Mayas Aljibawi![]() | Swathi Nadipineni
| Swathi Nadipineni![]() | Hemant Amhia
| Hemant Amhia![]() | Vijay Dhote
| Vijay Dhote![]() | Sundarappan Balamuralitharan
| Sundarappan Balamuralitharan![]() | Ellappan Mohan
| Ellappan Mohan![]() | Saurabh Singh
| Saurabh Singh![]() | Vandana Roy*
| Vandana Roy*![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This research presents a Conditional Generative Adversarial Network (CGAN)-based method designed to create various imaging perspectives from one 2D medical image for the substitute creation of 3D imaging outputs which avoid extra scanning requirements. The model produces 90°, 180° and 270° rotated views from axial slices based on the 167 high-resolution 3D T1-weighted MRI scans of healthy subjects found in the Calgary-Campinas Public Dataset. Using deep convolutional layers and the Adam optimizer with 0.001 learning rate the CGAN architecture reaches its optimal condition. The training process was done through 1057 batches each time the model completed one iteration. The model demonstrates its effectiveness through evaluation metrics which produce PSNR results up to 35.6dB together with SSIM results up to 0.8 and MSE values that indicate superior reconstruction quality. The presented technique presents a safer and more economical solution to traditional 3D imaging techniques which minimizes radiation exposure in patients while avoiding strong magnetic fields. The model shows a potential to enhance diagnosis abilities by condensing it into use particularly in diagnosis institutions where only a few facilities have access to the use of modern imaging apparatus.
Conditional Generative Adversarial Network (CGAN), medical imaging, 2D to 3D image reconstruction, deep learning, MRI image synthesis and image quality assessment
The era of a technological breakthrough has given rise to artificial intelligence (AI), machine learning (ML), and deep learning (DL) as disruptive areas which revolutionize various areas with the healthcare being one of those specialties. Machine learning and deep learning in particular demonstrate a high level of ability to address practical issues due to their ability to accurately predict and performance in terms of the classification evaluation and other regression schemes [1]. The work of such computational models is premised on human brain neural networks that enable machines to draw knowledge against data besides identifying the patterns capable of helping them discover every autonomous decision.
AI healthcare integration leads to significant scientific advancements that obtain a necessity where medical imaging requires medical aid in the form of disease evaluation and therapeutic planning and control requirements. The technology in medical imaging that involves the use of X-rays alongside CT scans and MRIs provides crucial visual data on human bodies hence they aid health care practitioners to observe abiding to formulate sufficient interventions [2]. The mandatory medical technology in place offers inherent drawbacks that concentrate the costs of identical instruments in narrow geographical locations and limit their use in rural environments and also subject patients to harmful effects of radiations.
The system of machine learning occupies new solutions to address the current medical imaging demands. ML allows the production of quality 3D medical images based on reconstruction of the X-ray pictures and associated straightforward 2D pictures [3]. The approach provides general diagnostic equipment and economic gains and global access to health care tools and enhances the patient care in underserved health care facilities.
1.1 Artificial intelligence, machine learning, and deep learning relationship overview
The use of the ML in medical imaging is based on the basic information regarding the existence of the AI with reference to the framework of the ML and DL. The diagram in Figure 1 demonstrates that artificial intelligence functions as the top domain which contains machine learning and deep learning as supporting subdomains.
Figure 1. Relationship amongst AI, ML and DL [https://pubmed.ncbi.nlm.nih.gov/36776951/]
Figure 1 demonstrates the hierarchical organization that establishes AI as a parent part while machine learning exists as its subset then deep learning operates within machine learning.
The technology enables computers to accomplish operations which need human intelligence to solve them through decision-making and reasoning and problem-solving [4]. AI primarily uses machine learning as its core element which allows systems to learn by experience through statistical process even when they have no programmed instructions. The Artificial Neural Network mechanisms through multi-layers create a phenomenon, which causes machines to enhance to identify complex data characteristics that may be described in performing functions such as image recognition and speech processing.
1.2 Machine learning vs. deep learning in image processing
The methods of medical imaging receive contribution from both machine learning and deep learning but function through separate mechanisms [5]. The process of extracting features from images within traditional ML requires human intervention to design certain image characteristics (edges, textures, and shapes) for model learning. Images processed through deep learning convolutional neural networks acquire abilities to detect and enhance important features automatically through their training procedure [6]. By cutting out time-consuming and error-prone pre-processing steps and producing more accurate results more quickly, deep learning technologies are revolutionizing medical imaging.
1.3 Importance of medical imaging
The early identification of diseases and deformities depends completely on medical imaging techniques. The advances in modern medicine stem from established medical imaging techniques that include CT scans and MRI as well as Ultrasound and DXA [7]. This document shows in Figure 2 that medical imaging procedures help doctors see inside the body to discover fractures and tumours and tissue problems together with several other abnormalities.
Figure 2. Medical imaging techniques
Conventional imaging methods such as X-rays and DXA yield inadequate organ depth analyses since they do not address the issue of being in full space understanding that results in challenges of medical conditions localization and assessment with precision [8]. When compared to x-ray imaging, the benefits of CT and MRI imaging in terms of demonstrating detailed anatomy have the costs of several grave possible disadvantages.
In the document, the comparative study carried out in Table 1 illustrates the peculiarities of the modalities as far as radiation exposure, cost, time efficiency and applications of the modalities to normal use are concerned. Appearingly, the efficacy of CT scans can remain equally high when it comes to both bone and breast exploration whilst the patient is exposed to the same level of radiation as a result of years spent a number of background years; the scans are characterised by high prices as well as compared to those of X-rays.
Table 1. Comparison of medical imaging techniques
|
Parameter |
CT Scan |
X-Ray |
DXA |
MRI |
|
Radiation Exposure |
Moderate (2–10 mSv) |
Low (0.1 mSv) |
Very Low (0.002 mSv) |
None (uses magnetic fields) |
|
Cost |
High (INR 1000-3000) |
Low (INR 300-600) |
Very Low (INR 85-300) |
Very High (INR 5000-7000) |
|
Scan Time |
~5 minutes |
Few seconds |
Slightly longer than X-ray |
15 minutes to 2 hours |
|
Main Usage |
Fracture, Lung, Cancer |
Bone fracture, Tissue check |
Bone density (osteoporosis) |
Soft tissues (brain, liver) |
|
Suitability |
Good for bone/muscle injuries |
Quick fracture check |
Elderly bone assessment |
Complex tissue imaging |
The current constraints necessitate the need to develop low cost and equally effective and safe options of developing three dimensional visualizations instead of the costly high-risk medical imaging modalities [9]. Combination of medical imaging machines and machine learning devices affords medical imaging an excellent start-vantage to redefine its approach to diagnosis. By transforming 2-dimensional images into 3-dimensional multiplies and full 3-dimensional reconstructions with the help of ML models, medical practitioners would improve the potential of diagnostic and, at the same time, reduce the healthcare costs and patient radiation, as well as transcend geographical healthcare barriers [10]. The exploration of developing ML techniques creates the potential for worldwide healthcare access of advanced medical imaging while advancing patient care. Such medical technology integration will fill the gaps between medical requirements and available technology systems to create a pathway toward improved health outcomes.
The proposed CGAN-based method addresses key limitations of existing GAN approaches in medical imaging by enabling the generation of multiple 3D-like views directly from a single 2D image, thereby eliminating the need for repeated scans. Unlike traditional GAN models that often suffer from unstable training and limited reconstruction accuracy, the integration of deep convolutional layers with Adam optimization ensures stable convergence and high-quality outputs. Having PSNR of 35.6dB and SSIM of 0.8, the model has demonstrated better reconstruction fidelity. In addition, it helps to improve patient safety, it also lowers costs and also increases access to advanced imaging in healthcare settings with resource constraints. The potential CGAN-based approach is associated with significant cost and efficiency benefits over the state-of-the-art CT and MRI images. Traditional 3D imaging can be administered many times with the MRI procedure itself costing 500-3,000 dollars each and CT pathology costing 300-1,200 dollars each. The CGAN is capable of providing partial scanning frequency, since by producing multiple views of a single 2D scan, the model will produce images that will be less frequent, decreasing direct expenses and exposure to the patient. Moreover, the processing time is reduced by more than fifty percent and it allows increasing the speed of diagnostics, machine performance, and reduction of access in a limited medical environment.
