Qiang Guo
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
In many enterprises, the work efficiency is suppressed by the irrational allocation of enterprise resources. To solve the problem, this paper puts forward the optimal scheduling path algorithm for enterprise resource workflow (ERWOSA). To measure the task efficiency of each person after project issuance, the ERWOSA models enterprise resource workflow, and quantifies each node in the model. Then, novel attributes like mean execution accuracy, mean execution time, and node weight were calculated. Based on the calculation result, the optimal scheduling path was solved, which is highly accurate and efficient. In this way, the ERWOSA manages to bring more benefits to the enterprise.
workflow, quantification, path, accuracy, efficiency
Workflow management system (WMS) is a type of support system that ensures the accuracy, efficiency, and quality of projects in an enterprise by decomposing each enterprise project into several tasks and allocating them to the right personnel [1]. In the WMS, task allocation depends on the efficiency of actors in the workflow model. The entire project is greatly affected by whether the tasks can be allocated reasonable.
During the implementation of an enterprise project, the type of resources required by the workflow model is usually determined during model construction. Once the project is issued, the enterprise can allocate the tasks of the project in time to the suitable personnel. However, a serious problem may arise in this process: if one or several tasks are allocated incorrectly, the quality and timeliness of the entire project will be affected. To solve the problem, it is necessary to find a more reasonable method to collect allocate the tasks, making the project implementation more efficient and accurate.
Workflows aim to reduce labor cost or expense through process control. Many attempts have been made to apply workflow scheduling to enterprise resource management. For instance, Pourmirza et al. [2] developed a business process management system (BPMS) to handle highly complex modern-day business, and specified the level of elaboration and architectural style of the system, providing insights into the modelling of complex business resources. To overcome the difficulty in medical resource scheduling of medical enterprises, Gichoya et al. [3] designed an opensource registry system for workflow model, which introduces the workflow-driven management mechanism to rationalize the scheduling of radiology resources of medical enterprises.
After analyzing traditional enterprise analysis platforms, Rashmi and Basu [4] proposed a Hadoop-based workflow scheduling model, and solved the model by the stochastic hill climbing (SCH) algorithm, achieving a dynamic balance between cloud load, workflow response time, and resource utilization efficiency. To simplify the business process modelling of enterprise resources, Kim et al. [5] put forward a conceptual method that applies proportional probability theory to business process modeling; the conceptual method offers formal and graphical descriptions of a series of process frameworks and operating mechanisms, and facilitates the reorganization and redesign of enterprise business process, thereby improving the execution quality of the business process.
A standard solution regarding business process management automation in enterprises is the use of workflow management systems working by the Rule-Based Reasoning approach. In such systems, the process model which is designed entirely before the implementation has to meet all needs deriving from business activity of the organization. In practice, it means that great limitations arise in process control abilities, especially in the dynamic business environment. Therefore, new kinds of workflow systems may help which typically work in more agile way e.g. following the Case-Based Reasoning approach. The paper shows another possible solution – the use of emergence theory which indicates among other conditions required to fulfill stimulation of the system (for example the business environment) to run grass-roots processes that lead to arising of new more sophisticated organizing forms. The paper also points the using opportunity of such techniques as the processing of complex events to fulfill key conditions pointed by the emergence theory.
Inspired by the WMS with rule-based reasoning, Koryl and Mazur [6] put forward a flexible workflow management model, providing an alternative to the fixed management mode of complex enterprise resources. Considering the key problems of cloud workflow scheduling (e.g. heterogeneity, complex billing models, and infinite resource demand), Prathibha et al. [7] invented a high-performance workflow scheduling method based on cloud computing platform, i.e. the non-dominated sorting particle swarm optimization scheduling algorithm; the algorithm provides a better workflow scheduling solution for cloud computing than the existing workflow scheduling algorithms. Saygili et al. [8] examined the different roles of enterprise resource plan (ERP) in business management workflow model of different enterprises, classified the modelling methods of enterprise resource workflow, and provided a six-dimensional structure for critical success factors (CSFs) in quality and successful ERP applications.
