Mohammed S. Kotb* | Ali Sharawy | Marwa M. Mohie El-Din
© 2021 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This paper develops a Bayesian analysis in the context of progressive first failure censoring from the two-parameter Kumaraswamy distribution. The Bayesian and E-Bayesian estimations based on progressive first failure censoring are derived for the unknown parameters and some survival time parameters (reliability and hazard functions). The estimates are obtained based on Al-Bayyati loss, general entropy loss and LINEX loss functions. The properties of E-Bayesian estimation are given. The Bayesian and E-Bayesian estimations are compared via a Monte Carlo simulation study. Finally, a numerical example is established to clear the theoretical procedures.
E-Bayesian estimation, Kumaraswamy distribution, progressive first failure censored, Monte Carlo simulation
Nowadays, due to highly competitive market reliability of products is of great interest. Hence life-testing and reliability experiments are carried out before and during the products are put on the market. In these life-tests, it is not always possible to observe the failure times of all units subjected to the test due to time limits and other restrictions, so censored sample schemes are of great importance. The progressive type-II right censoring scheme is one of the most common censoring schemes where the experimenters have experiences with situations where the removal of units prior to failure is preplanned. This scheme allows us to tackle analyzing Kumaraswamy (KW) progressive data in medical studies, reliability and survival where some of the experimental units are removed during the experiment. For some applications on XLPE-insulated cable models under combined thermalelectrical stresses [1]. Recently, a considerable body of literature has been devoted to the inference problems based on progressive censored samples, as demonstrated in Refs. [2-8]. If the life distribution of the product tested is not known, different methods were introduced to deal with testing product data [9, 10] derived empirical Bayes estimators of reliability performances using progressive type-II censoring from Lomax model. In the last two decades, several authors have used the different losses for Bayesian parameter estimation of some distributions. Further details are explained in Ref. [11-13].
Among various censoring schemes, the progressively firstfailure censoring scheme arose as one of the most popular censoring schemes during the last decade. Suppose that $n$ independent groups with $k$ items within each group are put on a life test. The sampling process of these censored samples is described as follows. After the time of the first failure, $R_{1}$ groups and the group is observed are randomly removed from the test as soon as the first failure $X_{1: m: n, k}^{\left(R_{1}, R_{2} \ldots, R_{m}\right)}$ has occurred, $R_{2}$ groups and the group in which the second failure is observed are randomly removed from the test as soon as the second failure occurred $X_{2: m: n, k}^{\left(R_{1}, R_{2}, \ldots, R_{m}\right)}$ and finally when the $m$ th failure $X_{m: m: n, k}^{\left(R_{1}, R_{2}, \ldots, R_{m}\right)}$ is observed, the remaining groups $R_{m}$ are removed from the test. Then $X_{1: m: n, k}^{\left(R_{1}, R_{2}, \ldots, R_{m}\right)}<\cdots<$ $X_{m: m: n, k}^{\left(R_{1}, R_{2}, \ldots, R_{m}\right)}$ are called progressively first-failure censored order statistics with the progressive censored scheme, where $n=m+\sum_{i=1}^{m} R_{i}$.
Embracing the assumption that the lifetimes of the above units have the Kumaraswamy distribution [14] with probability density function (pdf) and cumulative distribution function (cdf) respectively:
$\left.\begin{array}{c}f(x)=\alpha \beta x^{\alpha-1}\left(1-x^{\alpha}\right)^{\beta-1}, \quad 0<x<1 \\ F(x)=1-\left(1-x^{\alpha}\right)^{\beta}, \quad 0<x<1\end{array}\right\}$ (1)
where, $\alpha>0$ and $\beta>0$ are positive shape parameters. Therefore, the reliability and hazard functions at an arbitrary time t for the KW distribution are given by:
$R(t)=\left(1-x^{\alpha}\right)^{\beta}$ and $H(t)=\frac{\alpha \beta t^{\alpha-1}}{1-t^{\alpha}}, 0<t<1$. (2)
This model was originally conceived to model hydrological phenomena and has been effectively used for this and also for other purposes. For a detailed discussion on the importance and structural properties of KW distribution, one may refer to [15-20]. Recently, a considerable body of literature has been devoted to the inference problems based on KW distribution [21-23].
The main aim of this paper is to consider the E-Bayesian estimation (E-BE) problem based on progressive first failure censored KW data. A number of authors [24-26] have considered E-BE problems for some distributions using different types of censoring data.
The rest of this paper is organized as follows: Section 2, contains some model details of the different loss functions used in our paper. In Section 3, the Bayesian estimators (BEs) for the parameter, the reliability and hazard functions of the KW distribution based on progressive first failure censored order statistics are developed. In Section 4, the E-BEs of the parameters, the reliability and hazard functions are derived, and the properties of E-BE are also discussed. The sample- based estimators using Bayesian approach under Al-Bayyati loss, general entropy loss and LINEX loss functions are developed. Intensive Monte Carlo simulation study is performed to clear and compare among all estimation methods in Section 5. Finally, we conclude the paper in Section 6.
For most statisticians, the error loss functions play important role used for obtaining the BEs and corresponding risk functions. In this paper, we consider BEs under three different losses: the Al-Bayyati loss (AL), the general entropy loss and the asymmetric LINEX loss functions. Al-Bayyati [27] introduced the AL function, and many other authors [28, 29] have used AL function different estimation problems. This loss function is of the form:
$L_{B}(\tilde{\beta}, \beta)=\beta^{q}(\tilde{\beta}-\beta)^{2}, q \in \mathbb{R}$.
By using the posterior $\pi(\beta \mid \mathbf{x})$, we have the following risk function:
$R^{*}(\tilde{\beta})=\int_{0}^{\infty} \beta^{q}(\tilde{\beta}-\beta)^{2} \pi(\beta \mid \mathbf{x}) \mathrm{d} \beta$.
Under the AL function, the BE of the parameter is given by solving the following equation $\partial R^{*}(\tilde{\beta}) / \partial \tilde{\beta}=0$. This in turn implies that the BE of β is given by:
$\tilde{\beta}_{A L}=\frac{E\left(\beta^{q+1} \mid \mathbf{x}\right)}{E\left(\beta^{q} \mid \mathbf{x}\right)}$. (3)
Calabria and Pulcini [30] proposed the general entropy loss (GEL) function, which is one of the most popular asymmetric loss functions. The BE for the parameter β based on the GEL function may be defined as:
$\tilde{\beta}_{G E}=\left[E\left(\beta^{-\lambda} \mid \mathbf{x}\right)\right]^{-1 / \lambda}$, (4)
provided that $E\left(\beta^{-\lambda} \mid \mathbf{x}\right)$ exists and is finite. For $\lambda=-2$, the GEL function is referred to as the precautionary loss function which is an asymmetric loss function. For $\lambda=-1$, the GEL function is square error loss (SEL) function, while the weighted SEL function obtained by setting $\lambda=1$ and therefore, almost symmetric. For $\lambda>0$, a positive error has a more serious effect than a negative error and for $\lambda<0$, a negative error has a more serious effect than a positive error.
Finally, Varian [31] introduced the most popular asymmetric loss function which is the LINEX loss function. The LINEX loss function has been used widely in the literatures $[32,33]$. The LINEX loss function for $\beta$ can be expressed from the assumption that the minimal loss occurs at $\tilde{\beta}=\beta$ as:
$L(\vartheta) \propto \exp [c \vartheta]-c \vartheta-1, \quad c \neq 0, \quad \vartheta=\tilde{\beta}-\beta$,
where, $\tilde{\beta}$ is an estimate of $\beta$. The sign of the shape parameter $c$ represents the direction and its magnitude represents the degree of symmetry. For $c$ close to zero, the LINEX loss function is approximately the almost symmetric (SEL function). The posterior expectation $E_{\beta}(L(\vartheta))$ of the LINEX function with respect to the posterior density of $\beta$ is given by:
$E(L(\vartheta)) \propto \exp [c \tilde{\beta}] E_{\beta}(\exp [-c \beta])-c\left(\tilde{\beta}-E_{\beta}(\beta)\right)$$-1$. (5)
Under the LINEX loss function, the BE $\tilde{\beta}_{L I}$ of β which minimizes (5) is given by:
$\tilde{\beta}_{L I}=-\frac{1}{c} \ln \left[E_{\beta}(\exp [-c \beta])\right]$, (6)
provided that $E_{\beta}(\exp [-c \beta])$ exists and is finite. For more details on choosing the value of the constant c see the Refs. [30-34].
Here, we consider the estimation problem when the observed failure data are progressive first failure censored. The different BEs of the model parameter $\beta, R(t)$ and $H(t)$ are provided. If the failure times of the $n \times k$ items originally in the test are from a continuous population, whose pdf and $\mathrm{cdf}$ are given in (1), with the censoring scheme (CS) $\boldsymbol{R}=$ $\left(R_{1}, R_{2}, \ldots, R_{m}\right)$, the likelihood function of $\alpha$ and $\beta$ is accordingly given by:
$L(\alpha, \beta \mid \mathbf{x}) \propto \alpha^{m} \beta^{m}\left(\prod_{i=1}^{m} \frac{x_{i}^{\alpha-1}}{1-x_{i}^{\alpha}}\right)$$\times \exp \left[\beta k \sum_{i=1}^{m}\left(R_{i}+1\right) \ln \left(1-x_{i}^{\alpha}\right)\right]$, (7)
where, $\mathbf{x}=\left(x_{1}, x_{2}, \ldots, x_{m}\right)$ and $0<x_{1}<x_{2}<\cdots<x_{m}<\infty$. Here, we use gamma distribution as informative prior. Under the assumption that the shape parameter $\alpha$ is known and to develop the estimate of $\beta$, we consider prior of $\beta$ has gamma distribution (denoted as $G(\eta, \gamma)$ ), because gamma distribution is very flexible, with the following density:
