Ramya Navaneethan![]() | Hemavathi Devarajan*
| Hemavathi Devarajan*![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Diabetic Retinopathy and Glaucoma are two common diabetic retinal pathogens. It has the potential to damage human retina and result in vision impairment. Based on the International Diabetes Federation (IDF) reports, In India 77 million people were affected with diabetics 2019 and approximately 147.2 million people are expected by 2045. By effectively managing diabetes and undergoing routine eye examinations, would avoid or reduce the risk of eye complications such as diabetic retinopathy, cataracts, and Glaucoma. The Timely identification and precise delineation of affected areas in retinal pathogen images are crucial for effective disease management. To address this, we propose a novel hybrid diabetic retinal pathogen classification mechanism using Artificial Fish Swarm and Deep Convolutional Radial Basis Function network (AFS-DCRBF). This method utilizes retinal images containing normal, Diabetic-Retinopathy, and Glaucoma as inputs. Preprocessing of raw input images is performed using a spatial filtering technique in the initial phase. A vector-auto regression method is then employed for feature engineering, followed by retinal pathogen classification. The Deep-Convolutional Neural Network (DCNN) selects most informative traits from the extracted feature sequence, while the Radial Basis Function (RBF) module performs the classification task. The Artificial Fish Swarm (AFS) optimization fine-tunes the hyperparameters of DCRBF and improves classification performance. The proposed study was evaluated using ORIGA data set and publicly available datasets for DR. The proposed method required a total time of 1.12 seconds and achieved 99.40% accuracy and 99.61%specificity, and dice coefficient of 0.97.
artificial fish swarm optimization, diabetic retinal pathogen, Deep Convolutional Neural Network, Glaucoma, Radial Basis Function Network, spatial filtering
The primary causes of poor eye vision and blindness worldwide are age-related retinal disorders, such as Diabetic Retinopathy (DR) and Glaucoma. Glaucoma is often characterized by irregular intraocular pressure regulation [1]. Glaucoma comprises various forms, including secondary, congenital, angle-closure, and open-angle Glaucoma [2]. DR is the primary consequence of diabetes mellitus and occurs due to swelling and bleeding of small blood vessels in the retina [3]. This leads to retinal damage and impaired vision. There are five different stages of DR, ranging from normal (nonDR) to proliferative DR [4]. Early identification and treatment of these retinal pathogens are required for better treatment outcomes [5]. Medical professionals use various methods to diagnose glaucoma, including measuring intraocular pressure [6] and examining of the optic nerve with a dilated eye examination. They also monitored the vision-loss region [7]. However, an accurate and reliable method for diagnosing retinal disease is necessary. Currently, DR is diagnosed through an intensive ophthalmologic examination with dilation [8], which involves taking cross-sectional retinal images to assess thickness and detect fluid leakage. This method requires highly qualified medical professionals and is time-consuming and expensive [9]. Therefore, there is a need for an alternative solution to accurately and reliably diagnose retinal pathogens [10].
Researchers currently use AI for pattern recognition and object identification to diagnose diabetic retinopathy (DR) and Glaucoma [11]. ML/DL algorithms offer the capability to capture and learn patterns in data, and make automatic predictions [12]. This automatic retinal fundus image prediction can assist medical professionals in taking appropriate treatment measures [13]. As a result, there are now more affordable, accessible, accurate, and reliable means of identifying DR and Glaucoma [14]. ML approaches such as random-forest (RF), K-Nearest Neighbor (KNN), and Support Vector Machine (SVM), are used to diagnose diabetic retinal pathogens from fundus images [15, 16]. These techniques undergo effective training, learn patterns from images, and perform classification. They are more accurate than manual detection but depend on the dataset quality and computational power. On the other hand, DL algorithms, such as CNN, Deep- Neural Networks, and DBN, capture diseases through extensive training and make predictions [17]. They also investigated spatial and temporal data aspects, making them more effective, although they require a lot of data for training and are resource-intensive [18].
Diabetic Retinopathy (DR) and glaucoma are significant eye diseases that require accurate identification and classification to ensure proper treatment. The ML / DL algorithms used for image classification typically lack generalizability and lead to overfitting [19]. Weights, bias vectors, and other parameters must be optimized for effective training. Existing methods have excessive training time, over-fitting, data dependency, a lack of generalizability, scalability, and resource consumption. To address these limitations, a new deep-learning method was developed.
The primary contributions of the study are simply stated below:
Sudhan et al. [20] introduced a novel deep DL framework for early prediction of glaucoma. This approach uses a deep CNN to classify of retinal images. Initially, the authors utilized a U-Net structure for augmentation of the optic cup and a pre-trained DenseNet for feature extraction and selection. This method was trained and tested using the ORIGA dataset and achieved 97.32% accuracy. However, the combination of multiple DL methods increases architectural complexity.
Bilal et al. [21] proposed a two-phase automatic diabetic-retinopathy identification framework using a DL algorithm. In the first phase, a pre-trained U-Net was employed for the optic disc fragmentation. Subsequently, in the second phase, a CNN was deployed for the extraction of features. The CNN pre-processes the retinal images and selects unique attributes. This framework was evaluated using three publicly available DR datasets, namely DIARETDB0, Messidor2, and EyePACS1, and achieved accuracies of 93.42%, 94.59%, and 97.92%, respectively. However, this method requires additional computational resources.
