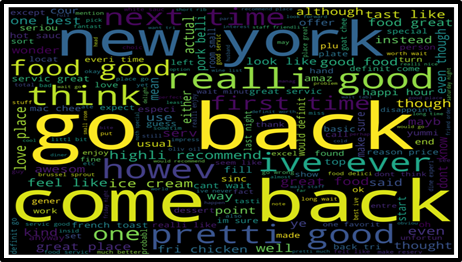Wesam Hameed Asaad*![]() | Ragheed Allami
| Ragheed Allami![]() | Yossra Hussain Ali
| Yossra Hussain Ali![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Online customer reviews have become an increasingly influential tool in shaping purchasing decisions. However, the growing impact of these reviews has led to a surge in the publication and promotion of fake reviews by some businesses, either to enhance their own product's reputation or to undermine their competitors. These counterfeit reviews can have an especially detrimental impact on small businesses, with even a single negative fake review capable of causing significant damage. In this context, the current study introduces a technique for classifying and identifying fake reviews using machine learning (ML) methodologies. The proposed algorithm was applied to the Yelp dataset for hotel services. The text was initially preprocessed through four stages: tokenization, normalization, stop word removal, and stemming. Subsequently, features were extracted using TFIDF techniques to leverage the benefits of sentiment analysis and to ascertain the presence of spam comments in the feature extraction approach. During the classification phase, the study employed three ML algorithms: Xgboost, a support vector classifier, and stochastic gradient descent. The proposed model was evaluated on both balanced and imbalanced datasets, using oversampling and undersampling techniques to determine its accuracy. The findings of this research hold promise for enhancing the credibility of online reviews and protecting businesses from the adverse effects of fake reviews. By unmasking fraudulent reviews, this study contributes to ensuring the integrity of online review platforms and safeguarding the interests of both businesses and consumers.
opinion mining, machine learning, fake review, XGboost, e-commerce
Using computational approaches, opinion mining examines and finds views, feelings, and subjective data in enormous amounts of text. It was utilized for testing goods and services, notably in terms of consumer acceptance and perceptions of specific companies and people [1]. Everyone is free to express their views and opinions anonymously and without fear of repercussions. Social media and online posting have made expressing oneself openly and confidently easier. These opinions have pros and cons; while they could help get the right feedback to the right individual, who could help fix the problem, they can also be manipulated. These viewpoints are seen as beneficial. This makes it simple for those with bad intentions to take advantage of the system, provide the appearance of sincerity, and publish comments to promote their goods or disparage those of rivals without disclosing who they are or where they operate. Such folks can write any bogus review. This behavior might be referred to as "opinion spamming”.
Because it has the potential to distort public discourse and galvanize large groups of people behind causes that run counter to legal or ethical norms, opinion spamming on social and political problems can be downright terrifying. As social media opinions become more widely used in real life, it's realistic to assume that opinion spamming will grow more pervasive and sophisticated, making it harder to spot. However, they must be identified to guarantee that social media remains a reliable source of public opinion rather than one rife with propaganda and misinformation.
This study uses the Yelp.com dataset to construct a model for classifying the features derived from text and spam using machine learning techniques to detect spam or non-spam reviews. Several classifiers named Extreme Gradient Boosting, Stochastic Gradient Descent Stochastic, and Support vector classifier are proposed to analyze the fake reviewer “spam and not spam “to suggest a better model for review-centric fake detection. Our model was applied to the balanced and imbalanced datasets as original, with oversamples and undersamples in random techniques.
The remaining part of the paper proceeds as follows: Section 2: Literature Review; Section 3: Tying up the various theoretical backgrounds Section 4 proposes a system framework; and Section 5 discusses the model outline and work. Section Performance Evaluation Section seven illustrates the conclusion and future work.