Lee et al. [9] presented a method for analyzing the effect of implementing an enterprise system (ES) in the construction industry during the ES introduction and planning stages: the enterprise management workflow model is simplified with digital and automation techniques, laying the basis for efficient enterprise resource management. Femmam et al. [10] mapped enterprise resource scheduling to the Petri net, creating the evolutionary Petri net (EPN); the EPN is an extension of the Petri net, enriched with two genetic operators: crossover and mutation; the optimal scheduling path was found by the EPN to minimize the cost of cloud resources in the enterprise. Based on a model-driven workflow scheduling mechanism, Benaben et al. [11] developed the mediation information system engineering (MISE) approach, which exploits the associated models at each level to build the models of the next level, and optimize the resource scheduling through the transition mechanisms between levels.
To improve the timeliness and accuracy of enterprise resource scheduling, Hoyland [12] designed the reinforced enterprise business architecture (REBAR), which illustrates the basic figures and tables of general workflows; The REBAR captures the essence of the unique enterprise in a graphical application that can be queried and dynamically recombined to illustrate details of complex workplace collaborations, enabling decision-makers to make correct decisions. Using cloud computing workflow scheduling technology, Taylor et al. developed an enterprise resource workflow management system to effectively analyze and optimize the use of enterprise cloud resources, and later proposed a cloud simulation platform for small and medium-sized enterprises (SMEs) (CloudSME); the CloudSME is a generic approach that combines an AppCenter with the workflow of the WS-PGRADE/gUSE science gateway framework, reducing the development cost of cloud-based simulator for business scheduling [13, 14].
Liu and Li [15] proposed a new quality of service (QoS) negotiation model to optimize the service quality of enterprise resources; the model adjusts the negotiation strategy through intelligent learning, such that the application and the resource provider can reach a QoS agreement quickly under multiple concurrent resource requests. Datskova and Shi [16] described a workflow scheduling method to simulate the performance of production tasks within the ALICE grid; this method constructs event states based on datacenter operations, computing, storage, and user behaviors, and optimizes the allocation of enterprise resources according to the transitions between event states. Kalra and Singh [17] presented a workflow model based on intelligent water drops algorithm, which balances the utilization of enterprise resources in the cloud computing environment while minimizing the execution time of the workflow; experimental results show that the model is superior to similar techniques in makespan and load balancing.
Narayani and Banu [18] designed a fairness-based heuristic workflow scheduling and placement algorithm, which minimizes the overall profit and execution time based on the features of tasks and physical servers in the datacenter; CloudSim experiments show that their algorithm successfully improves the QoS parameters: the makespan and total execution cost were improved by 5% and 3%, respectively. To solve time inconsistency and consensus bias, Viriyasitavat and Hoonsopon [19] suggested an architecture of business processes in blockchain era, which allows business partner to select nodes in performing consensus and inherits the merits of blockchain, namely, persistency, validity, auditability, and disintermediary. Ahn and Kim [20] devised a series of formal definitions and algorithms for discovering a work transference network from a workflow procedure, and from its enactment histories in event logs; the proposed algorithms can graphically and mathematically represent workflow procedures, promoting enterprise management and evaluation of human resources.
Oukfif et al. [21] presented a reliability-aware method based on discrete particle swarm optimization (RDPSO) for workflow scheduling in multiple and heterogeneous cloud datacenters; simulation results show that the RDPSO greatly outperforms the reliability aware heterogeneous earliest finish time (HEFT) method in makespan, transferred data and reliability. Ouldkablia et al. [22] invented a semantics operator called a gateway for intelligent process scheduling of the Internet of things (IoT) (GIPSIT), enabling the management of data flows circulating between the connected objects of the IoT; Simulation results highlight the importance of the GIPSIT operator in enterprise resource scheduling under the IoT. Almi’ani et al. [23] presented the resource demand aware scheduling algorithm (RDAS+) to maximize resource utilization by allocating the minimum number of resources. Aghabaghery et al. [24] proposed a novel optimal scheduling method for enterprise resource workflow; the resource scheduling is optimized by modeling the physical generalized flow diagram from the event logs and the information on the data exchange among organizational roles, and setting up rules that map motifs with certain features to logical structures.
