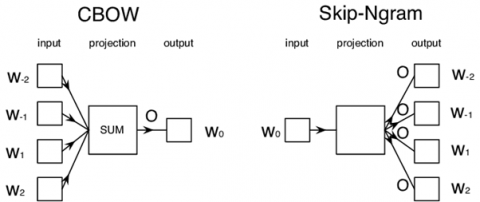
The pooling layer radically diminishes the spatial feature of the information volume with two objectives: 1. Calculation cost is diminished in light of the fact that the measure of parameters is decreased by 75% and 2. It will control the over flow of values. Fully connected layers are used for completing the process of analysing the information in the system. The information volume is the result of the past layer (hidden or Pooling). The result is a N dimensional vector where N is the quantity of classes. For instance, to group between a feathered creature, nightfall, pooch, feline or chicken, N would be 5. Each number in the vector speaks to the likelihood of a specific class. The completely associated layer figures out which includes generally connect to a specific class. In the model picture/content of a feathered creature, it will have high qualities in the feature maps that speak to significant level features like wings. In the model, the subsequent vector could be [{0.75, 0}, {0.05, 0}, {0.2,0}] implying that there is a 75% change that the picture/content speaks to a winged creature. Representing words as nonstop vectors isn't new in the realm of NLP that has another renaissance with the presentation of Word2Vec [1, 2]. One of the fundamental thoughts of Word2Vec is that the consistent vectors could catch various degrees of similitude during model preparing. Word2Vec comprises of two algorithms for training word vectors: Continuous Bag-Of-Words (CBOW) and Skip-gram (SG). Figure 4 shows an overview of the neural architectures of these algorithms.
Figure 4. CBOW and Skip-gram for word processing
Both CBOW and Skip-gram are shallow neural network language models. The objective function for Word2Vec relate to the probabilities of projecting a word vector vt given surrounding words vectors in a context window c = {vt−ws, ..., vt−1, vt+1, ..., vt+ws} of width ws (CBOW) or projecting the context window c = {vt−ws, ..., vt−1, vt+1, ..., vt+ws} given a word vector vt (Skip-gram).
These probabilities are based on Equation 3. To maximize this probability, the optimization algorithm must maximize the scalar product between the target word and the context while minimizing the scalar product between the contexts with all other words in the vocabulary. For CBOW the contextual vector is defined as the sum of the word vectors in the context window. The sample considered is mapped to features that are relevant and irrelevant and the spam data is classified and the clusters are formed using
$\begin{aligned}
\operatorname{Ig}(\operatorname{CS}(i))=\sum_{i=1}^{p} \mathrm{M} \sum_{I=1 \atop i=1}^{q} \mathrm{~W}(\mathrm{i}) * p i+\operatorname{Sim}(p, q) &+\beta_{\text {med }}^{n}
\end{aligned}$ (3)
$\mathrm{vc}=\sum \mathrm{c}^{\prime} \in \mathrm{cvc}^{\prime}$ and for Skip-gram it is the word vector vc = vt. The Skip-gram algorithm, as it tries to predict multiple words, locally maximizes the expression:
$\sum_{c^{\prime} \varepsilon c} \mathrm{~V} \log p\left(c^{\prime} \mid t\right)$ (4)
Because it performs many comparisons that are more computationally intensive than the CBOW algorithm, which only maximizes log p(t|c) as the features can be reduced that are not relevant. For every context ct associated with a word t, in a document D, in a corpus D, the algorithms improve the detection rate.
