Maturi Sreerama Murty* | Nallamothu Nagamalleswara Rao
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Following the accessibility of Resource Description Framework (RDF) resources is a key capacity in the establishment of Linked Data frameworks. It replaces center around information reconciliation contrasted with work rate. Exceptional Connected Data that empowers applications to improve by changing over legacy information into RDF resources. This data contains bibliographic, geographic, government, arrangement, and alternate routes. Regardless, a large portion of them don't monitor the subtleties and execution of each sponsored resource. In such cases, it is vital for those applications to track, store and scatter provenance information that mirrors their source data and introduced tasks. We present the RDF information global positioning framework. Provenance information is followed during the progress cycle and oversaw multiple times. From that point, this data is appropriated utilizing of this concept URIs. The proposed design depends on the Harvard Library Database. The tests were performed on informational indexes with changes made to the qualities??In the RDF and the subtleties related with the provenance. The outcome has quieted the guarantee as in it pulls in record wholesalers to make significant realities that develop while taking almost no time and exertion.
provenance, semantic web, linked data, LOD
Unquestionably, one of the fundamental positions of provenance has been to help examples of attribution and legitimacy, and in this way of significant worth for material things (for example artful culminations, special copies, and so on.). In science, provenance is required to give proof on the fundamental results that help insightful flows. The vitality of provenance truly applies in e-Science settings, where the information is acquired through computational techniques. In these cases, the provenance of the exploratory result is reliably a chart made record out of the individual computational advances, which is recorded in this way, at the degree of detail appeared by the structure instrumentation [1]. This sort of provenance, fittingly encoded for machine dealing with, would then have the choice to be mistreated utilizing an assortment of graph solicitation and assessment devices.
This scenario, where any bit of intelligent knowledge obtained by a computer system is linked to its provenance, is becoming consistently common [2]. Composed execution follows are collected reliably by various commonly used workflow management systems, including Pegasus, and others with regard to job steps [3]. Nonetheless, these systems also have restrictive models for coding the provenance of job measure executions. Furthermore, they get various models to choose the work estimates themselves. Such heterogeneity makes it hard for a pro to dissect and analyze provenance follows discovered utilizing the corresponding or close to work quantifies that were shown and affirmed utilizing various structures [4]. The nonattendance of a standard model for tending to work measure provenance comparably induces that open portals for sewing the follows made by various work measures, and in like manner helping the master in her appraisal, are likely going to be missed [5].
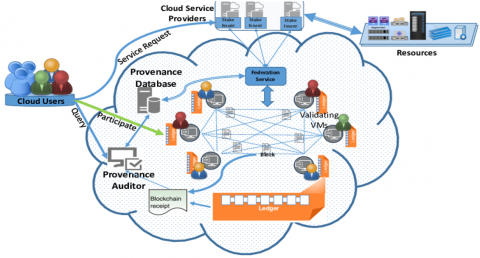
This record presents ProvONE, a model for genuine work measure provenance that plans to satisfy the necessities of the ideal norm [6]. The name begins from its progress regarding the DataONE Project, which is making an enormous expansion and joined information structure serving the examinations of the planet association. Considering, ProvONE is intended to help a colossal mix of WfMSs that in this manner are utilized by various standard researchers. The architecture of cloud based provenance model for resource tracking is shown in Figure 1.
Information lakes are getting a ton of consideration meanwhile. Organizations definitely know the contrast between information stockpiling and information pools. (Suggested Blog Posts - Inevitable Transition from Data Storage to Data Pools) Data pools contain information from different sources inside an association and can be long [7]. It is along these lines critical to discover approaches to record information from its source to the information pool and past. It is otherwise called "Information Provence".
We can understand how creativity in the block chain will assist with the creation of knowledge pools. Information pools isolate information within the association from various properties [8]. In the block chain network, this source of knowledge can be viewed as a record. The source must record the crude information or its hash on the block chain network as a major aspect of the review trail any time a lot of information enters from the data pool source. Using the source account in the block chain and therefore labelled with the source program, this record will be included. This will allow us to confirm later that by testing the block chain, the important information is really accessible from trusted data. Confirmation is completed by resetting and comparing the hash in the data with the hash etched on the square [9]. Notice that the hash-containing record is now labelled in the source code, which then indicates that the data was actually collected from an accurate, reliable source [10].
As this information is refined and refined, the exhibition result is returned in the block chain [11]. Likewise, when information is aggregated or ordered, it is written in block chain [12]. Along these lines, a totally unaltered record of information examination is made in the information pool, which can be confirmed that information.
