Kennedy Okokpujie*![]() | Imhade Princess Okokpujie
| Imhade Princess Okokpujie![]() | Roselyn Esoname Subair
| Roselyn Esoname Subair![]() | Emmanuel Oluwatobi Simonyan
| Emmanuel Oluwatobi Simonyan![]() | Adenugba Vincent Akingunsoye
| Adenugba Vincent Akingunsoye![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The advent of smart technology in urban environments has often been hailed as the solution to a plethora of contemporary urban challenges, ranging from environmental conservation to waste management and transportation. However, the critical aspect of security, encompassing crime detection and prevention, is frequently overlooked. Moreover, there is a dearth of research exploring the potential disruption of conventional face detection and recognition systems by new smart city surveillance security cameras, particularly those which autonomously update their databases. This paper addresses this gap by proposing the enhancement of security in smart cities through the development of an adaptive age-invariant face recognition (AIFR) model. A non-intrusive AIFR model was constructed using a convolutional neural network and transfer learning techniques, and was then integrated into surveillance cameras. These cameras, designed to capture the faces of city residents at regular intervals, consequently updated their databases autonomously. Upon testing, the developed model demonstrated its potential to substantially improve security by effectively detecting and identifying the residents and visitors of smart cities, and updating their database profiles. Remarkably, the model retained its effectiveness even with significant age intra-class variation, with the capability to alert relevant authorities about potential criminals or missing individuals. This research underscores the potential of adaptive face recognition systems in bolstering security measures within smart urban environments.
biometric, smart city, FG-NET ad, Age Invariant Face Recognition (AIFR), surveillance cameras, convolutional neutral network, data augmentation
Automated human face recognition, with its integral role in identification and authentication, holds indisputable significance across numerous real-world applications. This can be observed in various sectors, including security, access control as present in border control systems, voting systems, healthcare, and attendance tracking, among others [1]. However, the reliability of face recognition algorithms is often compromised over time due to intra-class differences resulting from the natural variability of the human face, an element referred to as age variance [2].
Age variance can cause 'query face templates' to be untrustworthy matches for user faces stored in databases [2]. This highlights the necessity for the development of a facial recognition system able to adapt to intra-class variations. Such a system would automatically adjust stored templates of authentic users to mitigate matching discrepancies, essentially establishing an age-invariant recognition system [3].
The global trend towards automated facial recognition is escalating, with developing countries already implementing it for security purposes in airports, offices, and access control systems [4]. However, most facial recognition systems are influenced by genetic factors such as ageing, a factor often overlooked by researchers in the design of smart cities [5]. If leveraged effectively, the creation of an invariant age facial recognition system could address the challenge of identifying individuals who utilize these systems across significant age gaps [6].
Smart cities, as per Elmaghraby and Losavio [7], are defined as the application of ICT to promote operational efficiency, independently communicate information within the system, and improve overall quality of operations and citizen wellbeing. Smart city expertise is widely hailed as the solution to numerous urban challenges including transportation, waste management, and environmental sustainability [8]. However, while designing smart city projects, researchers often neglect the aspect of security and crime prevention [9]. The potential impact of contemporary smart city security technologies on security and crime reduction is therefore rarely discussed [10, 11]. This paper aims to address this gap by developing and deploying an adaptive age invariant face recognition model to enhance security within smart cities.
Image augmentation techniques, used to artificially increase the number of images in the training dataset, create modified versions of the images in the dataset without the need for new image collection. Described as the method of creating image samples by transmuting training data, data augmentation aims to improve the accuracy and robustness of classifiers.
The primary contribution of this paper lies in the development of an adaptive age invariant face recognition model for sustainable security in smart cities. This model, when incorporated into surveillance cameras, would be able to update images despite a large range of age gaps of the same individuals (intra-class variation). A biometric trait is deemed to exhibit permanence and repeatability if its intra-class variance is low. If the intra-class variance is substantial, a biometric feature can be successfully used to differentiate between the same individuals with a different age gap. In this context, due to facial ageing, the face traits do not exhibit permanence, thereby necessitating the use of CNNs to mitigate this challenge.
1.1 Related work
The focus of this section is on the work carried out by others in actualizing their AIFR model, with an emphasis on the achieved percentage accuracy. It is worth noting that no attempts have been made to implement these developed models in smart city environments.