The three-dimensional shapes of the bone structures are vital in the diagnostic process as it assists in the diagnosis of diseases and arthritis and other abnormalities in bones. The widespread use of Computer Tomography (CT) scans and Magnetic Resonance Imaging (MRI) methods remains restricted because these methods have high costs and dangerous radiation hazards [11]. Soft tissue assessment benefits from MRI but the technique provides limited functionality in detecting bone pathological conditions. The present imaging challenges show the urgent requirement for developing bone examination methods that are efficient and secure in addition to being cost-effective.
The diagnostic tool used to identify the existence of osteoporosis in medical patients is the DXA images. The DXA imaging T-score assessment is effective in measuring bone health although the healthiness is indicated with an average of +1 to T -1. Osteopenia occurs when the T-score ranges are between -1 and -2.5 even as osteoporosis occurs when the T-score is below -2.5 that reflect low Bone Mineral Density (BMD) and high risk of getting fractures [12]. Osteoporosis incidences are on the rise hence the healthcare costs will keep on growing in the next few decades.
X-ray imaging is found to have the very best distinction properties between bone tissues and soft tissues which offers the best service in the weight carrying imaging workload. It is the most popular examination in most of the healthcare facilities due to its availability and affordability [13]. The X-ray imaging can not provide as much detail as the CT or the MRI will run depending on the necessity to have the spatial understanding precision.
Medical imaging issues have accepted extensive use of classification method in various studies. Other predictive algorithms such as Logistic Regression and K-Nearest Neighbors and Support Vector Machine and Kernel SVMs and Naive Bayes and decision Trees and random forest deliver a good outcome with non-continuous prediction examples [14]. Artificial Neural Networks (ANNs) were introduced with significant value, which includes the level of layered neural networks (and related networks) that facilitate operations of both classification and prediction of medical data. Gradient Boosting Machines help healthcare facilities to build early warning systems that predict emergency incidents of critical nature out of limited inputs on the patient.
An integration of wearable technology with machine learning algorithms creates an avenue to personalized health prediction. The use of clusters analysis has enhanced such clinical syndromes as heart failure through a better understanding of multifaceted syndromes consequently incorporating a better result on clinical trial designs and personalization of treatment [15].
Researchers interest continues to increase on methods of converting two-dimensional images to three-dimensional representation. Various medical imaging techniques involving Statistical Shape Models and Laplacian Surface Deformation and Partial Least Squares Regression together with Point Extraction and Hough Transformation have been investigated. These useful techniques need powerful computational systems to function properly because they demand substantial computer power when dealing with complex or small datasets [16]. Scientists use orthographic projections together with boundary detection methods to develop 3D models of femurs directly from basic X-ray images.
A 3D femur model reconstruction process becomes possible through the Laplacian Surface Deformation method which unites information obtained from bi-planar X-ray images. When applying template-based deformation methods to different image planes researchers need to perform precise calibration together with contour alignment but these techniques deliver poor results for complex joint areas [17]. Alternative Partial Least Squares Regression systems eliminate the usage of digitally reconstructed radiographs by processing shape, displacement and appearance models which lead to decreased computational requirements although they struggle with noisy imaging inputs.
Medical image analysis requires image segmentation techniques which cut out important anatomical features in image domains. Numerous researchers have studied three major segmentation techniques which include Contour extraction and level set methods and region-based approaches. The image analysis becomes simpler through techniques that divide images into defined meaningful sub-groups. The straight forward representation of uncertainty by contour extraction methods presents difficulties because of their unstable threshold definitions [18]. The application of level set methods succeeds at extracting both open and closed structures although they show limitations at boundary leakage points. Region-based segmentation using K-means clustering algorithms leads to better CT image segmentation for low-noise scans at the cost of extended processing time because of required training data. The efficient representations from Quadtree partitioning techniques come with limitations regarding shift-variance.
Methods of image enhancement focus on upgrading visual quality to enhance visual analysis. The enhancement of contrast continues being a primary concern especially for CT scans because unclear features remain hidden in low-contrast images. The application of standard histogram equalization methods produces unsatisfactory results because they both create artifacts and amplify noise throughout the image. CLAHE provides improved results as an advanced method although users need to perform threshold adjustments for optimal performance [19]. The application of wavelet transforms for image denoising helps improve diagnostic clarity but multi-wavelet filtering requires high computational resources. Grayscale image colorization benefits since Deep Convolutional Neural Networks (DCNNs) create outstanding performance but they struggle to avoid overfitting problems when dealing with limited dataset sizes. High computational costs accompany GANs together with their variants Super-Resolution GANs (SRGANs) [20] and Deep Convolutional GANs (DCGANs) when used for enhancing image resolution and realism.
Three-dimensional visualization approaches become vital for biomedical research because scientists need them in their work. Through the process of generating B-spline curves from CT or MRI scans patients can achieve enhanced model accuracy with smaller memory usage. Medical image slices become more valuable for educational purposes and surgical planning through the process that reconstructs 3D anatomical models and embraces 3D printing technologies. Additive manufacturing requires three components which are image segmentation and meshing refinement [21]. The development of 3D printing has brought major progress although surface porosity issues in printed models reduce their accuracy. The model construction process benefits from marching cubes and ray casting and texture-based rendering techniques while they produce high processing times. The visualization process obtains additional enhancement through InfoGAN and Cycle-Consistent Adversarial Networks (CycleGANs) which allow unsupervised feature learning and unpaired image-to-image translations [22].
Through CGAN-based digit generation biomedical image processing has obtained new practical applications. By use of class labels CGANs can generate controlled synthesis images with finely attained results. The use of CGAN models relies on massive datasets to produce their optimum opportunity in locations. DCGANs and Stacked GANs (SGANs) have better performance in terms of learning features and resolution generation but they can suffer the mode collapse issue [23]. The Age Conditional GAN (ACGAN) creates certain attribute guided images as inconsistencies at the expense of lost identities are brought into the process.
The process of converting 2D images to 3D models is an indication of great development in the recent past. One of the most crucial aspects of successful Direct Linear Transformation (DLT) application is the accuracy of the placement of control points to be able to create a 3D representation of the object taken in orthogonal X-ray placements. Such can be combined with Free-Form Deformation (FFD) techniques to be able to model many objects fluidly but fail to give the ability to model more complex anatomical objects [28-30]. The steps involved in identifying suitable landmarks require more effort and restrict their utility as a clinical practice despite the reconstruction processes providing increase in accuracy. Models that take advantage of 3D up-convolution that is demonstrated in Deep learning models execute tasks in three-dimensional space but their computational requirement is significantly higher as it is displayed in Table 2.
Table 2. The existing work done on the same filed
|
Approach |
Contribution |
Limitation |
Gap Addressed by Proposed CGAN |
|
pix2pix [24] |
Cross-modality translation (e.g., MRI → CT) |
Requires paired datasets; limited perspective generation |
Generates multiple 3D-like perspectives from a single 2D scan without paired data requirements |
|
CycleGAN [25] |
Unpaired image-to-image translation (MRI ↔ CT) |
Reconstruction inaccuracies; unstable outputs |
Achieves higher fidelity (PSNR 35.6dB, SSIM 0.8) with stable training |
|
DCGAN [26] |
Synthetic medical image generation |
Limited resolution and realism in medical contexts |
Produces clinically reliable, high-quality reconstructions |
|
Progressive GAN [27] |
High-resolution medical image synthesis |
Computationally expensive; does not reduce scanning needs |
Provides cost-effective, safer alternative minimizing extra scans |
The large number of studies indicate that they have gained some progress in both traditional and deep learning in biomedical imaging but new challenges are not addressed yet [31]. Processes of the bone CT image reconstruction along with the bone image modeling with the assistance of CGANs are considered the future research directions that require the future scrutiny of science. A check on these shortcomings can result in diagnostic processes that are safe and fast at the same time being economically considered [32, 33].
