Defri Kurniawan![]() | Abu Salam*
| Abu Salam*![]() | Yani Parti Astuti
| Yani Parti Astuti![]() | Catur Supriyanto
| Catur Supriyanto![]() | Guruh Fajar Shidik
| Guruh Fajar Shidik![]() | Pulung Nurtantio Andono
| Pulung Nurtantio Andono![]() | Noor Zuraidin Mohd Safar
| Noor Zuraidin Mohd Safar![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Breast cancer detection using medical imaging remains a challenging task due to the large volume of mammograms and the inherent class imbalance in datasets. This study proposes a novel regions of interest (ROIs)-based approach using RSNA screening mammography breast cancer detection dataset. By focusing on specific ROIs within the mammograms, the computational load is reduced while allowing the model to concentrate on the most critical areas. Additionally, SMOTE Tomek Link is applied to mitigate the class imbalance by generating synthetic samples for the minority (cancerous) class and removing noisy or overlapping samples. Three dataset splits were created: Split 1 (5:1 ratio of normal to cancer cases), Split 2 (3:1), and a fully balanced Random Under-Sampling (RUS) dataset. Various CNN models, including InceptionV3, ResNet152V2, DenseNet201, and EfficientNetB7, were evaluated on different dataset splits. Our results demonstrate that the EfficientNetB7 model, in conjunction with ROI extraction and SMOTE Tomek Link, achieves the highest accuracy of 97.41% on the Split 2 dataset, highlighting the effectiveness of these preprocessing techniques in enhancing deep learning-based breast cancer detection.
breast cancer detection, Region of Interest, SMOTE Tomek Link, oversampling, CNN
Breast cancer is a major global health concern and one of the most common malignancies affecting women globally [1-3]. After lung cancer, breast cancer ranks as the second most prevalent cause of death among women [4]. Breast cancer incidence continues to rise according to statistics from respectable health organizations, emphasizing the essential need for early detection and intervention. Early detection not only improves treatment outcomes but also increases the probability of a full recovery. Studies show that women diagnosed with breast cancer in its early stages have substantially better survival rates, enabling more effective and less invasive treatments [5].
Despite advancements in medical imaging technologies, accurate breast cancer detection remains a challenging task. The complexity lies in the vast volume of mammographic images and the relatively small size of abnormalities compared to surrounding breast tissue [6]. Moreover, the imbalanced nature of breast cancer datasets, where normal cases significantly outnumber cancerous ones, exacerbates the problem by skewing model predictions towards the majority class [7]. One of the key issues in breast cancer detection is how to efficiently process large volumes of medical images while maintaining a high level of accuracy in detecting malignancies. Manual examination of such datasets is time-consuming, labor-intensive, and prone to human error [8]. This highlights the need for automated methods that can accurately identify suspicious regions within images without overwhelming medical practitioners with data overload [9].
Breast cancer detection methods can be broadly classified into two types: region-of-interest (ROI)-based and patch-based approaches [10]. ROI-based methods focus on isolating specific areas of the image that are most likely to contain abnormalities, excluding irrelevant regions to streamline analysis. In contrast, patch-based methods divide the image into smaller segments, conducting feature extraction or detection on each segment individually [11]. Determining whether patch-based or ROI-based methods are better depends on various factors including the specific application, dataset characteristics, computational resources, and the desired balance between accuracy and efficiency [12]. Patch-based methods often offer more granularity and flexibility in analyzing images as they operate on smaller segments or patches, allowing for detailed feature extraction and potentially capturing local patterns effectively. However, they may require processing multiple patches across the entire image, which can be computationally intensive and time-consuming, especially for high-resolution images [13]. On the other hand, ROI-based methods focus only on the regions of interest containing relevant information, potentially reducing computational overhead and processing time. Choosing ROI is a common step in medical image analysis across all imaging modalities [14]. By isolating the target areas, ROI-based approaches may also enhance the signal-to-noise ratio and improve the efficiency of subsequent analysis steps. However, identifying accurate ROIs upfront can be challenging, and there is a risk of overlooking important information present in other parts of the image.