$C B O W: \sum_{D E D} \mathrm{~V} \sum_{t E D}+\log p\left(t^{\prime} \mid c * t\right)$ (5)
$\text { Skpp - gram: } \sum_{D E D} \mathrm{~V} \sum_{t E D}+\sum_{c^{\prime} E c t} \mathrm{D} \log p\left(t^{\prime} * c^{\prime} t \mid t\right)$ (6)
The log probability is used instead of the regular probability to promote numerical stability. In order to get more efficient computations, the softmax expression can be approximated by the hierarchical softmax. The hierarchical softmax traverses a binary probability tree, where each node in the probability tree holds the relative frequency of its child nodes. Hence the probability of a word t at depth L(t) is the product over L(t) − 1 nodes. To define the hierarchical softmax expression n(t, 1) is considered as the root shared by all words, n(t, L(t)) as the word itself and ch(n) as an arbitrary fixed child of n. The expression for the log probability then becomes,
$\begin{aligned}
\log _{p}(t \mid c) \approx & \sum_{i=1}^{l t-1} \log \lambda(I \mid n(t, j+1)\\
&=\operatorname{ch}(n(t, j)) \mid(v k(t, j), v c)
\end{aligned}$ (7)
where, I[b] = (−1)b+1 is a function of the Boolean statement b = {0, 1} and σ(x) = 1+exp(−x). The tree is implemented as a binary Huffman tree that assigns binary representations based on word frequency. This optimizes the structure to minimize information entropy and drops the average number of computations for the partition function from |V| to log (|V|). Another possible replacement for the softmax expression is called negative sampling (inspired by noise contrast estimation). It replaces the log probability with the expression,
$\begin{aligned}
\log _{p}(t \mid c) \approx & \log \lambda(\mathrm{Vi}-\mathrm{Vc}) \\
+& \sum_{i=1}^{k} \operatorname{Evi} \sim P(n)[\log \lambda(-V i, V c)]
\end{aligned}$ (8)
where, σ(x) is the same as for Equation 5, k is the number of negative samples to minimize and P(n) is the noise distribution from which the negative samples are drawn. The noise distribution P(n) used by Word2Vec is U(w), where U(w) is the word distribution of the corpus. The word negative relates to the fact that the words are uncorrelated noise and should be minimized to increase the contrast. The negative sampling strategy does not approximate the real softmax function. They also remark that the resulting vectors become good word representations despite this fact. Negative sampling is generally faster than hierarchical softmax if k < log(|V|). Despite this fact we shall primarily rely on the hierarchical softmax as it produces better vectors for rare words. Another trick to make Word2Vec computations more efficient is subsampling frequent words by only processing them with a probability,
$P(w)=1-\sqrt{\frac{t_{f}}{F(w)^{\mathrm{t}}}}+\log p\left(t^{\prime} \mid c * t\right)$ (9)
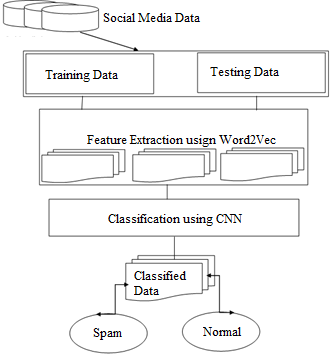
where, tf is a threshold parameter (typically between 10−3 to 10−5) and F(w) is the relative frequency of word w. These approximations and simplifications represent that the two Word2Vec algorithms are very efficient when compared to their continuous vector predecessors. This explanation of Word2Vec is sufficient for the purposes of this proposed work. Read Rong’s “word2vec Parameter Learning Explained” [9] for a detailed description of how the CBOW and Skip-gram algorithms are structured. After training the word vectors, one can utilize the property of context being captured by the scalar product. The Figure 5 represents the proposed model architecture. Metrics such as the cosine similarity are used to infer contextual relations between 2 word vectors v, v′.