Table 1. Summary of various methodologies
|
References |
Methodology |
Data Collection Approach |
Key Findings |
Limitations |
|
[20] |
Deep Convolutional Neural Network |
Glaucoma segmentation, and acquired accuracy of 97.32% |
Higher accuracy, and accurate segmentation |
Implementation complexity |
|
[21] |
Convolutional neural network |
DR detection, and achieved accuracy of 93.42%, 94.59%, and 97.92% for DIARETDB0, Messidor-2, and EyePACS-1 datasets |
Effective feature extraction and selection |
Computational demands |
|
[22] |
Combination of SVM and CNN |
Earned 91.9% accuracy in the training phase |
Effective training and feature tracking |
Overfitting issue and lack of generalization ability |
|
[23] |
Deep Neural Network |
Improved accuracy, sensitivity, and specificity |
Intelligent glaucoma detection with greater accuracy |
Not suitable for large image sequence |
|
[24] |
Transfer-learning-assisted VGGNet algorithm |
Achieved accuracy of 92.25%, 93.95%, and 96.60% for DIARETDB0, Messidor-2, and EyePACS-1 |
Efficient image segmentation |
Depends on trained models |
|
[25] |
Data fusion algorithm (clustering-based automatic method) |
Earned accuracy of 97.34% |
Accurate segmentation and classification |
Lacks interpretability and scalability |
|
[26] |
Transfer learning-based DL mechanism |
Multimodal medical image classification |
Effective image fusion and feature extraction |
Resource-intensive and time-consuming |
|
[27] |
Deep Convolutional Neural Network |
DSC-0.87, and IOU-0.80 |
Accurate and reliable image segmentation |
Not interpretable |
|
[28] |
Restricted Boltzmann Machines |
Accuracy 96.15% |
Optimal feature extraction and fine-tuning |
Cannot handle large datasets |
|
[29] |
Deep Convolutional Recurrent Network integrated with Enhanced Aquila Optimization |
Accuracy-95.04%, Kappa value-97.83% |
Improved classification accuracy, and cataract detection |
Consumes more power and time |
Jena et al. [22] developed a classification strategy using a DL algorithm to categorize DR classes. The method involves applying contrast-constrained adaptive histogram equalization to improve image quality, tracking asymmetric DL attributes using the U-Net structure, and employing a combination of CNN with SVM for classification. However, this framework exhibited a lack of generalization ability and was prone to overfitting.
Thanki et al. [23] designed an intelligent computer-based classification strategy using a DNN and ML to analyze retinal fundus images and predict glaucoma images. The method utilized DNN for feature extraction and ML for classification; however, it could not process large sequences of images simultaneously.
Bilal et al. [24] presented a two-stage mechanism for automatically categorizing DR using retinal fundus images. This work focused on accurately distinguishing different stages of DR and employed the U-Net technique for image segmentation and the transfer-learning-assisted VGGNet algorithm for classification. The method was validated using public datasets, namely DIARETDB0, Messidor-2, and EyePACS-1, and achieved accuracy rates of 92.25, 93.95, and 96.60%, respectively. However, this method relies on pre-trained models.
Ali et al. [25] proposed an innovative automatic classification methodology based on a clustering algorithm that utilizing DR data collected from the Bahawal Victoria Hospital (BVH) in Pakistan. This method employs a data fusion algorithm to improve the accuracy of the classification process. Five different ML approaches, including the logistic model tree, multilayer perceptron, sequential minimal optimization, simple logistic, and decision tree, were used for classification, achieving accuracies of 97.34%, 96.23%, 95.53%, 91.66%, and 93.81%, respectively. However, this method lacked interpretability and scalability.
Kalamkar and Geetha [26] developed a hybrid mechanism combining transfer learning and DL methods for multimodal medical image classification, using discrete wavelet transform to fuse input data images and pre-trained VGG19 for feature extraction. The method was tested using MRI and CT datasets. However, this method is resource-intensive and time-consuming.
Nisa et.al. [27] developed an image classification method that utilized a pre-trained U-Net with ResNet Encoder for image segmentation. The efficiency of this method was evaluated using the Dice Similarity Coefficient (DSC) and Intersection Over Union (IOU), and the results demonstrated that the method achieved a DSC of 0.87 and an IOU of 0.80. However, this method cannot be interpreted. Naramala et al. [28] proposed a method that utilized ML/DL approaches to address diagnostic issues.
Saju and Rajesh [29] introduced an optimized Deep Convolutional Recurrent Network integrated with enhanced aquila optimization for cataract detection, using both slit and retinal images and Batch Equivalence ResNet-101 for image segmentation. This method achieved 95.04% accuracy and 97.83% kappa value, but it consumed more power and time to implement. A summary of various methodologies is presented in Table 1.
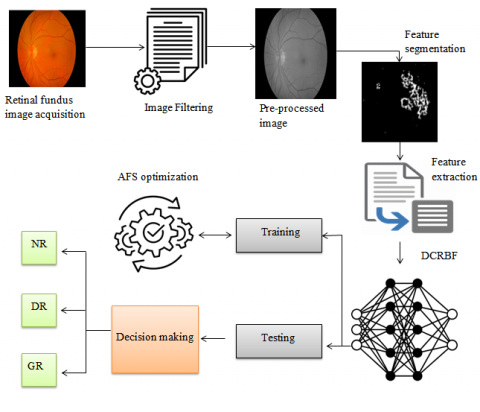
The development of the proposed optimized deep learning method was aimed at achieving an accurate classification of DR and Glaucoma. The method integrates the attributes of Artificial Fish Swarm (AFS) with a Deep Convolutional Radial Basis Function Network (DCRBF) architecture. The architecture of the proposed method is depicted in Figure 1. It comprises four distinct phases: data acquisition, preprocessing, feature engineering, and classification. In the initial phase, retinal fundus images were obtained from standard sources and imported into the system. In the second phase, the collected raw images were preprocessed using a spatial filtering mechanism to eliminate noise and enhance image quality.
Figure 1. Proposed flow diagram
In the third phase, feature engineering was conducted using the vector-auto regression method. This approach enables the system to differentiate between feature differences in normal and retinal pathogen images, resulting in a reduction in data dimensionality. In the fourth phase, the developed DCRBF was employed for the classification task, and its hyperparameters were fine-tuned and optimized using the AFS algorithm.