This study proposes a ROI-based approach combined with oversampling techniques to address these challenges. By focusing on specific areas within the mammograms that are likely to contain abnormalities, the ROI-based method reduces the computational load and allows the model to concentrate on the most critical parts of the image [15]. Additionally, SMOTE Tomek Link, an oversampling technique, is applied to handle the dataset imbalance by generating synthetic samples for the minority (cancerous) class while removing noisy or overlapping samples between the classes [16]. This combined approach not only improves the model's ability to detect cancerous regions but also mitigates the effects of class imbalance, leading to more reliable predictions.
The integration of ROI-based methods with SMOTE Tomek Link for breast cancer detection is a novel contribution in this field. While ROI-based methods have been explored in medical image analysis, most studies have focused on either ROI extraction or oversampling techniques in isolation. Our approach stands out by addressing two critical issues simultaneously: focusing on the region’s most likely to contain abnormalities and dealing with the class imbalance inherent in breast cancer datasets. In contrast to traditional patch-based methods that divide the entire image into smaller sections for analysis, our ROI-based method specifically isolates the most relevant areas, which reduces both computational costs and the risk of false positives. Moreover, the use of SMOTE Tomek Link further enhances the model's performance by balancing the dataset, allowing the CNN architectures to learn effectively from both normal and cancerous cases. By addressing both data imbalance and precise feature extraction, this study sets a new standard for breast cancer detection, making it a promising approach for clinical applications where accuracy and efficiency are paramount.
Mammography and ultrasonography are widely used as imaging modalities for the early detection of breast cancer. Mammography is a process that uses low-dose X-rays to capture images of the breast for diagnosing breast cancer from various projection angles. Meanwhile, ultrasonography is a non-radioactive and low-invasive procedure that captures images from various angles using probe pressure [17]. While both techniques are crucial in breast cancer diagnosis, mammography remains the gold standard, particularly with recent technological advancements such as digital mammography, tomosynthesis, and artificial intelligence (AI)-based CAD systems, which have significantly improved accuracy and sensitivity in cancer detection.
Recent studies have focused on improving mammography using deep learning and machine learning approaches. In the study by Jafari and Karami [18], a Convolutional Neural Network (CNN) approach is employed for diagnosing breast cancer using mammography images. CNNs have emerged as a dominant trend in the healthcare sector due to their powerful feature extraction capabilities. This approach leverages pre-trained CNN models for feature extraction, followed by classification using various machine learning algorithms, including k-Nearest Neighbors (k-NN), Support Vector Machine (SVM), Random Forest (RF), and Neural Network (NN). The dataset used in this study is the RSNA Screening Mammography Dataset. Additionally, the dataset includes key features such as age, implantation, Breast Imaging Reporting and Data System (BIRADS), and density, which are used to enhance the classification process. The results of this study demonstrate that the Neural Network-based model achieved the highest accuracy, reaching 92% for breast cancer diagnosis on the RSNA dataset.
In a study by Alsubai et al. [19], the authors propose a robust model for improving breast cancer classification. Their approach leverages advanced techniques like Deep CNN and InceptionV3 for feature extraction, Modified Scalable-Neighborhood Component Analysis for feature fusion, and Genetic-Hyper Parameter Optimization for tuning model parameters. This comprehensive approach aims to enhance both the accuracy and efficiency of breast cancer prognostication. Key contributions of the model include the extraction of significant features, optimization of distance-learning objectives, and identification of optimal hyperparameter values for classification. The model's performance was evaluated using multiple metrics, achieving a high accuracy rate of 99.87% on the CBIS-DDSM dataset, demonstrating its efficacy in distinguishing between normal and affected breast cancer cases. Consequently, in this research, the RSNA and CBIS-DDSM datasets will be employed for further evaluation.
