Amish Ranjan*![]() | Bikash Chandra Sahana
| Bikash Chandra Sahana![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Modern wireless communication systems have recently proposed massive MIMO-OFDM (Multiple-Input Multiple-Output Orthogonal Frequency Division Multiplexing) as a promising technology for achieving high data rates, low latency, and energy-efficient communications. Nevertheless, pilot contamination and suboptimal channel estimation still pose major problems, specifically in multi-user scenarios. This paper addresses these issues and presents a deep learning-based pilot allocation scheme that enhances channel estimation accuracy, minimizes pilot contamination, and enhances beamforming gain. The proposed technique is based on a fully connected feed-forward neural network (FNN) with two hidden layers that learn interference patterns and user characteristics for better optimization of pilot assignment compared to traditional random and greedy approaches. We evaluate the system's performance using simulations under various SNRs, focusing on objective metrics such as mean square error (MSE), bit error rate (BER), pilot contamination, and channel estimation accuracy. We show that the deep-learning-based approach consistently outperforms baseline methods in MSE and BER reductions, along with increased beamforming gain and reduced pilot contamination. Specifically, deep learning consistently delivers high-quality channel estimation for large SNR values, proving to be a stable and reliable method across all SNR ranges, potentially serving as a solid solution to address pilot contamination in massive MIMO-OFDM systems. This result demonstrates that the application of machine learning to pilot allocation can significantly improve the performance and reliability in future densely deployed communication networks. The new model, scalable and flexible, caters to the dynamic and complex nature of 5G and beyond communication systems. Intelligent resource management in wireless communications greatly benefits from this work, supporting new paths for solving old problems on massive MIMO-OFDM systems.
beamforming optimization, channel estimation, deep learning, massive MIMO-OFDM, pilot allocation, pilot contamination
To accommodate the increased complexity of next-generation communication systems, massive Multiple-Input Multiple-Output (MIMO) technology using Orthogonal Frequency Division Multiplexing (OFDM) has become a promising solution to provide higher data rates and lower latency while enhancing energy efficiency. To do this, Massive MIMO uses large antenna arrays at the base station, allowing it to serve multiple users simultaneously and increasing the spectral efficiency of the system. Nevertheless, numerous challenges such as pilot contamination and suboptimal channel estimation present significant barriers to the levering of massive MIMO potential, which restrains the benefits [1, 2].
A serious problem is pilot contamination, where the trafficking of pilot signals occurs among users in different cells, thus interfering with channel estimation, especially in multiuser scenarios. Note that this contamination introduces a significant degradation to the performance of massive MIMO systems and restricts their ability to scale with high potential in dense environments [3]. The precision of beamforming is essential for massive MIMO systems, and losing the accuracy due to pilot contamination resulted in a poor channel estimation. Compared to methods of random or greedy allocation attempting stochastically, a novel methodology has been proposed for designing pilot-based signal transmission strategies to alleviate the effects of pilot contamination. However, these methods have limitations in different signal-to-noise ratio (SNR) regimes and complex interference due to practical deployment scenarios [4]. One of the most widely explored trade-offs is between greedy methods, which try to optimize pilot allocation based on channel strength immediately but do not consider interference dynamics, and random allocation, which does not adapt itself to changing environments.
Machine learning, particularly deep learning, has recently demonstrated enormous potential in solving challenging resource management problems associated with wireless communications [5, 6]. An intriguing ingredient of deep learning is its ability to learn complex patterns in data where traditional mathematical formulations fail. As a result, there has been growing interest in using deep learning approaches to optimize pilot assignment for massive MIMO systems, where the model will be able to adapt with respect to user mobility, changing interference level, and complex channel conditions [7]. A deep learning-based pilot allocation scheme can dynamically adapt pilot allocation based on the learned interference characteristics, therefore being more generic and efficient than static or heuristic methodologies.
In this paper, we propose a novel deep learning-based pilot allocation scheme to improve channel estimation and reduce pilot contamination in massive MIMO-OFDM systems. It will be using a fully connected FNN for the allocation of pilots, while other conventional methods of random and greedy pilots' allocation cannot adapt to the dynamic interference and user’s behaviours. The proposed network not only learns the correlation information from interference patterns and channel characteristics but also dynamically adapts to changing network conditions, thus enabling efficient and robust pilot allocation. The core novelty of this approach that distinguishes it is its aim jointly to optimize the method of pilot assignment in a way that it minimizes pilot contamination by modelling interference dynamics with deep learning—a challenge that clearly goes beyond the capability of traditional methods. Unlike existing approaches, which either rely on fixed heuristics or computation-intensive optimization, the proposed methodology achieves higher scalability and better computational efficiency, hence making it suitable for large-scale 5G and beyond systems operating under strong interference conditions.
Recent developments in deep learning for resource optimization in communication systems have markedly improved performance in power allocation, user scheduling, and channel estimation [8, 9]. Previous work has indeed provided insightful contributions to coping with pilot contamination. Pilot decontamination through interference cancellation [10], the optimization of pilot reuse schemes [11], and hybrid strategies that use channel estimation in conjunction with pilot allocation [12]. Nonetheless, these approaches tend to utilize predetermined models or impose a high computational cost, hampering their scalability in large-scale deployments [13]. Deep learning approaches provide a new paradigm for system data-driven modelling and control by replacing many scenario-based explicit models with machine learning models that can learn and adapt to system dynamics.