The detection of false web content reviews could be greatly helped by ML techniques. Web mining systems [2] typically use a range of ML algorithms to find and extract valuable information. One of the tasks of web mining is content mining. Due to the fact that it employs ML to determine the sentiment of text (negative or positive), opinion mining [3] is a classic example of content mining. A classifier is created to look at both the features of the sentiments and the reviews. Detecting fake reviews often relies on the category of the reviews and criteria not directly associated with the content. Text and images are often employed to develop reviews on natural language processing (NLP) properties. To manufacture fake reviews, inventing reviewer-related elements like the review time or date or writing style might be essential. Thus, the creation of relevant reviewer feature extraction is essential to accurately identify fake reviews. For supervised ML, a variety of classification algorithms have been developed. Finding a model that distributes the training data is the main goal of these techniques. The discriminative classifier SVM, for instance, divides the input data into classes by identifying the best separable hyper-plane that classifies the given training data. [4-6] utilized algorithms such as KNN, Multinomial Nave Bayes, Logistic Regression, SVM, Random Forest Classifier, SGD, and Stemming for analyzing hotel ratings that were either negative or positive and can be deployed for gauging consumer sentiment for the neutralization of a product. Two models have been developed to support the model performance for "Amazon's Yelp" data set and their applicability to their deployment in real-time software. The study's results [7] have been compared between the two models. Consequently, the RF model performed significantly better than the NB approach. With a clear grasp of its necessity and legality, the fake review detection issue was effectively handled. The goal was to eliminate the NB and RF algorithms, which performed poorly in detecting false reviews (79.007% and 89.487% accuracy, respectively). This work set out to create a system for detecting fake reviews using elements pertinent to reviews, like linguistic traits, parts of speech (POS), and sentiment analysis traits. These components were all obtained and added to the ontology. A rule-based classifier enhanced the false review detections by inferring the ontology. Incorporating POS characteristics, sentiment analysis features, and linguistic features improved the categorization outcomes from the performance metrics of a rule-based classifier [8].
Most studies and research affected by these problems contain shortcomings, such as inadequate accuracy. The study makes use of a partial dataset.
This section reviews the theoretical concepts used in implementing the proposed system.
3.1 Opinion mining
Consider a consumer-authored review that offers feedback on a product that falls under the classification of reviews. The opinion or opinion created is the review the customer makes to communicate his or her thoughts—mostly positive or negative—about the goods. The review classification seeks to discern whether a person has written a positive or negative review depending on an assessment of the text's point of view.
Opinion mining aims to find the attributes regarding the object on which opinions were offered in each of the reviews r ϵ R and to determine the orientation of comments, i.e., whether the comments are negative or positive if a set of text reviews (R) with opinions on an object is provided.
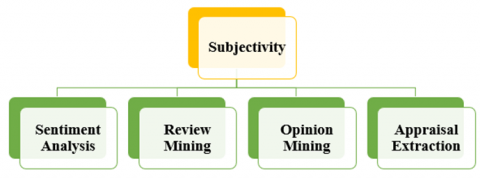
Assume you are provided with a collection of text reviews (R). When people have ideas about anything, opinion mining aims to locate the aspects discussed in each review (r R) and determine their orientation or whether they are positive or negative. Figure 1 illustrates many interchangeable phrases in opinion mining [9].
Figure 1. Synonyms of opinion mining [9]
Review mining has emerged in the past few years, which performs the computational evaluation of the users' opinions, sentiments, subjectivity, appraisals, feedback, emotions, etc., expressed in customer reviews. The term "subjectivity" relates to the person's feelings, perspectives, desires, and emotions. Objectivity typically stands in contrast to it. Speech/writing events expressing private states, private states, and expressive subjective elements. Extracting subjective hints, like phrases, terms or expressions, and applying them to determine whether the related sentence (or document) is objective or subjective are the two fundamental goals of subjectivity analysis. Subjectivity classification. It is required to extract any reviews or comments the author has made in order to obtain valuable data [9]. Modified Black Widow Optimization algorithm, which outperforms other bio-inspired approaches in global optimization and convergence speed, but is not as advanced as the best developed ones [10]. Research on the Holy Quran improves speaker identification systems, recognizing Arabic and English speakers using 14 professional reciters' speech signals, with improved LBG-VQ algorithm matching codebook centroids with 96.43% accuracy [11]. The review highlights the effectiveness of deep learning in energy forecasting, highlighting the use of various neural networks, including simple RNN, LSTM, GRU, and bidirectional RNN [12]. The research introduces an efficient odometry method for autonomous path planning, enabling global optimal planning, mapping, and localization in static obstacles, improving computing speed and position accuracy [13].