$\operatorname{similarity}\left(v, v^{\prime}\right)=\cos (\theta)=\frac{V \cdot V^{\prime}}{\|V\| *\left\|V^{\prime}\right\|}$ (10)
Figure 5. Proposed architecture
3.1 Pre-processing
The natural language utilized in online networking content isn't organized and doesn't follow the language rules. The starting investigation and pre – processing technique is required for compelling features election and characterization. Pre - processing is one of the basic undertakings in the zone of content characterization or Natural Language Processing (NLP). This is on the grounds that the raw information from the source is commonly inadequate, conflicting or loud and it requires cleaning and to be purchased in the structure where it very well may be utilized in the model for the classification task. This assignment is likewise subject to the sort or origin of information and the consequences of the classifiers differs, all things considered, because of pre-processing. To set up the information, different advances are performed like expulsion of exceptional characters, stop-word removal and tokenization. Uncommon characters allude to the characters like comma, full stop and so forth which are expelled from the raw information. The subsequent stage comprises of change of the information strings into tokens. The weights are calculated for text spam and image spam and then the clusters need to be arranged based on the weights that is performed as:
$\operatorname{CS}(W(i)) \operatorname{Ig}_{t+1}^{i}=\left(\beta_{k+1}\right) l_{k}^{i}+1-\sqrt{\frac{t_{f}}{F(w)^{\mathrm{t}}}}+\log p\left(t^{\prime} \mid c * t\right)$
$\beta$ is the maximum instance of image. $l_{k}^{i}$ is the Record instance 1 and Ik is the Record instance for weight comparison. The calculated weights are normalized as:
$W N(P, Q)_{i, j}=\frac{-\sqrt{\frac{t_{f}}{F(w)^{t}}}+\log p\left(t^{\prime} \mid c * t\right)+T_{j}^{\left(c_{i}\right)}}{\left(\beta_{k+1}\right) *\left|\operatorname{Ig}(W(i))_{j}\right|}$
The tokens are singular words that don't have any non – alphabetic characters in the middle. Alongside alphabetic tokens and numeric tokens are likewise held. These tokens structure the arrangement of feature space for the classifier models. From this list of capabilities, the most ordinarily happening words, otherwise called stopwords are expelled since these words don't contribute fundamentally to the list of capabilities. Aside from these essential advances, twitter information requires some extra pre-processing because of the idea of tweets. Since tweets that have been scratched are open live tweets in this way, each tweet comprises of a hyperlink that opens the tweet data in the Twitter App. These connections are expelled from the raw information. Tweets likewise contain the twitter data, for example twitter client name of the user sending the tweet. Since our work depends on the content highlights, in this way the twitter handle (beginning with @ followed by the client name) is expelled which isn't noteworthy for the content arrangement work. The error rate of the proposed model in detection of spam email accounts is calculated as:
$E_{t}=\sum_{i=1}^{\lambda} F(w)+W\left(R(i)+\alpha t_{F}\right)$
where, F(w) is word frequency, W(R(i)) indicates the weights of the spam account and $\alpha$ is the threshold value for spam categorization. The proposed work initially takes the data and split the data into 7:3 ratio as training and testing data and after splitting the data, it is given to the Word2Vec model. The framework extracts the features from the text data and these features are given to CNN classifier. CNN classifier performs processing the features in different CNN layers. Finally, CNN produces the binary results of spam or normal data. The working of proposed algorithm is specified below.
3.2 Pseudo code for Spam data classification using Word2Vec and CNN
Input: Social media data
Output: Classified data means spam data and genuine data.
Step-1: Take the input data set and split it into training and testing data
Step-2: while training
For each word in the Training Data:
If it exists in the model:
For each word in the Content Tree:
Calculate the correlation between the word vectors.
Parent →Word with Maximum Correlation
Add the word to the Content Tree as the child of the parent
Feature map →{Set of nodes in the content tree}
Apply CNN on the feature map
Return classified data
}
4.1 Dataset
Supervised learning classifiers are utilized to convey the order undertakings. In this manner, preparing just as testing information is required for viable order. The spam order is carried on the short internet based life instant messages that are constrained long. We have thought about two mechanisms of social content: the versatile messages as SMS content and content from small scale blogging webpage, Twitter. The information for the SMS message is taken from the UCI Repository link “https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences” and the Twitter content information is rejected from the open live tweets. These two datasets are portrayed beneath:
4.2 SMS Spam Corpora
SMS Spam Collection dataset is taken from UCI repository using the link “https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection” which was formed in 2012. It comprises of 5574 portable SMS out of which 747 are spam, and 4827 are ham. These instant messages were gathered from different sources like 425 spam messages were taken from the UK site: Grumble text, 3,375 ham SMS from NUS SMS Corpus (NSC), 450 ham messages from Caroline Tag's Thesis, (Ref) and rest 1002 messages from SMS Spam Corpus v.0.1. The dataset is as content document where each line comprises of a mark followed by the message. The conveyance of content SMS as spam and ham is appeared.