3.1 Retinal image acquisition and preprocessing
The first stage of the suggested framework entails the acquisition of retinal fundus images, which include examples of normal, glaucoma, and diabetic retinopathy (DR) pathogens. Because the images were obtained from diverse sources, they were manually annotated and consolidated into a unified dataset for prediction. Following the annotation process, the dataset comprised three distinct categories: Normal, DR, and Glaucoma. The annotated dataset is represented by Eq. (1):
Rimd =[rm1,rm2,rm3,rm4,……rmq] (1)
where, Rimd represents the consolidated retinal image dataset, rm represents the images present in the dataset, and q denotes the number of images available. Unprocessed retinal images often contain extraneous elements, such as backgrounds and noise, which can impede accurate analysis. To address this issue, a spatial filtering mechanism was implemented in the present study. Spatial filtering is a widely used technique designed to improve the quality of images by applying a filter, commonly referred to as a mask or kernel, to every pixel in the image. This method effectively eliminates noise and other undesirable characteristics, thereby enhancing overall image quality. The underlying principle of spatial filtering is convolution, which is particularly useful for obscuring and eliminating small image details and noise. Consequently, spatial filtering is a predominantly employed technique for enhancing image quality. Spatial filtering is mathematically expressed by Eq. (2):
P(a,b)=∑ui=−u∑vj=−vrm(a+u,b+v)∗M(u,v) (2)
where, P(a,b) indicates the pre-processed image (pixel value at location (a,b) in the filtered image, rm(a+u,b+v) defines the pixel value at a location (a+u,b+v) in the input image, M(u,v) refers to the filter or mask applied, and u and v indicate the extent of the filter kernel. Furthermore, an image normalization technique known as min-max scaling was implemented to standardize the image. This approach guarantees that all the pixel values within the image are confined within a consistent range.
3.2 Image segmentation
In this study, a U-Net architecture was modified by incorporating a Grey Wolf Optimizer (GWO) to increase the effectiveness of image segmentation. The modified architecture combines the GWO and U-Net frame works to enhance the precision and effectiveness of the image segmentation. The U-Net architecture consists of three fundamental blocks: encoder, bottleneck, and decoder. The encoder module uses convolutional layers in conjunction with pooling operations to achieve progressive downsampling.
The primary objective of the U-Net is to reduce the feature map’s spatial dimension. To achieve this, a deep neural network known as a bottleneck follows the encoder module. The bottleneck evaluates high-level features from the feature maps generated by the encoder after several layers of downsampling operations. The decoder module generates segmented images by up-sampling the pixel size of the feature maps, and reversing the downsampling carried out by the encoder. The blocks were connected using skip connections after the downsampling and upsampling. The skip connections link the appropriate encoder and decoder levels, providing the generation of both encoder provides high level semantic information, while the decoder captures fine-grained details. The performance of U-Net was assessed during the training phase using a loss function as represented in Eq. (3):
LFn(p,p′)=−∑mi=1p′(i)log(p(i)) (3)
where, LFn indicates the loss function, m refers to the number of classes, p′(i) denotes the probability of the ith class in the groundtruth, and p(i) represents the predicted probability of the ith class. The objectivewas to reduce the loss incurred by U-Net during the training process using the Grey Wolf Optimizer (GWO) method. GWO optimizes U-Net parameters, including weights and bias vectors, by adjusting their positions within the parameter space as they traverse it. During fine-tuning, the U-Net parameters were initialized to those of the wolf population. The GWO method reduces the loss function during training by optimizing U-Net parameters as represented in Eq. (4):
R(t+1)=R′(t)−ˉQ.ˉP (4)
where, R(t+1) denotes the updated position of the parameters, R′(t) defines the current position of the parameter with greater fitness, ˉQ defines the coefficient vectors, and ˉP defines the variation between the optimal and current positions which is estimated using Eq. (5):
ˉP=|ˉF⋅R′(t)−R(t)| (5)
where, ˉF indicates the coefficient vector and R(t) denotes the current position of the parameter. The determination of the fitness value for the updated parameters marks the final stage of the optimization process. Subsequently, the parameter that exhibited the highest fitness value was selected for training. Through iterative fine-tuning, the parameters were refined to achieve optimal performance.
3.3 Feature extraction
The proposed approach utilizes vector auto-regression (VAR) to extract the most salient features from a filtered image, thereby effectively reducing the dimensionality of the data. VAR is a statistical method that establishes relationships between multiple time series variables. In this context, VAR classifies each pixel as a time series and examines the correlation between neighboring pixels. The pixel values are then transformed into vectors, and the VAR model is applied to these vectors. The VAR model formulates a system of linear equations at each time step to delineate the correlations among the variables within the system, and is mathematically expressed in Eq. (6):
Yt=C+A1Yt−1+A2Yt−2+A3Yt−3+….+AnYt−n+et (6)
where, Yt defines the vector of the pixel values at time t,n denotes the order of the VAR model, A1An represents the coefficient matrices, and et refers to the error term. The coefficients in the Vector Autoregression (VAR) model determine the characteristics of the features and illustrate the progression of the pixel values over time. These coefficients delineate the gradual transformation of pixel values, and elucidate the temporal connections and interdependencies among adjacent pixels.
3.4 Classification
An enhanced deep learning method has been developed to improve the classification of retinal pathogens. By incorporating AFS optimization and DCRBF, the proposed approach reduces resource usage and computational time while achieving precise classification results. As shown in Figure 2, the DCRBF combines a deep CNN approach with an RBF approach. The DCNN technique focuses on identifying the most informative attributes from the extracted feature sequence, whereas the RBF approach is utilized to classify retinal pathogens. Meanwhile, AFS optimization refines the hyperparameters of the DCRBF approach and optimizes its training process, ultimately resulting in improved classification accuracy.
Figure 2. DCRBF layers
In the proposed work, the Deep Convolutional Neural Network (DCNN) serves as a feature selector, utilizing the extracted feature vector from the Vector Autoregression (VAR) model as its input. The DCNN comprises multiple layers, including input, convolution, pooling, and fully-connected output layers. The input layer processes the VAR feature sequence, whereas the convolutional layer automatically extracts the relevant local patterns from the input feature sequences. The convolutional layer is mathematically represented by Eq. (7):
Fi=AV(Wi∗Pi−1+bi) (7)
where, Fi denotes the feature map, AV refers to the activation function, Wi represents the weight matrix, Pi−1 indicates the previous layer's output, and bi defines the bias vector. The pooling layers in the network reduce the feature maps size generated by the convolutional layers. A fully connected layer then flattens the selected features into vectors. The output layer of the network provides the most informative feature subset that is used for retinal disease classification. This feature subset is then input into the RBF approach, which undergoes extensive training and classification. The input, hidden, and output layers comprise RBF neural network architecture. The input layer of the RBF accepts the selected feature subset as input and each feature is represented by an input node. The hidden layer of RBF is composed of neurons with RBF activation functions. The RBF activation function is typically a Gaussian function centered at each neuron in the hidden layer, and it calculates the correlation between the input data and the center of each RBF neuron, as defined in Eq. (8):
RBF(fe)=e−‖ (8)
where, R_{B F}(f e) denotes the RBF activation function for the input feature f e, C_{e i} denotes the i^{t h} neuron's, and s t indicates the Gaussian function's standard deviation. Then, the Radial Basis Function (RBF) network was then trained to carry out the classification task. The training process comprises two key stages: centroid selection and weight training. The centroid represents the core of the RBF neuron. Following its determination, the weights connecting the RBF neurons to the output layer were trained. Typically, the gradient descent method is used for RBF training. Ultimately, the output layer of the RBF network delivers the classification outcomes represented in Eq. (9):
Y_j(f e)=s t\left(\sum_{i=1}^k W_{r i j} R_{B F}(f e)\right) (9)
where, Y_j(f e) represents the output of the j^{t h} neuron for input f e, W_{r i j} represents the weight from RBF neuron i to output neuronj, and k defines the number of RBF neurons. After the weights were trained, the Radial Basis Function (RBF) network is utilized to classify new retinal images. The output neuron with the highest activity typically predicts class. To enhance the training process, it is essential to finetunes the hyperparameters of a DCRBF network. To address this, the current study employed an Artificial Fish Swarm (AFS) optimization algorithm to fine-tune the DCRBF hyperparameters.
