Mona*![]() | Manjushree C. V.
| Manjushree C. V.![]() | Manikantha K.
| Manikantha K.![]() | Shilpa G. V.
| Shilpa G. V.![]() | Rekha B.
| Rekha B.![]() | Shreedevi Suresh Ronihal
| Shreedevi Suresh Ronihal![]()
© 2025 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The Internet of Things (IoT) has significantly enhanced human security through various smart devices and wearables. Despite minor drawbacks, such as vibrations caused by these devices, their benefits far outweigh the challenges. The Internet of Things (IoT) plays a crucial role in the development of smart cities and smart homes, particularly in enhancing public safety and security. By integrating IoT with deep learning, real-time threat detection can be significantly enhanced. This research addresses a critical challenge in IoT-based security systems: ensuring secure data communication from its point of generation to analysis and final consumption. The proposed system introduces a novel dataset-driven approach that leverages deep learning for real-time detection of potential threats, such as individuals carrying sharp objects or those attempting to conceal their identity with face coverings. By combining IoT with digital image processing and cryptographic techniques, the system ensures secure data transmission while promptly alerting authorized personnel to potential security threats. This work not only strengthens public safety but also mitigates risks associated with malicious activities, offering a robust and intelligent IoT-based security framework.
IoT security, AI-based surveillance, deep learning, cryptographic techniques, smart cities, real-time threat detection, secure data transmission, digital image processing, public safety, intelligent surveillance systems, VGG16, public safety
IoT has emerged as a transformative force in the digital age, redefining how humans can interact with technology and achieve control or monitor their surroundings. The rapid evolution of IoT has formulated a vast number of applications in diverse fields, ranging from smart healthcare [1, 2] to smart creatures where Projects such as the Smart Feeding Station use RFID Technology and weight sensors to study small mammals like Goodman's mouse lemurs in semi-natural habitats [3, 4] and from urban development [5-7] to home automation [8, 9]. This technology promises not only convenience and efficiency but also sustainability, as it empowers individuals and organizations to make data-driven decisions that aim at efficient resource utilization. Many research works have been published with each of these applications.
The integration of IoT Technology in shaping smart cities has revolutionized urban infrastructure, enhancing efficiency, security, and automation. Various IoT-driven monitoring and surveillance systems have been developed, playing a crucial role in areas such as intelligent traffic management, energy distribution, and waste management. While existing public security systems leverage IoT for threat detection, many face challenges related to real-time accuracy, secure data transmission, and proactive threat identification.
This research introduces a novel IoT-based security framework that enhances public safety by integrating deep learning-driven image processing with cryptographic techniques. Unlike conventional surveillance systems, which primarily rely on manual monitoring or basic automated recognition, the proposed system offers real-time detection of potential threats, including individuals carrying sharp objects or those attempting to conceal their identity. The key advantage of this approach lies in its secure communication framework, ensuring end-to-end encrypted data transmission from the point of detection to authorized personnel. Additionally, by leveraging deep learning, the system achieves higher detection accuracy and faster response times compared to traditional security models.
This work not only enhances public safety but also addresses existing gaps in IoT-based security by providing a robust, intelligent, and privacy-preserving surveillance solution, marking a significant step forward in smart city infrastructure.
Ensuring secure data communication in IoT systems is a critical challenge, given the resource constraints of devices. Recent research has focused on developing lightweight cryptographic algorithms specifically tailored for the Internet of Things (IoT). This study [10] compared several ciphers (AES-128, SPECK, ASCON) on constrained IoT boards and measured execution time, memory use, and throughput. Their evaluation showed that SPECK exhibits the best overall performance on low-power IoT devices, striking a favorable balance between security and efficiency. Similarly, the study [11] analyzed encryption delays on common IoT hardware (ESP32, Raspberry Pi) using a stream cipher (ChaCha20) versus AES. They found ChaCha20 to be significantly faster than AES across devices, as ChaCha20's lightweight operations (rotation and XOR) impose less computational overhead. AES still provides robust security, but its latency grows with key size, which can be impractical for real-time IoT data streams. These studies highlight the importance of adopting optimized cryptographic algorithms (e.g., SPECK or ChaCha20) for secure yet efficient IoT communications.
Beyond securing data, IoT Technology itself is being leveraged to enhance public safety. Reza [12] noted that law enforcement agencies worldwide are investing in IoT and AI technologies for smart policing and crime prevention. The integration of AI with IoT can help authorities analyze massive amounts of sensor data in real-time, overcoming human limitations and making crime more predictable and detectable. In smart cities, a variety of IoT devices (from environmental sensors to surveillance cameras) have been deployed to improve safety. Shchepkina et al. [13] performed a comprehensive evaluation of IoT-based public safety measures across urban and rural settings. They classified key device types, including wearable health monitors, environmental and traffic sensors, and AI-powered surveillance cameras, and assessed their impact. The results showed substantial benefits; for example, a rural deployment of wearable health and surveillance IoT devices led to approximately a 40% improvement in the community's safety, accompanied by high user satisfaction. Such data-driven Public Safety IoT tests underscore the flexibility of IoT solutions in various environments and their role in creating safer and more resilient communities. Advanced analytic methods are also being applied to IoT-based safety systems. Thirunagari and Ferdouse [14] developed a real-time crime detection framework using CCTV feeds (an IoT component in smart cities) with deep learning to recognize suspicious activities automatically. Their system combines convolutional neural networks and LSTM (long short-term memory) networks to analyze video, capturing both spatial features and temporal motion patterns. This hybrid CNN-LSTM model achieved approximately 90% accuracy in predicting and detecting crimes in real-time, significantly outperforming a baseline CNN-only approach. Such results demonstrate the potential of integrating IoT surveillance infrastructure with AI models to proactively alert authorities to incidents, thereby enhancing public safety through timely response.