$\pi(\beta)=\frac{\gamma^{\eta}}{\Gamma(\eta)} \beta^{\eta-1} \exp [-\gamma \beta], \quad \eta, \gamma>0$. (8)
The Jeffreys prior $(\eta=0, \gamma=0)$ is a special case of $G(\eta, \gamma)$, where the Jeffreys prior can be used if prior information about $\beta$ is scanty. The parameters $\gamma$ and $\eta$ can be chosen such that the experimenter's prior beliefs of location and precision of the true value of $\beta$ are fulfilled, through $E(\beta)=\eta / \gamma$ and $\operatorname{Var}(\beta)=\eta / \gamma^{2}$. By combining (7) and (8), the posterior density of $\beta$ is obtained to be:
$\pi(\beta \mid \mathbf{x})=\pi(\beta) L(\alpha, \beta \mid \mathbf{x})$$=\phi^{-1}(\eta, \gamma) \beta^{m+\eta-1} \exp [-\beta(\gamma$$\left.\left.-\psi_{m, k}\right)\right]$, (9)
where,
$\left.\begin{array}{c}\phi(\eta, \gamma)=\frac{\Gamma(m+\eta)}{\left(\gamma-\psi_{m, k}\right)^{m+\eta}}, \\ \psi_{m, k}=k \sum_{i=1}^{m}\left(R_{i}+1\right) \ln \left(1-x_{i}^{\alpha}\right) .\end{array}\right\}$ (10)
Under the AL function, the BEs of $\beta$ can be shown by using Eq. (3) to be,
$\tilde{\beta}_{A L}=\frac{\phi(\eta+q+1, \gamma)}{\phi(\eta+q, \gamma)}=\frac{m+\eta+q}{\gamma-\psi_{m, k}}\quad$. (11)
Similarly, in making use of (2) and (9), the BEs for the reliability function $R(t)$ and $H(t)$ based on AL function are given respectively by:
$\left.\begin{array}{c}\tilde{R}_{A L}=\left(\frac{\gamma-\psi_{m, k}-q \ln \left(1-t^{\alpha}\right)}{\gamma-\psi_{m, k}-(q+1) \ln \left(1-t^{\alpha}\right)}\right)^{m+\eta}\quad, \\ \tilde{H}_{A L}=\left(\frac{m+\eta+q}{\gamma-\psi_{m, k}}\right)\left(\frac{\alpha t^{\alpha-1}}{1-t^{\alpha}}\right)\quad.\end{array}\right\}$ (12)
The BE of β, under the GEL function is obtained using (4) and the posterior density (9) as:
$\tilde{\beta}_{G E}=\left(\frac{\phi(\eta-\lambda, \gamma)}{\phi(\eta, \gamma)}\right)^{-\frac{1}{\lambda}}$$=\left(\frac{\Gamma(m+\eta-\lambda)}{\Gamma(m+\eta)}\right)^{-1 / \lambda} \frac{1}{\gamma-\psi_{m, k}}\quad$. (13)
Under the GEL function, the BEs for the reliability and hazard functions are given respectively by:
$\left.\begin{array}{c}\tilde{R}_{G E}=\left(1+\frac{\lambda \ln \left(1-t^{\alpha}\right)}{\gamma-\psi_{m, k}}\right)^{(m+\eta) / \lambda}\quad, \\ \widetilde{H}_{G E}=\frac{\alpha t^{\alpha-1}}{\left(\gamma-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\left(\frac{\Gamma(m+\eta)}{\Gamma(m+\eta-\lambda)}\right)^{1 / \lambda}\quad.\end{array}\right\}$ (14)
It can be observed from the above equation that the $\mathrm{BE} \tilde{\beta}_{S L}$ of the parameter $\beta$ under the SEL function is a special case $(\lambda=-1)$. Using Eq. (6), the BE of $\beta$ under the LINEX function is given by:
$\tilde{\beta}_{L I}=-\frac{1}{c} \ln \left(\frac{\phi(\eta, \gamma+c)}{\phi(\eta, \gamma)}\right)$$=\frac{m+\eta}{c} \ln \left(1+\frac{c}{\gamma-\psi_{m, k}}\right)$, (15)
where, $c \neq 0$. Similarly, the BEs for the reliability and hazard functions are given respectively by:
$\tilde{R}_{L I}=-\frac{1}{c} \ln \left(\sum_{i=0}^{\infty} \frac{(-c)^{i}}{i !}\left(1-\frac{i \ln \left(1-t^{\alpha}\right)}{\gamma-\psi_{m, k}}\right)^{-(m+\eta)}\right)$, (16)
and
$\widetilde{H}_{L I}=\frac{m+\eta}{c} \ln \left(1+\frac{c \alpha t^{\alpha-1}}{\left(\gamma-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)$. (17)
The prior parameters $\eta$ and $\gamma$ should be selected to guarantee that $\pi(\beta)$ is a decreasing function of $\beta$, as presented in Ref. [24]. The derivative of $\pi(\beta)$ with respect to $\beta$ is:
$\frac{\mathrm{d} \pi(\beta)}{\mathrm{d} \beta}=\frac{\gamma^{\eta}}{\Gamma(\eta)} \beta^{\eta-2}(\eta-\gamma \beta-1) \exp [-\gamma \beta]$. (18)
It is well known that $\eta>0, \gamma>0$ and $\beta>0$, it follows $0<\eta<1, \gamma>0$ due to $\mathrm{d} \pi(\beta) / \mathrm{d} \beta<0$ and therefore $\pi(\beta)$ is a decreasing function of $\beta$. Assuming that $\eta$ and $\gamma$ are independent with bivariate density function $\pi(\eta, \gamma)=$ $\pi_{1}(\eta) \pi_{2}(\gamma) .$ Then, the E-BE of $\beta($ expectation of the BE of $\beta)$ can be written as:
$\tilde{\beta}_{E-B}=\iint_{D} \tilde{\beta}_{B}(\eta, \gamma) \pi(\eta, \gamma) \mathrm{d} \gamma \mathrm{d} \eta$, (19)
where, $D$ be the set of all the possible values of $\gamma$ and $\eta$, $\tilde{\beta}_{B}(\eta, \gamma)$ is the $\mathrm{BE}$ of $\beta$ under $\mathrm{AL}$, GEL and LINEX loss functions E-BE based on three different distributions of the hyper-parameters $\eta$ and $\gamma$ is obtained in this subsection, to investigate the influence of different prior distributions on the $\mathrm{E}-\mathrm{BE}$ of $\beta .$ The following prior density functions, suggested by Okasha and Wang [26], of $\eta$ and $\gamma$ may be used:
$\pi_{1}(\eta, \gamma)=\frac{1}{(\epsilon-1) B(a, b)} \eta^{a-1}(1-\eta)^{b-1}$, (20)
$\pi_{2}(\eta, \gamma)=\frac{2(\epsilon-\gamma)}{(\epsilon-1)^{2} B(a, b)} \eta^{a-1}(1-\eta)^{b-1}$, (21)
$\pi_{3}(\eta, \gamma)=\frac{2 \gamma}{\left(\epsilon^{2}-1\right) B(a, b)} \eta^{a-1}(1-\eta)^{b-1}$, (22)
where, $0<\eta<1,1<\gamma<\epsilon$ and $B(a, b)$ is the beta function. For the prior density functions $(20-22)$ and using Eqns. (11) and (19), the corresponding E-BEs of $\beta$ based on AL function are respectively:
$\tilde{\beta}_{A L_{1}}=\frac{1}{(\epsilon-1) B(a, b)} \int_{0}^{1} \int_{1}^{\epsilon} \frac{m+\eta+q}{\gamma-\psi_{m, k}}$$\times \eta^{a-1}(1-\eta)^{b-1} \mathrm{~d} \gamma \mathrm{d} \eta$$=\frac{1}{(\epsilon-1)}\left(m+q+\frac{a}{a+b}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$, (23)
$\tilde{\beta}_{A L_{2}}=\frac{2}{(\epsilon-1)^{2}}\left(m+q+\frac{a}{a+b}\right)$$\times\left\{1-\epsilon+\left(\epsilon-\psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$, (24)
$\tilde{\beta}_{A L_{3}}=\frac{2}{\epsilon^{2}-1}\left(m+q+\frac{a}{a+b}\right)$$\times\left\{\epsilon-1+\psi_{m, k} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$. (25)
Similarly, by using Eqns. (13), (19), (20)-(22), the E-BEs of β based on GEL function can be expressed respectively as:
$\tilde{\beta}_{G E_{1}}=\frac{G(\lambda)}{(\epsilon-1) B(a, b)} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$, (26)
$\tilde{\beta}_{G E_{2}}=\frac{2 G(\lambda)}{(\epsilon-1) B(a, b)}$$\times\left\{-1+\left(\frac{\epsilon-\psi_{m, k}}{\epsilon-1}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$, (27)
$\tilde{\beta}_{G E_{3}}=\frac{2 G(\lambda)}{(\epsilon+1) B(a, b)}\left\{1+\frac{\psi_{m, k}}{\epsilon-1} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$, (28)
where,
$G(\lambda)=\int_{0}^{1} \eta^{a-1}(1-\eta)^{b-1}\left(\frac{\Gamma(m+\eta-\lambda)}{\Gamma(m+\eta)}\right)^{-1 / \lambda} \mathrm{d} \eta$. (29)
It is obvious that the exact form of the integration in (29) will not be tractable and then its direct computation will not be an easy task. Therefore, numerical integration methods can be implemented to compute the E-BEs of β based on GEL function.
Lemma 4.1. For $\lambda<m+\eta$ and $0<\eta<1$, we have $G(\lambda)>0$.
Proof. Since $\eta$ and $\left(\frac{\Gamma(m+\eta-\lambda)}{\Gamma(m+\eta)}\right)^{-1 / \lambda}$ are continuous on [0,1], according to the extended case of mean value theorem for definite integrals, there is at least one number $\eta_{0}$ between 0 and 1 such that:
$\int_{0}^{1} \eta^{a-1}(1-\eta)^{b-1}\left(\frac{\Gamma(m+\eta-\lambda)}{\Gamma(m+\eta)}\right)^{-1 / \lambda} \mathrm{d} \eta$$=\left(\frac{\Gamma\left(m+\eta_{0}-\lambda\right)}{\Gamma\left(m+\eta_{0}\right)}\right)^{-1 / \lambda} \int_{0}^{1} \eta^{a-1}(1-\eta)^{b-1} \mathrm{~d} \eta$$=\left(\frac{\Gamma\left(m+\eta_{0}-\lambda\right)}{\Gamma\left(m+\eta_{0}\right)}\right)^{-1 / \lambda} \quad B(a, b)>0$. (30)
Thus, the proof is completed.
In the same manner, using Eqns. (15) and (19), the E-BEs of β based on LINEX loss function are respectively:
$\tilde{\beta}_{L I_{1}}=\frac{1}{(\epsilon-1) B(a, b)} \int_{0}^{1} \int_{1}^{\epsilon} \frac{m+\eta}{c} \ln \left(1+\frac{c}{\gamma-\psi_{m, k}}\right)$$\times \eta^{a-1}(1-\eta)^{b-1} \mathrm{~d} \gamma \mathrm{d} \eta$
$=\frac{1}{c(\epsilon-1)}\left(m+\frac{a}{a+b}\right)\left\{\operatorname{c} \ln \left(\frac{c+\epsilon-\psi_{m, k}}{1+c-\psi_{m, k}}\right)\right.$$-\left(1-\psi_{m, k}\right) \ln \left(1+\frac{c}{1-\psi_{m, k}}\right)$$\left.+\left(\epsilon-\psi_{m, k}\right) \times \ln \left(1+\frac{c}{\epsilon-\psi_{m, k}}\right)\right\}$, (31)
$\begin{aligned} \tilde{\beta}_{L l_{2}}=\frac{1}{c(\epsilon-1)^{2}} &\left(m+\frac{a}{a+b}\right)\{\mathrm{c}(1-\epsilon)\\ &+\left(1-2 \epsilon \bar{\psi}_{m, k}\right.\\ &\left.-\psi_{m, k}^{2}\right) \ln \left(1+\frac{c}{1-\psi_{m, k}}\right) \\ &+c(c+2 \epsilon\\ &\left.-2 \psi_{m, k}\right) \ln \left(\frac{c+\epsilon-\psi_{m, k}}{1+\mathrm{c}-\psi_{m, k}}\right) \\ &+(\epsilon\\ &\left.\left.-\psi_{m, k}\right)^{2} \ln \left(1+\frac{c}{\epsilon-\psi_{m, k}}\right)\right\}, \end{aligned}$ (32)
$\begin{aligned} \tilde{\beta}_{L I_{3}}=\frac{1}{c\left(\epsilon^{2}-1\right)} &\left(m+\frac{a}{a+b}\right)\{\mathrm{c}(\epsilon-1)\\ &-\ln \left(1+\frac{c}{1-\psi_{m, k}}\right) \\ &+\epsilon^{2} \ln \left(1+\frac{c}{\epsilon-\psi_{m, k}}\right) \\ &+\psi_{m, k}^{2} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right) \\ &-\left(c-\psi_{m, k}\right)^{2} \\ &\left.\times \ln \left(\frac{c+\epsilon-\psi_{m, k}}{1+\mathrm{c}-\psi_{m, k}}\right)\right\} \end{aligned}$, (33)
where, $\bar{\psi}=1-\psi$.
4.1 Property of E-BE of β
Here, we shall discuss property of the E-BE relations between the $\tilde{\beta}_{A L_{j}}(j=1,2,3)$, as well as the relations between $\tilde{\beta}_{G E_{j}}(j=1,2,3)$ and also relations among $\tilde{\beta}_{L I_{j}}(j=1,2,3)$.
Theorem 4.2. Let $\epsilon>1$ and let $\tilde{\beta}_{A L_{j}}, \tilde{\beta}_{G E_{j}}$ and $\tilde{\beta}_{L I_{j}}, j=$ $1,2,3$ be given by $(23-28,31-33)$. Then
Proof. See Appendix A.
Theorem 4.3. Let $\epsilon>1$ and let $\tilde{\beta}_{A L_{j}}, \tilde{\beta}_{G E_{j}}$ and $\tilde{\beta}_{L I_{j}}, j=$ $1,2,3$ be given by $(23-28,31-33)$. Then
Proof. See Appendix A.