4.3 Twitter corpora
This dataset has been made by rejecting the open live tweets from the smaller scale blogging website Twitter utilizing Twitter Programming interface. The dataset is available in the link “https://www.kaggle.com/kazanova/sentiment140”. While rejecting the tweets, the catchphrases were given that may assist us with retrieving the ideal sort of tweets tending to be categorized as one of the classes of spam or ham. A few instances of the watchwords or the dictionaries are "pornography", "lottery", "school", "video" and so forth. These tweets have been physically named ham or spam.
1. Accuracy is the quantity of right forecasts made in both of the class partitioned by the all-out number of expectations made. It is then duplicated by 100 for getting the rate. It is determined as appeared in Equation:
$\text { Accuracy }=\frac{T P+T N}{T P+F P+F N+T N}$
2. Precision is the quantity of True Positives partitioned by the aggregate of True Positives and False Positives. A low precision may show an enormous number of False Positives. It is determined as appeared in Equation:
$\text { Precision }=\frac{T P}{T P+F P}$
3. Recall is the quantity of True Positives partitioned by the absolute number of True Positives and False Negatives. A review can be thought of as a proportion of a classifiers culmination. A low review demonstrates high False Negatives. It is determined as appeared in Equation:
$\text { Recall }=\frac{T P}{T P+F N}$
4. F1 Score is outstanding amongst other proportion of classifier's exactness. While ascertaining F1 scores, precision and review both are considered as it is the weighted normal of both. It has the incentive somewhere in the range of 0 and 1 while 0 being the most pessimistic scenario and 1 being the best case. It is determined as appeared in Equation:
$\text { Fi }=2 * \frac{\text { Precision } * \text { Recall }}{\text { Precision }+\text { Recall }}$
This section presents the visualization results for the classifying the spam data from social media data. The proposed work is implemented in ANACONDA and here the graphs represents different existing works and a proposed model of Word2Vec based CNN. The comparison results show for the performance metrics of Accuracy, precession, recall and F1-Score for two different standard data sets.
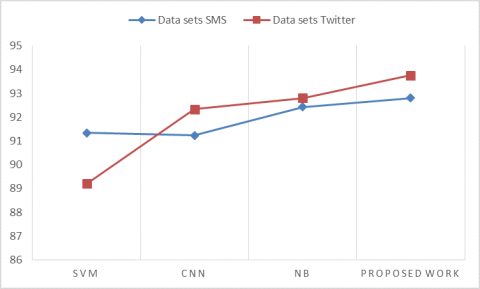
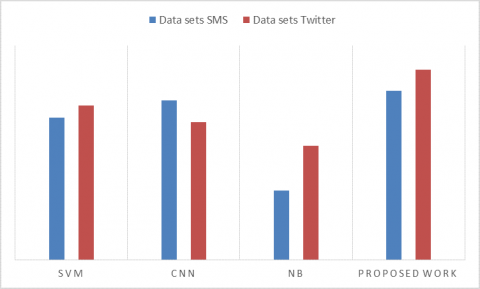
Figure 6. Accuracy
Figure 6 represents the accuracy comparative analysis of our proposed mechanism of Word2Vec based CNN mechanism with respect to different existing works of SVM, CNN and NB classifiers. Here proposed system accuracy is far better than existing works because proposed mechanism is a hybrid mechanism which can able to handle with different kinds of data like Url’s, text and other formats of data also in an effective way to produce better accuracy compared to existing works.
Figure 7 describes the comparative precession value analysis of differ spam classification mechanism with respect to proposed mechanism. Proposed work gives better analysis than exiting in two different datasets.
Figure 8 describes the comparative recall value analysis of differ spam classification mechanism with respect to proposed mechanism. Proposed work gives better analysis than exiting in two different datasets.
Figure 7. Precession
Figure 8. Recall
Figure 9. F1-score
Figure 9 describes the comparative F1-score value analysis of differ spam classification mechanism with respect to proposed mechanism. The proposed model exhibits better performance than the traditional models.