3.2 Sentiment analysis
Sentiment analysis, which is usually referred to as "opinion mining," is the research subject. Analysis is done on people's attitudes, views, feelings, assessments, and appraisals of goods, services, organizations, people, issues, events, subjects, and traits [14]. Sentiment analysis determines the text's relative polarity. It determines if a text is constructive, destructive, or neutral. It is also known as "opinion mining" since it reveals the speaker's viewpoint or attitude. Users can publish product reviews on social networking and shopping websites, which serve as platforms for classification. A training set is needed to analyze the reviews [15] effectively. In the e-commerce reviews, the sentiment analysis technique is applied. A "tough mountain" is saved for the quantity of reviews.
Sentiment analysis also assists in classifying free-form language as positive, negative, or neutral, summarizing the customer's judgment to comprehend another customer's expression and strengths for products and merchants.
3.3 Fake review detection
Fake review detection can be defined as a field of NLP. It aims to evaluate, identify, and classify product reviews on online e-commerce sites as either fake or authentic. Deceptive product reviews frequently employ false opinions [16]. It is currently a popular academic subject. Fake reviews are often described as spam reviews, deceptive opinions, and spam opinions, and the people who write them could also be called spammers [17]. Review readers are duped by the practice of mind spamming. Users who engage in spamming activities are referred to as "spammers." Spammers' fake reviews aim to give a company a false reputation, either negative or positive. Certain companies hire spammers to download the material in an effort to get new customers or to demote a competent company inside the same company [18]. People publish erroneously good product reviews to advertise products. Sometimes, maliciously unfavourable reviews of other (competition) products are written to harm their reputation. Some are commercials and promos, neither offering reviews or opinions on the goods. Fake reviews have many drawbacks that can influence people's decisions to buy commercial goods, including it might be difficult since a term might be positive in one situation but harmful in another. For example, saying "long" while referring to a laptop's battery life is a favourable attitude, yet using the same word when referring to the startup time is unfavourable. The opinion mining system trained on words from many viewpoints cannot comprehend a word's nature, which has multiple interpretations that depend upon context. Different people have different ways of expressing themselves. Almost all traditional text-processing techniques operate under the presumption that minute textual differences have little impact on meaning. The difficulty in determining reviews that were intentionally edited is tricking people by using various DM methods. People frequently make contradictory statements, which makes it difficult to ascertain their opinions. A negative review can actually have a positive meaning. Opinions of the product may periodically be negative or positive. They also examined the benefits and drawbacks of data mining (DM) techniques to anticipate dishonest and honest ratings.
3.4 XGBoost
The gradient boosting approach has been scaled up and refined, and Extreme Gradient Boosting (XGBoost) was created to increase the model's performance. It is a piece of the Distributed Machine Learning Community's open-source library [19]. XGBoost is a flawless software and hardware solution that quickly and accurately enhances the current boosting approaches. Tianqi Chen developed it. Two tree construction methods are used in it: Scaled Quantile Sketch and Sparsity-aware Split Finding. These are two techniques for finding splits and choosing where to divide. A method for equitably distributing possible splits across the data to take into consideration the significance or weight of a particular data point is called a weighted quantile sketch. Through binning continuous data, a histogram is created; as a result, splits should be performed only once per bin instead of for each function value. A missing value in Split Finding with Handles for Sparsity directs the choice down the left or right path, depending on the feature, by figuring out the default path of the tree node, which shows that the XGBoost disregards rows with missing data. Like every other ML technique, XGBoost optimizes the loss function that defines the model's error. It accomplishes this by applying gradient descent to the loss function.
3.4.1 Stochastic gradient descent stochastic
A linear Gradient Descent classifier increases algorithm performance and lowers the cost function to produce a more accurate model. Using the classifier function SGD Classifier, we put this method into action. Despite the SGD Algorithm, despite its apparent lack of complexity, has emerged as a leading contender among the default standard optimization algorithms for ML classification methods such as the NN and LR. However, the gradient descent of the SGD favours picking a data instance at random. The model is a powerful facilitator because of its simplicity; the SGD Algorithm has been considered one of the effective and default standard optimization algorithms for ML classification, like the NN and LR. On the other hand, the gradient descent of the SGD is biased toward randomly selecting an instance of data [20]. This model is strong facilitation. Data categorization and NLP are two areas where traditional machine learning approaches have struggled, but SGD has proven effective at overcoming these challenges. Efficient and Rapid Computation.