In the study by Alrubaie et al. [20], a deep learning model incorporating advanced feature selection techniques was employed for breast cancer detection using ultrasound images. The researchers utilized CNN and VGG16 for feature extraction, alongside Principal Component Analysis (PCA) for dimensionality reduction. By combining these methods, the study achieved classification accuracies ranging from 93% to 97%, highlighting the model's ability to identify relevant patterns in breast cancer diagnosis. To enhance the precision of the model, the dataset was preprocessed using ROI technique, which involved cropping the ultrasound images to focus on the most significant areas for analysis. This preprocessing step ensured that the model concentrated on the most informative regions, thus improving its performance in detecting cancerous tissues. The integration of feature extraction with CNN and VGG16, combined with PCA for feature selection, demonstrates a well-rounded approach to maximizing classification accuracy while reducing computational complexity.
While this study demonstrated the effectiveness of CNN models in breast cancer detection, it did not address the issue of class imbalance within the dataset, which can lead to biased model predictions. Our study improves upon this limitation by incorporating oversampling techniques, specifically SMOTE Tomek Link, to balance the dataset and enhance detection accuracy. In the study by Alrubaie et al. [20], a breast cancer dataset with significant class imbalance—355 benign instances and 214 malignant instances—posed challenges for accurate machine learning predictions. To address this, the researchers applied SMOTE-Tomek Link, a data preprocessing technique that combines Synthetic Minority Over-sampling Technique (SMOTE) to generate synthetic minority class samples and Tomek Link to remove noisy or overlapping samples between classes, thereby improving data balance. The study utilized Naive Bayes and SVM models to predict breast cancer, and performance was evaluated using accuracy, sensitivity, and Area Under the Curve (AUC) metrics. Results showed that the SVM model achieved 96.80% accuracy, with matching sensitivity and AUC values, while the Naive Bayes model achieved 95.00% accuracy, with 94.00% sensitivity and an AUC of 95.00%, demonstrating an overall improvement in classification performance due to the data preprocessing approach.
3.1 Dataset
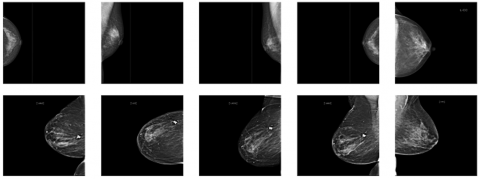
The RSNA screening mammography breast cancer detection dataset is a large dataset specifically designed for developing machine learning models for breast cancer detection. It consists of 54,713 mammographic images from around 11,000 patients, with each patient having at least four images taken from different projection angles and laterality to ensure comprehensive coverage of the breast tissue. The dataset includes crucial metadata such as age, implantation status, BIRADS scores, and breast density, which are important features for classification and risk assessment. The mammograms were originally stored in DICOM format and later resized to 512×512 pixels and converted to 8-bit grayscale to standardize the images for deep learning model training. The example of the images is shown in Figure 1. Figure 1 illustrates a visual comparison between mammogram images representing two distinct classes: the normal class (first row) and the cancer class (second row). In the first row, images depict mammograms from patients classified as normal, meaning no cancerous regions are detected. These images exhibit smooth, uniform breast tissue without any apparent masses or irregularities. The mammograms show clear areas with no signs of abnormal growth or suspicious features. In contrast, the second row contains mammograms from the cancer class, where cancerous regions are present. These images demonstrate noticeable differences compared to the normal class, with visible irregular masses or calcifications that may indicate the presence of malignant tumors. These abnormalities are typically denser and have an uneven shape, which is characteristic of cancerous tissue in mammograms. The visual differences between the normal and cancerous mammograms highlight the importance of feature extraction and detection, as well as the role of the deep learning model in distinguishing between these two classes to support early and accurate diagnosis.
