Miguel Angel Valles-Coral*![]() | Jorge Raul Navarro-Cabrera
| Jorge Raul Navarro-Cabrera![]() | Lloy Pinedo
| Lloy Pinedo![]() | Jorge Damián Valverde-Iparraguirre
| Jorge Damián Valverde-Iparraguirre![]() | Richard Injante
| Richard Injante![]() | Paula Clotilde Liza-Santa-Cruz
| Paula Clotilde Liza-Santa-Cruz![]() | Luis Gerardo Salazar-Ramirez
| Luis Gerardo Salazar-Ramirez![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Academic recommendation systems have emerged as key tools for optimizing course selection in higher education, allowing personalized curriculum planning based on each student's profile. This study presents one of the first integrations of Principal Component Analysis (PCA) and clustering techniques with deep neural networks for elective course recommendations in the context of Peruvian higher education. The model was developed using academic records from 120 students at the Universidad Nacional de San Martín, applying PCA for dimensionality reduction and K-Means clustering, with the elbow method identifying five optimal clusters. A regression-based neural network was then used to predict the course selection likelihood. The evaluation metrics showed an MSE of 2.9632, RMSE of 1.7214, and R² of 0.8518, confirming adequate generalization and model accuracy. The findings highlight the feasibility of predictive models in academic decision-making and suggest further improvements through the inclusion of diverse data sources. However, the current system is limited to academic history data, excluding variables such as personal interests, learning styles, and career goals, which could enhance the precision of recommendations in future implementations.
clustering, curriculum optimization, higher education, machine learning, personalized recommendations, predictive modeling
Universities play a fundamental role in training highly skilled and competitive professionals [1]. To achieve this, they design curricula that seek to balance the development of technical competencies with training in soft skills and critical thinking [2, 3]. In this context, elective courses play a key role by allowing students to expand their knowledge beyond their main discipline, thus strengthening their academic and professional profiles [4, 5].
However, course selection does not always follow a structured process that is based on objective criteria. Students’ choice of elective subjects is influenced by informal recommendations from peers, scheduling constraints, and perceptions of faculty performance [6, 7]. These decisions, shaped by subjective factors, may limit the benefits of educational opportunities and reduce the positive impact of elective courses on academic and professional development [8].
Although some universities provide academic advice to guide students in this process, these efforts are often insufficient or not properly targeted [9, 10]. For example, in Peru, the Universidad Nacional de San Martín (UNSM) lacks a structured system to help students select elective courses based on their interests, prior competencies, and academic performance, making it difficult for them to make informed decisions.
In this context, the advancement of Artificial Intelligence (AI) and recommendation systems has provided new opportunities to improve academic guidance through technological tools capable of analyzing multiple factors and offering personalized suggestions [11-13]. In particular, hybrid recommendation models have proven effective by combining collaborative filtering techniques, machine learning, and preference analysis to generate more precise recommendations aligned with a student's profile [14].
Current approaches, especially in non-Anglophone contexts, are often based on academic history, socioeconomic data, and subjective weighting criteria using expert systems based on inference engines [15, 16]. However, these approaches can be improved through the use of more advanced AI techniques, such as deep learning, which enables greater accuracy in recommendations and more effective adaptation to students' needs [17, 18].
In this regard, this study proposes the development of a hybrid recommendation model to assist final-year students at UNSM in making more informed elective course selection. This model integrates advanced data analysis and machine learning strategies to enhance the quality of recommendations, foster a more enriching educational experience, and contribute to the training of professionals who are better prepared for the challenges of the labor market.
2.1 Study approach
An integrated methodological approach was adopted to achieve the stated objectives by combining advanced supervised and unsupervised learning techniques. This hybrid approach optimizes the elective course recommendation process, ensuring precise alignment with students' competencies and preferences.
