Sissy Sacharisa*![]() | Iman Herwidiana Kartowisastro
| Iman Herwidiana Kartowisastro![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Scoliosis prevalence is witnessing an upward trend, rendering image segmentation an invaluable tool in appraising the condition's severity. The segmentation of spinal images, however, poses notable challenges primarily due to the image quality and the complexity of discerning the Region of Interest (ROI) on X-ray imagery. This difficulty arises from the uniform texture and luminosity of the background, complicating the ROI detection process. Our study investigates the performance of U-Net in image segmentation using anterior-posterior X-ray imagery of spines afflicted with scoliosis. A corpus of 609 high-resolution images was assembled for this purpose, partitioned into 481 training and 128 testing images. Prior to model implementation, a data augmentation process was carried out to bolster the training datasets, mitigating the risk of model overfitting. The augmentation involved mirroring and adding black and white intensity to each image, thereby generating thirteen new images from each original image. This process amplified the size of the training dataset from 481 to 6734 images. Our findings validate the efficacy of the U-Net model in accurately segmenting the spine in X-ray images, demonstrating an accuracy of 97% in training and 94% in validation, with a corresponding loss of 0.063 and validation loss of 0.16. The resultant segmentation is poised to enhance the precision of scoliosis severity assessment.
image segmentation, Region of Interest (ROI), scoliosis, U-Net
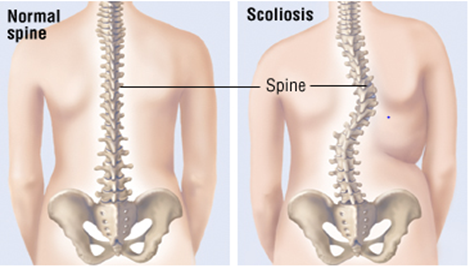
Scoliosis, a debilitating spinal disorder, afflicts approximately 2.5 percent of the global adolescent demographic, characterized by a pronounced spinal curvature, which, in its manifestation, bears resemblance to the letters "S" or "C" [1]. Scoliosis is clinically defined as a curvature exceeding 10°. The contrast between the spinal structure of a healthy individual and that of a scoliosis patient is illustrated in Figure 1. The etiology of adolescent scoliosis, which accounts for 70 to 80 percent of all cases, remains predominantly idiopathic or unknown. The rapid skeletal growth characteristic of adolescence may exacerbate scoliosis progression if not promptly identified and addressed.
Figure 1. The difference between a normal spine and a scoliosis spine [1]
As the incidence of scoliosis escalates over time [2], image segmentation's role in assessing the severity of the condition gains increasing significance. Nonetheless, the segmentation of spinal images presents formidable challenges, largely contingent on the quality of the images. The Region of Interest (ROI) in X-ray images of the spine constitutes the principal obstacle to effective segmentation due to the uniform texture and brightness of the background, complicating the detection of the ROI [3]. The accuracy of scoliosis severity measurement is intrinsically linked to the quality of spinal segmentation, forming the basis for the subsequent therapeutic strategy delineation by the clinician.
The pivotal role of medical image segmentation in identifying key elements in images such as X-rays for further processing is widely recognized. Significant research efforts have been channeled into segmentation in medical imaging, including cancer detection in the brain [4], lungs [5], and breasts [6]. A critical task in medical image analysis involves differentiating pixels pertaining to spinal imaging from the background in X-ray images for subsequent analysis. The curvature of the spine in scoliosis patients' X-ray images complicates the segmentation of the spine from the image.
Image segmentation is a prerequisite for X-ray image-based scoliosis severity calculation, serving to mitigate image noise and focus on the image area. Despite its critical importance, image segmentation represents one of the most complex and time-consuming pre-processing steps [7]. Radiologists traditionally rely on subjective standards in image segmentation, although recent research encompasses edge detection, thresholding, region growth, and deformable models, in addition to more conventional image segmentation techniques [8]. Segmentation techniques primarily fall into one of four categories: thresholding-based, region-based, edge-based, and clustering-based [9].
