Palraj Vimal Kumar*![]() | Subramaniam Erana Veerappa Dinesh
| Subramaniam Erana Veerappa Dinesh![]() | Ganesan Mareeswari
| Ganesan Mareeswari![]() | Mahalingam Jeya Sundari
| Mahalingam Jeya Sundari![]()
© 2026 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
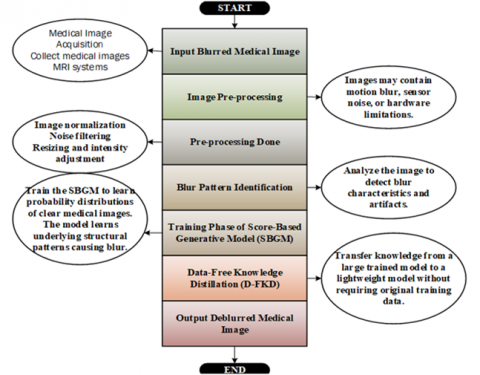
Image blurring presents a significant obstacle to medical imaging, hence reducing the precision and diagnostic use of obtained data. With the use of creative, effective sampling techniques and Score-Based Generative Models (SBGMs), this work tackles the crucial problem of rapid deblurring in medical imaging. This is a concern since better diagnostic accuracy and subsequent clinical decision-making depend on quick yet accurate deblurring. To accomplish effective and quick deblurring of medical images, the suggested system presents a novel method that makes use of SBGMs. Typically, motion artifacts or intrinsic imaging equipment limitations result in blurry medical images at the beginning of the system flow. Once taught to recognize the underlying patterns and characteristics causing image blurring, these images are processed through a specifically developed SBGM. The perceptual consistency (PC) model and sophisticated Data-Free Knowledge Distillation (D-FKD) techniques are integrated with effective sampling strategies to enable the SBGM to quickly learn and produce high-fidelity deblurred images. Extensive testing results show the significant improvements in medical image deblurring, reducing MSE from 50.32 to 20.07, increasing Signal-to-Noise Ratio (SNR) from 12.53 to 40.90, and enhancing Peak Signal-to-Noise Ratio (PSNR) from 33.69 to 43.26, without sacrificing image quality. In addition to addressing efficiency issues in medical image processing, the suggested system advances medical imaging technologies by helping to smoothly transfer deblurring models from lab settings to real-world clinical applications. However, limitations may exist concerning specific imaging modalities or complex blurring patterns, warranting further investigation. Nonetheless, our approach holds promise for improving medical imaging processes and clinical decision-making.
sampling method, deblurring, medical imaging technology, Data-Free Knowledge Distillation, Score-Based Generative Models, perceptual consistency model
Image deblurring tackles the problem of eliminating the different kinds of blur effects that are frequently present in images, making it an essential task in image processing. Motion blur, which is the result of relative motion between the camera and the object, and defocus blur, which is produced by spatially variable amounts, are two common types of blur that significantly affect image quality [1]. Various methods are employed to remove the blur in an image; deconvolution is able to remove blur in the image, but it consumes more time [2]. The diagnosis of the inside structure of the body is influenced by various factors such as the patient's motion degree and their movements in the equipment [3, 4]. Even though the existing traditional method faces various struggles in evaluating the image's sharp edges, it leads to loss of image information and artifacts interventions [5]. To overcome these challenges, the dual attention deep image prior (DADIP) network and 2-dimensional (2D) blur kernel estimation using a convolutional neural network (CNN) method is established, but this system also has some limitations [6]. Furthermore, there is still a challenging problem with uneven blur in images that needs to be rectified. Current approaches often fall short in properly integrating multi-scale feature extraction with a self-attention mechanism, while ignoring the potential contribution of image frequency domain information to image restoration. In response to these challenges, a residual wavelet transform and self-attention-based method for image deblurring has been presented [7]. This approach integrates sophisticated feature extraction and attention methods to enhance the restoration of non-uniform blurred images. Video deblurring has gained more interest in the field of computer vision. Mainstream methods, such as the Multi-Attention Convolutional Neural Network (MACNN), aim to restore sharp videos from blurry ones [8]. These techniques fuse the aligned frames for restoration to compensate for fuzzy pixels by aligning neighboring frames according to anticipated optical fluxes. In our proposed system, we employed Score-Based Generative Models (SBGMs) as efficient sampling strategies, which have an empirical remark in the domain of audio synthesis and image generation, and also attain a strong effect on the quality of samples and distribution coverage [9]. It is instantly employed for numerous networks and data spaces for the sampling process [10].
1.1 Research motivation
MRI and CT scans are two examples of medical imaging technologies that are very important for diagnosing diseases and making clinical decisions. But images taken with these methods often have blur because of motion artifacts, hardware limits, or fast acquisition protocols. This kind of degradation makes the image less clear and could lead to wrong medical interpretations. Conventional image deblurring techniques depend on inverse problem formulations and optimization-based strategies, including Wiener filtering and iterative reconstruction algorithms. Even though these methods give mathematically sound answers, they often have trouble with complicated blur patterns and can create artifacts. Recent progress in deep learning has made image restoration tasks much better. CNNs, generative adversarial networks (GANs), and transformer-based architectures have been utilized in the reconstruction of medical images. These models, on the other hand, often need a lot of training data and might not be able to capture the full range of clean medical images. Recently, score-based generative algorithms have become a strong way to solve inverse imaging problems. These models learn the gradient of the data distribution and make high-quality samples by using iterative diffusion processes. Even though diffusion-based methods work well, they need hundreds or thousands of sampling steps, which makes them very expensive to run. To overcome this limitation, this paper suggests an effective sampling strategy combined with SBGMs to speed up the process of deblurring medical images while keeping the quality of the reconstruction high. Motion artifacts, acquisition limitations, and hardware constraints frequently result in blurred images that diminish diagnostic quality. CNNs and optimization-based deblurring methods have a hard time keeping fine anatomical details while still being efficient in terms of computation. In this study, we present an expedited medical image deblurring structure utilizing SBGMs integrated with efficient sampling techniques and knowledge distillation. The suggested method adds a quick sampling method that cuts down on the number of iterative diffusion steps while keeping the quality of the reconstruction. A perceptual consistency (PC) module is also built in to keep anatomical structures intact during reconstruction. The results show that the proposed framework is a strong and efficient way to restore high-quality medical images. However, this study contributes to medical imaging by proposing a novel system leveraging SBGMs, Data-Free Knowledge Distillation (D-FKD), and a PC model. It addresses the challenge of motion artifacts and imaging device limitations, enhancing image quality and diagnostic accuracy. The system offers rapid and precise deblurring of medical images, reducing processing time and computational complexity. Through innovative sampling strategies and advanced algorithms, it achieves significant improvements in preserving image details and reducing artifacts compared to existing methods. By incorporating objective metrics such as MSE, SNR, Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index Measure (SSIM), it quantitatively evaluates the performance, demonstrating superior results across various datasets and compression ratios. Overall, this study provides a promising approach for enhancing medical imaging applications, facilitating more accurate diagnoses and treatments.