Note that block chain can record total crude information (unwritten or encoded) or hash of crude information [13]. The previous guarantees that you have total information accessible on the block chain for some time later, yet this likewise implies extra pointless stockpiling [14]. Finally it guarantees that your block chain sparkles, giving you a similar degree of verification benefits [15].
Figure 1. Architecture of cloud based provenance model for resource tracking
The RDF information model is like the old demonstrating techniques, (for example, business-class connections or class drawings) [16]. In view of the idea of offering expressions about assets (particularly web assets) in the structure title-object-object structure, known as triple [17]. RDF is an unambiguous model with numerous kinds of serialization (for example record designs), so the establishment of a particular asset code or triple changes relying upon the configuration [18].
Ali et al. [1] addressed cloud computing as a technological transition for third parties named service providers to offer services remotely. Service providers keep our data secure and we have no influence over our data. This means that while cloud computing minimizes corporate spending for storage and maintenance of the data and the management of resources, malicious insider attacks in the cloud environment constitute the key security concern. Security is therefore one of the most important issues that impede cloud growth. This paper explores all the advantages, the basic features, cloud computing service models in depth and describes the different motivations of malicious insider users.
Aman et al. [3] has identified the provision of resources that enables users and providers to access specified resources in accordance with their resource availability in VOs. Grid scheduling decides to assign jobs to resources across various administrative realms. The main purpose of the new resource provision and resource scheduling is to give Grid users and non-users advance services rights while following QoS parameters.
The Virtual Organizing Clusters (VOC) architecture developed by Bauer et al. [4] offers a mechanism whereby each VO has its own dedicated Grid clusters. The size and the number of jobs submitted by the user may be dynamically extended, contracted, instantiated or terminated.
Bharadwaj et al. [6] introduced a model for high-power distributed computer management that describes a network of logical machines over time and space. In this work, a resource management system was used to supply resource and resource abstracted over large-scale distributed resources through resource programming. Virtualization has been considered for timely targeted applications in the Grid environment.
This strategy for characterizing assets is vital to W3C's Semantic Web work: The rise period of the World Wide Web where robotized programming can store, trade, and use machine-coherent data appropriated over the Web, empowering clients to manage effective and solid data. Straightforward RDF information model and the capacity to demonstrate an alternate, vague idea have additionally prompted its expanding use in data the board frameworks inconsequential to crafted by Semantic Web.
The arrangement of RDF proclamations plainly speaks to a named, directed diagram. This in principle makes the RDF information model more reasonable for particular kinds of data portrayal than different sorts of connections or ontological. In any case, truly, RDF information is typically put away in an information base of connections or local introductions (likewise called Triplestores — or Quad stores, if a diagram like substance named is additionally put away in the RDF multiple times each).
The title of the RDF proclamation can be a similar asset identifier called URI, the two of which demonstrate assets. Assets showed on void hubs are called unknown sources. They are not straightforwardly distinguished in the RDF proclamation. The predicate is a URI that additionally shows the application, speaking to the relationship. The item is a URI, a clear hub or a genuine Unicode string.
In Semantic online apps, just as in well-known RDF projects, for example, RSS and many other assets are regularly spoken to by URIs that mean deliberately, and can be utilized to get to, genuine information on the online. Notwithstanding, the RDF, all in all, isn't restricted to the meaning of Internet-based assets. Actually, the URI naming the application shouldn't be regarded by any means. For instance, a URI that begins with "http:" and is utilized as the subject of an RDF proclamation doesn't have to speak to a HTTP-open assistance, nor does it have to speak to an obvious, network-empowered help - such URI can speak to anything. In any case, there is an overall understanding that a vacant URI that profits a 300-level reaction when utilized in a HTTP GET application ought to be treated as a sign of an effective web access.
In this manner, producers and purchasers of RDF proclamations must concur on the semantics of asset references. Such an arrangement isn't in accordance with the RDF itself, in spite of the fact that there are some controlled terms that are ordinarily utilized, for example, the DCore Metadata, which are recorded to some extent in the URI region for use in the RDF. The motivation behind distributing RDF-put together ontologies with respect to the web is ordinarily to build up, or skip, directed unmistakable depictions of the gadgets used to produce information on the RDF. For instance, URI.