Figure 1. Sample images from the RSNA dataset [21]
3.2 Proposed method
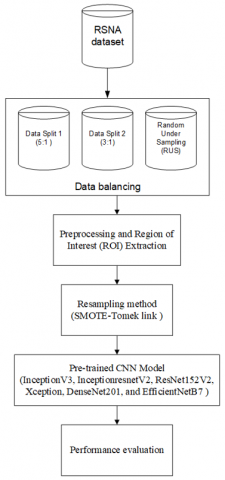
The proposed method of this study shown in Figure 2. It begins by utilizing the RSNA dataset, a widely recognized collection of mammographic images for breast cancer detection. The original RSNA dataset appears highly imbalanced as only about 1.8% of the images fall into the cancer class. To prepare the data for analysis, the dataset undergoes data splitting using two distinct ratios. The first split follows a 5:1 ratio, resulted 5,790 of normal class and 1,158 of cancer class. A second split with a 3:1 ratio is also employed, resulted 3,474 normal class and 1,158 cancer class. Additionally, a Random Under Sampling (RUS) technique is applied to address the issue of class imbalance in the dataset. This involves reducing the number of majority class samples, ensuring that the model does not become biased towards one class during training. The class distribution of dataset shown in Figure 3. Once the dataset is balanced, the images proceed through a preprocessing stage. During preprocessing, the images are converted to grayscale, which simplifies the image by removing color information and highlighting the most critical structures. This is a crucial step for reducing computational complexity while preserving key details necessary for detecting abnormalities. Following this, a ROI extraction method is applied to isolate specific areas of the mammograms that are most likely to contain cancerous lesions. By focusing only on these regions, the model becomes more efficient at detecting abnormalities while reducing noise from irrelevant parts of the image.
Figure 2. Proposed method
Figure 3. Class distribution
To further address the issue of class imbalance, a hybrid resampling method combining the SMOTE and Tomek Link is applied. SMOTE works by generating synthetic samples for the minority class (cancerous images) through interpolation between existing minority samples. This approach effectively increases the representation of the minority class, reducing the bias towards the majority class. However, while SMOTE addresses the imbalance, it can introduce noisy or overlapping data points. To counteract this, Tomek Link is employed as a cleaning technique. It identifies pairs of samples (one from the minority class and one from the majority class) that are closest to each other and misclassified by the classifier, known as Tomek Links. These pairs are removed to increase the separation between classes. By combining SMOTE and Tomek Link, the method not only oversamples the minority class but also removes borderline examples that may lead to model confusion, thus creating a cleaner and more distinct decision boundary. This hybrid approach offers an advantage over other oversampling techniques by simultaneously increasing minority class representation and reducing noise and class overlap, improving the model’s ability to accurately distinguish between cancerous and non-cancerous images.
The core of the analysis involves the use of several pre-trained CNN models, including InceptionV3, InceptionResNetV2, ResNet152V2, Xception, DenseNet201, and EfficientNetB7. These models have been previously trained on large image datasets, which allows them to perform highly effective feature extraction from medical images. In this study, these pre-trained models are fine-tuned to detect breast cancer within the extracted ROIs from the mammograms. By leveraging transfer learning, the research takes advantage of the powerful feature representations learned by these models, ensuring that they can accurately identify subtle patterns associated with breast cancer.
Finally, the performance of these models is evaluated using a range of standard metrics to assess their effectiveness in detecting breast cancer. Metrics such as accuracy, precision, recall, and F1-score are likely used to provide a comprehensive evaluation of each model's ability to correctly classify the images. This performance evaluation allows the study to determine the most effective approach for detecting breast cancer using the combination of ROI extraction, data balancing techniques, and pre-trained CNN models. This detailed methodology demonstrates the rigorous approach taken to develop an accurate and robust system for breast cancer detection.
3.3 Experimental setting
This experimental setup ensure that the models are well-optimized to achieve high accuracy and robustness in detecting breast cancer, especially in a dataset with significant class imbalance. The dataset is divided into two parts, with 80% allocated for training and 20% for testing, while 10% of the training data is set aside as validation data to monitor performance and prevent overfitting. The dataset is processed using various CNN architecture models, with optimized hyperparameters as detailed in Table 1. These include a learning rate of 0.0001, a batch size of 32, 100 epochs, the Adam optimizer, and the ReLU activation function to ensure optimal performance. The chosen learning rate allows for fine-tuned weight adjustments, while the batch size balances memory usage and computational efficiency. The Adam optimizer is selected for its adaptability and ability to handle noisy gradients, aiding faster convergence, and the ReLU activation function enables the model to effectively capture non-linear relationships within the data. The entire experiment is conducted using Python on a DGX A100 server equipped with 40GB of RAM, leveraging GPU acceleration to handle large-scale computations. This setup ensures the model can efficiently process high-resolution mammographic images, reducing training time and overcoming memory constraints, while enabling high performance in breast cancer detection.
