Imane Moustati*![]() | Noreddine Gherabi
| Noreddine Gherabi![]() | Mostafa Saadi
| Mostafa Saadi![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Accurate energy consumption forecasting is essential in the decision-making process, and in optimizing energy production and distribution to meet customers’ demands, especially given the fluctuating demand. The widespread deployment of smart meters has revolutionized the collection of time-series data on energy consumption, providing detailed insights into usage patterns at a granular level. This paper presents a comprehensive comparison of eight time-series forecasting models: Autoregressive Integrated Moving Average (ARIMA) and Seasonal ARIMA (SARIMA), Decision Trees (DT), K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Artificial Neural Networks (ANN), Convolutional Neural Networks (CNN), and Long Short-Term Memory networks (LSTM) to assess the most efficient model on the smart meters’ dataset. The models are evaluated using several statistical metrics, and based on the experimental results analysis, the LSTM model provided the best prediction performance with an RMSE of 2.106, a MAPE of 0.19, and a MAE of 1.599.
time-series forecasting models, smart meters, LSTM, energy consumption forecasting, models performance comparison
Energy consumption forecasting is a critical task in energy management and sustainability. With rising energy demand, electricity production must meet consumers' demand, and accurate prediction of energy consumption is essential for optimizing energy production and distribution. Therefore, based on consumer demand, which varies during peak hours, weekdays, weekends, and holidays, the power infrastructure must promptly adapt its power generation level to match consumers demands without experiencing any shortages or waste, especially since electricity cannot be easily stored [1]. On the other hand, the rapid advancements in technology and the increasing demand for efficient energy management have led to the widespread deployment of smart meters, with millions being deployed in houses. These smart meters generate a vast amount of time-series data on energy consumption, and revolutionized the way energy consumption data is collected, providing detailed information about energy usage patterns at a granular level (e. g, household level). Analyzing this data is crucial for optimizing energy usage, predicting future demand, and enhancing grid stability [2]. Energy consumption forecasting is crucial for the operational management of electrical grids. Power generation needs to align with demand in real-time to maintain grid stability, and over- or under-estimating energy demand are inadequacies in energy manipulation that can lead to wastage and unnecessary operational costs, or blackouts and brownouts. Renewable energy production often fluctuates due to weather conditions; therefore, reliable consumption forecasts allow grid operators to plan backup generation, ensuring consistent power delivery even during periods of low renewable output. It also plays an important role in helping households manage their energy usage more effectively. Automated systems use consumption forecasts to manage appliances, heating, and cooling for optimal energy usage, and provide consumers with insights into their energy consumption patterns to encourage energy-saving behaviors [3]. Furthermore, while more precise matching of supply and demand reduces reliance on inefficient and high-emission backup generators, governments and corporations can use forecasting data to design targeted energy efficiency programs, identifying high-consumption periods or sectors for improvement.
As a result, building models capable of assessing electric time-series from smart meters and effectively inferring and forecasting energy consumption is crucial [4, 5]. It implies proper scheduling of power facilities to ensure production is near real demands for given times, and thus benefiting technically and economically from both an operational and commercial standpoint. Indeed, regulatory agencies can penalize grid operators if their prediction significantly departs from what is actually needed and consumed. The Colombian Comisión de Regulación de Energía y Gas (CREG, https://creg.gov.co/) imposes fiscal penalties on energy suppliers with a prediction percent inaccuracy exceeding a specific threshold [6]. Therefore, multiple techniques seek to solve the energy consumption prediction problem. Traditional time-series forecasting models such as ARIMA (Autoregressive Integrated Moving Average) and SARIMA (Seasonal ARIMA) have been widely used for their simplicity and interpretability [5-10]. However, the advent of machine learning (ML) and deep learning (DL) has introduced more sophisticated models, including Support Vector Machines (SVM), Decision Trees (DT), k-Nearest Neighbors (KNN) [11-16], Artificial Neural Networks (ANN), Convolutional Neural Networks (CNN), and Long Short-Term Memory networks (LSTM) [5, 17-22]. This research paper aims to comprehensively compare these three categories’ models in the context of energy consumption forecasting. By leveraging the time-series data collected from smart meters, we evaluate each model’s performance using several statistical metrics to identify the most effective model. The comparison of these models is crucial for understanding the strengths and limitations of each approach and for selecting the most appropriate model for energy consumption forecasting applications. The results of this study will provide valuable insights into the performance of different models for energy consumption forecasting and help practitioners chose the most adequate one for their specific energy consumption forecasting applications.
The rest of this work is structured as follows: Section 2 reviews the relevant literature on energy consumption forecast models. Section 3 presents the dataset and the preprocessing steps and details the methodology, including model specifications and evaluation metrics. Section 4 shows the empirical results and analysis, and Section 5 concludes this paper with key findings and discusses future research directions.
The forecasting of energy consumption has been a topic of significant interest in the research community, with various modeling approaches being explored and compared. The state-of-the-art models fall into three categories: traditional statistical methods, modern DL techniques, and classic ML algorithms.
Time-series forecasting is a well-established field with numerous applications in various domains, including energy consumption forecasting. Conventional statistical models like ARIMA and SARIMA have widely been used for energy consumption forecasting thanks to their straightforwardness and ease of implementation. For example, the study [7] adopted ARIMA to forecast daily household load, and the study [23] for predicting peak electrical energy consumption. Others also utilized it as an approach to forecasting daily peaks and electrical load [8, 9, 24], to predict domestic, commercial, and industrial electricity demand in Ghana [25], forecast electricity consumption in Pakistan [10], forecast Turkish fuel primary energy demand [26], and predict energy consumption in China [11]. Similarly, SARIMA was applied to predict the demand for electricity in China [27], predict energy in Ghana [12], and forecast electric load time series [19, 28].