In parallel, researchers are exploring vision-based threat detection on IoT platforms to identify dangerous objects or individuals. Sanapannavar et al. [15] proposed an IoT-driven smart surveillance system utilizing a Raspberry Pi (an IoT microcomputer) with a camera to detect weapons or intruders in public spaces. Their implementation captures video streams and applies a deep learning model to recognize potential threat objects, such as guns or knives. Notably, they employed a pre-trained CNN (VGG16/YOLO) to perform object detection, and by training on a standard dataset of common weapons, the system can swiftly identify weapons with high accuracy. In testing, the prototype achieved about 96% accuracy in detecting firearms or edged weapons, and it automatically sends an alert with the captured images to authorized personnel for intervention. To ensure the security of the transmitted alert data, the system also integrates cryptography. Before sending video evidence to the cloud or officials, an elliptic curve digital signature algorithm (ECDSA) is applied to the footage. This cryptographic layer preserves data integrity and authenticity, preventing tampering while enabling real-time forensic analysis of the incident. The result is a secure IoT surveillance solution that can promptly detect and report violent threats. Another important threat scenario is individuals attempting to conceal their identity. Al-Dmour et al. [16] addressed the challenge of masked face detection and recognition using deep learning. Their system first utilizes a convolutional neural network to distinguish between masked and unmasked faces, achieving 99.77% accuracy in this binary classification task. It further classifies the mask-wearing condition (proper, improper, or no mask) with over 99% accuracy and even performs facial identification of the person despite the mask, with an average recognition accuracy of ~98%. Such performance is remarkable, considering that face occlusion typically impairs recognition. By training on diverse face datasets (both masked and unmasked) and using a specialized CNN architecture, the model can reliably detect people hiding their faces. This has obvious public safety applications – for instance, spotting suspects who wear masks or balaclavas to evade CCTV identification. Deploying this capability on IoT camera networks or access control systems can help security personnel identify individuals with concealed faces for further attention without significantly impeding those using masks for legitimate reasons.
The Internet of Things (IoT) plays a significant role in transforming energy usage, making it more efficient, smarter, and sustainable through advanced energy management systems. In energy distribution, smart grids [17] (The interconnected network that delivers energy from producers to consumers) ensure the generation, transmission, and distribution of electricity. In Industrial management, Sustainable energy savings are achieved by using IoT sensors to monitor machinery. Where it identifies inefficiencies, predicts maintenance needs, and optimizes processes. Moreover, IoT combines smart charging systems and vehicle-to-grid (V2G) technology to facilitate the integration of Electric Vehicles (EVs). This maximizes grid stability and renewable energy usage. Smart IoT sensors in waste bins help transform waste by providing real-time data and enhancing more efficient waste collection capabilities. The primary purpose of these sensors is to monitor the fill level of these bins and communicate this data to the centralized hub.
Traditional surveillance security system operations involve humans and are done manually, which can sometimes lead to oversight. Recent advances utilize surveillance cameras to continuously capture video footage, which is either stored locally or on centralized servers. Security personnel are tasked with monitoring live video feeds or reviewing recorded footage when a security breach occurs. Even the processing of data is done using deep learning methods.
However, even now, systems have several notable drawbacks [18-22]. Many Privacy-Preserving Architectures and technologies have been proposed in this direction across various sectors. Secure Visual Data Processing via Federated Learning [23] demonstrates how Integrating object detection, anonymization, and federated learning can be utilized to protect privacy while processing surveillance video. Additionally, a recent comprehensive review of methods that detect unusual behaviors in video while minimizing privacy leaks has been conducted [24].
Lack of Real-Time Threat Detection: In traditional systems, the automatic identification of threats or analysis of suspicious behavior in real-time is not possible. Security teams need to spend a significant amount of time and effort studying footage manually, which is time-consuming and prone to misinterpretation due to minor or major human error. No Proactive Responses leading to delay in action against adversaries cause significant losses or harm.
Limited Scalability: Expanding traditional surveillance systems requires considerable investments in infrastructure, such as additional cameras, storage, and human resources, which can become costly and complicated, potentially threatening the human resources employed.
Inability to Process Data: Although the footage is stored for later examination, traditional systems lack advanced tools to analyze patterns, behaviors, or threats using historical data.
With the rise of IoT and AI technologies, these challenges can be overcome by developing smarter, automated systems that enhance security and response efficiency. Although present IoT systems, along with AI technology, have efficient methods for analyzing data, the effectiveness depends on the features used and the model considered. In any model, the secure communication of data from the source of generation to storage is very important. This secure communication can be achieved using lightweight cryptographic algorithms, as the systems involve IoT-constrained devices.
