Christine Dewi![]() | Hanna Prillysca Chernovita
| Hanna Prillysca Chernovita![]() | Stephen Abednego Philemon
| Stephen Abednego Philemon![]() | Christian Adi Ananta
| Christian Adi Ananta![]() | Guowei Dai
| Guowei Dai![]() | Abbott Po Shun Chen*
| Abbott Po Shun Chen*![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The rapid development and use of artificial intelligence in various industries in recent years have markedly improved transportation systems. Automobile collisions can lead to numerous fatalities and significant financial losses. Automated vehicles can employ road detection as one of their functionalities. Notwithstanding the appalling nature of traffic accidents, numerous nations are employing artificial intelligence to create smart cities and autonomous vehicles. This research concentrates on traffic sign detection at night, building upon significant studies conducted by numerous researchers utilizing public road sign data sets. This dataset is essential for training autonomous vehicles to recognize traffic signs in low-light conditions. Nighttime object detection has numerous problems and is not less difficult than daytime detection. This research employs the YOLOv9 algorithm, a state-of-the-art, one-stage object detection model known for its speed and accuracy in identifying traffic signs during nighttime. The Contrast Limited Adaptive Histogram Equalization (CLAHE) method is evaluated and compared with nocturnal road sign detection. This study integrates YOLOv9 and CLAHE to provide an ideal model for enhancing nighttime road sign recognition efficiency. Our results indicate that the combination of YOLOv9 and CLAHE achieves the highest mean Average Precision (mAP) of 76.2%. The suggested model exhibits potential for incorporation into autonomous vehicle systems, facilitating real-time identification of road objects, pedestrians, and other vehicles, hence enhancing safety and navigation.
Contrast Limited Adaptive Histogram Equalization, Convolutional Neural Network, deep learning, YOLOv9, nighttime detection, autonomous vehicles
Single Shot Detection (SSD) is an object detection methodology that identifies many objects inside a single image or video processing instance. This technique differs from previous methods that necessitate multi-stage picture processing. SSD employs a Convolutional Neural Network (CNN) to extract characteristics from images, subsequently utilizing several convolutions to generate a collection of bounding boxes accompanied by confidence values for various item classes.
Traditional nighttime object recognition methods, like Histogram of Oriented Gradient (HOG) and Support Vector Machine (SVM), exhibit computational efficiency but lack resilience in intricate environments. Recent deep learning methodologies, such as Faster R-CNN and YOLO variations, provide enhanced accuracy; nonetheless, they frequently encounter challenges with elevated noise levels and diminished contrast characteristics of nighttime images.
YOLOv9 represents a recent advancement in the YOLO line of models, renowned in the field of object identification [1, 2]. YOLOv9 upholds the legacy of YOLO by delivering exceptionally rapid detection speeds and a high degree of accuracy. YOLOv9 presumably employs more efficient and resilient neural network architecture. This may involve employing more advanced backbones for feature extraction and incorporating cutting-edge technology in machine learning, such as transformers or improved CNNs. Detecting road markers is the foundation upon which autonomous driving and computer vision are built. The objective of these responsibilities is to recognize and adhere to road markers, including lane lines, and to traverse real-time stop lines as they shift positions instantaneously. The use of onboard sensors and computers accomplishes this [3].
The identification of road signs at night is crucial for ensuring safety and efficiency on the road. The following are key reasons for the significance of road sign detection during nighttime: Driver and Passenger Safety: At night, natural sight is markedly diminished, rendering traffic signs less discernible for drivers. Accurate and clear identification of these signals enables drivers to make suitable and safe judgments when operating a vehicle, therefore diminishing the likelihood of accidents. Adhere to road sign Regulations: Road signs convey essential information concerning speed limits, limitations, and additional directives. Effective nighttime detection will enhance driver compliance with traffic regulations, consequently decreasing violations and improving traffic order. Mitigates Driver Fatigue: Nighttime driving can be more exhausting as the eyes exert greater effort to perceive signs and the roadway. A proficient traffic sign-detecting system can alleviate this load by delivering explicit warnings and information to motorists. Support for Autonomous Vehicle Technology: Autonomous cars depend on precise detection systems to identify traffic signs and other roadway components. Accurate nighttime detection is essential for the safe and reliable operation of autonomous vehicles without human oversight. Enhanced Advanced Driver Assistance Systems (ADAS) technology: Advanced driver assistance systems, such as traffic sign recognition, utilize detection technologies to aid drivers by delivering real-time information regarding road conditions and traffic signage. Enhanced nocturnal detection augments the efficacy of this ADAS system [4, 5].
Driving at night presents considerable hazards to road safety owing to diminished visibility, glare from artificial illumination, and heightened dependence on driver perception. The World Health Organization (WHO) reports that road traffic injuries are a predominant source of global mortality, with nocturnal incidents contributing significantly to the death toll. Approximately 1.19 million individuals perish annually due to road traffic collisions. Road traffic injuries constitute the primary cause of mortality among children and young adults aged 5 to 29 years [6].
