Omar Kanaan Taha Alsultan![]() | Mohammad Tarik Mohammad*
| Mohammad Tarik Mohammad*![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Individuals with visual impairments frequently confront substantial difficulties in interacting with their environment, a problem that is often exacerbated by the cost and accessibility of existing assistive technologies. This study introduces a prototype for a cost-effective and accessible assistive device that employs deep learning techniques for object recognition. The proposed system utilizes the YOLO-V7 model, a deep learning algorithm trained on a comprehensive dataset encompassing various everyday objects, including US dollar denominations. In conjunction with two transfer learning-based cascade models, the system offers detection across 86 object categories. Upon object identification, the name of the item is converted into a Braille-readable format using the Python Braille library. Comprehensive experiments and analyses were undertaken to assess the efficacy of the proposed system. The results corroborate the system's effectiveness in achieving its intended purpose, demonstrating its potential to significantly aid visually impaired individuals in recognizing and interacting with objects in their environment. With a processing and Braille code generation time of 188.5 ms per frame, the model achieved recall, precision, and mAP scores of 0.81, 0.92, and 0.96, respectively. The integration of deep learning technology with high-performance platform boards has facilitated the development of a promising solution to the challenges faced by visually impaired individuals in environmental interaction. Overall, the proposed prototype represents an accessible and cost-effective assistive device, potentially revolutionizing the manner in which visually impaired individuals interact with their surroundings.
blind person, Braille code, object detection, YOLO-V7, transfer learning, text to speech
Vision, one of the most vital senses in humans, is critical to our survival and accounts for approximately 83 percent of the information humans acquire [1]. For individuals living with visual impairments, performing routine tasks and interacting with the external world can pose significant challenges. Such individuals often find it difficult to navigate, identify objects, drive, recognize currency, or travel independently. Many visually impaired people rely on sighted companions to navigate unfamiliar environments, compounding the challenges they face in their daily lives [2]. These interpersonal barriers can reduce opportunities for socialization for visually impaired individuals, potentially leading to diminished self-esteem. A 2022 survey by the World Health Organization (WHO) reported that an estimated 2.2 billion individuals globally suffer from near or distant vision impairment. Astonishingly, preventative measures could have been implemented or are still unaddressed in at least 1 billion of these cases. The global cost of productivity losses associated with visual impairment is estimated to be US$411 billion annually, exerting a significant financial burden on the global economy [3]. The majority of individuals afflicted with visual impairment and blindness are over the age of 50. Although visual loss can affect individuals across all age groups, it is predominantly observed in this demographic [3]. This trend underscores the urgent need for accessible and cost-effective solutions to support visually impaired individuals in their daily activities and interactions with the world around them.
The person who suffers from blindness or any visual issue continuously needs a support system; it can assist in imagining the actual world and enjoying ordinary life. Many techniques have been developed by researchers. Object detection is one of the promising techniques that uses artificial intelligence to detect different objects. The following is an overview of some related works in this area:
In 2018, Potdar et al. [4] used a convolutional neural network to recognize pre-trained items on the ImageNet dataset. A camera aligned with the system's predetermined orientation serves as input to a computer system, which has the object identification neural network installed to perform real-time object detection. The network output can then be processed and presented to the visually impaired person in the form of audio or Braille text. In 2019, Bhandari et al. [5] analyzed twelve systems, and several CNN approaches were compared in terms of design and applicability. If an individual requires assistance, such as a system that aids with opening and shutting doors, other things will be concealed, necessitating the use of more than one system. In 2021, Mahendran et al. [6] offered an improvement and the development of a revolutionary, comprehensive vision system for the visually handicapped for interior and outdoor navigation, as well as scene perception. In 2022, Rama Devi et al. [7] developed an integrated machine learning system technology that allows blind patients to recognize and categorize real-time items using voice input and distance. This also generates alerts regardless of how close or far they are to the object. This technology provides voice guidance to visually impaired people.