3.1 Open provenance model
OPM is a finished completing model for cautiously separating the beginning of anything on the web [6]. OPM permits provenance information to be showcased between various divisions, similarly as arrangement assists with making provenance systems dependent on a common provenance model [6]. OPM depends on three components. The reason for OPM is to discuss how things came to fruition and how they are happy to consider their various areas at various occasions. The condition of the data object is talked about utilizing the relics presented in the cycle. The cycle is hindered by the supplier. Provenance information is caught as an outline that contains a component, a cycle and an administrator. The chart portrays different circumstances and connections between objects.
3.2 Provenance vocabulary
It is a case of exhibiting the accessibility of web data. This model essentially centers around giving data about data preparing, the executives space, creation rules, remainders and performers engaged with making data. The Provenance Vocabulary utilizes area 8 http://openprovenance.org/9 http://trdf.sourceforge.net/provenance/ns.html 10 http://www.w3.org/TR/prov-preparation/11 http: Chart of/semanticweb.org/wiki/VoID to show web data containing three kinds of apparatuses: Actors, Execution, and Artifacts. It uncovers that media outlets are in a condition of motion. The performers alluded to the data wholesalers who utilized the other data that gave the kinds of administrations. Antiquated discovers allude to data objects, for instance, the RDF information base or resources. Certain components of the provenance type produce provenance information and administer associations with one another.
Surmising Web is an information base dependent on Semantic Web that underpins intuitive depictions of sources, ideas, study information, and reactions as a confided in supplier. Provenance - if clients (people and operators) utilize and aggregate information from obscure, dubious, or numerous sources, they need metadata to start cooperation testing - numerous projects utilize various assets and motors to control data, in this way expanding joint effort needs Description/Correction - if information is utilized (for example , by sound or by working techniques), following data ought to be accessible to the Trust - if a few sources are more dependable than others, dependability guidelines are required The Inference Web has two key highlights: Proof Markup Language (PML) Ontology - Semantic Web based Definitions including subtleties of provenance - portraying wellsprings of data - determining steps to reach determinations or making subtleties of work processes trust - depicting solid check about data and assets IW unit Tool - Web-based and independent apparatuses that permit singular clients to peruse, investigate, decipher, and separate data inserted in the PML.
The RD Framework is a norm for characterizing assets. What is an application? That is a significant inquiry, and the exact clarification is still there. With our expectations we can consider it anything we can see. You are an asset, similar to your landing page, this instructional exercise, number one and large white whale in Moby Dick.
Our good examples in this examination will be individuals. They use RDF portrayal for VCARDS. RDF is best idea of as hub and circular segment charts. A straightforward vcard may resemble this on RDF:
The asset, John Smith, is appeared as a circle and is recognized by URI 1, in this "http:/.../JohnSmith". In the event that you attempt to get to that asset utilizing your program, you will presumably not succeed; April's first appealing jokes, you may be shocked if your program can carry John Smith to your table at the top. In the event that you are new to URIs, consider them words that look abnormal.
Assets have properties. In these models we are keen on the kind of properties that will show up on John Smith's business card. Figure 1 shows just a single property, the complete name of John Smith. The structure is spoken to by a curve, marked with the name of the structure. The name of the structure is likewise a URI, yet since the URIs are long and complex, the drawing shows it in the XML qname structure. The part previously ':' is called toward the start of the space name and speaks to the spot name. The part after the ':' is named after the spot and speaks to the name in that name space. Properties are generally spoken to in this type of qname when they are composed as RDF XML and are an ideal rundown of the pictures and text. Solidly, nonetheless, the properties are controlled by URI. The nsprefix: localname structure could be a shorthand for the URI of the namespace concatated with the localname. The Properties URI does not ought to verify something once gotten to by the program.
Every benefit has a worth. For this situation the worth is genuine, which we would now be able to consider as strings2. Liters are appeared in a square shape.
Essential RDF model
The RDF establishment is a model for speaking to land and property estimations. The RDF model uses settled standards from an assortment of agent networks. RDF structures can be considered as images of assets and in this sense are related with sets of customary descriptive word esteems. RDF structures likewise speak to the connection among assets and the RDF show and consequently can be like a business relationship graph. (In particular, RDF Schemas - which are average of RDF information types - are ER graphs.) For the situation of item plan, assets are related with articles and structures that compare to display fluctuation. The RDF information model considers the resources using the equation:
$\mathrm{R}\left(P\left[l_{i}, l_{j}, . . N\right]\right)=\sqrt{\sum_{l=\mathrm{i}}^{\mathrm{N}}\left(T-R s_{n}\left(I\left[l_{s}, l_{f}\right]\right)\right)^{2} \times P_{l}^{I\left[l_{s}, l_{f}\right]}}$ (1)
The RDF information model is a nonpartisan represent RDF talks. Portrayal of the information model is utilized to test the precision of the definition. The two RDF articulations are equivalent if and just if their information model introductions are the equivalent. This meaning of condition takes into consideration some syntactic variety in discourse without adjusting the significance.