To select the correct scheduling path, this paper systematically quantifies the workflow model, and refines each node in the model, thereby obtaining the relative weight of each node in each task. Firstly, a workflow model was established for enterprise resources based on network flow. Next, the mean execution efficiency and mean execution time of each node (person) in the model were calculated, and used to compute the relative weight of each node, reflecting the role of each person in his/her task. After that, the paths to complete the project were identified through the multi-workflow model under constraints, and the total weight of all nodes on each path was obtained. The total weight indicates the possible efficiency of project execution along each path.
3.1 Enterprise resource workflow model
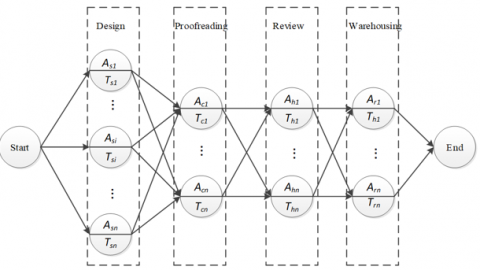
The modeling of enterprise resource workflow is to reasonably arrange a project as a directed graph containing a set of active nodes. The enterprise resource workflow model details the personnel for each task of the project. The set of personnel in all tasks forms a reasonable path to complete the project
Definition 1. Enterprise resource workflow model
The enterprise resource workflow model W is a four-tuple W=<S,C,H,R>, where S is the set of designers; C is the set of proofreaders; H is the set of reviewers; R is the set of warehousing personnel.
Since the personnel roles are fixed in the enterprise, various completion paths can be obtained for the project by linking up the personnel with different roles: L={Si,Ci,Hi,Ri}, i={1,2,3...,n}. Together, these paths constitute a complete enterprise resource workflow model (Figure 1).
Figure 1. The enterprise resource workflow model
3.2 Role constraints
Role constraints aim to reasonably allocate resources throughout the project execution. Some personnel involved in the project can play several roles, while some can only partake in one task, due to the conflict between different roles. To improve the efficiency of the project, this paper attempts to rationalize the role of each person in a path to complete the project.
(1) The AND relationship between roles
The AND relationship, denoted as ▲, indicates that a person can play two or more roles. If person P can simultaneously serve as designer and proofreader, the relationship between the two roles can be expressed as <P, designer, proofreader, ▲>.
(2) The XOR relationship of roles
The XOR relationship, denoted as ▼, indicates that a person cannot play more than one role at the same time. If person P can either serve as designer or act as proofreader, the relationship between the two roles can be expressed as <P, designer, proofreader, ▼>.
During an enterprise project, one person is only allowed to partake in one task. To optimize the project effect, the task to be chosen by each person needs to be determined by a suitable algorithm.
Although the enterprise resource workflow is fixed, it is critical to find the most efficient path to complete a project. Therefore, this paper introduces the efficiency of each person in completing each task of the project to the enterprise resource workflow model, and searches for the optimal path to complete the project, shedding light on the decision-making for the optimal scheduling of the project.
Definition 2. Mean execution accuracy A
The mean execution accuracy refers to the expected accuracy of each person in completing a task. The accuracy varies from person to person, because the personnel have different tasks with different degrees of difficulty. Hence, accuracy and difficulty were combined to solve the expected accuracy of each person for a task of the enterprise project.
The mean execution accuracy A of a person is defined as a two-tuple <a, e>, where a is the accuracy of the person in completing a task; e is the difficulty of the task. Then, each task P can be expressed as a two-tuple P<a, e>. The mean execution accuracy A of the person can be derived from multiple tasks P1<a1, e1>, P2<a2, e2>, and P3<a3, e3>...:
$A=\left(\sum_{i=1}^{n} a_{i} / e_{i}\right) / n$ (1)
Definition 3. Mean execution time T
The mean execution time refers to the expected time of each person to complete a task. The time varies from person to person, because the personnel have different tasks with different degrees of difficulty. Hence, time and difficulty were combined to solve the expected time of each person for a task of the enterprise project.