Recently, DL models have also been successfully applied to extract insights from time series data. The LSTM model has been used in time-series forecasting tasks including the energy consumption field by effectively capturing long-range dependences in the data. For instance, a study applied an LSTM model in forecasting short-term load for a grid operator in Columbia [6] while others used it to predict the periodic energy consumption [29], to foresee the production of broken horizontal wells in a volcanic reservoir [18], predict short-term electrical load [19], emphasize the value of spatiotemporal locality in spotting patterns, as well as sequentially assessing multi-attribute industrial data for future projections [20], and for accurately forecasting the output power of photovoltaic systems [30]. CNN models have been successfully employed with time-series data to forecast electrical energy consumption [21, 22, 31, 32], as well as in other fields when having to manipulate time-series datasets. This study applied a 1D CNN model to take in charge time-series data and forecast premature ventricular contraction in children [33], while others applied it to fields like finance and industry [33, 34]. On the other hand, academics have also applied ANN to successfully forecast time-series data. For instance, Chitsaz et al. [35], employed ANN in a short-term electricity load prediction scenario and Panapakidis and Dagoumas [36] used it to predict day-ahead price. Others have applied CNN to predict the Iranian renewable energy consumption [37], long-term energy consumption in Greek [38], short-term load conditions in future [39], the natural gas consumption [40], and electricity demand in Thailand [41].
Traditional ML models were also intensely studied and successfully used for energy consumption forecasting. SVM has been utilized by Kaytez et al [13]. to predict electricity in Turkey, Liu et al. [42] applied it to predict energy time-series data in office and campus buildings, and Fu et al. [43] employed it to infer the following-day electricity load of public buildings. The SVM has also been studied with time-series data in different domains [14]. Other academics have applied DT models to forecast time-series data. For example, Basu et al. [15] used it to predict appliance usage, and another study [44] utilized DT to build a system that considers sequential relationships to predict home appliance usage. On the other hand, the research community has also studied KNN for forecasting time-series data in this field. For instance, Troncoso Lora et al. [16] utilized a KNN model to forecast electric energy data for Spain. Lei et al. [17] used it to forecast the electrical day-to-day load data for a district in Chongqing, Brown et al. [45] suggested a KNN-based model for building energy modeling and detecting events in real-time, Al-Qahtani and Crone [46] employed a multivariate KNN model to predict the electricity demand in the UK per hour, and Lachut et al. [47] applied it to predict the power draw of appliances and home energy consumption in Arkansas.
The models discussed have shown promising results and performances in predicting time-series data in other domains other than the energy sector. They have been successfully used to predict seasonal item sales [48], Covid-19 [49], gold price [50], crude oil prices [51], surface water quality [52], air pollution [53] and for profit forecasting [54].
3.1 Dataset and data preprocessing
In this study, we have used the Electricity Customer Behaviour Trial dataset (ECBT) [55], which contains data collected from smart meters deployed in Ireland. The Commission for Energy Regulation (CER) in Ireland launched the Smart Metering Project, involving around 6,000 households and businesses in Ireland between 2009 and 2010. The dataset contains half-hourly electricity consumption data from thousands of households and businesses, providing high-resolution insights into energy usage patterns and allowing for comparing energy consumption across different types of users. This high resolution is crucial for analyzing patterns in electricity usage and developing accurate predictive models. It also spans over a year, covering various seasons, which allows for the examination of daily, weekly, and seasonal consumption variations. As the dataset reflects actual electricity consumption behavior, it allows for the empirical evaluation of models on real-world data, ensuring that the comparison results apply to practical scenarios. Samples of the energy usage of 6000-meter IDs were collected once per thirty minutes, seven days a week, for more than a year. The data is in KW and has been categorized into groups according to typical electrical habits. Rather than keeping it aggregated at the half-hourly level, the time series data is compiled on an hourly basis and cleaned, and the missing or null values are removed. Next, a min-max normalization into the [0, 1] interval is used to create input characteristics at comparable ranges, and the K-Means technique is then used to find groups with common power consumption habits. After clustering the data, the chosen models will be applied for forecasting, and insights will be drawn. The dataset was divided into 80% training and 20% test samples, with 10,272 observations for training the models and 2568 for testing them.
3.2 Methodology workflow
This study aims to empirically discover the best time-series forecasting model on the smart meter dataset. We chose the eight most popular and widely utilized time-series forecasting models and would like to know the most efficient one that will produce the finest results, in order to aid researchers in this field. The findings of this study will give significant insights into the efficacy of several models for energy consumption forecasting, assisting practitioners in selecting the most appropriate one for their unique energy consumption forecasting applications. The workflow of the proposed methodology is illustrated in Figure 1.
Figure 1. The workflow of the proposed methodology for energy consumption forecasting
3.3 The forecasting models
3.3.1 Autoregressive Integrated Moving Average (ARIMA)
ARIMA models are the most elementary, generic, and basic of the time-series prediction methods, and it is widely employed in the energy forecasting [24]. It is a generic Auto-Regressive Moving Average (ARMA) model that centers on changing time series to stationary via the differencing method. The ARIMA (p, d, q) model contains the model's key features: auto-regression (AR), integration (I) to keep time-series stable, and a moving average (MA), which accounts for the interconnections between the observed values and the residual errors [56]. Autoregression (AR) uses the dependency between an observation and lagged prior observations to make predictions. The integrated component (I) of the model (d) contains the terms that specify the degree of distinction to be performed on the time series. The moving average portion of the model (q) permits us to characterize our model's error as a linear mixture of anterior errors observed [23]. Eq. (1) [23] illustrates the ARIMA (p, d, q) model with L the polynomial lag.