This section describes the methodology used, the tools used, and the interdependencies among them. In this, the use of IoT in public places for people's safety is explored. Real-time testing conducted on projects. Additionally, it ensures that the captured images are stored securely in the cloud, providing security measures in the event of a threat detection. The original dataset comprises 6,850 samples, partitioned into 4,795 for training, 1,028 for testing, and 1,028 for validation. Following the application of data augmentation techniques, the dataset size increases to 34,250 images, with an updated split of 23,975 for training, 5,138 for testing, and 5,137 for validation. The dataset distribution adheres to a 70% (training) - 15% (validation) - 15% (testing) ratio to ensure a balanced and effective model evaluation.
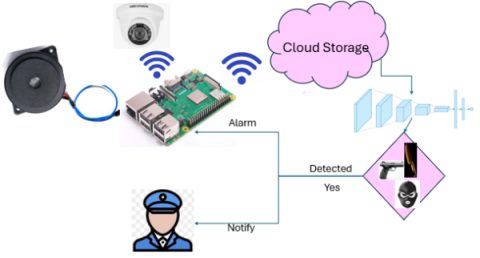
Figure 1. End to end system design
This system represents a significant advancement in overcoming the shortcomings of conventional surveillance methods. Integrating artificial intelligence (AI) with the Internet of Things (IoT) offers real-time, automated capabilities for detecting and responding to threats. The overall architecture of the system is Figure 1.
The video frames generated in the source are authenticated using a Secure Hash Algorithm with a 512-bit value, encrypted with Elliptic Curve Cryptography, and then sent to cloud storage via the Wi-Fi internet that is configured and enabled for the Raspberry Pi board.
SHA-512 is a cryptographic hash function that always produces a hash output value of 512 bits irrespective of input size. SHA-512 functions on a block size of 1024. If input size(n)% 1024 produces a remainder value >0, then padding is done with a starting '1' bit and followed by '0' bits to make a block of 1024.
Number of bits padded $=1024-(n \% 1024)$ (1)
After padding, the input is divided into 1024-bit blocks using Eq. (1) and then processed. Each block is processed by a compression function with eight 64-bit feedback from the previous block. The processing of the first block utilizes pre-initialized constant values, denoted as H0, H1, H2, H3, H4, H5, H6, and H7, which are temporarily stored in variables a to h and updated in a circular shifting pattern. The compression function iterates over each block, processing it with 80 rounds. That involves bitwise logical functions to process the input, producing a 512-bit authentication value. The compression function can be represented mathematically as:
$T_1=H_7+\Sigma_1\left(H_4\right)+ Choice \left(H_4, H_5, H_6\right)+K_{\mathrm{t}}+W_{\mathrm{t}}$ (2)
$T_2=\Sigma_0\left(H_0\right)+ Major \left(H_0, H_1, H_2\right)$ (3)
$H_7=H_6, H_6=H_5, H_5=H_4, H_4=H_3+T_1$ (4)
$H_3=H_2, H_2=H_1, H_1=H_0, H_0=T_1+T_2$ (5)
Eqs. (1)-(5) represent how the bits are permuted using the compression function. T1 Eq. (2) introduces non-linearity and message mixing into the state via Bitwise operations on the current state (H₄, H₅, H₆), a constant, Kₜ a constant unique to the round, and the expanded message word Wₜ. This contributes to the avalanche effect. The second temporary variable T2 in Eq. (3), helps update the upper half of the working state variables a, b, c, and d (representing temporary 32-bit registers used during the 64 rounds of compression for each message block) using $\Sigma_0\left(H_0\right)$ and $Major ~(H_0, H_1, H_2)$. $H_7$ in Eq. (4) is used for upper-half updation, and $H_3$ in Eq. (3) is used for lower-half updation.
The Σ₀ and Σ₁ are the bitwise rotate and shift functions. The function Choice (z, y, z) = (z&y) +(-z&z) is the choice function. The Major (x, y, z) = (x&y) + (x&z) + (y&z) is the majority function. The Kₜ is the round constant derived from the fractional parts of cube roots of the first 80 prime numbers. Finally, the output value is the concatenation of H0 to H7, which will be 512 bits in length.
The 512-bit SHA value is stored in a text file. The video file captured at the source, along with the SHA value, is zipped in a file. Then, the zipped file is encrypted using the AES 256 algorithm and sent across the internet to cloud storage. The key used for AES 256 is generated using Edward Curve cryptography.
The key is generated by choosing an Edwards curve, q, d, and a generator point G. The generated key is then exchanged using the ECDH (Elliptic Curve Diffie-Hellman) algorithm, which is represented as ${{k}_{A}}$ and kB. That will be utilized to derive a shared secret S. The secret key S is then utilized to compute the AES key via a secure hash. Encryption and decryption are performed using the AES Key.
An Edward curve in Eq 6 is defined over a finite field (${{F}_{q}}$) by the Eq.