4.2 E-BE for the reliability and hazard functions
Under the AL function, the E-BE of $R(t)$ is obtained for the prior density functions given by Eqns. (20)-(22) as:
$\tilde{R}_{A L_{1}}=\iint_{D} \tilde{R}_{A L} \pi_{1}(\eta, \gamma) \mathrm{d} \gamma \mathrm{d} \eta$
$=\frac{1}{\epsilon-1} \int_{1}^{\epsilon}\left(\xi_{q}(\gamma)\right)^{-m}{ }_{1} F_{1}\left(a, a+b,-\ln \xi_{q}(\gamma)\right) \mathrm{d} \gamma$,
$\tilde{R}_{A L_{2}}=\frac{2}{(\epsilon-1)^{2}} \int_{1}^{\epsilon}(\epsilon-\gamma)\left(\xi_{q}(\gamma)\right)^{-m}$$\times{ }_{1} F_{1}\left(a, a+b,-\ln \xi_{q}(\gamma)\right) \mathrm{d} \gamma$,
$\tilde{R}_{A L_{3}}=\frac{2}{\epsilon^{2}-1} \int_{1}^{\epsilon} \gamma\left(\xi_{q}(\gamma)\right)^{-m}{ }_{1} F_{1}\left(a, a+b,-\ln \xi_{q}(\gamma)\right) \mathrm{d} \gamma$,
where, ${ }_{1} F_{1}(a, b, z)$ is the Kummer confluent hypergeometric function defined and available in MATHEMATICA and,
$\xi_{q}(\gamma)=1-\frac{\ln \left(1-t^{\alpha}\right)}{\gamma-\psi_{m, k}-q \ln \left(1-t^{\alpha}\right)}\quad$.
It is obvious that the form of above equations will not be tractable and then its direct computation will be impossible. Therefore, numerical computations must be used to compute this parametric function. Using Eqns. (20)-(22), it follows that the E-BE of $H(t)$ based on AL function are given, respectively, as:
$\widetilde{H}_{A L_{1}}=\iint_{D} \widetilde{H}_{A L} \pi_{1}(\eta, \gamma) \mathrm{d} \gamma \mathrm{d} \eta$$=\frac{\alpha t^{\alpha-1}}{(\epsilon-1)\left(1-t^{\alpha}\right)}\left(m+q+\frac{a}{a+b}\right)$$\times \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$, (34)
$\widetilde{H}_{A L_{2}}=\frac{2 \alpha t^{\alpha-1}}{(\epsilon-1)^{2}\left(1-t^{\alpha}\right)}\left(m+q+\frac{a}{a+b}\right)$$\quad \times\left\{1-\epsilon+\left(\epsilon-\psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$, (35)
$\begin{aligned} \widetilde{H}_{A L_{3}} &=\frac{2 \alpha t^{\alpha-1}}{\left(\epsilon^{2}-1\right)\left(1-t^{\alpha}\right)}\left(m+q+\frac{a}{a+b}\right) \\ & \times\left\{\epsilon-1+\psi_{m, k} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\} \end{aligned}$. (36)
Under the GEL function, and by using Eqns. (20)-(22), the E-BEs of $R(t)$ and $H(t)$ are given by:
$\tilde{R}_{G E_{1}}=\frac{1}{\epsilon-1} \int_{1}^{\epsilon}\left(T_{\lambda}(\gamma)\right)^{m / \lambda}{ }_{1} F_{1}\left(a, a+b, \frac{\ln T_{\lambda}(\gamma)}{\lambda}\right) d \gamma$, (37)
$\tilde{R}_{G E_{2}}=\frac{2}{(\epsilon-1)^{2}} \int_{1}^{\epsilon}(\epsilon-\gamma)\left(T_{\lambda}(\gamma)\right)^{m / \lambda}$$\times{ }_{1} F_{1}\left(a, a+b, \frac{\ln T_{\lambda}(\gamma)}{\lambda}\right) d \gamma$, (38)
$\tilde{R}_{G E_{3}}=\frac{2}{\epsilon^{2}-1} \int_{1}^{\epsilon} \gamma\left(T_{\lambda}(\gamma)\right)^{\frac{m}{\lambda}}$$\times{ }_{1} F_{1}\left(a, a+b, \frac{\ln T_{\lambda}(\gamma)}{\lambda}\right) d \gamma$, (39)
where,
$T_{\lambda}(\gamma)=1+\frac{\lambda \ln \left(1-t^{\alpha}\right)}{\gamma-\psi_{m, k}}$.
It does not seem possible to obtain the E-BEs in Eqns. (37)-(39) in an explicit form and would of course require numerical integration. Similarly, in making use of (2) and (9), the E-BEs of $H(t)$ based on GEL function are given respectively by:
$\widetilde{H}_{G E_{1}}=\frac{\alpha t^{\alpha-1} G(\lambda)}{(\epsilon-1)\left(1-t^{\alpha}\right) B(a, b)} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$, (40)
$\widetilde{H}_{G E_{2}}=\frac{2 \alpha t^{\alpha-1} G(\lambda)}{(\epsilon-1)\left(1-t^{\alpha}\right) B(a, b)}$$\times\left\{1-\frac{\epsilon-\psi_{m, k}}{\epsilon-1} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$, (41)
$\widetilde{H}_{G E_{3}}=\frac{2 \alpha t^{\alpha-1} G(\lambda)}{(\epsilon+1)\left(1-t^{\alpha}\right) B(a, b)}$$\times\left\{1+\frac{\psi_{m, k}}{\epsilon-1} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$, (42)
where, $G(\lambda)$ is given by $(29)$. Under the LINEX loss function, and by using Eqns. (20)-(22), the E-BEs of $R(t)$ and $H(t)$ are given by:
$\tilde{R}_{L I_{j}}=-\frac{1}{c} \int_{0}^{1} \int_{1}^{\epsilon} \ln \left[\sum_{i=1}^{\infty} \frac{(-c)^{i}}{i !}\left(1-\frac{i \ln \left(1-t^{\alpha}\right)}{\gamma-\psi_{m, k}}\right)^{-(m+\eta)}\right]$$\times \pi_{j}(\eta, \gamma) \mathrm{d} \gamma \mathrm{d} \eta, \quad j=1,2,3$, (43)
and,
$\widetilde{H}_{G E_{1}}$$=\frac{\alpha t^{\alpha-1} G(\lambda)}{(\epsilon-1)\left(1-t^{\alpha}\right) B(a, b)} \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$
$-\left(1-\psi_{m, k}\right) \ln \left(\frac{\zeta(1)}{\left(1-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)$
$\left.+\left(\epsilon-\psi_{m, k}\right) \times \ln \left(\frac{\zeta(\epsilon)}{\left(\epsilon-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)\right\}$, (44)
$\begin{aligned} \widetilde{H}_{L I_{2}}=\frac{1}{c(\epsilon-1)^{2}} &\left(m+\frac{a}{a+b}\right)\left\{\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}(1-\epsilon)+\left(1-2 \epsilon \bar{\psi}_{m, k}-\psi_{m, k}^{2}\right) \ln \left(\frac{\zeta(1)}{\left(1-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)\right.\\+&\left.\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}\left(\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}+2 \epsilon-2 \psi_{m, k}\right) \ln \left(\frac{\zeta(\epsilon)}{\zeta(1)}\right)+\left(\epsilon-\psi_{m, k}\right)^{2} \ln \left(\frac{\zeta(\epsilon)}{\left(\epsilon-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)\right\}, \end{aligned}$ (45)
$\begin{aligned} \widetilde{H}_{L I_{3}}=& \frac{1}{\mathrm{c}\left(\epsilon^{2}-1\right)}\left(m+\frac{a}{a+b}\right)\left\{\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}(\epsilon-1)-\left(\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}-\psi_{m, k}\right)^{2} \ln \left(\frac{\zeta(\epsilon)}{\zeta(1)}\right)+\psi_{m, k}^{2}\right.\\ &\left.\times \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)-\ln \left(\frac{\zeta(1)}{\left(1-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)+\epsilon^{2} \ln \left(\frac{\zeta(\epsilon)}{\left(\epsilon-\psi_{m, k}\right)\left(1-t^{\alpha}\right)}\right)\right\} \end{aligned}$, (46)
where, $\zeta(\epsilon)=c \alpha t^{\alpha-1}+\left(\epsilon-\psi_{m, k}\right)\left(1-t^{\alpha}\right)$.
4.3 Property of E-BE of H(t)
Now, we shall discuss the property of the E-BE relations between the $\widetilde{H}_{A L_{j}}(j=1,2,3)$, as well as relations among $\widetilde{H}_{G E_{j}}(j=1,2,3)$ and $\widetilde{H}_{L I_{j}}(j=1,2,3)$.
Theorem 4.4. Let $\epsilon>1$ and let $\widetilde{H}_{A L_{j}}, \widetilde{H}_{G E_{j}}$ and $\widetilde{H}_{L I_{j}}, j=$ $1,2,3$ be given by $(34-36,40-42,44-46)$. Then,
Proof. See Appendix B, for the proof.
Theorem 4.5. Let $\epsilon>1$ and let $\widetilde{H}_{A L_{j}}, \widetilde{H}_{G E_{j}}$ and $\widetilde{H}_{L I_{j}}, j=$ $1,2,3$ be given by $(34-36,40-42,44-46)$. Then
Proof. By using the same lines as in theorem 4.3, it is easy to get the stated result.
In this section, we conduct a Monte Carlo (MC) simulation study to illustrate our previous theoretical results and we consider a simulated data set and another real data set. All the computations are conducted using Mathematica software.
5.1 Simulation study
In this section, we conduct a comprehensive simulation study to illustrate the inferential procedures for estimating the model parameters and some survival time parameters of the removed units in the progressively first failure censored KW data. Here, a MC simulation is used for a comparison between the performances of the E-BEs and the BEs for different CSs. The following steps describe our methodology:
$\operatorname{MSE}\left(\tilde{\vartheta}_{j}\right)=\frac{1}{10000} \sum_{i=1}^{10000}\left(\tilde{\vartheta}_{j, i}-\overline{\tilde{\vartheta}}_{\jmath}\right)^{2}, j=1,2,3$,
where, $\tilde{\vartheta}_{1}=\tilde{\beta}, \tilde{\vartheta}_{2}=\tilde{R}(t), \tilde{\vartheta}_{3}=\widetilde{H}(t)$ and,
$\overline{\tilde{\vartheta}}_{J}=\frac{1}{10000} \sum_{i=1}^{10000} \tilde{\vartheta}_{j, i}$.
The results are displayed in Tables 4-9, for different choices of k.
Table 1. CSs
|
Scheme |
(n,m) |
CS |
|
R1 |
(50,35) |
(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,20*0) |
|
R2 |
(50,35) |
(10*0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,10*0) |
|
R3 |
(50,35) |
(20*0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1) |
|
R4 |
(25,15) |
(10,14*0) |
|
R5 |
(25,15) |
(7*0,10,7*0) |
|
R6 |
(25,15) |
(14*0,10) |
5.2 Data analysis (Tensile strength)
Here in this section, we discuss the analyses of the censored data produced from practical experiments with KW fitting distribution. Table 2, the data on the measurements on the tensile strength of polyester fibers to see if they were consistent with the lognormal distribution, was given by Quesenberry and Hales [36]. We first check whether the Kumaraswamy model is appropriate for this data set by using the Kaplan-Meier [37] estimator (KME) and Kolmogorov-Smirnov (KS) distance. Based on the data set in Table 2, the maximum likelihood estimator of β with α(known)=0.5, 0.7 is obtained to be $\tilde{\beta}=0.9672$. To test the null hypothesis $H_{0}: F(x)=$ KW distribution $\quad$ vs. $\quad H_{1}: F(x) \neq$ KW distribution.