Table 1. Hyperparameter setting
|
Hyperparameter |
Value |
Task |
|
Learning Rate |
0.0001 |
Ensures stable convergence and avoids overshooting the optimal weights. |
|
Batch Size |
32 |
Balances memory efficiency and stable gradient updates for large datasets. |
|
Epochs |
100 |
Allows sufficient time for model convergence without overfitting. |
|
Optimizer |
Adam |
Adam’s adaptive learning rates accelerate convergence, particularly for deep models. |
|
Activation Function |
ReLU |
Introduces non-linearity, essential for capturing complex image patterns. |
|
CNN Architectures |
InceptionV3, ResNet152V2, DenseNet201, Xception, EfficientNetB7 |
Selected due to their proven performance in medical image analysis and feature extraction. |
3.4 Performance metrics
The performance of the models was evaluated using accuracy, precision, recall, and F1 score. These metrics were derived from the model’s confusion matrix, which is based on the values of True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN), as shown in Eqs. (1)-(4). Each metric provides a different perspective on the model’s ability to correctly classify cancerous and non-cancerous regions, offering a comprehensive assessment of its performance.
Accuracy $=\frac{T P+T N}{T P+T N+F P+F N}$ (1)
Precision $=\frac{T P}{T P+F P}$ (2)
Recall $=\frac{T P}{T P+F N}$ (3)
$F 1-Score =\frac{2 *( { Precision }+ { Recall })}{{ Precision }+ { Recall }}$ (4)
4.1 Result of image preprocessing and ROI extraction
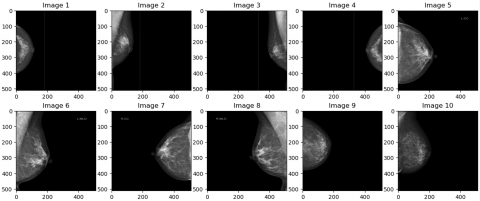
This section presents a comparison of the image between the original dataset and the image cutting result obtained from the ROI extraction, shown in Figure 4. The process starts with converting the image to a grayscale scale, performing a pixel value filter with a threshold value of 0.05, performing the object selection process and cutting the selected area as well as resizing the image for 400 × 250 feature modeling. The ROI extraction removes unnecessary parts of the mammogram, retaining only the areas crucial for classification or detection tasks. This preprocessing step helps reduce computational complexity and focuses the model's attention on regions where abnormalities are likely to occur.
(a) Image size of 512 × 512 from original dataset
(b) Image size of 400 × 250 from ROI
Figure 4. Comparison results of original dataset and ROI extraction
The performance comparison of breast cancer detection using CNN both with and without ROI extraction across various datasets shown in Table 2. RSNA original dataset achieves 50% accuracy both with and without ROI extraction, indicating no significant improvement from applying ROI extraction to this particular dataset. Data split 1 and Data split 2 showed ROI extraction significantly improves accuracy. Without ROI, accuracy is around 55-58%, but with ROI extraction, accuracy jumps to 82-86%. This indicates that ROI extraction enhances the model's ability to focus on relevant features, leading to better performance. Similar to the RSNA original data, there is no improvement with ROI extraction as both methods yield a 50% accuracy rate on RSU dataset.