In 2022, Kumar and Jain [8] presented an upgrade and built a 3D model designed in CAD with Fusion 360 and subsequently printed. A machine-learning algorithm trains the wearable gadget to recognize important items in the user's route, and a vision-based stick employs GPS, ultrasonic, and a camera to improve the accuracy of the existing model. In 2022, Ganesan et al. [9] presented a system that incorporates text and visuals from course books: CNN extracts the necessary information, whereas LSTM describes the visual input. The data is sent to users in the form of voice messages generated by the text-to-speech module. The LSTM model is trained using the Alexnet, GoogleNet, ResNet, SqueezeNet, and VGG16 networks. According to studies, the LSTM-based training model delivers the best picture descriptions and predictions.
The limitations of current systems and technologies highlight the need for an accessible and cost-effective solution that can enable people who are blind to effectively and freely engage with their environment. This paper suggests a prototype of an assistive smart gadget that makes use of deep learning techniques to address the problems faced by people who are visually impaired in response to this demand. It aims to address the limitations of existing technologies by leveraging the advancements in deep learning, specifically the YOLO-V7 model. Due to its outstanding accuracy in object analysis and recognition, deep learning has become a potent solution. We can identify a variety of object categories using the YOLO-V7 model, including necessities like US dollars that are necessary for daily living. To ensure the accessibility of our system, the Python Braille library is integrated, which transforms object identifiers into Braille code that can be read by a Braille displayer. This makes it possible for the visually impaired person to understand and use items in their environment without difficulty or dependence. This paper is organized as follows: you only look once (YOLO) is presented in section two, while section three demonstrates the Braille code. Sections four and five contain system methodology and results. Finally, the conclusion is presented in section six.
You Only Look Once is an open-source, convolutional neural network (CNN) for performing real-time object detection techniques. Although the original YOLO model established a single-stage detection framework, it had difficulty detecting tiny objects accurately. Anchor boxes, multi-scale training, and hierarchical classification were all included in YOLO-V2, which also enhanced localization. With a redesigned architecture, feature pyramid networks, and numerous detection scales, YOLO-V3 improved accuracy even more. With innovations like CSPDarknet53 and new components, YOLO-V4 produced cutting-edge results. To improve speed and effectiveness, YOLO-V5 simplified the architecture. The most recent scientific effort, YOLO-V7, was released in July 2022. This model is much faster than the previous ones. It recognizes pictures at speeds ranging from 5 FPS to 160 FPS with a mean average precision (AP) of 56.8%. YOLO-V7 is selected in the proposed system due to its high accuracy and fast real time speed compared with other object detection methods as shown in Table 1. These criteria are very important to the proposed system. The YOLO model was created using Python's PyTorch module. This is a machine learning framework that is open source and uses increased processing performance to expedite the route from the research prototype to production deployment. The YOLO-V7 excellently blends speed and precision, earning it industry popularity. Figure 1 depicts the typical detection pipeline's three components: the backbone, encoder, and decoder. The YOLO-V7 structure is divided into three parts: input, the backbone feature extraction network, the strengthened feature extraction network, and predictions [10].
Table 1. Object detection methods in terms of speed, accuracy, and suitability
|
Methods |
Speed |
Accuracy |
Suitability |
|
YOLOv7 |
Fast real-time |
High |
General object detection, real-time processing |
|
Faster R-CNN |
Slower |
High |
Precise localization, complex scenes |
|
SSD (Single Shot Detector) |
Fast real-time |
Moderate |
Real-time applications with balanced speed |
|
RetinaNet |
Fast |
Moderate |
Object detection in dense scenes and small objects |
Because every model has a basic framework, Some model structures may change depending on the model scale, however, this is the YOLO structure in general [11]. A convolutional neural network (CNN) serves as the backbone, image pixels are pooled to form features with varying granularities. Feature pyramids are used to distinguish between objects of differing sizes. The convolutional network layer representations are combined and mixed by the neck before being passed to the prediction head. The last section of CNN is the heading. The YOLO model predicts the locations and classifications of bounding boxes. The models in these investigations are trained using a transfer learning strategy using the pretrained weights file from the YOLO-V7 official GitHub source. There are various processes involved in training a custom model. The initial stage is to gather the dataset and tag image datasets using tools.