The hazards of nocturnal driving are exacerbated by inadequate illumination, which hinders the prompt recognition of pedestrians, bicycles, and other vehicles. This is especially crucial in low-resource environments and rural regions, where the infrastructure for sufficient street lighting is frequently deficient. Tackling this issue is crucial for enhancing driver safety and for the progression of technologies such as autonomous vehicles and intelligent transportation systems that depend on precise and reliable object detection algorithms.
Current object detection frameworks, although proficient in well-lit settings, frequently encounter difficulties in low-light scenarios due to issues like low contrast, glare, and inconsistent lighting. This paper introduces an innovative amalgamation of CLAHE with the YOLOv9 detection framework to mitigate these constraints. The objective is to augment object visibility and enhance detection precision in difficult nocturnal settings, consequently fostering safer roadways and more intelligent urban systems. CLAHE is an image processing approach employed to enhance image contrast in a more adaptive and regulated manner than conventional histogram equalization methods [7]. CLAHE is crucial in data preparation due to its capacity to enhance image quality, hence augmenting the efficacy of numerous computer vision and image processing applications [8]. CLAHE is proficient at enhancing visual contrast, particularly in photos characterized by low contrast or extreme brightness or darkness. Enhancing contrast facilitates the recognition and analysis of significant components within a picture. This research will detect road signs, especially at night, using the SSD model, namely YOLOv9 combined with CLAHE. This research can have a significant impact on researchers in the same field.
The suggested YOLOv9 framework utilizes CLAHE to improve image quality, guaranteeing strong performance in low-light environments. This combination rectifies the deficiencies of previous approaches by sustaining elevated detection accuracy while attaining real-time processing velocities. Our method establishes a new standard for nighttime object detection by combining state-of-the-art detection algorithms with advanced preprocessing techniques. This has implications for applications in surveillance systems and autonomous vehicles.
The following section is a succinct summary of the study's principal contributions: This study gathers videos of real drivers maneuvering autos. This creates the Taiwan Road Marking Sign Dataset at Night (TRMSDN), encompassing road markings. (2) A variety of YOLO models are evaluated to ascertain which one is the most effective in identifying Taiwan's road signs. (3) The study analyzes and contrasts the differences among these three methods, examining the impact of CLAHE on photos acquired in nighttime driving conditions. (4) The identification algorithm that was developed in this work is currently being implemented in a variety of YOLOv9c versions to assess its ability to accurately identify road markings in Taiwan. (5) Experiments indicate that CLAHE has the potential to improve the efficacy of all models.
The subsequent sections will delineate the development of this work. In Section II, we examine some comparable works. Our proposed methodology is comprehensively explained in Section III. Section IV delineates the methodology and outcomes. Our findings are thoroughly examined and discussed in Section V. In Section VI, we report our results and propose possible directions for future research.
2.1 Road marking sign identification
The identification of road signs is an essential component of both the management of road safety and the automotive insurance contracting process. The process entails the detection and analysis of traffic signs to supply motorists with vital information regarding routes, directions, and warnings. An example of a system that has been put into place to guarantee the safety of drivers is the Road Safety Audit guideline [9]. The process of detecting and recognizing the many sorts of markings that are painted on roadways to communicate information, enforce laws, or provide direction to vehicles and pedestrians is referred to as road marking sign identification.
Tai et al. [10] utilized techniques such as DCGAN, LSGAN, and WGAN in their research project to produce high-fidelity images of prohibited traffic signs. The improvement of the intersection over union (IoU) and the performance of road sign detection are both essential components of road safety management and automotive insurance contracting. The process involves recognizing and evaluating traffic signs to provide motorists with vital information on routes, directions, and warnings. Road Safety Audit guidelines employ YOLOv3 and YOLOv4 models that make use of synthetic photographs to ensure road safety.
Chen et al. [11] used the YOLO model to identify road signs in Taiwan. They compared the original image captured at night with Contrast Stretching (CS), Histogram Equalization (HE), and CLAHE techniques in a nighttime setting. Shahbaz et al. [12] aimed to assess the efficacy of the image processing technique in identifying road signs and to determine the most suitable threshold value range for this purpose. They evaluated the cascade object detector's ability to detect road signs in relation to threshold values and speed. Mijic et al. [13] proposed a solution for vehicle control using detected traffic signs. They investigated the feasibility of employing cutting-edge machine learning algorithms, specifically YOLOv3 and YOLOv4, for traffic sign detection. The vehicle control solution is designed using the Robot Operating System (ROS) and thoroughly evaluated in the CARLA open-source simulator. Traffic sign (TS) detectors are assessed using both real-world and synthetic datasets, followed by testing the suggested solution across various scenarios generated in the CARLA simulator under diverse weather conditions (sunny, wet, foggy, night).