The rest of the paper is organized as follows. Section 2 reviews relevant literature on image segmentation. The methodology adopted in this study is elaborated in Section 3, followed by a detailed exposition of the implementation of the aforementioned approach in Section 4. Section 5 presents the results of spine segmentation using the U-Net model.
Image segmentation, predicated on the analysis and processing of 2D or 3D images utilizing computer image processing technologies, facilitates segmentation, extraction, and three-dimensional reconstruction [10]. Segmentation, as it pertains to medical imaging, is typically categorized into semantic segmentation, instance segmentation, and panoramic segmentation, with semantic segmentation tasks predominantly associated with medical images [10]. Traditional methods such as threshold-based [11], region-based [12], and edge detection-based segmentation [13] are increasingly being supplanted by segmentation methods grounded in deep learning due to their superior efficacy.
Zhou et al. [14] conducted an extensive review of segmentation on medical images utilizing deep learning methodologies, with a particular focus on multi-modality fusion. This approach amalgamates multiple pieces of information to refine segmentation, and comprises four distinct stages: data pre-processing, network architecture, fusion method, and post-processing. During the data pre-processing stage, the data dimension is selected, and pre-processing is deployed to minimize the variability across images. Data augmentation may also be employed to expand the training data and circumvent overfitting. The network architecture and fusion strategy stages entail the training of the segmentation network using a fundamental network and comprehensive multi-modal image fusion techniques. The data post-processing stage incorporates techniques such as morphological methods and conditional random fields to enhance the final segmentation result.
Hesamian et al. [15] highlighted several challenges associated with deep learning models, including overfitting, training time, gradient vanishing, and organ appearance. Overfitting occurs when a model's ability to accurately represent the patterns and regularities in the training set surpasses its capability to handle novel instances of the problem. Overfitting can be addressed through the application of "dropout" during the training phase, which entails the removal of the output of a random sample of neurons in each iteration from the fully connected layers [16]. The application of pooling layers to reduce the dimensionality of the parameters during training represents one of the earliest solutions to this problem [17]. Gradient vanishing, another major issue, is characterized by the signal (gradient) exploding or vanishing entirely in deeper networks [18]. The diverse appearance of the target organ represents a significant challenge in medical image segmentation. The target organ or lesion can vary greatly in terms of size, shape, and location across patients [19]. According to reports, deepening the network is an effective solution to this issue [20].
Imran et al. [1] proposed an end-to-end model using a neural network with the U-Net model, which can expedite the measurement time due to its automation. The measurement results differed from the results of measurements by doctors by a mere 2.41° [4]. Meanwhile, Zhang et al. detected and segmented the Vertebral Body (VB) based on spinal MR images using the Sequential Conditional Reinforcement Learning network (SCRL) approach, which had an accuracy of 92.3% IoU in the spine, 92.6% dice in spinal segmentation, and 96.4% of the spine classification using the Y-Net model [21]. Some researchers improved the previous best result in semantic segmentation by converting modern classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and applying their learned representations to the segmentation problem. They successfully segmented PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context using their fully convolutional network [22].
A novel automated spinal ultrasound segmentation approach was proposed by Jiang et al. [23] integrated artificial intelligence methodologies to develop a new model called ultrasound global guidance block network (UGBNet). The UGBNet model offers a fully automated and reliable approach for segmenting the spine and visualizing scoliosis in ultrasound images. This network architecture includes a global guidance block module that effectively combines spatial and channel attention mechanisms, enabling the network to learn long-range feature dependencies and contextual scale information. The findings indicated that the implementation of UGBNet led to a notable enhancement in segmentation precision, achieving up to 74.2% on the Dice score evaluation metric.