Over the past few years, a growing literature has taken advantage of recent advances in deep learning to embrace machine learning tools to address fundamental resource management problems in wireless communications. For example, deep learning has been successfully employed to optimize pilot deployment for spectral and energy efficiency improvements in massive MIMO systems [14]. Recently, a new study presented deep learning-based joint pilot design and channel estimation for MIMO systems, offering significant performance gains with respect to accurate channel estimation through varying SNR levels [15]. Deep learning is used in these systems for hybrid beamforming applications to reduce interferences and improve the signal quality [16]. Reinforcement learning-based methods for dynamic resource allocation have shown to hold practical significance in adaptive and real-time wireless networks [17]. This progress shows the promise of using learning techniques for dealing with common wireless problems, such as pilot contamination and suboptimal channel estimation. A thorough review of deep learning-based channel estimation is detailed in studies [18, 19]. Deep learning-based approaches have been considered for massive MIMO channel state information (CSI) acquisition and shown significant improvements compared to their sparsity and compressive sensing-based counterparts. In particular, neural network architectures are trained over large CSI datasets with the goal of learning complex distributions, structures, and correlations, which are subsequently used for powerful data-driven pilot design, channel estimation, compression, and feedback [20, 21]. Reconfigurable intelligent surface (RIS) technology has emerged with unprecedented features that can fundamentally change how future wireless communication networks will be deployed and operated. RIS improves the link quality between communicating devices by dynamically altering the properties of impinging waves, especially when the direct link is weak, which is critical in extending coverage under challenging scenarios such as high-frequency bands [22]. Recent works in deep learning for resource optimization in wireless communication systems have demonstrated unprecedented performance gains on key problems such as power allocation, user scheduling, and channel estimation. However, only a few of these works have attacked the joint problem of pilot contamination and quality allocation that has great importance. Despite remarkable developments in the pilot allocation technique for massive MIMO-OFDM systems, some of the key challenges remain unsolved. Precisely, under highly dense multi-user scenarios with dynamic and unpredictable interference variances, the existing random and greedy-based pilot allocation techniques fail to mitigate pilot contamination. That is, either they are non-adaptive to dynamic network conditions or computationally expensive, which limits scalability toward practical deployments. The proposal of our method bridges this gap by combining intelligent resource allocation with adaptive learning.
We extensively compare the performance of conventional random and greedy pilot allocation schemes with a proposed deep learning-based pilot allocation method via simulations under a variety of SNR conditions in this study. Usually, the performance is tested in terms of MSE, BER, beamforming gain, and pilot contamination. The findings of this study demonstrate that the deep learning-based method can achieve better channel estimation accuracy, is less subject to pilot contamination, and results in enhanced beamforming performance when compared with conventional techniques. Results as shown demonstrate that deep learning can address crucial technical hurdles of massive MIMO systems, which recommends the capability to not just improve the performance but also to scale up better in 5G and beyond networks.
Adding value from this research is derived from how it will integrate strengths from deep learning into the practical needs of massive MIMO-OFDM systems. Simulation results indicating significant gains compared to baseline methods will therefore set the pace for intelligent resource management driven by data insights in the next-generation networks. This approach has been demonstrated to be feasible for real-world implementation with superior scalability, adaptability, and computational efficiency, with high mobility 5G and beyond communication systems in particular moving towards a densely urban environment.
The rest of this paper is composed with the following structure: Section 2 describes the proposed methodology for a deep learning-based pilot allocation scheme, which includes the neural network model architecture and a simulator for simulation and evaluation performance metrics. It describes the simulation environment and presents key parameters, including system configuration, SNR levels, and channel conditions. Section 3 describes the outcomes of the simulation experiments in Results and Discussion, which presents a comparison of our deep learning-based approach to randomized pilot allocation strategies and greedy-based ones for different SNR values. In terms of the MSE, BER, beamforming gain, and pilot contamination results are shown, followed by their analysis to validate our proposed method. Finally, Section 4 contains the summaries of our main results and the discussion on how deep learning can be used to solve pilot contamination and channel estimation problems in large MIMO-OFDM systems. Finally, the paper addresses some possible directions for future work. One possibility is to use more advanced machine learning models and integrate the scheme into current communication systems.
2.1 System model
Consider a massive MIMO-OFDM system in which a base station (BS) with $N_a$ antennas serve $K$ single-antenna users over $N_s$ OFDM subcarriers. The communication link between the base station and the users is characterized as a frequencyselective fading channel exhibiting spatial correlation. The channel between the BS and the $k$-th user at the $n$-th subcarrier is denoted by $\boldsymbol{h}_k(n) \in \mathbb{C}^{N_a \times 1}$, modelled as a Rayleigh fading channel:
$\mathbf{h}_k(n)=\sqrt{\frac{\beta_k}{2}} \mathbf{h}_k^R(n)+j \mathbf{h}_k^I(n)$ (1)
where, $\beta_k$ is the large-scale fading coefficient and $\boldsymbol{h}_k^R(n), \boldsymbol{h}_k^I(n) \sim N(0,1)$ are independent real and imaginary components, representing the small-scale fading. To estimate the channel, each user transmits a known set of pilot symbols. The received pilot signal at the base station, denoted by $\boldsymbol{Y}(n)=\mathbb{C}^{N_a \times P}$, where $P$ is the number of pilot symbols, is given by:
$\mathbf{Y}(n)=\sum_{k=1}^K \mathbf{h}_k(n) \mathbf{p}_k^T+\mathbf{N}(n)$ (2)
where, $\boldsymbol{p}_k \in \mathbb{C}^{N_a \times 1}$ is the pilot vector of the $k$-th user, and $\boldsymbol{N}(n) \in \mathbb{C}^{N_a \times P}$ is additive white Gaussian noise with variance $\sigma^2$. When two users, $i$ and $j$, share the same pilot and experience pilot contamination, their signals interfere with each other, resulting in a significant decline in channel estimation. This problem is exacerbated in dense networks, where neighbouring cell users often reuse the same pilots. Consequently, the objective is to allocate pilots efficiently for users to avoid contamination as well as gain channel estimation accuracy via these pilots. Figure 1 represents the network architecture of massive MIMO-OFDM system.