2.2 Contrast Limited Adaptive Histogram Equalization
A technique employed in image processing to enhance the contrast of an image and mitigate noise amplification is known as image enhancement [14, 15]. Histogram Equalization is a method utilized to improve image contrast by reallocating intensity values. It functions by distributing the prevalent intensity values to comprehensively utilize the complete spectrum of intensity values.
Adaptive Histogram Equalization (AHE) is a technique that overcomes the constraints of conventional histogram equalization by accounting for the fluctuating illumination conditions inside an image. AHE processes distinct segments of the image independently, facilitating enhanced accuracy in image enhancement compared to conventional approaches. The image is segmented into smaller sections by AHE, and histogram equalization is executed on each region independently [16]. This approach mitigates excessive noise amplification but may lead to increased noise in reasonably uniform regions. Contrast Limitation: To address the issue of excessive noise amplification in AHE, CLAHE integrates a restriction on contrast [17]. The technique constrains the histogram of each region to ensure that no pixel intensity surpasses a designated threshold. This facilitates the modulation of noise amplification while concurrently improving contrast. Interpolation is commonly utilized in CLAHE to efficiently reduce abrupt transitions between neighboring areas, ensuring the lack of noticeable abnormalities at the boundaries of these areas [18]. CLAHE effectively enhances the contrast of images with varying lighting circumstances while minimizing the risk of noise amplification. It is commonly employed in medical image processing, satellite images, and other areas where picture contrast enhancement is critical [19].
2.3 YOLOv9
YOLOv9 represents the most recent advancement in the YOLO line of real-time object detection systems. It enhances prior iterations by integrating breakthroughs in deep learning methodologies and architectural design to attain greater efficacy in object-detecting tasks. The integration of the Generalized ELAN (GELAN) architecture with the Programmable Gradient Information (PGI) concept resulted in the development of YOLOv9, which represents a significant improvement in efficiency, speed, and accuracy.
The following are the key features of YOLOv9:
(1) Real-Time Object Detection: YOLOv9 preserves the defining characteristic of the YOLO series by offering real-time object detection capabilities. This refers to its ability to rapidly process input images or video streams and precisely identify objects within them without sacrificing speed [20, 21].
(2) PGI Integration: YOLOv9 implements the Programmable Gradient Information (PGI) concept, which enables the production of dependable gradients through an auxiliary reversible branch. This guarantees that deep features maintain essential characteristics that are essential for the execution of target tasks, thereby resolving the issue of information loss during the feedforward process in deep neural networks [22].
(3) Generalized ELAN (GELAN) Architecture: YOLOv9 employs the Generalized ELAN (GELAN) architecture, which is intended to enhance inference speed, accuracy, computational complexity, and parameters. GELAN improves the efficacy and adaptability of YOLOv9 by enabling users to choose the most suitable computational blocks for various inference devices [11].
(4) Enhanced Performance: Experimental results indicate that YOLOv9 achieves optimal performance in object detection tasks on benchmark datasets such as MS COCO [23, 24].
Single Shot Detection (SSD) frameworks, exemplified by YOLO, execute object detection by forecasting bounding boxes and class probabilities in a singular traversal of the network. This method obviates the necessity for region proposal phases included in two-stage detectors such as Faster R-CNN, markedly diminishing computer complexity and facilitating real-time processing. In applications such as autonomous vehicles and surveillance, where judgments must be made quickly, the performance advantage of SSD-based models is essential. Moreover, SSD frameworks demonstrate superior capabilities in identifying objects of diverse scales, which is especially advantageous in nocturnal conditions where the perceived size and contrast of objects can fluctuate due to uneven illumination.
YOLOv9 signifies the most recent progress in the YOLO series of one-stage object detectors, providing an unparalleled amalgamation of speed, precision, and resilience compared to earlier iterations. These characteristics render YOLOv9 an advantageous option for tackling the difficulties of nocturnal object detection, especially in scenarios with constrained processing resources.
Nighttime object detection poses distinct obstacles, including low contrast, glare, and inconsistent illumination. To mitigate these difficulties, CLAHE was incorporated as a preprocessing measure. Preprocessing input photos with CLAHE markedly improves object visibility, allowing YOLOv9 to extract substantial features even in difficult nighttime settings.
The integration of CLAHE with YOLOv9 in the SSD framework establishes a strong and effective pipeline for nocturnal object detection. CLAHE optimally enhances input images, enabling YOLOv9 to accomplish accurate and swift detection. This novel integration of technologies establishes a new standard for nocturnal object detection, with considerable ramifications for practical applications in driverless vehicles, surveillance systems, and other safety-sensitive areas.