The mean execution time T of a person is defined as a two-tuple <t,e>, where t is the time of the person to complete a task; e is the difficulty of the task. Then, each task P can be expressed as a two-tuple P<a,e>. The mean execution time T of the person can be derived from multiple tasks P1<t1,e1>, P2<t2,e2>, and P3<t3,e3>...:
$T=\left( \sum\limits_{i=1}^{n}{ti/ei} \right)/n$ (2)
Definition 4. Node weight K
The node weight measures the efficiency of a person in completing a task. The relative weight K of each node, i.e. the node weight, depends on the mean execution accuracy and time of each person executing the task. Therefore, the node weight can be defined as a two-tuple K<A, T>, which reflects the relative importance between accuracy and time of a person in completing the corresponding task. The greater the K value, the better the person performs in executing the task. The node weight K can be calculated by:
K=A/T (3)
Definition 5. Total weight of a path S
The total weight of a path equals the sum of the weights of all nodes on that path. For any path that can complete the project, each node (person) has a weight. The sum of these weights reveals the relative importance between efficiency and time, if the project is completed along that path. Let {K1, K2, K3...} be the set of node weights along a path. Then, the total weight of the path S can be obtained by adding up K1, K2, K3... The greater the S value, the higher the efficiency of adopting this path. The total weight of a path S can be calculated by:
$S=\sum\limits_{i=1}^{n}{Ki}$ (4)
The above solutions to the mean execution accuracy A, mean execution time T, node weight K, and total weight S make it possible to identify the optimal path to complete the target project.
5.1 Quantification strategy
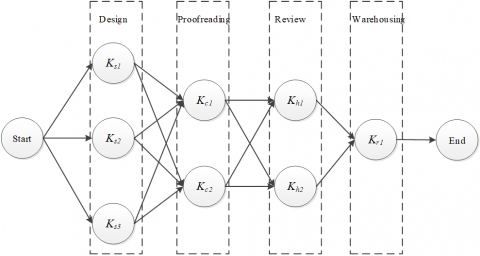
For a given enterprise resource workflow (Figure 2), the execution accuracy a and execution time t of each node were quantified, and substituted to formulas (1) and (2) to calculate the mean execution accuracy A and mean execution time T. Then, the relative weight K of each node was computed by formula (3), reflecting the effect of each person in executing a task in the enterprise resource workflow. After that, the total weight S of each path for the workflow was derived from the node weights Ki. On this basis, the optimal path to complete the project was identified, making the project execution more efficient.
Figure 2. The quantification process of an enterprise resource workflow
5.2 The ERWOSA
According to the above quantification strategy, the ERWOSA was designed for optimal scheduling of enterprise resource workflow:
Inputs: Enterprise resource workflow model W, and parameters of each node.
Outputs: Total weights S of different paths.
Step 1. Establish the workflow model W as a four-tuple<S,C,H,R>.
Step 2. Solve the mean execution accuracy A, and mean execution time T of each person in sets S, C, H, and R.
Step 3. Calculate the weight <A,T> of each node.
Step 4. Initialize the identifier Flag=0 of each node; For the nodes of ▼ relationship, set the layer Flag as cFlag=0.
Step 5. Start choosing a node for the design layer.
Step 6. Check whether the node relationship is ▲ or ▼; if the relationship is ▲, i.e. Flag=0, add the node to the design layer and set cFlag=1; if the relationship is ▼, add the node to the design layer and set Flag=1, or do not add the node to the layer and set Flag=0; if the relationship is neither ▲ nor ▼, add the node to the path and set Flag=1.