3.4.2 Support vector classifier
The support vector classifier (SVC) can be defined as a subtype of SVM [1]. When dealing with problems involving two groups, a supervised ML model, or SVM, utilizes classification methods [1]. After receiving new data for each category, an SVM model could classify it [1]. An SVM produces a hyperplane or set of hyperplanes in a high- or infinite-dimensional space, which could be utilized for regression, classification, or other tasks like outliers’ detection [4]. Closer to the hyperplane than other data points, the support vectors affect the hyperplane's position and orientation [3]. An SVM algorithm should be able to handle new data that it has never seen before, in addition to classifying objects into two groups [5]. The main step of this approach based on the following parameters;
Parameter C for the regularization process. A more complicated model with less room for error will arise from increasing C. If you set C lower, your model will be easier to understand and have more room for error.
The kernel functions. The data is mapped onto a higher-dimensional space, where the classes are more easily linearly separable, using the kernel function.
Kernel coefficient, or gamma. Each data point's weight in determining the decision boundary is determined by the gamma coefficient.
Degree is the degree of the kernel of the polynomial.
Polynomial kernel constant term coefficient, denoted as coef0.
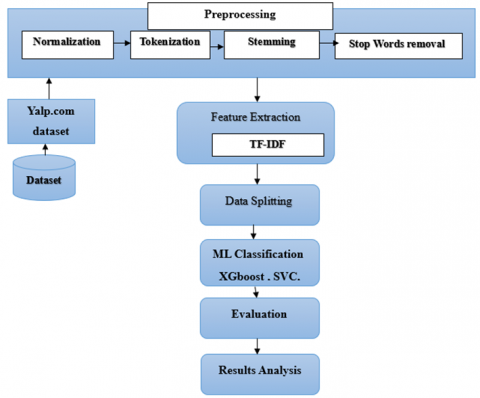
As depicted in Figure 2, the overall structure displays the processing phases of the training and testing data split. Afterwards, the testing data was used to evaluate the training model.
Figure 2. The general framework of the proposed method
4.1 Data-sets
A data-set is a group of data that is saved in any file format type, such as text, CSV, and others. Tabular data can be kept for this information. The rows denote the record for each column, and each column denotes a variable about that unique dataset. The data set was used to provide particular training data for the model. Table 1 states that the Excel file data set from Kaggel was employed [6].
Table 1. Yalp.com data-set
|
Variable |
Description |
|
User_id |
Index review |
|
Product_id |
This ID is unique within a dataset |
|
Review |
Fake review |
|
Rating |
(5-star) overall rating of satisfaction |
|
Date |
Review Date |
|
Features |
Fake review features |
|
Spam (1) and Not Spam (0) |
Opinion Spam Corpus |
|
Sentiment |
Positive and negative opinions |
4.2 Preprocessing
Data preprocessing is the second step of the suggested method. It is crucial in many supervised learning approaches as well as text mining. The suggested system's preprocessing procedures are a crucial step in achieving excellent results. There are four internal processes: Stopword removal, stemming, normalization, and tokenization.
4.2.1 Normalization
This method combines several forms of the same letter by eliminating everything (symbols and numerals) and changing all characters to uppercase or lowercase. Standardized steps include: - Deleting all numbers. - Removing all symbols, such as !, ?, #, $, @, *, [ ], { },, =, %, &, (),-, _,;,:-, ", !=, +, ', and /. - Convert each word to the lowercase (LC).
4.2.2 Tokenization
This is the second step in the pre-processing review. This process divides each review phrase into individual words or tokens according to the spaces between the words. Moreover, it is an efficient process for sentiment analysis.
4.2.3 Stemming
The word's suffix is being removed in order to return it to its original stem. It is a crucial method for reducing computation time and vocabulary size in NLP, particularly in sentiment analysis. Porter stemming was utilized in the suggested method to minimize calculations and feature space requirements.