2.2 Population and data sources
This study focused on undergraduate students from the Systems and Informatics Engineering Program at the Universidad Nacional de San Martín (UNSM), specifically, those in the final semesters of their academic training. The selection of this population was based on the necessity of choosing elective courses as part of their curriculum. Two primary data sources were used for data collection: the students' academic records, which included grades obtained in subjects from various areas of the curriculum, and a course competency matrix developed from the latest available curriculum structure to identify the skills and knowledge imparted in each course. These sources were integrated into a unified dataset to analyze the relationship between course competencies and students' academic preferences or needs.
The sample population consisted of 120 student academic profiles selected to reflect diversity in academic trajectories and decision-making regarding elective course selection.
2.3 Data cleaning and preprocessing
Rigorous data-cleaning procedures were implemented to ensure the quality of the dataset. First, redundancies were removed, and data consistency was verified in the course competency matrix. Simultaneously, outliers and missing values in the academic records were corrected to ensure that grades and areas of interest accurately reflected student performance and preferences.
Subsequently, data preprocessing was performed. Principal Component Analysis (PCA) was applied to reduce dimensionality and retain only the most relevant features. Additionally, variable standardization was conducted to normalize the data and improve model stability. As part of this process, the K-Means algorithm was used to cluster courses into categories based on similarities in their competencies, enriching the representation of the relationships between courses and students.
2.4 Processing and recommendation model
To generate elective course recommendations, a supervised learning model based on statistical regression was implemented. This model was trained using a pre-processed dataset to predict the likelihood of a student selecting a course based on their academic history and course competencies.
The model was integrated into a comprehensive recommendation system consisting of two main modules: a regression-based recommendation engine that provides personalized recommendations, and a user interface designed to allow students to visualize and select the recommended courses and enhance the user experience.
2.4.1 Hyperparameter tuning and training configuration
A structured two-phase hyperparameter tuning procedure was implemented to determine the optimal configuration of the regression model. The first phase consisted of a broad random search across the predefined ranges. In the second phase, Bayesian optimization using the Optuna framework with a Tree-structured Parzen Estimator (TPE) sampler was applied to the top ten configurations with the lowest validation loss. The explored ranges, tuning heuristics, and selected optimal values are listed in Table 1.
Table 1. Hyperparameter tuning procedure and selected optimal values
|
Hyperparameter |
Search Range |
Heuristic Applied |
Optimal Value |
|
Initial learning rate |
1 × 10⁻⁴ to 5 × 10⁻³ (log-uniform) |
Linear warm-up (5 epochs) + cosine annealing |
1.5 × 10⁻³ |
|
Batch size |
64, 96, 128, 256 |
Trade-off between gradient variance and GPU usage |
128 |
|
Dropout |
0.0 to 0.5 (step 0.05) |
Gradual increase to prevent overfitting |
0.25 |
|
Weight decay |
0 to 1 × 10⁻³ |
L2 regularization |
1 × 10⁻⁴ |
|
Hidden units (FC1) |
64 to 512 (powers of 2) |
Explored model capacity variations |
128 |
|
Gradient clipping (L2 norm) |
0 (off), 1.0, 5.0 |
Enabled if gradients exceeded threshold |
1.0 |
|
Early stopping |
5 to 15 epochs |
Training halted if validation loss did not improve |
10 |
Each configuration was trained for 40 epochs with early stopping and evaluated using the mean squared error (MSE) on the validation set. The final configuration was selected based on the lowest average validation loss across five runs with different, randomly selected seeds. This process ensured the robustness and stability of the model prior to deployment.
2.5 Model evaluation
The model was evaluated using standard validation metrics for the predictive models. The Mean Squared Error (MSE) was used to quantify the average magnitude of the prediction errors, whereas the Root Mean Squared Error (RMSE) was applied to express errors on the same scale as the target values, providing a more intuitive interpretation. Additionally, the coefficient of determination (R²) was calculated to assess the explanatory power of the model and determine the proportion of data variability explained by the predictive model. These metrics facilitated model optimization, ensuring robustness and the ability to generate accurate recommendations tailored to students’ needs.