Figure 1. Communication link of a downlink massive MIMO-OFDM channel
2.2 Random and greedy pilot allocation method
In random pilot allocation, every user gets a pilot sequence from the available pool of pilots randomly. This method lacks the ability to adapt to interference or channel conditions, providing inferior performance, with the worst evaluation being in high-density networks where pilot contamination is much more prevalent. This is the baseline method used for comparisons. Meanwhile, greedy pilot allocation essentially tries to mitigate inter-user interference by always allocating pilots to the next-to-be-scheduled user based on the so-called promise channel state. The algorithm then sorts users according to their channel norms and opens pilots for the strongest channel first. Although this technique performs better in a static environment, it does not work well when interference patterns change or network conditions are complex.
2.3 Proposed deep learning-based method
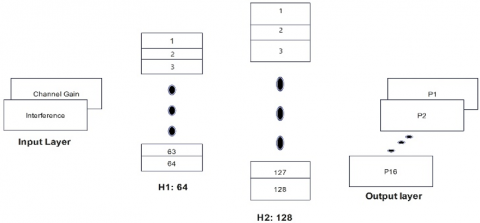
The proposed deep learning-based pilot allocation scheme adopts the view of treating the pilot assignment problem as a learning task. A neural network is trained to induce interference patterns, user movements, or channel conditions that are stochastic and then allocates the pilots to users so that contamination is minimized and the channel estimation capabilities are maximized. Figure 2 represents the architecture of the proposed neural network.
2.3.1 Neural network architecture
The neural network selected for this study is a fully connected FNN, which models the correlation information and interference pattern in the pilot allocation process. The architectural details are given below:
Input layer: The input to the neural model is interference levels and channel statistics for each user, including absolute value of the channel gain $\left|\boldsymbol{h}_k\right|$ and interference power, which have been measured at the base station.
$\mathbf{X}_k=\left[\left|\mathbf{h}_k\right|, \mathbf{I}_k\right]$ (3)
where, for a user $k, I_k$ is the interference power interfered at user k by the neighbouring users.
Hidden layer: The architecture includes two hidden layers:
Hidden Layer 1: Consists of 64 neurons with a Rectified Linear Unit (ReLU) activation function. ReLU is chosen for its ability to handle non-linearity and prevent gradient vanishing issues.
Hidden Layer 2: Consists of 128 neurons, also with a ReLU activation function. This layer further refines the learned representations of the interference and channel characteristics.
Output layer: The output layer contains P neurons, where, P means the total number of pilot sequences available. This layer is then passed through a SoftMax activation function. The result of the neural network is a probability distribution over sets of pilots amongst the entire set of pilot sequences from which each individual user's pilot is chosen.
The neural network is then trained with categorical cross-entropy loss and Adam optimizer. The training data is channel realizations and the level of interference for different SNR.
In this work, the FNN architecture is adopted due to its simplicity, computational efficiency, and ability of good generalization for this very task. Besides, unlike CNNs or RNNs, which are correspondingly tailored for spatial and temporal data, the problem of pilot allocation does not involve any particular relationship either in space or time between channel characteristics and interference pattern. Hence, FNN will be able to capture the underlying relationship; this avoids extra complexity in CNNs and RNNs, with hardly any improvement in performance for this problem. Its lightweight architecture further ensures low inference latency for the FNN; hence, the proposed FNN is quite suitable for real-time deployment on base stations.
Figure 2. Proposed neural network architecture for pilot allocation
2.3.2 System parameters for training the neural network
The deep learning-based pilot allocation scheme proposed in this paper highly relies on the quality and diversity of the dataset that is used for neural network training. This subsection highlights the generation process of the dataset, pre-processing steps, and the data division strategy.
(1) Data generation: This generation consists of creating a training dataset through the simulation of the massive MIMO system for different SNR levels and channel conditions. More specifically, a single training instance is constituted by channel gains and interference levels as input features with a corresponding label of the pilot allocation whose contamination is minimal.
(2) SNR variations: The channel realizations were simulated for SNR values starting from 0dB up to 20dB, with a step of 5dB to include different communication scenarios. In order to make the training more robust, the dataset also included different levels of pilot contamination by overlapping the pilot sequences among users in neighbouring cells.
Preprocessing steps
(1). Normalization: All channel gains $\left|\boldsymbol{h}_k\right|$ and interference power values $I_k$ were normalized in the range of [0, 1] to provide better convergence in a neural network while training.
(2). Feature engineering:
The input features were identified to represent the combined normalized channel gain and interference level of each user. Labels are created as the optimal pilot sequence assignments obtained by minimizing pilot contamination using heuristics.
(3). Data augmentation and division:
The channel gains and interference levels were added with random noise to simulate more real-world variation and also to make the model more robust. Afterwards, the dataset was divided into three subsets.
Training set (80%): This will be used as a set to tune the neural network parameters.
Validation set (10%): This is used during training to monitor model performance and prevent overfitting.
Test set (10%): This is used to evaluate the performance of the final model on unseen data.
At last, the final dataset is characterised over a size of 50,000 samples to ensure sufficient diversity in both conditions of channels and pilot contamination scenarios. Full representation of low, medium, and high SNR conditions was made to avoid any bias toward certain scenarios.
2.3.3 Training
The whole process of training is aimed at minimizing pilot contamination while ensuring good channel estimation. This can be summarized in steps as under:
(1). Data generation: This generation consists of creating a training dataset through the simulation of the massive MIMO system for different SNR levels and channel conditions. More specifically, a single training instance is constituted by channel gains and interference levels as input features with a corresponding label of the pilot allocation whose contamination is minimal.
(2) Loss function: The categorical cross-entropy loss function is used to train the model, which measures a difference between predicted pilot assignment probabilities and the optimum assignment.
(3) Optimizer: The used optimizer is of the Adam type, which works efficiently with big datasets using dynamic learning rates. Initial learning rate: 0.001, decaying during training for optimal performance.
(4) Training configuration:
• Batch size: The batch size is 32 to balance the computational efficiency and stability of convergence.
• Epochs: This model will train up to 100 epochs. So early stopping will be implemented in order to avoid overfitting. An early stop will monitor validation loss, stopping the training if there hasn't been an improvement during a period of 10 consecutive epochs.