In this phase we used a removing stop word: As stop words cannot significantly contribute to the meaning of customer comments, this is a crucial phase in the sentiment analysis process. These, along with other regularly used words like "is," "to," "for," "one," and "in," were employed in natural language.
4.3 Features extraction
A pattern recognition or machine learning system can be improved by feature extraction. Distilling the data down to its essential components includes feature extraction. The loader now has access to more pertinent data. Features extraction is a method for eliminating extraneous characteristics from the data, which might decrease the model's accuracy.
4.3.1 Term Frequency-Reverse Document Frequency (TF-RDF)
The TF-RDF algorithm's overarching goal is to transform text into an understandable representation of numbers. Which is employed in order to modify machine algorithms for the process of prediction. The review R is written as (W1, W2, W3,..., Wn), where Wi stands for the feature's weight in the review R. The terms for attribute weighting techniques are as follows:
i. Term Frequency (TF)
Every feature in the review has had its TF assessed by keeping track of how frequently it appears. With this approach, a characteristic's significance in an evaluation is emphasized. The TF formula is as follows:
Tf (T, R) = f (T, R) (1)
where, T= term, R= Text review, and D= Dataset
For example:
review A = “Love it! Well made, sturdy, and highly comfortable. I love it! So pretty".
review B = “They’re the perfect touch for me, but the only thing that I wish they had been a little bit bigger space”.
ii. Inverse Document Frequency (IDF)
IDF is one of the most widely used feature weighting approaches for rating feature relevance across a group of evaluations, unlike TF, which determines feature importance in one review. The IDF has been founded on the notion that a feature must be simple to distinguish from other features if it only appears in a small number of them. The equation is used to calculate the IDF. An example calculates the frequency of negative reviews. The following is the formula for calculating IDF:
$(\mathbf{t}, \mathbf{R})=\log \frac{N}{|\{d \in D: t \in d\}|}$ (2)
where, N represent the number of text reviews in the dataset.
iii. Term Frequency - Inverse Document Frequency TF-IDF
It compares how frequently an attribute appears in a given score to how frequently it does in the training set Intuitive. This computation establishes an attribute's suitability for a given assessment. For instance, this equation provides the formula for calculating TF-IDF:
TF-idf (T, R, D) = tf (T,R) × idf (T, D) (3)
Here we have several feature-extraction options to contrast, such as the TF-IDF and a word-count list (BoW). In contrast to TF-IDF, which considers inverse document frequency and term frequency while weighing each term, the BoW displays the frequency with which a word or set of words appears in a text.
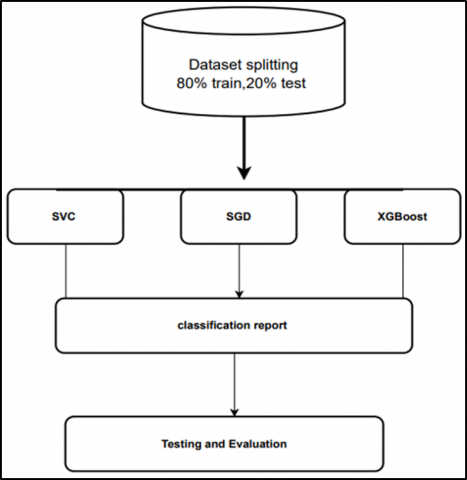
The suggested model identifies fake reviews using machine learning, including SVC, SGD, and (XGboost). The dataset utilized in the implementation is separated into training and testing data based on its actual characteristics, with 80% for training and 20% for testing. It is arguable if the fake review filters increase the user’s confidence in the review system. The price of filters might go much higher. Such behavior fosters mistrust by increasing the knowledge of bogus reviews. The proposed method looks into and analyzes the comments, classifying them as either real or fake. The Yelp.com dataset's real features, such as spam (1) and not spam (0), as well as features (stop words removed), are used in this model's feature extraction and sentiment analysis. Figure 3 demonstrates our ML technique. Most crucially, we process three ML algorithms' approaches concurrently.
Figure 3. Machine learning approach
The experiments used to determine the usefulness of the supervised grade using the typical hotel review dataset are presented in this section. Two grams, spam (1) and not spam (0), were utilized as features for training and testing the suggested classifier. The suggested classifier's primary objective was to detect and classify the review text as a real or fake review.