Table 2. Measurements on the tensile strength of polyester fibers
|
Real Data Set |
|||||
|
0.023 |
0.032 |
0.054 |
0.069 |
0.081 |
0.094 |
|
0.105 |
0.127 |
0.148 |
0.169 |
0.188 |
0.216 |
|
0.255 |
0.277 |
0.311 |
0.361 |
0.376 |
0.395 |
|
0.432 |
0.463 |
0.481 |
0.519 |
0.529 |
0.567 |
|
0.642 |
0.674 |
0.752 |
0.823 |
0.887 |
0.926 |
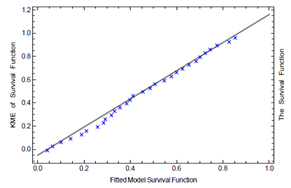
We reject $H_{0}$ (and accept $H_{1}$ ) at a significance level of $\tau=$ $0.05$ if $p-$ value $<\tau$. Table 3 gives the Anderson-Darling (AD), Cramer-von Mises (CvonM), KS distance, Mardia skewness (MS), Pearson $\chi^{2}$ and Watson $U^{2}$ statistics and the corresponding $p-$ values. The $P-P$ plot of $\mathrm{KME}$ versus fitted survival function as well as empirical and fitted survival functions are presented in Figures 1 and 2. Table 3 and Figures, 1 and 2 indicate clearly that the KW distribution fits the data set well.
Now, we assume that the measurements on the tensile strength of polyester fibers are randomly grouped into 15 groups with k=2 carbon fibers within each group. The tensile strength of polyester fibers of the groups are:
$\{0.023,0.032\},\{0.054,0.069\},\{0.081,0.094\},\{0.105,0.127\}$,
$\{0.148,0.169\},\{0.188,0.216\},\{0.255,0.277\},\{0.311,0.361\}$,
$\{0.376,0.395\},\{0.432,0.463\},\{0.481,0.519\},\{0.529,0.567\}$,
$\{0.642,0.674\},\{0.752,0.823\},\{0.887,0.926\} .$
Suppose that the pre-determined progressively first-failure censoring plan is applied using progressive censoring scheme: $\boldsymbol{R}=(1,1,1,1,1,0,0,0,0,0)$. The progressively first-failurecensored sample of size $(m=10)$ out of 15 groups was taken as follows: $0.023,0.081,0.148,0.255,0.376,0.481,0.529$, $0.642,0.752,0.887$. The estimates of the parameter $\beta, R(t)$ and $H(t)$ with $t=0.5$ are obtained in Table 10 .
Table 3. The statistics and the corresponding p−values of the real data sets
|
|
AD |
CvonM |
KS |
MS |
Pearson $\chi^{2}$ |
Watson $U^{2}$ |
|
Statistic |
0.6080 |
0.0839 |
0.1164 |
1.4929 |
5.2000 |
0.0735 |
|
p- value |
0.1118 |
0.1842 |
0.3741 |
0.2218 |
0.3920 |
0.2228 |
Table 4. MSEs of the estimates of β when k=2
|
|
|
|
BE |
|
E-BE |
||||
|
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
|
|
|||||||||
|
$\boldsymbol{R}_{1}$ |
0.3 |
$\tilde{\beta}$ |
(0.00235,0.00268) |
(0.00291,0.00290) |
(0.00289,0.00297) |
$\tilde{\beta}_{1}$ |
(0.00234,0.00261) |
(0.00282,0.00283) |
(0.00272,0.00283) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00235,0.00263) |
(0.00288,0.00287) |
(0.00277,0.00287) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00233,0.00260) |
(0.00279,0.00280) |
(0.11259,0.10754) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.01343,0.01456) |
(0.01559,0.01535) |
(0.01679,0.01621) |
$\tilde{\beta}_{1}$ |
(0.01342,0.01419) |
(0.01465,0.01466) |
(0.01528,0.01510) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.01346,0.01438) |
(0.01526,0.01511) |
(0.01593,0.01559) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.01342,0.01411) |
(0.01436,0.01445) |
(0.59743,0.55273) |
|
$\boldsymbol{R}_{2}$ |
0.3 |
$\tilde{\beta}$ |
(0.00266,0.00236) |
(0.00314,0.00255) |
(0.00313,0.00262) |
$\tilde{\beta}_{1}$ |
(0.00265,0.00231) |
(0.00305,0.00249) |
(0.00296,0.00249) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00266,0.00233) |
(0.00311,0.00253) |
(0.00302,0.00253) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00265,0.00230) |
(0.00302,0.00247) |
(0.11018,0.10538) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.01341,0.01343) |
(0.01527,0.01446) |
(0.01645,0.01538) |
$\tilde{\beta}_{1}$ |
(0.01346,0.01294) |
(0.01438,0.01370) |
(0.01501,0.01414) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.01348,0.01317) |
(0.01496,0.01419) |
(0.01563,0.01468) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.01347,0.01284) |
(0.01411,0.01347) |
(0.58867,0.56988) |
|
$\boldsymbol{R}_{3}$ |
0.3 |
$\tilde{\beta}$ |
(0.00263,0.00259) |
(0.00307,0.00281) |
(0.00306,0.00288) |
$\tilde{\beta}_{1}$ |
(0.00262,0.00253) |
(0.00298,0.00274) |
(0.00290,0.00274) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00263,0.00255) |
(0.00304,0.00278) |
(0.00295,0.00278) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00262,0.00252) |
(0.00296,0.00272) |
(0.10913,0.10704) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.01460,0.01360) |
(0.01592,0.01423) |
(0.01710,0.01499) |
$\tilde{\beta}_{1}$ |
(0.01474,0.01334) |
(0.01509,0.01363) |
(0.01578,0.01401) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.01474,0.01348) |
(0.01564,0.01402) |
(0.01636,0.01444) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.01477,0.01328) |
(0.01484,0.01345) |
(0.57251,0.54197) |
|
$\boldsymbol{R}_{4}$ |
0.3 |
$\tilde{\beta}$ |
(0.00635,0.00756) |
(0.00917,0.00913) |
(0.00933,0.00976) |
$\tilde{\beta}_{1}$ |
(0.00628,0.00700) |
(0.00859,0.00858) |
(0.00826,0.00867) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00635,0.00720) |
(0.00897,0.00894) |
(0.00862,0.00903) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00626,0.00690) |
(0.00840,0.00840) |
(0.14295,0.14312) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.03407,0.02840) |
(0.04069,0.03196) |
(0.04962,0.03654) |
$\tilde{\beta}_{1}$ |
(0.03509,0.02720) |
(0.03590,0.02870) |
(0.04110,0.03087) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.03497,0.02783) |
(0.03906,0.03083) |
(0.04500,0.03336) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.03525,0.02698) |
(0.03445,0.02775) |
(0.69177,0.61575) |
|
$\boldsymbol{R}_{5}$ |
0.3 |
$\tilde{\beta}$ |
(0.00598,0.00617) |
(0.00889,0.00752) |
(0.00899,0.00803) |
$\tilde{\beta}_{1}$ |
(0.00592,0.00575) |
(0.00833,0.00707) |
(0.00792,0.00711) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00598,0.00590) |
(0.00870,0.00736) |
(0.00827,0.00740) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00590,0.00568) |
(0.00814,0.00692) |
(0.14415,0.13617) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.02992,0.02896) |
(0.03370,0.03207) |
(0.04012,0.03648) |
$\tilde{\beta}_{1}$ |
(0.03185,0.02796) |
(0.02997,0.02896) |
(0.03352,0.03110) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.03128,0.02853) |
(0.03241,0.03099) |
(0.03641,0.03348) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.03222,0.02778) |
(0.02887,0.02806) |
(0.65028,0.60192) |
|
$\boldsymbol{R}_{6}$ |
0.3 |
$\tilde{\beta}$ |
(0.00639,0.00599) |
(0.00984,0.00721) |
(0.01000,0.00769) |
$\tilde{\beta}_{1}$ |
(0.00624,0.00562) |
(0.00920,0.00679) |
(0.00879,0.00683) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00633,0.00575) |
(0.00963,0.00707) |
(0.00919,0.00711) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00620,0.00555) |
(0.00899,0.00665) |
(0.15141,0.13238) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.02788,0.02926) |
(0.03315,0.03291) |
(0.03978,0.03761) |
$\tilde{\beta}_{1}$ |
(0.02960,0.02797) |
(0.02920,0.02957) |
(0.03271,0.03181) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.02908,0.02865) |
(0.03179,0.03176) |
(0.03578,0.03437) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.02994,0.02773) |
(0.02802,0.02860) |
(0.67157,0.61846) |
|
$\tilde{\beta}_{i}$ is the E-BE of $\beta$ based on $\pi_{i}(\eta, \gamma), i=1,2,3$. |
|||||||||
Table 5. MSEs of the estimates of β when k=5
|
|
|
|
BE |
|
E-BE |
||||
|
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
|
|
|||||||||
|
$\boldsymbol{R}_{1}$ |
0.3 |
$\tilde{\beta}$ |
(0.00267,0.00235) |
(0.00312,0.00254) |
(0.00311,0.00261) |
$\tilde{\beta}_{1}$ |
(0.00267,0.00229) |
(0.00303,0.00248) |
(0.00295,0.00248) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00268,0.00231) |
(0.00309,0.00252) |
(0.00300,0.00252) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00267,0.00228) |
(0.00300,0.00246) |
(0.10922,0.10568) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.01464,0.01338) |
(0.01653,0.01397) |
(0.01779,0.01470) |
$\tilde{\beta}_{1}$ |
(0.01466,0.01316) |
(0.01560,0.01339) |
(0.01630,0.01376) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.01470,0.01328) |
(0.01621,0.01377) |
(0.01695,0.01418) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.01465,0.01311) |
(0.01531,0.01322) |
(0.58953,0.53873) |
|
$\boldsymbol{R}_{2}$ |
0.3 |
$\tilde{\beta}$ |
(0.00264,0.00254) |
(0.00323,0.00279) |
(0.00321,0.00287) |
$\tilde{\beta}_{1}$ |
(0.00261,0.00247) |
(0.00313,0.00272) |
(0.00303,0.00272) |
|
|
$\tilde{\beta}_{2}$ |
(0.00263,0.00249) |
(0.00319,0.00277) |
(0.00309,0.00276) |
|||||
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00261,0.00245) |
(0.00310,0.00270) |
(0.11353,0.10964) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.01371,0.01368) |
(0.01494,0.01450) |
(0.01602,0.01534) |
$\tilde{\beta}_{1}$ |
(0.01390,0.01331) |
(0.01416,0.01381) |
(0.01477,0.01424) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.01387,0.01350) |
(0.01467,0.01426) |
(0.01531,0.01472) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.01394,0.01323) |
(0.01392,0.01361) |
(0.56977,0.55469) |
|
$\boldsymbol{R}_{3}$ |
0.3 |
$\tilde{\beta}$ |
(0.00244,0.00278) |
(0.00292,0.00306) |
(0.00290,0.00315) |
$\tilde{\beta}_{1}$ |
(0.00243,0.00269) |
(0.00283,0.00298) |
(0.00274,0.00298) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00244,0.00272) |
(0.00289,0.00303) |
(0.00279,0.00303) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00242,0.00267) |
(0.00280,0.00295) |
(0.11042,0.11180) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.01418,0.01365) |
(0.01541,0.01447) |
(0.01651,0.01530) |
$\tilde{\beta}_{1}$ |
(0.01436,0.01329) |
(0.01462,0.01379) |
(0.01525,0.01420) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.01433,0.01347) |
(0.01514,0.01423) |
(0.01580,0.01468) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.01439,0.01322) |
(0.01438,0.01359) |
(0.56989,0.55466) |
|
$\boldsymbol{R}_{4}$ |
0.3 |
$\tilde{\beta}$ |
(0.00629,0.00655) |
(0.00951,0.00788) |
(0.00963,0.00842) |
$\tilde{\beta}_{1}$ |
(0.00617,0.00612) |