1.2 Novelty highlights and main contributions
The main contributions of this work can be summed up as follows:
2.1 Classical image deblurring methods
Early methods for deblurring used optimization-based techniques like Wiener filtering and Richardson-Lucy deconvolution, along with regularization-based methods. These methods need to be able to accurately guess the blur kernel, and they often have trouble with complicated real-world blur patterns [11, 12].
Ren et al. [13] introduced a novel approach for image deblurring using Image-conditioned Diffusion Probabilistic Models (icDPMs). Addressing limitations in robustness with out-of-domain images, multiscale structure guidance is incorporated, enhancing deblurring results, especially on unseen domains. The guidance is derived from a regression network's latent space, capturing essential sharp structures. The proposed icDPM model, equipped with both blurry input and multiscale guidance, exhibits an improved understanding of blur, resulting in cleaner image recovery. This paper comprehensively reviews deep learning methods for both CT images denoising and deblurring individually and concurrently [14]. The discussion extends to promising directions, including integration with large-scale pre-trained models and language models.
2.2 Deep learning-based deblurring
Recent deep learning models utilize CNN architectures to acquire end-to-end mappings among blurred and sharp images. Adversarial training is a feature of GAN-based methods that makes perceptual quality even better.
But when coping with complex blur, these methods may make artifacts or results that are too smooth [15-18].
In this article, a technique for extracting information from medical images taken with acquisition devices that produce blurry images was proposed [19]. For deblurring the images, an end-to-end trained deep-scale recurrent network is used, which performs better than previous efforts and is more suited for removing blur from hazy images. An iterative methodology was presented in a study [20] to address the need for deblurring images while utilizing the two methods already in use for observations. One is the Landweber technique, which uses a low-pass filter as a constant to account for hazy observations. Second, use the initial estimates from the original images as a guide. Then, a version that integrates the two changes into a single framework for repeatedly deblurring images was proposed, which updates this estimate as the iterative process moves along. Table 1 shows the comparison of image deblurring approaches in the literature.
Table 1. Comparison of image deblurring approaches in the literature
|
Ref. |
Method Category |
Core Technique / Model |
Application Domain |
Key Contributions |
Advantages |
Limitations |
|
Ren et al. [13] |
Diffusion-based Deblurring |
Image-conditioned Diffusion Probabilistic Model (icDPM) |
Natural image restoration |
Introduces multiscale structure guidance derived from latent space to improve out-of-domain robustness |
Improved blur understanding and better generalization to unseen images |
Computationally expensive diffusion sampling |
|
Lei et al. [14] |
Review Study |
Deep learning models for CT denoising and deblurring |
Medical imaging |
Comprehensive survey covering CNN, GAN, and hybrid restoration models |
Provides future directions, including pre-trained foundation models |
Does not propose a new algorithm |
|
Sharif et al. [19] |
Deep Learning-Based Deblurring |
Deep-scale recurrent network |
Medical imaging |
End-to-end model designed to remove blur from acquisition devices |
Captures temporal information and improves reconstruction accuracy |
Requires large training datasets |
|
Zhang et al. [20] |
Iterative Optimization |
Landweber-based iterative deblurring framework |
Image restoration |
Combines low-pass filtering with iterative estimation refinement |
Interpretable optimization process |
Slow convergence and limited performance on complex blur |
|
Zhang et al. [21] |
GAN-Based Deblurring |
Dual Adversarial Network (DAN) with patch-wise contrastive constraint |
Magnetic Particle Imaging (MPI) |
Handles PSF estimation challenges and improves boundary restoration |
Effective for unpaired datasets |
GAN training instability |
|
Tien et al. [22] |
GAN-Based Medical Deblurring |
Cycle-Deblur GAN |
Cone Beam CT (CBCT) |
Combines CycleGAN and Deblur-GAN for improving radiotherapy imaging |
Reduces noise, artifacts, and scatter |
Requires paired or semi-paired training datasets |
|
Ma et al. [23] |
CNN-Based Deblurring |
Defocus-aware neural network with defocus map estimation |
Single image defocus deblurring |
Introduces auxiliary defocus estimation task and new dataset |
Improved defocus blur handling |
Limited applicability to motion blur |
|
Li et al. [24] |
Deep Unrolling Model |
DUBLID (Deep Unrolling for Blind Deblurring) |
Natural images |
Bridges model-based optimization with deep learning |
Interpretable and efficient architecture |
Performance depends on training data |
|
Singh et al. [11] |
Score-Based Generative Model |
Score-based generative reconstruction |
PET imaging |
Handles Poisson noise and dynamic range in PET reconstruction |
Robust reconstruction for lesion detection |
Slow diffusion sampling |
|
Mei et al. [12] |
Score-Based Model |
Score-based inpainting reconstruction |
Orthopedic CT imaging |
Reduces metal artifacts using conditional resampling |
Effective for large missing regions |
Requires simulated training data |
|
Hong et al. [15] |
Score-Based Restoration |
High-dimensional assisted score model |
Image color restoration |
Uses channel-copy and pixel-scale transformations for restoration tasks |
Improves sampling diversity |
High computational complexity |
|
Li et al. [16] |
Diffusion-Based Segmentation |
Diffusion model with feature denoising module |
Medical image segmentation |
Plug-and-play denoising mechanism for segmentation |
Accurate segmentation of small lesions |
Computationally intensive |
|
Scassola et al. [17] |
Generative Neuro-Symbolic Framework |
Conditional diffusion with logical constraints |
Multimodal data |
Integrates symbolic reasoning into generative modeling |
Flexible data representation |
Limited application to image restoration |
|
Trippe et al. [18] |
CNN Restoration Model |
OCR-guided U-Net architecture |
Text image restoration |
Uses OCR-based scoring to guide deblurring |
Useful for document restoration |
Not designed for medical imaging |
A patch-wise contrastive constraint and a Dual Adversarial Network (DAN) for deblurring Magnetic Particle Imaging (MPI) images are proposed in this publication [21]. The suggested method efficiently overcomes constraints in unpaired data circumstances by addressing difficulties in measuring the Point Spread Function (PSF) properly due to environmental influences and magnetic particle relaxation. Through enhanced performance in reducing boundary blur, the DAN model improves the quality of MPI images in both simulated and real data assessments. Cycle-Deblur GAN is a deep learning model that integrates CycleGAN and Deblur-GAN and is presented in this work [22] to improve the picture quality of chest Cone beam Computed Tomography (CBCT) images used in image-guided radiotherapy. The model is trained on 8706 CBCT and fan-beam computed tomography (FBCT) picture pairings and tested on 1150 image pairs to address issues including X-ray scattering, noise, and artifacts that impair CBCT image quality. The Cycle-Deblur GAN improves image quality better than the current models.
In this paper, a novel network architecture for single-picture defocus deblurring is presented [23]. To improve deblurring results, the network uses defocus map estimation as a supplementary job. An innovative large-scale dataset consisting of defocus photos, defocus maps, and all-sharp images has been developed to facilitate network training. This study introduced a novel neural network architecture, Deep Unrolling for Blind Deblurring (DUBLID), based on the concept of algorithm unrolling [24]. Leveraging an iterative algorithm akin to total-variation regularization in the gradient domain, DUBLID connects traditional model-based methods to neural network structures. The proposed architecture achieves substantial practical performance improvements in blind image deblurring, maintaining interpretability and efficiency by learning key algorithm parameters from training images.