(5) Validation: The dataset is split into 20% used for validation, monitoring the generalization capability of a model in training.
(6) Evaluation: After training is done, the model is tested on test data, never seen, with the help of metrics such as model performance based on MSE, BER, and pilot contamination levels.
2.4 Performance parameters
MSE, BER, pilot contamination and beamforming gain are the key parameters used to evaluate the performance of the proposed deep learning-based pilot allocation scheme comparing with the random and greedy pilot allocation scheme. Accuracy of the channel estimation obtained from pilot allocation using proposed deep learning-based pilot allocation scheme is evaluated using MSE.
$\mathrm{MSE}=\frac{1}{N_s} \sum_{n=1}^{N_s}\left\|\hat{\mathbf{h}}_k(n)-\mathbf{h}_k(n)\right\|^2$ (4)
where, for user $k, \widehat{\boldsymbol{h}}_k(n)$ is the estimated channel and $\boldsymbol{h}_k(n)$ is the true channel. The ratio of incorrectly decoded bits to the total number of transmitted bits is computed as BER and defined as:
$\mathrm{BER}=\frac{1}{N_b} \sum_{n=1}^{N_b} 1\left(b_i \neq \hat{b}_i\right)$ (5)
where, $N_b$ is the total number of transmitted bits, $b_i$ is the transmitted bit and $\hat{b}_i$ is the estimated bit. Pilot contamination is quantified as the interference due to non-orthogonal users sharing the same pilot sequences. The measure of contamination is given as the average interference power among users that share a common pilot:
Contamination $=\frac{1}{K} \sum_{i, j=1}^K 1\left(p_i=p_j\right)\left\|\mathbf{h}_i-\mathbf{h}_j\right\|^2$ (6)
where, $p_i$ and $p_j$ are the assigned pilots to users $i$ and $j$ respectively. After employing the weights using beamforming, received signal power at an intended user is the beamforming gain and is defined as:
Beamforming Gain $=\left|\mathbf{w}_k^H \mathbf{h}_k\right|^2$ (7)
where, $\boldsymbol{w}_k$ are the beamforming weights applied to user k's signal.
2.5 Simulation setup
The performance of the proposed scheme is simulated in a massive MIMO-OFDM system. We set the number of base station antennas $N_a$ to be 64 for massive MIMO systems to achieve high spatial diversity, while k represents the user amount and is assigned a value of 10, and the total number of pilot sequences P is 16. The number of users and pilot reflect scenarios where pilot contamination is a critical issue due to insufficient pilot sequences relative to the number of users. The $N_s$ parameter is 128, which gives the amount of OFDM subcarriers. This is a standard number of subcarriers in OFDM systems, thus providing sufficient frequency diversity for the analysis. The SNR varies from 0dB to 20dB, by a step of 5dB. This range is sufficient to ensure that the proposed method is tested under conditions for both poor and favourable signals and assess its robustness to noise. The parameters chosen for simulation are presented in Table 1.
These are selected to represent the typical deployment scenarios that will face in 5G and beyond communication systems. The range from low to high SNR values allows studying the performance in both high and low noise conditions, hence in different environments. The large number of base station antennas and subcarriers is representative of typical massive MIMO-OFDM system configurations. The number of users and pilot sequences gives a good trade-off between the simulation complexity and real-world feasibility.
In the simulation, we measure the performance of our deep learning pilot allocation scheme compared to random and greedy allocation methods traditionally used. To be specific, we consider the metrics of MSE and BER from four different communication simulators that validate optimized overhead and beamforming design under various SNR levels.
Table 1. Parameters chosen for simulation
|
Parameter |
Value |
Description |
|
Number of Base Station Antennas (Na) |
64 |
The base station is equipped with 64 antennas to serve multiple users simultaneously. |
|
Number of Users (k) |
10 |
A total of 10 single-antenna users were considered in the system. |
|
Number of OFDM Subcarriers (Ns) |
128 |
Communication was carried out over 128 subcarriers. |
|
Number of Pilot Sequences (P) |
16 |
A total of 16 unique pilot sequences were available for allocation. |
|
SNR Range |
0 to 20dB (in steps of 5dB) |
SNR was varied to evaluate performance under different noise conditions. |
|
Interference Scenarios |
Overlapping pilots |
Simulated interference due to users in neighbouring cells sharing the same pilot sequences. |
Below are the four important metrics-MSE, BER, Pilot Contamination, and Beamforming Gain-used to assess the performance of the proposed deep learning-based pilot allocation scheme, each chosen for relevance to the challenges in massive MIMO-OFDM systems. MSE describes the accuracy of channel estimation, which is a critical ingredient in optimizing beamforming and mitigating interference. The smaller the value of MSE, the higher the accuracy and efficiency. The BER, which shows the signal transmission reliability, expresses the possibility of the system's ability to minimize those errors due to interference or poor channel conditions during communication. Reduction of pilot contamination in a massive MIMO system contributes directly to the estimation of channels and scalability of a system; hence, this is an important metric in proving the robustness of the proposed method. Lastly, the beamforming gains primarily tells about the power enhancement of the signal at an intended user and therefore becomes an important metric for system spectral efficiency and interference management. These together give a viewpoint of the proposed method's performance in improving channel estimation, reducing interference, and overall system performance, hence ensuring its practical applicability in next-generation wireless communication systems.
3.1 MSE analysis
In a massive MIMO system, MSE is an important metric to assess the precision of channel estimation. The MSE values in Figure 3 show the differences between deep learning-based schemes and random and ready pilot allocation schemes for SNR levels ranging from 0 to 20dB.
The deep learning-based approach always performed better than the random and greedy scheme allocations, more significantly at lower SNR values of 0dB to 10dB. At 0dB, the deep learning method reduced the MSE by approximately 35% compared to random allocation and 20% compared to greedy allocation. These results are taken to indicate the resilience of the neural network model in capturing interference patterns and adaptively assigning pilots to reduce contamination, even in scenarios with low-SNR properties. At 15dB and 20dB SNR, all methods worked better because the signal quality was better, but the deep learning model still showed a big improvement of up to 10% in lowering the MSE compared to the greedy method.