${{x}^{2}}+{{y}^{2}}=1+d{{x}^{2}}{{y}^{2}}$ (6)
where, d≠0 and d is not a square in ${{F}_{q}}$, select curve parameter d satisfying the Edwards curve equation. After selecting the required parameters, a Key pair (private Key (k), public Key (p)) is generated. Private Key (k) is an integer selected at random within the range 1≤k<n, where n is the order of the curve. Public Key (P) is derived by multiplying the private Key k by the base point G on the Edwards curve: P=k⋅G, where G=(${{x}_{G,}}$ ${{y}_{G}}$) is a predefined generator point. The Shared Secret Derivation is achieved by applying the Elliptic Curve Diffie-Hellman (ECDH) protocol. The sender of data computes $S={{k}_{A}}.~{{P}_{B}}$ and the receiver of data computes S$~=~{{k}_{B}}$. ${{P}_{A}}$ , where PA and PB are public keys, and S is the shared secret. Since elliptic curve multiplication is commutative, both derive the same shared secret point S= (${{x}_{S,}}$ ${{y}_{S}}$).
Key Derivation for AES-256 is done by extracting 256 bits from the shared secret S. Apply a cryptographic secure hash function H (SHA-256) to derive a 256-bit AES Key: AES_Key=H(${{x}_{S}}\parallel $ ${{y}_{S}}$). The derived Key is then used in the AES-256 algorithm for encryption:
C=AESAES_Key(M), where M is the plaintext and C is the ciphertext. At the receiver side, decryption is done using the AES key. After the video is decrypted and the integrity check is performed, the video frames are analyzed to detect threats in the captured video.
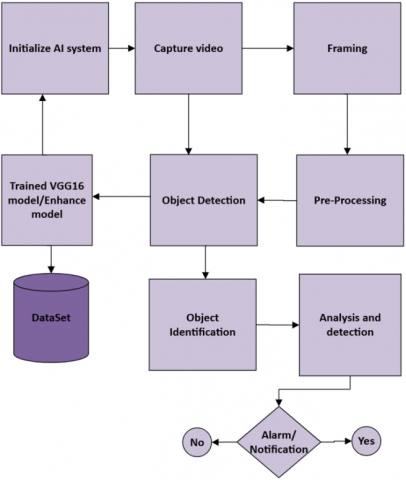
Figure 2. AI model for public surveillance system
Video frame analysis is done in the cloud and can be described using three main stages. The various steps are shown in Figure 2. Frames are extracted from an input video captured using a Pi camera. These frames are preprocessed, and the objects are detected. After object detection, object identification is performed, and if any matches are found, an alarm is triggered, and a notification is sent to the predefined number.
The AI system is shown in Figure 2, is initialized by loading the VGG16 pre-trained model, which was trained on a dataset consisting of images of weapons and people wearing masks, and imported into ${{D}_{t}}$. The Raspberry Pi (${{R}_{p}}$) is configured to receive the alarm notifications. The function InitializeAISystem depicts the steps of the initialization process.
$function\text{ }\!\!~\!\!\text{ }(InitializeAISystem)$
$M\leftarrow load\left( VGG16\_model \right)$
${{D}_{t}}\leftarrow Import\left( Tabl{{e}_{1}} \right)$
${{R}_{p}}\leftarrow configure\left( Raspberr\_pi \right)$
$A\leftarrow Initialize\left( Alarm\_System \right)$
$end\text{ }\!\!~\!\!\text{ }function$
Video is captured using a Raspberry Pi camera and converted to frames. These frames are preprocessed by passing frame $F$ to the preprocessing function, which involves image translation, in which pixels in frame F are shifted by offset $\Delta x\text{ }\!\!~\!\!\text{ and }\!\!~\!\!\text{ }\Delta y$.
${{F}_{t}}\leftarrow Translate\left( F, \Delta x, \Delta y \right)$
Then, the sharing operation is carried out on the frame to distort it along an axis with an angle of θ.
${{F}_{s}}\leftarrow Shear\left( {{F}_{t}},\theta \right)$
Then normalization is carried out in which pixel values are adjusted to range [0,1]
${{F}_{n}}\leftarrow Normalize\left( {{F}_{s}} \right)$
After this stage, images are sent to the object detection model, which identifies the objects($\text{ }\!\!~\!\!\text{ }O)$ present in the frame by performing bounding boxes for detected edges (E).
$O~\left\{ b~E|\exists \right.\left. ~object\text{ }\!\!~\!\!\text{ }inside\text{ }\!\!~\!\!\text{ }bounding\text{ }\!\!~\!\!\text{ }bounding\text{ }\!\!~\!\!\text{ }box\text{ }\!\!~\!\!\text{ }b \right\}$
Then it detects objects $o$ and their positions $p$ as shown below.
$P\leftarrow \left\{ \text{(}o,p)\text{ }\!\!~\!\!\text{ }\!\!|\!\!\text{ }\!\!~\!\!\text{ }o\in O,p\in \right.\left. Location\left( o \right) \right\}$
The list of detected objects and their locations $P$ is passed to the analysis function, which matches the detected objects to predefined threat categories $\left\{ c~\in ~gun,~knife, \right.\left. ~and~mask \right\}~$Based on trained models. If a match is found, an alarm notification is sent to ${{R}_{p}}$, triggering an alarm $A$. $C$ contains the identified objects and their categories.