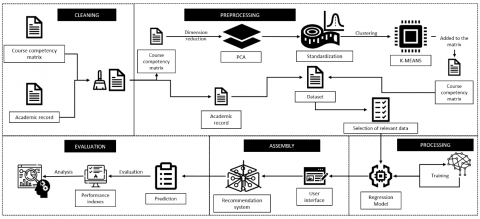
Figure 1 presents a methodological flowchart of the elective course recommendation system, including the stages of data cleaning, pre-processing, modeling, and evaluation.
Figure 1. Methodological flow diagram
3.1 Data cleansing
During the data-cleaning stage, various actions were performed to ensure the quality and consistency of the information used in this study. First, the course competency matrix is reviewed to identify and eliminate redundancies, ensuring that each course is associated with unique and accurately described competencies. Regarding academic records, missing and outlier data were addressed using mean-based imputation techniques to ensure that grades and course history accurately represented students' academic performance and preferences. Additionally, non-numeric values such as "NP," were removed to prevent distortions in the analysis results.
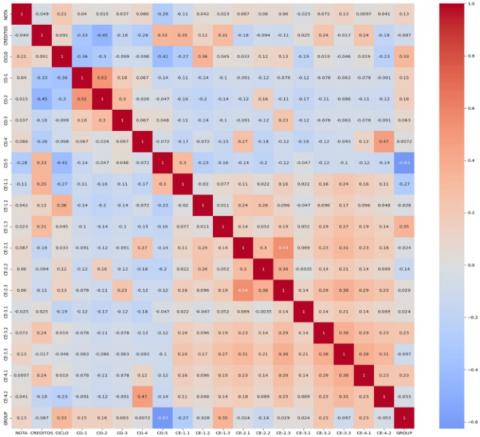
To evaluate the interrelationships between the dataset variables, a Pearson correlation matrix was generated, allowing the identification of potential relationships between key attributes. Figure 2 presents the correlation matrix, where patterns of association between the academic variables are observed.
Figure 2. Pearson correlation matrix
3.2 Data preprocessing
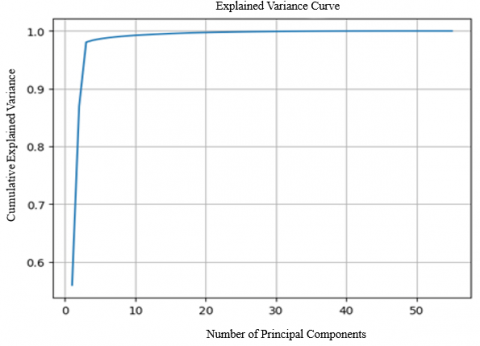
The data preprocessing stage incorporated advanced techniques to optimize the structure and quality of the dataset before model training. Initially, PCA was applied to perform dimensionality reduction, aiming to retain the most informative features while reducing redundancy and mitigating multicollinearity across academic variables. To determine the number of components to retain, eigenvalue decomposition of the covariance matrix was conducted, followed by a scree plot analysis. The explained variance curve shown in Figure 3 reveals an inflection point at the fourth component, indicating a sharp decline in the marginal contribution beyond this point. The first four principal components were retained as they captured 86.42 percent of the cumulative variance, which was deemed sufficient to preserve the underlying structure of the dataset while simplifying its dimensionality.
Figure 3. Variance curve explained by PCA
Following dimensionality reduction, all variables were normalized using z-score standardization to ensure a uniform scale and eliminate bias due to differing variable magnitudes. This standardization step was essential for enhancing the stability and convergence of the machine learning models in the later stages.