$\left(1-\sum_{i=1}^p \varphi_i L^i\right)(1-L)^d=\left(1-\sum_{j=1}^q \theta_j L^i\right) \varepsilon_t$ (1)
3.3.2 Seasonal ARIMA (SARIMA)
SARIMA is a derivative of the ARIMA model that models univariate time series with seasonal factors. It is recommended for scenarios including patterns and seasonal changes in the time-series. SARIMA is expressed as ARIMA (p, d, q) (P, D, Q) s, with P indicates the seasonal auto-regressive order, D defines the seasonal difference order, Q represents the seasonal moving average order, and s specifies the yearly data points. SARIMA's seasonal parameters (P, D, Q, s) are similar to ARIMA's nonseasonal parameters, yet they include seasonal period backshifts.
3.3.3 Support Vector Machine (SVM)
The SVMs [57] are based on the notion of decision hyperplanes, which divide data to two distinct collections. Establishing this hyperplane aims to determine the maximum margin (distance) separating the two collections. Margin, introduced by Vapnik [58], is the greatest width of a plane parallel to the hyperplane that contains no interior data points. SVM may be used for more than just data classification. It can additionally develop regression models to find a function that diverges of the observed outputs for each set of input values by at most an error term. In nonlinear regression cases, the data is processed using a nonlinear kernel function, mapping inputs to a multidimensional feature space.
3.3.4 Decision Tree (DT)
DT [59], a potent and common classification and prediction method, is a ML approach that uses a tree model to generate judgments based on input data points. The Decision Tree separates the data recursively into tiny groupings of variables based on the characteristic that yields the most information. All internal nodes with a minimum of a single child node indicate the assessment of input variables. Decision trees are appealing because they express rules unlike neural networks or deep learning algorithms, and rules may be easily expressed so that humans comprehend them.
3.3.5 K-Nearest Neighbors (KNN)
KNN, a supervised ML model, is a widely used approach for pattern categorization and prediction based on individual similarity within a specified group. Members of a group are enclosed by others with comparable characteristics. This is the fundamental learning rule for KNN-based classification. It gives the classification to the nearest previously classified point for newly unclassified sample points. The KNN approach accounts the training set to be the model [60], and the essential parameters that define the KNN model are the chosen metric used to evaluate two time-series similarities and the number of neighbors.
3.3.6 Artificial Neural Networks (ANN)
ANNs are made of interconnected nodes, similar to neurons, that transfer signals between each other. The fundamental learning rule of ANNs is to reduce the gap and errors between the forecasted and the observed values by adjusting the weights of the connections between nodes. This is achieved through backpropagation, where the error is propagated backward through the network and the weights are updated accordingly.
3.3.7 Long Short-Term Memory (LSTM)
The LSTM [61] is a special architecture of Recurrent Neural Networks (RNNs) that can learn order-dependence in series estimation and can greatly serve in the settings of time-stamp, sequential, and long time-dependent data, avoiding the issues of vanishing and exploding gradient. In comparison with the conventional RNN, the LSTM appends three memory and gates to supervise the transformation of features. Thus, it is able of memorizing short-term and long-term information. The LSTM block is defined as in Eq. (2). Where $W$ and $b$ are weight matrices and vectors, $t$ indicates the current iteration of the RN, $\Gamma_u$ refers to the update gate, $\Gamma_f$ is the forget gate, $\Gamma_o$ symbolizes the output gate, $\hat{c}^{<t>}$ refers to the memory cell value, $c^{<t>}$ indicates the actual value of the memory cell, and $a^{<t>}$ is the output value or the hidden state.
$\begin{aligned} & \Gamma_u=\sigma\left(W_{u u} a^{<t-1>}+W_{u x} x^{<t>}+b_u\right) \\ & \Gamma_f=\sigma\left(W_{f f} a^{<t-1>}+W_{f x} x^{<t>}+b_f\right) \\ & \Gamma_o=\sigma\left(W_{o o} a^{<t-1>}+W_{o x} x^{<t>}+b_o\right) \\ & \hat{c}^{<t>}=\tanh \left(W_{c c} a^{<t-1>}+W_{c x} x^{<t>}+b_c\right) \\ & c^{<t>}=\Gamma_u \odot \hat{c}^{<t>}+\Gamma_f \odot c^{<t-1>} \\ & a^{<t>}=\Gamma_o \odot \tanh \left(c^{<t>}\right)\end{aligned}$ (2)
3.3.8 Convolutional Neural Network (CNN)
CNN is a widely used DL model because it can recognize relevant features without human supervision and because of its weight-sharing function strategy, which significantly decreases the parameters that can be trained on the network, thereby enhancing generalization and avoiding overfitting. When applied to time series data, CNN's convolutional and max-pooling layers enable the learning of filters that reflect recurring patterns in the series and their subsequent application in value forecasting [62]. CNNs were first intended to process reorganized 2D and 3D data with a topology akin to a grid, yet it can also successfully handle 1D data, such as time series load sequences. Additionally, the CNN-based model performs very well in solving real-time issues because of its ability to decrease training time and boost training efficiency due to its local connection and parameter-sharing features. CNN uses the back-propagation technique to solve the unidentified variables and maximize the network topology.
