Kheira Zineb Bousmaha | Khaoula Hamadouche* | Ismahane Gourara | Lamia Belguith Hadrich
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Today, many sources of unstructured information such as social networks and blogs are more or less freely available on the web, and their volume is constantly growing, which constitutes a free gold mine for collecting public opinion. Opinion plays a crucial role because it can influence the decision-making process. Sentiment or opinion analysis is a discipline that can be used to meet decision-making needs, provide feedback to new product launches and marketing campaigns, and protect a company’s reputation, especially in social networking environments with massive data by exploiting textual data generated by users. In contrast to the techniques used, we have used and adapted in this study deep learning techniques: CNN and LSTM to identify their potential in this area and apply it to a corpus of Arabic data and in particular in Algerian dialect collected from social networks (50572 Facebook comments). We obtained promising results with an 85% f-measure. This represents a good start for an opinion analysis on the Algerian Dialect.
opinion analysis, Algerian dialect, deep learning, word-embedding, natural language processing
The appearance of social media has led to an explosion in the volume of user-generated data, it represents a free gold mine for public opinion collecting that can be used for several applications as sales prediction, consumer modeling, or opinion surveys. Nevertheless, faced with the richness of opinions, feelings and emotions present on these media, one of the research topics of social media mining is of great interest to the research community. This topic is none other than opinion mining and sentiment analysis, which extract feelings and emotional polarity of given information in the text for particular subject [1]. They are considered today as most active research field in automatic natural language processing, data mining, web mining and text mining [2]. However, one of the major characteristics of the content present in social media is the wealth of languages and dialects used by users [3].
Recently, considerable interest has been garnered to Arabic dialects and especially to the variety of this dialect found within social media. Dialect identification and processing has even been considered as the first component of preprocessing for any NLP (Natural Language Processing) tasks as opinion mining and sentiment analysis [4].
Among the most recorded Arabic dialects, we find the Algerian dialect.
Our problematic is interested in the task of opinion analysis in texts in Arabic language and more precisely in Algerian dialect. This task is difficult; due to the originality of the subject, the lack of research works and learning corpus the Arabic language complexity and its lexico-syntactic-semantic ambiguities. The Algerian dialect is distinguished by the lack of standard and resources.
It differs from classical Arabic in linguistic representation (phonological and morphological), lexicon and syntactic representation. All these aspects make NLP tools that have been developed for AALP (Automatic Arabic Language Processing) powerless in front of such a dialect.
However, we found that most of the work done is based on the Egyptian and Tunisian dialects. As far as the Algerian dialect is concerned, very few works have touched it.
The works that have dealt with this dialect focus on the linguistic aspect in general, omitting the different possible writings within the social media.
In this study, we aim to explore the field of opinion analysis in Arabic texts and try to address the previous difficulties of the Algerian dialect opinion analysis which has very little researches and studies, moreover, from a marketing perspective, automated analysis of customer feedback provides very important information, such as what makes customers happy or frustrated, that will help social media companies, business owners and advertisers make effective business decisions, strategies and goals across a range of industries. We use Deep Learning techniques in particular, as the latter have given remarkable results in the English language. We propose to use LSTM (Long Short Term Memory) and CNN (Convolutional Neural Network) as learning techniques and FastText as text representation methods. The results obtained are promising with 85% f-measure.
This article will be organized as follows: Section 1 gives an introduction; the 2nd section presents related works done in the field of Arabic text sentiment analysis. The methodology section describes our contribution, detailed description of the proposed approach and the used corpus The 4th section is dedicated to the results and the evaluation of the suggested model. At the end, we present the conclusion and the perspectives.
In this section, we review the works done in the area of Arabic text sentiment analysis.
Al-Smadi et al. [5] provided a state-of-the-art study for sentiment analysis based on the aspect of Arabic hotel reviews using two implementations of long-term memory neural networks (LSTMs). The first is: a character-level BiLSTM with a conditional random field classifier (BiLSTMCRF) for aspect opinion target expressions (OTE) extraction, and the second is: an aspect-based LSTM for aspect sentiment polarity classification. The suggested approaches are assessed using a benchmark dataset of Arab hotel reviews. The results show that these approaches perform better than the baseline search on both aspects with improvement of 39% for the aspectOTE extraction and 6% for the second aspect.
Abdelli et al. [6] have applied two supervised approaches: Support Vector Machines (SVM) and Deep Learning, for the Algerian dialect and the Modern Arabic sentiment analysis on a big annotated dataset taken from various Arabic Algerian sources. The conclusions showed promising results.