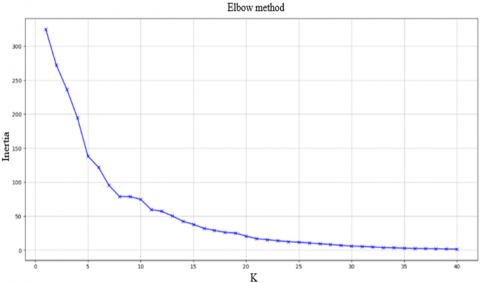
As a final preprocessing step, the K-Means algorithm was applied to group the courses into clusters according to similarities in their competencies, as this method allows the data to be structured efficiently, minimizing the variability within each group and maximizing the separation between them [19]. The optimal number of clusters was first estimated using the elbow method, which plots the within-cluster sum of squares (WCSS) for different values of k. As shown in Figure 4, the elbow was observed at k = 5, suggesting that this number of clusters provides a suitable balance between intra-cluster cohesion and inter-cluster separation [20].
Figure 4. Determining the optimal number of clusters
To validate this selection, the Silhouette coefficient was computed for values of k ranging from 2 to 10. The highest coefficient was obtained at k = 5, with a value of 0.3920. This score, although moderate, indicates an acceptable cluster structure, considering the high dimensionality and partial overlap in course competency profiles. The Silhouette coefficient measures both the cohesion within clusters and the separation between them, with values close to 1 indicating well-differentiated clusters [21]. The resulting course clusters were subsequently incorporated into the dataset as new categorical variables, enriching the representation of the relationships between course competencies and students' academic characteristics.
3.3 Processing and recommendation model
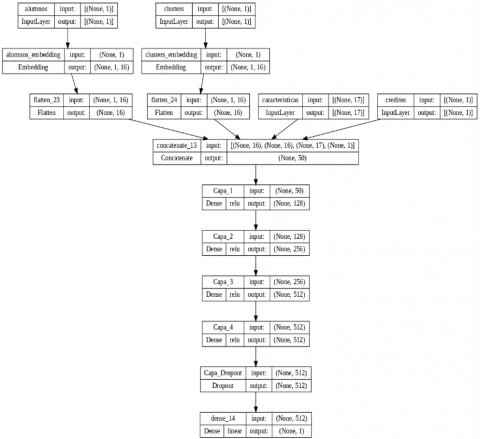
To generate personalized elective course recommendations, a supervised regression model based on deep neural networks was implemented. The neural network architecture consisted of four dense layers, trained with a preprocessed dataset that integrated the competency matrix, academic history, and the clusters obtained using K-Means. Figure 5 illustrates the structure of the deep-learning model used in the recommendation system.
Figure 5. Architecture of the neural network used for elective course prediction
Additionally, the required nature of the courses and the number of credits were included as input variables, allowing the model to capture more precise patterns in course selection. The model was trained to minimize errors in predicting future grades based on the previous courses.
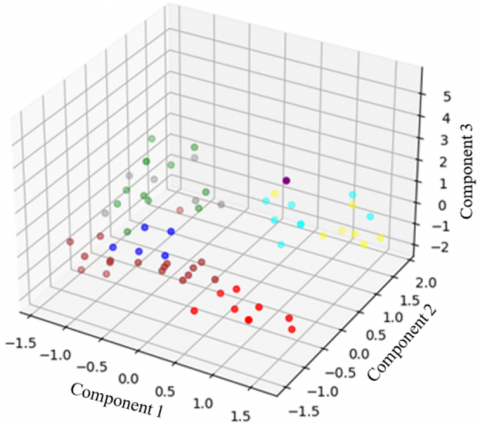
Figure 6 shows a three-dimensional visualization of the clusters generated using K-Means, reflecting the distribution of courses according to their latent characteristics. This clustering allowed courses with similar characteristics to be identified within each cluster, ensuring clear differentiation between them. This resulted in a well-defined structure that facilitated the interpretation of the data patterns and optimized the course organization.
Figure 6. Three-dimensional distribution of courses based on their main components and clusters generated using K-Means
3.4 Assembling the recommendation system
In the assembly phase, the system components were integrated to provide a functional solution for the students. Based on a regression model, the recommendation system processes each student's academic information and generates a prioritized list of elective courses aligned with their interests and competencies.