To assess the models’ performance on the dataset, we have calculated the MAPE, MASE, RMSE, MAE, and MSE metrics. Analogously to the other metrics, low values of the MAPE imply strong model performance as it quantifies the absolute deviation of the model's output series from the original series. Pao et al. [63] evaluated the MAPE findings to assess the precision of the prediction methods employed, concluding that a forecast that is less than 10% is highly precise, a prediction that is between 10% and 20% is favorable, a prediction between 20% and 50% is respectable, and a prediction that is more than 50% is inaccurate. The expressions to calculate these indicators are illustrated in Eq. (3).
$\begin{aligned} & \mathrm{MAPE}=\frac{1}{n} \sum_{i=1}^n\left|\frac{y_i-\hat{y}_i}{y_i}\right|, \mathrm{MAE}=\frac{1}{n} \sum_{i=1}^n\left|y_i-\hat{y}_i\right| , \\ & \mathrm{MSE}=\frac{1}{n} \sum_{i=1}^n\left(y_i-\hat{y}_i\right)^2, \\ & \mathrm{RMSE}=\sqrt{\frac{1}{n} \sum_{i=1}^n\left(y_i-\hat{y}_i\right)^2} \\ & \text { and MASE }=\frac{\frac{1}{j} \sum_0^j\left|e_j\right|}{\frac{1}{T-1} \Sigma_{t=2}^T\left|y_i-y_{i-1}\right|}\end{aligned}$ (3)
where, $\mathrm{y}_i$ and $\hat{y}_i$ are the real and the forecasted values, n is the total number of samples, $e_j$ is the prediction error for a specific period, $j$ is the number of forecasts, $T$ the number of in-sample values.
This study used a combination of these metrics to measure different aspects of forecast accuracy and error, offering a comprehensive assessment of the models' performance across various dimensions and ensuring that the models are robust under different evaluation criteria. MAPE expresses the size of the error relative to the actual values, making it a useful metric for understanding the proportional error. It is useful for communicating model performance because it shows on average, the predictions deviate from the true values in percentage terms. MASE is scale-independent, compares the forecast error to the error of a naive forecast, and helps contextualize how much better or worse a forecasting model is compared to a simple baseline model. It provides a normalized measure of forecast accuracy. RMSE gives more weight to larger errors, thus penalizing larger errors more heavily. It's a widely used metric in forecasting studies because it emphasizes the importance of avoiding significant forecasting errors; while, MAE is less sensitive to large outliers, making it a robust measure when the primary goal is to minimize overall error without overemphasizing larger deviations. MSE emphasizes larger errors but in a more mathematically tractable form (as it avoids the square root operation). Thereby, MAE and MAPE provide a direct understanding of average error, and RMSE and MSE emphasize larger deviations. This multi-metric approach ensures that the strengths and weaknesses of the models are captured across different error dimensions and provides a standardized assessment of their performance.
5.1 Statistical methods’ performance
Applying the ARIMA and SARIMA models to our dataset to successfully predict energy consumption requires fitting the model with the optimal parameter values. We utilized the Akaike information criterion (AIC) to identify the optimum values to strengthen prediction. AIC is an often-used metric for determining an ARIMA model’s parameters; it is based on maximizing the model's likelihood function and accounts for model complexity by appending a sanction for the parameter's estimated number. The AIC metric is defined in Eq. (4) below. With k representing the number of parameters estimated and Γ the model's maximum likelihood function.
$A I C=2 k-2 ln (\Gamma)$ (4)
Based on the AIC values illustrated in Table 1, we chose the ARIMA (3, 1, 0) model, since it had the inferior AIC value.
Table 1. AIC values for ARIMA models
|
ARIMA Parameters (p, d, q) |
AIC Value |
|
(1, 0, 0) |
38334.920 |
|
(2, 1, 1) |
29816.577 |
|
(3, 1, 0) |
29811.659 |
|
(3, 1, 1) |
29815.491 |
|
(4, 1, 0) |
29815.203 |
The data we want to forecast have a weekly seasonality as presented in Figure 2, and based on the AIC values for the SARIMA model in Table 2, we chose to apply the SARIMA (5, 1, 3) (2, 0, 1, 7) having the optimum AIC value.
Figure 2. Visualizing data seasonality
Table 2. AIC values for SARIMA models
|
Parameters |
AIC Value |
|
|
p, d, q |
P, D, Q, m |
|
|
0, 0, 0 |
0, 1, 1, 7 |
61716.759 |
|
0, 1, 3 |
2, 0, 1, 7 |
29606.834 |
|
5, 1, 3 |
2, 0, 1, 7 |
27824.938 |
|
5, 1, 0 |
2, 1, 0, 7 |
32676.977 |
|
5, 2, 3 |
2, 0, 1, 7 |
30098.857 |
5.2 Results of the applied models
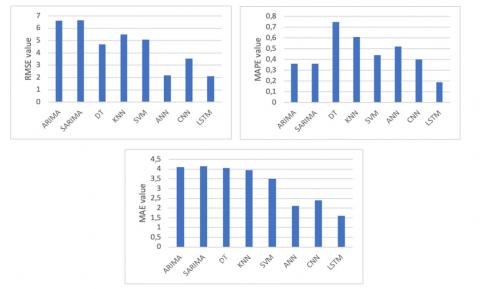
In this section, we predict the hourly energy consumption for the cluster. We conducted an evaluation through different lenses to assess the model with the highest performance in forecasting energy consumption. The results are presented in the Table 3, highlighting the values for the performance metrics discussed earlier (MAPE, MASE, RMSE, MAE, MSE). A combination of metrics is used to emphasize the importance of a multifaceted evaluation approach in assessing the predictive capabilities of the models accurately and Figure 3 illustrates these models’ performance.