3.1 Taiwan road marking sign dataset at night
Additionally, we executed our experiment using genuine traffic signs located on conventional highways in Taiwan. The signs included indicators for vehicle turning directions, speed limits, pedestrian crossings, and stop lines. Upon recognizing these signals, vehicles should either adjust their behavior or have their movement restricted. This research sought to tackle the challenge of road sign recognition by recording video footage from the driver's viewpoint in various Taiwanese cities and manually collecting traffic signs to develop a distinctive dataset called the TRMSDN dataset [11]. A total of 4,386 distinct photos were collected for training purposes. The photos were classified into 15 distinct categories, with 80% designated for the training set and 20% for the testing set. A 512 by 288-pixel image is utilized.
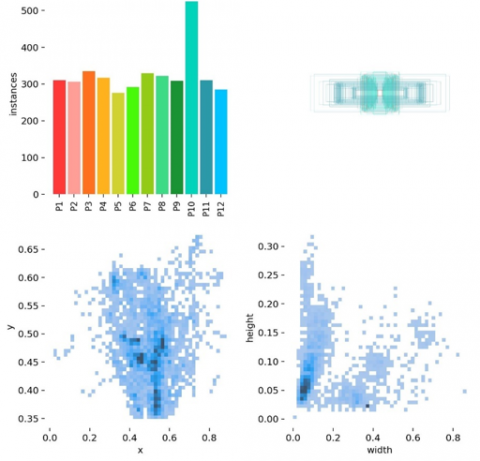
Table 1 and Figure 1 exhibit the training and testing labels for each category of road marking sign, respectively. The document has both categories of labels. The TRMSDN dataset indicates an average of 399 to 409 occurrences per class. Access the following URL: https://drive.google.com/drive/folders/1e5xbkuqnN2EeoCleV9JQ3zOTOB8F_YU1?usp=sharing.
Table 1. TRMSDN dataset
|
Class |
Name |
Training |
Testing |
Total Image |
|
P1 |
Turn Right |
277 |
69 |
405 |
|
P2 |
Turn Left |
301 |
75 |
401 |
|
P3 |
Go Straight |
283 |
71 |
407 |
|
P4 |
Turn Right or Go Straight |
307 |
77 |
409 |
|
P5 |
Turn Left or Go Straight |
272 |
68 |
403 |
|
P6 |
Speed Limit (60) |
276 |
69 |
400 |
|
P7 |
Zebra Crossing (Crosswalk) |
327 |
82 |
401 |
|
P8 |
Slow Sign |
275 |
69 |
399 |
|
P9 |
Overtaking Prohibited |
310 |
77 |
404 |
|
P10 |
Barrier Line |
295 |
74 |
409 |
|
P11 |
Cross Hatch |
302 |
76 |
398 |
|
P12 |
Stop Line |
283 |
71 |
403 |
|
|
Total |
3509 |
877 |
4386 |
Figure 1. TRMSDN dataset instances
3.2 Experiment setting
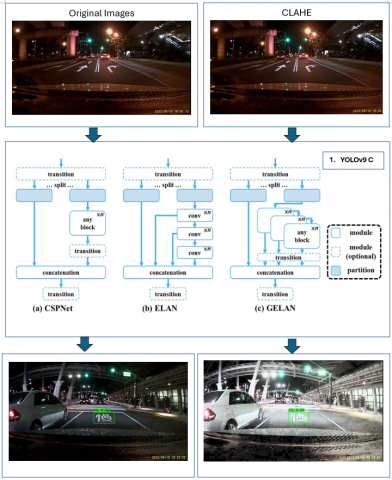
In this experiment, we classify our dataset into two categories: Dataset 1 and Dataset 2. Dataset 1 consists of the unaltered image without any image enhancement methods applied. Dataset 2 is the conclusive set, comprising the CLAHE-enhanced original image. Figure 2 exhibits an example of the image enhancement method with (a) the original image and (b) CLAHE. Moreover, Figure 3 shows our research workflow. Our works will implement YOLOv9c to train and test our Dataset 1 and Dataset 2. YOLOv9 seeks to mitigate information bottlenecks with an auxiliary supervision architecture termed Programmable Gradient Information (PGI). PGI is primarily intended as a training aid to enhance the efficiency and accuracy of gradient backpropagation through connections to preceding layers, utilizing a detachable branch that allows for the elimination of these supplementary computations during inference, hence optimizing model compactness and inference speed. To enhance these interconnections, it employs multi-level auxiliary information with integration networks that aggregate gradients from various convolutional stages to combine significant gradients for propagation.
Figure 2. Example of the image enhancement methods with (a) Original image, and (b) CLAHE image
Figure 3. Research workflow
3.3 Training result
Table 2 shows the training result in the TRMSDN dataset with YOLOv9c. Among the datasets, Dataset 1 has an average accuracy of 74.5 percent, while Dataset 2 demonstrates the best accuracy of 76.6 percent. The CLAHE algorithm in Dataset 2 earns the highest score and has the potential to increase the mAP performance by 2.1% when compared to the original images included in Dataset 1.