Sille et al. [24] proposed a systematic approach to overcoming obstacles in brain tumor segmentation techniques. The model consists of an 11-layered deep capsule network with transfer learning and two dropout layers at the input, as well as 5 layers of segmentation channel with dropout layers. This paper focuses on achieving a high dice score coefficient and accuracy in brain tumor segmentation from MRI images. The proposed work achieved comparatively better results in terms of dice score coefficients, such as (0.80, 0.76, 0.76) for whole tumor [WT], active tumor [AT], and core tumor [CT].
Brain tumor segmentation in MRI images using the optimal morphology thresholding methods proposed by Pongsatitpat et al. [25] The optimal morphology thresholding methods are novel methods for solving problems and diagnosing diseases. These are the RGB to Grayscale conversion, the image quality improvement, and the optimum thresholding processes. The proposed methods could automatically segment brain tumors in MRI images based on shapes found in public databases. The maximum absolute error was 3.96%, with an accuracy of 98.00%.
Based on a review of the literature on image segmentation methods, it is apparent that the U-Net architecture is well-suited for X-ray image segmentation tasks, as it effectively addresses the various challenges encountered in deep learning models, including overfitting and training time. In this study, the U-Net model is employed to segment the spine in scoliosis patients. This model facilitates the distinction of the image from background noise by utilizing attributes such as intensity, color, and texture.
Based on previous research, the most recent research on deep learning for medical picture segmentation uses U-Net networks because U-Net solved several issues with deep learning models, including overfitting and training time. Besides that, U-Net has the highest accuracy to do the segmentation based on previous research. Applying "dropout" during the training phase to eliminate the output of a random sample of neurons in each iteration from the fully connected layers is another method to handle overfitting. Applying pooling layers to minimize the dimensionality of the parameter’s during training is one of the earliest solutions to this problem. Therefore, we decided to use U-Net to segment the spine on X-ray images of patients with scoliosis in this study.
Compared to UGBNet [23], which combines artificial intelligence methods to create a new spine ultrasound image segmentation model, U-Net is appropriate for X-ray image segmentation tasks that address several issues with deep learning models, such as overfitting and training time. In addition, UGBNet is limited by the fact that ultrasound images frequently contain acoustic artifacts, spots, and reticulated noise, which conceal bony features, such as spinous and transverse processes, and make manual recognition and segmentation increasingly difficult.
A Fully Convolutional Network (FCN) is the foundation of the U-Net approach, which was intended to work with fewer training photos and provide more accurate biomedical image segmentation [26]. Adding numerous feature channels to the up sampling portion, which enables the network to disseminate information at a higher resolution layer, is a crucial innovation. It results in a U-shaped building by making the expanded path symmetrical with the contracting path.
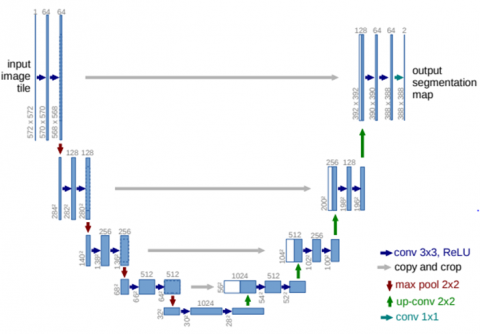
Two pathways, an encoder, and a decoder, make up the U-Net network's design. While exact localization is accomplished in the decoder using transposed convolution, context capture is accomplished in the encoder route utilizing the input image. Figure 2 details the U-Net design.
Contracting routes (left side) and expanding paths can be seen in the architecture in Figure 2 (right side). The contracting path uses a convolutional network architecture of repeated applications of two 3x3 convolutions (unpadded convolutions). Each convolution is followed by a rectified linear unit (ReLu), a 2x2 max pooling operation with stride 2 for down sampling. The number of feature channels doubles for every down sampling. Each step on the expansive path includes an up sampling of the feature map, followed by a 2x2 convolution that splits the number of feature channels, a sequence that cuts the feature map appropriately from the contracting path, and two 3x3 convolutions with ReLu following each convolution. Each of the 64 features in the final layer's convolution 1x1 is mapped to the required number of classes. There are 23 convolutional layers in total in this network. The network design described in the original paper on U-Net [24] utilizes repeated applications of two 3x3 convolutions without padding, with each convolution being followed by a ReLu. As a result, U-Net uses a 3x3 kernel.