Table 3. Statistical indicators for the models
|
|
ARIMA (3, 1, 0) |
SARIMA (2, 0, 1, 7) |
DT |
KNN |
SVM |
ANN |
CNN |
LSTM |
|
RMSE |
6.610 |
6.658 |
4.70 |
5.51 |
5.09 |
2.18 |
3.55 |
2.106 |
|
MAPE |
0.36 |
0.36 |
0.75 |
0.61 |
0.44 |
0.52 |
0.40 |
0.19 |
|
MASE |
4.67 |
114 |
4.50 |
4.64 |
3.90 |
3.22 |
4.01 |
2.13 |
|
MSE |
43.692 |
44.334 |
22.07 |
30.39 |
25.92 |
5.03 |
6.30 |
4.436 |
|
MAE |
4.109 |
4.155 |
4.05 |
3.94 |
3.51 |
2.11 |
2.39 |
1.599 |
Figure 3. A representation of RMSE, MAPE and MAE performance of the models
The analysis of the table data offers valuable insights on the performance of important models in predicting energy consumption. We observe that the ARIMA and SARIMA models performed slightly similarly, with only the MASE statistic indicating a remarkable difference. However, they performed less effectively than the other models, with ARIMA surpassing SARIMA in data forecasting. This suggests that traditional statistical models may not be as effective as machine learning and deep learning models for this time-series data, possibly due to their inability to capture complex temporal patterns. The ARIMA model and its variants have limitations in predicting non-linear data and are better efficient at detecting linear trends in time-series data. The ARIMA (3, 1, 0) model achieves an RMSE, MAPE, and MAE of 6.610, 0.36, and 4.109, respectively, whereas the SARIMA (2, 0, 1, 7) model achieves 6.658, 0.36, and 4.109. ML models performed better than ARIMA and SARIMA models.
When comparing DT, KNN, and SVM, DT's lower RMSE (4.70) and MSE (22.07) indicate that the model handles large deviations and outliers well, minimizing significant errors. However, its worse MAE (4.05) and MAPE (0.75) indicate more frequent smaller errors or inferior relative performance. KNN and SVM may provide more balanced predictions with fewer large errors, hence the worse RMSE (5.51 and 5.09) and MSE (30.39 and 25.92). Still, they perform better in terms of average and relative errors (MAE (3.94, 3.51) and MAPE (0.61, 0.44). SVM's better MASE suggests it adjusts better to the scale of the data compared to DT and KNN.
Both ANN and CNN perform well, particularly compared to the traditional models already discussed. ANN’s low RMSE (2.18), MASE (3.22), and MAE (2.11) indicate its capability in general error minimization, while CNN shows better results in MAPE (0.40), suggesting that CNN may handle relative errors more effectively. However, all the other metrics illustrated the superiority of ANN in our scenario to CNN, which has an RMSE of 3.55, a MASE of 4.01, an MSE of 6.30, and an MAE of 2.39. LSTM consistently outperformed all other models across all metrics. This suggests its advanced architecture effectively captures temporal dependencies and handles the complexity of hourly energy consumption data. In Figure 3, we can observe that the LSTM model performance aligns with the real data values, demonstrating its capabilities in accurately predicting energy consumption over time. Its superior performance across RMSE (2.106), MASE (2.13), MSE (4.436), and MAE (1.599) makes it the most reliable model in our scenario. LSTM also excels in MAPE (0.19), indicating its superior relative accuracy across varying scales of energy consumption, and achieves the lowest RMSE (2.106), suggesting it has the smallest average error magnitude when penalizing larger deviations more heavily.
The LSTM has outperformed the other models due to its unique architecture and ability to effectively capture long-term dependencies in time-series data.
Energy consumption data often exhibits complex patterns over time, influenced by both short-term fluctuations (daily or weekly cycles) and long-term trends (seasonal variations or gradual changes in behavior), and the LSTM's ability to maintain a memory of past observations through its gated architecture (i.e., the forget, input, and output gates) allows it to learn both short- and long-term dependencies effectively. Its recurrent structure enables it to capture better seasonality, complex temporal patterns, nonlinear relationships, and long-term dependencies. The implications of these findings suggest that LSTM can significantly enhance the efficiency of energy management systems, leading to more sustainable and cost-effective practices in real-world energy forecasting. It can offer utility companies more accurate demand forecasts, and implement more effective demand-side management (DSM) programs, thus optimizing energy generation, distribution, and pricing strategies.
While this study provides a robust comparison of time-series forecasting models, there are limitations that need to be addressed in future research. The study does not address the interpretability of the models, which is important for understanding how forecasts are generated and for building trust with users. Also, it is limited to a single dataset, and the models’ generalizability across different datasets and scenarios remains untested. As a future direction, we may examine the prediction performance of advanced hybrid models, such as combining CNN with LSTM or ARIMA with LSTM to improve the model's accuracy and resilience. We may also develop and investigate the potential of transformer-based hybrid models, and explore methods to ameliorate DL models’ interpretability by applying Explainable AI (XAI) approaches.