Step 7. Traverse the nodes on the subsequent layer, and looks for nodes with Flag=0. Then, restart from Step 4 again until all such nodes have been discovered. Next, set the identifiers of nodes with ▼ relationship to Flag=0.
Step 8. Traverse the nodes on the previous layer, and check whether there are nodes with Flag=0, or nodes with ▼ relationship and cFlag=0. If yes, jump to Step 4; otherwise, jump to Step 6.
Step 9. Complete the traversal once reaching the start node, which means all paths have been traversed.
Step 10. Solve the total weight S for each path.
To sum up, the entire enterprise resource workflow is firstly abstracted into a workflow model. Then, the role of each person in the project is analyzed according to his/her task. On this basis, all the paths to complete the project are identified by the ERWOSA. The total weight S of each path is calculated by formula (4). The path with the highest S, i.e. the set of maximum node weights Wmax, is the most accurate and efficient path to complete the project.
6.1 Simulation environment
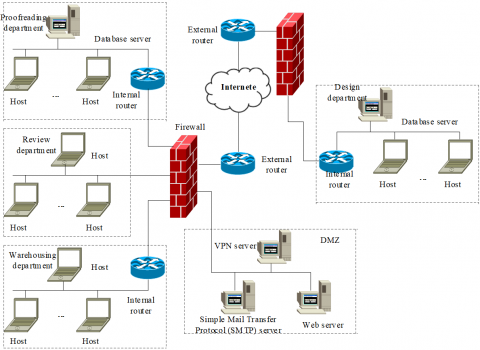
To verify the performance of the ERWOSA in optimal scheduling, a simulation environment was configured by the topology in Figure 3. The main modules in the environment are the design department, the proofreading department, the review department, the warehousing department, and a demilitarized zone (DMZ). Specifically, the proofreading department, review department, and warehousing department form an enterprise intranet with the DMZ; the design department accesses the intranet through the Internet via virtual private network (VPN); all the departments are combined into a logical network to complete the production scheduling of enterprise resource workflow.
6.2 Simulation
The workflow of the target enterprise goes as follows: Start -> Design -> Proofreading -> Review -> Warehousing -> End. Through a survey on the daily management of the enterprise, it is learned that the design department S has three designers s1, s2, and s3; the proofreading department C has two proofreaders c1 and c2; the review department has two reviewers h1 and h2 (s2); the warehousing department has only one person r1. Note that the roles of h2 and s2 are played by the same person, who can serve as designer or reviewer. But this person can only play one of the two roles, that is, the two roles have an XOR relationship. Table 1 lists the mean execution accuracy Ai and mean execution time Ti of each person, and the weight Ki of each node calculated from Ai and Ti.
The data in Table 1 were imported to the ERWOSA to quantify the scheduling paths of the project (Figure 4).
Figure 3. The topology of simulation environment
Table 1. The mean execution accuracy A, mean execution time T, and weight K of each node
|
Task |
Personnel |
Mean execution accuracy A |
Mean execution time T |
Weight K |
|
Design |
s1 |
0.800 |
10 |
0.080 |
|
s2 |
0.784 |
9 |
0.087 |
|
|
s3 |
0.815 |
10 |
0.081 |
|
|
Proofreading |
c1 |
0.851 |
12 |
0.071 |
|
c2 |
0.897 |
11 |
0.081 |
|
|
Review |
h1 |
0.834 |
14 |
0.060 |
|
h2 (s2) |
0.832 |
13 |
0.064 |
|
|
Warehousing |
r1 |
0.886 |
9 |
0.098 |
Figure 4. The scheduling paths after quantification
The total weight S of each path in Figure 4 was calculated by formula (4). The results are recorded in Table 2 below.