3.5 Optimization
The AFS algorithm is an optimization method that draws inspiration from the characteristics and behaviors of fish within a population. This technique was applied to optimize the hyperparameters of the DCRBF in the aforementioned study. The AFS approach aims to identify the most effective configuration of the hyperparameters, thereby enhancing the training process of DCRBF and resulting in optimal outcomes. The hyperparameter set consists of various components, such as the learning rate, weight matrix, bias vector, and centroid selection. The AFS optimization process commences by generating an initial population, each member of which represents a specific set of hyperparameters for DCRBF. Following initialization, the fitness solution for each hyperparameter sequence is calculated.
In the AFS optimization process, the fish navigate their solution space, which is influenced by factors such as their individual and social experiences, as well as the exploration-exploitation trade-off. Similarly, the hyperparameter set moves within its parameter space and is updated based on its fitness value and movement strategies. The hyperparameter set with the highest fitness value was then selected for DCRBF training. Consequently, AFS optimization improves the classification performance by fine-tuning the hyperparameters. The flow diagram is shown in Figure 3 and the pseudocode in Algorithm 1.
Figure 3. Flow diagram of proposed work
|
Algorithm 1: AFS-DCRBF |
|
Start |
|
{ |
|
Initialize input dataset Rimd; |
|
//Annotate and consolidate the dataset into three classes |
|
Preprocessing () |
|
{ |
|
Apply spatial filter; |
|
Normalize the dataset; //use min-max scaling |
|
} |
|
Segmentation () |
|
{ |
|
Initialize U-Net parameters; |
|
//Define encoder, bottleneck, and decoder; |
|
Downsample image // encoder |
|
Extract high-level features //Bottleneck |
|
Upsample feature maps // decoder |
|
U-Net training () |
|
{ |
|
Calculate loss function; |
|
Initialize GWO parameters and population; |
|
Define objective function; |
|
Evaluate fitness; |
|
For each iteration t: |
|
Update the position of parameters; |
|
Calculate fitness for updated parameters; |
|
U-Net parameters=fine-tuned parameters; |
|
} |
|
} |
|
Feature extraction () |
|
{ |
|
Initialize VAR model parameters; |
|
For each pre-processed image: |
|
Apply the VAR model; //extract the relevant features |
|
Extract feature coefficients; //Transform pixels into vectors |
|
} |
|
Feature selection () |
|
{ |
|
Initialize the feature coefficient and DCNN parameters; |
|
Learn the patterns; //Convolutional layers |
|
Down-sampling; //Pooling layer |
|
Flatten features; //fully-connected layer |
|
Train DCNN; // Select the most informative features |
|
} |
|
Classification () |
|
{ |
|
Initialize RBF parameters; |
|
RBF training; //Train the RBF for classification |
|
Classification=output probability//output layer |
|
} |
|
Optimization () |
|
{ |
|
Initialize the AFS parameters and RBF parameter sequence; |
|
For each iteration i: |
|
{ |
|
Define objective function (); |
|
Evaluate fitness; |
|
Update the position and fine-tune the parameters; |
|
Calculate fitness for the updated parameter set; |
|
} |
|
i++; |
|
RBF parameters=tuned parameter set; |
|
} |
|
} |
|
Stop |
This research presented a novel deep-learning approach for the identification of DR and Glaucoma. It integrates artificial fish swarm optimization and deep convolutional Radial Basis Function Networks for precise classification. The proposed framework was implemented in MATLAB software version R2020a, operating on a 64-bit Windows platform. The method was trained and evaluated using the publicly available dataset from Kaggle, and the experimental outcomes were assessed in terms of the Dice Coefficient, accuracy, specificity, sensitivity, and F-measure.
4.1 Dataset description
The current investigation utilized publicly accessible Diabetic Retinopathy and Glaucoma datasets from Kaggle Digital Retinal pictures for Vessel Extraction (DRIVE) and the Structured Analysis of the Retina (STARE). The former is accessible at < https://www.kaggle.com/diabetic-retinopathy-detection / data > and comprises five classes, namely Non DR, Mild, Moderate, Severe, and Proliferate DR. The dataset is furnished in CSV format, with a size of 88.29GB and consists of 3658 images. Conversely, the Glaucoma dataset is available at < https://www.kaggle.com/arnavjain1/glaucoma-datasets > and comprises 2-class labels, namely Glaucoma (With Glaucoma) and No Glaucoma, with 2040 image files. Because these datasets were obtained from different sources, they were manually annotated by combining the collected dataset into a single directory with three classes (normal, DR, and Glaucoma). Next, the dataset was split at 80: 20 for training and testing. Table 2 lists the sample retinal image and its corresponding segmentation.
Table 2. Input images and their pre-processed and segmented images
|
Class |
Input Images |
Pre-processed |
Tracked Image |
Segmentation |
|
Diabetic Retinopathy |
||||
|
Glaucoma |
||||
|
Normal Healthy |
4.2 Performance assessment
This module evaluates the proposed framework's accuracy and loss throughout training and testing. This evaluation tracks the model’s performance as iterations increases. The training accuracy of the model serves as an indicator of its ability to effectively capture and learn patterns from training data. This metric is useful for determining the speed at which the proposed method can distinguish between images of DR, Glaucoma, and Normal Healthy eyes. The developed algorithm achieved an average training accuracy of 0.97 as the number of iterations increased.