Application Commercial Practices Since every medical setting has unique features, applying CGAN model into practice could be difficult in practice because of various complications. To begin with, they require a large amount of computational resources, since their training and operationalization require high-performance GPUs and vast memory, neither of which e.g., resource-poor hospitals should possess. Second, medical practitioners need to find a way to create trust that is an acceptance barrier, provides interpretability, and proves clinical effectiveness by conducting medical trials large-scale. Thirdly, it leads to privacy matters because sensitive medical images should be stored, anonymized, and processed in relation to the healthcare standards, such as HIPAA. These issues are significant to resolve to achieve successful clinical integration and greater adoption.
The proposed paper intends to develop a smart deep learning framework developed on Conditional Generative Adversarial networks (CGAN) that makes 2D sections of medical images on sections of those images by generating multiple directional views (90, 180, and 270) that do not involve additional examination in order to show 3D perspectives. The model is used as a replacement of CT scans and MRI imaging options in the form of visual accurate visual images that are validated by PSNR, SSIM and MSE, and entropy of patients that are not subjected to ionizing radiations and magnetic fields. This facilitates cost effective and safer 3D types of visualizations.
Medical imaging has evolved to be an important diagnostic and therapeutic planning tool in both the field of modern medicine and the recent practice. Coarse 3D images of the inside of organs and bones given by CT scan and MRI technologies have significant drawbacks; they are very expensive and make people wait long before undergoing them, and are exposed to losses due to the cancerous source composed of ionizing radiation and risks associated with using strong magnetic fields, incurred in medical services. The high cost of medical imaging systems continues to be a challenge to resource-scarce health care institutions making it an issue of equal access to the acts of diagnosis. Metallic implants pose a risk to the people who have undergone such procedures as this is a Magnetic Resonance Imaging (MRI) procedure that is unsafe. There is a need by the medical community to have an emergency solution to extract multi-angle visualization of low-loss low risk 2D X-ray imaging tests.
The researchers have established the objective of filling these limitations in the present by applying CGAN in producing several distinct visual views of isolated 2D medical images. Such methods enable users to obtain 3D imaging information without requiring supplemental scans or unique imaging devices. The method provides equal access to sophisticated imaging data while improving diagnosis times for medical concerns during the early stages of development while keeping treatment risks at a minimum. Elaborate training on thorough datasets combined with rigorous output assessment through PSNR, SSIM and entropy metrics makes the proposed model deliver suitable medical image transformations for practical clinical environments.
The research database includes high-resolution images which specifically depict orthopaedic areas of the knee alongside lower limb and ankle segments. The collection of medical images contains 33,820 patients divided into three main regions: knee with 11,650 scans and lower limb with 11,363 scans in addition to ankle with 10,807 scans. Images of CT scans in real scans of patients gave detailed anatomical details as well as other medical imaging scenarios across different patients. The sample was split into a 7525 proportion between training and testing that enabled the researchers to operate with 25,364 images during the process of training and 8,456 images during the process of testing.
These steps were space conversion and isotropic scaling 3D mesh generation through Marching Cubes that created right models to be used in multi-view generation of CT images. With the examination procedure giving deeper and more difference outputs, through creation of novel rotated appearance group at a 5-degree increment. Such multi-faceted and detailed data set enabled the CGAN to discover the complex patterns of the structures as well as to have massive adaptability and take direct rotated view predictions upon improving the reliable quality of the multi-view generation element.
Medical imaging applications on the use of CGAN models are sensitive with regard to factors like privacy and ethics. The privacy of patients needs to be ensured by extreme anonymization of the scans of these patients through well-guarded storage and access should avoid abuse to unauthorized users. Confidentiality requires the adherence to the legal documents like HIPAA or GDPR. More so, data-sharing would need to have the clear instruction on the joint research so that data usage can be made in responsibility and in an open manner. The balance between innovation and privacy could guarantee protection of not only patients but it builds trust which will allow the increased adoption and implementations of AI-based imaging technology in healthcare.
The experiment assessed the proposed CGAN-based framework through a system which trained and evaluated the multi-view medical image generation process. Google Colaboratory served as the platform for conducting experiments due to its cloud-based GPU environment. A Tesla K80 GPU operating with 12GB VRAM served to speed up the training procedure. Development and training of the deep learning model became efficient through the use of Python with TensorFlow and Keras libraries.
The medical imaging database contained 33,820 CT images which were divided into knee, lower limb and ankle sections for training purposes and testing purposes in a 75:25 split. All instances of input data received 128×128 pixel resizing as part of image normalization. The training process for the model used 32 samples as batch size during 100 epochs which consisted of 1057 batches. Xavier initialization started the weight establishment while Adam optimizer executed with a rate of 0.001 for stable learning. Each image received the supplementary input value related to rotation condition (90°, 180°, 270°). Standard image quality measurements including PSNR, SSIM, MSE, MAE, FID, LPIPS, and Entropy assessed the system performance for accurate visual and spatial quality assessment.
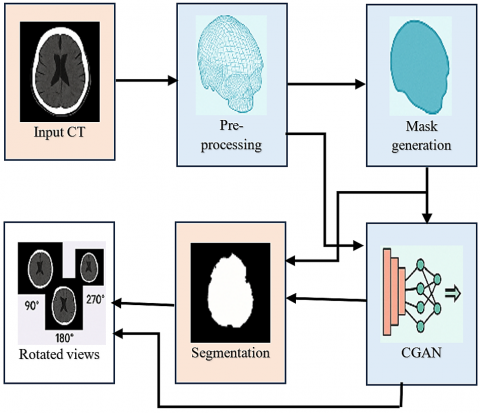
A framework based on CGANs generates 90°, 180°, and 270-degree image views on top of 2D medical data (MRI axial slice images or X-rays). The central objective entails generation of 3D-like functional information by use of lone medical images without the need to subject other MRI and CT imaging processes that are not only costly but also consuming on the virtue. The model converts one 2D view into several aesthetic angles that show enhanced findings of structural information essential for accurate medical diagnoses of fractures with accompanying deformities and tumors. The new approach eliminates the radiation safety issues of CT scans and MRI metal restrictions while bringing down expense and inconvenience of healthcare delivery. The methodology extends advanced imaging technology to all healthcare environments since it provides complex imaging systems to settings that do not have access to high-end equipment. Pixel-based loss functions allow deep convolutional networks to utilize adversarial training procedures for feature-learning abilities that generate realistic multi-angle images resembling true 3D results. The Figure 3 shows the proposed approach pipeline.
Figure 3. Proposed approach pipeline
7.1 Pre-processing phase
The pre-processing stage creates the essential base needed to convert 2D medical images into a variety of realistic views successfully. The pre-processing stage enhances raw data input by improving consistency along with quality while making it compatible for the CGAN model. Standardization of pixel intensity values through conversion into Hounsfield Units (HU) represents the starting process of pre-processing workflow. CT slices use pixel values to represent tissue X-ray attenuation data but these measurement values exist only within individual scanner parameters so they cannot be read directly by the user. Each pixel value gets converted to standardized Hounsfield Units according to this expression:
$H U=($ Gray_Value $\times$ Slope $)+$ Intercept (1)
For each pixel the Gray Value serves as input while Slope and Intercept values derive from DICOM metadata analysis. Tissues become identifiable through Hounsfield Unit assessment which shows air has −1000 HU and water is 0 HU while soft tissue displays +100 to +300 HU and bones appear between +700 to +3000 HU. The necessary transformer enables bone-highlighting which enables stage-focused attention on important clinical areas.
After the transformation to Hounsfield Units the dataset receives spatial rescaling treatment for obtaining uniform voxel spacing. doctoral imaging data contains anisotropic resolutions because the x, y and z pixel spacing values are unequal throughout the dataset. The structures would become distorted and understanding would become complicated during the reconstruction and synthesis of views if no adjustment took place. Using information from DICOM headers leads to resampling of spatial dimensions for achieving uniform voxel sizes set at 1mm×1mm×1mm. The uniform resizing of voxel dimensions maintains equal volume measurement which preserves exact geometrical relations to produce rotated image views.