Table 2. The total weight S of each scheduling path
|
Serial number |
Scheduling path |
Total weight S |
|
1 |
Ks1→Kc1→Kh1→Kr1 |
0.309 |
|
2 |
Ks1→Kc1→Kh2→Kr1 |
0.313 |
|
3 |
Ks1→Kc2→Kh1→Kr1 |
0.319 |
|
4 |
Ks1→Kc2→Kh2→Kr1 |
0.323 |
|
5 |
Ks2→Kc1→Kh1→Kr1 |
0.316 |
|
6 |
Ks2→Kc2→Kh1→Kr1 |
0.326 |
|
7 |
Ks3→Kc1→Kh1→Kr1 |
0.310 |
|
8 |
Ks3→Kc1→Kh2→Kr1 |
0.314 |
|
9 |
Ks3→Kc2→Kh1→Kr1 |
0.320 |
|
10 |
Ks3→Kc2→Kh2→Kr1 |
0.324 |
As shown in Table 2, the scheduling path with the highest total weight S=0.326, i.e. Ks2→Kc2→Kh1→Kr1, was taken as the optimal path. Through this path, the project can be completed at a fast speed and of a high quality.
6.3 Results analysis
(1) Relationship between mean execution time T and performance
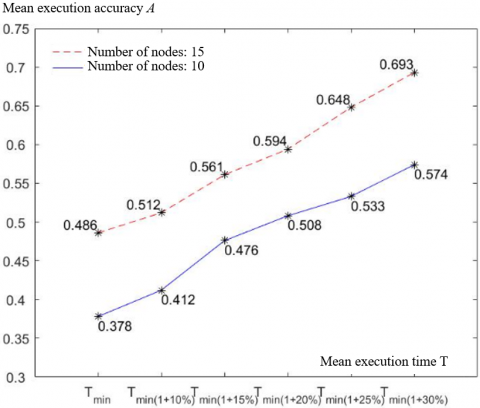
To disclose the relationship between mean execution time T and optimal scheduling performance of the ERWOSA, the number of nodes in the enterprise resource workflow model were set to 10 and 15 in turn, and the mean execution time T of each person was increased by 0.1, 0.15, 0.2, 0.25, and 0.3, respectively, before calling the ERWOSA to optimize the scheduling of the workflow. Figure 5 records the variation of mean execution accuracy A with the number of nodes and the mean execution time T.
As shown in Figure 5, when there were 10 nodes, the mean execution accuracy A of the enterprise resource workflow model increased by 0.412, 0.476, 0.508, 0.533, and 0.574, respectively, as the mean execution time T of each person was increased by 0.1, 0.15, 0.2, 0.25, and 0.3. When there were 15 nodes, the mean execution accuracy A increased by 0.512, 0.561, 0.594, 0.648, and 0.693 respectively, as the mean execution time T of each person was increased by 0.1, 0.15, 0.2, 0.25, and 0.3. Therefore, the mean execution accuracy A of the ERWOSA is positively correlated with the mean execution time T.
Figure 5. The variation of mean execution accuracy A with the number of nodes and the mean execution time T
(2) Relationship between number of nodes and performance
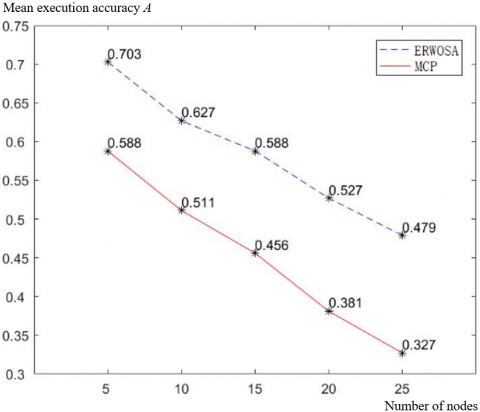
To disclose the relationship between the number of nodes and optimal scheduling performance of the ERWOSA, the number of nodes in the enterprise resource workflow model were set to 5, 10, 15, 20, and 25 in turn, and the mean execution time T of each person was increased by 0.2, before separately calling the ERWOSA and the minimum critical path (MCP) algorithm [25] to optimize the scheduling of the workflow. Figure 6 records the variation of mean execution accuracies A of the two algorithms with the number of nodes.