Another work that has used the traditional Machine Learning algorithms and the models of Deep Learning (CNN and RNN) on corpus obtained from social media (YouTube, Twitter and Facebook) concerning the Hirak 19, written in Algerian develovep by Mazari and Djeffal in the study [7]. The results have been positively demonstrated with 63.28% of accuracy (CNN) and 60.97% (RNN) of cross validation tests.
An effective Bidirectional LSTM model (BiLSTM) was investigated to improve Arabic Sentiment Analysis, using Forward-Backward to encapsulate the contextual information of Arabic feature sequences, it was proposed by Elfaik [8]. The experimental results of six benchmark datasets for sentiment analysis showed that this model outperforms the state-of-art deep learning models and the baseline classical machine learning methods.
Klouche et al. [9] have proposed a new approach to analyze the Algerian dialect sentiments for the benefit of the Algerian Telephone Operator Ooredoo based on CNN and SVM classifier from the machine learning approach that has used to classify the polarity of the data. Experimental results have revealed that deep learning approaches perform better than sentiment traditional methods.
Saleh et al. [10] have used five regular ML techniques: LR, Decision Tree (DT), KNearest Neighbor (KNN), Naive Bayes (NB) and RF with three different of pre-trained Deep Learning (DL) models: Long Short-Term Memory (LSTM), Recurrent Neural Network (RNN), Gated Recurrent Unit (GRU) to enhance the performance of models for predicting Arabic sentiment analysis, using three benchmarks Arabic dataset. Parameters of Machine Learning (ML) and DL have been optimized using Grid search and KerasTuner, respectively. As conclusion, the proposed ensemble model has achieved the best performance for each dataset compared with other models.
In this section, we present the conceptual part of our opinion analysis system DZ-OPINION specialized on texts in Arabic and Algerian Dialect.
DZ-OPINION is based on deep learning techniques, in particular LSTM and CNN. Both of them could achieve excellent classification effects [11]. Moreover, the combination of these two techniques has been very successful in the field of natural language processing [12].
We adopted it for the processing of the texts in our corpus. Given the specificity of the dialect used, we chose to use the FastText model to convert words that could form textual sentiments into numerical vectors in order to align them with the property of LSTM that treats the data as a sequential stream.
Our goals were achieved and we obtained a very good performance. We illustrate in the following the proposed approach and all the modules involved in this design.
It is divided into five basic modules as shown in Figure 1:
•The first module consists of data collection. They are collected from various web sources.
•The second module is the preprocessing of these comments.
•The third is the Word embedding where the sentence is converted into a numerical vector through a set of processes.
•The fourth module is the learning process on these numerical vectors.
Finally, the fifth module is the obtained classification model.
Figure 1. Global system design
3.1 Data preparation
The purpose of the collection is to extract the data and to prepare them from the social networks. These data will be stored to feed our system aiming at their exploitation in the analysis of opinions.
We are more interested in Facebook because it is the most widespread platform in Algeria. The posts are retrieved first followed by the comments.
The process is summarized in Figure 2. The posts are retrieved first followed by the comments. We retrieved the company data and the post IDs. Then, the comments go through a cleaning step by removing duplicates and spam. Structuring this data is important before storing it in the persistent layer. We were more interested in Facebook because it is the most widespread platform in Algeria.
Figure 2. Data preparation
Figure 3: An extract from our data file
Among the pages consulted, we chose the most popular pages in Algeria such as: Ooredoo Algeria, Algeria Telecommunications, SEOR SPA, Frenchy.
We start by collecting the posts by manually selecting them from the the previous pages. Then we collect the comments and manually classify them as positive, negative, neutral to build our own dataset.
We also relied on a set of databases [6] containing reviews and opinions expressed in Arabic and AD focused on hotels, books, movies, products and some airlines, which contain 49,742 reviews.
The distribution of these comments and their classification statistics are represented in Table 1.
Table 1. Dataset statistics
|
Positive comments |
Negative comments |
|
24932 |
24932 |
Our total dataset in xlsx format contains 3 columns (id, text, sentiment: negative, positive or neutral) of 50572 comments as shown in Figure 3.
As a technique for collecting data from the web, we used APIs, proposed by the Facebook platform: API Graph. Among the access modes, we chose to access the API as an application in order to avoid problems related to the user’s context and to have a neutral and global view on all the monitored pages.