Li et al. [12] utilized a Discriminative Model for Age Invariant Face Recognition. The authors acknowledged the difficulty in creating effective feature representation and a functional corresponding structure for age-invariant facial recognition software. They proposed a discriminative model to handle face matching in the presence of age variation, achieving a recognition accuracy of 47.50%.
El Khiyari and Wechsler [13] developed a deep learning and set-based method of recognizing faces, with their experimental outcomes confirming improved performance compared to the singleton-based method for face identification and authentication.
Zhou and Lam [14] proposed an Ageing-Guided Identity-Inference Model (AG-IIM), based on autonomous ageing subspace learning for Age-Invariant Face recognition. Using the FGNET data for their face recognition study, their experimental findings on the AG-IIM showed training and verification accuracy of 89.8% and 88.2% respectively.
Li et al. [15] presented an innovative distance metric optimization focused culture method. Their model was evaluated, achieving a verification accuracy of 91.1%.
Despite the high accuracies achieved by various models proposed by these researchers, most studies have not made efforts towards developing an adaptive age invariant face recognition model for enhancing sustainable security in smart cities.
2.1 Complexities and specifications of the dataset
The 1002 samples in the FG-NET collection are from 82 different people who range in age from babies to 69 years old. However, the statistics shows a predominance of ages up to 40. The value of the photographs depends on the skill of the photographer, the cost of the graphic paper, and the equipment used to take the pictures. This was the case because, with the exception of the additional, brand-new digital photos, the majority of the images used came from people's personal collections. Significant differences may be seen in the images' resolution, picture sharpness, illumination, background, viewpoint, and facial expression. This made the data for age-invariant facial recognition extremely baffling. Additionally, hats, facial hair, and eyeglasses served as occlusions in a number of images [16].
2.2 Inception ResNet-v2
More than a million images from the ImageNet dataset were used to train Inception-ResNet-v2. In recent years, various convolution neural network architectures have been subjected to picture challenges using the open-source ImageNet large-scale visual recognition dataset. CNN Inception-ResNet-v2 is well known. This CNN has 164 layers and can classify photos into 1,000 different object classes. Figure 1 shows the exact structure of the stem layer. The input image size is 299×299 as well. In this study, to train an Inception-ResNet-v2 system to learn representative features from the FG-NET database for Age-Invariant Face recognition, transfer learning was used. This system has already mastered the art of extracting useful information from raw images [17-23].
The first part of Figure 1 further shows the block diagram for the modified ResNet-v2 Network used in the Age-Invariant Face recognition model. The input represents the pre-processed and augmented images, while the stem represents the part of the convolutional neural network called the residual network as shown in section 2.2.1. Furthermore, the stem does the initial convolution operations on the input images. The Inception-ResNet-A represents the first Inception module that performs the next convolutional operations. This operation is repeated five times. Reduction block A performs the first dimension reduction through max-pooling and passes its output to the next Inception module called Inception-ResNet-B. Inception-ResNet-B performs the convolution operation, and the operation repeats ten times. The Reduction-B block also carries out dimension reduction using max-pooling. The final Inception module is called Inception-ResNet-C, which does the final convolution and assigns the final weights/biases on the images. Dropout is performed, and average pooling makes a final dimension reduction. From the stem to the average-pooling layer are used to learn and extract the image features. While the final layer called Softmax is used to classify the images from the features learned (for this application; only eighty-two (82) classes. Through the instruments of transfer learning and loss function, the proposed model can classify face images correctly even with the interference of “trait-ageing”, after several epochs. Thus, making the proposed model “age-invariant”.
2.2.1 Calculations of the stem for inception ResNet-v2
The detailed structure of the stem layer and formula for the calculation of the output of the stem is as shown in Figure 1 and Eq. (1) respectively.