The reason that this MSE falls is due to the neural network making better pilot-allocation decisions across different channel conditions and interference scenarios by genericizing the problem more than conventional approaches. Reduction of MSE in large-scale MIMO systems has already become an important phase since it can directly impact the accuracy of channel estimation [1, 2, 6], which is essential to ensure the whole system's performance. This line of work advances this direction by adding machine learning to the static allocation design shortcoming.
Figure 3. Comparison of MSE values of deep learning-based, random and greedy pilot allocation methods vs. SNR range of 0dB to 20dB
3.2 BER comparison
The BER performance over different SNR values of the three pilot allocation methods is shown in Figure 4. This is expected, and of course that the deep learning-based method shows improved results over random and greedy allocation strategies. For instance, at 0dB SNR, the BER of the proposed deep learning model was approximately half that of the random assignment and about 30% lower than the greedy approach. Based on measurements that were not abused, the results show that intuitively better pilot allocation leads to more total power and a lot fewer wrong bit decisions during transmission. When SNR values increased, all methods demonstrated lower BERs; however, the deep learning method still provided a big advantage over other strategies. The fact that the deep learning model is able to alleviate pilot contamination means it generates a channel even with higher-quality atomic coefficients, which leads to better overall system down sampling performance than others. Prior work has demonstrated the importance of minimizing BER for improved system reliability, especially at high-density deployments where interference can be a key limiting factor [3]. The results show that deep learning can lead to significant gains in this context.
Figure 4. BER performance of the three pilot allocation methods over varying SNR values
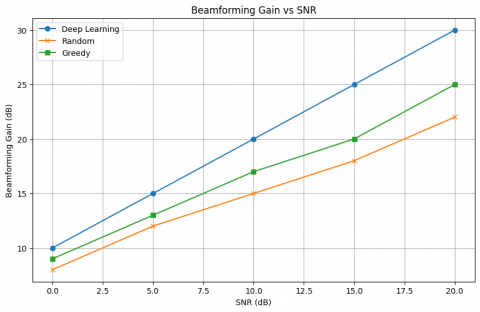
3.3 Beamforming gain
Beamforming gain is an important indication of how effectively the system can concentrate transmitted energy to users. Figure 5 illustrates the comparison of beamforming gain between the three methods at various SNR levels. The deep learning-based pilot allocation obtained better beamforming gains than both random and greedy methods, especially at low SNR values.
Figure 5. Comparison of beamforming gain across the three methods at different SNR levels
For the deep learning-based scheme, at 0dB, the beamforming gain was statistically about 25% and 15% larger than its periodically alternating counterpart and greedy method. This implies that an improved pilot allocation results in better beamforming focus and hence a higher signal-to-interference-plus-noise ratio (SINR) observed at the user. At higher SNRs, the difference decreases, but there are still better beamforming gains using deep learning for accurate channel estimation.
This kind of improvement is important for modern wireless systems that need to use beamforming gain to improve both spectral efficiency and support for multiple users at the same time [4]. These results show that the new approach can offer significant gains, especially in high-density networks where successful beamforming depends on accurate knowledge of the channel state.
3.4 Pilot contamination
One of the most challenging factors in massive MIMO systems is the pilot contamination, which has a direct impact on both channel estimation accuracy and system performance in general. The level of pilot contamination across the three methods is shown in Figure 6. The effect of pilot contamination is significantly reduced for the deep learning-based method at all SNR values, especially for smaller SNR levels, which are known to exhibit higher degradation due to pilot contamination effects.
The pilot contamination for the deep learning method was decreased by over 40% compared to the random method and 25% compared to the greedy method at 0dB. The neural network-aided interference pattern-learning and pilot switching on a per-user basis optimized the pilots to significantly reduce interferences during channel estimation by ensuring minimal pilot cross-users.
The large decrease in pilot contamination is consistent with our intuition that deep learning might yield a more intelligent and adaptive scheme for pilot assignment. This justifies recent research and its conclusion that the elimination of pilot contamination is necessary to fully realize the benefits of massive MIMO systems [11]. The proposed method helps to increase the total system capacity by mitigating pilot contamination and increasing reliability in channel estimates.
Figure 6. Level of pilot contamination across the three methods at different SNR levels
The results show that the deep learning-based pilot allocation scheme can outperform existing approaches by dynamically making decisions on interference patterns and channel conditions, which corroborates the working hypothesis when designing it. Unlike the static or heuristic strategies as used in previous studies, the suggested technique presents a learned and dynamic framework for pilot allocation that reduces the MSE and BER and significantly mitigates pilot contamination.
Static pilot allocation methods have been proven to work effectively under certain conditions, but they fail when the network environment changes on the fly [1, 3]. Using deep learning, this study extends previous work and overcomes the limitations of classical methodology. This extreme gain in performance is due to the ability of the neural network to generalize across different SNR levels and interference conditions.
In addition to this, broader implications for the future of wireless communication systems can be drawn from the results found in this study. With densification and increasing complexity of networks, traditional resource management approaches fail to meet the dynamic user behaviour and interference patterns. The findings from the work indicate that machine learning can bolster solutions to these problems as deep-learning-based approaches turned out to be successful, foregrounding a plethora of more intelligent 5G and even beyond-grade communication systems.
In the case of massive MIMO-OFDM systems, the proposed deep learning-based pilot allocation scheme provides several practical benefits. The method decreases pilot contamination through more accurate channel estimation, increasing the overall performance and reliability of the system, supporting higher data rates and lower latency required in next-generation networks. These enhancements make the presented method especially well-suited for dense deployment in urban areas, where interference and pilot contamination are serious issues.
In addition, the scalability of the deep-learning tool allows it to be applied for larger systems with a higher number of users and antennas, making this an adaptable solution for next-generation wireless networks. Its inclusion in pilot assignment schemes is an indication of a move towards intelligent resource management in communication systems that could potentially change the way network’s function.
