Gyana Ranjan Panigrahi![]() | Prabira Kumar Sethy*
| Prabira Kumar Sethy*![]() | Surya Prasada Rao Borra
| Surya Prasada Rao Borra![]() | Nalini Kanta Barpanda
| Nalini Kanta Barpanda![]() | Santi Kumari Behera
| Santi Kumari Behera![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The advent of deep learning (DL) technologies has paved the way for a plethora of applications, the creation of hyperrealistic images via generative adversarial networks (GANs) being a compelling example. However, these synthetic images, nearly indistinguishable from genuine ones to the human eye, can be exploited for nefarious activities such as cybercrime, extortion, politically motivated campaigns, propaganda, among others. This paper proposes a deep ensemble learning approach to detect such counterfeit images, aiming to mitigate the issues arising from deepfake multimedia. The impetus for engaging ensemble models stems from their capacity to reduce the generalization error of predictions, provided the foundational models exhibit diversity and independence. Consequently, the prediction error diminishes when an ensemble approach is deployed. In this study, the CASIA v2 benchmark datasets, comprising 12,323 color images (5,123 originals and 7,200 counterfeits), were utilized. This investigation employed an ensemble of 13 pre-trained CNN models. The ensemble technique amalgamates these models to form a comprehensive perceptual model, wherein each model contributes to the final outcome. The classification predictions from each model are considered a 'vote', with the majority verdict serving as the final prediction. The proposed methodology was also juxtaposed with prevailing techniques. Assessment of our approach's efficacy revealed a 100% accuracy rate, 97.75% precision, 87.46% recall, and 99.9% AUC, underscoring the improvement offered by the proposed system.
digital image forensics, fake image detection, deepfake detection, deep learning, ensemble learning, convolutional neural network, multimedia
Digital media, such as digital images and documents, should be authenticated against forgery because of the availability of potent editing and manipulation tools. Newspapers, digital forensics, scientific research, medicine, and other professionals rely on digital photographs. Currently, digital photos are widely used and shared on social networking platforms. Digital photographs are regarded as one of the most important sources of knowledge. Using the widespread exchange of images and their platforms, such as Instagram, WhatsApp, Telegram, and Wikipedia, it is difficult to identify genuine photos of those that have been doctored. The availability of numerous photo-manipulation software tools makes it increasingly challenging to determine the authenticity of an image. Common passive picture forgery methods include splicing and copy-movement. To conceal certain vital information, one part is copied and pasted over another section in the same image in the copy-move forgeries. On the other hand, image splicing involves cutting and pasting one portion of one image over another region to generate an innovative digital image. Based on the aforementioned categorization, the fundamental concept of forgery detection is to discover an area with identical characteristics in the copy-move or wholly separate region in the spliced picture. The same pipeline is used by all forgery detection algorithms, which include matching, feature extraction, and postprocessing. Copy/move image forgery detection is simpler to identify than picture splicing because identical contours of an object can be easily detected in the same image owing to their identical sizes, transitions, and textures. Different textures, sizes, and transition properties are introduced during image splicing, making it difficult to detect fraud [1].
The detection of photomontage forgeries depends on the traces left behind after image manipulation. Inconsistency, camera-caused edge discontinuity, and geometric and illumination conditions are among the most common image-splicing concerns [2]. Multiple cameras capture images with distinct properties, and indication manipulation can be confirmed [3]. Additionally, dithering can lead to discrepancies in lighting. Because an image is subjected to two successive compression operations, a double quantization effect may result in the appearance of icing artifacts [4, 5]. Image manipulation typically leaves no visible traces; however, the image statistics can be altered. Copy and move [5] and cut-and-paste [6] recognition methods. After training on large datasets, cutting-edge algorithms such as MobileNet, CNN, and ResNet50v2 can identify and automatically extract possible characteristics owing to advancements in deep learning. CNN-based feature extraction includes in-depth features used for assessing the image quality [7], re-identification of a person [8], and classification of skin lesions [9]. These extracted features are integrated into the inherent structural patterns of the data. This is the primary reason for their non-discriminatory and robust architecture as opposed to handcrafted features [9]. Inspired by the deep learning method, this study presents a deep ensemble-based learning strategy for authentic/forged picture recognition [10, 11]. Here, by evaluating 13 independent CNN models as base learners, a deep ensemble learning technique was employed to obtain a good data-driven classifier fit. In the last few decades, many studies have been conducted to detect fake images. Deep learning detects accurate data and delivers explainable decisions and forensic analysis of an attention-based intelligible deep fake detector. The attention blocks examine the decision-making face of the model. To push the model to accommodate more facial parts without losing attention, it lowers and broadens the area. Researchers apply the Grad-CAM explanation to evaluate the models' attention map decisions and score 92.4% on the DFDC, a challenging dataset [12].