Figure 1. General detection pipeline [10]
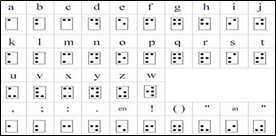
The tactile writing method known as Braille is used by visually impaired people. It may be viewed on a textured sheet or refreshable Braille displays [12]. A language does not seem to be braille; it is a code that can represent language. All languages can be written and read with this code. Today, Braille is utilized in practically every nation and has been translated into almost all spoken languages, Additionally, Braille codes have been created to represent the various symbols used in shorthand, highly technical and advanced mathematical writing, and musical notation. Braille cells are the discrete spaces where Braille codes are formed. As seen in Figure 2, a complete Braille cell is made up of six raised dots organized in two perpendicular vertical rows, each with three dots. The numerals one through six specify the dot position. Combining each of these six dots, 63 combinations are achievable. A number, punctuation mark, letter of the alphabet, or even a whole word can be represented by a cell [13].
Figure 2. Standard Braille English alphabets [13]
A system for visually impaired assistance was implemented using YOLO-V7 deep learning algorithm. The dataset was constructed to train the YOLO-V7 network model. The network result is processed to generate Braille code.
4.1 Dataset construction
The YOLO network model was trained using a dataset that was constructed from different images for the items. In the proposed system, 86 different category items are detected. For 80 category item images, Microsoft COCO (Common Objects in Context) uses an open dataset that is available online for the developer which contains 123,287 images and 886,284 instances. For the other six items, manually collect a dataset containing the images of the items. Utilizing a variety of online sources, each image was visually inspected. The dataset is constructed with a large, balanced distribution of items after any inappropriate photographs have been carefully removed. a variety of United States dollars $\$ 1, \$ 5, \$ 10, \$ 20, \$ 50$, and $\$ 100$ are collected. Two hundred images were collected for each dollar category; different orientations and half-crop items were picked. These images are passed into the augmentation process. There are four types of augmentation: performing a noise effect on images up to 5% of the pixels. Sher effect of up to 10% in both horizontal and vertical directions. The brightness affects between -25% and 25% of the exposure. the effect between -15% and 15%. Adding these effects helps the model be more resilient to changes in light and camera settings as shown in Figure 3. The “Roboflow” website [14] provides everything you need to turn images into information. It involves all the tools necessary for managing, labeling, and augmenting. All dataset images are exported into Yolo-V7 format.
Figure 3. Various image augmentation approaches on acquired images
4.2 YOLO model training
Two cascade Yolo models are used in the proposed system. the first model that detects 80 categories based on Microsoft COCO. YOLO-V7 is already based on this data set, and all the model weights inherited from the pretrained model are available on the official YOLO-V7 website. The second model is trained on the manually collected data set of the USD. About 3200 images are used, most of them for training more than 80 percent and some for validating and testing. Transfer learning is used to train the Yolo model to detect the required items. The same Microsoft COCO model was chosen for this process. Transfer learning from a pre-trained model produces the greatest increase in YOLO-V7 item detection accuracy. Also, reduce the model learning time needed in the process to provide an accurate result during careful use. The process starts by adding the collected data set to the pretrained model. A new class adds to the pretrained model. Freeze the convolutional base, compile the models, and then run the model train.
4.3 System diagram
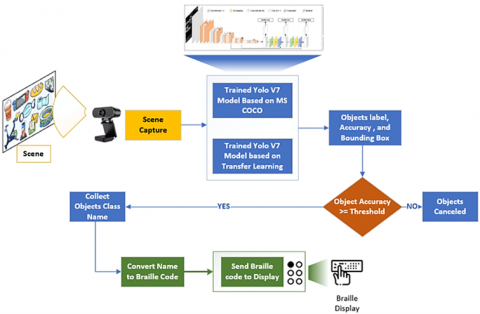
The system starts by capturing the scene using an image acquisition, as illustrated in Figure 4, which may be done with the camera. The image is fed into two cascades of trained YOLO-V7 models. Two models are used to detect the 86 categories of objects. Each model produces output for each detected object, including a label, accuracy percentage, and bounding box. Only the object that exceeded the predetermined accuracy threshold will be processed in the next steps. The suggested method has no shape restrictions and can detect many items in a single image. For various object labels which is the name of the object as a string, is transformed into Braille code. The Python Braille Library is used to convert names into Braille code. This code can be displayed on any Braille code displayer. As a result, the visually impaired individual can read it from the Braille display.