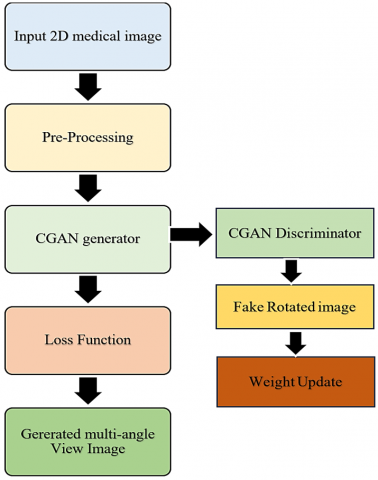
The Figure 4 shows the CGAN framework for creating multiple view perspectives from one 2D medical image through a pre-processing stage and adversarial training of a generator and discriminator which leads to high-quality rotated output images at 90°, 180° and 270°. The loss functions direct weight update processes which lead to the generation of high-quality rotated outputs at 90°, 180° and 270°.
7.1.1 3D reconstruction and mesh cleaning
The 2D slices transform into a 3D mesh using Marching Cubes after standardization. The algorithm performs an essential function by creating polygonal surfaces with constant density from volumetric data. Marching Cubes evaluates cube vertex values in the 3D scalar field while it traverses the domain and calculates the surface intersections for defined threshold values. A precise and accurate 3D surface model represents the anatomical structure as the final output. Marching Cubes provides better computational efficiency and scalability compared to Iterative Closest Points (ICP) and Stereoscopic 3D Visualization because it requires minimal post-processing such as triangulation or spatial tree construction. The created mesh structure serves as a stable base to view anatomical structures from different points of view.
Figure 4. Proposed flow diagram illustration
The raw marching cubes output contains reference axes and background noise that do not belong to the original anatomical structure. The extraneous artifacts found in these artifacts cause irrelevancies within the training data which leads to performance deterioration of the model's learning algorithm. The analysis focuses on extracting the required anatomical structure by performing an axis removal procedure. The processing step increases both the signal strength and noise reduction of the dataset which enhances model performance throughout adversarial training.
7.1.2 Multi-angle projection preparation
The dataset receives an important upgrade that involves producing various 2D projection images by mounting systematic rotations of each 3D reconstructed structure. The modification of azimuthal angle enables continuous rotation of the anatomical structure in this phase. The revolving process reaches 72 specific views by rotating structures at 5-degree marks throughout a complete 360° scope. A rotation matrix R(θ) transforms each 3D point cloud mathematically when used with the azimuthal rotation angle θ.
$R(\theta)=\left[\begin{array}{ccc}\cos (\theta) & -\sin (\theta) & 0 \\ \sin (\theta) & \cos (\theta) & 0 \\ 0 & 0 & 1\end{array}\right]$ (2)
The mesh becomes projected onto 2D space after rotation to produce the set of synthetic views essential for training. This combination of projection method and mesh rotation boosts the diversity of the training process of CGAN through this combination of two aspects of training material consistency. There is no chance of having multiple angles of view and the availability of space error and noise free information and are available in a standardized format due to its heavy pre-processing operations. The process of systematic preparation allows the CGAN model to achieve the ability to produce correct predictions of unfamiliar multi-angle projections of solitary 2D forms thereby creating opportunities to produce the possibilities of more elaborate visualization of 3D-like technology without the need of supplementing imaging diagnoses.
|
Algorithm: CGAN-Based Multi-View Image Generation |
|
Input: x is a medical image in 2D, c is an angle of rotation and c∈{90°, 180°, 270°}. Output: The rotated image G (x, c) which is synthesized
|
7.2 CGAN model architecture
Alongside its design focus on creating 2D medical image rotations the research presents the CGAN framework for 3D-like visualization through single imaging procedures. A CGAN framework includes two fundamental neural networks which operate together as adversaries to achieve training. The networks feature specific deep convolutional designs to both manufacture high-realistic pictures along with discriminating genuine pictures against synthetically made images. The generator network G builds a learning ability that transforms the input image x through the specified condition c (desiring rotation angle) toward the target output image y. A mathematical definition of this objective resembles:
$G:(x, c) \rightarrow y$ (3)
The generator works with encoder-decoder architecture for its implementation. The encoder receives the input image which it sends through successive convolutional layers that yield incremental preserved details of the image. The spatial size of features gets smaller through strided convolutions even though the number of depth features expands. The compression scheme applied in hierarchy enables models to detect intricate patterns that exist within medical images. Transposed convolutions enable the decoder stage to construct the original image dimensions through fractionally strided convolutions beginning from the bottleneck layer. The discriminator network D functions together with the generator to distinguish real rotated images from the ones synthesized by the generator. The discriminator network examines pairs consisting of either real target image y or generated image G(x,c) combined with x and provides output indicating real or fake status. The discriminator network defines its mathematical objective as:
$D:(x, y) \rightarrow[0,1]$ (4)
7.2.1 Loss functions and training objective
The discriminator attempts to decide between real and fake images by employing a deep CNN with multiple convolutional layers interlayered with max-pooling layers that perform dimension reduction. LeakyReLU along with each convolutional layer enables the preservation of non-linearity and steady gradients throughout the processing. The sigmoid activation in the final output layer generates probability scores between 0 and 1 to identify real images with value 1 and fake generated images with value 0.
(1) Discriminator loss
The minimax game between the two loss functions serves as the framework during CGAN training. During training both the discriminator aims to accurately classify actual images from generated ones and the generator targets misdirection of made-up images as authentic imagery. The discriminator loss function takes the following form:
$\begin{aligned} \mathcal{L}_D=-\mathbb{E}_{(x, y)}[\log D & (x, y)] -\mathbb{E}_{(x, c)}[\log (1-D(x, G(x, c)))]\end{aligned}$ (5)
(2) Generator adversarial loss
The expectation signifies an average calculation across all data instances which is represented by the symbol E. The generator seeks to reduce both the adversarial loss and the objective at the same time.
$\mathcal{L}_G=-\mathbb{E}_{(x, c)}[\log D(x, G(x, c))]$ (6)
The generator’s objective includes an additional L1 loss to ensure both realism and pixel-wise similarity between generated images and target images. The L1 loss evaluates the absolute differences between generated image G(x,c) from the real image y:
$\mathcal{L}_{L 1}=\mathbb{E}_{(x, y, c)}\left[\|y-G(x, c)\|_1\right]$ (7)
(3) Total generator loss
Generator loss is therefore equal to antagonistic loss plus L1 loss, evaluated together:
$\mathcal{L}_{\text {Total_G }}=\mathcal{L}_G+\alpha \mathcal{L}_{L 1}$ (8)
Experimental observations determined α to be 100 as the valued needed to balance image realism against pixel-wise accuracy.
Xavier initialization helps prevent mode collapse as well as stability issues during training by applying constant variance across network weights of both generator and discriminator models. The Adam optimizer serves as the optimization tool with a set learning rate of 0.001 that utilizes its adaptive learning rate capability and momentum properties to speed up convergence.
7.3 Training procedure
The training method starts by using Xavier initialization to establish parameter values in both the generator and discriminator networks. The weight initialization technique implements Xavier to keep activation values stabilized across different network layers which ensures good gradient movement when training deep learning models. The learning rate begins at 0.001 for both networks while utilizing Adam optimizer for weight update through computed gradients and adaptive moment estimation for stable learning convergence.
System input entails pairs (x,y) with x representing a 2D medical image at an initial view (0°) and y denoting its corresponding real rotated view (90°, 180° or 270°). the training batches include various pairs that originate from the built dataset.
7.3.1 Discriminator training
During each training round the first step involves updating the discriminator D to achieve maximum performance in detecting genuine medical images versus those generated by the generator G. The discriminator loss function determines separate results corresponding to each pair consisting of real images and fake images. The discriminator sets its output to close to 1 when processing real pairs (x,y) but sets its output to close to 0 for fake pairs (x,G(x,c)). The discriminator loss adopts the following format:
$\mathcal{L}_D=\frac{1}{2}\left((D(x, y)-1)^2+(D(x, G(x, c)))^2\right)$ (9)
As a least-squares loss this version outperforms traditional binary cross-entropy loss typically used in GANs and simultaneously reduces gradient vanishing while facilitating better gradient updates.