To identify Deepfake movies, ResNext uses a CNN algorithm with Long Short-Term Memory (LSTM). The built Deep-Learning (DL) model achieved 91% accuracy on the Celeb-Df dataset [13]. The COMSATS face database may assist future face identification and detection systems in improving their efficiency and reliability, including age estimation, gender classification, intellect, emotion, expression, age prediction, and modeling of facial features. The simulation results of the suggested database prove that the PAL face identification method can be reliably used for low-resolution pictures of face posture fluctuations in real time [14]. D3 is an ensemble-based method for deepfake detection that outperforms adversarial training and previous ensemble-based adversarial example defenses in terms of robustness. D3 is an ensemble-based method for spotting deepfakes, which greatly enhances adversarial resilience compared with adversarial training and other ensemble-based adversarial example defenses. GAN-generated deepfakes have redundancy in their frequency-space artifacts. Using this redundancy, we may construct disparate ensembles that foil the adversary's plan to focus on the commonly exploited characteristics. Technically, the ensemble strategy shrinks the subspace where adversarial deepfakes reside, and empirically, we establish that D3 provides substantial improvements in adversarial resilience under multiple attacks [15, 16]. The researchers utilized seven GAN-generated datasets and two open-source natural datasets (FFHQ and CelebA). The results of the experiments reveal that the proposed technique achieves a higher generalization accuracy than the modern current methods. In addition, the projected method is strong in contrast to attacks such as the insertion of Gaussian noise and blur [17]. Other systems cannot employ all the deepfake models. The deep learning system can detect them, but using the same model for various deepfakes may reduce the precision. Many of these methods are expensive and may become a practical issue. To identify deepfakes disseminating disinformation, average people must run models using ordinary people on their devices [18]. Furthermore, the regular use of various success metrics within papers has constrained our investigation, making it difficult to evaluate models rather than the models themselves [19]. DFDT is a vision-transformer-based end-to-end deepfake detection system. Unlike CNN-based deepfake detection methods, DFDT employs vision transformer networks to encode both local image characteristics and global pixel associations. DFDT outperforms many benchmarks, including Celeb-DF (V2), Face Forensics++, and Wild Deepfake, by 99.41%, 99.31%, and 81.35%, respectively. DFDT's cross-manipulation and cross-dataset generalization improved its efficacy [20].
This study examined the efficiency of score-level fusion in deepfake detection using the complementarity of six distinct state-of-the-art detectors. Several fusion strategies have been investigated, which can be broadly classified as non-parametric fusion, weighted average fusion, and classification model fusion. This was achievable because all the models under consideration were trained using comparable data from the FF++dataset (except ResNet, which was trained on an ad-hoc basis sample), allowing us to emphasize the merits of each fusion model [21]. By contrast, neural network algorithms include Xception, NAS-Net, VGG16, and MobileNet. All the study models were built using the benchmark deepfake dataset, which included genuine and fake faces. With applied learning approaches and state-of-the-art studios, the proposed DFP methodology outperformed other methods. For deep fake detection, the proposed model achieved an accuracy of 94%. Neural network approaches were confirmed using the confusion analysis method and examined using time series analysis [22].