Thus, testing accuracy indicates the model’s proficiency in performing diabetic retinal pathogen classification on unseen data (test data). The proposed approach achieved a higher testing accuracy of 0.94 as the iteration count increased. Figure 4 illustrates the validation of accuracy.
Figure 4. Model accuracy validation
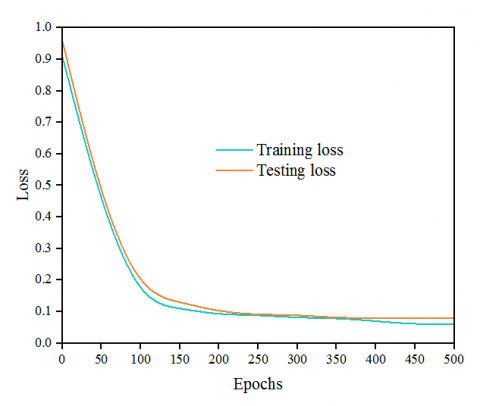
Conversely, the loss parameter measures the error that arises during both training and testing processes. The training loss reflects the error that occurs when recognizing the image patterns. The proposed method attained a minimum training loss of 0.03 as the iteration count increased.
The testing loss is a measure of the misclassifications made by the proposed method and serves to quantify the disparity between the actual and predicted results of the test data. The devised framework achieves a lower loss value of 0.06, as shown in Figure 5. The enhanced accuracy and minimized loss attained by the proposed algorithm throughout the training and testing phases substantiates its ability to discern retinopathy patterns with precision and accuracy.
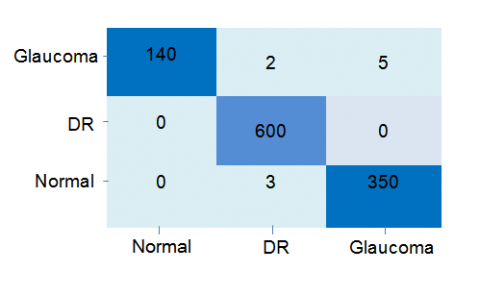
A confusion matrix is useful for comparing predicted class labels to actual class labels to evaluate a classification approach. As depicted in Figure 6, the confusion matrix obtained through the utilization of the proposed method is exhibited.
Figure 5. Model loss validation
Figure 6. Confusion matrix
4.3 Metrics evaluation
This section evaluates and compares the proposed method with several existing techniques, including modified Gear and steering based Rider-Optimization with Deep-Belief Network (MGGSR-DBN), CNN, Gaussian Algorithm with CNN (GA-CNN), Capsule Neural Network (CapsNet), Regional CNN (RCNN), and Transfer Learning with CNN (TL-CNN).
4.3.1 Accuracy
A model's accuracy is the percentage of right predictions out of all the predictions. The formula for determining accuracy is provided in Eq. (10):
A_{q y}=\left(\frac{t_{p t}+t_{n g}}{t_{p t}+t_{n g}+f_{p t}+f_{n g}}\right) (10)
where, A_{q y} indicates the model accuracy t_{p t}\, t_{n g} \,f_{p t} and f_{n g} terms "true-positive," "true-negative," "false-positive," and "false-negative" refer to, respectively, a correct identification of a positive case, a correct identification of a negative case, an incorrect identification of a positive case as negative, and an incorrect identification of a negative case as positive.
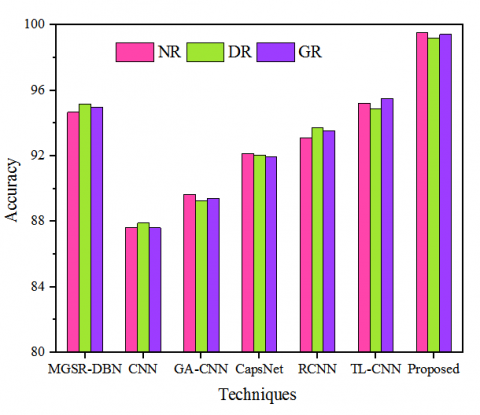
Figure 7. Evaluation of model accuracy for different data classes
The accuracy of the proposed model in comparison to existing methods for different data classes (NR-Normal Retina, DR – Diabetic Retinopathy, GR – Glaucoma Retina) is shown in Figure 7. The accuracy of the proposed model is compared to that of conventional classification techniques such as MGSR-DBN, CNN, GA-CNN, CapsNet, RCNN, and TL-CNN. For the NR class, it achieved 99.56% accuracy, whereas the other existing models achieved accuracies of 94.97, 87.65, 89.66, 92.15, 93.11, 95.23, and 87.90, respectively. Similarly, for the DR class, it achieved 99.21% accuracy, whereas the other existing models achieved accuracies of 95.17, 87.90, 89.26, 92.05, 93.75, 94.90, and 92.15, respectively. Finally, for the GR class, it achieved 99.43% accuracy, whereas the other existing models achieved accuracies of 94.99, 87.61, 89.43, 91.95, 93.54, 94.93, and 95.51, respectively. This shows that the proposed work is more accurate than conventional models.
4.3.2 Precision
The measurement of precision assesses the level of accuracy in making positive predictions. It was calculated by comparing the model's correct positive predictions with its overall positive predictions. This concept is mathematically represented by the formula provided in Eq. (11):
P_{e s}=\left(\frac{t_{p t}}{t_{p t}+f_{p t}}\right) (11)
where, P_{\text {es }} represents the precision.