Output $=\frac{n+2 p-f}{s}+1$ (1)
where,
n=input image,
p=padding,
f=filter size, and
s=stride
Input image size and channel=299×299×3
For layer one
n=299, p=0, f=3, s=2
Substituting these value into Eq. (1)
Output $=\frac{299+2(0)-3}{2}+\mathbf{1}=$=149×149×32
For 149×149×32
For layer two
n=149, p=0, f=3, s=1
Output $=\frac{149+2(0)-3}{1}+1$=147×147×32
For 147×147×32
For layer three
n=147, p=1, f=3, s=1
Output $=\frac{147+2(1)-3}{1}+1$=147×147×64
For 147×147×64
For layer four A
n=147, p=0, f=3, s=2
Output $=\frac{147+2(0)-3}{2}+1$=73×73×64
For 147×147×96
For layer four B
n=147, p=0, f=3, s=2
Output $=\frac{147+2(0)-3}{2}+1$=73×73×96
Filter concatenation
Output=73×73×(64+96)=73×73×160
For layer five A
For 73×73×64
n=73, p=0, f=3, s=1
Output$=\frac{73+2(0)-3}{1}+\mathbf{1}$=71×71×96
For 73×73×64
For layer five B
n=73, p=0, f=3, s=1
Output $=\frac{73+2(0)-3}{1}+\mathbf{1}$=71×71×96
Filter concatenation
Output=71×71×(96+96)=71×71×192
For 71×71×192
For layer six A
n=71, p=0, f=3, s=2
Output $=\frac{71+2(0)-3}{2}+\mathbf{1}$=35×35×192
For 71×71×192
For layer six B
n=71, p=0, f=3, s=2
Output $=\frac{71+2(0)-3}{2}+\mathbf{1}$=35×35×192
Filter concatenation
Output=35×35×(192+192)=35×35×354
Final output from the stem in Inception-ResNet-V2=35×35×384
Figure 1. Schema for ResNet-v2 Network showing the detailed structure of the stem layer [18]
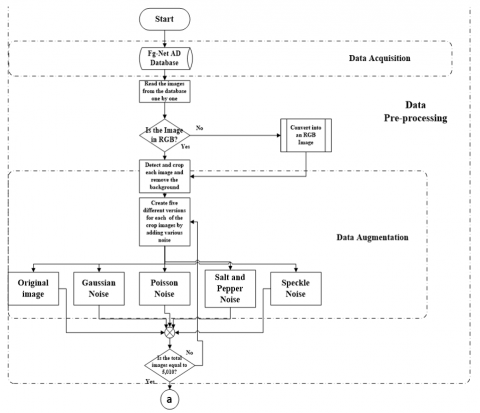
In addition, Figure 2 presents the flowchart of the proposed development AIFR data augmentation phase. Also, Table 1 shows the detailed information of the modified Inception ResNet-v2 network architecture. The Table shows the designed specification of the type of processes, image size input fed to each layer, the patch dimension and strides.
2.3 FG-NET dataset pre-processing
CNN models require a massive quantity of datasets for learning. Meanwhile, the FG-NET dataset comprises about 10 to 15 sample imageries of one subject at dissimilar ages; which is actual few dataset for Convolutional Neural Network experimentation. The dataset was pre-processed to enhance the samples and augment the amount of samples for improved feature extraction utilizing a Convolutional Neural Network. The individual samples were read one by one from the dataset, and subsequently, some procedures were executed, as shown in Figure 1.
Increased image count in the dataset, less over-fitting in the algorithm, and improved feature extraction are all benefits of adding noise. Data augmentation is the process of adding noise to photos in order to boost the quantities [24]. The idea of data augmentation has a long history in literature and everyday life [25-31]. As a result, we were able to collect a pre-processed FG-NET dataset that included 5010 total face photos and an average of 60 face images per person. This amount of dataset is considered suitable for Convolutional Neural Network experimentation.
2.4 Training and development of the AIFR model
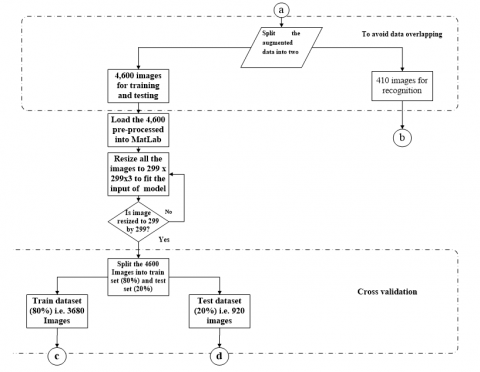
Figure 3 and Figure 4 display the flowchart of how the AIFR model was trained and developed using transfer learning on the training dataset derived on the pre-trained Inception-ResNet-v2 network.