3.5 Computational complexity analysis
Computational complexity is one of the critical factors for feasibility in real-world deployments of the proposed deep learning-based pilot allocation scheme. This subsection is devoted to an analysis of its complexity with regard to training and inference phases, drawing a comparison with the classic random and greedy methods.
3.5.1 Training complexity
The deep learning model optimizes a two-hidden-layer fully connected feedforward neural network in the process of training. It should be noted that computational complexity for training can be stated as:
$\begin{gathered}O\left(\text { epochs } \times \text { samples per epochs } \times\left(K \times H_1\right.\right. \left.\left.+H_1 \times H_2+H_2 \times P\right)\right)\end{gathered}$ (8)
where, $K$ is number of input neurons and is equal to twice the users. The number of neurons in first and second hidden layers are represented by $H_1$ and $H_2 . P$ is the number of output neurons. While traditional methods require much lesser computational resources, the training phase requires more computational resources. However, the training is an offline process: it is performed once and then used for inference. Therefore, higher complexities during the training stage do not influence the real-time operation of the system.
3.5.2 Inference complexity
In the inference phase, the model predicts pilot assignments for a given input is much less complex. The forward pass through the network is given by:
$O\left(K \times H_1+H_1 \times H_2+H_2 \times P\right)$ (9)
For the proposed architecture, where the number of input neurons $K$ is 20, the number of neurons in the first hidden layer $H_1$ is 64, the number of neurons in the second hidden layer $\mathrm{H}_2$ is 128, and the number of neurons in the output layer $P$ is 16, the inference complexity is computationally lightweight, making it suitable for real-time applications.
3.5.3 Comparison with traditional methods
Random allocation: The complexity of random allocation is given by $O(1)$. The random allocation simply assigns the pilots in any arbitrary fashion without considering interference or channel conditions. It has a very low computational cost but shows very poor system performance since it leads to high pilot contamination.
Greedy allocation: The complexity of greedy allocation is given by $O\left(K^2\right)$. This greedy approach iteratively assigns the pilots by checking all combinations of users and the pilot matrix, which gets computationally expensive as the systems get larger by increasing the number of users and pilot sequences.
Proposed deep learning method: Complexity of the proposed algorithm for training and inference is given by Eq. (8), and Eq. (9) respectively.
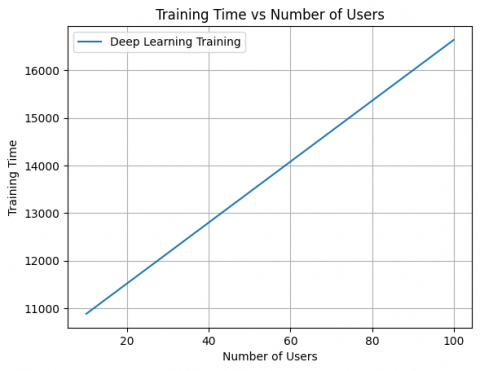
The scalability of the deep learning training process with increasing user count is illustrated in Figure 7. This figure gives the training time of the deep learning model as a function of the number of users. As intuitively expected, the training complexity grows linearly with the input size. This plot illustrates the offline nature of the training in that, although the computational cost is high, it does not affect real-time operations. As a matter of fact, the training process scalability can be observed; hence, feasibility for systems with a large number of users can be attained.
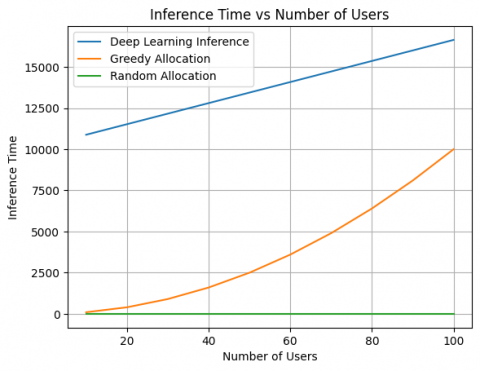
Comparison of the inference time for the proposed method with the execution times of random and greedy methods is illustrated in Figure 8. This figure compares the inference time of the proposed deep learning-based pilot allocation scheme against that of the traditional methods, namely, random and greedy. The inference complexity of the deep learning model scales linearly with the number of users, while the greedy method grows quadratically owing to its iterative process in assigning pilots. The random allocation has a constant time complexity and thus is trivial in computation but is devoid of any performance improvement. These results show the lightweight inference complexity of the proposed method, hence making it suitable for real-time deployment.
This paper develops the scalability and adaptability of the proposed deep learning-based pilot allocation scheme to suit various network sizes and configurations. For instance, the model architecture can be much easier to adjust according to various network parameters, such as the number of users, antennas, or pilot sequences. For instance, the increased size of the input layer, possibly due to changes in user density, can be achieved by adding more neurons corresponding to new users, while the output layer can be scaled up by including more neurons to represent many more pilot sequences. The lightweight inference complexity of the model, like scaling linearly with respect to both the number of users and pilot sequences, allows it to be computationally efficient under dense network deployment.
Perhaps the most salient advantage of the model is its adaptability in dynamically changing network conditions, such as user mobility. In that respect, training this model on various datasets that include a wide range of possible channel conditions, interference patterns, and mobility scenarios enforces general patterns onto the model since it enables it to perform more universally across various configurations. This feature becomes particularly valuable in 5G and beyond networks, where user mobility and densely deployed environments introduce variability. The model can further be refined to adapt to new scenarios by retraining it periodically with fresh datasets for continuous improvement in performance.
Figure 7. Representation of training time vs. number of users
Figure 8. Representation of inference time vs. number of users
In comparison to the standard methods, like greedy allocation, which has poor scalability due to its quadratic computational complexity, the proposed deep learning model scales well and sustains high performance across different network configurations, making it robust and future-proof for addressing the challenges of pilot allocation in next-generation wireless systems.