The essential information model has three kinds of things:
Resources All the components characterized by the RDF articulations are called assets. The asset can be a whole Web page; as the HTML text "http://www.w3.org/Overview.html" for instance. The asset can be essential for a Web page; for example, something HTML or XML object inside an archive source. The asset can likewise be a finished arrangement of pages; for example, the whole site. The asset can likewise be something that isn't legitimately accessible through the Web; for example, printed book. Assets are typically dictated by URIs and discretionary id stays (see [URI]). Anything can have a URI; an expansion in URIs permits the presentation of the identifiers of any business you can envision. For every resource weights are allocated as:
$W(R(i, N))=\sum_{i=1}^{n} \frac{R(p)+\sum_{i}^{M} \operatorname{Ar}(i+1) *(i-j)^{2}}{(i-j)^{2}+R(W)}$ (2)
Properties An advantage is a particular component, characteristic, property, or relationship used to depict an instrument. Every benefit has a particular significance, depicts its allowed qualities, sorts of gear that can be characterized, and its relationship to different properties. This record doesn't cover how the basic components are communicated; For subtleties, see the subtleties of the RDF Schema). The properties for every resource are allotted as:
$P(R S(i, N))=\sum_{i} \sum_{j} \frac{\left(W(R(i))-W_{u}\right)\left(R S(j)-W_{v}\right)}{\sigma_{i j}}$ (3)
Statements A particular thing and structure named and the estimation of that benefit is utilized in an RDF explanation. These three pieces of an announcement are called, in arrangement, title, relational word, and item. The announcement thing (e.g., estimation of the benefit) might be from another source or might be real; e.g., a utility (articulated URI) or a basic link or other kind of old information characterized by XML. Regarding RDF terms, the first may contain XML light substance yet isn't additionally tried by the RDF processor. The Table 1 represents the evaluation results with provenance levels.
As appeared in Figure 2, resource subtleties close to source information, master information as approved information is gone into the customer. In the following segment, the data expert explores the data to be dealt with. This will guarantee that the data gave can be taken care of by the data handling association. The evaluation results of linked data with provenance are represented in Table 2. The data change measure assumes control over all the data, changing over it into RDF and Linked Data.
Table 1. Evaluation results (legacy record to RDF with provenance)
|
Dataset |
No. of Legacy Record |
Time to convert Legacy record to RDF without Provenance (in Seconds) |
Time to convert Legacy record to RDF with Provenance (in Seconds) |
Number of RDF Resource (in %) |
|
Dataset 1 |
100000 |
28s |
52s |
96% |
|
Dataset 2 |
100000 |
24s |
50s |
97% |
|
Dataset 3 |
100000 |
21s |
45s |
87% |
|
Dataset 4 |
100000 |
16s |
39s |
100% |
|
Dataset 5 |
100000 |
18s |
40s |
94% |
|
Dataset 6 |
100000 |
23s |
48s |
87% |
Table 2. Evaluation results (legacy record to linked data with provenance)
|
Dataset |
No. of Legacy Record |
Time to convert Legacy record to RDF without Provenance (in Seconds) |
Time to convert Legacy record to RDF with Provenance (in Seconds) |
Number of RDF Resource (in %) |
|
Dataset 1 |
100000 |
31243s |
31904s |
96% |
|
Dataset 2 |
100000 |
27209s |
29138s |
97% |
|
Dataset 3 |
100000 |
28971s |
31278s |
87% |
|
Dataset 4 |
100000 |
30929s |
39614s |
100% |
|
Dataset 5 |
100000 |
32138s |
33860s |
94% |
|
Dataset 6 |
100000 |
19260s |
21156s |
87% |
Naturally, Semantic MediaWiki (SMW) stores all information in similar connections information base (normally, MySQL information base) utilized by MediaWiki. This guarantees simple arrangement; however the relationship information base is anything but a decent method to store semantic information. The regular information model for SMW information is RDF, an information design that sorts out information on diagrams and not on composed information tables. Luckily, it is conceivable to utilize RDF-based frameworks, by coordinating a standard SQL information base, to oversee and question SMW information. This page clarifies the subtleties. Regardless of whether the RDF store can be utilized for a specific week relies upon numerous variables, including the particular RDF information base utilized. In any case, we can sensibly anticipate the accompanying:
In the language of the SPARQL query, RDF stores are intended to respond to inquiries. In this language, SMW requests can be communicated more naturally than the SQL inquiry language of related data. SMW inquiries are the standard use of RDF knowledge base frameworks along these lines, while the standard use of similar information frameworks is. In addition, various critical knowledge-related information methods are useless or misleading to SMW inquiries. It can therefore be common for RDF stores to deliver elevated query execution.