The major contributions of this study are as follows:
The remainder of this paper is organized as follows. The materials and methodology are detailed in Section 2. Section 3 records the findings and provides a detailed discussion. Finally, the paper is concluded in Section 4.
This section details the dataset and the adapted methodology.
2.1 About dataset
The CASIA v2 dataset contains 12,323 color photos, 5123 authentic images, and 7200 forgeries. This collection contains photos with size variants ranging from 320×240 to 800×600, in addition to uncompressed TIFF, JPEG, and BMP examples. A genuine sample was derived from the dataset [23]. In contrast, the tampered subset was created by Splicing in Photoshop with pre- and postprocessing after blurring the authentic subset. Figure 1 shows the original and fake photos of the CASIA v2 dataset [24]. The particular image subset is broken down into nine different categories, which are as follows: scene, animal, architecture, character, plant, article, nature, indoors, and texture.
Figure 1. Samples of CASIA_V2
2.2 Proposed methodology
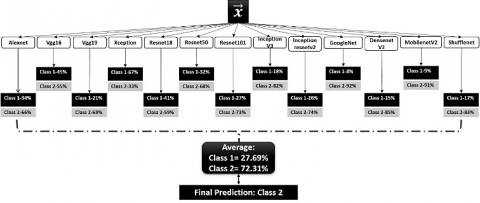
Computer vision applications, including image categorization, with unrivaled accuracy and robustness [6, 11, 25-27]. Therefore, we trained multiple categorization architectures rather than focusing on a single-model architecture to ensure the reliability of the results. Here, 13 CNN models were chosen: Xception [11, 28-30], InceptionResNetV2 [31], DenseNet121 [32], MobileNetV2 [33], ResNet101 [34-36], VGG16 [37], AlexNet [38], Vgg19 [39], Resnet18 [40], Resnet50 [41], InceptionV3 [42], GoogleNet [43], and ShuffleNet [44]. Deep ensemble-based learning is generally characterized by assembling a set of predictions derived from various deep convolutional neural network (CNN) models. However, current revolutionary practices involve reframing ensemble deep learning by integrating data, most typically predictions, for a single conclusion. As shown in Figure 2, this knowledge or prediction can be derived from numerous independent models for a single model. Computational features and softmax classification (with scores) were used to evaluate each pipeline model in the ensemble (cited in Algorithm 1). Current state-of-the-art prediction methods use ensemble networks with average softmax classifier score values. To create a probabilistic classifier, we took the best possible score from each pipeline's implementation of the softmax classifier and averaged them together. As shown in Figure 3, this is premised on the idea that, given a test image, a pipeline model that has learned the characteristics properly would recognize it with a reasonably high probability. The dataset contained nine different image subsets: scene, animal, architecture, character, plant, article, nature, indoor, and texture. In these nine subsets of images, no particular CNN model provided satisfactory results for the classification of fake and original images. Therefore, we consider 13 CNN models, introduce the ensemble technique, and take the results of the best one with respect to the maximum voting value for the final prediction.