3.2 Data preprocessing
This phase is considered one of the most important steps that precede the learning process. It takes care of extracting only important data from the comments.
3.2.1 Subject detection
Subject detection helps to know the opinion of users about a particular product mentioned in the post. There are many approaches to automatic comment classification namely: rule-based approaches, lexical approaches, Machine Learning approaches [13].
We propose an algorithm based on linguistic rules. This algorithm allows us to find the topic in the comments and to compare it with the proposed topic. We start by eliminating the stop comments (established list) and then for each comment, we search the proposed topic.
If it exists, we detect the polarity. Otherwise, we check the subjectivity of the comment using linguistic rules to find its topic (الفاعل, المبتدأ). We designed a set of rules based on the MSA [14] and the DA.
Once the subject is found if it and its synonyms are different from the proposed subject, the comment is eliminated. On the other hand, if the comment is without subject, we pass to the preprocessing procedure.
The Figure 4 provides the algorithm:
Figure 4. Subject detection algorithm
Example: We assume that our subject is: الكتاب so the result of the algorithm is below in Table 2.
Table 2. Example of the algorithm results
|
Comments |
Subject |
Result |
|
الكتاب مليح |
الكتاب |
Positive Polarity |
|
الحال راه مغيم |
الحال # الكتاب |
Comment Eleminatetd |
|
هدا عجبني بزاف |
No subject |
Positive Polarity |
3.2.2 Preprocessing procedure
We followed this process [15]:
Tokenization: We used a tokenization function approved by Keras.
Deletion: of hashtags, tags, links, emails, numbers, extra spaces, symbols, and stop words.
We have manually built a list of stop words from collected data (comments). Our list contains 79 words from the AD. Table 3 lists some of these.
Table 3. Types of stop words in AD
|
|
Algerian Dialect |
|
Linking Tools |
و، من، بعد |
|
Pronouns |
انا، حنا، هوما، نتوما |
|
Conjunction Tools |
في ، ب، ل |
Some examples of this process are given in Table 4:
Table 4. Types of stop words in AD
|
|
Comments |
Results |
|
Links |
زوروا موقعنا الالكتروني www.ooredoo.com |
زوروا موقعن الالكتروني |
|
Hashtags, Tags |
هدا المطعم عنده ماكلة بنينة#food@محمد |
هدا المطعم عنده ماكلة |
|
Extra Space, Symbols |
للأسف اسعاركم غالية بزاف سمحلي و ربي يعاونكم تحلو في وهران اليوم الثاني من العيد ؟ |
للأسف اسعاركم غالية بزاف سمحلي و ربي يعاونكم تحلو في وهران اليوم الثاني من العيد |
|
Redundant characters |
بزاااااف |
بزاف |
|
Stop Words |
كل مازادت نسبة التلقيح زادت معاها نسبة الوفيات مافهمنا والو |
مازادت نسبة التلقيح زادت نسبة الوفيات مافهمنا |
3.3 Data representation “Word Embedding”
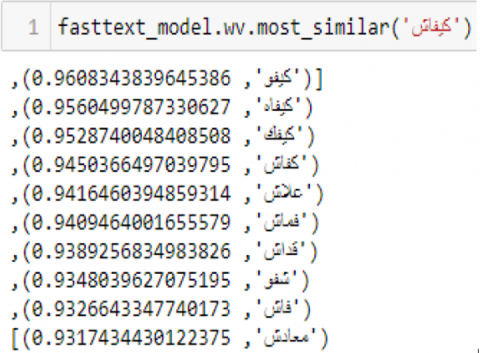
Figure 5. Similarity example of the word كفاش
We mention one of the techniques we adopted the FastText (FT) method. The latter is an embedding construction method [16] and an extension of word2vec [17].
Word2vec considers words as atomic lexical units. Words are considered unbreakable: each word represents the smallest unit.
In contrast to word2vec, FastText considers words as bags of n-grams of characters. It reduces the size of the atomic unit by considering n-grams. Each n-gram constitutes a subword. It associates vectors with the n-grams of characters, and the words are then represented by the sum of these vectors.
Thus, IT is able to extract more semantic relations between words sharing the common character n-grams. It also allows to obtain plots for rare words never seen before by summing its vectors with n-grams of known characters.
It shows comparable results, but with significantly less training time. We also opted for FastText because our dialect needs closest word similarity and not similarity across the context.
Here in Figure 5 is an example of similar words using fasttext.