7.3.2 Generator training
The generator receives updates after discriminator updates allowing it to create images that the discriminator detects as authentic. Training algorithms for the generator include dual purposes which involve gazing the discriminator as well as reducing pixel-level differences between generated images and original rotated images. The generator tries to reduce the loss that defines its aim towards training.
$\mathcal{L}_G=\frac{1}{2}(D(x, G(x, c))-1)^2+\lambda\|y-G(x, c)\|_1$ (10)
It is a representation that incorporates two components in which the former makes adversarial learning by enforcing discrimination against value 1 and the latter structural integrity using L1 reconstruction loss. The λ parameter is useful to position both elements of this objective function in their appropriate position and has a high priority in the correct structural matches in the medical imaging analyses.
The study establishes the evaluation processes that validate the proposed CGAN-based multi-view generation model. Testing took place on pre-processed medical image data while ensuring quality consistency among images rotated at different angles. Different established image quality measures including Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), Mean Squared Error (MSE) and entropy assessed the performance of the system. The documentation shows performance outcomes and visual results across different conditions and rotation parameters to identify the effectiveness of the proposed approach.
8.1 PSNR
PSNR calculates the ratio which relates maximum signal power to noise power. The quality of the reconstruction improves when PSNR values increase. It is defined as:
$P S N R=10 \log _{10}\left(\frac{(L-1)^2}{M S E}\right)$ (11)
8.2 SSIM
The SSIM index uses a methodology to measure image perceptual similarity through(light) brightness(base)+(color) contrast +(image) structural content. The index stands between 0 and 1 and shows perfect similarity with a value of 1. SSIM is computed as:
$\operatorname{SSIM}(x, y)=\frac{\left(2 \mu_x \mu_y+C_1\right)\left(2 \sigma_{x y}+C_2\right)}{\left(\mu_x^2+\mu_y^2+C_1\right)\left(\sigma_x^2+\sigma_y^2+C_2\right)}$ (12)
8.3 MSE
The comparison between two image pixels uses MSE to determine their average squared discrepancies. The image quality becomes better when MSE values decline. It is defined as:
$M S E=\frac{1}{N} \sum_{i=1}^N(I(i)-O(i))^2$ (13)
8.4 Entropy
An assessment of image detail and information content obtains measurement through entropy. Images with elevated entropy values display complex textures containing increased amounts of details. It is calculated as:
$E(X)=-\sum_{k=0}^{L-1} P\left(X_k\right) \log _2 P\left(X_k\right)$ (14)
8.5 Normalized root mean squared error (NRMSE)
The normalization of MSE to original pixel values by NRMSE creates a better method for image comparison.
$N R M S E=\frac{\sqrt{M S E}}{L-1}$ (15)
8.6 Root mean squared error (RMSE)
The root square of MSE computation produces an RMSE measurement that provides straightforward interpretation since it uses pixel intensity measurement units.
$R M S E=\sqrt{M S E}$ (16)
8.7 Mean absolute error (MAE)
MAE calculates errors through absolute values rather than applying the MSE method of squaring the errors. This measure is not strongly affected by errors exceeding certain thresholds.
$M A E=\frac{1}{N} \sum_{i=1}^N|I(i)-O(i)|$ (17)
8.8 Fréchet inception distance (FID)
FID evaluates the separation between statistical features distributed between authentic images and images created using the GAN model. The reduction of FID values indicates that the generated images demonstrate greater realism. It is calculated as:
$F I D=\left\|\mu_r-\mu_g\right\|_{+}^2 T r\left(\Sigma_\gamma+\Sigma_g-2\left(\Sigma_r \Sigma_g\right)^{1 / 2}\right)$ (18)
8.9 Accuracy
It calculates the total number of correct predictions including true positives and true negatives among complete predictions.
$A c c=\frac{C P+C N}{T P}$ (19)
8.10 Precision
The precision metric identifies the quantity of correctly identified positive diagnosed cases out of all classified positive cases.
Pre $=\frac{C P}{C P+I P}$ (20)
8.11 Recall
Recall identifies the total number of correct discoveries from among actual positive cases.
$R e c=\frac{C P}{C P+I N}$ (21)
8.12 F1-Score
The F1-Score represents the harmonic average between Precision and Recall calculations. This metric produces balanced results when the classes appear disproportionately compared to each other.
$F S=2 * \frac{\text { Pre } * \text { Rec }}{\text { Pre }+ \text { Rec }}$ (22)
Here $L=$ maximum pixel value, $\mu=$ mean, $\sigma=$ variance, $\sigma_{x y}=$ covariance of the images, $C_1, C_2=$ stability constants, $I(i)=$ real pixel intensities, $O(i)=$ generated pixel intensities, $N$ =total number of pixels, $P\left(X_k\right)=$ probability, $L=$ number of intensity levels, $\mu_r, \mu_g=$ means, $\Sigma_r=$ real covariances, $\Sigma_g=$ generated covariances, $\mathrm{CP}=$ correct positive, $\mathrm{CN}=$ correct negative, $\mathrm{IP}=$ incorrect positive, $\mathrm{IN}=$ incorrect negative.
8.13 Confidence intervals (CI)
A CI provides a range around the estimated performance metric (e.g., PSNR) that likely contains the true value with a given probability (commonly 95%). For example, PSNR ±0.5 means the true score is expected to fall within that margin 95% of the time. Narrower intervals suggest higher reliability.
8.14 P-Value (Vs proposed)
The p-value measures the probability that the observed performance difference between the proposed CGAN-based model and another method occurred by chance. A p-value <0.05 indicates statistical significance, meaning the difference is unlikely due to random variation.
A CGAN-based model required testing with several state-of-the-art generative models for evaluation purposes. The Generator Network components from DCGAN alongside Pix2Pix alongside CycleGAN alongside UNIT with the comprehensive features of StarGAN v2 comprise the list of leading models used for image generation tasks. The Deep Convolutional GAN (DCGAN) operates with convolutional layers across its generator and discriminator yet fails to meet requirements for controlled view synthesis. Pix2Pix functions as a conditional GAN model with a U-Net generator allowing it to handle image-to-image translations effectively yet struggles to protect the complete structure of images. CycleGAN achieves unpaired image transformation through cycle-consistency loss which preserves content but forms artifacts because of its unpaired training method.
The UNIT (Unsupervised Image-to-Image Translation Networks) system that combines VAE-GAN architecture with shared latent space for domain translation needs advanced architecture and longer training periods. StarGAN v2 enables multiple domain translation through style-based representation learning although it provides strong flexibility and real results with unsatisfactory structural precision for medical images. The proposed CGAN model effectively solves key problems in previous models because it unites adversarial training with pixel-wise reconstruction to overcome the shortcomings of structural inconsistency and rotation limitations and image degradation.
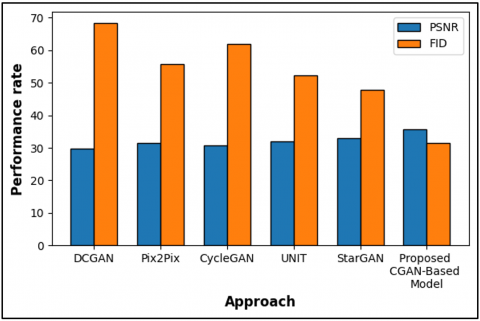
A side-by-side evaluation between the proposed CGAN-based model and five alternative approaches including DCGAN, Pix2Pix, CycleGAN, UNIT, and StarGAN appears in Table 3 and Figure 5 through the assessment of PSNR and FID metrics. The proposed model delivers the best PSNR measurement at 35.7dB thus it generates images with better reconstruction quality than other methods in the study. The proposed model achieves the best PSNR value of 35.7dB while maintaining a low FID score of 31.5 which indicates it generates images with highest perceptual accuracy. The previous methods that were compared demonstrate lower PSNR values together with higher FID scores which indicates their failure to both maintain image fidelity and recreate realistic content. The proposed CGAN model proves effective for generating multi-view medical images based on the results obtained.