Figure 2. Probabilistic ensemble approach of multiple classifiers
Figure 3. The proposed approach for the detection of fake images
Algorithm 1. Identification of fake images
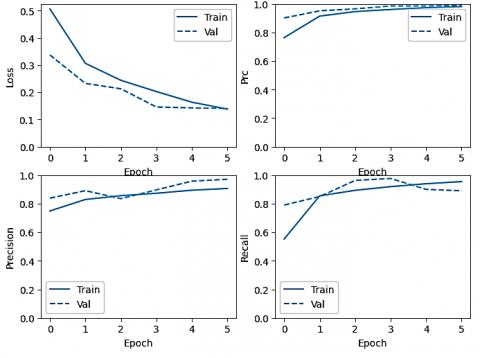
In this part of the article, the outcomes of using the proposed strategy are shown, and in subsequent sections, alternative machine learning models are tested utilizing the same dataset. The models' overall performance was determined by analyzing the test data with which they were provided. MATLAB 2021a was used to construct the aforementioned model, which was developed on an Intel(R) Core (TM) i7-12th generation CPU. The trials were carried out using a graphics processing unit (GPU) from NVIDIA RTX 3050 Ti equipped with between 4 and 16 gigabytes of random-access memory (RAM). Image splicing is a frequent kind of image forgeries in which a section from one image is copied and pasted into another, so forming a composite image that is referred to as a spliced image [45, 46]. Copy-move forgery is a prevalent and simple image-manipulation technique in which at least one component of an image is copied, moved, and pasted into other areas of the same image to duplicate or remove items from the image [45, 47]. Splicing is the most common method for creating fake images. Therefore, for a rigorous evaluation of the model, the CASIA_V2 dataset contained spliced and blurred images. Again, the photographs come in a variety of sizes and include a wide variety of subject matter, including scenery, animals, architecture, characters, plants, articles, nature, inside, and textures. Additionally, the images come in a variety of file formats, including JPEG, BMP, and TIFF. Again, the model’s performance was evaluated using 5-fold cross-validation techniques [48]. Typically, five-fold cross-validation (CV) is a process in which all data are randomly split into k folds; in our case, k=5, and then the model has trained on the k-1 folds, while one-fold is left to test the model. This process is carried out k times in total. The measurements of the confusion matrix were determined by taking the average of all of the repeats. Figure 4. depicts how well the suggested approach works in practice.
Figure 4. Performance of proposed model (a) Loss curve (b) Precision-recall curve (c) Precision curve (d) Recall curve
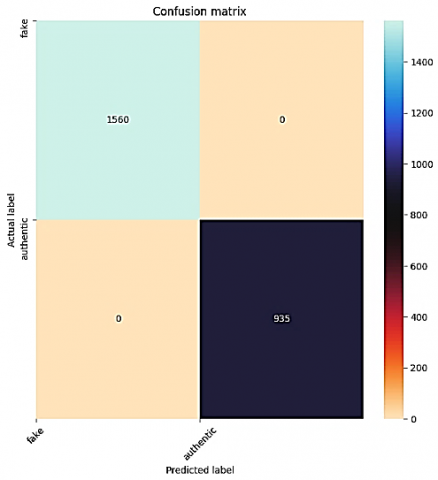
Figure 5. Confusion matrix of deep ensemble approach to identify fake images
Figure 4 shows the loss, precision-recall (PRC), precision, and recall curves for five epochs. Furthermore, the performance achieved by the deep ensemble-based learning model for detecting fake images in terms of accuracy was 100%, precision was 97.75%, recall was 87.46%, AUC was 99.3%, PRC was 99.18%, and loss was 1.39%. Finally, the confusion matrix of the proposed deep ensemble-based learning method is illustrated in Figure 5.
Table 1. Comparison with existing methods
|
References |
Method of Creating Fake Images |
Images Categories |
Performance |
|
[46] |
Image splicing |
fix size image 384×256 with JPEG extension |
0.52 MCC score |
|
[47] |
Copy-move and splicing |
Variable size images ranging from 320×240 to 800×600 with JPEG, BMP, and TIFF extension |
90.09% accuracy |
|
[48] |
Copy-move and splicing |
Variable size images ranging from 320×240 to 800×600 with JPEG, BMP, and TIFF extension |
99.3% accuracy |
|
Proposed method |
Copy-move and splicing |
Variable size images ranging from 320×240 to 800×600 with JPEG, BMP, and TIFF extension |
100% accuracy |
Again, a comparative analysis with state-of-art methods was carried out, as shown in Table 1.
From Table 1, it is clear that the proposed method for detecting fake images outperformed existing methods.