3.4 Learning
In this phase, we rely on one of the recurrent neural network techniques that are CNN and LSTM. This combination brings us an improvement in the performance of polarity detection on the corpus and allows us to obtain good results.
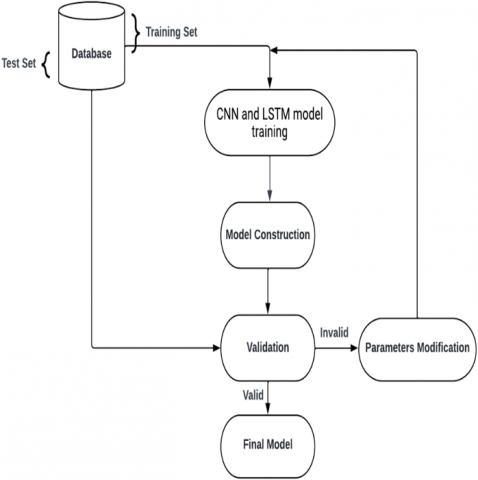
The Figure 6 shows a flowchart of the learning process.
Figure 6. The learning process
The neural network is trained on a training base in order to obtain a classification model, which will be validated from the test base. If the trained model is not valid, a parameter review process will be implemented during which the neural network hyper-parameters are modified in order to obtain better results [18].
The Table 5 gives the result of the training on comment examples.
Table 5. Training results of comment examples
|
Comment |
Positivity |
Negativity |
|
هدا البلاصة ماشي مليحة |
46% |
54% |
|
السعر هايل بزاف |
63% |
37% |
|
عجبني بصح ما يساعدش |
51% |
49% |
The architecture model is as follows:
Embedding layer: Provides the presentation of words and their relative meanings. Each message is first transformed into a vector representation of size equal to the maximum size of all messages in the dataset.
Conv1D layer: The convolution layer in which the main processing of the model takes place. Predefined filters hover over the sentence matrix and reduce it to a low-dimensional matrix.
Max Pooling1D layer: Consolidates the output of the convolutional layer by computing the maximum value Lstm layer: stores words and predicts next words based on previous words.
Dropout layer: Removes some neurons from previous layers. We apply this to avoid overlearning problems.
Dense layer: Reduces the outputs by getting the inputs from the Flatten layer. The dense layer uses all the inputs from the neurons in the previous layer, performs computation, and sends two outputs. Moreover, the activation function, which helps to decide which neuron, should pass and which neuron should fire. Thus, the activation function of the node defines the output of this node given an input or a set of inputs.
Figure 7. An extract from the Facebook comments corpus
Figure 8. Word embedding result
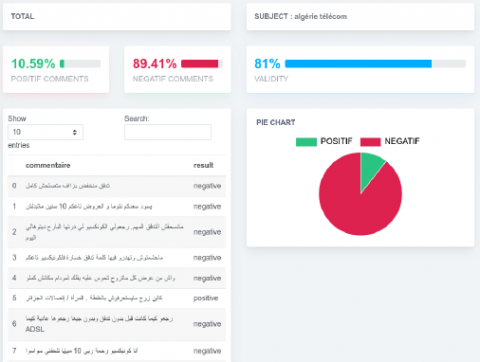
Figure 9. DZ-OPINION result
In this section, we will detail the final module in our DZ-OPINION system which is the evaluation. The techniques we have chosen have been validated on a corpus of Facebook posts, the Figure 7 shows an extract from the Facebook comments corpus. The result of word embedding (FT) is presented in Figure 8. We present the result of our DZ-OPINION application on these comment examples in the Figure 9.
4.1 Evaluation
We present the experimental results of the proposed ensemble model on our corpus. Or we have divided it into 80% comments for training and 20% for testing our 2 models.
The first one with LSTM and the second one with LSTM + CNN. By calculating the accuracy of the latter, we obtained 85% for the training, 82% for the test model 1 and 79% for the test model 2 and an error rate of 15% for the training and 18% for the test model 1 and 43% for the test model 2, as shown in Table 6.