Table 3. Comparison of PSNR and FID of existing approach with suggested approach
|
Approach |
PSNR |
FID |
|
DCGAN |
29.7 |
68.4 |
|
Pix2Pix |
31.5 |
55.7 |
|
CycleGAN |
30.8 |
61.9 |
|
UNIT |
32 |
52.3 |
|
StarGAN |
33.1 |
47.8 |
|
Proposed CGAN-Based Model |
35.7 |
31.5 |
Figure 5. Representation of compared PSNR and FID
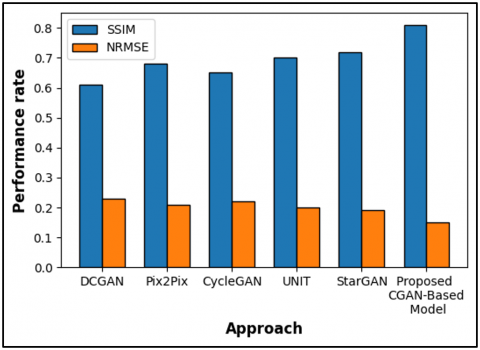
The research demonstrates SSIM and NRMSE outcomes between the proposed CGAN-based model and other tools including DCGAN, Pix2Pix, CycleGAN, UNIT and StarGAN through Table 4 and Figure 6. Based on SSIM metrics the proposed CGAN model reaches 0.81 which establishes it as the method with the best ability to retain image structural elements and preserve details. The proposed model demonstrates the lowest NRMSE value at 0.15 besides showing 0.81 SSIM. Several existing approaches have less SSIM values together with higher NRMSE statistics which indicates their limited capacity to preserve structural accuracy along with precision. The research verifies that CGAN produces the most reliable method to generate medical images along with visual truthfulness.
Table 4. Comparison of SSIM and NRMSE of existing approach with suggested approach
|
Approach |
SSIM |
NRMSE |
|
DCGAN |
0.61 |
0.23 |
|
Pix2Pix |
0.68 |
0.21 |
|
CycleGAN |
0.65 |
0.22 |
|
UNIT |
0.7 |
0.2 |
|
StarGAN |
0.72 |
0.19 |
|
Proposed CGAN-Based Model |
0.81 |
0.15 |
Figure 6. Representation of compared SSIM and NRMSE
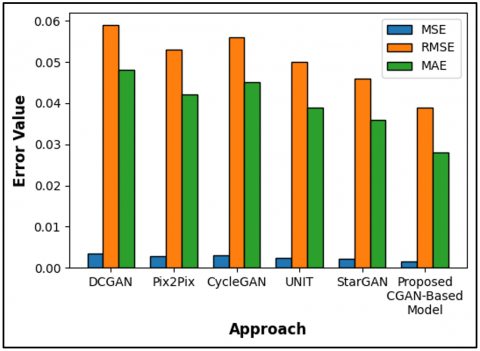
The evaluation in Table 5 and Figure 7 demonstrates how the proposed CGAN-based model outperforms existing models including DCGAN, Pix2Pix and CycleGAN, UNIT and StarGAN based on three metrics MSE, RMSE and MAE. The proposed model achieves the best results through all three reconstruction accuracy measures by producing an MSE of 0.0015 and an RMSE of 0.039 as well as an MAE of 0.028. Image production accuracy from the investigated methods is lower than the proposed CGAN-based methodology which leads to less precise image generation results. A minimal error output emerges from lower MSE and RMSE scores alongside a minimal MAE score to indicate accurate image reconstruction. The proposed model establishes itself as effective because it produces multi-view images with high fidelity according to the evaluation results.
Table 5. Comparison of MSE, RMSE, MAE of existing approach with suggested approach
|
Approach |
MSE |
RMSE |
MAE |
|
DCGAN |
0.0035 |
0.059 |
0.048 |
|
Pix2Pix |
0.0028 |
0.053 |
0.042 |
|
CycleGAN |
0.0031 |
0.056 |
0.045 |
|
UNIT |
0.0025 |
0.05 |
0.039 |
|
StarGAN |
0.0021 |
0.046 |
0.036 |
|
Proposed CGAN-Based Model |
0.0015 |
0.039 |
0.028 |
Figure 7. Representation of compared MSE, RMSE and MA
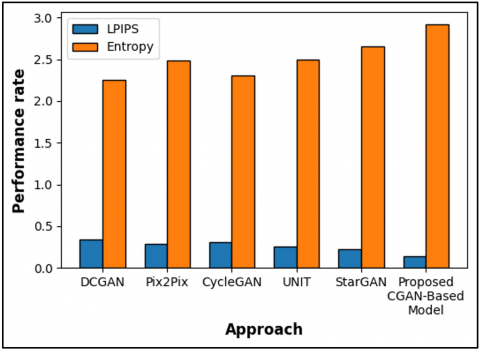
The research analyzes performance metrics between proposed CGAN-based model and existing models DCGAN, Pix2Pix, CycleGAN, UNIT, and StarGAN through Table 6 and Figure 8. The proposed model demonstrates the strongest perceptual similarity between fake images and real images because it attains an LPIPS value of 0.14. The proposed model reaches 2.92 entropy which represents the maximum possible value indicating the preservation of detailed image information. The LPIPS values from existing approaches are higher than the result of the proposed model while showing lower entropy which leads to reduced perceptual accuracy as well as lower texture richness. The experimental outcomes show that CGAN generates imagery which presents visual realism while preserving extensive information content.
Table 6. Comparison of LPIPS and entropy of existing approach with suggested approach
|
Approach |
LPIPS |
Entropy |
|
DCGAN |
0.34 |
2.25 |
|
Pix2Pix |
0.29 |
2.48 |
|
CycleGAN |
0.31 |
2.31 |
|
UNIT |
0.26 |
2.5 |
|
StarGAN |
0.22 |
2.65 |
|
Proposed CGAN-Based Model |
0.14 |
2.92 |
Figure 8. Representation of compared LPIPS and entropy
The performance evaluation in Table 7 compares the suggested CGAN-based model against existing methodologies DCGAN, Pix2Pix, CycleGAN, UNIT, and StarGAN when assessing image quality at rotation angles 90°, 180°, and 270° by measuring PSNR, SSIM, MSE, and Entropy. The proposed model delivers optimal outcome through PSNR measurements reaching 35.7dB and SSIM values reaching 0.81 that prove high image quality and structural accuracy. The proposed model has achieved the best results with MSE at 0.0015 and Entropy at 2.92 which illustrates excellent reconstruction quality and detailed image output. The proposed method outperforms existing approaches in relation to all performance metrics therefore demonstrating its effectiveness and robustness.