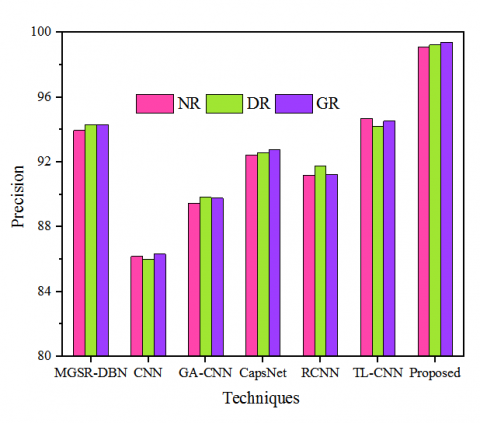
Figure 8 presents the assessment of the system's precision utilizing conventional methods. The precision attained by the proposed algorithm was evaluated against existing methodologies such as MGSR-DBN, CNN, GA-CNN, CapsNet, RCNN, and TL-CNN for various input classes, including NR, DR, and GR. The precision rates achieved by the proposed model and conventional techniques were 93.96, 86.18, 89.45, 92.43, 91.17, 94.71, and 99.12, respectively, for the DR class. This evaluation of precision validates that the proposed technique attained a higher precision rate compared to the others.
Figure 8. Precision validation
4.3.3 Sensitivity
The model's sensitivity measures its ability to recognize positive cases. This is the percentage of positive predictions that are correct for all positive situations. The formula for determining the sensitivity is expressed in Eq. (12):
S_{e n}=\left(\frac{t_{p t}}{t_{p t}+f_{p t}}\right) (12)
where, S_{e n} defines the sensitivity parameter.
Figure 9. Comparison of sensitivity
The comparison of system sensitivity with the existing methods is presented in Figure 9. The existing techniques employed for comparative study include MGSR-DBN, CNN, GA-CNN, CapsNet, RCNN, and TL-CNN. The above-stated conventional techniques and the proposed method attained sensitivity of 96.34, 87.65, 89.45, 93.35, 91.54, 95.86, and 99.60, respectively, for the NR class. For the GR class, these approaches earned sensitivity of 96.51, 87.45, 89, 93.71, 92.64, 95.86, and 99.73, respectively. On the other hand, these methods acquired sensitivity of 96.19, 87.65, 89.22, 93.80, 92.49, 95.86, and 99.5, respectively. From the comparative sensitivity study, it is clear that the developed approach achieved a better sensitivity rate than the conventional approaches.
4.3.4 F-measure
In situations with an imbalance of positive and negative occurrences, the F-Measure indicates the harmonic mean of precision and recall, providing a balanced approach for categorization performance assessment. The F-measure calculation is presented in Eq. (13):
F_{m e}=\left(2 \times\left(\frac{R_{e c} \times P_{c r}}{R_{e c}+P_{c r}}\right)\right) (13)
where, F_{m e} denotes the F-measure, R_{e c} represents the recall, and P_{c r} defines precision.
Figure 10. F-measure evaluation
The results of the F-measure validation are shown in Figure 10. Existing techniques, including MGSR-DBN, CNN, GA-CNN, CapsNet, RCNN, and TL-CNN, as well as the research work, achieved F-measures of 96.41, 87.65, 89.20, 93.89, 92.33, 95.09, and 99.30, respectively, for the overall dataset. For the GR class, these techniques achieved F-measures of 96.30, 87.50, 88.89, 93.80, 9.30, 95.1, and 99.65, respectively. This comparative analysis confirms that the proposed method outperforms the existing techniques in terms of the F-measure.
4.3.5 Dice coefficient
The Dice-coefficient is a metric used to assess the similarity between two sets and is frequently employed in image segmentation tasks. It measures the model's predictions' agreement with the ground truth in diabetic retinal pathogen identification. The formula for the Dice coefficient is expressed in Eq. (14):
D_c=\frac{(2 *(X \cap Y))}{(|X|+|Y|)} (14)
where, D_c indicates the Dice Coefficient, |X| indicates the size of set X (the predicted segmentation mask), and |Y| denotes the size of set Y (ground truth segmentation mask).
The Dice coefficients for the comparison between the conventional techniques and the proposed approach are presented in Figure 11. For the NR class, the conventional techniques and the proposed approach achieved Dice coefficients of 0.93, 0.80, 0.85, 0.93, 0.90, 0.93, and 0.98, respectively. For the DR class, the techniques achieved Dice coefficients of 0.94, 0.81, 0.83, 0.91, 0.88, 0.94, and 0.97, respectively. Additionally, for the GR class, the approaches achieved Dice coefficients of 0.94, 0.82, 0.81, 0.90, 0.91, 0.90, and 0.97, respectively. These results demonstrate that the developed system attained a significantly higher Dice coefficient than the conventional methods.
Figure 11. Dice coefficient comparison
4.3.6 Computational time
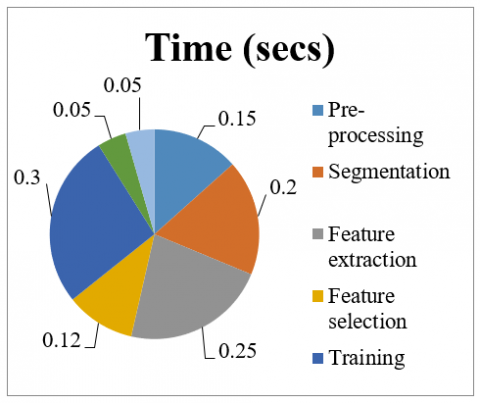
The amount of time required for the system to finish tasks such as image preprocessing, segmentation, feature extraction, selection, classification, and optimization is referred to as the computational time. This was determined by calculating the total time taken by the system to perform all of these tasks, and the results are presented in Figure 12. and Figure 13 demonstrate that the developed method required a total time of 1.12 seconds and a computational time for validation using different techniques respectively.
In this research, we present a novel segmentation and classification method for diabetic retinal. Our method utilized two publicly available datasets, DR and Glaucoma, and combines them into a single annotated dataset. Our method also employs a custom Fine-tuned U-Net approach for accurate segmentation of diabetic retinal pathogens. In addition, we developed a hybrid DCRBF technique for the precise classification of DR and Glaucoma. To further improve the classifier's performance, we employed AFS optimization to fine-tune the DCRBF parameters.