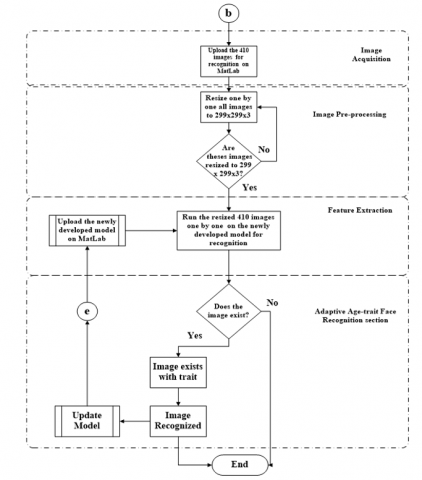
Figure 5 shows the flowchart for the application of the adaptive AIFR model in Smart cities. The connection b in Figure 4 was the 410 images separated for recognition purposes, as presented in Figure 1. These images have not been seen (for training) nor used (for testing) by the developed AIFR model to avoid cross-data overlapping.
2.5 System specification
In about 10 hours, the training, testing, and recognition were accomplished on a 64GB RAM with Core i7 CPU processor and Figure 5 depicts the training and testing experimental progress charts, which represent the loss and accuracy of the system at each epoch and iteration.
Table 1. The outline of the modified inception ResNet network architecture
|
Type |
Input Size |
Patch Dimension/Stride |
|
Convolution |
299×299×3 |
3×3/2 |
|
Convolution |
149×149×32 |
3×3/1 |
|
Convolution padded |
147×147×32 |
3×3/1 |
|
Max Pool |
147×147×64 |
3×3/2 |
|
Convolution |
73×73×160 |
3×3/1 |
|
Convolution |
71×71×192 |
3×3/2 |
|
Convolution |
35×35×384 |
3×3/1 |
|
5×Inception-ResNet-A |
35×35×256 |
- |
|
Reduction-A |
17×17×896 |
- |
|
10×Inception-ReseNet-B |
17×17×896 |
- |
|
Reduction-B |
8×8×1792 |
- |
|
5×Inception-ResNet-C |
8×8×1792 |
- |
|
Average Pooling |
1792 |
8×8 |
|
Dropout |
1792 |
Keep 0.8 |
|
Softmax |
82 |
Classifier |
Table 2 summarizes the results and the simulated parameters of the adaptive age invariant face recognition model for enhanced security in smart cities.
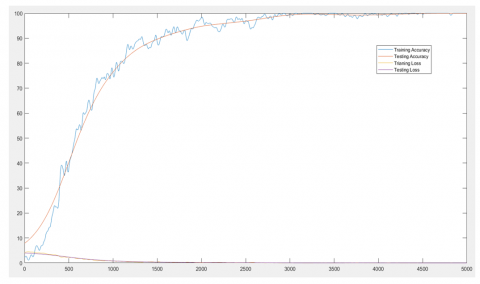
Figure 5 depicts the suggested age invariant face recognition model's accuracy and loss (error). Where the x-axis and y-axis represent the accuracy/loss and Iteration, respectively. It was found that the training accuracy was 100%, the post training and transfer learning were used to learn and fix the model's parameters.
Figure 5. The flowchart for the application of the adaptive AIFR model in smart cities
A comparison with the ground truth recognized during testing and the test photos fed into the CNN model produced an accuracy of 99.94%. This shows that the CNN accurately classified nearly all of the test imageries it was fed.
Utilizing the negative log-likelihood, a little loss (error) was calculated. The model accurately interpreted the training and testing data.
As the number of epochs grew, the total number of errors committed throughout training and testing continued to decline.
On both the training and testing data, the loss function values for the learning model are well-minimized. of 0.008% and 0.003%, respectively after 50 epochs at 5000 iterations.
Finally, Figure 6 shows the percentage training and testing loss and accuracy graphical representation.
Figure 6. Percentage training and testing loss and accuracy graphical representation
Table 2. Result and simulation parameters summary table
|
1. Experimental Results |
|
|
i. Training Accuracy |
100% |
|
ii. Testing Accuracy |
99.94% |
|
iii. Training Loss |
0.008% |
|
iv. Testing Loss |
0.003% |
|
2. Simulation Parameters |
|
|
i. Learning Rate Schedule |
Constant |
|
ii. Learning Rate |
0.01 |
|
iii. Weight Delay |
0.00004 |
|
iv. Batch normalization Decay |
0.9997 |
|
v. Batch normalization Epsilon |
0.001 |
|
vi. Dropout Keep Probability |
0.8 |
This paper proposes improving security in smart cities using adaptive age invariant face recognition model.