(0.00889,0.00741) |
(0.00849,0.00748) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00624,0.00628) |
(0.00930,0.00772) |
(0.00886,0.00779) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00614,0.00605) |
(0.00870,0.00726) |
(0.14830,0.13559) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.03094,0.03001) |
(0.03698,0.03398) |
(0.04489,0.03892) |
$\tilde{\beta}_{1}$ |
(0.03228,0.02848) |
(0.03256,0.03044) |
(0.03701,0.03280) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.03197,0.02927) |
(0.03546,0.03275) |
(0.04054,0.03551) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.03252,0.02820) |
(0.03123,0.02940) |
(0.68310,0.62811) |
|
$\boldsymbol{R}_{5}$ |
0.3 |
$\tilde{\beta}$ |
(0.00572,0.00653) |
(0.00803,0.00791) |
(0.00812,0.00845) |
$\tilde{\beta}_{1}$ |
(0.00574,0.00608) |
(0.00753,0.00744) |
(0.00720,0.00749) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00577,0.00625) |
(0.00787,0.00775) |
(0.00750,0.00780) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00573,0.00601) |
(0.00737,0.00728) |
(0.13622,0.13717) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.03130,0.02983) |
(0.03640,0.03391) |
(0.04363,0.03889) |
$\tilde{\beta}_{1}$ |
(0.03287,0.02827) |
(0.03227,0.03034) |
(0.03631,0.03271) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.03246,0.02906) |
(0.03498,0.03268) |
(0.03955,0.03544) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.03317,0.02797) |
(0.03104,0.02929) |
(0.66926,0.63142) |
|
$\boldsymbol{R}_{6}$ |
0.3 |
$\tilde{\beta}$ |
(0.00664,0.00643) |
(0.01025,0.00777) |
(0.01042,0.00829) |
$\tilde{\beta}_{1}$ |
(0.00645,0.00601) |
(0.00958,0.00732) |
(0.00917,0.00737) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00655,0.00616) |
(0.01003,0.00762) |
(0.00958,0.00766) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00641,0.00594) |
(0.00936,0.00718) |
(0.15363,0.13604) |
|
|
0.7 |
$\tilde{\beta}$ |
(0.02995,0.03123) |
(0.03710,0.03509) |
(0.04500,0.04011) |
$\tilde{\beta}_{1}$ |
(0.03115,0.02970) |
(0.03254,0.03151) |
(0.03686,0.03396) |
|
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.03088,0.03051) |
(0.03554,0.03385) |
(0.04047,0.03671) |
|
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.03137,0.02939) |
(0.03117,0.03046) |
(0.69855,0.62440) |
|
$\tilde{\beta}_{i}$ is the E-BE of $\beta$ based on $\pi_{i}(\eta, \gamma), i=1,2,3$. |
|||||||||
Table 6. MSEs of the estimates of R(t) when t=0.5 and k=2
|
|
|
|
BE |
|
E-BE |
||||
|
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
|
|
|||||||||
|
$\boldsymbol{R}_{1}$ |
0.3 |
$\widetilde{R}$ |
(0.00202,0.00199) |
(0.00174,0.00189) |
(0.00173,0.00187) |
$\tilde{R}_{1}$ |
(0.00191,0.00192) |
(0.00167,0.00184) |
(0.12072,0.12012) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00194,0.00194) |
(0.00169,0.00186) |
(0.12098,0.12038) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00190,0.00191) |
(0.00167,0.00183) |
(0.26973,0.26926) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00422,0.00382) |
(0.00343,0.00362) |
(0.00349,0.00363) |
$\tilde{R}_{1}$ |
(0.00395,0.00372) |
(0.00344,0.00363) |
(0.04358,0.04308) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00407,0.00377) |
(0.00344,0.00364) |
(0.04408,0.04357) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00389,0.00369) |
(0.00334,0.00363) |
(0.09927,0.09887) |
|
$\boldsymbol{R}_{2}$ |
0.3 |
$\widetilde{R}$ |
(0.00219,0.00179) |
(0.00192,0.00170) |
(0.00192,0.00168) |
$\tilde{R}_{1}$ |
(0.00209,0.00172) |
(0.00187,0.00165) |
(0.11991,0.11994) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00212,0.00174) |
(0.00189,0.00167) |
(0.12017,0.12019) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00207,0.00171) |
(0.00186,0.00164) |
(0.26910,0.26915) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00408,0.00360) |
(0.00335,0.00334) |
(0.00342,0.00334) |
$\tilde{R}_{1}$ |
(0.00382,0.00345) |
(0.00338,0.00331) |
(0.04329,0.04386) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00393,0.00352) |
(0.00338,0.00333) |
(0.04379,0.04437) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00377,0.00342) |
(0.00339,0.00330) |
(0.09906,0.09950) |
|
$\boldsymbol{R}_{3}$ |
0.3 |
$\widetilde{R}$ |
(0.00214,0.00196) |
(0.00189,0.00186) |
(0.00189,0.00184) |
$\tilde{R}_{1}$ |
(0.00205,0.00188) |
(0.00184,0.00181) |
(0.11972,0.12009) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00208,0.00191) |
(0.00186,0.00183) |
(0.11998,0.12035) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00203,0.00187) |
(0.00183,0.00180) |
(0.26896,0.26925) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00416,0.00367) |
(0.00359,0.00350) |
(0.00365,0.00351) |
$\tilde{R}_{1}$ |
(0.00395,0.00358) |
(0.00365,0.00352) |
(0.04258,0.04285) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00404,0.00363) |
(0.00364,0.00352) |
(0.04307,0.04334) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00391,0.00356) |
(0.00366,0.00352) |
(0.09850,0.09872) |
|
$\boldsymbol{R}_{4}$ |
0.3 |
$\widetilde{R}$ |
(0.00598,0.00576) |
(0.00441,0.00511) |
(0.00441,0.00497) |
$\tilde{R}_{1}$ |
(0.00541,0.00527) |
(0.00415,0.00474) |
(0.12020,0.12156) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00560,0.00544) |
(0.00424,0.00487) |
(0.12082,0.12220) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00532,0.00519) |
(0.00410,0.00468) |
(0.26890,0.26985) |
|
|
0.7 |
$\widetilde{R}$ |
(0.01018,0.00784) |
(0.00748,0.00693) |
(0.00774,0.00698) |
$\tilde{R}_{1}$ |
(0.00913,0.00734) |
(0.00788,0.00701) |
(0.03956,0.04088) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00962,0.00759) |
(0.00777,0.00702) |
(0.04062,0.04197) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00891,0.00725) |
(0.00795,0.00703) |
(0.09546,0.09656) |
|
$\boldsymbol{R}_{5}$ |
0.3 |
$\widetilde{R}$ |
(0.00596,0.00499) |
(0.00436,0.00441) |
(0.00436,0.00428) |
$\tilde{R}_{1}$ |
(0.00537,0.00454) |
(0.00408,0.00408) |
(0.12079,0.12143) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00556,0.00469) |
(0.00418,0.00419) |
(0.12142,0.12206) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00528,0.00447) |
(0.00403,0.00403) |
(0.26935,0.26984) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00965,0.00790) |
(0.00712,0.00709) |
(0.00735,0.00716) |
$\tilde{R}_{1}$ |
(0.00862,0.00748) |
(0.00756,0.00724) |
(0.03927,0.04036) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00909,0.00769) |
(0.00743,0.00722) |
(0.04032,0.04144) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00841,0.00740) |
(0.00764,0.00727) |
(0.09529,0.09615) |
|
$\boldsymbol{R}_{6}$ |
0.3 |
$\widetilde{R}$ |
(0.00638,0.00475) |
(0.00460,0.00421) |
(0.00460,0.00409) |
$\tilde{R}_{1}$ |
(0.00573,0.00434) |
(0.00428,0.00391) |
(0.12162,0.12080) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00594,0.00448) |
(0.00439,0.00402) |
(0.12226,0.12142) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00562,0.00427) |
(0.00422,0.00386) |
(0.26994,0.26939) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00952,0.00804) |
(0.00659,0.00712) |
(0.00682,0.00717) |
$\tilde{R}_{1}$ |
(0.00835,0.00754) |
(0.00693,0.00720) |
(0.04007,0.04084) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00888,0.00778) |
(0.00683,0.00721) |
(0.04115,0.04193) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00812,0.00744) |
(0.00700,0.00722) |
(0.09597,0.09651) |
|
$\tilde{R}_{i}$ is the E-BE of $R(t)$ based on $\pi_{i}(\eta, \gamma), i=1,2,3$. |
|||||||||
Table 7. MSEs of the estimates of R(t) when t=0.5 and k=5
|
|
|
|
BE |
|
E-BE |
||||
|
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
|
|
|||||||||
|
$\boldsymbol{R}_{1}$ |
0.3 |
$\widetilde{R}$ |
(0.00216,0.00178) |
(0.00190,0.00189) |
(0.00190,0.00167) |
$\tilde{R}_{1}$ |
(0.00206,0.00171) |
(0.00186,0.00164) |
(0.11969,0.12002) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00209,0.00174) |
(0.00187,0.00166) |
(0.11995,0.12028) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00205,0.00170) |
(0.00185,0.00164) |
(0.26894,0.26921) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00434,0.00362) |
(0.00363,0.00346) |
(0.00370,0.00347) |
$\tilde{R}_{1}$ |
(0.00409,0.00354) |
(0.00366,0.00348) |
(0.04313,0.04277) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00420,0.00358) |
(0.00366,0.00348) |
(0.04363,0.04326) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00404,0.00352) |
(0.00367,0.00349) |
(0.09890,0.09866) |
|
$\boldsymbol{R}_{2}$ |
0.3 |
$\widetilde{R}$ |
(0.00222,0.00196) |
(0.00192,0.00185) |
(0.00192,0.00183) |
$\tilde{R}_{1}$ |
(0.00211,0.00187) |
(0.00186,0.00179) |
(0.12064,0.12074) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00214,0.00190) |
(0.00188,0.00181) |
(0.12090,0.12100) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00209,0.00186) |
(0.00185,0.00178) |
(0.26965,0.26973) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00403,0.00361) |
(0.00345,0.00340) |
(0.00351,0.00341) |
$\tilde{R}_{1}$ |
(0.00382,0.00350) |
(0.00352,0.00340) |
(0.04264,0.04328) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00391,0.00355) |
(0.00350,0.00341) |
(0.04314,0.04378) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00377,0.00348) |
(0.00353,0.00340) |
(0.09856,0.09905) |
|
$\boldsymbol{R}_{3}$ |
0.3 |
$\widetilde{R}$ |
(0.00202,0.00209) |
(0.00176,0.00198) |
(0.00175,0.00195) |
$\tilde{R}_{1}$ |
(0.00192,0.00200) |
(0.00170,0.00190) |
(0.12018,0.12100) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00195,0.00203) |
(0.00172,0.00193) |
(0.12044,0.12126) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00191,0.00199) |
(0.00170,0.00189) |
(0.26932,0.26991) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00415,0.00372) |
(0.00358,0.00351) |
(0.00364,0.00352) |
$\tilde{R}_{1}$ |
(0.00394,0.00361) |
(0.00364,0.00350) |
(0.04258,0.04330) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00404,0.00366) |
(0.00363,0.00352) |
(0.04307,0.04380) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00390,0.00358) |