RDF stores uphold the SPARQL standard and permit different applications to approach SPARQL inquiries for their subtleties without heading off to the SMW frontend. This takes into consideration effective utilization of wiki information in different applications. Some operational information bases of SPARQL further help (sometimes) the language of OWL 2 metaphysics and give interoperable connection to inquiry the data set (for example by means of OWL Link convention). Semantic Web applications likewise utilize standard libraries, (for example, librdf or OWL API) that can help coordinate them with other low-level apparatuses.
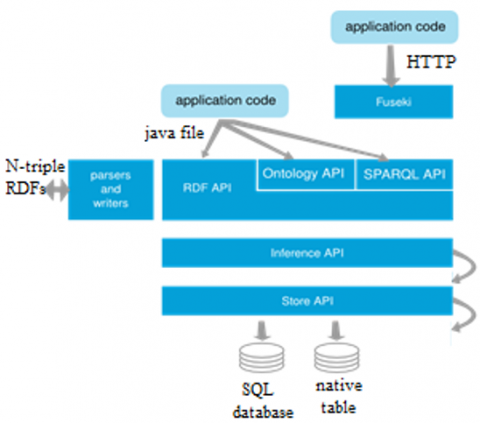
Utilizing a backend information base not at all like MediaWiki gives a simple method to circulate assignments over different workers. Specifically, complex inquiries can be kept from influencing the essential usefulness of the wiki, regardless of whether it startlingly expends a denied measure of PC power, e.g., in the event that they execute a worker that runs the RDF information base. The architecture view of AllegroGraph is shown in Figure 2 that represents the complete process performed for resource stalking.
Figure 2. Architecture view of AllegroGraph
Mplementations of Triplestores
A. 3 store
The traits of this dispatch area unit as per the following: Ts = right, Qs = SP ARQL, Ss = string_id, Js = RDBMS_based, Ds = RDB, Fs = T Box, Dm = none, Qm = none, Sm = none. Store three [13] was at first utilised for net linguistics applications significantly for record repositing hyphen.info RDF informationrmational assortment, that portrays software package engineering esearch within the Great Britain. The last variety of the data contained of five,000 categories and around twenty million thrice. 3store was sent on head of the MySQL info the executives framework. It enclosed easy discourteous talents as an example classification, sub class, what is a lot of, inquiries below the property, utilised principally by MySQL inquiry techniques. Hashing is used to decipher URIs it's become an indoor portrayal. 3store inquiry motor uses RDQL question language portrayed toward the beginning of the pitched battle venture structure. RDQL Triple articulations area unit initial reborn into connected measurements. Difficulties area unit superimposed to connected numerical talks reborn into SQL. The thought is used by a mix of forward and switch around associations checked info results.
B. 4 store
The qualities of this dispatch area unit as per the following: Ts = right, Qs = SP ARQL, Ss = string_id, Js = standard_in request, Ds = RDB, Dm = hash, Qm = data_parallel, Am = nothing. 4store [14] was planned what is more, was utilised to support a summation of novel applications from the linguistics net. RDF knowledge subtleties worked from website pages as well as people driven info from philosophy with billions of RDF multiple times. requirements should be preserved and restrained 15x109 multiple times. 4store set up passionate about 3store for the foremost half in however RDF considerably will increase area unit spoken to.
C. Virtuoso
The traits of this dispatch area unit as per the following: Ts = right, Is = GSP O_OGP S, Qs = SP ARQL, Ss = string_id, Js = RDBMS_based, Ds = RDB, Fs = Box T, ABox, Dm = missing, Qm = missing, Sm = missing. Virtuoso [8, 9] info base administration of varied models a framework passionate about connected knowledge innovation. Aside from- activity of a connected info the executives framework, it also, offers RDF info the board, XML info the executives, content administration, and net application employee.