Figure 3 shows that from X-ray image input, preprocessing is performed by resizing the image and augmenting data from the existing dataset. The original size of the image for the entire dataset is 755x2125x1 pixel, which will be resized to 128x256x1 pixel. Image resizing is needed to adjust the image size to the U-Net model so that the feature extraction process can perform efficiently. After that, data augmentation will be performed, namely adding the number of existing datasets to avoid overfitting the model by mirroring, adding black intensity, and adding white intensity to each image. From Figure 3, on augmented image 1 is the rotation of 5-degree, augmented image 2 is mirror of augmented image 1, augmented image 3 is rotation of 10-degree, augmented image 4 is mirror of augmented image 3. So that from each original image, three new images will be formed which are the result of data augmentation to increase the number of existing datasets and to avoid overfitting in the training process. After that, segmentation of the spinal image will be performed using U-Net to detect the part of the image which is part of the spine.
Figure 2. U-Net architecture [23]
Figure 3. Overview spine segmentation
As detailed in Algorithm 1, we used training data spine X-ray images that have been done pre-processing stages and their reference segmentation mask from the labeled dataset as input to be processed with the U-Net model. To segment the spinal part of the X-ray image, we loop through each training data with batch size 64 and mini-batch 32 based on Figure 2, which used 64 features in the final layer's convolution 1x1. Then we compute the output of the segmentation model for each mini-batch using U-Net model with learnable parameters to produce predicted segmentation spine mask from the image.
|
Algorithm 1. Image segmentation algorithm |
|
input: training data spine X-ray images that has been done pre-processing stages and their reference segmentation mask from labeled dataset for each step over training data do: batch size=64 mini batch=32 compute model output for mini batch: U-Net model with learnable parameter to produce predicted segmentation mask calculate loss for the model predictions using binary cross entropy function |
|
end for |
To calculate the loss amount from the model of the entire N spinal X-ray image dataset between masks spinal segmentation y and prediction segmentation model $\hat{y}$, loss function with binary cross-entropy will be used as shown in Eq. (1). Besides that, we used accuracy to calculate the ratio between the number of correct predictions to the total number of predictions. Accuracy is a metric that generally describes how the model performs across all classes as described in Eq. (2) with TP as true positive and TN as true negative. TP is when the spine is correctly categorized as a spine and TN is when the background is categorized as not a spine.
Loss $=-\frac{1}{N} \sum_{i=1}^N y_i \cdot \log \widehat{y}_l+\left(1-y_i\right) \cdot \log \left(1-\hat{y}_i\right)$ (1)
Accuracy $=\frac{T P+T N}{\text { Total All Data }}$ (2)
A total of 609 high-resolution anterior-posterior X-ray images from spineweb website (www.spineweb.digitalimaginggroup.ca) were utilized in our study. The images were split into 481 training and 128 testing and were manually annotated by spine experts. Before the images are implemented to the models, we perform data augmentation to increase the training datasets to avoid overfitting the model by mirroring, adding black intensity, and adding white intensity in each image. With the result that from each original image, thirteen new images will be formed, which are the results of data augmentation to increase the number of existing training datasets from 481 images to 6734 images. All the images have been resized and normalized to 128×256×1 to match the input of the U-Net model before feeding them to the network. The models were trained on the training set. Their performances were evaluated on the testing set. The validation set was used for hyper-parameter tuning and model selection. The Adam optimizer was used, along with a binary cross-entropy loss function [27]. The selection of binary cross-entropy as the loss function is motivated by the perception of X-ray segmentation as a binary classification problem. The binary cross-entropy loss function is more appropriate for this problem than the mean squared error (MSE) loss function because there are two distinct classes in a binary classification problem, allowing for the prediction of the probability of an example belonging to the first class. The objective is to find a collection of model weights that minimizes the disparity between the predicted probability distribution of the model based on the dataset and the probability distribution observed in the training dataset. We implemented a 0.1 dropout rate because too high a dropout rate can slow the convergence rate of the model, and often hurt final performance.