Table 6. Comparison between the results of the 2 models
|
|
Error Rate |
Accuracy |
F-measure |
|
Training Set (LSTM-CNN) (LSTM) |
15% |
85% |
85% |
|
Test Set LSTM-CNN |
18% |
82% |
82% |
|
Test Set LSTM |
43% |
79% |
79% |
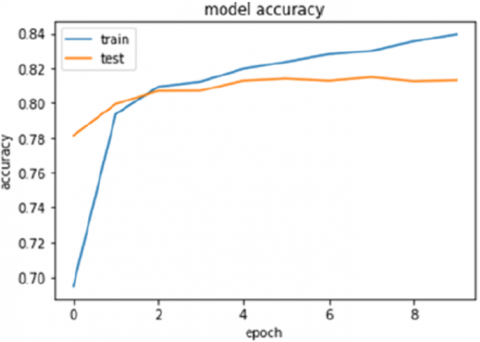
Figure 10. Accuracy rate of model 1
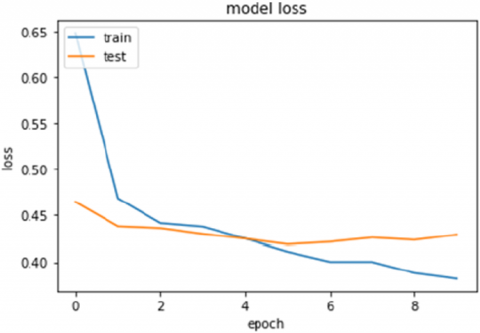
Figure 11. Error rate of model 1
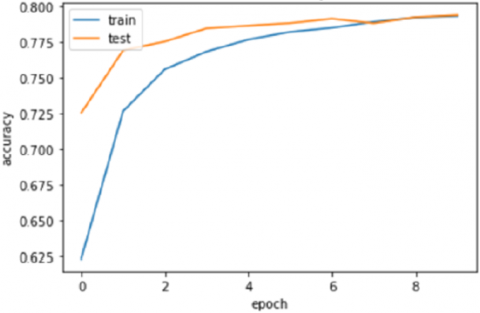
In order to follow more closely the results obtained, it becomes clearer to follow them through graphs. The following graphs allow us to follow the evolution of the precision and the error rate: Figures 10 and 12 illustrate the accuracy of the model 1 and 2 respectively, Figures 11 and 13 illustrate the error rate.
As we can see, we obtain a certain gain in performance using the 2nd model with LSTM + CNN.
This represents a good start for an opinion analysis on the Algerian Dialect.
Figure 12. Accuracy rate of model 2
Figure 13. Error rate of model 2
4.2 Result discussion
We have achieved remarkable results in the accuracy and F-measure of a rate of 85%; these results are mainly due to:
1. The choice of the FastText model for word representation; which is very useful for morphologically rich languages: the Algerian dialect.
2. The choice of LSTM and CNN as learning techniques. This combination brings us an improvement in the performance of polarity detection on the corpus.
3. Not using the lexicon or the dictionary. That is to say that our model is able to do opinion analysis from data (comments) already classified as positive or negative.
For the managerial implications, it was significant in terms of time and money, we had contacted a start-up who were paying for 4 people thousands of dollars for a week for a simple annotation of comments (positive, negative and neutral), and it was also paid in number of annotated comments. It is a relatively expensive price in Algeria.
This work is situated in the framework of the analysis of opinions in Arabic. Our goal is to predict the polarity of a sentence of posts in Algerian dialect.
Given the specificity of the language used, we proposed to use the FastText model instead of Word2vec to transform the words into numerical vectors.
We used for the first time the LSTM neural network with long and short-term memory to train the model for sentiment analysis, the LSTM network is very effective for sequential data models. Our experimental results show that deep neural networks are the best model for realizing sequential data models, as they do not require any prior knowledge, design and feature engineering.
Second, we used CNN with LSTM which provides better test accuracy compared to LSTM with approximately the same weights and less training time. Therefore, faster training is possible with CNN, reducing the training time required for a large data set.
This combination brings us an improvement in the performance of polarity detection on the corpus and allows us to obtain good results. The results obtained are promising and we hope to have brought back with this work a great plus and a great help for the Automatic Arabic Language Processing community.
We can say that our solution is an approach that has given good results in an area that remains a research axis to be explored.
For future projects, we aim at the following:
•Testing different types of CNNs in addition to LSTMs for our models, for example, the use of bidirectional LSTMs could give an even better result.
•Detecting emoticons, because in direct communication, feelings can be perceived through expressions. The interest of emoticons and emojis in opinion analysis is undeniable.
•The integration of a large database to make our model more efficient and to enrich the corpus and the dictionary of opinion words given the diversity of the Algerian dialect.