2.3 Generative models
Generative models that use scores learn the gradient of the log probability density of clean images. These models create high-quality samples from noisy observations by repeatedly reversing a diffusion process. Even though diffusion-based models work well, they have slow sampling speeds that make them less useful in medical imaging.
This study [11], introduces PET-specific adaptations to SBGMs, addressing challenges like Poisson noise and dynamic range in PET image reconstruction. Our framework accommodates both 2D and 3D PET, with an extension for guided reconstruction using magnetic resonance images. Through extensive in-silico experiments, we validate the approach on patient-realistic data, showcasing robustness and significant potential for enhanced PET reconstruction, particularly in scenarios involving lesions. In 3D reconstructions performed during orthopedic surgery using metallic implants, metal artifacts are discussed in this study [12]. The suggested method focuses on in-painting to minimize noise in the conditional resampling process, using an SBGM trained on simulated knee projections. The SBM demonstrates its efficacy in reducing metal artifacts for better image quality during orthopedic surgeries by demonstrating its generalization capabilities, especially in recovering projections with big circular and rectangular masks.
To restore the color to the image, this work [15] provides a high-dimensional aided SBGM. The channel-copy transformation and the pixel-scale transformation approach are used, respectively, to increase the sample count and decrease the space dimension. Determine the denoising score sequentially until the network matches the high-dimensional tensor sets. Overall, the results of inpainting and demosaicking the photos are discovered by our suggested iterative restoration procedure. The author of this study [16] put up a diffusion model to segment medical images even when noise and artifacts are present. To refine the features from the images that play as a plug-and-play procedure with maximum flexibility to segment the input image with seamless training throughout the process, the feature map denoising module is utilized. In comparison to cutting-edge methods, it provides an accurate segmentation of small lesions and minor organs.
A neuro-symbolic framework was presented in this study by using generative models based on conditioning to encode several types of data, including time series, tabular data, and magic images [17]. Here, two conditions are used in conjunction with noise-dependent classifiers. First, the data are manipulated using user-defined constraints and an un-normalized distribution. After these are combined, the defined framework for encoding the logical constraints is constructed to provide an efficient heuristic with better approximations. Presented a deep learning model to address the problem of deblurring the random text image data [18]. Generate ground truth values and data pairs for each input message using the optical character recognition-based scoring function, then fed into the trained U-Net architecture. When identifying the characters in the images, it obtains 70% correct precision.
3.1 Image acquisition
In MRI technology, the inside body structure of the patient details are captured by using radio frequency pulses with strong magnetic fields. It begins by positioning the patient with the machine. During the process, the patient should not move to get the fine images. Sometimes, muscle twitch or motion of patients leads to blurred results in images. Before the scanning process, each patient is instructed to hold their breath while scanning, which can reduce the motion artifacts. On account of physical factors and discomfort may cause an inherent imperfection that leads to image blurring. So, our proposed system aims to improve the image quality of the captured image continuously, which is blurred using the Contrast Limited Adaptive Histogram Equalization (CLAHE) model and also the Conditional Generative Adversarial Network (C-GAN) model is used.
3.2 Preliminary
In the image processing field, our proposed SBGM model plays a crucial role in enhancing the blurred image. It can be used for various purposes such as perturbation, reverse process, and resampling [25]. To create a continuous diffusion process at, where t fluctuates between 0 and 1, the perturbation process first perturbs the initial blurry image ao using a stochastic process. A stochastic differential equation (SDE) of the following form describes this process:
$d a_t=F\left(a_t, \mathrm{t}\right) d t+g(t) d w t(t)$ (1)
The drift coefficient in this case is represented by $F\left(a_t, \mathrm{t}\right)$ the diffusion coefficient by $g(t)$ and the normal Wiener process by $w t(t)$. SDEs are classified as $\operatorname{sub} \operatorname{Var}_P$, variance exploding $\operatorname{Var}_E$, and variance-preserving $\operatorname{Var}_P$ according to how the variance behaves during perturbation. In this case, $\operatorname{Var}_E$ SDEs are used, which are distinguished by the lack of drift $\mathrm{F}=0$ and a diffusion coefficient $g(t)$ that is established by the variation in variance $\delta^2(t)$ with time, as expressed by:
$g(t)=\sqrt{\frac{d\left[\delta^2(t)\right]}{d t}}$ (2)
$\delta(t)=\delta(0)\left(\frac{\delta(1)}{\delta(0)}\right)^t$ (3)
where, $\delta(t)$ represents the variance at time $t$, increasing with t. The resulting diffusion process $a_t$ at time t is obtained as:
$a_t=a_0+\left[\delta^2(t)-\delta^2(0)\right] I_{\text {dis }}$ (4)
where, $I_{\text {dis }}$ represents a normal distribution. Following the perturbation process, the reverse process aims to gradually restore the perturbed image using a reverse-time SDE:
$\begin{gathered}d a_t=\left[F\left(a_t, t\right) d t-g(t)^2 O\left(a_t\right) \log q_t\left(a_t\right)\right] +g(t) d \bar{w}_t\end{gathered}$ (5)
Here, $O\left(a_t\right) \log q_t\left(a_t\right)$ denotes the score function of $q_t\left(a_t\right)$ and $\bar{w}_t$ represents the reverse Wiener process. In the case of VE SDEs, this equation simplifies to:
$d a_t=-\frac{d\left[\delta^2(t)\right]}{d t} O\left(a_t\right) \log q_t\left(a_t\right)+\frac{d\left[\delta^2(t)\right]}{d t} d \bar{w}_t$ (6)
The restored image $a_t$ at a time is obtained as:
$a_t=a_{t+\Delta t}-d a_{t+\Delta t}$ (7)
This reverse process gradually restores the perturbed image to its original state. For projection inpainting, a particular pipeline is followed from Figure 1, where missing pixels in the metal region need to be restored, and background pixels serve as conditional information. The binary metal mask with ones in the backdrop is designated as n , and the projection that needs to be inpainted as b . To get $a_1^t$ and $a_2^t$, respectively, two processes forward and reverse SDEs are used. While $a_2^t$ forecasts the inpainted pixels, $a_1^t$ gives background information. The projection $a_t$ after restoration as:
$a_t=a_1^t \odot n+a_2^t \odot(1-n)$ (8)

Figure 1. Representation of projection inpainting

Figure 2. Structural diagram of Score-Based Generative Model (SBGM)
Here, denotes pixelwise multiplication. This comprehensive framework of SBGM processing effectively restores blurred images by leveraging SDEs and SBGMs, offering a sophisticated approach to image enhancement [26] and restoration as shown in Figure 2.