6.1 Word clouds
Word clouds are a method for visualizing a review's most significant and frequently occurring words Each word's size and prominence in the text is proportional to how often it appears. Word clouds are regularly employed in order to highlight the most salient or prevalent terms in a document.
Figure 4. Real not spam
Figure 5. Fake spam
Figures 4 and 5 show the word clouds of fake reviews and comments about the words "one, one, go back," "real, not spam," and "spam as fake," respectively.
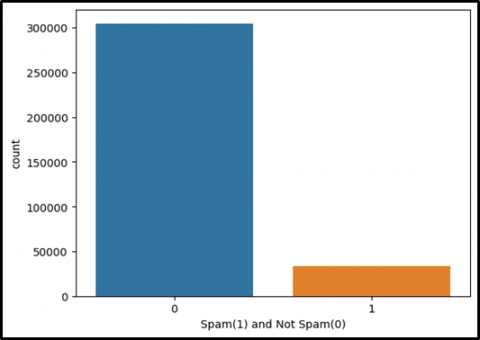
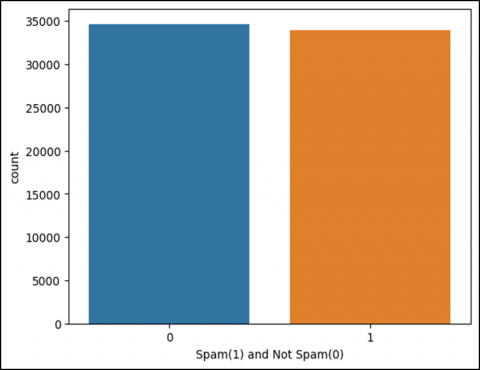
To visualize the dataset Figure 6 shows the original dataset. As we mentioned earlier, we balanced the dataset through random sampling methods. Figure 7 shows the balanced dataset.
Figure 6. Original dataset
Table 2. Classification report for three machine-learning methods with balanced and imbalanced datasets in random sampling
Unbalanced data
|
Classifier |
Precision |
Recall |
F1-score |
Support |
Class |
Accuracy |
|
XGBClassifier |
0.90 |
1.00 |
0.95 |
60929 |
0 |
0.90 |
|
|
0.71 |
0.00 |
0.00 |
6793 |
1 |
|
|
LinearSVC |
0.90 |
1.00 |
0.95 |
60929 |
0 |
0.90 |
|
|
0.27 |
0.00 |
0.00 |
6793 |
1 |
|
|
SGDClassifier |
0.90 |
1.00 |
0.95 |
60929 |
0 |
0.90 |
|
|
0.00 |
0.00 |
0.00 |
6793 |
1 |
|
Balanced data
|
Classifier |
Precision |
Recall |
F1-score |
Support |
Class |
Accuracy |
|
XGBClassifier |
0.65 |
0.57 |
0.59 |
7002 |
0 |
0.61 |
|
|
0.58 |
0.62 |
0.60 |
6716 |
1 |
|
|
LinearSVC |
0.63 |
0.56 |
0.59 |
7002 |
0 |
0.60 |
|
|
0.59 |
0.66 |
0.62 |
6716 |
1 |
|
|
SGDClassifier |
0.63 |
0.56 |
0.59 |
7002 |
0 |
0.61 |
|
|
0.59 |
0.66 |
0.62 |
6716 |
1 |
|
Table 3. The classification report results
Under-sampling
|
Classifier |
Precision |
Recall |
F1-score |
Support |
Class |
Accuracy |
|
XGBClassifier |
0.94 |
0.50 |
0.65 |
60929 |
0 |
0.52 |
|
|
0.14 |
0.72 |
0.23 |
6793 |
1 |
|
|
LinearSVC |
0.93 |
0.58 |
0.71 |
60929 |
0 |
0.58 |
|
|
0.14 |
0.64 |
0.24 |
6793 |
1 |
|
|
SGDClassifier |
0.94 |
0.52 |
0.67 |
60929 |
0 |
0.54 |
|
|
0.14 |
0.71 |
0.24 |
6793 |
1 |
|
Random Oversampling
|
Classifier |
Precision |
Recall |
F1-score |
Support |
Class |
Accuracy |
|
XGBClassifier |
0.94 |
0.54 |
0.68 |
60929 |
0 |
0.55 |
|
|
0.14 |
0.68 |
0.23 |
6793 |
1 |
|
|
LinearSVC |
0.93 |
0.66 |
0.77 |
60929 |
0 |
0.65 |
|
|
0.15 |
0.55 |
0.24 |
6793 |
1 |
|
|
SGDClassifier |
0.94 |
0.53 |
0.68 |
60929 |
0 |
0.55 |
|
|
0.14 |
0.71 |
0.24 |
6793 |
1 |
|
Table 4. Comparison of selected researchers
|
NO. S |
Authors |
Utilized Method |
Performance |
|
1 |
Elmurngi and Gherbi [4] |
Naïve Bayes; SVM; KNN KStar DecisionTree -J48. |
70.9% 76%
70.5% 69.4% 69.9% |
|
2 |
Elmogy et al. [5] |
SVMs NB K-NN Random forest Logistic Regression |
accuracy has been acquired with the use of the SVM classifier with a 86.90% score |
|
3 |
Bansode and Birajdar [6] |
LR KNN SVM NB SGD |
77.58% 60.54% 76.25% 75.38% 77.81% |
|
4 |
Anas and Kumari [7] |
Random forest Naïve Bayes |
89.487 79.007 |
|
5 |
Proposed model |
LightGBM SVD SGD |
90% 90% 90% |
Figure 7. Balanced dataset