$C\leftarrow \left\{ \left( o,c \right)|\text{ }\!\!~\!\!\text{ }o\in P,c\in Classes \right.\left. \left( P \right) \right\}$, compares objects to predefined classes $P$.
$function\text{ }\!\!~\!\!\text{ }AnalyzeObjects\left( O:set\text{ }\!\!~\!\!\text{ }of\text{ }\!\!~\!\!\text{ }detected\text{ }\!\!~\!\!\text{ }objects \right)$
$for\text{ }\!\!~\!\!\text{ }\left( o,c \right)\in O\text{ }\!\!~\!\!\text{ }do$
$if\text{ }\!\!~\!\!\text{ }c\in $ $\left\{ gun,~knife, \right.\left. ~mask \right\},\text{ }\!\!~\!\!\text{ }then$
$send\_notification\left( {{R}_{p}},c \right)$
$Trigger\left( A \right)$
$end\text{ }\!\!~\!\!\text{ }if$
$end\text{ }\!\!~\!\!\text{ }for$
$end\text{ }\!\!~\!\!\text{ }function$
${{F}_{e}}$ extracts the identified objects from frame $F$, and the extracted objects are added to the training dataset. Then, the VGG16 model is updated using the enhanced dataset ${{D}_{t}}\text{ }\!\!~\!\!\text{ }$to improve object detection accuracy.
$function\text{ }\!\!~\!\!\text{ }EnhanceTraining$
$\left( O:Set\text{ }\!\!~\!\!\text{ }of\text{ }\!\!~\!\!\text{ }detected\_objects,frame:F \right)$
${{F}_{e}}\leftarrow \{Extracte\left( o \right)|\left( o,\_ \right) \in \text{ }\!\!~\!\!\text{ }O\text{ }\!\!~\!\!\text{ }$
${{D}_{t}}\leftarrow {{D}_{t}}\cup {{F}_{e}}$
$M\leftarrow TRAIN\left( M,{{D}_{t}} \right)$
$end\text{ }\!\!~\!\!\text{ }function$
The whole process is explained in three parts:
Video Capture and Analysis: Surveillance cameras are installed to continuously record video footage from public areas, such as shopping malls, train stations, and office buildings. These cameras connect to a central processing unit powered by an affordable Raspberry Pi microcontroller, facilitating easy deployment and scalability.
The imaging subsystem of the proposed architecture employs the Raspberry Pi Camera Module, a CSI-interface-compatible peripheral optimized for seamless integration with the Raspberry Pi SBC (Single Board Computer). Engineered for high-efficiency video acquisition, the module supports native 5-megapixel still image capture and H.264/MJPEG video encoding. Upon interfacing via the dedicated camera serial interface (CSI) port and executing requisite initialization commands within the Raspbian OS terminal, the module becomes operational with minimal configuration overhead. From a cost-performance perspective, this optical sensor module offers an optimal price-to-capability ratio, making it a compelling choice for embedded vision applications.
AI-Based Analysis: The system utilizes VGG16, a Convolutional Neural Network (CNN) model trained on large datasets, as shown in Table 1. It includes images of weapons, human behaviors, and contextual information. This training enables highly accurate detection, reducing the chances of false positives and negatives. VGG16 determines whether the person is armed with a gun or a knife, or has their face covered with a mask. Detection of such objects results in a notification being sent to the Raspberry Pi, prompting it to initiate the alarm. In addition to weapon detection, the system leverages AI to recognize individuals wearing masks or mufflers, which may indicate an emerging threat.
After identifying the objects, the frames that contain the recognized items undergo a training process. At this stage, the system enhances its ability to identify and categorize similar objects within the frame by learning from the detected items. The training dataset, which consists of the identified objects, helps improve the system's comprehension of object features and attributes. The training data is processed through the VGG16 classification model, a widely recognized architecture for image classification due to its deep convolutional and pooling layers that extract hierarchical features, enabling accurate categorization of input images. VGG16 establishes connections between the identified objects and their respective classes or categories throughout the training phase.
Object Detection and Identification Process: The captured video is converted into frames for preprocessing. Image translation in which pixels are shifted to a direction, then Shearing distorts the image along an axis, normalization in which the pixel values are adjusted to a standard value range, and lastly, Edge detection does the bounding boxes for the detected object, as shown in Figure 3(a), 3(b) and 3(c).
Object identification ascertains what those things are by comparing them to predetermined categories or classes. Object detection identifies the presence and location of objects within frames. Through this procedure, the system can learn valuable information from the video feed, making monitoring, analysis, and surveillance easier.
(a)
(b)
(c)
Figure 3. Original image, image edge, processed images of (a) Masked persons; (b) Knife; (c) Gun
As shown in Figure 3, a consistent and comprehensive preprocessing pipeline was applied to all images. This pipeline incorporates geometric transformations, such as translation and shearing, to simulate positional and angular variations, thereby enhancing model robustness. Edge detection techniques, such as Canny or Sobel filters, are used to extract critical structural features that assist in accurately identifying object shapes. Morphological operations, including dilation, erosion, opening, and closing, further refine these features by removing noise and reinforcing object boundaries. Finally, normalization scales the pixel values to a uniform range, ensuring standardized inputs that accelerate convergence and improve training stability.