This study presents a novel framework for detecting and classifying deep fake images more accurately than many existing systems. The proposed method employs ensemble learning to improve the performance of the model in the detection of fake images. In this day and technology, we must be able to distinguish between genuine and manipulated photos. This paper proposes a deep ensemble-based learning strategy for spotting fake photos. The framework proposed here relies on the probabilistic ensemble technique, which considers the aggregate output of 13 CNN classification models in terms of the probability score. The deep ensemble-based learning model achieved 100% accuracy, 97.75% precision, 87.46% recall, 99.3% AUC, 99.18% PRC, and 1.39% loss in recognizing false images. Furthermore, the proposed model outperformed previous techniques. It is important to note that innovative work has a significant impact on society. Using this technology, false victims can quickly determine whether an image is authentic or not. People will maintain their vigilance because our work will enable them to identify profound fake images.
[1] Fridrich, J., Soukal, D., Lukas, J. (2003). Detection of copy-move forgery in digital images. International Journal of Computer Science, 3: 55-61.
[2] Yerushalmy, I., Hel-Or, H. (2011). Digital image forgery detection based on lens and sensor aberration. International Journal of Computer Vision, 92: 71-91. https://doi.org/10.1007/s11263-010-0403-1
[3] Akhtar, N., Saddique, M., Asghar, K., Bajwa, U.I., Hussain, M., Habib, Z. (2022). Digital video tampering detection and localization: review, representations, challenges and algorithm. Mathematics, 10(2): 168. https://doi.org/10.3390/math10020168
[4] Dirik, A.E., Memon, N. (2009). Image tamper detection based on demosaicing artifacts. In 2009 16th IEEE International Conference on Image Processing (ICIP), pp. 1497-1500. https://doi.org/10.1109/ICIP.2009.5414611
[5] Christlein, V., Riess, C., Jordan, J., Riess, C., Angelopoulou, E. (2012). An evaluation of popular copy-move forgery detection approaches. IEEE Transactions on Information Forensics and Security, 7(6): 1841-1854. https://doi.org/10.1109/TIFS.2012.2218597
[6] Zampoglou, M., Papadopoulos, S., Kompatsiaris, Y. (2017). Large-scale evaluation of splicing localization algorithms for web images. Multimedia Tools and Applications, 76(4): 4801-4834. https://doi.org/10.1007/s11042-016-3795-2
[7] Varga, D. (2020). Multi-pooled inception features for no-reference image quality assessment. Applied Sciences, 10(6): 2186. https://doi.org/10.3390/app10062186
[8] Bai, X., Yang, M., Huang, T., Dou, Z., Yu, R., Xu, Y. (2020). Deep-person: Learning discriminative deep features for person re-identification. Pattern Recognition, 98: 107036. https://doi.org/10.1016/j.patcog.2019.107036
[9] Kawahara, J., BenTaieb, A., Hamarneh, G. (2016). Deep features to classify skin lesions. In 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), pp. 1397-1400. https://doi.org/10.1109/ISBI.2016.7493528
[10] Lee, J.A., Kwak, K.C. (2022). Personal identification using an ensemble approach of 1D-LSTM and 2D-CNN with electrocardiogram signals. Applied Sciences, 12(5): 2692. https://doi.org/10.3390/app12052692
[11] Müller, D., Soto-Rey, I., Kramer, F. (2022). An analysis on ensemble learning optimized medical image classification with deep convolutional neural networks. IEEE Access, 10: 66467-66480. https://doi.org/10.1109/ACCESS.2022.3182399
[12] Silva, S.H., Bethany, M., Votto, A.M., Scarff, I.H., Beebe, N., Najafirad, P. (2022). Deepfake forensics analysis: An explainable hierarchical ensemble of weakly supervised models. Forensic Science International: Synergy, 4: 100217. https://doi.org/10.1016/j.fsisyn.2022.100217
[13] Vamsi, V.V.V.N.S., Shet, S.S., Reddy, S.S.M., Rose, S.S., Shetty, S.R., Sathvika, S., Supriya, M.S., Shankar, S.P. (2022). Deepfake detection in digital media forensics. Global Transitions Proceedings, 3(1): 74-79. https://doi.org/10.1016/j.gltp.2022.04.017