We did three different experiments in training to reach model stability. Table 2 shows the classification report for three machine learning methods with balanced and imbalanced datasets in random sampling. A series of tests were utilized to evaluate the model once it had been trained and tested. Accuracy, precision, recall, and an F1 score are the possible evaluation metrics for the model's performance. When false reviews were discovered, the proposed system was assessed using the dataset and a justification of the findings. Using a collection of data from Yelp.com, the suggested model was trained and put to the test. Also, the test dataset utilized to evaluate the performance of the suggested system was provided in this work.
To test our models, we tried experimenting with over-sampling and under-sampling techniques. Table 3 shows the classification reports.
As a value, the sentiment analysis of the fake review aids consumers in selecting the best services and goods while getting valuable public opinion and input. Table 4 displays studies for detecting fake reviews in e-commerce. The approaches utilized in training to determine the best worldwide fake review based on opinion are what caused the accuracy ratios in this work. This includes the name of the author or each researcher, the study's name, the method or algorithm each researcher employed, their conclusions about accuracy, and a summary of e-commerce perspectives.
In this paper, we applied three machine learning approaches to detect fake reviewer, and the results were somewhat similar. The approach of the current work can accurately identify the false reviews on the Yelp dataset in terms of balanced and unbalanced.
Our methodology shows effective results with an imbalanced dataset for binary classes. In contrast to the prior study, the suggested model in the present study could accurately detect fake reviews in the Yelp data set.
The following are suggestions for future works:
1- A further in-depth investigation could take time performance and other analysis approaches into account to evaluate whether a specific person posts too many reviews quickly.
2- Including other datasets in this work, like the Amazon dataset. The future study will use deep learning techniques (such as LSTM, CNN, and RNN).
3- We highly recommend a hybrid feature selection and sentiment analysis method for more accurate results.
4- As part of the recognize user behavior strategy, more effort should be put into developing chatbots that can accurately read and react to human emotions.
[1] Alexandridis, G., Varlamis, I., Korovesis, K., Caridakis, G., Tsantilas, P. (2021). A survey on sentiment analysis and opinion mining in Greek social media. Information, 12(8): 331. https://doi.org/10.3390/info12080331
[2] Hemmatian, F., Sohrabi, M.K. (2019). A survey on classification techniques for opinion mining and sentiment analysis. Artificial intelligence review, 52(3): 1495-1545. https://doi.org/10.1007/s10462-017-9599-6
[3] Hossain, M.F. (2019). Fake review detection using data mining. Missouri State University. https://bearworks.missouristate.edu/theses/3423.