[1] Luo, S.Y., Gu, Y.J., Yao, X.X., Fan, W. (2021). Research on text sentiment analysis based on neural network and ensemble learning. Revue d'Intelligence Artificielle, 35(1): 63-70. https://doi.org/10.18280/ria.350107
[2] Liu, B. (2012). Sentiment analysis and opinion mining (Synthesis Lectures on Human Language Technologies). University of Illinois: Chicago, IL, USA.
[3] Guellil, I., Boukhalfa, K. (2015, April). Social big data mining: A survey focused on opinion mining and sentiments analysis. In 2015 12th international symposium on programming and systems (ISPS), Algiers, Algeria, pp. 1-10. https://doi.org/10.1109/ISPS.2015.7244976
[4] Sadat, F., Kazemi, F., Farzindar, A. (2014, July). Automatic identification of arabic dialects in social media. In Proceedings of the First International Workshop on Social Media Retrieval and Analysis, Gold Coast Queensland, Australia pp. 35-40. https://doi.org/10.1145/2632188.2632207
[5] Al-Smadi, M., Talafha, B., Al-Ayyoub, M., Jararweh, Y. (2019). Using long short-term memory deep neural networks for aspect-based sentiment analysis of Arabic reviews. International Journal of Machine Learning and Cybernetics, 10(8): 2163-2175. https://doi.org/10.1007/s13042-018-0799-4
[6] Abdelli, A., Guerrouf, F., Tibermacine, O., Abdelli, B. (2019, December). Sentiment analysis of Arabic Algerian dialect using a supervised method. In 2019 International Conference on Intelligent Systems and Advanced Computing Sciences (ISACS), Taza, Morocco, pp. 1-6. https://doi.org/10.1109/ISACS48493.2019.9068897
[7] Mazari, A.C., Djeffal, A. (2021). Deep Learning-Based sentiment analysis of Algerian dialect during Hirak 2019. In 2020 2nd International Workshop on Human-Centric Smart Environments for Health and Well-being (IHSH), Boumerdes, Algeria, pp. 233-236. https://doi.org/10.1109/IHSH51661.2021.9378753
[8] Elfaik, H. (2021). Deep bidirectional LSTM network learning-based sentiment analysis for Arabic text. Journal of Intelligent Systems, 30(1): 395-412. https://doi.org/10.1515/jisys-2020-0021
[9] Klouche, B., Benslimane, S.M., Mahammed, N. (2022). Sentiment analysis of Algerian dialect using a deep learning approach. In International Conference on Artificial Intelligence and its Applications, pp. 122-131. https://doi.org/10.1007/978-3-030-96311-8_12
[10] Saleh, H., Mostafa, S., Alharbi, A., El-Sappagh, S., Alkhalifah, T. (2022). Heterogeneous ensemble deep learning model for enhanced Arabic sentiment analysis. Sensors, 22(10): 3707. https://doi.org/10.3390/s22103707
[11] Sharma, G., Sharma, D. (2022). Improving extractive text summarization performance using enhanced feature based RBM method. Revue d'Intelligence Artificielle, 36(5): 777-784. https://doi.org/10.18280/ria.360516
[12] Liang, S., Zhu, B., Zhang, Y., Cheng, S., Jin, J. (2020, December). A double channel CNN-LSTM model for text classification. In 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Cuvu, Fiji, pp. 1316-1321. https://doi.org/10.1109/HPCC-SmartCity-DSS50907.2020.00169
[13] Devika, M.D., Sunitha, C., Ganesh, A. (2016). Sentiment analysis: a comparative study on different approaches. Procedia Computer Science, 87: 44-49. https://doi.org/10.1016/j.procs.2016.05.124
[14] Bousmaha, K.Z., Chergui, N.H., Mbarek, M.S.A., Hadrich, L.B. (2020). AQG: Arabic question generator. Revue d'Intelligence Artificielle, 34(6): 721-729. https://doi.org/10.18280/ria.340606
[15] Guellil, I., Azouaou, F. (2017). ASDA: Analyseur Syntaxique du Dialecte Algérien dans un but d'analyse sémantique. arXiv preprint arXiv:1707.08998.
[16] Bojanowski, P., Grave, E., Joulin, A., Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5: 135-146. https://doi.org/10.1162/tacl_a_00051
[17] Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of Workshop at ICLR.
[18] Koutsoukas, A., Monaghan, K.J., Li, X., Huan, J. (2017). Deep-learning: investigating deep neural networks hyper-parameters and comparison of performance to shallow methods for modeling bioactivity data. Journal of Cheminformatics, 9(1): 1-13. https://doi.org/10.1186/s13321-017-0226-y