3.3 Data-Free Knowledge Distillation
The process of transferring knowledge from one pre-trained model to another without needing access to labeled data is called D-FKD. This technique is particularly useful in scenarios where obtaining labeled data for training is impractical or expensive [27]. In the context of image deblurring, D-FKD allows for the rapid learning of an SBGM by distilling the knowledge captured by a pre-trained model into a more compact form that can be utilized by the SBGM for image deblurring tasks.
The Teacher model $M_T$ is trained using the transfer set created from the initial training data in a typical Knowledge Distillation. The aim is to teach the student model $M_S$ to anticipate the right hard labels on the training set and to imitate the teacher's soft labels. This is achieved by minimizing a loss function $L$ consisting of two terms: the distillation loss and the cross-entropy loss,
$\begin{gathered}L=\sum_{(a, b) \in I_t} L_{\text {dist }}\left(M_S\left(x, \sigma_S, \tau_{\text {dist }}\right), M_T\left(x, \sigma_T, \tau_{\text {dist }}\right)\right) +\beta L_{c e}(\hat{y}, y)\end{gathered}$ (9)
here, $I_t$ represents the transfer set comprising input-target tuples, $L_{\text {dist }}$ is the distillation loss, $\sigma_T$ and $\sigma_S$ are the parameters of the Teacher and Student models, respectively, $\tau_{\text {dist }}$ is the distillation temperature, and $\beta$ is a hyper-parameter that balances the loss terms [28]. $L_{c e}$ refersto cross-entropy loss. However, in situations where obtaining the original training data is not feasible, such as in DFKD, alternative strategies are needed. One approach is to compose synthetic transfer sets using existing datasets, but this may lead to visually different samples that do not accurately represent the data manifold. To tackle this, we investigate the efficacy of transfer sets that consist of random samples chosen at random from datasets that are accessible to the public [29]. In our proposed approach, the objective is to compose an arbitrary transfer set that spans uniformly across all classification regions, ensuring the representation of all target labels. This lessens the distortion in the choice boundaries that the student model learns. To create such a transfer set, an algorithm must randomly choose samples from a range of possible datasets while maintaining a uniform distribution of anticipated labels. The teacher model architecture is built on a U-Net diffusion backbone, which is often used in SBGMs. The student model architecture, which uses a convolutional network that is less complex with fewer layers. The initialization strategy, which trains the teacher model first using pairs of noisy and clean images, and the D-FKD mechanism, which uses synthetic samples made by the teacher model to guide the student model without needing more labeled data.
$\begin{aligned} & \sigma_S^* =\arg \min _{\sigma_S} \sum_{a \in I_t^*} L_{\text {dist }}\left(M_T\left(x, \sigma_T, \tau_{\text {dist }}\right), M_S\left(x, \sigma_S, \tau_{\text {dist }}\right)\right)\end{aligned}$ (10)
here, $I_t^*$ represents the composed transfer set with a balanced label distribution. Unlike existing D-FKD approaches, our method does not involve generating synthetic samples but utilizes existing unlabelled datasets.
The computational complexity is greatly reduced because the Teacher model only needs to be run through once for each sample, with no back propagations. To summarize, Figure 3 illustrates how the D-FKD works to quickly transfer knowledge from a trained model to the SBGM for image deblurring without requiring labeled data [30]. By composing a balanced arbitrary transfer set and optimizing the student model using distillation loss, the SBGM can effectively learn from the insights captured by the pre-trained model, enhancing its performance on the target task.

Figure 3. Working principle of the Data-Free Knowledge Distillation (D-FKD) process
3.4 Perceptual consistency model
The model aims to ensure that the deblurred images maintain perceptual similarity with the original images by incorporating perceptual loss functions that measure the perceptual difference between the two [31]. This model utilizes two key processes: Perceptual Correspondence and Measuring Consistency.
3.4.1 Perceptual correspondence
In the context of deblurring images, Perceptual Correspondence identifies the most correlated pixels between two nearby frames, $X_p$ and $X_q$, and their respective feature maps, $F M_p$ and $F M_q$. By optimizing the cosine similarity between their feature vectors, which is determined by,
$C_{p, q}^*\left(i, j ; F M_p, F M_q\right)=\max _{i^{\prime} j^{\prime}} \delta\left(F M_p(i, j), F M_q\left(i^{\prime}, j^{\prime}\right)\right)$ (11)
The maximum similarity between pixels $(i, j)$ in $X_p$ and its equivalent pixels in $X_q$, is shown by the resulting correlation $C_{p, q}^*$, with the most correlated pixel being indicated as $\left(i^{\prime}, j^{\prime}\right)$. This procedure guarantees that the deblurred image maintains visual coherence with the original because adjacent frames usually have heavily overlapping visual elements.
3.4.2 Measuring consistency
To ensure the correct representation of the original information in the deblurred image, the model then assesses the consistency between segmentation decisions and perceptual correspondence, as illustrated visually in Figure 4. Consistency is high when segmentation decisions match perceptual correspondence, meaning that the pixels should be in the same class. To be more precise, if pixel ( $i, j$ ) in $X_q$, maintains a significant perceptual correlation (albeit not the highest correlation) with pixel ( $i, j$ ) in $X_p$, then $C p_{p, q}^{\dagger}(i, j)$ will remain near $C p_{p, q}^{\star}(i, j)$, indicating a high degree of agreement between segmentation choices and perceptual correspondence. In contrast, the value of $C p_{p, q}^{\dagger}(i, j)$ will be significantly smaller than $C p_{p, q}^{\star}(i, j)$,. if pixel ( $\mathrm{i} \dagger, \mathrm{j} \dagger$ ) in $X_q$ is not perceptually similar to pixel $(i, j)$ in $X_p$. Pixels $(i, j)$ in $X_p$ and its perceptually equivalent pixels in $X_q$ are not assigned the same class in this instance, as the segmentation decisions deviate from the perceptual correspondence. The pixel-wise consistency between segmentation decisions and perceptual correspondence is captured by the model by comparing $C p_{p, q}^{\dagger}(i, j)$ with $C p_{p, q}^{\star}(i, j)$ as shown as,
$\begin{aligned} & \rho\left(Y_p, Y_q\right) =\frac{1}{H \times W} \min \left(\frac{\sum_{i, j}\left(C p_{p, q}^{\dagger}(i, j)-\overline{C p}_{p, q}^{\dagger}\right)}{\sum_{i, j}\left(C p_{p, q}^{\star}(i, j)-\overline{C p}_{p, q}^*\right)}, \frac{\sum_{i, j}\left(C p_{q, p}^{\dagger}(i, j)-\overline{C p}_{q, p}^{\dagger}\right)}{\sum_{i, j}\left(C p_{q, p}^{\star}(i, j)-\overline{C p}_{q, p}^{\star}\right)}\right)\end{aligned}$ (12)
Figure 4(b) illustrates the proposed flowchart. The PC between the segmentation choices of the two frames, combined throughout the frame height and width, is represented by the symbol $\rho\left(Y_p, Y_q\right)$ in this instance. These are the corresponding frame-level averages:
$\overline{C p}_{p, q}^{\dagger}, \overline{C p}_{p, q}^{\star}, \overline{C p}_{q, p}^{\dagger}$ and $\overline{C p}_{q, p}^{\star}$

(a)
(b)
Figure 4. (a) Working principle of the perceptual consistency mode; (b) proposed flowchart model
By incorporating perceptual loss functions into the training of the Single-Blind Generative Model (SBGM), the PC model guides the generation of visually pleasing deblurred images that faithfully represent the original content. The synergy between these two techniques enhances the efficiency and effectiveness of the SBGM in generating high-fidelity deblurred images, making it a powerful tool for image restoration tasks [32].