Table 2. Training result in TRMSDN dataset with YOLOv9c
|
Class |
Images |
Instances |
Original (Dataset 1) |
CLAHE (Dataset 2) |
||||
|
P |
R |
mAP50 |
P |
R |
mAP50 |
|||
|
P1 |
877 |
78 |
0.39 |
0.91 |
0.52 |
0.403 |
0.91 |
0.567 |
|
P2 |
877 |
76 |
0.463 |
0.803 |
0.61 |
0.468 |
0.868 |
0.556 |
|
P3 |
877 |
85 |
0.687 |
0.929 |
0.835 |
0.654 |
0.882 |
0.797 |
|
P4 |
877 |
80 |
0.594 |
0.84 |
0.834 |
0.596 |
0.863 |
0.838 |
|
P5 |
877 |
69 |
0.627 |
0.928 |
0.833 |
0.671 |
0.913 |
0.851 |
|
P6 |
877 |
73 |
0.968 |
0.959 |
0.988 |
0.972 |
0.958 |
0.988 |
|
P7 |
877 |
82 |
0.478 |
0.635 |
0.587 |
0.543 |
0.768 |
0.617 |
|
P8 |
877 |
78 |
0.909 |
0.974 |
0.989 |
0.864 |
0.987 |
0.987 |
|
P9 |
877 |
79 |
0.834 |
0.937 |
0.972 |
0.914 |
0.949 |
0.984 |
|
P10 |
877 |
128 |
0.638 |
0.207 |
0.411 |
0.629 |
0.25 |
0.393 |
|
P11 |
877 |
78 |
0.729 |
0.949 |
0.834 |
0.729 |
0.949 |
0.829 |
|
P12 |
877 |
71 |
0.515 |
0.873 |
0.573 |
0.42 |
0.845 |
0.589 |
|
All |
877 |
977 |
0.653 |
0.829 |
0.745 |
0.655 |
0.845 |
0.76 |
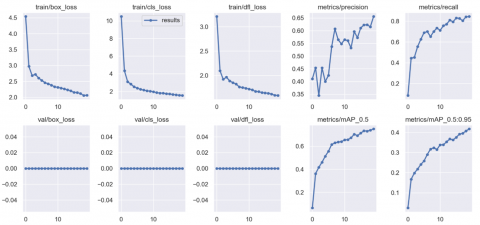
Furthermore, Figure 4 explains the training process of YOLOv9c with CLAHE (Dataset 2). The results of the training for each category are presented in a manner that is proportional to the number of times the neural network repeated the training process. Following more than thirty cycles of training, the various loss functions started to decrease, which was an indication that the training of the network's parameters had reached a point of convergence. All the loss functions moved in the same direction and eventually decreased, which is an indication that the parameters of the network were trained appropriately.
Figure 4. Training process YOLOv9c with CLAHE dataset
YOLOv9 is a substantial advancement in real-time object identification, delivering significant advantages in terms of efficiency, accuracy, and adaptability. It is a vital development in the field. YOLOv9 establishes a new standard for research and application that will be conducted in the sector in the future by tackling crucial difficulties using innovative technologies such as PGI and GELAN. Considering the ongoing development of the artificial intelligence community, YOLOv9 serves as a powerful illustration of the role that collaboration and creativity play in propelling technological advancement. YOLOv9c experiment during validation batch 0 with CLAHE Dataset 2 is shown in Figure 5. In our experiment, we just implemented the default configuration with YOLOv9 data augmentation approach. The performance and robustness of YOLO models can be significantly enhanced by incorporating a variety of augmentation methods, including HSV augmentation, image angle/degree, translation, perspective transform, image scale, flip up-down, and flip left-right, as well as more advanced techniques like Mosaic, CutMix, and MixUp.
Figure 5. Validation batch 0 with YOLOv9c and CLAHE dataset
The Intersection over Union (IoU) quantifies the overlap ratio between the predicted bounding box (pred) and ground truth (gt), as shown in Eq. (1) [25, 26].
$I o U=\frac{\text {Area}_{\text {pred}} \cap \text {Area}_{\text {gt}}}{\text {Area}_{\text {pred}} \cup \text {Area}_{\text {gt}}}$ (1)
However, the output examples can be categorized into three kinds. True positive (TP) refers to accurately identified samples, false positive (FP) indicates samples that were incorrectly identified, and true negative (TN) represents samples that were not recognized. Precision and Recall are represented by Yuan et al. [27] in Eqs. (2)-(3).
${Precision} (P)=\frac{T P}{T P+F P}$ (2)
${Recall}(R)=\frac{T P}{T P+F N}$ (3)
Another evaluation index, F1 [28], is shown in Eq. (4).