Figure 4. Visually impaired assistant system diagram
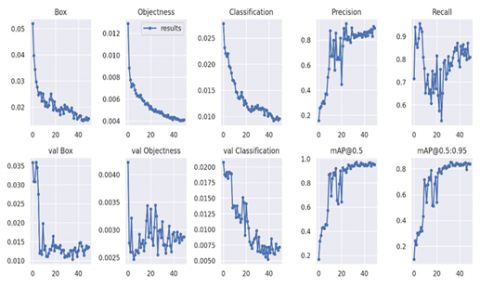
The performance of the proposed system has been evaluated through different procedures. The transfer learning model is trained using the manually collected images to detect the six categories. The Google Colab platform with an Intel Xeon CPU (2.00 GHz), an NVIDIA Tesla T4 GPU, and 12 GB of RAM is used to train the model. The dataset is linked to the Google Colab code using a Roboflow account to feed the model with images. The MS COCO YOLO-V7 pretrained model weight is appended to the model as the starting point. The Yolo-V7 backbone part of the model is frozen, then it starts to train. Several measures, including recall, accuracy, and mean average precision, are used to assess the trained model. Figure 5, demonstrates the metrics curves' evolution during the period of the training, and the model achieves scores of 0.81 for recall. The precision score was 0.92, while the mAP score was 0.96. The model was trained across 50 epochs only; this is the expected achievement of transfer learning, as shown in Figure 6. The model's ability to detect and identify US currency has been demonstrated by the testing results.
Figure 5. Metrics curves for the model training
Figure 6. Sample for the model detecting
Two cascade YOLO-V7 models were tested by passing images from the internet to detect the objects in the images. The model's result shows the model's ability to detect the 86 category items as shown in Figure 7.
(a) (b)
Figure 7. (a) Original image. (b) Image after detecting an object and placing its name on the image
The proposed system is tested using an image captured by a web camera with real time processing. The camera converts the scene into an image, which is then fed into the cascade model. Five objects were detected with a different label, and accuracy as shown in Figure 8. Detected objects are processed to determine the desirable object. Two objects (a couch and 20 dollars) drop because they have not exceeded the predetermined threshold. Three objects are labeled and converted to Braille (a person, a cell phone, and a remote control). forms for the Braille code are produced by the system: first, an image for the Braille code using dots. Second, a two-dimensional array that specified the state of the six dots that implement each character. The number of elements in the array is equal to the number of characters in the label. These arrays can be sent directly or preprocessed to be used with any Braille code display. Table 2 shows the Braille code for the three detected objects. The proposed system can process and generate Braille code every 188.5 ms per frame.
(a) (b)
Figure 8. (a) Scene captured image. (b) Detected objects based on model output
Table 2. Proposed system braille code sample
|
Object Label |
Braille Code |
Braille Code Implemented with an Array |
|
Person |
⠏⠑⠗⠎⠕⠝ |
p [[1, 1], [1, 0], [1, 0]] e [[1, 0], [0, 1], [0, 0]] r [[1, 0], [1, 1], [1, 0]] s [[0, 1], [1, 0], [1, 0]] o [[1, 0], [0, 1], [1, 0]] n [[1, 1], [0, 1], [1, 0]] |
|
Cell phone |
⠉⠑⠇⠇⠀ ⠏⠓⠕⠝⠑ |
c [[1, 1], [0, 0], [0, 0]] e [[1, 0], [0, 1], [0, 0]] l [[1, 0], [1, 0], [1, 0]] l [[1, 0], [1, 0], [1, 0]] [[0, 0], [0, 0], [0, 0]] p [[1, 1], [1, 0], [1, 0]] h [[1, 0], [1, 1], [0, 0]] o [[1, 0], [0, 1], [1, 0]] n [[1, 1], [0, 1], [1, 0]] e [[1, 0], [0, 1], [0, 0]] |
|
Remote |
⠗⠑⠍⠕⠞⠑ |
r [[1, 0], [1, 1], [1, 0]] e [[1, 0], [0, 1], [0, 0]] m [[1, 1], [0, 0], [1, 0]] o [[1, 0], [0, 1], [1, 0]] t [[0, 1], [1, 1], [1, 0]] e [[1, 0], [0, 1], [0, 0]] |
The proposed system stands out from other object detection methods due to its high accuracy, and suitability for general object detection across multiple categories of 86 classes as shown in Table 3. Its integration of deep learning, YOLOv7 model, and assistive technologies offers a comprehensive and efficient solution for visually impaired individuals using the brille code which offers a promising transducer. This transducer can sense any healthy part of the person's hand and also become a solution for users that suffers from hearing problem.