[14] Haq, M.U., Sethi, M.A.J., Ullah, R., Shazhad, A., Hasan, L., Karami, G.M. (2022). COMSATS face: A dataset of face images with pose variations, its design, and aspects. Mathematical Problems in Engineering, 2022. https://doi.org/10.1155/2022/4589057
[15] Hooda, A., Mangaokar, N., Feng, R., Fawaz, K., Jha, S., Prakash, A. (2022). Towards adversarially robust deepfake detection: An ensemble approach. arXiv Preprint arXiv: 2202.05687. https://doi.org/10.48550/arXiv.2202.05687
[16] Masood, M., Nawaz, M., Malik, K.M., Javed, A., Irtaza, A., Malik, H. (2023). Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Applied Intelligence, 53(4): 3974-4026. https://doi.org/10.1007/s10489-022-03766-z
[17] Chen, B., Tan, W., Wang, Y., Zhao, G. (2022). Distinguishing between natural and GAN‐generated face images by combining global and local features. Chinese Journal of Electronics, 31(1): 59-67. https://doi.org/10.1049/cje.2020.00.372
[18] Dagar, D., Vishwakarma, D.K. (2022). A literature review and perspectives in deepfakes: Generation, detection, and applications. International Journal of Multimedia Information Retrieval, 11(3): 219-289. https://doi.org/10.1007/s13735-022-00241-w
[19] Mallet, J., Dave, R., Seliya, N., Vanamala, M. (2022). Using deep learning to detecting deepfakes. arXiv Preprint arXiv: 2207.13644. https://doi.org/10.48550/arXiv.2207.13644
[20] Khormali, A., Yuan, J.S. (2022). DFDT: An end-to-end deepfake detection framework using vision transformer. Applied Sciences, 12(6): 2953. https://doi.org/10.3390/app12062953
[21] Concas, S., La Cava, S.M., Orrù, G., Cuccu, C., Gao, J., Feng, X. Marcialis, G.L., Roli, F. (2022). Analysis of score-level fusion rules for deepfake detection. Applied Sciences, 12(15): 7365. https://doi.org/10.3390/app12157365
[22] Raza, A., Munir, K., Almutairi, M. (2022). A novel deep learning approach for deepfake image detection. Applied Sciences, 12(19): 9820. https://doi.org/10.3390/app12199820
[23] Qazi, E.U.H., Zia, T., Almorjan, A. (2022). Deep learning-based digital image forgery detection system. Applied Sciences, 12(6): 2851. https://doi.org/10.3390/app12062851
[24] Mahdian, B., Saic, S. (2010). A bibliography on blind methods for identifying image forgery. Signal Processing: Image Communication, 25(6): 389-399. https://doi.org/10.1016/j.image.2010.05.003
[25] Shen, D., Wu, G., Suk, H.I. (2017). Deep learning in medical image analysis. Annual Review of Biomedical Engineering, 19: 221-248. https://doi.org/10.1146/annurev-bioeng-071516-044442
[26] Cai, L., Gao, J., Zhao, D. (2020). A review of the application of deep learning in medical image classification and segmentation. Annals of Translational Medicine, 8(11): 713. https://doi.org/10.21037%2Fatm.2020.02.44
[27] Singh, A., Sengupta, S., Lakshminarayanan, V. (2020). Explainable deep learning models in medical image analysis. Journal of Imaging, 6(6): 52. https://doi.org/10.3390/jimaging6060052
[28] Neena, A., Geetha, M. (2018). Image classification using an ensemble-based deep CNN. In Recent Findings in Intelligent Computing Techniques. Springer Singapore. Proceedings of the 5th ICACNI 2017, 3: 445-456. https://doi.org/10.1007/978-981-10-8633-5_44
[29] Rana, M.S., Sung, A.H. (2020). Deepfakestack: A deep ensemble-based learning technique for deepfake detection. In 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), pp. 70-75. https://doi.org/10.1109/CSCloud-EdgeCom49738.2020.00021
[30] Chollet, F. (2017). Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1251-1258. https://doi.org/10.1109/CVPR.2017.195
[31] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818-2826. https://doi.org/10.1109/CVPR.2016.308
[32] Solano-Rojas, B., Villalón-Fonseca, R., & Marín-Raventós, G. (2020). Alzheimer’s disease early detection using a low cost three-dimensional densenet-121 architecture. In The Impact of Digital Technologies on Public Health in Developed and Developing Countries: 18th International Conference, ICOST 2020, Hammamet, Tunisia, June 24–26, 2020, Proceedings 18 (pp. 3-15). Springer International Publishing.