FG-NET ageing dataset was adopted and augmented by injecting four kinds noises, thereby expanding the dataset and making it appropriate for convolutional neural network processing. An AIFR model was developed using pre-trained CNN with several processes such as training, testing, etc. Integrating and deploying the developed AIFRT model would be found to be capable of identifying persons over long age intervals of the smart city dweller and updating its database overtime. The AIFR model will help to detect criminals and missing persons in respective the time lag and alert the appreciate authorities.
We acknowledge the part sponsorship of Covenant University Center for Research and Innovation and Development (CUCRID), Ota, Ogun State, Nigeria.
[1] Okokpujie, K., Noma-Osaghae, E., John, S., Grace, K.A., Okokpujie, I. (2017). A face recognition attendance system with GSM notification. In 2017 IEEE 3rd International Conference on Electro-Technology for National Development (NIGERCON), Owerri, Nigeria, pp. 239-244. https://doi.org/10.1109/NIGERCON.2017.8281895
[2] Okokpujie, K., Noma-Osaghae, E., John, S., Oputa, R. (2017). Development of a facial recognition system with email identification message relay mechanism. In 2017 International Conference on Computing Networking and Informatics (ICCNI), Lagos, Nigeria, pp. 1-6. https://doi.org/10.1109/ICCNI.2017.8123776
[3] Charity, A., Okokpujie, K., Etinosa, N.O. (2017). A bimodal biometrie student attendance system. In 2017 IEEE 3rd International Conference on Electro-Technology for National Development (NIGERCON) Owerri, Nigeria, pp. 464-471. https://doi.org/10.1109/NIGERCON.2017.8281916
[4] Noma-Osaghae, E., Robert, O., Okereke, C., Okesola, O. J., Okokpujie, K. (2017). Design and implementation of an iris biometric door access control system. In 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, pp. 590-593. https://doi.org/10.1109/CSCI.2017.102
[5] Okokpujie, K., Noma-Osaghae, E., Okesola, O., Omoruyi, O., Okereke, C., John, S., Okokpujie, I.P. (2019). Fingerprint biometric authentication based point of sale terminal. In Information Science and Applications 2018: ICISA 2018, Springer Singapore, pp. 229-237. https://doi.org/10.1007/978-981-13-1056-0_24
[6] Okokpujie, K., Noma-Osaghae, E., Okesola, O., Omoruyi, O., Okereke, C., John, S., Okokpujie, I.P. (2019). Integration of iris biometrics in automated teller machines for enhanced user authentication. In Information Science and Applications 2018: ICISA 2018, Springer Singapore, pp. 219-228. https://doi.org/10.1007/978-981-13-1056-0_23
[7] Elmaghraby, A.S., Losavio, M.M. (2014). Cyber security challenges in Smart Cities: Safety, security and privacy. Journal of Advanced Research, 5(4): 491-497. https://doi.org/10.1016/j.jare.2014.02.006
[8] Ankitha, S., Nayana, K.B., Shravya, S.R., Jain, L. (2017). Smart city initiative: Traffic and waste management. In 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, pp. 1227-1231. https://doi.org/10.1109/RTEICT.2017.8256794
[9] Gohar, M., Muzammal, M., Rahman, A. U. (2018). SMART TSS: Defining transportation system behavior using big data analytics in smart cities. Sustainable Cities and Society, 41: 114-119. https://doi.org/10.1016/j.scs.2018.05.008
[10] Laufs, J., Borrion, H., Bradford, B. (2020). Security and the smart city: A systematic review. Sustainable Cities and Society, 55: 102023. https://doi.org/10.1016/j.scs.2020.102023
[11] Patel, J., Wala, H., Shahu, D., Lopes, H. (2018). Intellectual and enhance digital solution for police station. In 2018 International Conference on Smart City and Emerging Technology (ICSCET) Mumbai, India, pp. 1-4. https://doi.org/10.1109/ICSCET.2018.8537378
[12] Li, Z., Park, U., Jain, A.K. (2011). A discriminative model for age invariant face recognition. IEEE Transactions on Information Forensics and Security, 6(3): 1028-1037. https://doi.org/10.1109/TIFS.2011.2156787