4.1 Dataset
The dataset consists of 33 patients' imaging data that were acquired using a 1.5 T scanner and a vocal-tract technique. A 13-interleaf spiral-out spoiled gradient echo pulse sequence was used for imaging in the mid-sagittal plane. 2.4 × 2.4 mm² of spatial resolution, 6 mm slice thickness, and TR/TE = 6.004/0.8 ms were the imaging parameters. Using a dynamic off-resonance correction approach (DORC), various off-resonance effects were corrected. The resulting field maps and photographs were sized 84 × 84 × 400 (time) for every subject. Three sets of data were extracted from the dataset: training (23 subjects), validation (5 subjects), and test (5 subjects) [33].
4.2 Simulation setup
The proposed system's experimental setup leverages a Microsoft Windows 10 operating system within the MATLAB R2019a environment. Powered by a four Intel Xeon E7-4880 CPU and equipped with 1TB of RAM, the computational infrastructure ensures robust performance. This simulation process was carried out with the noise condition as mean and variance of 0 and 0.002, respectively [34]. Our proposed system attains the deblurring of images with the help of the D-FKD process and PC model that is evaluated using various performance metrics and compared with the existing methodologies. This part goes into great detail about the implementation environment and educating process used for the proposed deblurring structure to make sure that it can be repeated and is clear. The proposed model is built with the PyTorch deep learning structure and trained on a workstation with an NVIDIA GPU. The training process uses stochastic gradient descent optimization via an adaptive learning rate schedule to make sure that convergence is stable. The SBGM learns to reverse the process of adding Gaussian noise to clean medical images by using a noise perturbation schedule that slowly adds noise to the images.
The student model for knowledge distillation is meant to have a lot fewer parameters than the teacher diffusion model. The distillation process moves the learned score function from the teacher simulation to the student network by making the difference among their score estimates as small as possible. This lets the student model act like the teacher while using less processing power. The PC component is combined with the reconstruction loss during training to keep structural features. To find out how similar reconstructed images are to ground truth MRI slices, we use feature maps from the middle layers of a pretrained network. This helps keep the restored images true to their original shapes. There are 100 epochs of training, and a batch size of 16. Early stopping is used to keep the model from overfitting. The best validation achievement, measured by the structural similarity index (SSIM), is used to choose the final model parameters.
4.3 Performance metrics
SNR denotes the strength of the signal measured. It calculates to,
$S N R=10 \cdot \log _{10}\left(\frac{\text {Mean signal Intensity}}{\text {Mean noise Intensity}}\right)$ (13)
|
Algorithm 1: Accelerated Score-Based Deblurring with Knowledge Distillation |
|
Input:Blurred medical image $y$, blur operator $H$, pretrained teacher score model $S_T$, student score model $S_s$. sampling steps $T$ Output: Reconstructed sharp image $x$ Step 1: Initialization
Step 2: Accelerated Reverse Diffusion 3. While $t>0$ do 4. Compute score estimate using student model $s_t=S_S\left(x_t, t\right)$ 5. Estimate reconstruction gradient using blur constraint $g_t=H^T\left(y-H x_t\right)$ 6. Update image estimate with accelerated sampling rule $x_{t-1}=x_t+\alpha_t s_t+\beta_t g_t$ 7. Apply adaptive step reduction to skip redundant sampling steps 8. Decrease timestep $t=t-1$ Step 3: Knowledge Distillation Training 9. Train the student model by minimizing distillation loss $L_{\text {diatifl }}=\left\|S_T(x, t)-S_S(x, t)\right\|_2^2$ Step 4: Perceptual Consistency Optimization 10. Apply perceptual loss to preserve anatomical structures $L_{\text {perc }}=\|\phi(x)-\phi(\hat{x})\|_2$ Return: reconstructed image $x_0$ |
PSNR is a commonly known metric that can measure the deblurred image quality by comparing it with the original image.
$P S N R=10 . \log _{10}\left(\frac{\operatorname{Max}^2}{M S E}\right)$ (14)
where, ${Max}$ denotes the maximum level of the image pixel value.
The MSE between the deblurred image's pixel values and the original image's corresponding pixel values is calculated.
$M S E=\frac{1}{M N} \sum_{j=1}^n \sum_{i=1}^m\left(I_{\text {deblurred }}(j, i)-I_{\text {original }}(j, i)\right)^2$ (15)
where, $I_{\text {deblurred }}$ and $I_{\text {original }}$ defines the deblurred and blurred images, respectively. m and n denote the dimensions of the images.
SSIM assesses the similarity between two images, taking into account luminance, contrast, and structure. It is calculated as,
$\operatorname{SSIM}(a, b)=\frac{\left(2 \mu_a \mu_b+C_1\right)\left(2 \delta_{a b}+C_2\right)}{\left(\mu_a^2+\mu_b^2+C_1\right)\left(\delta_a^2+\delta_b^2+C_2\right)}$ (16)
where, $\mu_a$ and $\mu_b$ are the means $y, \delta_a$, and $\delta_b$ are the standard deviations, $\delta_{a b}$ is the covariance, and $C_1$ and $C_2$ denote constants.
4.4 Comparative analysis
In our proposed system, the original MRI brain image is fed to the proposed SBGM+ D-FKD+PC method to deblur the image to get the original image, and then its performance is calculated by parameter metrics that are observed below Table 1.
Table 1. Performance metrics comparison
|
Metrics |
Image Types |
|||
|
Input the Original Brain Image |
Blurred Brain Image |
Image Before Performing SBGM+ D-FKD+PC |
Image after Performing SBGM+ D-FKD+PC |
|
|
MSE |
32.53 |
50.32 |
25.42 |
20.07 |
|
SNR |
17.532 |
12.53 |
21.63 |
40.90 |
|
PSNR |
33.47 |
33.69 |
33.73 |
43.26 |
Figure 5 presents objective metrics to evaluate the quality of brain images across different stages of processing. Initially, the input original brain image exhibits an MSE of 32.53 and SNR of 17.532, indicating some level of blurriness and noise. After undergoing blurring, the image's MSE increases to 50.32, and SNR decreases to 12.53, reflecting heightened distortion and reduced clarity. Upon applying the Proposed SBGM + D-FKD + PC method, the image's MSE decreases to 25.42, indicating improved fidelity, while the SNR increases to 21.63, suggesting noise reduction. Furthermore, the PSNR values demonstrate consistently high image fidelity throughout the process, with slight fluctuations reflecting the impact of the SBGM + D-FKD + PC method, deblurring. Overall, these metrics highlight the effectiveness of the SBGM + D-FKD + PC method in enhancing image quality by reducing blurriness and noise, thus improving diagnostic accuracy in medical imaging applications.