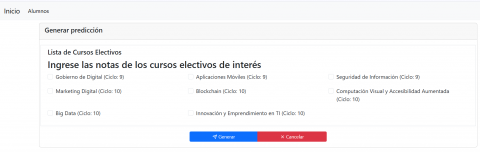
An intuitive user interface was developed as part of the assembly process to facilitate student interaction with the system. Through this interface, users can view the generated recommendations and explore the details of each course before making an informed decision. Figure 7 shows the interface of the system in the course-prediction module.
Figure 7. User interface of the elective course recommendation system
3.4.1 Usability evaluation of the system
A pilot usability evaluation was conducted with 48 final-year undergraduate students who used the recommendation platform for two consecutive weeks to plan their elective courses. Upon completion of the interaction period, three instruments were administered: the System Usability Scale (SUS), a 5-point Likert scale assessing overall satisfaction, perceived usefulness, and ease of navigation, and a set of open-ended questions to gather qualitative feedback from the participants.
Table 2 presents the results of the usability evaluation. The average SUS score was 82.4, indicating a high level of system usability. Satisfaction, perceived usefulness, and ease of navigation also received high mean ratings, all with narrow confidence intervals, confirming consistency in user responses.
Table 2. Results of the system usability evaluation
|
Metric |
Mean ± SD |
95% CI |
|
SUS (0–100) |
82.4 ± 7.6 |
80.0 – 84.8 |
|
Overall satisfaction (1–5) |
4.46 ± 0.63 |
4.28 – 4.64 |
|
Perceived usefulness (1–5) |
4.38 ± 0.71 |
4.17 – 4.59 |
|
Ease of navigation (1–5) |
4.58 ± 0.55 |
4.42 – 4.74 |
A total of 87% of the participants highlighted the clarity of the recommendation screen and the relevance of the displayed selection criteria. The most frequent suggestions were the inclusion of schedule-based filters and alerts regarding course-seat availability.
3.5 Model evaluation
Given the nature of the task to be performed by the model and, therefore, by the recommendation system, its performance was measured using regression metrics. The metrics used included Mean Square Error (MSE), Root Mean Square Error (RMSE), and Coefficient of Determination (R²). These metrics allowed us to evaluate the accuracy of the system in predicting the probability of a student choosing a specific course based on their academic characteristics and course competencies, thus generating the expected grade.
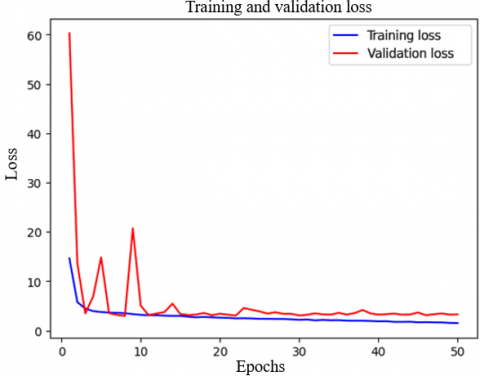
After completing the model training, the loss (MSE) values achieved using the training set were extracted and compared with those obtained using the validation set. Figure 8 illustrates the evolution of the loss during the training and validation over 50 epochs. An accelerated decrease was observed in the first iteration, indicating efficient learning in the initial stage. However, between epochs 5 and 15, the validation curve exhibited fluctuations, suggesting instability in the generalization of the model during this interval.
Figure 8. Loss curve in training and validation of the recommendation model
From epoch 15 onward, both curves began to stabilize and converge toward low values, indicating that the model had reached an equilibrium point where the validation loss remained close to the training loss. This suggests that the model was not overfitting, as the difference between the two curves was minimal in the later iterations. Furthermore, the absence of a significant increase in the validation loss after convergence confirmed that the model achieved good generalization.