[13] El Khiyari, H., Wechsler, H. (2017). Age invariant face recognition using convolutional neural networks and set distances. Journal of Information Security, 8(3): 174. https://doi.org/10.4236/jis.2017.83012
[14] Zhou, H., Lam, K.M. (2018). Age-Invariant Face recognition based on identity inference from appearance age. Pattern Recognition, 76: 191-202. https://doi.org/10.1016/j.patcog.2017.10.036
[15] Li, Y., Wang, G., Nie, L., Wang, Q., Tan, W. (2018). Distance metric optimization driven convolutional neural network for age invariant face recognition. Pattern Recognition, 75: 51-62. https://doi.org/10.1016/j.patcog.2017.10.015
[16] Okokpujie, K., John, S., Ndujiuba, C., Badejo, J.A., Noma-Osaghae, E. (2021). An improved age invariant face recognition using data augmentation. Bulletin of Electrical Engineering and Informatics, 10(1): 179-191. https://doi.org/10.11591/eei.v10i1.2356
[17] Krizhevsky, A., Sutskever, I., Hinton, G.E. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6): 84-90. https://doi.org/10.1145/3065386
[18] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-9. https://doi.org/10.1109/CVPR.2015.7298594
[19] Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/arXiv.1409.1556
[20] He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778.
[21] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818-2826. https://doi.org/10.48550/arXiv.1512.00567
[22] Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A. (2017). Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, 31(1): 4278-4284. https://doi.org/10.1609/aaai.v31i1.11231
[23] Kamarajugadda, K.K., Polipalli, T.R. (2019). Age-Invariant Face recognition using multiple descriptors along with modified dimensionality reduction approach. Multimedia Tools and Applications, 78: 27639-27661. https://doi.org/10.1007/s11042-019-7741-y
[24] Okokpujie, K., Apeh, S. (2020). Predictive modeling of trait-aging invariant face recognition system using machine learning. In Information Science and Applications: ICISA 2019, Springer Singapore, pp. 431-440. https://doi.org/10.1007/978-981-15-1465-4_43
[25] Shorten, C., Khoshgoftaar, T.M. (2019). A survey on image data augmentation for deep learning. Journal of Big Data, 6(1): 1-48. https://doi.org/10.1186/s40537-019-0197-0
[26] Okokpujie, K., John, S., Ndujiuba, C., Noma-Osaghae, E. (2020). Development of an adaptive trait-aging invariant face recognition system using convolutional neural networks. In Information Science and Applications: ICISA 2019, Springer Singapore, pp. 411-420. https://doi.org/10.1007/978-981-15-1465-4_41
[27] Aquino, N.R., Gutoski, M., Hattori, L.T., Lopes, H.S. (2017). The effect of data augmentation on the performance of convolutional neural networks. In Brazilian Society of Computational Intelligence, Niteroi, Rio, Janeiro, pp. 1-12.
[28] Yan, C., Meng, L., Li, L., Zhang, J.H., Wang, Z., Yin, J., Zhang, J.Y., Sun, Y.Q., Zheng, B.L. (2022). Age-Invariant Face recognition by multi-feature fusionand decomposition with self-attention. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 18(1s): 1-18. https://doi.org/10.1145/3472810
[29] Tripathi, R.K., Jalal, A.S. (2022). A robust approach based on local feature extraction for age invariant face recognition. Multimedia Tools and Applications, 81(15): 21223-21240. https://doi.org/10.1007/s11042-022-12783-6
[30] Xie, J.C., Pun, C.M., Lam, K.M. (2022). Implicit and explicit feature purification for age-invariant facial representation learning. IEEE Transactions on Information Forensics and Security, 17: 399-412. https://doi.org/10.1109/TIFS.2022.3142998
[31] Dharavath, K., Gaini, A., Adla, V. (2022). A Parallel Deep Learning Approach for Age Invariant Face Recognition system. In 2022 International Conference on Computer Communication and Informatics (ICCCI) Coimbatore, India, pp. 1-6. https://doi.org/10.1109/ICCCI54379.2022.9740907