(0.00366,0.00350) |
(0.09850,0.09906) |
|
$\boldsymbol{R}_{4}$ |
0.3 |
$\widetilde{R}$ |
(0.00626,0.00507) |
(0.00456,0.00449) |
(0.00455,0.00437) |
$\tilde{R}_{1}$ |
(0.00564,0.00464) |
(0.00425,0.00418) |
(0.12120,0.12093) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00585,0.00478) |
(0.00436,0.00429) |
(0.12183,0.12156) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00554,0.00457) |
(0.00420,0.00413) |
(0.26963,0.26945) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00980,0.00809) |
(0.00697,0.00712) |
(0.00722,0.00717) |
$\tilde{R}_{1}$ |
(0.00868,0.00756) |
(0.00734,0.00719) |
(0.03985,0.04102) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00919,0.00782) |
(0.00724,0.00720) |
(0.04092,0.04211) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00846,0.00746) |
(0.00742,0.00720) |
(0.09575,0.09664) |
|
$\boldsymbol{R}_{5}$ |
0.3 |
$\widetilde{R}$ |
(0.00542,0.00516) |
(0.00401,0.00456) |
(0.00401,0.00444) |
$\tilde{R}_{1}$ |
(0.00490,0.00471) |
(0.00379,0.00424) |
(0.11966,0.12129) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00507,0.00486) |
(0.00387,0.00435) |
(0.12028,0.12193) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00481,0.00464) |
(0.00375,0.00418) |
(0.26854,0.26972) |
|
|
0.7 |
$\widetilde{R}$ |
(0.01001,0.00814) |
(0.00731,0.00714) |
(0.00757,0.00719) |
$\tilde{R}_{1}$ |
(0.00894,0.00759) |
(0.00772,0.00718) |
(0.03950,0.04116) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00943,0.00786) |
(0.00760,0.00721) |
(0.04056,0.04226) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00872,0.00748) |
(0.00780,0.00719) |
(0.09544,0.09675) |
|
$\boldsymbol{R}_{6}$ |
0.3 |
$\widetilde{R}$ |
(0.00663,0.00520) |
(0.00479,0.00462) |
(0.00479,0.00449) |
$\tilde{R}_{1}$ |
(0.00596,0.00476) |
(0.00445,0.00429) |
(0.12177,0.12116) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00618,0.00490) |
(0.00457,0.00440) |
(0.12241,0.12179) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00585,0.00468) |
(0.00440,0.00424) |
(0.27003,0.26961) |
|
|
0.7 |
$\widetilde{R}$ |
(0.00997,0.00837) |
(0.00683,0.00746) |
(0.00709,0.00752) |
$\tilde{R}_{1}$ |
(0.00876,0.00789) |
(0.00713,0.00755) |
(0.04038,0.04074) |
|
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00931,0.00813) |
(0.00705,0.00756) |
(0.04147,0.04183) |
|
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00851,0.00779) |
(0.00719,0.00757) |
(0.09617,0.09639) |
|
$\tilde{R}_{i}$ is the E-BE of $R(t)$ based on $\pi_{i}(\eta, \gamma), i=1,2,3$. |
|||||||||
Table 8. MSEs of the estimates of H(t) when t=0.5 and k=2
|
|
|
|
BE |
|
E-BE |
||||
|
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
|
|
|||||||||
|
$\boldsymbol{R}_{1}$ |
0.3 |
$\widetilde{H}$ |
(0.01372,0.01561) |
(0.01696,0.01689) |
(0.01849,0.01803) |
$\widetilde{H}_{1}$ |
(0.01362,0.01521) |
(0.52371,0.52371) |
(0.01726,0.01708) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.01368,0.01536) |
(0.52541,0.52541) |
(0.01762,0.01738) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.01359,0.01514) |
(0.52371,0.52371) |
(0.01708,0.01694) |
|
|
0.7 |
$\widetilde{H}$ |
(0.07826,0.08489) |
(0.09084,0.08948) |
(0.12244,0.10325) |
$\widetilde{H}_{1}$ |
(0.07824,0.08269) |
(2.85140,2.85139) |
(0.10899,0.09476) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.07847,0.08383) |
(2.86049,2.86050) |
(0.11473,0.09847) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.07823,0.08222) |
(2.85142,2.85141) |
(0.10627,0.09302) |
|
$\boldsymbol{R}_{2}$ |
0.3 |
$\widetilde{H}$ |
(0.01551,0.01377) |
(0.01827,0.01487) |
(0.01981,0.01587) |
$\widetilde{H}_{1}$ |
(0.01546,0.01346) |
(0.52372,0.52371) |
(0.01865,0.01502) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.01552,0.01357) |
(0.52540,0.52541) |
(0.01901,0.01528) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.01544,0.01340) |
(0.52372,0.52371) |
(0.01848,0.01490) |
|
|
0.7 |
$\widetilde{H}$ |
(0.07814,0.07825) |
(0.08901,0.08425) |
(0.11954,0.09900) |
$\widetilde{H}_{1}$ |
(0.07847,0.07541) |
(2.85142,2.85134) |
(0.10662,0.08971) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.07858,0.07675) |
(2.86048,2.86055) |
(0.11215,0.09369) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.07852,0.07485) |
(2.85143,2.85136) |
(0.10399,0.08785) |
|
$\boldsymbol{R}_{3}$ |
0.3 |
$\widetilde{H}$ |
(0.01532,0.01512) |
(0.01787,0.01635) |
(0.01935,0.01745) |
$\widetilde{H}_{1}$ |
(0.01530,0.01474) |
(0.52372,0.52371) |
(0.01824,0.01653) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.01534,0.01488) |
(0.52540,0.52541) |
(0.01858,0.01682) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.01528,0.01468) |
(0.52372,0.52371) |
(0.01807,0.01639) |
|
|
0.7 |
$\widetilde{H}$ |
(0.08510,0.07925) |
(0.09282,0.08294) |
(0.12225,0.09521) |
$\widetilde{H}_{1}$ |
(0.08594,0.07774) |
(2.85146,2.85141) |
(0.11010,0.08760) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.08589,0.07856) |
(2.86043,2.86049) |
(0.11538,0.09090) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.08606,0.07743) |
(2.85148,2.85142) |
(0.10759,0.08606) |
|
$\boldsymbol{R}_{4}$ |
0.3 |
$\widetilde{H}$ |
(0.03700,0.04404) |
(0.05344,0.05321) |
(0.06710,0.06281) |
$\widetilde{H}_{1}$ |
(0.03662,0.04080) |
(0.52010,0.51993) |
(0.05870,0.05543) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.03699,0.04199) |
(0.52907,0.52924) |
(0.06153,0.05793) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.03647,0.04023) |
(0.52012,0.51995) |
(0.05733,0.05422) |
|
|
0.7 |
$\widetilde{H}$ |
(0.19860,0.16550) |
(0.23716,0.18626) |
(0.49995,0.26632) |
$\widetilde{H}_{1}$ |
(0.20453,0.15851) |
(2.83301,2.83213) |
(0.39505,0.21726) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.20379,0.16221) |
(2.87932,2.88022) |
(0.44476,0.23886) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.20544,0.15726) |
(2.83319,2.83232) |
(0.37181,0.20737) |
|
$\boldsymbol{R}_{5}$ |
0.3 |
$\widetilde{H}$ |
(0.03485,0.03597) |
(0.05182,0.04381) |
(0.06451,0.05160) |
$\widetilde{H}_{1}$ |
(0.03452,0.03354) |
(0.52008,0.51994) |
(0.05627,0.04536) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.03483,0.03440) |
(0.52910,0.52923) |
(0.05896,0.04737) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.03439,0.03313) |
(0.52009,0.51996) |
(0.05497,0.04439) |
|
|
0.7 |
$\widetilde{H}$ |
(0.17440,0.16877) |
(0.19640,0.18690) |
(0.38614,0.26448) |
$\widetilde{H}_{1}$ |
(0.18566,0.16298) |
(2.83314,2.83230) |
(0.30659,0.21728) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.18232,0.16628) |
(2.87918,2.88004) |
(0.34214,0.23822) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.18781,0.16191) |
(2.83332,2.83249) |
(0.29004,0.20770) |
|
$\boldsymbol{R}_{6}$ |
0.3 |
$\widetilde{H}$ |
(0.03727,0.03490) |
(0.05737,0.04202) |
(0.07231,0.04943) |
$\widetilde{H}_{1}$ |
(0.03638,0.03274) |
(0.52003,0.51997) |
(0.06297,0.04355) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.03688,0.03353) |
(0.52914,0.52920) |
(0.06609,0.04546) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.03616,0.03237) |
(0.52005,0.51999) |
(0.06145,0.04263) |
|
|
0.7 |
$\widetilde{H}$ |
(0.16247,0.17055) |
(0.19322,0.19184) |
(0.39170,0.27380) |
$\widetilde{H}_{1}$ |
(0.17251,0.16302) |
(2.83287,2.83214) |
(0.30790,0.22375) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.16951,0.16699) |
(2.87946,2.88021) |
(0.34522,0.24587) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.17449,0.16162) |
(2.83305,2.83233) |
(0.29050,0.21361) |
|
$\widetilde{H}_{i}$ is the E-BE of $\mathrm{H}(t)$ based on $\pi_{i}(\eta, \gamma), i=1,2,3$. |
|||||||||
Table 9. MSEs of the estimates of H(t) when t=0.5 and k=5
|
|
|
|
BE |
|
E-BE |
||||
|
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
|
|
|||||||||
|
$\boldsymbol{R}_{1}$ |
0.3 |
$\widetilde{H}$ |
(0.01559,0.01368) |
(0.01816,0.01480) |
(0.01968,0.01581) |
$\widetilde{H}_{1}$ |
(0.01556,0.01336) |
(0.52372,0.52371) |
(0.01855,0.01496) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.01561,0.01348) |
(0.52540,0.52541) |
(0.01890,0.01522) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.01554,0.01330) |
(0.52372,0.52371) |
(0.01838,0.01483) |
|
|
0.7 |
$\widetilde{H}$ |
(0.08531,0.07801) |
(0.09634,0.08143) |
(0.12825,0.09330) |
$\widetilde{H}_{1}$ |
(0.08543,0.07669) |
(2.85143,2.85141) |
(0.11498,0.08592) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.08566,0.07743) |
(2.86047,2.86048) |
(0.12073,0.08912) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.08541,0.07642) |
(2.85144,2.85143) |
(0.11226,0.08445) |
|
$\boldsymbol{R}_{2}$ |
0.3 |
$\widetilde{H}$ |
(0.01538,0.01483) |
(0.01881,0.01628) |
(0.02047,0.01746) |
$\widetilde{H}_{1}$ |
(0.01523,0.01438) |
(0.52371,0.52370) |
(0.01918,0.01645) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.01531,0.01453) |
(0.52541,0.52542) |
(0.01958,0.01675) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.01519,0.01430) |
(0.52371,0.52370) |
(0.01899,0.01630) |
|
|
0.7 |
$\widetilde{H}$ |
(0.07991,0.07975) |
(0.08710,0.08450) |
(0.11476,0.09809) |
$\widetilde{H}_{1}$ |
(0.08104,0.07758) |
(2.85146,2.85138) |
(0.10312,0.08963) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.08083,0.07868) |
(2.86044,2.86052) |
(0.10812,0.09329) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.08124,0.07713) |
(2.85147,2.85139) |
(0.10075,0.08792) |
|
$\boldsymbol{R}_{3}$ |
0.3 |
$\widetilde{H}$ |
(0.01420,0.01621) |
(0.01700,0.01784) |
(0.01849,0.01916) |
$\widetilde{H}_{1}$ |
(0.01415,0.01567) |
(0.52372,0.52370) |
(0.01734,0.01804) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.01420,0.01586) |
(0.52540,0.52542) |
(0.01769,0.01839) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.01413,0.01558) |
(0.52372,0.52370) |
(0.01717,0.01787) |
|
|
0.7 |
$\widetilde{H}$ |
(0.08263,0.07958) |
(0.08984,0.08432) |
(0.11783,0.09767) |
$\widetilde{H}_{1}$ |
(0.08370,0.07747) |
(2.85146,2.85138) |
(0.10611,0.08931) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.08353,0.07852) |