$F 1=\frac{2 \times{Precision} \times {Recall}}{{Precision}+ {Recall}}$ (4)
Yolo loss function based on Eq. (5) [28].
$\begin{gathered}\lambda_{\text {coord }} \sum_{i=0}^{s^2} \sum_{j=0}^B l_{i j}^{o b j}\left[\left(x_i-\hat{x}_i\right)^2+\left(y-\hat{y}_i\right)^2\right] \\ +\lambda_{\text {coord }} \sum_{i=0}^{s^2} \sum_{j=0}^B l_{i j}^{o b j}\left[\left(\sqrt{w_i}-\sqrt{\widehat{w}_i}\right)^2+\left(\sqrt{h_i}-\sqrt{\widehat{h}_i}\right)^2\right] \\ +\sum_{i=0}^{s^2} \sum_{j=0}^B l_{i j}^{o b j}\left(C_i-\hat{C}_i\right)^2+\lambda_{\text {noob } j} \sum_{i=0}^{s^2} \sum_{j=0}^B l_{i j}^{n o o b j}\left(C_i-\hat{C}_i\right)^2 \\ +\sum_{i=0}^{s^2} l_i^{o b j} \sum_{c \epsilon c l a s s e s}\left(p_i(c)-\hat{p}_i(c)\right)^2\end{gathered}$ (5)
where, $l_{i j}^{o b j}$ denotes if the object appears in cell i, and $l_{i j}^{o b j}$ notes that the $j^{t h}$ bounding box predictor in cell i is responsible for the prediction. Next, $(\hat{x}, \hat{y}, \widehat{w}, \hat{h}, \hat{c}, \widehat{\text { and } p})$ are represented as the predicted bounding box's center coordinates, width, height, confidence, and category probability. The symbols lacking the cusp represent authentic labeling. Furthermore, our research has determined the λcoordvalue to be 0.5, indicating that the errors in width and height are less significant in calculations. A λnoobjvalue of 0.5 is implemented to mitigate the influence of several grids devoid of objects on the loss value.
Table 3 displays the results of the testing that was performed on the TRMSDN dataset using YOLOv9c. The testing phase yields a mean absolute performance (mAP) of 74.9% for Original Dataset 1, while CLAHE Dataset 2 achieved a mAP of 76.2 %. Considering the findings of the training and testing, we can conclude that CLAHE has the potential to enhance the performance result of YOLOv9c.
In addition, the recognition result of YOLOv9c with both datasets is displayed in Figure 6. When compared to the original datasets, YOLOv9c with the CLAHE dataset performs exceptionally well. It can be shown in Figure 6(e) that YOLOv9c was unable to identify two of the objects in the images using Dataset 1.
The image enhancement approach, known as CLAHE, is quite common and offers several advantages, including the following: (1) Improved Contrast: CLAHE improves the contrast of an image, which makes it simpler to perceive features that may have been difficult to distinguish in the original image. (2) Enhancement of Local Contrast: CLAHE can maintain local details since it enhances the contrast of an image in specific locations rather than on a global scale. (3) No Over-enhancement: In contrast to conventional histogram equalization, CLAHE employs a limiting function to prevent the image from being over-enhanced, which can lead to the appearance of artifacts and noise. (4) Modifiable Parameters: CLAHE provides some parameters that can be modified to fine-tune the enhancement for a specific image. These parameters include the block size and the clip limit, among others. (5) CLAHE is a well-established method that is extensively used in a variety of applications.
Table 3. Testing result in TRMSDN dataset with YOLOv9c
|
Class |
Images |
Instances |
Original Dataset |
CLAHE Dataset |
||||
|
P |
R |
mAP50 |
P |
R |
mAP50 |
|||
|
P1 |
877 |
78 |
0.39 |
0.91 |
0.52 |
0.403 |
0.91 |
0.568 |
|
P2 |
877 |
76 |
0.463 |
0.803 |
0.611 |
0.468 |
0.868 |
0.556 |
|
P3 |
877 |
85 |
0.687 |
0.929 |
0.834 |
0.654 |
0.882 |
0.797 |
|
P4 |
877 |
80 |
0.594 |
0.84 |
0.834 |
0.596 |
0.863 |
0.838 |
|
P5 |
877 |
69 |
0.627 |
0.928 |
0.833 |
0.671 |
0.913 |
0.851 |
|
P6 |
877 |
73 |
0.968 |
0.959 |
0.988 |
0.972 |
0.958 |
0.988 |
|
P7 |
877 |
82 |
0.478 |
0.636 |
0.586 |
0.543 |
0.768 |
0.619 |
|
P8 |
877 |
78 |
0.909 |
0.974 |
0.989 |
0.864 |
0.987 |
0.987 |
|
P9 |
877 |
79 |
0.834 |
0.937 |
0.972 |
0.914 |
0.949 |
0.984 |
|
P10 |
877 |
128 |
0.638 |
0.207 |
0.411 |
0.629 |
0.25 |
0.394 |
|
P11 |
877 |
78 |
0.729 |
0.949 |
0.836 |
0.729 |
0.949 |
0.829 |
|
P12 |
877 |
71 |
0.515 |
0.873 |
0.573 |
0.42 |
0.845 |
0.591 |
|
All |
877 |
977 |
0.653 |
0.829 |
0.749 |
0.655 |
0.845 |
0.762 |
Figure 6. Recognition result with YOLOv9c
The primary focus of this research is to examine the ways in which image enhancement methods can enhance the performance of the original image. Using techniques such as CLAHE, our study blends the original image with other image-enhancing techniques. To train, we use a variety of images, both in terms of quantity and size. As part of our research, we study and investigate CNN models that have been integrated with a variety of backbone architectures and extractor features, notably YOLOv9c, for the purpose of identification of road markings during the night.