The fluctuations observed in the early stages indicate the need to optimize certain hyperparameters, such as the learning rate or batch size, to improve training stability. However, the final values obtained for MSE, RMSE, and R² (Table 3) in the validation reflect the satisfactory performance of the model in predicting elective courses, which supports its applicability in academic recommendations.
Table 3. Comparison of recommendation approaches
|
Dataset |
Algorithm |
Validation |
||
|
MSE |
RMSE |
R2 |
||
|
Collaborative filtering |
SVD++ (matrix factorization) |
5.1840 |
2.2770 |
0.7324 |
|
Content-based method |
k-NN + cosine similarity |
4.8925 |
2.2119 |
0.7518 |
|
Proposed hybrid model |
PCA + K-Means + Neural Network |
2.9632 |
1.7214 |
0.8518 |
The final performance evaluation of the model is presented in Table 3, which provides a comparative analysis of the proposed hybrid approach with traditional baseline methods. To contextualize these results, two reference models were implemented: a collaborative filtering system based on matrix factorization using SVD++ and a content-based approach employing k-nearest neighbors with cosine similarity applied to TF-IDF vectors constructed from course competencies. The metrics obtained from the validation set demonstrated the superior predictive accuracy of the hybrid model, providing empirical support for its generalization capabilities.
The hybrid model achieved an MSE of 2.9632 and an R² of 0.8518, outperforming the collaborative filtering model (MSE = 5.1840, R² = 0.7324) and content-based method (MSE = 4.8925, R² = 0.7518). These differences were statistically significant according to the Wilcoxon signed-rank test (p < 0.01) applied to the instance-level absolute errors, confirming the superiority of the proposed approach.
The results show that the combination of dimensionality reduction (PCA), segmentation (K-Means), and deep learning captures complex patterns that traditional methods cannot model independently. In particular, the explicit integration of the course competency structure (through clustering) enables the hybrid model to better contextualize the affinity between students and courses, resulting in a 36% reduction in the prediction error compared to collaborative filtering and a 39% reduction compared to the content-based method.
The results demonstrate the effectiveness of the proposed hybrid model in recommending elective courses, thereby allowing students to make informed decisions based on their academic history and competencies. The accuracy achieved in the model validation, with an R² of 0.8518, is comparable to that of previous studies on academic recommendation systems [18, 22]. These findings reinforce the viability of using machine learning algorithms to optimize the course selection process, which aligns with previous research highlighting the positive impact of recommendation systems in educational settings [11, 17]. However, although the model achieved adequate generalization, some instability was observed in the early stages of training, suggesting the need to fine-tune the hyperparameters, such as the learning rate or batch size, to improve the stability of the initial training.
The integration of dimensionality reduction (PCA) and clustering (K-Means) techniques allowed the data to be efficiently structured, minimizing redundancy and maximizing separation between course groups. Validation of the optimal number of clusters using the elbow method and the Silhouette coefficient (0.3920) confirmed that the segmentation performed was adequate and consistent with previous approaches [19, 20]. These results suggest that recommendation systems can benefit from clustering techniques to improve the personalization of suggestions offered to students, which recent studies have explored in other educational contexts [15, 16]. However, one challenge identified in this process is the assignment of labels to the generated clusters, as the interpretation of the resulting groups may require additional criteria to improve the comprehension and usability of recommendations.
In terms of applicability, incorporating an intuitive user interface into the recommendation system represents a significant advance in the accessibility of these tools for students. As previous studies [12, 14] have pointed out, usability and user interaction play key roles in the effective adoption of recommendation systems in education. The developed platform not only allows users to view personalized recommendations but also facilitates the exploration of course options based on individual preferences. Despite these advances, a limitation of the present study lies in the exclusive dependence on academic data for recommendations, without considering other factors such as personal interests, professional expectations, or learning styles, which have been shown to be relevant in previous studies [2, 6]. Future research could incorporate these variables to improve the accuracy and personalization of the system and evaluate its impact on student satisfaction and academic performance.