[33] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C. (2018). Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510-4520.
[34] Zhang, Q. (2022). A novel ResNet101 model based on dense dilated convolution for image classification. SN Applied Sciences, 4: 1-13.
[35] Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K. (2017). Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1492-1500.
[36] He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778. https://doi.org/10.1109/CVPR.2016.90
[37] Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv Preprint arXiv: 1409.1556. https://doi.org/10.48550/arXiv.1409.1556
[38] Mao, J., Yin, X., Zhang, G., Chen, B., Chang, Y., Chen, W., Yu, J., Wang, Y. (2022). Pseudo-labeling generative adversarial networks for medical image classification. Computers in Biology and Medicine, 147: 105729. https://doi.org/10.1016/j.compbiomed.2022.105729
[39] Elhassan, A., Al-Fawa'reh, M., Jafar, M.T., Ababneh, M., Jafar, S.T. (2022). DFT-MF: Enhanced deepfake detection using mouth movement and transfer learning. SoftwareX, 19: 101115. https://doi.org/10.1016/j.softx.2022.101115
[40] Alighaleh, P., Khosravi, H., Rohani, A., Saeidirad, M.H., Einafshar, S. (2022). The detection of saffron adulterants using a deep neural network approach based on RGB images taken under uncontrolled conditions. Expert Systems with Applications, 198: 116890. https://doi.org/10.1016/j.eswa.2022.116890
[41] Dai, W., Li, D., Tang, D., Wang, H., Peng, Y. (2022). Deep learning approach for defective spot welds classification using small and class-imbalanced datasets. Neurocomputing, 477: 46-60. https://doi.org/10.1016/j.neucom.2022.01.004
[42] Puttagunta, M., Subban, R. (2022). A novel COVID-19 detection model based on DCGAN and deep transfer learning. Procedia Computer Science, 204: 65-72. https://doi.org/10.1016/j.procs.2022.08.008
[43] Nguyen, A., Nguyen, C.L., Gharehbaghi, V., Perera, R., Brown, J., Yu, Y., Kalbkhani, H. (2022). A computationally efficient crack detection approach based on deep learning assisted by stockwell transform and linear discriminant analysis. In Structures. Elsevier, 45: 1962-1970. https://doi.org/10.1016/j.istruc.2022.09.107
[44] Aljuaid, H., Alturki, N., Alsubaie, N., Cavallaro, L., Liotta, A. (2022). Computer-aided diagnosis for breast cancer classification using deep neural networks and transfer learning. Computer Methods and Programs in Biomedicine, 223: 106951. https://doi.org/10.1016/j.cmpb.2022.106951
[45] Sulaiman, N., Bagiwa, M.A., Shafii, K., Mohammed, A.U. (2022). Effect of image splicing and copy move forgery on haralick features of a digital image. SLU Journal of Science and Technology, 4(1&2): 49-60.
[46] Zhang, Y., Goh, J., Win, L.L., Thing, V.L. (2016). Image region forgery detection: A deep learning approach. SG-CRC, 2016: 1-11. https://doi.org/10.3233/978-1-61499-617-0-1
[47] Salloum, R., Ren, Y., Kuo, C.C.J. (2018). Image splicing localization using a multi-task fully convolutional network (MFCN). Journal of Visual Communication and Image Representation, 51: 201-209. https://doi.org/10.1016/j.jvcir.2018.01.010
[48] Chaitra, B., Reddy, P.B. (2023). An approach for copy-move image multiple forgery detection based on an optimized pre-trained deep learning model. Knowledge-Based Systems, 269: 110508