Table 2. Result of breast cancer detection using CNN
|
Dataset |
Without ROI Extraction (%) |
With ROI (%) |
|
RSNA original data |
50 |
50 |
|
Data split 1 |
55.82 |
82.33 |
|
Data split 2 |
58.19 |
85.78 |
|
RUS |
50 |
50 |
4.2 Result of breast cancer detection with SMOTE-Tomek Link resampling on CNN pretrained model
The optimized results of breast cancer detection using the SMOTE-Tomek Link oversampling technique combined with CNN, both with and without ROI extraction highlighted on Table 3. Data split 1 used SMOTE-Tomek Link and CNN, the accuracy without ROI is 70.91%, but with ROI extraction, the accuracy jumps to 87.07%. This indicates a substantial performance improvement of over 16% with ROI extraction. While on the data split 2, the model achieves 79.31% accuracy without ROI and 91.38% with ROI extraction. The ROI extraction improves accuracy by around 12%.
Table 3. Optimized result of breast cancer detection using SMOTE-Tomek Link and CNN
|
Dataset |
Without ROI |
With ROI |
|
Split 1 |
70.91 |
87.07 |
|
Split 2 |
79.31 |
91.38 |
Table 4. Optimized accuracy results of data split 2 with ROI extraction
|
Pretrained Model |
Without SMOTE-Tomek Link (%) |
With SMOTE-Tomek Link (%) |
|
InceptionV3 |
84.70 |
92.24 |
|
InceptionresnetV2 |
79.96 |
91.81 |
|
ResNet152V2 |
84.48 |
91.59 |
|
Xception |
80.39 |
92.24 |
|
DenseNet201 |
87.93 |
93.10 |
|
EfficientNetB7 |
96.77 |
97.41 |
Table 5. Optimized precision result of data split 2 with ROI extraction
|
Pretrained Model |
Without SMOTE-Tomek Link (%) |
With SMOTE-Tomek Link (%) |
|
InceptionV3 |
97.41 |
98.71 |
|
InceptionresnetV2 |
96.98 |
98.28 |
|
ResNet152V2 |
98.71 |
98.28 |
|
Xception |
99.14 |
99.14 |
|
DenseNet201 |
99.57 |
99.14 |
|
EfficientNetB7 |
99.57 |
97.41 |
The impact of applying the SMOTE-Tomek Link oversampling technique on the accuracy of various pretrained models of data split 2 for breast cancer detection using ROI extraction shown on Table 4. Across all models, the accuracy improves significantly after using SMOTE-Tomek Link, which addresses the issue of class imbalance. EfficientNetB7 demonstrates the highest performance, with accuracy rising from 96.77% to 97.41%, while DenseNet201 and InceptionV3 also show notable improvements. Even models with lower initial accuracy, like InceptionResNetV2 and Xception, achieve over 91% accuracy after oversampling. This highlights the effectiveness of combining ROI-based detection with oversampling techniques to enhance model performance, particularly in imbalanced medical imaging datasets.
Table 5 presents the optimized precision results for various pretrained models on data split 2 before and after applying the SMOTE-Tomek Link technique for ROI-based breast cancer detection. Most models show slight improvements in precision after oversampling, with InceptionV3 improving from 97.41% to 98.71% and InceptionResNetV2 from 96.98% to 98.28%. Xception maintains a consistent precision of 99.14% both before and after applying SMOTE-Tomek Link. Interestingly, EfficientNetB7 experiences a slight drop in precision from 99.57% to 97.41% post-oversampling, despite maintaining the highest precision before applying the technique. Overall, these results demonstrate that applying the SMOTE-Tomek Link on data split 2 generally enhances precision, though the extent of improvement varies depending on the model used.
4.3 Comparison result of the previous studies
Table 6 highlights a comparison between previous studies and our approach using EfficientNetB7 with ROI extraction and the SMOTE-Tomek Link oversampling technique for breast cancer detection. Our method outperforms both previous studies in terms of accuracy, recall, precision, and F1-Score, achieving 97.41% across all metrics. In contrast, the study by Huynh et al. [10, 22], which also used EfficientNet, reported a slightly lower accuracy of 95.6% but did not provide other performance metrics like recall or precision, limiting the ability to fully assess its model’s effectiveness. Jafari and Karami [18] achieved 92% accuracy and 96% recall using concatenated CNN features, but their precision and accuracy lagged behind our results. The implications of these findings are significant, by incorporating both ROI-based detection and the SMOTE-Tomek Link technique to address class imbalance, our approach demonstrates enhanced overall model performance, particularly in handling challenging cases of minority class detection (e.g., positive cancer cases). This suggests that oversampling methods, combined with advanced feature extraction models like EfficientNetB7, are crucial for improving the robustness and reliability of breast cancer detection systems.