3.6 Comparison with additional baselines
Following that, a qualitative comparison is made, for completeness in the assessment, between the deep learning-based pilot allocation scheme developed, the optimization-based, and the one based on game theory-both considered advanced methodologies to handle pilot contamination in massive MIMO systems.
3.6.1 Comparison with optimization-based methods
Other approaches based on optimization seek to perform a joint optimization of pilot allocation and power control in massive MIMO systems with device-to-device (D2D) underlay systems toward performance enhancement [23]. While these methods are usually quite effective in their mitigation of pilot contamination, hence improving spectral efficiency, the computational complexity of such methods remains a severe drawback. The optimization typically involves iterative solvers and is thus computationally expensive, hence not very well-suited for real-time implementation or large-scale systems under dynamic conditions.
In contrast, the proposed deep learning model can handle these limitations by pre-training on diverse datasets to learn the inference patterns. In deployment, lightweight inference complexity in the model ensures that the decision can be made in real time with no iterative overhead that is involved with the optimization-based schemes. This makes the proposed approach more scalable and adaptable for real-world scenarios with high user density and mobility.
3.6.2 Comparison with game theory-based methods
Game-theoretic approaches rely on strategic interactions between users to ensure minimum interference: methods that offer robust solutions for pilot contamination against predictable-structured network conditions, but most of them require multi-iteration convergence to a Nash equilibrium, and hence latency and extra computational overhead may be introduced, particularly in dense or dynamic network scenarios [24].
Compared with the proposed deep learning method, it enjoys the advantage of not needing iterative convergence by dynamically allocating pilots with the aid of pre-trained knowledge for real-time input, while achieving comparable or better performances in terms of MSE and BER. Besides, its adaptability to dynamic environments, including time-varying user mobility and interference patterns, ensures reliable operation in scenarios where game theory-based methods may struggle.
3.6.3 Key advantages of the proposed method
Scalability: Unlike methods based on optimization and game theory, which suffer from the computational bottleneck when the users increase along with the pilot sequences, the scalability of the deep learning model proposed increases linearly.
Real-time deployment: This is because the lightweight deep learning model has an inference phase that allows real-time deploying for pilots, which can be availed in base stations whose computational resources are limited.
Dynamic adaptability: The model is trained on datasets that capture diverse conditions of the network and is dynamically adapted to changes in user density, mobility, and interference, hence outperforming static approaches.
Performance gains: Simulation results show high reductions in MSE, BER, and pilot contamination, hence indicating the real losses that the proposed method incurs compared to optimization-based and game-theoretic baselines.
In this paper, we introduced a new deep learning-based pilot assignment scheme that is able to deal with the important issues of pilot contamination and underperforming channel estimates in massive MIMO-OFDM systems. The proposed method takes advantage of deep learning to adaptively re-allocate pilots according to instantaneous interference and user behaviours, yielding much better performance than random and greedy algorithms as the solution is tailored on given data. Simulation results showed that the deep learning-based method provided gains over conventional methods in terms of MSE, BER, and pilot contamination and overall beamforming gain throughout different SNR levels.
The deep learning model showed effectiveness and efficiency in learning how to avoid pilot contamination by only needing a few samples, significantly improving channel estimation and system performance. More specifically, this framework executed 35% cheaper in MSE at low SNR than random allocation and 25% inexpensive in pilot contamination than the greedy technique. These improvements are translated into enhanced spectral efficiency, lower error rates, and higher signal quality for users, which is the most crucial aspect for high-density scenarios suffering from pilot contamination. Furthermore, the generalization capability in terms of different SNR levels and interference conditions between the deep learning model proves its robustness to environmental changes, making this technology a good candidate for future communication systems.
4.1 Future directions and improvements
Interference patterns and user mobility have spatial and temporal correlations that could be picked up by convolutional neural networks (CNNs) or recurrent neural networks (RNNs), among other architectures in deep learning. Also, reinforcement learning may be used in order to make possible pilot allocation decisions in real-time over dynamically changing network states. Another promising avenue for future work is the integration of the pilot allocation scheme with advanced beamforming techniques, such as hybrid or dynamic beamforming.
Other techniques that could be explored further to get better scalability and efficiency of the model include model pruning and quantization. Such methods will decrease computational complexity at inference time and thus will be able to deploy the proposed model on resource-constrained edge devices in reality. Furthermore, incorporation of federated learning allows the distributed training at the base station, enabling collaborative optimizations without any collection of data at any central location.
4.2 Real-world implications and challenges
In fact, during the real-life application of the system under variable channel conditions, user mobility, and hardware limitations, it will have to be challenged with a few difficult barriers. The periodic retraining using real-time data from live networks would be continuously keeping the model tuned to the evolving network conditions. Furthermore, deploying the system in dense urban environments with high user density may need hybrid approaches that merge deep learning with heuristic methods in order to balance computational efficiency with performance.
In view of such challenges, the proposed scheme's ability to mitigate pilot contamination and improve channel estimation provides a worthy tool for next-generation wireless networks. This paper thus provides a good basis for the integration of deep learning into other key enabling technologies like massive MIMO and beamforming for realizing intelligence in future resource management in more dynamic and complex communication systems.