The findings of this study demonstrate that integrating machine learning models into academic recommendation systems can optimize elective course selection and facilitate student decision-making based on their academic history and competencies. The combination of dimensionality reduction using PCA and K-Means clustering allows for efficient data structuring, ensuring that recommendations are consistent with student performance patterns. Validation of the model with regression metrics confirmed its ability to generalize correctly, avoid overfitting problems, and achieve accuracy comparable to previous recommendation systems in the educational field.
At the implication level, the implementation of a functional and accessible user interface represents a step forward in adopting this system within academic institutions. Personalized recommendations can contribute to better curriculum planning, reduce uncertainty in course selection, and improve the alignment between acquired competencies and students' professional expectations. However, the effectiveness of the system depends on the quality and diversity of the data used, suggesting the need to incorporate complementary sources of information, such as individual interests and career goals, to improve recommendation accuracy.
Furthermore, one limitation of this study lies in the reduced diversity of the dataset, which was restricted to 120 students from a single institution. This narrow scope may affect the generalizability of the model to broader educational contexts. Future implementations should consider cross-institutional validation and data collection across various academic environments to enhance the robustness and external applicability of the recommendation system.
In terms of projection, future research should explore the integration of hybrid models that combine content-based approaches with collaborative filtering algorithms to enable more adaptive and contextual recommendations. For instance, advanced hybrid architectures based on matrix factorization combined with content-based features derived from course descriptions or user profile vectors could be tested to improve performance under sparse data conditions.
Additionally, incorporating natural language processing techniques based on transformer architectures, such as BERT, could enhance the system’s ability to extract semantic and affective information from open-ended student feedback, identify sentiment patterns, and refine recommendations based on qualitative insights. Other approaches, such as topic modeling and sentiment classification, could further contribute to capturing student preferences beyond structured academic records.
Thanks to the Universidad Nacional de San Martín for funding the project "Modelo híbrido de recomendación de cursos electivos para estudiantes de pregrado basado en ponderación, preferencias y aprendizaje automático", funded by University Council Resolution No. 1063-2022-UNSM/CU-R.
[1] Miotto, G., Del-Castillo-Feito, C., Blanco-González, A. (2020). Reputation and legitimacy: Key factors for higher education institutions’ sustained competitive advantage. Journal of Business Research, 112: 342-353. https://doi.org/10.1016/j.jbusres.2019.11.076
[2] Patel, N.S., Puah, S., Kok, X.F.K. (2024). Shaping future-ready graduates with mindset shifts: Studying the impact of integrating critical and design thinking in design innovation education. Frontiers in Education, 9: 1358431. https://doi.org/10.3389/feduc.2024.1358431
[3] Costa, M.F.B., Cipolla, C.M. (2025). Critical soft skills for sustainability in higher education: A multi-phase qualitative study. Sustainability, 17(2): 377. https://doi.org/10.3390/su17020377
[4] Hammond, D.A., Rowe, J.M., Wiley, T.L., Painter, J.T. (2018). Evaluation of an elective course for preparing students to pursue postgraduate residency training. Currents in Pharmacy Teaching and Learning, 10(9): 1264-1271. https://doi.org/10.1016/j.cptl.2018.06.007