Table 6. Comparison results of the previous studies
|
Methods |
Accuracy (%) |
Recall (%) |
Precision (%) |
F1-Score (%) |
|
EfficientNet [22] |
95.6 |
- |
- |
- |
|
Concatenate features from CNN + NN [18] |
92 |
96 |
92 |
- |
|
EfficientNetB7 with ROI and SMOTE+Tomek Link |
97.41 |
97.41 |
97.41 |
97.4 |
This study proposes the use of ROI in the detection of breast cancer, assessing various image proportion schemes to address the significant imbalance observed in the original dataset. The original dataset, along with three modified versions—Split 1, Split 2, and RUS datasets—were evaluated for effectiveness. The Split 1 and Split 2 datasets were derived by extracting data at ratios of 5:1 and 3:1, respectively, from the original dataset, resulting in progressively less severe imbalances. The RUS dataset represents a balanced version achieved through RUS method. Experimental results reveal that the Split 2 ratio scheme yields superior accuracy compared to the other datasets, with the EfficientNetB7 model achieving the highest accuracy of 97.41% after applying SMOTE+Tomek Link oversampling. Although the study yielded promising outcomes, opportunities for further refinement exist. Future work could include incorporating more advanced data augmentation techniques to enhance dataset diversity. Additionally, deploying the system in a real-world clinical setting and testing its efficacy on a larger and more varied dataset could significantly contribute to its validation, enhancing its robustness and generalizability for practical applications.
We express our gratitude to the Universitas Dian Nuswantoro (UDINUS) Office of Research and Community Service (LPPM) for their invaluable support in making this research possible (Contract No.: 109/A.38-04/UDN-09/XI/2023).
[1] Gómez-Flores, W., de Albuquerque Pereira, W.C. (2020). A comparative study of pre-trained convolutional neural networks for semantic segmentation of breast tumors in ultrasound. Computers in Biology and Medicine, 126: 104036. https://doi.org/10.1016/j.compbiomed.2020.104036
[2] Xu, Y., Dos Santos, M.A., Souza, L.F., Marques, A.G., Zhang, L., da Costa Nascimento, J.J., Rebouças Filho, P.P. (2022). New fully automatic approach for tissue identification in histopathological examinations using transfer learning. IET Image Processing, 16(11): 2875-2889. https://doi.org/10.1049/ipr2.12449
[3] Bray, F., Laversanne, M., Sung, H., Ferlay, J., Siegel, R. L., Soerjomataram, I., Jemal, A. (2024). Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: A Cancer Journal for Clinicians, 74(3): 229-263. https://doi.org/10.3322/caac.21834
[4] Bayrak, E.A., Kırcı, P., Ensari, T. (2019). Comparison of machine learning methods for breast cancer diagnosis. In 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, pp. 1-3. https://doi.org/10.3322/caac.21834
[5] Lee, H., Chen, Y.P.P. (2015). Image based computer aided diagnosis system for cancer detection. Expert Systems with Applications, 42(12): 5356-5365. https://doi.org/10.1016/j.eswa.2015.02.005
[6] Mahmood, T., Li, J., Pei, Y., Akhtar, F., Rehman, M.U., Wasti, S.H. (2022). Breast lesions classifications of mammographic images using a deep convolutional neural network-based approach. Plos One, 17(1): e0263126. https://doi.org/10.1371/journal.pone.0263126
[7] Walsh, R., Tardy, M. (2022). A comparison of techniques for class imbalance in deep learning classification of breast cancer. Diagnostics, 13(1): 67. https://doi.org/10.3390/diagnostics13010067