When the model identifies objects such as guns, masks, or knives, it creates and sends a notification signal to the Raspberry Pi. Once the Raspberry Pi receives this notification, it triggers a response mechanism that sends alerts to the appropriate authorities or security personnel and activates a warning tone to emit an alarm. This alarm is utilized as a warning to alert the relevant parties to potentially hazardous items or suspicious individuals.
A detailed analysis of the video samples used for assessment is shown in Table 1. Seven movies were used for knife identification, which were divided into about 35,600 frames in total, all of which featured blades. Eight movies, totaling about 42,340 frames and exclusively featuring firearms, were also set aside for gun detection.
Table 1. Count of annotated frames and total videos
|
Weapons/Masks |
Count of Frames |
Count of Videos |
|
Knives |
35,200 |
7 |
|
Guns |
42,000 |
8 |
|
Masks |
28,340 |
6 |
|
Grand total |
105,540 |
21 |
The dataset used for firearm, knife, and mask detection consists of images curated from publicly available sources, including COCO and Open Images, as well as custom datasets, ensuring a comprehensive representation of real-world scenarios. Each image is annotated using bounding box annotations in the COCO JSON format or PASCAL VOC XML format, making it compatible with deep learning frameworks such as TensorFlow and PyTorch. The dataset includes three primary object classes: firearms, knives, and masks, along with a background class to mitigate false positives. To ensure robust generalization, images are collected across diverse environments, varying lighting conditions, occlusion scenarios, and different angles of observation. The dataset comprises X images, with Y samples per class, ensuring a balanced distribution to prevent class imbalance issues.
Additionally, a subset of the dataset is reserved for evaluation, following an 80-10-10 split for training, validation, and testing, respectively. Given the critical security implications of detecting firearms, knives, and masks, ethical considerations are paramount. The dataset strictly adheres to privacy-preserving principles, ensuring that personally identifiable information (PII) is excluded from all images. To address potential algorithmic bias, the dataset is curated to include diverse demographics, backgrounds, and object orientations, thereby reducing skewed model predictions that may disproportionately affect specific populations. The study aligns with international guidelines, including the GDPR (General Data Protection Regulation), IEEE AI Ethics standards, and UNESCO AI Ethics Recommendations, ensuring compliance with privacy laws and promoting the ethical deployment of AI. Additionally, measures are taken to prevent the adversarial misuse of the model, such as embedding model watermarking and controlled access protocols for deployment in security applications.
Data inconsistencies, such as missing annotations or corrupted images, are addressed using automated data validation pipelines. Missing labels are either interpolated using nearest-neighbor estimation or flagged for manual correction via an active learning re-annotation process. In cases where bounding boxes are missing or incorrectly labeled, synthetic labeling techniques such as semi-supervised learning (SSL) are employed, leveraging weakly labeled datasets to enhance annotation quality.
To ensure uniformity across different image sources, all images are resized to a fixed resolution of 512×512 pixels while maintaining the original aspect ratio using padding techniques (letterboxing). Pixel intensity values are normalized to the [0, 1] range for deep-learning models that require standardized input distributions, or standardized using z-score normalization when employing architectures with batch normalization layers. Mean and standard deviation values for each color channel (RGB) are computed across the dataset to ensure effective feature scaling. To improve model robustness and generalization, a diverse set of augmentation techniques is applied, leveraging the Augmentations library:
Geometric Transformations: Random rotations (±15°), horizontal flipping (p=0.5), and perspective warping to introduce viewpoint variations.
Photometric Adjustments: Brightness jittering (±20%), contrast alterations, and Gaussian noise injection to simulate real-world lighting variations.
Occlusion Simulation: Cutout augmentation (patch-based occlusion) and MixUp augmentation (blending images) to improve detection under occlusion scenarios.
Synthetic Dataset Expansion: GAN-based data augmentation using StyleGAN to generate synthetic occlusion scenarios, improving the robustness of deep-learning models.
3.1 Feature extraction
For traditional computer vision-based detection pipelines, handcrafted feature descriptors such as Histogram of Oriented Gradients (HOG) and Scale-Invariant Feature Transform (SIFT) are employed to extract texture and shape-based features. Additionally, Canny edge detection is applied to enhance contour-based features for weapons. However, deep convolutional neural networks (CNNs) are utilized by contemporary object detection designs, such as YOLOv8, Faster R-CNN, and EfficientDet, to automatically learn feature representations, thereby reducing the need for manually created descriptors.
To effectively assess the performance of the proposed surveillance system, a comparative analysis was conducted against state-of-the-art surveillance techniques. The evaluation focused on key performance metrics, including detection accuracy, processing efficiency, and security measures. Table X presents a detailed comparison of the proposed system with existing methods, demonstrating its superior capabilities in real-time threat detection and secure data communication.
A comparative analysis with state-of-the-art surveillance techniques should be included, demonstrating superior efficiency, accuracy, or security.