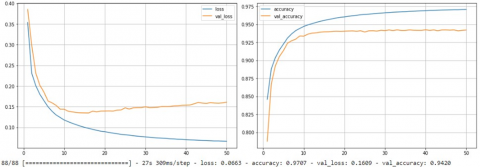
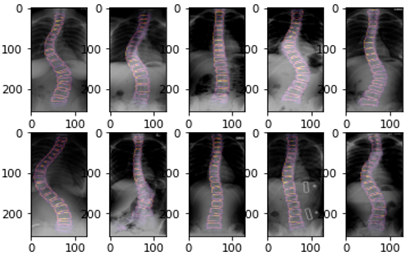
We applied image segmentation with the U-Net model to the spine X-ray dataset with 50 epochs, 64 batch sizes, and a binary cross entropy loss function. From Figure 4, segmentation training accuracy has the result of 97% with a loss of 6.3% and validation accuracy 94% with a loss of 16%. Figure 5 and Figure 6 show the loss in every epoch that is on training and validation, with 26% epoch loss on training and 32% epoch loss on validation. Figure 7 visualize segmented vertebrae from spine X-ray dataset.
From Figure 4, with the x-axis as the amount of epoch and the y-axis as the loss amount, on training we get the amount of loss which decreases as the epoch increases until it reaches epoch 50 because it uses the equation in Eq. (1) to calculate the loss amount. It shows that U-Net models can carry out the training process well because it gets the result of a loss of 6.3% on the training data. Meanwhile, we get more significant results than during the training process. The loss graph in the validation process has increased at epochs 40 to 50. It shows that the model does not perform the validation process as well as during training because we get a result of 26% during validation.
Meanwhile, for accuracy using the equation in Eq. (2) when training, the model can produce accuracy which increases as more epochs are performed. It shows that the model can perform training well and get the result with an accuracy of 97%. Meanwhile, the model validation process did not show a significant increase at 10-50 epochs, and the result was an accuracy of 94%.
Based on Figure 5 in the training data, from epoch 1 to 50 it continues to show a decrease in the loss value in each epoch. It can happen because when running the training, an equation in Eq. (1) calculates the loss in each epoch using the binary cross entropy equation. Meanwhile, data validation shows a decrease in the loss at epochs 1 to 25. However, it does not experience a significant decrease in the loss until epoch 50 because the model does not work well in predicting the validation dataset compared to the existing segmentation mask. With the result, epochs 26 to 50 did not experience a significant loss reduction.
Figure 4. Accuracy and loss result in training (Blue) andvalidation (Orange)
Figure 5. Epoch loss result in training (Blue) and validation (Pink)
Figure 6. Epoch accuracy in training (Blue) and validation (Pink)
Figure 7. Visualization of segmentation in spine X-ray images
On the Figure 6 in segmenting using training data, in epochs 1 to 5 the model experienced an increase in accuracy in predicting segmentation based on existing masks. Then at epochs 6 to 36 there was no increase or decrease in accuracy in training, but the model again experienced an increase in accuracy at epochs 37 to 50. This was because at each epoch accuracy was evaluated using Eq. (1) so that at epoch 50 the model has an accuracy of 90%. Meanwhile in the validation data, at epochs 1 to 42 the model can immediately predict segmentation with an accuracy of 87% for each epoch, but the model experiences a decrease in accuracy at epochs 43 to 50 so that at epoch 50 the validation data has an epoch accuracy of 86%.