[4] Elmurngi, E., Gherbi, A. (2018). Fake reviews detection on movie reviews through sentiment analysis using supervised learning techniques. International Journal on Advances in Systems and Measurements, 11(1): 196-207.
[5] Elmogy, A.M., Tariq, U., Ammar, M., Ibrahim, A. (2021). Fake reviews detection using supervised machine learning. International Journal of Advanced Computer Science and Applications, 12(1): 601-606.
[6] Bansode, M., Birajdar, A. (2021). Fake review prediction and review analysis. International Journal of Innovative Technology and Exploring Engineering, 10(7): 143-151.
[7] Anas, S.M., Kumari, S. (2021). Opinion mining based fake product review monitoring and removal system. In 2021 6th International Conference on Inventive Computation Technologies (ICICT), pp. 985-988. https://doi.org/10.1109/ICICT50816.2021.9358716
[8] Vidanagama, D.U., Silva, A.T.P., Karunananda, A. S. (2022). Ontology based sentiment analysis for fake review detection. Expert Systems with Applications, 206: 117869. https://doi.org/10.1016/j.eswa.2022.117869
[9] Seerat, B., Azam, F. (2012). Opinion mining: Issues and challenges (A survey). International Journal of Computer Applications, 49(9): 42-51.
[10] Rathor, A.S., Agarwal, A., Dimri, P. (2018). Comparative study of machine learning approaches for Amazon reviews. Procedia computer science, 132: 1552-1561. https://doi.org/10.1016/j.procs.2018.05.119.
[11] Semchedine, M., Bensoula, N. (2022). Enhanced black widow algorithm for numerical functions optimization. Revue d'Intelligence Artificielle, 36(1): 1-11. https://doi.org/10.18280/ria.360101
[12] Al-Jarrah, M.A., Al-Jarrah, A., Jarrah, A., AlShurbaji, M., Magableh, S.K., Al-Tamimi, A.K., Bzoor, N., Al-Shamali, M.O. (2022). Accurate reader identification for the Arabic Holy Quran recitations based on an enhanced VQ algorithm. Revue d'Intelligence Artificielle, 36(6): 815-823. https://doi.org/10.18280/ria.360601
[13] Paramasivan, S.K. (2021). Deep learning based recurrent neural networks to enhance the performance of wind energy forecasting: A review. Revue d'Intelligence Artificielle, 35(1): 1-10. https://doi.org/10.18280/ria.350101
[14] Karupusamy, S., Maruthachalam, S., Mayilswamy, S., Sharma, S., Singh, J., Lorenzini, G. (2021). Efficient computation for localization and navigation system for a differential drive mobile robot in indoor and outdoor environments. Revue d'Intelligence Artificielle, 35(6): 437-446. https://doi.org/10.18280/ria.350601
[15] Sjaif, N.N.A. (2021). A survey on sentiment analysis approaches in e-commerce. International Journal of Advanced Computer Science and Applications, 12(10): 674-679.
[16] Al-Adhaileh, M.H., Alsaade, F.W. (2022). Detecting and analysing fake opinions using artificial intelligence algorithms. Intelligent Automation & Soft Computing, 32(1): 644-655. https://doi.org/10.32604/iasc.2022.02225
[17] Mohawesh, R., Xu, S., Tran, S.N., Ollington, R., Springer, M., Jararweh, Y., Maqsood, S. (2021). Fake reviews detection: A survey. IEEE Access, 9: 65771-65802. https://doi.org/10.1109/ACCESS.2021.3075573
[18] Kumar, J. (2020). Fake review detection using behavioral and contextual features. arXiv preprint arXiv:2003.00807. https://doi.org/10.48550/arXiv.2003.00807
[19] Nahma, D.R., Abbas, A.R. (2020). Patient opinion mining: Analysis of patient drugs satisfaction using support vector machine and logistic regression algorithm. Journal of Madenat Al-Elem College/Magallat Kulliyyat Madinat Al-ilm, 12(2): 164-171.
[20] Sharma, A. (2018). Guided stochastic gradient descent algorithm for inconsistent datasets. Applied Soft Computing, 73: 1068-1080. https://doi.org/10.1016/j.asoc.2018.09.038