Table 3. Comparison with other assistive work for the visually impaired
|
References |
Classes |
Algorithm |
Extra Sensor |
Dataset |
Cost |
Accuracy |
Transducers |
|
[15] |
13 |
SSD |
Laser sensor |
Custom dataset |
Low |
99.3% to 98.4% |
Sound (Head phone) |
|
[16] |
80 |
YOLO v3 |
No |
MS COCO dataset |
N/A |
85% to 95% |
Sound (Head phone) |
|
[17] |
12 |
ORCS |
No |
Custom dataset |
N/A |
N/A |
Sound (Head phone) |
|
[18] |
5 |
YOLO |
No |
Custom dataset |
N/A |
90% |
Sound (Head phone) |
|
[19] |
4 |
YOLO v4 |
No |
Custom dataset |
N/A |
N/A |
Sound + App |
|
[20] |
4 |
YOLO v3 |
No |
Custom dataset |
N/A |
87% to 90% |
Sound |
|
Proposed System |
86 |
YOLO v7 |
No |
MS COCO + Custom |
Low |
96% |
Brille Code |
For those who are blind or visually challenged, combining the YOLOv7 model with assistive technology has substantial practical advantages. The technology provides greater contact with the environment, increasing independence and overall quality of life by properly detecting and identifying things in real-time. It improves object identification and enables users to recognize common objects, read labels, and calculate money values. To ensure safe navigation, the system analyzes the area and delivers crucial information about obstructions. It improves access to information through digital displays, by translating object names into Braille code. By giving real-time information on adjacent items or people, the technology encourages social engagement while improving inclusiveness and confidence. Overall, the approach empowers people with visual impairments by promoting autonomy, reducing dependency, and expanding chances for personal development and social involvement. Accuracy, item category coverage, flexibility to dynamic contexts, tolerance to fluctuations, cost, and human involvement are some of the constraints of the existing technology. Future work should concentrate on raising accuracy for challenging scenarios, improving item category coverage, handling dynamic environments, enhancing robustness, lowering expenses, and taking user feedback into account. This can be accomplished by employing strategies such as alternative object detection algorithms, training on a variety of datasets, development of tracking capabilities, improvement of adaptability to environmental variations, exploration of affordable hardware options, and incorporation of user-friendly interaction mechanisms. These developments will result in a system for people who are blind or visually impaired that is more precise, adaptable, accessible, and user-centric.
[1] Parab, A., Nagare, R., Kolambekar, O., Patil, P. (2020). Electronic orientation aid for visually impaired using graphics processing unit (GPU). ITM Web of Conferences, 32: 03054. https://doi.org/10.1051/itmconf/20203203054
[2] Vaidya, S., Shah, N., Shah, N., Shankarmani, R. (2020). Real-time object detection for visually challenged people. In 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, pp. 311-316. https://doi.org/10.1109/ICICCS48265.2020.9121085
[3] World Health Organization official website. https://www.emro.who.int/control-and-preventions-of-blindness-and-deafness/announcements/global-estimates-on-visual-impairment.html, accessed on Jan. 2023.