Based on Figure 4, Figure 5, and Figure 6, we get the accuracy on validation image 94% it means the model can do the segmentation quite well with validation loss 16%. The gap between the training line and the validation line shows that the model is not overfitting in learning. For future work, data augmentation, dropout, or early stopping can be used to reduce overfitting. From that result, Figure 7 shows the visualization of segmented vertebrae from the spine X-ray dataset using the U-Net model.
The U-Net model can segment medical X-ray images with good results. So that it is possible to apply it to other medical images such as MRI, ultrasound, or CT scans, but considering the data preprocessing methods on MRI, ultrasound, and CT scan images may differ depending on the number of datasets and the sharpness of the images. The ability to perform image segmentation can improve the results of measuring the level of scoliosis so that the doctor can decide on the treatment for the patient’s scoliosis.
In this paper, we have presented segmentation using U-Net in X-ray spine images. We trained the U-Net model for segmentation of X-ray spine images because the accurate segmentation and identification are critical to measuring scoliosis cobb angle. Our research demonstrates that the U-Net model is quite accurate at segmenting the spine on X-ray images, with accuracy values of 97% on training and 94% on validation. It means that the model can do spine segmentation quite well from the dataset. We are also aware of the limitations of this model, as well as the necessity to fine-tune its parameters so that it can distinguish between the spine and the white portion of the image at the bottom of the X-ray image. In further studies, we plan to improve the model's segmentation accuracy to achieve even better segmentation outcomes.
[1] Imran, A.A.Z., Huang, C., Tang, H., Fan, W., Cheung, K., To, M., Qian, Z., Terzopoulos, D. (2020). Fully-automated analysis of scoliosis from spinal X-ray images. In 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), 114-119. https://doi.org/10.1109/CBMS49503.2020.00029
[2] von Heideken, J., Iversen, M.D., Gerdhem, P. (2018). Rapidly increasing incidence in scoliosis surgery over 14 years in a nationwide sample. European Spine Journal, 27, 286-292. https://doi.org/10.1007/s00586-017-5346-6
[3] Greiner, K.A. (2002). Adolescent idiopathic scoliosis: radiologic decision-making. American Family Physician, 65(9): 1817-1823.
[4] Sahoo, D.K., Mishra, S., Mohanty, M.N. (2022). Review on brain tumour segmentation and classification using CNN and deep learning approach. Stochastic Modeling & Applications, 26(3): 341-349.
[5] Abbas, Q., Asif, M., Yasin, M.Q. (2020). Lung cancer detection using convolutional neural network. International Journal of Recent Advances in Multidisciplinary Topics, 3(4): 90-92.
[6] Abunasser, B.S., Daud, S.M., Zaqout, I., Abu-Naser, S.S. (2023). Convolution neural network for breast cancer detection and classification-final results. Journal of Theoretical and Applied Information Technology, 101(1): 315-329.
[7] Isinkaye, F.O., Aluko, A.G., Jongbo, O.A. (2021). Segmentation of medical X-ray bone image using different image processing techniques. I.J. Image, Graphics and Signal Processing, 13(5): 27-40. https://doi.org/10.5815/ijigsp.2021.05.03
[8] Song, Y., Yan, H. (2017). Image segmentation techniques overview. In 2017 Asia Modelling Symposium (AMS). IEEE, pp. 103-107. https://doi.org/10.1109/AMS.2017.24
[9] Zeebaree, D.Q., Haron, H., Abdulazeez, A.M., Zebari, D.A. (2019). Machine learning and region growing for breast cancer segmentation. In 2019 International Conference on Advanced Science and Engineering (ICOASE). IEEE, pp. 88-93. https://doi.org/10.1109/ICOASE.2019.8723832