Figure 5. Comparative analysis of Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR) across compressive sensing ratios
We consider that the input image is simulated at the compressive sensing (CS) ratio of 0.2 and SNR of 40dB for analysis of the system performance, as illustrated in Table 2, based on the results of the analysis of the proposed system in comparison with the existing method, such as the sequential method and Alternating Direction Method of Multipliers (ADMM) [35].
Figures 5 and 6 present a comparative analysis of image quality metrics, specifically SSIM and PSNR, across different CS ratios for three methods, respectively: the sequential method, ADMM (Alternating Direction Method of Multipliers), and the proposed method. When the CS value is decreased, all the values of each method are also reduced, depicting the data compression.
Table 2. Comparative analysis of compressive sensing ratios and metrics
|
CS Ratio |
Metrics |
Sequential Method |
ADMM |
Proposed SBGM + D-FKD + PC Method |
|
0.8 |
SSIM |
74.89 |
78.53 |
79.83 |
|
PSNR |
26.45 |
27.82 |
32.13 |
|
|
0.6 |
SSIM |
67.93 |
77.43 |
77.53 |
|
PSNR |
25.32 |
27.74 |
32.33 |
|
|
0.4 |
SSIM |
66.42 |
73.24 |
73.52 |
|
PSNR |
24.63 |
28.57 |
32.73 |
|
|
0.2 |
SSIM |
65.84 |
70.35 |
71.42 |
|
PSNR |
23.63 |
27.42 |
32.77 |

Figure 6. Comparative analysis of Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR) across compressive sensing ratios
However, the proposed method consistently outperforms the sequential and ADMM methods across all CS ratios, exhibiting higher SSIM and PSNR values. This suggests that the proposed SBGM + D-FKD + PC method is more effective in reconstructing high-quality images from compressed data, highlighting its superior performance and suitability for applications requiring accurate image reconstruction from limited data. Then, analyze the performance of the method over an increasing count of images.
In the comparative analysis between image count and Mean Squared Error (MSE) of methods, it is observed from Figure 7 and Table 3 that the MSE values consistently decrease across all methods. Specifically, for image 1, the MSE values are 0.025, 0.032, and 0.020 for CNN, ADMM, and the proposed method, respectively. Similarly, for image 2, the MSE values decrease to 0.030, 0.035, and 0.022 for CNN, ADMM, and the proposed method, respectively. Similarly, for image 3, the CNN, ADMM, and the proposed method have an MSE of 0.028, 0.034, and 0.021, respectively. These values show the error minimization by utilizing all methods.

Figure 7. Comparative analysis of image count and mean squared error
Table 3. Comparative analysis of existing and proposed methods
|
Image |
Metrics |
CNN |
ADMM |
Proposed SBGM+ D-FKD+PC Method |
|
1 |
MSE |
0.025 |
0.032 |
0.020 |
|
PSNR |
30.5 |
28.9 |
32.1 |
|
|
SSIM |
75.32 |
73.24 |
79.83 |
|
|
2 |
MSE |
0.030 |
0.035 |
0.022 |
|
PSNR |
29.8 |
28.3 |
32.4 |
|
|
SSIM |
74.62 |
70.35 |
78.43 |
|
|
3 |
MSE |
0.028 |
0.034 |
0.021 |
|
PSNR |
30.0 |
28.5 |
32.2 |
|
|
SSIM |
75.23 |
73.24 |
77.53 |

Figure 8. Comparative analysis of image count and Peak Signal-to-Noise Ratio (PSNR)
Figure 8 shows the comparison between the image counts and the PPSNR values of various methods. Our proposed method shows better PSNR results compared to the existing methodologies. For instance, in Figure 1, the proposed system attains higher PSNR values than the CNN and ADMM; this trend is followed by all three 3 images. This shows our proposed system yields a higher performance compared to existing methods in terms of PSNR across all images.
The analysis of existing and proposed methods' insight into SSIM metrics is shown in Figure 9. For instance, in image 1, the CNN has 75.32, ADMM has 73.24, and our proposed system has 79.83. Similarly, for image 2, the CNN has 74.62, ADMM has 70.35, and our proposed system has 78.43. Lastly, for image 3, the CNN has 75.23, ADMM has 73.24, and our proposed system has 77.53. From the above observation, our proposed system exhibits higher SSIM values compared to the existing method, which depicts a higher performance in reconstructing the original images than others.

Figure 9. Analysis of image count and Structural Similarity Index
The suggested method shows that combining SBGMs with effective sampling strategies can greatly enhance the performance of medical image restoration. The knowledge distillation system lowers the amount of computing power needed even more, making the model suitable for use in clinical settings. Despite encouraging outcomes, the study is constrained by the comparatively small dataset size. Future research will investigate extensive medical imaging datasets as well as multi-modal reconstruction tasks. In summary, the findings of the proposed system indicate its effectiveness in deblurring medical images. By applying novel methods such as SBGMs, D-FKD, and PC models, the procedure exhibits excellent outcomes in improving the quality of the image. Our proposed system outperforms the other existing methods in terms of MSE, SNR, PSNR, and SSIM. However, the proposed SBGM system can quickly learn and produce high-quality deblurred medical images with promising results for doctors to make better diagnoses of disease and provide treatment sooner.
4.5 Discussion of sensitivity results
We do a sensitivity analysis to see how well the proposed method works in different imaging situations. The analysis takes into account three key factors: noise levels, blur kernel size, and blur kernel size, which are shown in Tables 4-6.
Table 4. Sensitivity analysis under different noise levels
|
Noise Level (σ) |
PSNR |
SSIM |
MSE |
|
0.01 |
33.5 |
0.941 |
0.0038 |
|
0.02 |
33.1 |
0.938 |
0.0042 |
|
0.05 |
32.7 |
0.933 |
0.0047 |
|
0.10 |
31.9 |
0.925 |
0.0056 |
Table 5. Sensitivity analysis for blur kernel size
|
Kernel Size |
PSNR |
SSIM |
|
3 × 3 |
33.2 |
0.938 |
|
5 × 5 |
32.9 |
0.935 |
|
7 × 7 |
32.7 |
0.933 |
|
9 × 9 |
32.2 |
0.928 |
Table 6. Comparison with diffusion-based models
|
Method |
Sampling Strategy |
PSNR |
SSIM |
|
DDPM |
Standard diffusion |
32.2 |
0.927 |
|
Score-SDE |
Score-based diffusion |
32.4 |
0.930 |
|
DDIM |
Accelerated diffusion |
32.5 |
0.931 |
|
Proposed Method |
Efficient sampling + distillation |
32.7 |
0.933 |
The sensitivity analysis shows that the suggested deblurring framework works well in a variety of imaging situations. The model still does a good job of reconstructing, even when the noise levels are higher or the blur kernels are bigger. The diffusion-based prior accurately represents the intrinsic distribution of pristine MRI images, enabling the simulation to reconstruct anatomically significant details despite significant degradation. These results show that the proposed method can be used in real-world clinical imaging situations where the conditions for getting the images may change.