[8] Bi, W.L., Hosny, A., Schabath, M.B., Giger, M.L., Birkbak, N.J., Mehrtash, A., Aerts, H.J. (2019). Artificial intelligence in cancer imaging: Clinical challenges and applications. CA: A cancer Journal for Clinicians, 69(2): 127-157. https://doi.org/10.3322/caac.21552
[9] Elyan, E., Vuttipittayamongkol, P., Johnston, P., Martin, K., McPherson, K., Moreno-García, C.F., Sarker, M.M.K. (2022). Computer vision and machine learning for medical image analysis: Recent advances, challenges, and way forward. Artificial Intelligence Surgery, 2(1): 24-45. https://doi.org/10.20517/ais.2021.15
[10] Huynh, H.N., Tran, A.T., Tran, T.N. (2023). Region-of-interest optimization for deep-learning-based breast cancer detection in mammograms. Applied Sciences, 13(12): 6894. https://doi.org/10.3390/app13126894
[11] Hasan, A.M., Diepeveen, D., Laga, H., Jones, M.G., Sohel, F. (2023). Image patch-based deep learning approach for crop and weed recognition. Ecological Informatics, 78: 102361. https://doi.org/10.1016/j.ecoinf.2023.102361
[12] Rayed, M.E., Islam, S.S., Niha, S.I., Jim, J.R., Kabir, M.M., Mridha, M.F. (2024). Deep learning for medical image segmentation: State-of-the-art advancements and challenges. Informatics in Medicine Unlocked, 47: 101504. https://doi.org/10.1016/j.imu.2024.101504
[13] Ullah, F., Salam, A., Abrar, M., Amin, F. (2023). Brain tumor segmentation using a patch-based convolutional neural network: A big data analysis approach. Mathematics, 11(7): 1635. https://doi.org/10.3390/math11071635
[14] Hossain, M.S., Shahriar, G.M., Syeed, M.M., Uddin, M.F., Hasan, M., Shivam, S., Advani, S. (2023). Region of Interest (ROI) selection using vision transformer for automatic analysis using whole slide images. Scientific Reports, 13(1): 11314. https://doi.org/10.1038/s41598-023-38109-6
[15] Gao, Y.E., Lin, J., Zhou, Y., Lin, R. (2023). The application of traditional machine learning and deep learning techniques in mammography: A review. Frontiers in Oncology, 13: 1213045. https://doi.org/10.3389/fonc.2023.1213045
[16] Swana, E.F., Doorsamy, W., Bokoro, P. (2022). Tomek link and SMOTE approaches for machine fault classification with an imbalanced dataset. Sensors, 22(9): 3246. https://doi.org/10.3390/s22093246
[17] Sahu, A., Das, P.K., Meher, S. (2024). An efficient deep learning scheme to detect breast cancer using mammogram and ultrasound breast images. Biomedical Signal Processing and Control, 87: 105377. https://doi.org/10.1016/j.bspc.2023.105377
[18] Jafari, Z., Karami, E. (2023). Breast cancer detection in mammography images: A CNN-based approach with feature selection. Information, 14(7): 410. https://doi.org/10.3390/info14070410
[19] Alsubai, S., Alqahtani, A., Sha, M. (2023). Genetic hyperparameter optimization with Modified Scalable-Neighbourhood Component Analysis for breast cancer prognostication. Neural Networks, 162: 240-257. https://doi.org/10.1016/j.neunet.2023.02.035
[20] Alrubaie, H.D., Aljobouri, H.K., Aljobawi, Z.J. (2023). Efficient feature selection using CNN, VGG16 and PCA for breast cancer ultrasound detection. Revue d'Intelligence Artificielle, 37(5): 1255-1261. https://doi.org/10.18280/ria.370518
[21] RNSA-Mammography-512px-8bit. https://www.kaggle.com/datasets/deltaechov/rnsamamographt512px8bit/data.
[22] Huynh, H.N., Nguyen, N.A.D., Tran, A.T., Nguyen, V.C., Tran, T.N. (2023). Classification of breast cancer using radiological society of north America data by EfficientNet. Engineering Proceedings, 55(1): 6. https://doi.org/10.3390/engproc2023055006