D. RDF-3X
The qualities of this dispatch area unit as per the following: Ts = right, Is = sixty freelance, Qs = SP ARQL, Ss = string_id, Js = normal_ordering, Ds = RDB, Dm = does not exist, Qm = does not exist, Sm = does not exist. From one monumental table. Markers area unit squeezed utilizing this byte-wise technique fastidiously selected to enhance the viability of the question cycle. See also, fictional coordinated pointers for SP, PS, SO, OS, PO, what is a lot of, OP.
E. Hexastore
The properties of this execution area unit as per the following: Ts = vertical, Is = 6_independent, Qs = real (modified), Ss = strings_id, Js = obscure (tseemsnone), Cs = none, Dm = none, Qm = none, Sm = none.
F. Apache pitched battle
The properties of this dispatch area unit as per the following: Ts = property, Qs = SP ARQL, Ss = string_id, Js = RDBMS_based, caesium = reif ied_statement, Ds = RDB, Dm = does not exist, Qm = does not exist, Sm = does not exist. a few cluster of data developed from the information set network, pitched battle may be a language community that kinds out the language condition in Java RDF [6, 17]. It offers straightforwardness yield ANd RDF chart the executives interface is spoken to in vast memory and is upheld up by an info base motor. Constancy of RDF charts is gotten utilizing the SQL info through JDBC association. pitched battle underpins a numerous info base frameworks, as an example, MySQL, Postgres, Oracle, also, BerkeleyDB. within the elementary interface of the administration of RDF diagrams, pitched battle incorporates a summation of RDF parsers, question language, and I/O modules for N3, N-Triple, and XML/RDF. The Figure 3 represents the control flow of Apche Jena model that indicates the complete process for RDF.
Figure 3. Control Flow of view of Apache Jena
G. SW-Store
The qualities of this usage are as per the following: Ts = level, Ss = string_id, Js = column_store_based, Cs = materialized_path_index, Ds = method, Dm = none, Qm = none, Sm = none. Abadi recommends utilizing direct partition of the portrayal of the RDF data information [1]. Advantages of utilizing section stores to look after RDF are: viable portrayal of NULL qualities; viable usage of high worth signs; heterogeneous help records; powerful mix of organized sections; and decreased number of associations being referred to. Accomplishing snappy admittance to the choice access techniques, made by bodies.
H. BitMat
The traits of this execution are as per the following: Ts = direct, Is = network, Qs = SP ARQL, Ss = string_id, Js = cutting, Ds = technique, Sm = pipe. A triple store was accounted for by Bauer et al. [4] utilized three sizes A compacted grid file named BitMat. It maintains a strategic distance from maintenance significantly increased however much as could be expected. The adequacy of its inquiry The SPARQL join calculation has two areas. First the class makes triple trees effectively. The second the segment performs dynamic restricting recreations in every one of the three examples to acquire conclusive outcomes. Both of these measures apply pressure BitMats without building a join table.
I. AllegroGraph
The qualities of this dispatch are as per the following: Qs = SP ARQL, Ds = technique, Dm = hash, Qm = data_parallel, Am = memory. AllegroGraph [11] is an outsider store worked at the AllegroCache object store. The truth is out items identified with Franz Inc. Straight development of AllegroGraph has not been completely revealed. Strong point cutoff of its capacity and preparing speed.
The advantage of this type of relationship is that the SPARQL queries can be managed effectively regardless of where the change takes place (title, property, item) because one of the markers will work. Likewise, it allows file-based investigations that prepare to complete a particular join - modified to query specific files. Although the hand joining is required, a snappy join mix can be used from each list created in the main section. Obviously Worse, apparently, the use of space, and without refining different markers if the details are not all. The above methods apply specifically to the collection and distribution of waist-mounted methods for their specific needs. Where there is an opportunity for this information to differentiate and share, this works well, but there are conditions where fragmentation and distribution may be affected by different requirements. For example, in various applications, the exact RDF data is sorted by point (e.g., various domains), or separated by independent data providers; it may be sensible news in the realm of knowledge. In these cases, these strategies may not be allowed to classify information as needed. In this way, resistance to SPARQL fragmentation may be attractive.
Contributions and overview
The commitments of this paper are three-overlap:
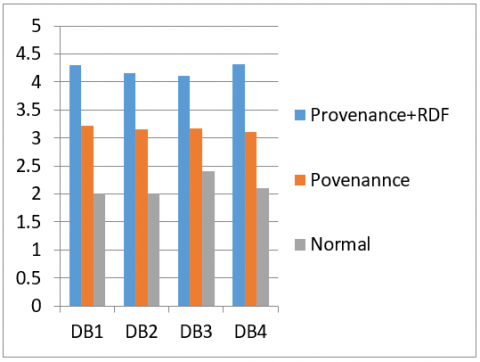
The Figure 4 indicates the evaluation results from different database servers. The evaluation results represent that the proposed model is better in Resource handling. The Figure 5 indicates the comparison levels between linear RDF and provenance RDF models.