4.6 Robustness analysis
In real-world medical imaging situations, reconstruction algorithms need to be able to handle changes in imaging conditions. Consequently, the proposed framework is assessed in various demanding scenarios, encompassing noise corruption, motion artifacts, and fluctuating blur intensities. First, the simulation is tested on MRI images that have been damaged by synthetic Gaussian noise with different levels of variance. The results show that the diffusion-based generative prior lets the model get rid of noise while still getting back structural details. Second, we test how well the system can handle motion blur by using different blur kernels that mimic patient movement during MRI acquisition. The proposed method exhibits enhanced resilience compared to traditional deep learning techniques, owing to its probabilistic modeling of image distributions. Third, we look at how fewer sampling steps affect the accelerated diffusion process. The proposed sampling strategy keeps reconstruction accuracy while cutting inference time by a huge amount, even though it requires a lot fewer sampling iterations. These results show that the suggested structure keeps its performance stable across a wide range of imaging conditions.
4.7 Clinical significance
There are a lot of possible uses for the suggested deblurring method in clinical imaging workflows. For accurate diagnosis, treatment planning, and disease monitoring, high-quality medical images are very important. But MRI scans often have motion blur because the patient moves or the acquisition protocols are too fast. The suggested framework can make MRI images clearer without needing more time to scan. This is especially helpful in clinical settings where quick imaging is needed, like in emergency diagnostics or pediatric imaging, where it's hard to keep the patient still. The proposed method could cut down on the number of scans needed by improving image quality via post-processing reconstruction. This would make patients more comfortable and lower healthcare costs. Also, the model works well because it combines accelerated sampling along with understanding distillation. This makes it a good choice for use in real-time medical imaging devices.
4.8 Limitations of the study
Even though the suggested method shows good results, there are some problems that need to be addressed. First, the experimental assessment is performed on a relatively small MRI dataset with only 33 subjects. This dataset offers adequate variability for initial validation; however, larger datasets encompassing multiple institutions as well as imaging modalities would facilitate a more thorough evaluation. Second, this study mainly looks at motion-induced blur in MRI images. The current framework does not explicitly model other types of degradation, like undersampling artifacts along with scanner noise. Third, even though accelerated diffusion sampling makes things a lot easier for computers, it still needs neural network inference operations that might be too much for medical systems with few resources. Future research should focus on overcoming these limitations.
To overcome motion artifacts and imaging device restrictions in medical images, the suggested system effectively used novel techniques such as SBGMs, D-FKD, and the PC model. This paper introduces an innovative framework for expedited medical image deblurring utilizing SBGMs. The proposed method significantly lowers the cost of computation while keeping the quality of reconstruction high by using efficient sampling strategies as well as understanding distillation. Experimental results on MRI datasets show that the method works to improve image quality and keep anatomical structures intact. The suggested framework shows a promising way to use generative diffusion theories in medical imaging. The effectiveness of the suggested strategy was demonstrated by the results, which showed notable increases in picture quality measures: MSE reduced from 50.32 to 20.07, SNR increased from 12.53 to 40.90, PSNR enhanced from 33.69 to 43.26, and SSIM improved substantially. The potential for therapeutic applications is highlighted by these developments, which show notable gains in diagnostic value and image clarity. The use of simulated data is one of the system's drawbacks, though, and additional validation using clinical datasets from actual environments is required to assess the suggested system's generalizability. This discovery has a significant impact since it not only solves a pressing issue in medical imaging but also creates avenues for quicker and more precise diagnoses, both of which are essential for patient care. The study provides valuable insights that highlight the significance of combining sophisticated generative models with reliable sampling methods to improve the quality of medical images. Future research should focus on the assimilation of the proposed system into clinical workflows, extensive validation studies, and exploring additional enhancements to further improve image quality and diagnostic precision. Through the establishment of a link between laboratory research and real-world clinical application, this work sets the stage for significant progress in medical imaging technologies.
Future efforts will concentrate on various promising avenues to enhance the proposed framework further. One possible extension is the combination of different types of medical imaging data, such as CT, PET, and ultrasound images. Training generative algorithms on a variety of imaging modalities could enhance generalization abilities and facilitate wider clinical applications. Another option is to look into self-supervised, along with semi-supervised training methods, to cut down on the need for big labeled datasets. This is especially important in medical imaging, where there isn't always a lot of data with labels. We will also look into how to make real-time diffusion-based reconstruction systems. Utilizing optimized neural architectures with hardware acceleration, near real-time image restoration for clinical applications may be attainable. Lastly, working with doctors will make it possible to do clinical validation studies that look at how the proposed deblurring technique affects diagnosis.
[1] Quan, Y.H., Wu, Z.C., Ji, H. (2021). Gaussian kernel mixture network for single image defocus deblurring. Advances in Neural Information Processing Systems, 34: 20812-20824. https://doi.org/10.48550/arXiv.2111.00454
[2] Zhao, H.X., Ke, Z.W., Chen, N.B., Wang, S.J., et al. (2020). A new deep learning method for image deblurring in optical microscopic systems. Journal of Biophotonics, 13(3): e201960147. https://doi.org/10.1002/jbio.201960147
[3] Chen, Z., Niu, C., Gao, Q., Wang, G., Shan, H. (2024). LIT-Former: Linking in-plane and through-plane transformers for simultaneous CT image denoising and deblurring. IEEE Transactions on Medical Imaging. 43(5): 1880-1894. https://doi.org/10.1109/TMI.2024.3351723
[4] Zeng, X., Dong, Q., Li, Y. (2023). MG-CNFNet: A multiple grained channel normalized fusion networks for medical image deblurring. Biomedical Signal Processing and Control, 82: 104572. https://doi.org/10.1016/j.bspc.2023.104572
[5] Liu, Y., Sheng, Z., Shen, H.L. (2022). Guided image deblurring by deep multi-modal image fusion. IEEE Access, 10: 130708-130718. https://doi.org/10.1109/ACCESS.2022.3229056
[6] Tian, S., Zhang, S., Lin, B. (2021). Blind image deblurring based on dual attention network and 2d blur kernel estimation. In 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, pp. 1729-1733. https://doi.org/10.1109/ICIP42928.2021.9506340
[7] Zhang, B., Sun, J., Sun, F.M., Wang, F.S., Zhu, B. (2024). Image deblurring method based on self-attention and residual wavelet transform. Expert Systems with Applications, 244: 123005. https://doi.org/10.1016/j.eswa.2023.123005
[8] Zhang, X.Q. Wang, T., Jiang, R.H., Zhao, L., Xu, Y.W. (2021). Multi-attention convolutional neural network for video deblurring. IEEE Transactions on Circuits and Systems for Video Technology, 32(4): 1986-1997. https://doi.org/10.1109/TCSVT.2021.3093928
[9] Kwon, D., Fan, Y., Lee, K. (2022). Score-based generative modeling secretly minimizes the Wasserstein distance. Advances in Neural Information Processing Systems, 35: 20205-20217.