Precise energy demand predictions are critical to making informed decisions about energy usage and ameliorating energy efficiency. In this study dedicated to forecasting smart meters energy consumption, eight approaches were studied: ARIMA, SARIMA, DT, KNN, SVM, ANN, CNN, and LSTM. Analyzing the models’ predictions results showed that the LSTM model gives the best accuracy with an RMSE of 2.106, a MAPE of 0.19, and an MAE of 1.599. Also, both ANN and CNN performed well, and even though SVM, DT, and KNN achieved less efficient results, they still surpassed the ARIMA and SARIMA models that struggled with the non-linearity and variability inherent in the dataset. The success of ANN and CNN suggests that DL models are better equipped to handle the complexities and non-linearities present in smart meter data compared to traditional ML or statistical approaches. Although this study uses the ECBT dataset, which is specific to households in Ireland, the findings are not inherently limited to this context. The methodologies and models explored in this study could be generalized and applied to other countries, but the accuracy and model performance would need to be carefully evaluated based on the specific characteristics of the new datasets. The findings of this study are highly relevant for utility companies, energy providers, and smart grid operators seeking to improve the accuracy of their energy demand forecasts. The results obtained will give insights into the strengths and limits of each model, and suggest that LSTM and other DL models should be prioritized in forecasting applications where accurate predictions are necessary for optimizing energy distribution, implementing demand-side management, or integrating renewable energy sources.
[1] Dong, H., Gao, Y., Fang, Y., Liu, M., Kong, Y. (2021). The short-term load forecasting for special days based on bagged regression trees in Qingdao, China. Computational Intelligence and Neuroscience, 2021(1): 3693294. https://doi.org/10.1155/2021/3693294
[2] Quesada, C., Astigarraga, L., Merveille, C., Borges, C.E. (2024). An electricity smart meter dataset of Spanish households: Insights into consumption patterns. Scientific Data, 11(1): 59. https://doi.org/10.1038/s41597-023-02846-0
[3] Moustati, I., Gherabi, N., El Massari, H., Saadi, M. (2023). From the Internet of Things (IoT) to the Internet of Behaviors (IoB) for data analysis. In 2023 7th IEEE Congress on Information Science and Technology (CiSt), Agadir-Essaouira, Morocco, pp. 634-639. https://doi.org/10.1109/CiSt56084.2023.10409989
[4] Moustati, I., Gherabi, N., Saadi, M. (2024). Leveraging the internet of behaviours and digital nudges for enhancing customers' financial decision-making. International Journal of Computer Applications in Technology, 74(3): 208-221. https://doi.org/10.1504/IJCAT.2024.141957
[5] Aguilar Madrid, E., Antonio, N. (2021). Short-term electricity load forecasting with machine learning. Information, 12(2): 50. https://doi.org/10.3390/info12020050
[6] Caicedo-Vivas, J.S., Alfonso-Morales, W. (2023). Short-term load forecasting using an LSTM neural network for a grid operator. Energies, 16(23): 7878. https://doi.org/10.3390/en16237878
[7] Cao, X., Dong, S., Wu, Z., Jing, Y. (2015). A data-driven hybrid optimization model for short-term residential load forecasting. In 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing, Liverpool, UK, pp. 283-287. https://doi.org/10.1109/CIT/IUCC/DASC/PICOM.2015.41
[8] As' ad, M. (2012). Finding the best ARIMA model to forecast daily peak electricity demand. In the Fifth Annual ASEARC Conference—Looking to the Future—Programme and Proceedings, University of Wollongong, Wollongong, NSW, Australia.
[9] Nengling, T., Stenzel, J., Hongxiao, W. (2006). Techniques of applying wavelet transform into combined model for short-term load forecasting. Electric Power Systems Research, 76(6-7): 525-533. https://doi.org/10.1016/j.epsr.2005.07.003
[10] Yasmeen, F., Sharif, M. (2014). Forecasting electricity consumption for Pakistan. International Journal of Emerging Technology and Advanced Engineering, 4(4): 496-503.
[11] Li, S., Li, R. (2017). Comparison of forecasting energy consumption in Shandong, China Using the ARIMA model, GM model, and ARIMA-GM model. Sustainability, 9(7): 1181. https://doi.org/10.3390/su9071181
[12] Abledu, G.K. (2013). Modeling and forecasting energy consumption in Ghana. Journal of Energy Technologies and Policy, 3(12): 1-10.