[5] Mahajan, R., Singh, T. (2021). Electives in undergraduate health professions training: Opportunities and utility. Medical Journal Armed Forces India, 77: S12-S15. https://doi.org/10.1016/j.mjafi.2020.12.005
[6] Ma, B.X,, Lu, M., Taniguchi, Y., Konomi, S. (2021). Investigating course choice motivations in university environments. Smart Learning Environments, 8: 31. https://doi.org/10.1186/s40561-021-00177-4
[7] Samara, F. (2015). Factors influencing students’ choice of elective science courses: A case study from the American University of Sharjah. Open Journal of Social Sciences, 3(8): 93-99. https://doi.org/10.4236/jss.2015.38010
[8] He, Z.H., Yang, S.H., Liu, Y., Yin, L., Li, Z.G., Weng, Q.Y. (2022). The effect of course characteristics and self-efficacy on practical training course satisfaction: Moderating effect of the perceived usefulness of wisdom teaching. Sustainability, 14(23): 15660. https://doi.org/10.3390/su142315660
[9] Oripova, M. (2022). The impact of intrusive college academic advising on high school students’ college degree attainment commitment levels: A quantitative quasi-experimental study. Social Sciences & Humanities Open, 6(1): 100315. https://doi.org/10.1016/j.ssaho.2022.100315
[10] Iatrellis, O., Kameas, A., Fitsilis, P. (2017). Academic advising systems: A systematic literature review of empirical evidence. Education Sciences, 7(4): 90. https://doi.org/10.3390/educsci7040090
[11] Gulzar, Z., Leema, A.A., Deepak, G. (2018). PCRS: Personalized course recommender system based on hybrid approach. Procedia Computer Science, 125: 518-524. https://doi.org/10.1016/j.procs.2017.12.067
[12] Lynn, N.D., Emanuel, A.W.R. (2021). A review on Recommender Systems for course selection in higher education. IOP Conference Series: Materials Science and Engineering, 1098(3): 032039. https://doi.org/10.1088/1757-899X/1098/3/032039
[13] Zaqueu, L. (2024). Challenges and opportunities for digital transformation in Mozambique's higher education institutions. Revista Científica de Sistemas e Informática, 4(2): e690. https://doi.org/10.51252/rcsi.v4i2.690
[14] Urdaneta-Ponte, M.C., Mendez-Zorrilla, A., Oleagordia-Ruiz, I. (2021). Recommendation systems for education: Systematic review. Electronics, 10(14): 1611. https://doi.org/10.3390/electronics10141611
[15] Fedushko, S., Ustyianovych, T., Syerov, Y. (2022). Intelligent academic specialties selection in higher education for Ukrainian entrants: A recommendation system. Journal of Intelligence, 10(2): 32. https://doi.org/10.3390/jintelligence10020032
[16] Noguera, A., Rúa, S., Toro-Ossaba, A., Arcila, M., Ramírez-Neria, M., Tejada, J.C. (2023). Recommender System for enrollment advice of elective courses for students of Electronic Engineering and Telecommunications Engineering from UNAD. In 2023 IEEE 6th Colombian Conference on Automatic Control (CCAC), Popayan, Colombia, pp. 1-5. https://doi.org/10.1109/CCAC58200.2023.10333617
[17] Esteban, A., Zafra, A., Romero, C. (2020). Helping university students to choose elective courses by using a hybrid multi-criteria recommendation system with genetic optimization. Knowledge-Based Systems, 194: 105385. https://doi.org/10.1016/j.knosys.2019.105385
[18] Cha, S., Loeser, M., Seo, K. (2024). The impact of AI-based course-recommender system on students’ course-selection decision-making process. Applied Sciences, 14(9): 3672. https://doi.org/10.3390/app14093672
[19] Lloyd, S.P. (1982). Least squares quantization in PCM. IEEE Transactions on Information Theory, 28(2): 129-137. https://doi.org/10.1109/TIT.1982.1056489
[20] Liu, F., Deng, Y. (2021). Determine the number of unknown targets in open world based on elbow method. IEEE Transactions on Fuzzy Systems, 29(5): 986-995. https://doi.org/10.1109/TFUZZ.2020.2966182
[21] Rousseeuw, P.J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20: 53-65. https://doi.org/10.1016/0377-0427(87)90125-7
[22] Almiman, A., Othman, M.T.B. (2024). Predictive analysis of computer science student performance: An ACM2013 knowledge area approach. Ingénierie des Systèmes d’Information, 29(1): 169-189. https://doi.org/10.18280/isi.290119