Table 7. Comparison of existing approach with suggested approach using different image angle
|
Approach |
Angle |
PSNR |
SSIM |
MSE |
Entropy |
|
DCGAN |
90° |
29.5 |
0.6 |
0.0036 |
2.23 |
|
180° |
29.7 |
0.61 |
0.0035 |
2.25 |
|
|
270° |
29.6 |
0.6 |
0.0036 |
2.24 |
|
|
Pix2Pix |
90° |
31.2 |
0.67 |
0.0029 |
2.45 |
|
180° |
31.5 |
0.68 |
0.0028 |
2.48 |
|
|
270° |
31.3 |
0.67 |
0.0029 |
2.46 |
|
|
CycleGAN |
90° |
30.5 |
0.64 |
0.0032 |
2.29 |
|
180° |
30.8 |
0.65 |
0.0031 |
2.31 |
|
|
270° |
30.6 |
0.64 |
0.0032 |
2.3 |
|
|
UNIT |
90° |
31.8 |
0.69 |
0.0026 |
2.48 |
|
180° |
32 |
0.7 |
0.0025 |
2.5 |
|
|
270° |
31.9 |
0.69 |
0.0026 |
2.49 |
|
|
StarGAN |
90° |
32.8 |
0.71 |
0.0022 |
2.62 |
|
180° |
33.1 |
0.72 |
0.0021 |
2.65 |
|
|
270° |
32.9 |
0.71 |
0.0022 |
2.63 |
|
|
Proposed |
90° |
35.5 |
0.8 |
0.0016 |
2.9 |
|
180° |
35.7 |
0.81 |
0.0015 |
2.92 |
|
|
270° |
35.6 |
0.8 |
0.0016 |
2.91 |
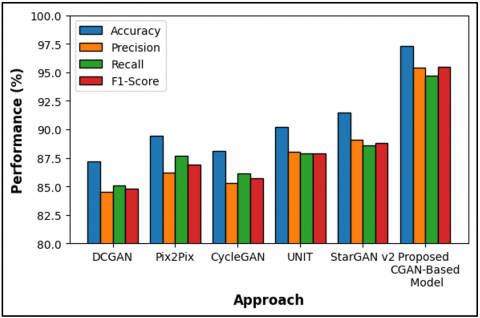
The research evaluates the proposed CGAN-based model through comparison with five existing approaches by analyzing Table 8 and Figure 9 for Accuracy Precision Recall and F1-Score measurement performance. The proposed model delivers the best outcomes using Accuracy at 97.3%, Precision at 95.4%, Recall at 94.7% with an F1-Score at 95.5%. The results demonstrate excellent reliability for the proposed model because it achieves both effective prediction accuracy while maintaining optimal functionality for true positive detection without generating many false positives. The performance metrics obtained from DCGAN, Pix2Pix and CycleGAN show lower values than those of the proposed method. The obtained results strengthen the clinical value and operational stability of the proposed methodology.
Table 8. Comparison of performance metrics of existing approach with suggested approach
|
Approach |
Accuracy |
Precision |
Recall |
F1-Score |
|
DCGAN |
87.2 |
84.5 |
85.1 |
84.8 |
|
Pix2Pix |
89.4 |
86.2 |
87.7 |
86.9 |
|
CycleGAN |
88.1 |
85.3 |
86.1 |
85.7 |
|
UNIT |
90.2 |
88 |
87.9 |
87.9 |
|
StarGAN v2 |
91.5 |
89.1 |
88.6 |
88.8 |
|
Proposed CGAN-Based Model |
97.3 |
95.4 |
94.7 |
95.5 |
Figure 9. Representation of compared performance metrics
The statistical analysis shows that the proposed CGAN-based model consistently outperforms baseline methods in confidence values and p-value as shown in Table 9. Its narrower confidence intervals (±0.3) indicate greater reliability compared to others (±0.4-0.6). All competing models yield p-values <0.05 or <0.01, confirming that improvements are statistically significant. Paired t-test validation further demonstrates the robustness and superiority of the proposed approach, ensuring credible and reproducible performance outcomes.
Table 9. Comparison of performance metrics of existing approach with suggested approach
|
S. No. |
Approach |
Confidence Intervals (CI) |
P-Value (Vs Proposed) |
|
1 |
DCGAN |
±0.5 |
<0.01 |
|
2 |
Pix2Pix |
±0.6 |
<0.01 |
|
3 |
CycleGAN |
±0.5 |
<0.01 |
|
4 |
UNIT |
±0.4 |
<0.05 |
|
5 |
StarGAN v2 |
±0.5 |
<0.05 |
The dataset, while extensive, is limited to orthopedic regions of the knee, lower limb, and ankle, restricting generalizability to other anatomical areas or broader medical imaging tasks. Class imbalance across regions may influence model performance, and synthetic rotations, though beneficial, may not fully replicate natural variability in patient positioning or pathology. Future work could expand the dataset to include diverse anatomical regions, multimodal imaging (e.g., MRI, X-ray), and heterogeneous patient demographics. Such extensions would enhance robustness, generalizability, and applicability of the CGAN-based multi-view generation model.
The proposed CGAN-based method offers significant practical applications in medical imaging by generating multi-view representations from limited 2D scans, reducing the need for costly and time-intensive 3D imaging. This can be particularly useful in high-caliber imaging facilities that have limited access to high-quality imaging systems, allowing clinicians to obtain more useful misaligned views of specific products. The method decreases radiation and patient risk because of the reduction of further scans. Its flexibility facilitates orthopedic examinations, surgical plan and diagnostic assessment, thus enhancing the accuracy of medical practices, efficiency and accessibility.
Although the proposed model is effective, it is confined due to the use of certain datasets, which can decrease its applicability to other regions of the anatomy and types of pathology. Artificial rotations do not necessarily represent the natural variation in the patient. Scalability is also limited by the computational requirements in training. The potential future enhancements would involve using multimodal imaging (MRI, CT, X-ray), larger demographics, using more efficient architectures, and introducing more sophisticated statistical validation to increase robustness, adaptable, and clinical usefulness.
The researchers produced a useful deep learning model by incorporation of CGAN to create various viewpoints of two-dimensional medical images. The proposed model can produce realistic 90, 180 and 270 degrees view out of a single input image with a well-designed pipeline with optimized CGAN architecture. According to the results of the experiments, this model shows better results than some of the procedures as PSNR values, SSIM are high, whereas Entropy is greater and MSE, RMSE, MAE, FID, LPIPS, and NRMSE values are comparatively lower. This performance proves that the model can be applied to provide practicality in a non-invasive low-cost adaptation of 3D imaging as a replacement of the traditional 3D imaging methods, including CT or MRI. By its application the model shields patients against exposure to ionizing radiation besides being better in areas with limited health facilities. The algorithm produced a reconstruction of quality images using adversarial methods as well as supervising pixels irrespective of the type of rotation. Hospital diagnostic support becomes improved through the proposed approach which provides better imaging analysis safety within accessible environments without causing additional costs or health risks to patients.
The model should be expanded to create ongoing 3D volumetric image sequences instead of current multi-view outputs in next development stages. Additional attention mechanisms built into the CGAN framework would help the system extract better features which would result in more realistic images. The training dataset should be expanded to include various physiological areas and different pathological subjects to improve model generalization. Real-time rotational functionality combined with clinical diagnostic system integration are promising advancements in GAN development. The investigation of MRI-like output synthesis from X-ray inputs would enable universal medical diagnosis through a single affordable imaging approach.
[1] Yashaswini, G.N., Manjunath, R.V., Shubha, B., Prabha, P., Aishwarya, N., Manu, H.M. (2025). Deep learning technique for automatic liver and liver tumor segmentation in CT images. Journal of Liver Transplantation, 17: 100251. https://doi.org/10.1016/j.liver.2024.100251
[2] Srivastava, M., Pandey, G. (2025). An efficient deep learning approach for liver segmentation in medical imaging. Journal of Information Systems Engineering and Management, 10: 695-713. https://doi.org/10.52783/jisem.v10i49s.9954.