[10] Liu, X., Song, L., Liu, S., Zhang, Y. (2021). A review of deep-learning-based medical image segmentation methods. Sustainability, 13(3): 1224. https://doi.org/10.3390/su13031224
[11] Xu, A., Wang, L., Feng, S., Qu, Y. (2010). Threshold-based level set method of image segmentation. In 2010 Third International Conference on Intelligent Networks and Intelligent Systems. IEEE, pp. 703-706. https://doi.org/10.1109/ICINIS.2010.181
[12] Cigla, C., Alatan, A.A. (2008). Region-based image segmentation via graph cuts. In 2008 15th IEEE International Conference on Image Processing, pp. 2272-2275. https://doi.org/10.1109/ICIP.2008.4712244
[13] Zhao, Y.Q., Guo, W.H., Chen, Z.C., Tang, J.T., Li, L.Y. (2006). Medical images edge detection based on mathematical morphology. In 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, pp. 6492-6495. https://doi.org/10.1109/IEMBS.2005.1615986
[14] Zhou, T., Ruan, S., Canu, S. (2019). A review: Deep learning for medical image segmentation using multi-modality fusion. Array, 3: 100004. https://doi.org/10.1016/j.array.2019.100004
[15] Hesamian, M.H., Jia, W., He, X., Kennedy, P. (2019). Deep learning techniques for medical image segmentation: Achievements and challenges. Journal of Digital Imaging, 32: 582-596. https://doi.org/10.1007/s10278-019-00227-x
[16] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. The Journal Of Machine Learning Research, 15(1): 1929-1958.
[17] Dou, Q., Yu, L., Chen, H., Jin, Y., Yang, X., Qin, J., Heng, P.A. (2017). 3D deeply supervised network for automated segmentation of volumetric medical images. Medical Image Analysis, 41: 40-54. https://doi.org/10.1016/j.media.2017.05.001
[18] Kamnitsas, K., Ledig, C., Newcombe, V.F., Simpson, J.P., Kane, A.D., Menon, D.K., Rueckert, D., Glocker, B. (2017). Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Medical Image Analysis, 36: 61-78. https://doi.org/10.1016/j.media.2016.10.004
[19] Yu, L., Chen, H., Dou, Q., Qin, J., Heng, P.A. (2016). Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Transactions on Medical Imaging, 36(4): 994-1004. https://doi.org/10.1109/TMI.2016.2642839
[20] Wang, R., Lei, T., Cui, R., Zhang, B., Meng, H., Nandi, A.K. (2022). Medical image segmentation using deep learning: A survey. IET Image Processing, 16(5): 1243-1267. https://doi.org/10.1049/ipr2.12419
[21] Zhang, D., Chen, B., Li, S. (2021). Sequential conditional reinforcement learning for simultaneous vertebral body detection and segmentation with modeling the spine anatomy. Medical Image Analysis, 67: 101861. https://doi.org/10.1016/j.media.2020.101861
[22] Long, J., Shelhamer, E., Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3431-3440. https://doi.org/10.48550/arXiv.1411.4038
[23] Jiang, W., Mei, F., Xie, Q. (2022). Novel automated spinal ultrasound segmentation approach for scoliosis visualization. Frontiers in Physiology, 13: 1051808. https://doi.org/10.3389/fphys.2022.1051808
[24] Sille, R., Choudhury, T., Chauhan, P., Sharma, D. (2021). A systematic approach for deep learning based brain tumor segmentation. Ingénierie des Systèmes d’Information, 26(3): 245-254. https://doi.org/10.18280/isi.260301
[25] Pongsatitpat, B., Prathepha, K., Obma, J., Sa-Ngiamvibool, W. (2022). The automatic brain tumor segmentation based on MRI using optimal morphology thresholding methods. Ingénierie des Systèmes d’Information, 27(3): 409-414. https://doi.org/10.18280/isi.270306
[26] Ronneberger, O., Fischer, P., Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015: 18th International Conference, Munich, Germany, Springer International Publishing. Proceedings, Part III, 18: 234-241. https://doi.org/10.1007/978-3-319-24574-4_28
[27] Kingma, D.P., Ba, J. (2014). Adam: A method for stochastic optimization. arXiv Preprint arXiv: 1412.6980. https://doi.org/10.48550/arXiv.1412.6980