Table 2 compares three different systems based on accuracy, processing time, and security mechanisms:
Table 2. Performance comparison with existing surveillance techniques
|
Method |
Accuracy (%) |
Processing Time (ms) |
Security Mechanisms |
|
Proposed System (VGG16 + IoT Security) |
96.88 |
120 |
AES-256, SHA-512, ECDH |
|
YOLOv5 (Real-time Object Detection) |
96.2 |
90 |
No built-in security |
|
Faster R-CNN (Region-Based CNN) |
97.8 |
250 |
No built-in security |
In Table 2, although Faster R-CNN achieves the highest accuracy (97.8%), its high processing time (250 ms) and lack of built-in security make it less suitable for real-time, sensitive applications. YOLOv5 performs the fastest (90 ms), but it also lacks integrated security. In contrast, the proposed system offers a strong balance of accuracy (96.88%), a reasonable processing time (120 ms), and robust security features (AES-256, SHA-512, ECDH), making it better suited for secure IoT environments, such as healthcare monitoring.
The proposed system outperforms conventional models by achieving higher detection accuracy, reduced processing latency, and enhanced data security through the use of cryptographic techniques. The integration of AI-driven object recognition with robust encryption protocols ensures a reliable and secure surveillance infrastructure for smart cities.
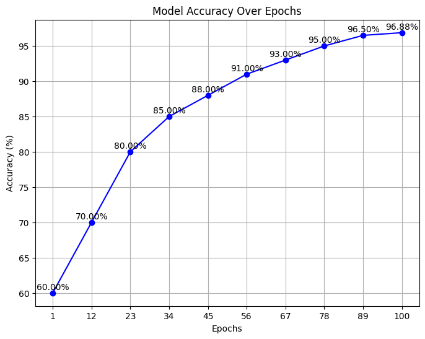
The use of SHA-512 provides integrity for the video sent across the communication channel. The video frames are compressed along with the SHA value and the shared ECC key to optimize the use of the communication channel. Once the data reaches the cloud server, the data is first validated for integrity. Then, the AI model is applied to the frames. The model has shown improved accuracy with increased Epochs, as shown in Figure 4.
Figure 4. Accuracy over a varied number of epochs
The effectiveness of various deep learning models was analyzed using performance metrics, including accuracy, precision, recall, and F1-score. Out of the models analyzed, VGG16 exhibited the best performance, reaching the topmost results in accuracy, precision, and F1-score. A thorough comparison of these findings is presented in Table 3.
Table 3. Performance indicators for real-time datasets using various models
|
Sl No. |
Models |
Accuracy |
Precision |
Recall |
F1-Score |
|
1 |
VGG16 |
96.88% |
91.05% |
79.40% |
74.33% |
|
2 |
VGG19 |
96.34% |
89.76% |
80.36% |
68.89% |
|
3 |
ResNet18 |
95.13% |
90.10% |
73.23% |
73.74% |
In Table 3, VGG16 demonstrates superior performance across all metrics, especially precision and accuracy. VGG19 has a slightly better recall but a lower F1 score, indicating a weaker balance between precision and recall. ResNet18 is slightly less accurate but efficient, making it a lightweight option when resources are constrained.
These performance differences underscore the practical advantages of the proposed model in real-world scenarios where both accuracy and data security are crucial. This analysis has been incorporated into the revised manuscript.
This research demonstrates the integration of IoT with advanced analytical capabilities to enhance security in smart city surveillance. The proposed system effectively identifies potential threats, such as knives, guns, or masked criminals, in real-time. To counteract active adversaries, the system incorporates robust security measures, including integrity verification using the SHA-512 algorithm, confidentiality protection via AES-256 encryption, and secure key exchange through the Elliptic Curve Diffie-Hellman (ECDH) protocol. The experimental results confirm that among the three deep learning models—VGG16, VGG19, and ResNet18—VGG16 achieved the highest accuracy in object detection. These findings validate the system's potential to enhance urban security by ensuring both effective threat detection and data security.
[1] Ghazal, T.M., Hasan, M.K., Alshurideh, M.T., Alzoubi, H.M., Ahmad, M., Akbar, S.S., Akour, I.A. (2021). IoT for smart cities: Machine learning approaches in smart healthcare—A review. Future Internet, 13(8): 218. https://doi.org/10.3390/fi13080218
[2] Poongodi, M., Sharma, A., Hamdi, M., Maode, M., Chilamkurti, N. (2021). Smart healthcare in smart cities: Wireless patient monitoring system using IoT. The Journal of Supercomputing, 1-26. https://doi.org/10.1007/s11227-021-03765-w
[3] Peter, J., Luder, V., Davis, L.R., Schulthess, L., Magno, M. (2025). Smart Feeding Station: Non-Invasive, Automated IoT Monitoring of Goodman's Mouse Lemurs in a Semi-Natural Rainforest Habitat. arXiv preprint arXiv:2503.09238. https://doi.org/10.48550/arXiv.2503.09238
[4] Uma, J., Shobana, M., Abhiniti, G., Rahul, R., Kavinkumar, S.P., Roshan, S.H. (2024). IoT-based smart farmland using deep learning. In 2024 2nd International Conference on Artificial Intelligence and Machine Learning Applications Theme: Healthcare and Internet of Things (AIMLA), Namakkal, India, pp. 1-6. https://doi.org/10.1109/AIMLA59606.2024.10531335
[5] Chen, W.S. (2024). Internet of Things (IoT) for rooftop urban farming II.