[4] Potdar, K., Pai, C.D., Akolkar, S. (2018). A convolutional neural network based live object recognition system as blind aid. arXiv preprint arXiv:1811.10399. https://doi.org/10.48550/arXiv.1811.10399
[5] Bhandari, A., Prasad, P.W.C., Alsadoon, A., Maag, A. (2019). Object detection and recognition: Using deep learning to assist the visually impaired. Disability and Rehabilitation: Assistive Technology, 16(3): 280-288. https://doi.org/10.1080/17483107.2019.1673834
[6] Mahendran, J.K., Barry, D.T., Nivedha, A.K., Bhandarkar, S.M. (2021). Computer vision-based assistance system for the visually impaired using mobile edge artificial intelligence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, pp. 2418-2427. https://doi.org/10.1109/CVPRW53098.2021.00274
[7] Rama Devi, P., Sahaja, K., Santrupth, S., Tony Harsha, M.P. Balasubramanyam Reddy, K. (2022). Blind assistance system using image processing. Global Journals, 22(2): 2022. https://doi.org/10.22214/ijraset.2022.41102
[8] Kumar, N., Jain, A. (2022). A deep learning based model to assist blind people in their navigation. Journal of Information Technology Education: Innovations in Practice, 21: 95-114. https://doi.org/10.28945/5006
[9] Ganesan, J., Azar, A.T., Alsenan, S., Kamal, N.A., Qureshi, B., Hassanien, A.E. (2022). Deep learning reader for visually impaired. Electronics, 11(20): 3335. https://doi.org/10.3390/electronics11203335
[10] Wang, Y., Wang, H., Xin, Z. (2022). Efficient detection model of steel strip surface defects based on YOLO-V7. IEEE Access, 10: 133936-133944. https://doi.org/10.1109/ACCESS.2022.3230894
[11] Patkar, U., Shrivas, S.B., Patil, U., Songire, S. (2022). Using YOLO V7 development of complete VIDS solution based on latest requirements to provide highway traffic and incident real time info to the ATMS control room using Artificial intelligence. Preprint from Research Square. https://doi.org/10.21203/rs.3.rs-2390984/v1
[12] Ramos-García, O.I., Vuelvas-Alvarado, A.A., Osorio-Pérez, N.A., Ruiz-Torres, M.Á., Estrada-González, F., Gaytan-Lugo, L.S., Fajardo-Flores, S.B., Santana-Mancilla, P.C. (2022). An IoT braille display towards assisting visually impaired students in Mexico. Engineering Proceedings, 27(1): 11. https://doi.org/10.3390/ecsa-9-13194
[13] Kavalgeri, S.A., Chakraborthy, R.V., Naz, S.F., Chaitanya, K.J. (2019). E-Braille: A study aid for visual impaired. International Journal of Research in Engineering, Science and Management, 2(2): 131-135.
[14] roboflowofficial website. https://roboflow.com/, accessed on Jan, 2023.
[15] Rahman, M.A., Sadi, M.S. (2021). IoT enabled automated object recognition for the visually impaired. Computer Methods and Programs in Biomedicine Update, 1: 100015. https://doi.org/10.1016/j.cmpbup.2021.100015
[16] Shaikh, S., Karale, V., Tawde, G. (2020). Assistive object recognition system for visually impaired. International Journal of Engineering Research & Technology (IJERT), 9(9): 736-740.
[17] Joshi, R., Tripathi, M., Kumar, A., Gaur, M.S. (2020). Object recognition and classification system for visually impaired. In 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, pp. 1568-1572. https://doi.org/10.1109/ICCSP48568.2020.9182077
[18] Mahesh, T.Y., Parvathy, S.S., Thomas, S., Thomas, S.R., Sebastian, T. (2021). Cicerone-a real time object detection for visually impaired people. In IOP Conference Series: Materials Science and Engineering, 1085(1): 012006. https://doi.org/10.1088/1757-899X/1085/1/012006
[19] Aljarf, A., Almaghrabi, G., Albarakati, H., Ahmed, H., Alharbi, R., Aljuhani, S. (2022). EBSAR: Detecting of objects that hinder visually impaired in a controlled area using deep learning. In 2022 Fifth National Conference of Saudi Computers Colleges (NCCC), Makkah, Saudi Arabia, pp. 19-25. https://doi.org/10.1109/NCCC57165.2022.10067421
[20] Najm, H., Elferjani, K., Alariyibi, A. (2022). Assisting blind people using object detection with vocal feedback. In 2022 IEEE 2nd International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering (MI-STA), Sabratha, Libya, pp. 48-52. https://doi.org/10.1109/MI-STA54861.2022.9837737