Figure 12. Computational time of the proposed method
Figure 13. Computational time validation
Table 3. Overall comparative analysis
|
|
Accuracy |
Precision |
Specificity |
Sensitivity |
F-Measure |
Dice Coefficient |
Computational Time (s) |
|
MGSR-DBN |
94.94 |
94.18 |
96.52 |
96.34 |
96.37 |
0.93 |
5.32 |
|
CNN |
87.72 |
86.17 |
87.81 |
87.58 |
87.48 |
0.81 |
7.8 |
|
GA-CNN |
89.45 |
89.68 |
89.17 |
89.22 |
89.06 |
0.83 |
6.5 |
|
CapsNet |
92.05 |
92.58 |
93.62 |
93.62 |
93.81 |
0.91 |
5.9 |
|
RCNN |
93.46 |
91.37 |
92.62 |
92.55 |
92.32 |
0.89 |
6.21 |
|
TL-CNN |
95.21 |
94.48 |
95.36 |
95.86 |
95.05 |
0.93 |
3.82 |
|
Proposed |
99.40 |
99.25 |
99.47 |
99.61 |
99.46 |
0.97 |
1.13 |
Table 4. Methodologies with performance analysis
|
Methods |
Technique & Advantages |
Limitations |
Performance Metric |
|
|
Accuracy |
Specificity |
|||
|
U-Net |
Image segmentation with its symmetrical architecture |
Suffer from overfitting and limited fields |
98.17 |
98.21 |
|
ResNet |
It allows effective training of very deep networks and it minimize the gradient issues |
It requires substantial computational resources |
97.23 |
97.30 |
|
DenseNet |
Feature reuse, helps gradient flow and reducing parameter count |
Occupies more memory |
95.40 |
95.61 |
|
VGG-16 |
Simple and effective |
High computational cost due to their large number of parameters |
96.61 |
96.22 |
|
VGG-19 |
97.02 |
96.87 |
||
|
FT-U-Net |
Balances U-Net's benefits with improved generalization through transfer learning |
Needed large amounts of labelled data |
99.55 |
99.64 |
The research presented in this study was developed and conducted using MATLAB, and the outcomes were assessed in terms of accuracy, recall, F-measure, and precision. Additionally, a thorough comparative analysis was conducted using existing techniques, such as MGSR-DBN, CNN, GA-CNN, RCNN, and TL-CNN. A complete comparative analysis is presented in Table 3 & Table 4.
The proposed technique’s segmentation performance, including its specificity and accuracy, was compared to conventional methods such as U-Net, ResNet, DenseNet, VGG-16, and VGG-19. The proposed work achieved 99.55% accuracy and 99.64%, specificity, whereas the conventional methods achieved accuracies of 98.17%, 97.23%, 95.40%, 96.61%, and 97.02%, and specificity of 98.21%, 97.30%, 95.61%, 96.22%, and 96.87%, respectively. A comparison of the segmentation performances is presented in Table 4. This analysis demonstrates that the proposed method outperforms conventional techniques.
This work introduces an optimized hybrid method (AFS-DCRBF) for classifying diabetic retinal pathogens using the DR and Glaucoma datasets available on Kaggle. By combining the benefits of AFS with DCRBF, the developed method achieves effective retinal pathogen classification. The MATLAB implementation of the method achieved an average performance of 99.40% accuracy, 99.25% precision, 99.47% specificity, 99.61% sensitivity, 99.46% F-measure, and 0.97 dice coefficient. Additionally, an extensive comparative study was conducted using techniques such as the MGSR-DBN, CNN, GA-CNN, CapsNet, RCNN, and TL-CNN. Among these techniques, the proposed method outperformed the others, with improved performance in accuracy, precision, specificity, F-measure, and dice coefficient by 4.46%, 5.07%, 2.95%, 3.27%, and 0.04, respectively. Real-time retinal pathogen categorization is shown to be effective and suitable.
The authors hereby declare that they possess no financial interests or personal relationships that could potentially compromise or bias the findings and conclusions presented in this paper.
The authors gratefully acknowledge the contributions of everyone who assisted in the preparation of this publication and provided the data for the present investigation.
|
DL |
Deep Learning |
|
AFS |
Artificial Fish Swarm |
|
DR |
Diabetic Retinopathy |
|
CNN |
Convolutional Neural Network |
|
GWO |
Grey Wolf Optimizer |
|
SVM |
Support Vector Machine |
[1] Veena, H.N. (2022). A novel optic disc and optic cup segmentation technique to diagnose glaucoma using deep learning convolutional neural network over retinal fundus images. Journal of King Saud University - Computer and Information Sciences, 34(8): 6187-6198. https://doi.org/10.1016/j.jksuci.2021.02.003
[2] Camara, J., Neto, A., Pires, I.M., Villasana, M.V., Zdravevski, E., Cunha, A. (2022). Literature review on artificial Intelligence methods for glaucoma screening, segmentation, and classification. Journal of Imaging, 8(2): 19. https://doi.org/10.3390/jimaging8020019.