Spammers are working hard to advance, and it's unfortunate that spam researchers squander time while spammers may evade and beat spammers' techniques and tricks. Spammers can also spend more time on the job, even with the help of new skills. Consider offence to be the best defence, and you can't wait for spammers to continue their game in a new round. Spam data is a major issue in today's culture, whether it is conveyed in image or text format. The primary goal of this work is to identify spam data using a learning system. The proposed method is successful; research has been conducted on a number of currently available mechanisms, and a model using machine learning and CNN for spam detection has been proposed. The design of the classifier is complicated, and it is best completed with a large amount of data that has been trained and evaluated. It correctly detects spam communications and stops the transmission of spam material in image and text formats to end users. The future study will make use of already generated word vectors, such as Google's claim that word vectors are semanticized by characterization assignments. In this way, a technique is discovered in which the model learns the features rather than the highlights missed by the experts.
[1] Ma, J., Gao, W., Mitra, P., Kwon, S., Jansen, B.J., Wong, K.F., Cha, M. (2016). Detecting rumors from microblogs with recurrent neural networks. In IJCAI-16, pp. 3818-3824.
[2] Parikh, A.P., Täckström, O., Das, D., Uszkoreit, J. (2016). A decomposable attention model for natural language inference. arXiv preprint arXiv:1606.01933.
[3] Hochreiter, S., Schmidhuber, J. (1997). Long short-term memory. Neural Computation Archive, 9(1): 1735-1780. https://dl.acm.org/citation.cfm?id=1246450.
[4] Pennington, J., Socher, R., Manning, C.D. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532-1543.
[5] Shu, K., Sliva, A., Wang, S., Tang, J., Liu, H. (2017). Fake news detection on social media: A data mining perspective. ACM SIGKDD Explorations Newsletter, 19(1): 22-36. https://doi.org/10.1145/3137597.3137600
[6] Gilda, S. (2017). Evaluating machine learning algorithms for fake news detection/subscribe. Neural Computation Archive.
[7] Rubin, V.L., Conroy, N., Chen, Y., Cornwell, S. (2016). Fake news or truth? using satirical cues to detect potentially misleading news. In Proceedings of the Second Workshop on Computational Approaches to Deception Detection, pp. 7-17. https://doi.org/10.18653/v1/W16-0802
[8] Ferreira, W., Vlachos, A. (2016). Emergent: a novel data-set for stance classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1163-1168.
[9] Zhou, J., Lu, Y., Dai, H. N., Wang, H., Xiao, H. (2019). Sentiment analysis of Chinese microblog based on stacked bidirectional LSTM. IEEE Access, 7: 38856-38866. https://doi.org/10.1109/ACCESS.2019.2905048
[10] Potthast, M., Kiesel, J., Reinartz, K., Bevendorff, J., Stein, B. (2017). A stylometric inquiry into hyperpartisan and fake news. arXiv preprint arXiv:1702.05638.
[11] Chennam Lakhsmikumar, P. (2019). Fake news detection a deep neural network. Master's thesis, University of Stavanger, Norway.
[12] Ma, J., Gao, W., Mitra, P., Kwon, S., Jansen, B.J., Wong, K.F., Cha, M. (2016). Detecting rumors from microblogs with recurrent neural networks. Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), pp: 3818-3824.
[13] Chopra, S., Jain, S., Sholar, J.M. (2017). Towards automatic identification of fake news: Headline-article stance detection with LSTM attention models. In Stanford CS224d Deep Learning for NLP Final Project.
[14] Thorne, J., Chen, M., Myrianthous, G., Pu, J., Wang, X., Vlachos, A. (2017). Fake news stance detection using stacked ensemble of classifiers. In Proceedings of the 2017 EMNLP Workshop: Natural Language Processing Meets Journalism, pp. 80-83.
[15] Rashkin, H., Choi, E., Jang, J.Y., Volkova, S., Choi, Y. (2017). Truth of varying shades: Analyzing language in fake news and political fact-checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 2931-2937.
[16] Bahdanau, D., Cho, K., Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[17] Xiong, C., Zhong, V., Socher, R. (2016). Dynamic coattention networks for question answering. arXiv preprint arXiv:1611.01604.
[18] Rocktäschel, T., Grefenstette, E., Hermann, K.M., Kočiský, T., Blunsom, P. (2015). Reasoning about entailment with neural attention. arXiv preprint arXiv:1509.06664.