As shown in Figure 6, when the mean execution time T of each person was increased by 0.2, the mean execution accuracies A of the enterprise resource workflow model optimized by the ERWOSA increased by 0.703, 0.627, 0.588, 0.527, and 0.479, respectively, as the number of nodes was 5, 10, 15, 20, and 25; Meanwhile, those of the model optimized by the MCP increased by 0.588, 0.511, 0.456, 0.381, and 0.327, respectively. Hence, the ERWOSA achieved much better optimization effect than the MCP. It can also be seen from Figure 6 that the optimization effect of the ERWOSA declined with the growing number of nodes.
Figure 6. The variation of mean execution accuracies A of the two algorithms with the number of nodes
This paper firstly investigates the modelling and quantification of enterprise resource workflow, and then proposes an optimal scheduling algorithm called the ERWOSA. By this algorithm, the mean execution efficiency A, mean execution time T, and weight K of each node in the model are calculated, and used to derive the relative efficiency of each person in the model in completing his/her task; then, the weights of all nodes on each path are added up to obtain the total weight S of the path; the path with the highest total weight is taken as the most suitable and profitable path for the enterprise. The future research will optimize the workflow model in nonlinear scheduling environment.
[1] Schoville, R., Titler, M.G. (2020). Integrated technology implementation model: Examination and enhancements. Computers, Informatics, Nursing: CIN, 6: 12103-12122. https://doi.org/10.1097/CIN.0000000000000632
[2] Pourmirza, S., Peters, S., Dijkman, R., Grefen, P. (2017). A systematic literature review on the architecture of business process management systems. Information Systems, 66: 43-58. https://doi.org/10.1016/j.is.2017.01.007
[3] Gichoya, J.W., Kohli, M.D., Haste, P., Abigail, E.M., Johnson, M.S. (2017). Proving value in radiology: Experience developing and implementing a shareable open source registry platform driven by radiology workflow. Journal of Digital Imaging, 30(5): 602-608. https://doi.org/10.1007/s10278-017-9959-4
[4] Rashmi, S., Basu, A. (2017). Resource optimised workflow scheduling in Hadoop using stochastic hill climbing technique. Iet Software, 11(5): 239-244. https://doi.org/10.1049/iet-sen.2016.0289
[5] Kim, K., Yeon, M., Jeong, B.S., Kim, K.P. (2017). A conceptual approach for discovering proportions of disjunctive routing patterns in a business process model. TIIS, 11(2): 1148-1161. https://doi.org/10.3837/tiis.2017.02.030
[6] Koryl, M., Mazur, D. (2017). Towards emergence phenomenon in business process management. Archives of Control Sciences, 27(2): 263-277. https://doi.org/10.1515/acsc-2017-0017
[7] Prathibha, S., Latha, B., Sumathi, G. (2017). An improved multi-objective optimization for workflow scheduling in cloud platform. Journal of Internet Technology, 18(3): 589-599. https://doi.org/10.6138/JIT.2017.18.3.20161101
[8] Saygili, E.E., Ozturkoglu, Y., Kocakulah, M.C. (2017). End users' perceptions of critical success factors in ERP applications. International Journal of Enterprise Information Systems (IJEIS), 13(4): 58-75. https://doi.org/10.4018/IJEIS.2017100104
[9] Lee, C.J., Lee, C., Lee, E.B. (2018). A method for analyzing the effect of implementing an enterprise system based on the complexity of activities. Journal of Civil Engineering and Management, 24(7): 526-536. https://doi.org/10.3846/jcem.2018.6130
[10] Femmam, M., Kazar, O., Kahloul, L., Fareh, M.E.K. (2018). Labelled evolutionary Petri nets/genetic algorithm based approach for workflow scheduling in cloud computing. International Journal of Grid and Utility Computing, 9(2): 157-169. https://doi.org/10.1504/IJGUC.2018.091721