(2.86043,2.86052) |
(0.11116,0.09291) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.08389,0.07705) |
(2.85148,2.85139) |
(0.10372,0.08763) |
|
$\boldsymbol{R}_{4}$ |
0.3 |
$\widetilde{H}$ |
(0.03663,0.03820) |
(0.05540,0.04594) |
(0.06928,0.05411) |
$\widetilde{H}_{1}$ |
(0.03598,0.03568) |
(0.52005,0.51996) |
(0.06044,0.04773) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.03640,0.03662) |
(0.52912,0.52921) |
(0.06336,0.04985) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.03580,0.03524) |
(0.52007,0.51998) |
(0.05902,0.04671) |
|
|
0.7 |
$\widetilde{H}$ |
(0.18033,0.17488) |
(0.21551,0.19803) |
(0.45138,0.28404) |
$\widetilde{H}_{1}$ |
(0.18811,0.20453) |
(2.83293,2.83207) |
(0.35517,0.23166) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.18635,0.20379) |
(2.87940,2.88028) |
(0.39981,0.25490) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.18951,0.20544) |
(2.83311,2.83226) |
(0.33433,0.22099) |
|
$\boldsymbol{R}_{5}$ |
0.3 |
$\widetilde{H}$ |
(0.03331,0.03806) |
(0.04683,0.04609) |
(0.05807,0.05432) |
$\widetilde{H}_{1}$ |
(0.03348,0.03546) |
(0.52013,0.51995) |
(0.05078,0.04784) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.03365,0.03640) |
(0.52904,0.52923) |
(0.05315,0.04997) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.03341,0.03502) |
(0.52015,0.51996) |
(0.04964,0.04681) |
|
|
0.7 |
$\widetilde{H}$ |
(0.18242,0.17387) |
(0.21215,0.19763) |
(0.42357,0.28426) |
$\widetilde{H}_{1}$ |
(0.19160,0.16475) |
(2.83305,2.83202) |
(0.33632,0.23143) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.18920,0.16939) |
(2.87927,2.88033) |
(0.37586,0.25483) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.19330,0.16304) |
(2.83323,2.83222) |
(0.31785,0.22067) |
|
$\boldsymbol{R}_{6}$ |
0.3 |
$\widetilde{H}$ |
(0.03867,0.03750) |
(0.05976,0.04532) |
(0.07534,0.05314) |
$\widetilde{H}_{1}$ |
(0.03762,0.03506) |
(0.52002,0.51995) |
(0.06567,0.04689) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.03817,0.03593) |
(0.52915,0.52922) |
(0.06892,0.04891) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.03737,0.03465) |
(0.52004,0.51997) |
(0.06409,0.04592) |
|
|
0.7 |
$\widetilde{H}$ |
(0.17456,0.18205) |
(0.21625,0.20451) |
(0.45069,0.29220) |
$\widetilde{H}_{1}$ |
(0.18153,0.17308) |
(2.83275,2.83217) |
(0.35416,0.23929) |
|
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.17996,0.17782) |
(2.87959,2.88018) |
(0.39832,0.26302) |
|
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.18285,0.17131) |
(2.83293,2.83236) |
(0.33351,0.22838) |
|
$\widetilde{H}_{i}$ is the E-BE of $\mathrm{H}(t)$ based on $\pi_{i}(\eta, \gamma), i=1,2,3$. |
|||||||||
Table 10. Estimates of β, R(t) and H(t) when t=0.5 and k=2
|
|
|
BE |
|
E-BE |
||||
|
|
|
AL |
GEL |
LI |
|
AL |
GEL |
LI |
|
CS |
α |
Par. |
q(−2, −1) |
λ(−2, −1) |
c(−2, −1) |
Par. |
q(−2, −1) |
λ(−2, −1) |
|
|
||||||||
|
0.3 |
$\tilde{\beta}$ |
(0.00027,0.00029) |
(0.00444,0.00253) |
(0.00391,0.00317) |
$\tilde{\beta}_{1}$ |
(0.00085,0.00001) |
(0.00369,0.00200) |
(0.00231,0.00177) |
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.00069,0.00005) |
(0.00418,0.00235) |
(0.00270,0.00211) |
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.00094,0.00000) |
(0.00345,0.00183) |
(0.15377,0.14475) |
|
0.7 |
$\tilde{\beta}$ |
(0.17340,0.14673) |
(0.11115,0.12228) |
(0.11387,0.11814) |
$\tilde{\beta}_{1}$ |
(0.18419,0.15709) |
(0.11510,0.12625) |
(0.12388,0.12807) |
|
|
|
|
|
|
$\tilde{\beta}_{2}$ |
(0.18166,0.15447) |
(0.11244,0.12358) |
(0.12112,0.12536) |
|
|
|
|
|
|
$\tilde{\beta}_{3}$ |
(0.18546,0.15841) |
(0.11645,0.12759) |
(0.00006,0.00038) |
|
|
||||||||
|
0.3 |
$\widetilde{R}$ |
(0.00355,0.00224) |
(0.00093,0.00128) |
(0.00083,0.00105) |
$\tilde{R}_{1}$ |
(0.00227,0.00129) |
(0.00039,0.00062) |
(0.12599,0.12720) |
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.00260,0.00152) |
(0.00051,0.00077) |
(0.12699,0.12822) |
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.00212,0.00118) |
(0.00034,0.00055) |
(0.27358,0.27446) |
|
0.7 |
$\widetilde{R}$ |
(0.04366,0.04892) |
(0.05665,0.05413) |
(0.05742,0.05577) |
$\tilde{R}_{1}$ |
(0.04877,0.05411) |
(0.06190,0.05936) |
(0.00747,0.00777) |
|
|
|
|
|
|
$\tilde{R}_{2}$ |
(0.04733,0.05268) |
(0.06051,0.05795) |
(0.00772,0.00802) |
|
|
|
|
|
|
$\tilde{R}_{3}$ |
(0.04951,0.05483) |
(0.06260,0.06007) |
(0.06479,0.06522) |
|
|
||||||||
|
0.3 |
$\widetilde{H}$ |
(\ 0.00157,0.00167) |
(\ 0.02586,0.01475) |
(\ 0.03917,0.02480) |
$\widetilde{H}_{1}$ |
(0.00496,0.00008) |
(0.51416,0.51368) |
(0.02567,0.01491) |
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(0.00400,0.00028) |
(0.53517,0.53567) |
(0.02917,0.01736) |
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(0.00548,0.00002) |
(0.51422,0.51374) |
(0.02400,0.01375) |
|
0.7 |
$\widetilde{H}$ |
(1.01065,0.85519) |
(0.64780,0.71271) |
(0.58947,0.65321) |
$\widetilde{H}_{1}$ |
(1.07354,0.91559) |
(2.83160,2.83048) |
(0.64878,0.71166) |
|
|
|
|
|
|
$\widetilde{H}_{2}$ |
(1.05876,0.90030) |
(2.88063,2.88178) |
(0.63187,0.69546) |
|
|
|
|
|
|
$\widetilde{H}_{3}$ |
(1.08096,0.92328) |
(2.83174,2.83061) |
(0.65732,0.71983) |
Figure 1. P-P plot of KME versus fitted model survival function for real data set
Figure 2. Empirical and fitted survival function of real data set
In this article, we have tackled the BEs and E-BEs problems, for the KW model based on progressive first failure censoring, from a Bayesian viewpoint. The Bayesian inference, using AL, GEL and LINEX loss functions, is obtained based on the conjugate prior distribution. Also, comparisons are made between the different estimators based on a simulation study. Also, the details have been explained using a real-life example. It is observed that the E-BEs based on progressive first failure censoring have smaller MSEs than the corresponding BEs. From the numerical results presented in Tables 4-9, we may report the following observations:
We would like to appreciate the constructive comments by an associate editor and two anonymous referees which improved the quality and the presentation of our results.
|
AD |
Anderson-Darling |
|
AL |
Al-Bayyati loss |
|
BE cdf |
Bayesian estimator Cumulative distribution function |
|
CS |
Censoring scheme |
|
CvonM |
Cramer-von Mises |
|
E-BE |
Expected BE |
|
GEL |
General entropy loss |
|
KME |
Kaplan-Meier estimator |
|
KS |
Kolmogorov-Smirnov |
|
KW |
Kumaraswamy |
|
LINEX |
Linear-exponential |
|
MC |
Monte Carlo |
|
MS |
Mardia skewness |
|
MSE |
Mean square error |
|
|
Probability density function |
|
SEL |
Squared error loss |
Appendix A
Proof of Theorem 4.2
$\tilde{\beta}_{A L_{1}}-\tilde{\beta}_{A L_{3}}=\int_{0}^{1} \int_{1}^{\epsilon} \tilde{\beta}_{A L}\left(\pi_{1}(\eta, \gamma)-\pi_{3}(\eta, \gamma)\right) \mathrm{d} \gamma \mathrm{d} \eta$$=\frac{1}{\epsilon^{2}-1}\left(m+q+\frac{a}{a+b}\right)\{2$$-2 \epsilon$
$\left.+\left(1+\epsilon-2 \psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}=\tilde{\beta}_{A L_{2}}-\tilde{\beta}_{A L_{1}}$. (47)
Since $\epsilon>1$ and $\psi_{m, k}<0$, we have $\left(m+q+\frac{a}{a+b}\right) /$ $\left(\epsilon^{2}-1\right)>0$. Now, let,
$E_{1}(\epsilon)=2-2 \epsilon+\left(1+\epsilon-2 \psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$.
Then,
$£_{1}^{\prime}(\epsilon)=-2+\frac{1+\epsilon-2 \psi_{m, k}}{\epsilon-\psi_{m, k}}+\ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$,
$£_{1}^{\prime \prime}(\epsilon)=(\epsilon-1) /\left(\epsilon-\psi_{m, k}\right)^{2}>0, £_{1}(1)=£_{1}^{\prime}(1)=0$; $£_{1}(\epsilon)$ and $£_{1}^{\prime}(\epsilon)$ are increasing functions. So, we have $£_{1}(\epsilon)>0$. Thus, we have $\tilde{\beta}_{A L_{3}}<\tilde{\beta}_{A L_{1}}<\tilde{\beta}_{A L_{2}}$.
$\tilde{\beta}_{G E_{1}}-\tilde{\beta}_{G E_{3}}=\frac{G(\lambda)}{\left(\epsilon^{2}-1\right) B(a, b)}\{2-2 \epsilon+(1+\epsilon$$\left.\left.-2 \psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$$=\frac{\epsilon-1}{\epsilon+1}\left(\tilde{\beta}_{G E_{2}}-\tilde{\beta}_{G E_{1}}\right)$. (48)
From Lemma 4.1, we have $G(\lambda) /\left(\left(\epsilon^{2}-1\right) B(a, b)\right)>0$. Now, let,
$£_{2}(\epsilon)=2-2 \epsilon+\left(1+\epsilon-2 \psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$$=£_{1}(\epsilon)>0$. (49)
Since $(\epsilon-1) /(\epsilon+1)>0$ and by using Eqns. (48) and (49), we have $\tilde{\beta}_{G E_{3}}<\tilde{\beta}_{G E_{1}}<\tilde{\beta}_{G E_{2}}$.
$\tilde{\beta}_{L I_{1}}-\tilde{\beta}_{L I_{3}}=\frac{1}{c\left(\epsilon^{2}-1\right)}\left(m+\frac{a}{a+b}\right)$$\times\left\{\left(\epsilon+c-\psi_{m, k}\right)\left(1+c-\psi_{m, k}\right)\right.$
$\times \ln \left(\frac{\epsilon+c-\psi_{m, k}}{1+c-\psi_{m, k}}\right)-c(\epsilon-1)$$\left.-\left(\epsilon-\psi_{m, k}\right)\left(1-\psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$. (50)
Since $\epsilon>1$ and $c>0$, we have $\left(m+q+\frac{a}{a+b}\right) / c\left(\epsilon^{2}-\right.$ 1) $>0$. Now, let,
$\begin{aligned} \mathrm{£}_{3}(\epsilon)=(\epsilon+c-&\left.\psi_{m, k}\right)\left(1+c-\psi_{m, k}\right) \ln \left(\frac{\epsilon+c-\psi_{m, k}}{1+c-\psi_{m, k}}\right) \\ &-\left(\epsilon-\psi_{m, k}\right)\left(1-\psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)-c(\epsilon-1) \end{aligned}$. (51)
Then
$\begin{aligned} £_{3}^{\prime}(\epsilon)=(1+c-&\left.\psi_{m, k}\right) \ln \left(\frac{\epsilon+c-\psi_{m, k}}{1+c-\psi_{m, k}}\right) \\ &-\left(1-\psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right) \end{aligned}$, (52)
and
$£_{3}^{\prime \prime}(\epsilon)=\frac{1+c-\psi_{m, k}}{\epsilon+c-\psi_{m, k}}-\frac{1-\psi_{m, k}}{\epsilon-\psi_{m, k}}>0$, (53)
$£_{3}(1)=£_{3}^{\prime}(1)=0 ; £_{3}(\epsilon)$ and $£_{3}^{\prime}(\epsilon)$ are increasing functions. This implies that $£_{3}(\epsilon)>0$. Thus, one can show that $\tilde{\beta}_{L I_{3}}<\tilde{\beta}_{L I_{1}}$. Similarly, we can show that $\tilde{\beta}_{L I_{1}}<\tilde{\beta}_{L I_{2}}$. This completes the proof.