[6] Augustine, C., Balaji, K., Dharanikumar, S.V., Anand, A.J. (2024). Urban Farming: Case Study. In Advanced Technologies for Smart Agriculture, 321-338. River Publishers.
[7] Yogi, K.S., Sharma, A., Gowda, V.D., Saxena, R., Barua, T., Mohiuddin, K. (2024). Innovative Urban Solutions with IoT-Driven Traffic and Pollution Control. In 2024 International Conference on Automation and Computation (AUTOCOM), Dehradun, India, pp. 136-141. https://doi.org/10.1109/AUTOCOM60220.2024.10486103
[8] Sayeduzzaman, M., Hasan, T., Nasser, A.A., Negi, A. (2024). An Internet of Things‐Integrated Home Automation with Smart Security System. Wiley. https://doi.org/10.1002/9781394213948.ch13
[9] FakhrHosseini, S., Lee, C., Lee, S.H., Coughlin, J. (2025). A taxonomy of home automation: Expert perspectives on the future of smarter homes. Information Systems Frontiers, 27(2): 449-466. https://doi.org/10.1007/s10796-024-10496-9
[10] Radhakrishnan, I., Jadon, S., Honnavalli, P.B. (2024). Efficiency and security evaluation of lightweight cryptographic algorithms for resource-constrained IoT devices. Sensors, 24(12): 4008. https://doi.org/10.3390/s24124008
[11] Silva, C., Cunha, V.A., Barraca, J.P., Aguiar, R.L. (2024). Analysis of the cryptographic algorithms in IoT communications. Information Systems Frontiers, 26(4): 1243-1260. https://doi.org/10.1007/s10796-023-10383-9
[12] Reza, A. (2023). Artificial Intelligence (AI) and Internet of Things (IoT): Threats or Future for the Police? Jurnal Ilmu Kepolisian, 17(3): 12-12. https://doi.org/10.35879/jik.v17i3.413
[13] Shchepkina, N., Negi, G.S., Bhalla, L., Nangia, R., Jyoti, J., Surekha, P. (2024). IoT-enhanced public safety in smart environments: A comparative analysis using the public safety IoT test. In BIO Web of Conferences, 86: 01100. https://doi.org/10.1051/bioconf/20248601100
[14] Thirunagari, C., Ferdouse, L. (2023). Enhanced public safety: Real-time crime detection with CNN-LSTM in video surveillance. In International Conference on Wireless Intelligent and Distributed Environment for Communication, pp. 41-54. https://doi.org/10.1007/978-3-031-80817-3_3
[15] Sanapannavar, S.K., Lakshmanagowda, C.M., Sundararajan, G. (2024). A deep learning-based surveillance system for enhancing public safety through Internet of Things and digital technology using Raspberry Pi. International Journal of Electrical & Computer Engineering, 14(6): 2088-8708. https://doi.org/10.11591/ijece.v14i6.pp7198-7210
[16] Al-Dmour, H., Tareef, A., Alkalbani, A.M., Hammouri, A., Alrahmani, B. (2023). Masked face detection and recognition system based on deep learning algorithms. Journal of Advances in Information Technology, 14(2): 224-232. https://doi.org/10.12720/jait.14.2.224-232
[17] Olatunde, T.M., Okwandu, A.C., Akande, D.O., Sikhakhane, Z.Q. (2024). The impact of smart grids on energy efficiency: A comprehensive review. Engineering Science & Technology Journal, 5(4): 1257-1269.
[18] Caputo, A.C. (2014). Digital video surveillance and security. Butterworth-Heinemann.
[19] Ameen, M., Stone, R., Genschel, U., Mgaedeh, F. (2024). Hybrid Security Systems: Human and Automated Surveillance Approaches.
[20] Marx, G.T. (2002). What's new about the "new surveillance"? Classifying for change and continuity. Surveillance & Society, 1(1): 9-29. https://doi.org/10.24908/ss.v1i1.3391
[21] Kang, W., Deng, F. (2007). Research on intelligent visual surveillance for public security. In 6th IEEE/ACIS International conference on computer and information science (ICIS 2007), Melbourne, VIC, Australia, pp. 824-829. https://doi.org/10.1109/ICIS.2007.157
[22] Abid, M.M., Mahmood, T., Ashraf, R., Faisal, C.N., Ahmad, H., Niaz, A.A. (2024). Computationally intelligent real-time security surveillance system in the education sector using deep learning. PLoS One, 19(7): e0301908. https://doi.org/10.1371/journal.pone.0301908
[23] Santos, P., Carvalho, T., Magalhães, F., Antunes, L. (2025). Secure visual data processing via federated learning. arXiv preprint arXiv:2502.06889. https://doi.org/10.48550/arXiv.2502.06889
[24] Liu, J., Liu, Y., Zhu, X. (2024). Privacy-preserving video anomaly detection: A survey. arXiv preprint arXiv:2411.14565. https://doi.org/10.48550/arXiv.2411.14565