Additionally, we derived the subsequent findings from our experiments: Experimentally, Dataset 2, which consists of the original image augmented by CLAHE, is the most effective dataset. This study endorses the utilization of CLAHE's YOLOv9c as the superior model, with a mean Average Precision (mAP) of 76%. Augmenting the noise during training will prolong the training duration and diminish the frequency of general errors. Consequently, enhancing item recognition efficacy can be achieved by integrating the dataset with CLAHE images and the original photographs. The results of this study have significant significance for practical applications, including autonomous vehicles, which indicates the improved detection capabilities of the suggested framework can boost the reliability of autonomous driving systems, especially in nocturnal conditions, hence mitigating accident risks and assuring safer navigation.
In the future, one of our objectives is to enhance the dataset that we have in Taiwan, namely by collecting data in a wider range of circumstances than merely at night. Because we want to emphasize the advantages of image enhancement, we are going to analyze it in comparison to other standards for road marking signs. Future work will involve extending the dataset to include diverse nighttime conditions and urban environments across different regions, starting with additional data collection in Taiwan. This expansion will enable the model to generalize better across varied scenarios.
This paper is supported by the National Science and Technology Council, Taiwan (Grant No.: NSTC-111-2637-H-324-001). This research is partially supported by the Vice-Rector of Research, Innovation, and Entrepreneurship at Satya Wacana Christian University.
[1] Hasegawa, R., Iwamoto, Y., Chen, Y.W. (2019). Robust detection and recognition of Japanese traffic sign in the complex scenes based on deep learning. In 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 2019, pp. 575-578. https://doi.org/10.1109/GCCE46687.2019.9015419
[2] Jintasuttisak, T., Edirisinghe, E., Elbattay, A. (2022). Deep neural network based date palm tree detection in drone imagery. Computers and Electronics in Agriculture, 192: 106560. https://doi.org/10.1016/j.compag.2021.106560
[3] Garach Morcillo, L., Calvo Poyo, F.J., Oña López, J.J.D. (2022). The effect of widening longitudinal road markings on driving speed perception. Transportation Research Part F: Traffic Psychology and Behaviour, 88: 141-154. https://doi.org/10.1016/j.trf.2022.05.021
[4] Muhammad, K., Ullah, A., Lloret, J., Del Ser, J., de Albuquerque, V.H.C. (2020). Deep learning for safe autonomous driving: Current challenges and future directions. IEEE Transactions on Intelligent Transportation Systems, 22(7): 4316-4336. https://doi.org/10.1109/TITS.2020.3032227
[5] Campbell, A., Both, A., Sun, Q.C. (2019). Detecting and mapping traffic signs from Google Street View images using deep learning and GIS. Computers, Environment and Urban Systems, 77: 101350. https://doi.org/10.1016/j.compenvurbsys.2019.101350
[6] WHO. (2023). Road traffic injuries. https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries#:~:text=Approximately%201.19%20million%20people%20die,adults%20aged%205%E2%80%9329%20years.