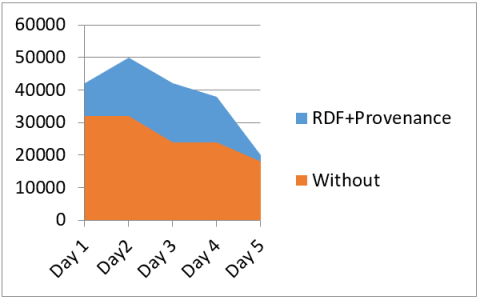
The Figure 6 indicates the time to convert legacy records. The proposed model takes less time that improves the system performance. The Figure 7 indicates the measurements of speed execution in various time intervals. This paper gives the legitimate premise to another proposition to speak to the metadata of the difficult proclamation and related inquiries in the RDF setting. We are thinking about setting up these establishments as the reason for orderly investigation of the exchange of our proposition. Subsequently, our future mission is to lead such an examination, which will take numerous hints: To start with, do we plan to examine how SPARQL pulls in? inquiries for clients by correlation in related SPARQL questions that it be routed to the other metadata-standard options in the RDF (e.g., standard RDF fortification, singleton properties, and singletons named in diagrams). Second, we need to comprehend the substantial consequences of utilizing SPARQL? covering based inquiries utilizing the guide depicted on this page. Indeed, we don't simply like RDF coverings support yet additionally singleton structures and named diagrams. Up until this point, work in this paper ought to be developed the portrayal (sparing data and question results conservation) of the guide of these two modes, which can be effortlessly adjusted definitions and results in Section 4. Third, we need to research the components to apply our proposition locally. An especially fascinating idea with regards to this setting is convey a perspective on the three debased bodies at body level. At long last, as another option with the most significant work, we intend to look at the RDF? in the thoughts of connections expended.
Figure 4. Evaluation results from different data base servers
Figure 5. Difference between linear and RDF+ Provenance Framework
Figure 6. Time to convert Legacy record to RDF with Provenance
Figure 7. Measurements of speed execution and results in various period of time
This research presents the RDF question motor for best practice with SPARQL inquiries. The calculation incorporates an IR-based answer for triple-point ID and a lot of administrators that perform best being referred to and-answer activity, a lot of RDF insights to gauge the expense of directing a question program, and a profoundly streamlined calculation that precisely distinguishes the inquiry framework. Tests show that this strategy works quite well and is outrageous to address three significant RDFs. The current work centers around the issue of addressing in the SPARQL essential diagram designs, just as the association and discretionary examples. Future work will grow this way to deal with subsidize channel provisos and named diagrams in SPARQL [3] by expanding existing measurements, focusing on frameworks and administrators. SPARQL is best utilized on the off chance that you need to inquiry RDF diagrams, as though at least one (likely conveyed) RDF charts structure an information base. Note that there is a great deal of conventional RDF data, however you don't have to utilize one to cite RDF utilizing SPARQL. This part starts by telling you the best way to inquiry RDF neighborhood documents, and afterward continues to question RDF records and information on the Web. Since we use URIs to distinguish both, you may not see the distinction. We prefer it as such in light of the fact that RDF and Linked Data are intended to work the manner in which the Web works. A detailed analysis was carried out to hit the study gap and to find answers to it. Due to the potential participation of a vast number of heterogeneous resources, the management of resources remains an important challenge. The security of acceptance, data security, data integrity, access control, authenticity and privileges are concerned. Each area is open to research that can provide deeper insight into how cloud organizations can be taken more confident, simpler and more efficient.