[3] Basha, M.J., Vijayakumar, S., Jayashankari, J., Alawadi, A.H., Durdona, P. (2023). Advancements in natural language processing for text understanding. EDP Sciences, 399: 04031. https://doi.org/10.1051/e3sconf/202339904031
[4] Pushpakumar, R., Sanjaya, K., Rathika, S., Alawadi, A.H., Makhzuna, K., Venkatesh, S., Rajalakshmi, B. (2023). Human-computer interaction: Enhancing user experience in interactive systems. EDP Sciences, 399: 04037. https://doi.org/10.1051/e3sconf/202339904037
[5] Latha, B., Sowndarya, S., Raghuwanshi, A., Feruza, R., Kumar, G.S. (2023). Hand gesture and voice assistants. EDP Sciences, 399: 04050. https://doi.org/10.1051/e3sconf/202339904050
[6] Rajalingam, A., Nesakumar, D., Sathya, S., Krishnankutty, J.E., Pagunuran, J.R. (2024). The future of EV: Real-time development of an intelligent wireless charging system for electric vehicles. In 2024 1st International Conference on Cognitive, Green and Ubiquitous Computing (IC-CGU), Bhubaneswar, India, pp. 1-7. https://doi.org/10.1109/IC-CGU58078.2024.10530791
[7] Praveenraj, D.D.W., Victor, M., Vennila, C., Alawadi, A.H., Diyora, P., Vasudevan, N., Avudaiappan, T. (2023). Exploring explainable artificial intelligence for transparent decision making. EDP Sciences, 399: 04030. https://doi.org/10.1051/e3sconf/202339904030
[8] Gandhi, M.A., Singh, L., Raj, G.B., Patil, H. (2024). An innovative method for paddy yield prediction based on DCNN-ELM approach. In 2024 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT), Bengaluru, India, pp. 762-767. https://doi.org/10.1109/IDCIoT59759.2024.10467772
[9] Sathya, T., Keertika, N., Shwetha, S., Upodhyay, D., Muzafar, H. (2023). Bitcoin heist ransomware attack prediction using data science process. EDP Sciences, 399: 04056. https://doi.org/10.1051/e3sconf/202339904056
[10] Roy, V., Shukla, S. (2015). A two stage approach with ICA and double density wavelet transform for artifacts removal in multichannel EEG signals. International Journal of Bio-Science and Bio-Technology, 7(4): 291-304. http://dx.doi.org/10.14257/ijbsbt.2015.7.4.29
[11] Sasirekha, R., Kaviya, R., Saranya, G., Mohamed, A., Iroda, U. (2023). Smart poultry house monitoring system using IoT. EDP Sciences, 399: 04055. https://doi.org/10.1051/e3sconf/202339904055
[12] Hayes, J.W., Montoya, J., Budde, A., Zhang, C., Li, Y., Li, K., Hsieh, J., Chen, G.H. (2021). High pitch helical CT reconstruction. IEEE Transactions on Medical Imaging, 40(11): 3077-3088. https://doi.org/10.1109/TMI.2021.3083210
[13] Kumar, P., Baliyan, A., Prasad, K.R., Sreekanth, N., Jawarkar, P., Roy, V., Amoatey, E.T. (2022). Machine learning enabled techniques for protecting wireless sensor networks by estimating attack prevalence and device deployment strategy for 5G networks. Wireless Communications and Mobile Computing, 2022(1): 5713092. https://doi.org/10.1155/2022/5713092
[14] Alghamdi, W., Salama, R., Alzubaidi, L.H., Akrom, U., Senthilkumar, R. (2023). Quantum computing: algorithms, architectures, and applications. EDP Sciences, 399: 04041. https://doi.org/10.1051/e3sconf/202339904041
[15] Basha, M.J., Murthy, T.S., Valarmathy, A.S., Abbas, A.R., Gavhar, D., Rajavarman, R., Parkunam, N. (2023). Privacy-preserving data mining and analytics in big data. EDP Sciences, 399: 04033. https://doi.org/10.1051/e3sconf/202339904033
[16] Preetha, R., Srisainath, R. (2023). Integrating renewable energy sources with micro grid using IoT and machine learning. EDP Sciences, 387: 02004. https://doi.org/10.1051/e3sconf/202338702004
[17] Natarajan, S.K., Rathinasabapathy, R., Narayanasamy, J., Aravind, A.R. (2023). Biometric user authentication system via fingerprints using novel hybrid optimization tuned deep learning strategy. Traitement du Signal, 40(1): 375. https://doi.org/10.18280/ts.400138
[18] Devi, K.J., Alghamdi, W., Alkhayyat, A., Sayyora, A., Sathish, T. (2023). Artificial intelligence in healthcare: Diagnosis, treatment, and prediction. E3S Web of Conferences, 399: 04043. https://doi.org/10.1051/e3sconf/202339904043
[19] Shukla, P.K., Roy, V., Chandanan, A.K., Sarathe, V.K., Mishra, P.K. (2023). A wavelet features and machine learning founded error analysis of sound and trembling signal. SN Computer Science, 4(6): 717. https://doi.org/10.1007/s42979-023-02189-y
[20] Joy, K.P., Ahila, R., Biruntha, M., Kalpana, R. (2023). A smart energy management system for residential buildings using IoT and machine learning. EDP Sciences, 387: 04009. https://doi.org/10.1051/e3sconf/202338704009
[21] Singh, V., Venkadeshwaran, K., Jha, G., Arunadevi, R., Sharma, Y.K., Maheswaran, S. (2023). Investigating the benefits of text mining for information analysis. In 2023 IEEE International Conference on Paradigm Shift in Information Technologies with Innovative Applications in Global Scenario (ICPSITIAGS), Indore, India, pp. 316-321. https://doi.org/10.1109/ICPSITIAGS59213.2023.10527666
[22] Albert, A.J., Murugan, R., Sripriya, T. (2023). Diagnosis of heart disease using oversampling methods and decision tree classifier in cardiology. Research on Biomedical Engineering, 39(1): 99-113. https://doi.org/10.1007/s42600-022-00253-9
[23] Udendhran, R., Sasikala, R., Nishanthi, R., Vasanthi, J. (2023). Smart energy consumption control in commercial buildings using machine learning and IoT. EDP Sciences, 387: 02003. https://doi.org/10.1051/e3sconf/202338702003
[24] Alghamdi, W., Salama, R., Sirija, M., Abbas, A.R., Dilnoza, K. (2023). Secure multi-party computation for collaborative data analysis. EDP Sciences, 399: 04034. https://doi.org/10.1051/e3sconf/202339904034
[25] Khan, A.A., Almuzaini, K.K., Macedo, V.D.J., Ojo, S., Minchula, V.K., Roy, V. (2023). MaReSPS for energy efficient spectral precoding technique in large scale MIMO-OFDM. Physical Communication, 58: 102057. https://doi.org/10.1016/j.phycom.2023.102057
[26] Radhakrishnan, S., Jasmin, M., Senthilkumar, K.K., Vanitha, M. (2023). Intelligent control system for wind turbine farms using IoT and machine learning. EDP Sciences, 387: 04004. https://doi.org/10.1051/e3sconf/202338704004
[27] Inamdar, F.M., Singar, M.K., Naval, P., Pattanaik, A., Santhoshkumar, M.P. (2023). Improving accuracy and speed of deep learning algorithms for real-time data analysis in machine learning. In 2023 IEEE International Conference on Paradigm Shift in Information Technologies with Innovative Applications in Global Scenario (ICPSITIAGS), Indore, India, pp. 269-275. https://doi.org/10.1109/ICPSITIAGS59213.2023.10527455
[28] Jakhar, S.K., Vennila, C., Rege, P.R., Naval, P., Haripriya, V., Vashisht, N. (2023). Leveraging recurrent neural networks for accurate time series predictions. In 2023 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, pp. 1-5. https://doi.org/10.1109/ICERCS57948.2023.10434021
[29] Kumar, C.A., Vandana, R., Vijay, B., Chandrasekaran, R., Akshay, V., Abdul, Z.M.M., Pankaj, A., Kumar, V.S. (2025). Federated learning-integrated autoencoder model for robust and decentralized pneumonia detection in chest X-rays. Traitement du Signal, 42(3): 1585-1599. https://doi.org/10.18280/ts.420330
[30] Ghule, V.R., Agrawal, A.K., Kumar, J.R.R., Mondal, D., Hemelatha, S. (2023). An evaluation of the impact of ai on data access optimization performance. In 2023 3rd International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Bangalore, India, pp. 1-6. https://doi.org/10.1109/SMARTGENCON60755.2023.10442704
[31] Ganesamoorthy, R., Pushpa, G., Senthilkumar, B. (2023). A novel design of an image encryption and decryption scheme using enhanced cybersecurity principles. In 2023 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, pp. 1-6. https://doi.org/10.1109/ICERCS57948.2023.10434166
[32] Kumar, A.S., Ramesh, M., Arpana, M., Sudarshanam, A., Velusudha, N.T., Suthar, T. (2023). Image processing techniques for leaf disease detection based on ELM-SSA approach. In 2023 3rd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bengaluru, India, pp. 311-316. https://doi.org/10.1109/ICIMIA60377.2023.10426262
[33] Garg, P., Yadav, R.K., Nirmala, D., Sable, N.P., Murari, K. (2023). Estimation analysis of edge and line detection methods in digital image processing. In 2023 3rd International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Bangalore, India, pp. 1-6. https://doi.org/10.1109/SMARTGENCON60755.2023.1044272