[7] Aulia, S., Rahmat, D. (2022). Brain tumor identification based on VGG-16 architecture and CLAHE method. JOIV: International Journal on Informatics Visualization, 6(1): 96-102. https://doi.org/10.30630/joiv.6.1.864
[8] Han, Y., Chen, X., Zhong, Y., Huang, Y., et al. (2023). Low-illumination road image enhancement by fusing retinex theory and histogram equalization. Electronics, 12(4): 990. https://doi.org/10.3390/electronics12040990
[9] Mansor, S.A., Saman, M.A., Razman, T.T., Masnel, H. (2019). Road safety audit–what we have learnt? IOP Conference Series: Materials Science and Engineering, 512: 012023. https://doi.org/10.1088/1757-899X/512/1/012023
[10] Tai, S.K., Dewi, C., Chen, R.C., Liu, Y.T., Jiang, X., Yu, H. (2020). Deep learning for traffic sign recognition based on spatial pyramid pooling with scale analysis. Applied Sciences, 10(19): 6997. https://doi.org/10.3390/app10196997
[11] Chen, R.C., Dewi, C., Zhuang, Y.C., Chen, J.K. (2023). Contrast limited adaptive histogram equalization for recognizing road marking at night based on YOLO models. IEEE Access, 11: 92926-92942. https://doi.org/10.1109/ACCESS.2023.3309410
[12] Shahbaz, S.J., Al-Zuky, A.A., Al-Obaidi, F.E. (2023). Real-night-time road sign detection by the use of cascade object detector. Iraqi Journal of Science, 64(6): 3164-3175. https://doi.org/10.24996/ijs.2023.64.6.43
[13] Mijic, D., Vranjes, M., Grbic, R., Jelic, B. (2021). Autonomous driving solution based on traffic sign detection. IEEE Consumer Electronics Magazine, 12(5): 39-44. https://doi.org/10.1109/MCE.2021.3090950
[14] Chakraverti, S., Agarwal, P., Pattanayak, H.S., Chauhan, S.P.S., Chakraverti, A.K., Kumar, M. (2024). De-noising the image using DBST-LCM-CLAHE: A deep learning approach. Multimedia Tools and Applications, 83(4): 11017-11042. https://doi.org/10.1007/s11042-023-16016-2
[15] Asghar, S., Gilanie, G., Saddique, M., Ullah, H., Mohamed, H.G., Abbasi, I.A., Abbas, M. (2023). Water classification using convolutional neural network. IEEE Access, 11: 78601-78612. https://doi.org/10.1109/ACCESS.2023.3298061
[16] Kamal, K., Hamid, E.Z. (2023). A comparison between the VGG16, VGG19 and ResNet50 architecture frameworks for classification of normal and CLAHE processed medical images. Research Square. https://doi.org/10.21203/rs.3.rs-2863523/v1
[17] Alwakid, G., Gouda, W., Humayun, M. (2023). Deep learning-based prediction of diabetic retinopathy using CLAHE and ESRGAN for enhancement. Healthcare, 11(6): 863. https://doi.org/10.3390/healthcare11060863
[18] Islam, M.R., Nahiduzzaman, M. (2022). Complex features extraction with deep learning model for the detection of COVID19 from CT scan images using ensemble based machine learning approach. Expert Systems with Applications, 195: 116554. https://doi.org/10.1016/j.eswa.2022.116554
[19] Dewi, C., Chen, R.C., Liu, Y.T., Tai, S.K. (2022). Synthetic Data generation using DCGAN for improved traffic sign recognition. Neural Computing and Applications, 34(24): 21465-21480. https://doi.org/10.1007/s00521-021-05982-z
[20] Dewi, C., Chen, R.C., Yu, H., Jiang, X. (2023). Robust detection method for improving small traffic sign recognition based on spatial pyramid pooling. Journal of Ambient Intelligence and Humanized Computing, 14(7): 8135-8152. https://doi.org/10.1007/s12652-021-03584-0
[21] Wang, C.Y., Yeh, I.H., Mark Liao, H.Y. (2025). YOLOv9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision, Milan, Italy, pp. 1-21. https://doi.org/10.1007/978-3-031-72751-1_1
[22] Yue, X., Qi, K., Na, X., Zhang, Y., Liu, Y., Liu, C. (2023). Improved YOLOv8-Seg network for instance segmentation of healthy and diseased tomato plants in the growth stage. Agriculture, 13(8): 1643. https://doi.org/10.3390/agriculture13081643
[23] Li, C., Xu, A., Zhang, Q., Cai, Y. (2024). Steel surface defect detection method based on improved YOLOx. IEEE Access, 12: 37643-37652. https://doi.org/10.1109/ACCESS.2024.3374869
[24] Ma, N., Su, Y., Yang, L., Li, Z., Yan, H. (2024). Wheat seed detection and counting method based on improved YOLOv8 model. Sensors, 24(5): 1654. https://doi.org/10.3390/s24051654
[25] Arcos-García, Á., Alvarez-Garcia, J.A., Soria-Morillo, L.M. (2018). Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing, 316: 332-344. https://doi.org/10.1016/j.neucom.2018.08.009
[26] Yang, H., Chen, L., Chen, M., Ma, Z., Deng, F., Li, M., Li, X. (2019). Tender tea shoots recognition and positioning for picking robot using improved YOLO-V3 model. IEEE Access, 7: 180998-181011. https://doi.org/10.1109/ACCESS.2019.2958614
[27] Yuan, Y., Xiong, Z., Wang, Q. (2016). An incremental framework for video-based traffic sign detection, tracking, and recognition. IEEE Transactions on Intelligent Transportation Systems, 18(7): 1918-1929. https://doi.org/10.1109/TITS.2016.2614548
[28] Redmon, J., Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767. https://doi.org/10.48550/arXiv.1804.02767