[19] Yin, W., Schütze, H., Xiang, B., Zhou, B. (2016). Abcnn: Attention-based convolutional neural network for modeling sentence pairs. Transactions of the Association for Computational Linguistics, 4: 259-272. https://doi.org/10.1162/tacl_a_00097
[20] Inference, O. Parikh, A.P. (2016). A decomposable attention model for natural language. Neural Computation Archive.
[21] Grier, C., Thomas, K., Paxson, V., Zhang, M. (2010). @ Spam: The underground on 140 characters or less. In Proceedings of the 17th ACM Conference on Computer and Communications Security, pp. 27-37.
[22] Wang, A.H. (2010). Detecting spam bots in online social networking sites: a machine learning approach. In IFIP Annual Conference on Data and Applications Security and Privacy, pp. 335-342.
[23] Wu, T., Liu, S., Zhang, J., Xiang, Y. (2017). Twitter spam detection based on deep learning. In Proceedings of the Australasian Computer Science Week Multiconference, pp. 1-8. https://doi.org/10.1145/3014812.3014815
[24] Zheng, X., Zeng, Z., Chen, Z., Yu, Y., Rong, C. (2015). Detecting spammers on social networks. Neurocomputing, 159: 27-34. https://doi.org/10.1016/j.neucom.2015.02.047
[25] Alsaleh, M., Alarifi, A., Al-Salman, A.M., Alfayez, M., Almuhaysin, A. (2014). TSD: Detecting sybil accounts in twitter. In 2014 13th International Conference on Machine Learning and Applications, pp. 463-469. https://doi.org/10.1109/ICMLA.2014.81
[26] Verma, M., Sofat, S. (2014). Techniques to detect spammers in twitter-A survey. International Journal of Computer Applications. https://doi.org/10.5120/14877-3279
[27] Wang, D., Irani, D., Pu, C. (2011). A social-spam detection framework. In Proceedings of the 8th Annual Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference, pp. 46-54. https://doi.org/10.1145/2030376.2030382
[28] Cao, C., Caverlee, J. (2015). Detecting spam URLs in social media via behavioral analysis. In European Conference on Information Retrieval, pp. 703-714. https://doi.org/10.1007/978-3-319-16354-3_77
[29] Jain, G., Sharma, M., Agarwal, B. (2018). Spam detection on social media using semantic convolutional neural network. International Journal of Knowledge Discovery in Bioinformatics (IJKDB), 8(1): 12-26. https://doi.org/10.4018/IJKDB.2018010102
[30] Ezpeleta, E., Iturbe, M., Garitano, I., de Mendizabal, I. V., Zurutuza, U. (2018). A mood analysis on YouTube comments and a method for improved social spam detection. In International Conference on Hybrid Artificial Intelligence Systems, pp. 514-525. https://doi.org/10.1007/978-3-319-92639-1_43
[31] Dwyer, C., Hiltz, S., Passerini, K. (2007). Trust and privacy concern within social networking sites: A comparison of Facebook and MySpace. AMCIS 2007 Proceedings, 339. https://aisel.aisnet.org/amcis2007/339
[32] Dutta, S., Ghatak, S., Dey, R., Das, A.K., Ghosh, S. (2018). Attribute selection for improving spam classification in online social networks: A rough set theory-based approach. Social Network Analysis and Mining, 8(1): 1-16. https://doi.org/10.1007/s13278-017-0484-8
[33] Ala’M, A.Z., Faris, H., Alqatawna, J.F., Hassonah, M.A. (2018). Evolving support vector machines using whale optimization algorithm for spam profiles detection on online social networks in different lingual contexts. Knowledge-Based Systems, 153: 91-104.
[34] Aslan, Ç.B., Sağlam, R.B., Li, S. (2018). Automatic detection of cyber security related accounts on online social networks: Twitter as an example. In Proceedings of the 9th International Conference on Social Media and Society, pp. 236-240. https://doi.org/10.1145/3217804.3217919
[35] Sedhai, S., Sun, A. (2017). Semi-supervised spam detection in Twitter stream. IEEE Transactions on Computational Social Systems, 5(1): 169-175. https://doi.org/10.1109/TCSS.2017.2773581