[13] Kaytez, F., Taplamacioglu, M.C., Cam, E., Hardalac, F. (2015). Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines. International Journal of Electrical Power & Energy Systems, 67: 431-438. https://doi.org/10.1016/j.ijepes.2014.12.036
[14] Tay, F.E., Cao, L. (2001). Application of support vector machines in financial time series forecasting. Omega, 29(4): 309-317. https://doi.org/10.1016/S0305-0483(01)00026-3
[15] Basu, K., Debusschere, V., Bacha, S. (2012). Appliance usage prediction using a time series based classification approach. In IECON 2012-38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, pp. 1217-1222. https://doi.org/10.1109/IECON.2012.6388597
[16] Troncoso Lora, A., Riquelme Santos, J.M., Riquelme, J.C., Gómez Expósito, A., Martínez Ramos, J.L. (2004). Time-series prediction: Application to the short-term electric energy demand. In Current Topics in Artificial Intelligence: 10th Conference of the Spanish Association for Artificial Intelligence, CAEPIA 2003, and 5th Conference on Technology Transfer, TTIA 2003, San Sebastian, Spain, pp. 577-586. https://doi.org/10.1007/978-3-540-25945-9_57
[17] Lei, S.L., Sun, C.X., Zhou, Q., Zhang, X.X. (2005). The research of local linear model of short term electrical load on multivariate time series. In 2005 IEEE Russia Power Tech, St. Petersburg, Russia, pp. 1-5. https://doi.org/10.1109/PTC.2005.4524543
[18] Song, X., Liu, Y., Xue, L., Wang, J., Zhang, J., Wang, J., Cheng, Z. (2020). Time-series well performance prediction based on Long Short-Term Memory (LSTM) neural network model. Journal of Petroleum Science and Engineering, 186: 106682. https://doi.org/10.1016/j.petrol.2019.106682
[19] Muzaffar, S., Afshari, A. (2019). Short-term load forecasts using LSTM networks. Energy Procedia, 158: 2922-2927. https://doi.org/10.1016/j.egypro.2019.01.952
[20] Khodabakhsh, A., Ari, I., Bakır, M., Alagoz, S.M. (2020). Forecasting multivariate time-series data using LSTM and mini-batches. In Data Science: From Research to Application, pp. 121-129. https://doi.org/10.1007/978-3-030-37309-2_10
[21] Koprinska, I., Wu, D., Wang, Z. (2018). Convolutional neural networks for energy time series forecasting. In 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, pp. 1-8. https://doi.org/10.1109/IJCNN.2018.8489399
[22] Le, T., Vo, M.T., Vo, B., Hwang, E., Rho, S., Baik, S.W. (2019). Improving electric energy consumption prediction using CNN and Bi-LSTM. Applied Sciences, 9(20): 4237. https://doi.org/10.3390/app9204237
[23] Pierre, A.A., Akim, S.A., Semenyo, A.K., Babiga, B. (2023). Peak electrical energy consumption prediction by ARIMA, LSTM, GRU, ARIMA-LSTM and ARIMA-GRU approaches. Energies, 16(12): 4739. https://doi.org/10.3390/en16124739
[24] Zhang, Y., Meng, G. (2023). Simulation of an adaptive model based on AIC and BIC ARIMA predictions. Journal of Physics: Conference Series, 2449(1): 012027. https://doi.org/10.1088/1742-6596/2449/1/012027
[25] Katara, S., Faisal, A., Engmann, G.M. (2014). A time series analysis of electricity demand in Tamale, Ghana. International Journal of Statistics and Applications, 4(6): 269-275. https://doi.org/10.5923/j.statistics.20140406.03
[26] Ediger, V.Ş., Akar, S. (2007). ARIMA forecasting of primary energy demand by fuel in Turkey. Energy Policy, 35(3): 1701-1708. https://doi.org/10.1016/j.enpol.2006.05.009
[27] Wang, Y., Wang, J., Zhao, G., Dong, Y. (2012). Application of residual modification approach in seasonal ARIMA for electricity demand forecasting: A case study of China. Energy Policy, 48: 284-294. https://doi.org/10.1016/j.enpol.2012.05.026
[28] Pereira, C.M., de Almeida, N.N., Velloso, M.L. (2015). Fuzzy modeling to forecast an electric load time series. Procedia Computer Science, 55: 395-404. https://doi.org/10.1016/j.procs.2015.07.089
[29] Wang, J.Q., Du, Y., Wang, J. (2020). LSTM based long-term energy consumption prediction with periodicity. Energy, 197: 117197. https://doi.org/10.1016/j.energy.2020.117197
[30] Abdel-Nasser, M., Mahmoud, K. (2019). Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Computing and Applications, 31: 2727-2740. https://doi.org/10.1007/s00521-017-3225-z
[31] Chan, S., Oktavianti, I., Puspita, V. (2019). A deep learning cnn and ai-tuned svm for electricity consumption forecasting: Multivariate time series data. In 2019 IEEE 10th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, pp. 0488-0494. https://doi.org/10.1109/IEMCON.2019.8936260
[32] Atik, I. (2022). A new CNN-based method for short-term forecasting of electrical energy consumption in the COVID-19 period: The case of Turkey. IEEE Access, 10: 22586-22598. https://doi.org/10.1109/ACCESS.2022.3154044
[33] Liu, Y., Huang, Y., Wang, J., Liu, L., Luo, J. (2018). Detecting premature ventricular contraction in children with deep learning. Journal of Shanghai Jiaotong University (Science), 23: 66-73. https://doi.org/10.1007/s12204-018-1911-3
[34] Balaji, A.J., Ram, D.H., Nair, B.B. (2018). Applicability of deep learning models for stock price forecasting an empirical study on BANKEX data. Procedia Computer Science, 143: 947-953. https://doi.org/10.1016/j.procs.2018.10.340
[35] Chitsaz, H., Shaker, H., Zareipour, H., Wood, D., Amjady, N. (2015). Short-term electricity load forecasting of buildings in microgrids. Energy and Buildings, 99: 50-60. https://doi.org/10.1016/j.enbuild.2015.04.011
[36] Panapakidis, I.P., Dagoumas, A.S. (2016). Day-ahead electricity price forecasting via the application of artificial neural network based models. Applied Energy, 172: 132-151. https://doi.org/10.1016/j.apenergy.2016.03.089