[1] Ali, S., Wang, G.J., Bhuiyan, M.Z.A., Jiang, H. (2018). Secure data provenance in cloud-centric internet of things via blockchain smart contracts. In IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Guangzhou, China, pp. 991-998. https://doi.org/10.1109/smartworld.2018.00175
[2] Alshehri, M., Elkhodr, M., Alsinglawi, B. (2018). Data provenance in the internet of things. In Proceedings of 32nd International Conference on Advanced Information Networking and Applications Workshops, Krakow, Poland, pp. 727-731. https://doi.org/10.1109/waina.2018.00175
[3] Aman, M.N., Chua, K.C., Sikdar, B. (2017). Secure data provenance for the internet of things. In Proceedings of the 3rd ACM International Workshop on IoT Privacy, Trust, and Security, pp. 11-14. https://doi.org/10.1145/3055245.3055255
[4] Bauer, S., Schreckling, D. (2018). Data provenance in the internet of things. In Proceedings of 32nd International Conference on Advanced Information Networking and Applications Workshops, pp. 727-731. https://doi.org/10.1109/waina.2018.00175
[5] Caro, M.P., Ali, M.S., Vecchio, M., Giaffreda, R. (2018). Blockchain-based traceability in Agri-Food supply chain management: A practical implementation. In IoT Vertical and Topical Summit on Agriculture-Tuscany, pp. 1-4. https://doi.org/10.1109/iot-tuscany.2018.8373021
[6] Bharadwaj, S., Hernández, M., Ho, H., Jain, P., Joshi, S., Karanam, H., Krishnan, S., Krishnamurthy, R., Li, Y.Y., Manivannan, S., Mittal, A., Chiticariu, L., Özcan, F., Quamar, A., Raman, P., Saha, D., Sankaranarayanan, K., Sen, J., Sen, P., Han, S.D. (2017). Creation and interaction with large-scale domain-specific knowledge bases. Proceedings of the VLDB Endowment, 10(12): 1965-1968. https://doi.org/10.14778/3137765.3137820
[7] Interlandi, M., Shah, K., Tetali, S.D., Gulzar, M.A., Yoo, S., Kim, M., Millstein, T., Condie, T. (2015). Titian: Data provenance uphold in Spark. Proceedings of the VLDB Endowment, 9(3): 216-227. https://doi.org/10.14778/2850583.2850595
[8] Diestelkamper, R., Herschel, M., Jadhav, P. (2017). Provenance in Disk frameworks: Reducing space overhead at runtime. In TaPP.
[9] Tramp, S., Frischmuth, P., Ermilov, T., Shekarpour, S., Auer, S. (2014). An architectureof a distributed semantic social network. Semantic Web – Interoperability, Usability, Applicability an IOS Press Journal, 5(1): 77-95.
[10] Mansour, E., Sambra, A., Hawke, S., Zereba, M., Capadisli, S., Ghanem, A., Aboulnaga, A., Berners-Lee, T. (2016). A demonstration of the solid platform for socialweb applications. WWW '16 Companion: Proceedings of the 25th International Conference Companion on World Wide, pp. 223-226. https://doi.org/10.1145/2872518.2890529
[11] Chacko, A., Kumar, S.M. (2017). Big data provenance research directions. In Proceedings of Region 10 Conference, pp. 651-656. https://doi.org/10.1109/TENCON.2017.8227942
[12] Chia, M.H., Keoh, S.L., Tang, Z. (2017). Secure data provenance in home energy monitoring networks. In Proceedings of the 3rd Annual Industrial Control System Security Workshop, pp. 7-14. https://doi.org/10.1145/3174776.3174778
[13] Javaid, U., Aman, M.N., Sikdar, B. (2018). BlockPro: Blockchain based data provenance and integrity for secure IoT environments. In Proceedings of the 1st Workshop on Blockchain-enabled Networked Sensor Systems, pp. 13-18. https://doi.org/10.1145/3282278.3282281
[14] Jayakody, J.A., Rupasinghe, L., Mapa, N., Disanayaka, T., Kandawala, D., Dinusha, K. (2018). A light weight provenance aware trust negotiation algorithm for smart objects in IoT. Annual Conference 2016 - IET- Sri LankaAt: Hotel GaladariVolume: IET ATC 2016.
[15] Jiang, L.C., Kuhn, W., Yue, P. (2017). An interoperable approach for Sensor Web provenance. In Proceedings of 6th International Conference on Agro-Geoinformatics, pp. 1-6. https://doi.org/10.1109/agro-geoinformatics.2017.8047046
[16] Jose, B., Ramanan, T.R., Kumar, S.M. (2017). Big data provenance and analytics in telecom contact centers. In Proceedings of Region 10 Conference, pp. 1573-1578. https://doi.org/10.1109/tencon.2017.8228107
[17] Psallidas, F., Wu, E. (2018). SMOKE: Fine-grained ancestry at intelligent speed. arXiv:1801.07237.
[18] Li, P., Chen, Z., Yang, L.T., Zhang, Q., Deen, M.J. (2017). Deep convolutional computation model for feature learning on big data in internet of things. IEEE Transactions on Industrial Informatics, 14(2): 790-798. https://doi.org/10.1109/tii.2017.2739340