[11] Benaben, F., Truptil, S., Mu, W., Pingaud, H., Touzi, J., Rajsiri, V., Lorre, J.P. (2018). Model-driven engineering of mediation information system for enterprise interoperability. International Journal of Computer Integrated Manufacturing, 31(1): 27-48. https://doi.org/10.1080/0951192X.2017.1379093
[12] Hoyland, C.A. (2018). The reinforced enterprise business architecture (REBAR) ontology. International Journal of Design and Nature and Ecodynamics, 13(1): 71-81. https://doi.org/10.2495/DNE-V13-N1-71-81
[13] Taylor, S.J., Anagnostou, A., Kiss, T., Terstyanszky, G., Kacsuk, P., Fantini, N., Lakehal, D., Costes, J. (2018). Enabling cloud-based computational fluid dynamics with a platform-as-a-service solution. IEEE Transactions on Industrial Informatics, 15(1): 85-94. https://doi.org/10.1109/TII.2018.2849558
[14] Taylor, S.J., Kiss, T., Anagnostou, A., Terstyanszky, G., Kacsuk, P., Costes, J., Fantini, N. (2018). The CloudSME simulation platform and its applications: A generic multi-cloud platform for developing and executing commercial cloud-based simulations. Future Generation Computer Systems, 88: 524-539. https://doi.org/10.1016/j.future.2018.06.006
[15] Liu, D., Li, Y. (2019). A novel QoS negotiation model based on intelligent learning technique in clouds. International Journal of Networking and Virtual Organisations, 20(3): 265-283. https://doi.org/10.1504/IJNVO.2019.100181
[16] Datskova, O., Shi, W. (2019). Large-scale data processing software and performance instabilities within HEP grid environments. International Journal of Grid and Utility Computing, 10(4): 402-414. https://doi.org/10.1504/IJGUC.2019.100903
[17] Kalra, M., Singh, S. (2019). An intelligent water drops-based approach for workflow scheduling with balanced resource utilisation in cloud computing. International Journal of Grid and Utility Computing, 10(5): 528-544. https://doi.org/10.1504/IJGUC.2019.101995
[18] Narayani, R., Banu, W.A. (2019). Fairness-based heuristic workflow scheduling and placement in cloud computing. International Journal of Vehicle Information and Communication Systems, 4(4): 355-374. https://doi.org/10.1504/IJVICS.2019.103932
[19] Viriyasitavat, W., Hoonsopon, D. (2019). Blockchain characteristics and consensus in modern business processes. Journal of Industrial Information Integration, 13: 32-39. https://doi.org/10.1016/j.jii.2018.07.004
[20] Ahn, H., Kim, K.P. (2020). Formal approach for discovering work transference networks from workflow logs. Information Sciences, 515: 1-25. https://doi.org/10.1016/j.ins.2019.11.036.
[21] Oukfif, K., Oulebsir-Boumghar, F., Bouzefrane, S., Banerjee, S. (2020). Workflow scheduling with data transfer optimisation and enhancement of reliability in cloud data centres. International Journal of Communication Networks and Distributed Systems, 24(3): 262-283. https://doi.org/10.1504/IJCNDS.2020.106322
[22] Ouldkablia, M.E., Kechar, B., Bouzefrane, S. (2020). IoT-based smart home process management using a workflow approach. International Journal of Information Technology and Web Engineering (IJITWE), 15(2): 50-76. https://doi.org/10.4018/IJITWE.2020040103
[23] Almi’ani, K., Lee, Y.C., Mans, B. (2018). On efficient resource use for scientific workflows in clouds. Computer Networks, 146: 232-242. https://doi.org/10.1016/j.comnet.2018.10.003
[24] Aghabaghery, R., Golpayegani, A.H., Esmaeili, L. (2020). A new method for organizational process model discovery through the analysis of workflows and data exchange networks. Social Network Analysis and Mining, 10(1): 12. https://doi.org/10.1007/s13278-020-0623-5
[25] Adhikari, M., Amgoth, T. (2019). An intelligent water drops-based workflow scheduling for IaaS cloud. Applied Soft Computing, 77: 547-566. https://doi.org/10.1016/j.asoc.2019.02.004