Proof of Theorem 4.3
(1,2) Since $\lim _{\psi \rightarrow-\infty}\left(1+\epsilon-2 \psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)=2(\epsilon-1)$, we find from (47) that:
$\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{A L_{1}}-\tilde{\beta}_{A L_{3}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{A L_{2}}-\tilde{\beta}_{A L_{1}}=0$, (54)
and from (48),
$\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{G E_{1}}-\tilde{\beta}_{G E_{3}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{G E_{2}}-\tilde{\beta}_{G E_{1}}=0$. (55)
Next, it can be easily checked that
$\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{A L_{1}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{A L_{2}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{A L_{3}}$,
and
$\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{G E_{1}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{G E_{2}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{G E_{3}}$.
(3) Since,
$\lim _{\psi \rightarrow-\infty}\left\{\left(\epsilon+c-\psi_{m, k}\right)\left(1+c-\psi_{m, k}\right) \ln \left(\frac{\epsilon+c-\psi_{m, k}}{1+c-\psi_{m, k}}\right)-\left(\epsilon-\psi_{m, k}\right)\left(1-\psi_{m, k}\right) \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)\right\}$$=2(\epsilon-1)$, (56)
We find from (50) that,
$\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{L I_{1}}-\tilde{\beta}_{L I_{3}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{L I_{2}}-\tilde{\beta}_{L I_{1}}=0$.
It can be easily checked that the above equation implies:
$\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{L I_{1}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{L I_{2}}=\lim _{\psi \rightarrow-\infty} \tilde{\beta}_{L I_{3}}$.
Hence, the theorem is proved.
Appendix B
Proof of Theorem 4.4
$\left.\begin{array}{rl}\widetilde{H}_{A L_{1}} & =\frac{\alpha t^{\alpha-1}}{1-t^{\alpha}}, \tilde{\beta}_{A L_{1}} \\ \widetilde{H}_{A L_{2}} & =\frac{\alpha t^{\alpha-1}}{1-t^{\alpha}} \tilde{\beta}_{A L_{2}}, \\ \widetilde{H}_{A L_{3}} & =\frac{\alpha t^{\alpha-1}}{1-t^{\alpha}} \tilde{\beta}_{A L_{3}}.\end{array}\right\}$ (57)
Hence it follows that
$\frac{\widetilde{H}_{A L_{1}}}{\widetilde{\beta}_{A L_{1}}}=\frac{\widetilde{H}_{A L_{2}}}{\tilde{\beta}_{A L_{2}}}=\frac{\widetilde{H}_{A L_{3}}}{\widetilde{\beta}_{A L_{3}}}$. (58)
According to part (1) of Theorem 4.2 and Eq. (58), the stated result follows.
$\widetilde{H}_{L I_{1}}-\widetilde{H}_{L I_{3}}=\frac{1}{c\left(\epsilon^{2}-1\right)}\left(m+\frac{a}{a+b}\right) £_{4}(\epsilon)$, (59)
where,
$£_{4}(\epsilon)=\left\{\left(\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}+\epsilon-\psi_{m, k}\right)\left(\frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}+1-\psi_{m, k}\right) \times \ln \left(\frac{\zeta(\epsilon)}{\zeta(1)}\right)\right.$
$-\left(\epsilon-\psi_{m, k}\right)\left(1-\psi_{m, k}\right) \times \ln \left(\frac{\epsilon-\psi_{m, k}}{1-\psi_{m, k}}\right)$
$\left.-(\epsilon-1) \frac{c \alpha t^{\alpha-1}}{1-t^{\alpha}}\right\}$ (60)
Using the same line as in part (3) of Theorem 4.2, details are avoided, it is easy to obtain $£_{4}(\epsilon)>0$. Thus, it can show that $\widetilde{H}_{L I_{3}}<\widetilde{H}_{L I_{1}}.$ Similarly, we can show that $\widetilde{H}_{L I_{1}}<\widetilde{H}_{L I_{2}} .$ This completes the proof.
[1] Montanari, G.C., Cacciari, M. (1988). Progressively-censored aging tests on XLPE-insulated cable models. IEEE Transactions on Dielectrics and Electrical Insulation, 23: 365-372. https://doi.org/10.1109/14.2376
[2] Abu-Awwad, R.R., Raqab, M.Z., Al-Mudahakha, I.M. (2015). Statistical inference based on progressively type-II censored data from Weibull model. Communications in Statistics - Simulation and Computation, 44(10): 2654-2670. https://doi.org/10.1080/03610918.2013.842589
[3] Balakrishnan, N. (2007). Progressive censoring methodology, an appraisal. Test, 16: 211-296. https://doi.org/10.1007/s11749-007-0061-y
[4] Balakrishnan, N., Aggarwala, R. (2000). Progressive Censoring – Theory, Methods, and Applications. Birkha ̈user, Boston, MA.
[5] Balakrishnan, N., Cramer, E. (2014). The art of progressive censoring, applications to reliability and quality. Birkhauser, Boston.
[6] Dube, M., Garg, R., Krishna, H. (2016). On progressively first failure censored Lindley distribution. Computational Statistics, 31: 139-163. https://doi.org/10.1007/s00180-015-0622-6
[7] Kotb, M.S., Raqab, M.Z. (2019). Statistical inference for modified Weibull distribution based on progressively type-II censored data. Mathematics and Computers in Simulation, 162: 233-248. https://doi.org/10.1016/j.matcom.2019.01.015
[8] Kundu, D. (2008). Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics, 50(2): 144-154. https://doi.org/10.1198/004017008000000217
[9] Mao, S.S., Luo, C.B. (1989). Reliability analysis of zero-failure data. Chinese Mathematical Statistics and Applied Probability, 4(4): 489-506.
[10] Mohie El-Din, M.M., Amein, M.M., El-Attar, H.E., Hafez, E.H. (2013). Estimation for parameters of Feller-Pareto distribution from progressive type-II censoring and some characterizations. Journal of Probability and Statistical Science, 11: 97-108.
[11] Dey, S., Dey, T., Luckett, D.J. (2016). Statistical inference for the generalized inverted exponential distribution based on upper record values. Mathematics and Computers in Simulation, 120: 64-78. https://doi.org/10.1016/j.matcom.2015.06.012
[12] Mohie El-Din, M.M., Kotb, M.S., Abd-Elfattah, E.F., Newer, H.A. (2017). Bayesian inference and prediction of the Pareto distribution based on ordered ranked set sampling. Communications in Statistics - Theory and Methods, 46(13): 6264-6279. https://doi.org/10.1080/03610926.2015.1124118
[13] Soliman, A.A., Al-Aboud, F.M. (2008). Bayesian inference using record values from Rayleigh model with application. European Journal of Operational Research, 185(2): 659-672. https://doi.org/10.1016/j.ejor.2007.01.023
[14] Kumaraswamy, P. (1980). A generalized probability density-function for double-bounded random processes. Journal of Hydrology, 46: 79-88. https://doi.org/10.1016/0022-1694(80)90036-0
[15] Courard-Hauri, D. (2007). Using Monte Carlo analysis to investigate the relationship between overconsumption and uncertain access to one’s personal utility function. Ecological Economics, 64(1): 152-162. https://doi.org/10.1016/j.ecolecon.2007.02.018
[16] Fletcher, S.C., Ponnambalam, K. (1996) Estimation of reservoir yield and storage distribution using moments analysis. Journal of Hydrology, 182: 259-275. https://doi.org/10.1016/0022-1694(95)02946-X
[17] Ganji, A., Ponnambalam, K., Khalili, D., Karamouz, M. (2006). Grain yield reliability analysis with crop water demand uncertainty. Stochastic Environmental Research and Risk Assessment, 20: 259-277. https://doi.org/10.1007/s00477-005-0020-7
[18] Sanchez, S., Ancheyta, J., McCaffrey, W.C. (2007). Comparison of probability distribution function for fitting distillation curves of petroleum. Energy and Fuels, 21: 2955-2963. https://doi.org/10.1021/ef070003y
[19] Seifi, A., Ponnambalam, K., Vlach, J. (2000). Maximization of manufacturing yield of systems with arbitrary distributions of component values. Annals of Operations Research, 99: 373-383. https://doi.org/10.1023/A:1019288220413
[20] Sundar, V., Subbiah, K. (1989). Application of double bounded probability density-function for analysis of ocean waves. Ocean Engineering, 16: 193-200. https://doi.org/10.1016/0029-8018(89)90005-X
[21] Jones, M.C. (2009). Kumaraswamy’s distribution: A beta-type distribution with some tractability advantages. Statistical Methodology, 6(1): 70-81. https://doi.org/10.1016/j.stamet.2008.04.001
[22] Wang, L. (2017). Inference for the Kumaraswamy distribution under k-record values. Journal of Computational and Applied Mathematics, 321: 246-260. https://doi.org/10.1016/j.cam.2017.02.037
[23] Wang, L. (2018). Inference of progressively censored competing risks data from Kumaraswamy distributions. Journal of Computational and Applied Mathematics, 343: 719-736. https://doi.org/10.1016/j.cam.2018.05.013
[24] Han, M. (2009). E-Bayesian estimation and hierarchical Bayesian estimation of failure rate. Applied Mathematical Modelling, 33: 1915-1922. https://doi.org/10.1016/j.apm.2008.03.019
[25] Jaheen, Z.F., Okasha, H.M. (2011). E-Bayesian estimation for the Burr type XII model based on type-II censoring. Applied Mathematical Modelling, 35: 4730-4737. https://doi.org/10.1016/j.apm.2011.03.055
[26] Okasha, H.M., Wang, J. (2016). E-Bayesian estimation for the geometric model based on record statistics. Applied Mathematical Modelling, 40(1): 658-670. https://doi.org/10.1016/j.apm.2015.05.004
[27] Al-Bayyati, H.N. (2002). Comparing methods of Estimating Weibull Failure Models Using Simulation. Ph.D. Thesis, College of Administration and Economics, Baghdad University, Iraq.
[28] Kotb, M.S., Mohie El-Din, M.M. (2021). Parametric inference for step-stress accelerated life testing from Rayleigh distribution under ordered ranked set sampling. IEEE Transactions on Reliability, pp. 1-12. https://doi.org/10.1109/TR.2020.2999392
[29] Kotb, M.S., Raqab, M.Z. (2018). Bayesian inference and prediction of the Rayleigh distribution based on ordered ranked set sampling. Communications in Statistics - Simulation and Computation, 47(3): 905-923. https://doi.org/10.1080/03610918.2017.1300262
[30] Calabria, R., Pulcini, G. (1996). Point estimation under asymmetric loss functions for left-truncated exponential samples. Communications in Statistics - Theory and Methods, 25(3): 585-600. https://doi.org/10.1080/03610929608831715
[31] Varian, H.R. (1975). A Bayesian approach to real estate assessment. North Holland, Amsterdam, pp. 195-208.
[32] Basu, A.P., Ebrahimi, N. (1991). Bayesian approach to life testing and reliability estimation using asymmetric loss function. Journal of Statistical Planning and Inference, 29: 21-31. https://doi.org/10.1016/0378-3758(92)90118-C
[33] Soliman, A.A., Abd-Ellah, A.H., Sultan, K.S. (2006). Comparison of estimates using record statistics from Weibull model: Bayesian and non-Bayesian approaches. Computational Statistics & Data Analysis, 51(3): 2065-2077. https://doi.org/10.1016/j.csda.2005.12.020
[34] Bernardo, J.M., Smith, A.F.M. (1994). Bayesian Theory. New York: Wiley.
[35] Mohammed, H.S., Ateya, S.F., Al-Hussaini, E.K. (2017). Estimation based on progressive first-failure censoring from exponentiated exponential distribution. Journal of Applied Statistics, 44(8): 1479-1494. https://doi.org/10.1080/02664763.2016.1214245
[36] Quesenberry, C.P., Hales, C. (1980). Concentration bands for uniformity plots. Journal of Statistical Computation and Simulation, 11: 41-53. https://doi.org/10.1080/00949658008810388
[37] Kaplan, E.L., Meier, P. (1958). Nonparametric estimation from incomplete observations. Journal of the American Statistical Association, 53: 457-481. https://doi.org/10.1007/978-1-4612-4380-9_25