[10] Vahdat, A., Kreis, K., Kautz, J. (2021). Score-based generative modeling in latent space. Advances in Neural Information Processing Systems, 34: 11287-11302. https://doi.org/10.48550/arXiv.2106.05931
[11] Singh, I.R., Denker, A., Barbano, R., Kereta, Ž., Jin, B., Thielemans, K., Maass, P., Arridge, S. (2023). Score-based generative models for PET image reconstruction. Journal of Machine Learning for Biomedical Imaging, 2: 547-585 https://doi.org/10.48550/arXiv.2308.14190
[12] Mei, S.Y., Fan, F.X., Maier, A. (2023). Metal inpainting in CBCT projections using score-based generative model. In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, pp. 1-5. https://doi.org/10.1109/ISBI53787.2023.10230638
[13] Ren, M., Delbracio, M., Talebi, H., Gerig, G., Milanfar, P. (2023). Multiscale structure guided diffusion for image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10721-10733.
[14] Lei, Y., Niu, C., Zhang, J., Wang, G., Shan, H. (2023). CT Image denoising and deblurring with deep learning: Current status and perspectives. IEEE Transactions on Radiation and Plasma Medical Sciences, 8(2): 153-172. https://doi.org/10.1109/TRPMS.2023.3341903
[15] Hong, K., Wu, C., Yang, C., Zhang, M., Lu, Y., Wang, Y., Liu, Q. (2021). High-dimensional assisted generative model for color image restoration. https://doi.org/10.48550/arXiv.2108.06460
[16] Li, G., Jin, D., Zheng, Y., Cui, J., Gai, W., Qi, M. (2024). A generic plug & play diffusion-based denoising module for medical image segmentation. Neural Networks, 172: 106096. https://doi.org/10.1016/j.neunet.2024.106096
[17] Scassola, D., Saccani, S., Carbone, G., Bortolussi, L. (2023). Zero-shot conditioning of score-based diffusion models by neuro-symbolic constraints. arXiv Preprint arXiv:2308.16534. https://doi.org/10.48550/arXiv.2308.16534
[18] Trippe, T., Genzel, M., Macdonald, J., März, M. (2022). Let's enhance: A deep learning approach to extreme deblurring of text images. https://doi.org/10.3934/ipi.2023019
[19] Sharif, S.M.A., Naqvi, R.A., Mehmood, Z., Hussain, J., Ali, A., Lee, S.W. (2022). Meddeblur: Medical image deblurring with residual dense spatial-asymmetric attention. Mathematics, 11(1): 115. https://doi.org/10.3390/math11010115
[20] Zhang, M., Young, G.S., Tie, Y., Gu, X., Xu, X. (2022). A new framework of designing iterative techniques for image deblurring. Pattern Recognition, 124: 108463. https://doi.org/10.1016/j.patcog.2021.108463
[21] Zhang, J., Wei, Z., Wu, X., Shang, Y., Tian, J., Hui, H. (2023). Magnetic particle imaging deblurring with dual contrastive learning and adversarial framework. Computers in Biology and Medicine, 165: 107461. https://doi.org/10.1016/j.compbiomed.2023.107461
[22] Tien, H.J., Yang, H.C., Shueng, P.W., Chen, J.C. (2021). Cone-beam CT image quality improvement using Cycle-Deblur consistent adversarial networks (Cycle-Deblur GAN) for chest CT imaging in breast cancer patients. Scientific Reports, 11(1): 1133. https://doi.org/10.1038/s41598-020-80803-2
[23] Ma, H., Liu, S., Liao, Q., Zhang, J., Xue, J.H. (2021). Defocus image deblurring network with defocus map estimation as auxiliary task. IEEE Transactions on Image Processing, 31: 216-226. https://doi.org/10.1109/TIP.2021.3127850
[24] Li, Y., Tofighi, M., Geng, J., Monga, V., Eldar, Y.C. (2020). Efficient and interpretable deep blind image deblurring via algorithm unrolling. IEEE Transactions on Computational Imaging, 6: 666-681. https://doi.org/10.1109/TCI.2020.2964202
[25] Mei, S., Fan, F., Maier, A. (2023). Metal inpainting in CBCT projections using score-based generative model. In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, pp. 1-5. https://doi.org/10.1109/ISBI53787.2023.10230638
[26] Gupta, S., Patel, N., Kumar, A., Jain, N.K., Dass, P., Hegde, R., Rajaram, A. (2023). Adaptive fuzzy convolutional neural network for medical image classification. Journal of Intelligent & Fuzzy Systems, 45(6): 9785-9801. https://doi.org/10.3233/JIFS-233819
[27] Zhang, Y., Chen, H., Chen, X., Deng, Y., Xu, C., Wang, Y. (2021). Data-free knowledge distillation for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7852-7861.
[28] Umaamaheshvari, A., Sivasankari, K., Suguna, N., Kshirsagar, P.R., Tirth, V., Rajaram, A. (2023). Optimization technique for optimal location selection based on medical image watermarking on healthcare system. Journal of Intelligent & Fuzzy Systems, 45(4): 6549-6559. https://doi.org/10.3233/JIFS-2245
[29] Nayak, G.K., Mopuri, K.R., Chakraborty, A. (2021). Effectiveness of arbitrary transfer sets for data-free knowledge distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, pp. 1430-1438. https://doi.org/10.1109/WACV48630.2021.00147
[30] Sucharitha, G., Sankardass, V., Rani, R., Bhat, N., Rajaram, A. (2024). Deep learning aided prostate cancer detection for early diagnosis & treatment using MR with TRUS images. Journal of Intelligent & Fuzzy Systems, 46(2): 3395-3409. https://doi.org/10.3233/JIFS-235744
[31] Zhang, Y., Borse, S., Cai, H., Wang, Y., Bi, N., Jiang, X., Porikli, F. (2022). Perceptual consistency in video segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, pp. 2564-2573. https://doi.org/10.1109/WACV51458.2022.00261
[32] Veeraiah, D., Sai Kumar, S., Ganiya, R.K., Rao, K.S., Nageswara Rao, J., Manjith, R., Rajaram, A. (2025). Multimodal medical image fusion and classification using deep learning techniques. Journal of Intelligent & Fuzzy Systems, 48(1): 637-651. https://doi.org/10.3233/JIFS-240018
[33] Lim, Y., Bliesener, Y., Narayanan, S., Nayak, K.S. (2020). Deblurring for spiral real-time MRI using convolutional neural networks. Magnetic Resonance in Medicine, 84(6): 3438-3452. https://doi.org/10.1002/mrm.28393
[34] Indira, D.N.V.S.L.S., Ganiya, R.K., Ashok Babu, P., Xavier, A.J., et al. (2022). Improved artificial neural network with state order dataset estimation for brain cancer cell diagnosis. BioMed Research International, 2022(1): 7799812. https://doi.org/10.1155/2022/7799812
[35] Khan, S., Huh, J., Ye, J.C. (2020). Adaptive and compressive beamforming using deep learning for medical ultrasound. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control, 67(8): 1558-1572. https://doi.org/10.1109/TUFFC.2020.2977202