[37] Azadeh, A., Babazadeh, R., Asadzadeh, S.M. (2013). Optimum estimation and forecasting of renewable energy consumption by artificial neural networks. Renewable and Sustainable Energy Reviews, 27: 605-612. https://doi.org/10.1016/j.rser.2013.07.007
[38] Ekonomou, L. (2010). Greek long-term energy consumption prediction using artificial neural networks. Energy, 35(2): 512-517. https://doi.org/10.1016/j.energy.2009.10.018
[39] Singh, S., Hussain, S., Bazaz, M.A. (2017). Short term load forecasting using artificial neural network. In 2017 Fourth International Conference on Image Information Processing (ICIIP), Shimla, India, pp. 1-5. https://doi.org/10.1109/ICIIP.2017.8313703
[40] Szoplik, J. (2015). Forecasting of natural gas consumption with artificial neural networks. Energy, 85: 208-220. https://doi.org/10.1016/j.energy.2015.03.084
[41] Kandananond, K. (2011). Forecasting electricity demand in Thailand with an artificial neural network approach. Energies, 4(8): 1246-1257. https://doi.org/10.3390/en4081246
[42] Liu, D., Chen, Q., Mori, K. (2015). Time series forecasting method of building energy consumption using support vector regression. In 2015 IEEE International Conference on Information and Automation, Lijiang, China, pp. 1628-1632. https://doi.org/10.1109/ICInfA.2015.7279546
[43] Fu, Y., Li, Z., Zhang, H., Xu, P. (2015). Using support vector machine to predict next day electricity load of public buildings with sub-metering devices. Procedia Engineering, 121: 1016-1022. https://doi.org/10.1016/j.proeng.2015.09.097
[44] Basu, K., Hawarah, L., Arghira, N., Joumaa, H., Ploix, S. (2013). A prediction system for home appliance usage. Energy and Buildings, 67: 668-679. https://doi.org/10.1016/j.enbuild.2013.02.008
[45] Brown, M., Barrington-Leigh, C., Brown, Z. (2012). Kernel regression for real-time building energy analysis. Journal of Building Performance Simulation, 5(4): 263-276. https://doi.org/10.1080/19401493.2011.577539
[46] Al-Qahtani, F.H., Crone, S.F. (2013). Multivariate k-nearest neighbour regression for time series data—A novel algorithm for forecasting UK electricity demand. In the 2013 International Joint Conference on Neural Networks (IJCNN), pp. 1-8. https://doi.org/10.1109/IJCNN.2013.6706742
[47] Lachut, D., Banerjee, N., Rollins, S. (2014). Predictability of energy use in homes. In International Green Computing Conference, Dallas, TX, USA, pp. 1-10. https://doi.org/10.1109/IGCC.2014.7039146
[48] Ensafi, Y., Amin, S.H., Zhang, G., Shah, B. (2022). Time-series forecasting of seasonal items sales using machine learning–A comparative analysis. International Journal of Information Management Data Insights, 2(1): 100058. https://doi.org/10.1016/j.jjimei.2022.100058
[49] Shastri, S., Singh, K., Kumar, S., Kour, P., Mansotra, V. (2020). Time series forecasting of Covid-19 using deep learning models: India-USA comparative case study. Chaos, Solitons & Fractals, 140: 110227. https://doi.org/10.1016/j.chaos.2020.110227
[50] Livieris, I.E., Pintelas, E., Pintelas, P. (2020). A CNN-LSTM model for gold price time-series forecasting. Neural Computing and Applications, 32: 17351-17360. https://doi.org/10.1007/s00521-020-04867-x
[51] Ariyanti, V.P., Yusnitasari, T. (2023). Comparison of Arima and Sarima for forecasting crude oil prices. Jurnal RESTI (Rekayasa Sistem dan Teknologi Informasi), 7(2): 405-413. https://doi.org/10.29207/resti.v7i2.4895
[52] Wang, X., Tian, W., Liao, Z. (2021). Statistical comparison between SARIMA and ANN’s performance for surface water quality time series prediction. Environmental Science and Pollution Research, 28: 33531-33544. https://doi.org/10.1007/s11356-021-13086-3
[53] Das, R., Middya, A.I., Roy, S. (2022). High granular and short term time series forecasting of pm 2.5 air pollutant—A comparative review. Artificial Intelligence Review, 55(2): 1253-1287. https://doi.org/10.1007/s10462-021-09991-1
[54] Sirisha, U.M., Belavagi, M.C., Attigeri, G. (2022). Profit prediction using ARIMA, SARIMA and LSTM models in time series forecasting: A comparison. IEEE Access, 10: 124715-124727. https://doi.org/10.1109/ACCESS.2022.3224938
[55] Commission for Energy Regulation (CER). (2012). CER Smart Metering Project - Electricity Customer Behaviour Trial, 2009-2010 [dataset]. 1st Edition. Irish Social Science Data Archive. https://www.ucd.ie/issda/.
[56] Siami-Namini, S., Tavakoli, N., Namin, A.S. (2018). A comparison of ARIMA and LSTM in forecasting time series. In 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA pp. 1394-1401. https://doi.org/10.1109/ICMLA.2018.00227
[57] Vapnik, V., Golowich, S., Smola, A. (1996). Support vector method for function approximation, regression estimation and signal processing. Advances in neural Information Processing Systems.
[58] Vapnik, V. (1995). The Nature of Statistical Learning Theory. New York, USA: Springer.
[59] Quinlan, J.R. (1979). Induction of Decision Trees, Expert Systems in the Micro-Electronic Age. Edinburgh University Press, 1979.
[60] Dasarathy, B.V. (1991). Nearest neighbor (NN) norms: NN pattern classification techniques. IEEE Computer Society Tutorial. Los Alamitos: IEEE Computer Society Press.
[61] Schmidhuber, J., Hochreiter, S. (1997). Long short-term memory. Neural Comput, 9(8): 1735-1780. https://doi.org/10.1162/neco.1997.9.8.1735
[62] Borovykh, A., Bohte, S., Oosterlee, C.W. (2017). Conditional time series forecasting with convolutional neural networks. arXiv preprint arXiv:1703.04691.
[63] Pao, H.T. (2009). Forecasting energy consumption in Taiwan using hybrid nonlinear models. Energy, 34(10): 1438-1446. https://doi.org/10.1016/j.energy.2009.04.026