[3] Atwany, Z.M. (2022). Deep learning techniques for diabetic retinopathy classification: A survey. IEEE Access, 10: 28642-28655. https://doi.org/10.1109/ACCESS.2022.3157632
[4] Priya, H.A.G., Anitha, J. Daniel, E. (2023). Grading of diabetic retinopathy using machine learning techniques. Computational Methods and Deep Learning for Ophthalmology, pp. 157-174. https://doi.org/10.1016/B978-0-323-95415-0.00001-2
[5] Aurangzeb, K., Alharthi, R.S., Haider, S.I., Alhussein, M. (2023). Systematic development of AI-enabled diagnostic systems for glaucoma and diabetic retinopathy. IEEE Access, 11. https://doi.org/10.1109/ACCESS.2023.3317348
[6] Latif, J., Tu, S.S., Xiao, C.B., Rehman, S.U., Imran, A., Latif, Y. (2022). ODGNet: A deep learning model for automated optic disc localization and glaucoma classification using fundus images. SN Applied Sciences, 4(98). https://doi.org/10.1007/s42452-022-04984-3
[7] Hervella, S.Á., Rouco, J. Novo, J. Ortega, M. (2022). End-to-end multi-task learning for simultaneous optic disc and cup segmentation and glaucoma classification in eye fundus images. Applied Soft Computing, 116: 108347. https://doi.org/10.1016/j.asoc.2021.108347
[8] Toğaçar, M. (2022). Detection of retinopathy disease using morphological gradient and segmentation approaches in fundus images. Computer Methods and Programs in Biomedicine, 214: 106579. https://doi.org/10.1016/j.cmpb.2021.106579
[9] Kashyap, R., Nair, R., Gangadharan, S.M.P., Botto-Tobar, M., Farooq, S., Rizwan, A. (2022). Glaucoma detection and classification using improved U-Net deep learning model. Healthcare, 10(12): 2497. https://doi.org/10.3390/healthcare10122497
[10] Nazir, T., Irtaza, A., Javed, A., Malik, H., Hussain, D., Naqvi, R.A. (2020). Retinal image analysis for diabetes-based eye disease detection using deep learning. Applied Sciences, 10(18): 6185. https://doi.org/10.3390/app10186185
[11] Wang, Z., Keane, P.A., Chiang, M., Cheung, C.Y., Wong, T.Y., Ting, D.S.W. (2021). Artificial intelligence and deep learning in ophthalmology. Artificial Intelligence in Medicine, pp.1-34, https://doi.org/10.1007/978-3-030-58080-3_200-1
[12] Palsapure, P.N., HA, A., G, A. BH, A.R., Jana, M. (2023). Deep learning approach to enhance accuracy for early detection of glaucoma. In 2023 3rd International Conference on Intelligent Technologies (CONIT), Hubli, India. https://doi.org/10.1109/CONIT59222.2023.10205533
[13] Sreng, S., Maneerat, N., Hamamoto, K., Win, K.Y. (2020). Deep learning for optic disc segmentation and glaucoma diagnosis on retinal images. Applied Sciences, 10(14): 4916. https://doi.org/10.3390/app10144916
[14] Bengani, S., Jothi, J.A.A., Vadivel, S. (2020). Automatic segmentation of optic disc in retinal fundus images using semi-supervised deep learning. Multimedia Tools and Applications, 80: 3443-3468. https://doi.org/10.1007/s11042-020-09778-6
[15] Shanthini, A., Manogaran, G., Vadivu, G., Kottilingam, K., Nithyakani, P., Fancy, C. (2021). Threshold segmentation based multi-layer analysis for detecting diabetic retinopathy using convolution neural network. Journal of Ambient Intelligence and Humanized Computing. https://doi.org/10.1007/s12652-021-02923-5
[16] Shanmugam, P., Raja, J., Pitchai, R. (2021). An automatic recognition of glaucoma in fundus images using deep learning and random forest classifier. Applied Soft Computing, 109: 107512.https://doi.org/10.1016/j.asoc.2021.107512
[17] Hasan, M.K., Alam, M.A., Elahi, M.T.E., Roy, S., Martí, R. (2021). DRNet: Segmentation and localization of optic disc and Fovea from diabetic retinopathy image. Artificial Intelligence in Medicine, 111(102001). https://doi.org/10.1016/j.artmed.2020.102001
[18] Veena, H.N., Muruganandham, A., Kumaran, T.S. (2020). A review on the optic disc and optic cup segmentation and classification approaches over retinal fundus images for detection of glaucoma. SN Applied Sciences, 2: 1476. https://doi.org/10.1007/s42452-020-03221-z
[19] Jesi, V.E., Aslam, S.M., Ramkumar, G., Sabarivani, A., Gnanasekar, A.K., Thomas, P. (2021). Energetic glaucoma segmentation and classification strategies using depth optimized machine learning strategies. Contrast Media & Molecular Imaging, 2021: 5709257. https://doi.org/10.1155/2021/5709257
[20] Sudhan, M.B., Sinthuja, M., Raja, S.P., Amutharaj, J., Latha, G.P.L., Rachel, S.S., Anitha, T., Rajendran, T., Waji, Y.A. (2022). Segmentation and classification of glaucoma using U-Net with deep learning model. Journal of Healthcare Engineering, 2022: 1601354. https://doi.org/10.1155/2022/1601354
[21] Bilal, A., Zhu, L.C., Deng, A., Lu, H.H., Wu, N. (2022). AI-based automatic detection and classification of diabetic retinopathy using U-Net and deep learning. Symmetry, 14(7): 1427. https://doi.org/10.3390/sym14071427
[22] Jena, P.K., Khuntia, B., Palai, C., Nayak, M., Mishra, T.K., Mohanty, S.N. (2023). A novel approach for diabetic retinopathy screening using asymmetric deep learning features. Big Data and Cognitive Computing, 7(1): 25. https://doi.org/10.3390/bdcc7010025
[23] Thanki, R. (2023). A deep neural network and machine learning approach for retinal fundus image classification. Healthcare Analytics, 3(100140). https://doi.org/10.1016/j.health.2023.100140
[24] Bilal, A., Sun, G.M., Mazhar, S., Imran, A., Latif, J. (2022). A transfer learning and U-Net-based automatic detection of diabetic retinopathy from fundus images. Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, 10(6): 663-674. https://doi.org/10.1080/21681163.2021.2021111
[25] Ali, A., Qadri, S., Mashwani, W.K., Kumam, W., Kumam, P., Naeem, S., Goktas, A., Jamal, F., Chesneau, C., Anam, S., Sulaiman, M. (2020). Machine learning based automated segmentation and hybrid feature analysis for diabetic retinopathy classification using fundus image. Entropy (Basel, Switzerland), 22(5): 567. https://doi.org/10.3390/e22050567
[26] Kalamkar, S., Geetha, M.A., (2022). Multi-modal medical image fusion using transfer learning approach. International Journal of Advanced Computer Science and Applications (IJACSA), 13(12): 483-488. https://doi.org/10.14569/ijacsa.2022.0131259
[27] Nisa, S.Q., Ismail, A.R. (2022). Dual U-Net with resnet encoder for segmentation of medical images. International Journal of Advanced Computer Science and Applications (IJACSA), 13(12): 537-542. https://doi.org/10.14569/ijacsa.2022.0131265
[28] Naramala, V.R., Kumar, B.A., Rao, V.S., Mishra, A., Hannan, S.A., El-Ebiary, Y.A.B., Manikandan, R. (2023). Enhancing diabetic retinopathy detection through machine learning with restricted Boltzmann machines. International Journal of Advanced Computer Science and Applications (IJACSA), 14(9). https://doi.org/10.14569/ijacsa.2023.0140961
[29] Saju, B., Rajesh. (2022). Eye-vision net: Cataract detection and classification in retinal and slit lamp images using deep network. International Journal of Advanced Computer Science and Applications (IJACSA), 13(12): 211-221. https://doi.org/10.14569/ijacsa.2022.0131227