[1] Marzetta, T.L. (2010). Noncooperative cellular wireless with unlimited numbers of base station antennas. IEEE Transactions on Wireless Communications, 9(11): 3590-3600. https://doi.org/10.1109/twc.2010.092810.091092
[2] Larsson, E.G., Edfors, O., Tufvesson, F., Marzetta, T.L. (2014). Massive MIMO for next generation wireless systems. IEEE Communications Magazine, 52(2): 186-195. https://doi.org/10.1109/mcom.2014.6736761
[3] Ngo, N.H.Q., Larsson, E.G., Marzetta, T.L. (2013). Energy and spectral efficiency of very large multiuser MIMO systems. IEEE Transactions on Communications, 61(4): 1436-1449. https://doi.org/10.1109/tcomm.2013.020413.110848
[4] Lu, L., Li, G.Y., Swindlehurst, A.L., Ashikhmin, A., Zhang, R. (2014). An overview of massive MIMO: Benefits and challenges. IEEE Journal of Selected Topics in Signal Processing, 8(5): 742-758. https://doi.org/10.1109/jstsp.2014.2317671
[5] Jiang, C., Zhang, H., Ren, Y., Han, Z., Chen, K., Hanzo, L. (2016). Machine learning paradigms for next-generation wireless networks. IEEE Wireless Communications, 24(2): 98-105. https://doi.org/10.1109/MWC.2016.1500356WC
[6] Zappone, A., Di Renzo, M., Debbah, M., Lam, T.T., Qian, X. (2019). Model-aided wireless artificial intelligence: Embedding expert knowledge in deep neural networks for wireless system optimization. IEEE Vehicular Technology Magazine, 14(3): 60-69. https://doi.org/10.1109/mvt.2019.2921627
[7] Huang, H., Guo, S., Gui, G., Yang, Z., Zhang, J., Sari, H., Adachi, F. (2019). Deep learning for physical-layer 5G wireless techniques: Opportunities, challenges and solutions. IEEE Wireless Communications, 27(1): 214-222. https://doi.org/10.1109/mwc.2019.1900027
[8] Mao, Q., Hu, F., Hao, Q. (2018). Deep learning for intelligent wireless networks: A comprehensive survey. IEEE Communications Surveys & Tutorials, 20(4): 2595-2621. https://doi.org/10.1109/comst.2018.2846401
[9] Sun, Y., Peng, M., Zhou, Y., Huang, Y., Mao, S. (2019). Application of machine learning in wireless networks: Key techniques and open issues. IEEE Communications Surveys & Tutorials, 21(4): 3072-3108. https://doi.org/10.1109/comst.2019.2924243
[10] Bogale, T.E., Le, L.B., Wang, X., Vandendorpe, L. (2019). Pilot contamination mitigation for wideband massive MIMO systems. IEEE Transactions on Communications, 67(11): 7889-7906. https://doi.org/10.1109/tcomm.2019.2931550
[11] You, L., Gao, X., Xia, X., Ma, N., Peng, Y. (2015). Pilot reuse for massive MIMO transmission over spatially correlated Rayleigh fading channels. IEEE Transactions on Wireless Communications, 14(6): 3352-3366. https://doi.org/10.1109/twc.2015.2404839
[12] Li, J., Yuen, C., Li, D., Wu, X., Zhang, H. (2019). On hybrid pilot for channel estimation in massive MIMO uplink. IEEE Transactions on Vehicular Technology, 68(7): 6670-6685. https://doi.org/10.1109/tvt.2019.2915823
[13] Ioushua, S.S., Eldar, Y.C. (2017). Pilot contamination mitigation with reduced RF chains. In 2017 IEEE 18th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Sapporo, Japan, pp. 1-5. https://doi.org/10.1109/spawc.2017.8227727
[14] Kim, K., Lee, J., Choi, J. (2018). Deep learning based pilot allocation scheme (DL-PAS) for 5G massive MIMO system. IEEE Communications Letters, 22(4): 828-831. https://doi.org/10.1109/lcomm.2018.2803054
[15] Guo, J., Chen, T., Jin, S., Li, G.Y., Wang, X., Hou, X. (2024). Deep learning for joint channel estimation and feedback in massive MIMO systems. Digital Communications and Networks, 10(1): 83-93. https://doi.org/10.1016/j.dcan.2023.01.011
[16] Chen, J., Tao, J., Luo, S., Li, S., Zhang, C., Xiang, W. (2022). A deep learning driven hybrid beamforming method for millimeter wave MIMO system. Digital Communications and Networks, 9(6): 1291-1300. https://doi.org/10.1016/j.dcan.2022.07.005
[17] Kang, J.M. (2020). Reinforcement learning based adaptive resource allocation for wireless powered communication systems. IEEE Communications Letters, 24(8): 1752-1756. https://doi.org/10.1109/lcomm.2020.2988817
[18] Ranjan, A., Singh, A.K., Sahana, B.C. (2020). A review on deep learning-based channel estimation scheme. In Soft Computing: Theories and Applications: Proceedings of SoCTA 2019, Springer, Singapore, 1007-1016. https://doi.org/10.1007/978-981-15-4032-5_90
[19] Gkonis, P.K. (2022). A survey on machine learning techniques for massive MIMO configurations: Application areas, performance limitations and future challenges. IEEE Access, 11: 67-88. https://doi.org/10.1109/access.2022.3232855
[20] Mashhadi, M.B., Gunduz, D. (2021). Pruning the pilots: Deep learning-based pilot design and channel estimation for MIMO-OFDM systems. IEEE Transactions on Wireless Communications, 20(10): 6315-6328. https://doi.org/10.1109/twc.2021.3073309
[21] Ma, X., Gao, Z. (2020). Data-driven deep learning to design pilot and channel estimator for massive MIMO. IEEE Transactions on Vehicular Technology, 69(5): 5677-5682. https://doi.org/10.1109/tvt.2020.2980905
[22] Haghshenas, M., Ramezani, P., Magarini, M., Björnson, E. (2024). Parametric channel estimation with short pilots in RIS-assisted near- and far-field communications. IEEE Transactions on Wireless Communications, 23(8): 10366-10382. https://doi.org/10.1109/twc.2024.3371715
[23] Nie, X., Zhao, F. (2021). Pilot allocation and power optimization of massive MIMO cellular networks with underlaid D2D communications. IEEE Internet of Things Journal, 8(20): 15317-15333. https://doi.org/10.1109/jiot.2021.3061510
[24] Zhi, H., Ding, X. (2019). Pilot allocation scheme based on coalition game for TDD massive MIMO systems. EURASIP Journal on Wireless Communications and Networking, 2019(1): 60. https://doi.org/10.1186/s13638-019-1372-x