© 2018 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The enactment of automatic medial image taxonomy using customary methods of machine learning and data mining mostly depend upon option of significant descriptive characteristics obtained from the medical images. Reorganization of those skins obliges domain-specific skillful awareness moreover not a forthright process. Here in this paper we are going to propose a deep learning based cnn’s named as deep cnn architecture. Which is a generic architecture and it accepts input as medical image data and produces the class or type of the decease. And we made comparison with the classical models like svm and elm.
deep learning, neural networks, medical image classification, processing, CNN, SVM
Contemporary development in the grounds of picture handling and also machine learning prompts likelihood of limiting tumor locales with less or no more human mediation. Such traditional methodology for distinguishing those districts about intrigue depends upon picture division strategies that perform either auxiliary or measurable example acknowledgment. In the previous case, the tissue association qualities are demonstrated utilizing worldwide highlights extricated from the chart built upon tissue segments (Ficsor et al., 2006). Within the final situation, the surface of nearby locales moreover morphological/hierarchical qualities of tissue parts were displayed utilizing data towards the pixel and also segment stage separately (Van der Maaten & Hinton, 2008). Within another methodology dependent upon machine learning, a classifier was prepared within the test picture information towards the stage of each particular pixels moreover great number of pixels (Zaitoun et al., 1998). To such particular situation, highlights vectors utilized depend upon basic nearby picture properties containing shading, morphology and also surface.
Here in the examination, we centeraround arranging districts within histological pictures into the tumor or also to non-tumor classes. Traditional machine-learning procedures, for example, bolster vector machine (SVM), extraordinary learning machine (ELM) has confinements within their capacity to process of these histological pictures into the crude shape (Cosatto et al., 2013; Abadi et al., 2016). The machine-learning framework needs cautious building and impressive space information to plan an element extractor which can change the crude information into a reasonable interior portrayal called the component vector (Sharma et al., 2015). The decision of these highlights decides adequacy in favor of such classifier and isn’t perfectly natural or clear. While an outcome, the execution of the SVM and also ELM was extraordinarily subject to the, and constrained by, the component extraction and also choice process. For beating this confinement of traditional machine learning strategies, deep learning (else synonymously, deep neural system) technique was suggested naturally finds portrayals required to arrangement (Sharma et al., 2016). Deep learning strategies were the subset of portrayal learning techniques within what kind of numerous stages of portrayals or chains of importance are developed. Each stage of portrayal is made out of basic however non-straight modules that change the portrayal at one stage to a portrayal at a higher and somewhat more dynamic stage. Within adequate structure of these change modules, extremely complex capacities also be scholarly (Krizhevsky et al., 2012; He et al., 2015). The important favorable position of deep learning rather than ordinary machine learning is such the layers about highlights were not recommended through people, rather were gained from the information utilizing the broadly useful learning technique (Deng & Yu, 2014; Deng, 2012; Najafabadi et al., 2015; Szegedy et al., 2015).
In previous couple of periods, deep learning systems, particularly convolutional neural systems (CNN) (LeCun et al., 1989), has drastically enhanced the condition of-workmanship within discourse acknowledgment, visual protest acknowledgment, question identification and also numerous different spaces, for example, medicate revelation furthermore genomics (Cruz-Roa et al., 2014; Ciresan et al., 2013). All the more as of late, CNN have observed extraordinary achievement within biomedical, organic picture investigation appeals, for example, mitosis cell location on the basis of histological pictures, carcinoma tumor identification on the basis of slide pictures, neuronal films division within electron microscopy pictures , skin sickness, malignancy arrangement, resistant cell discovery for immunohistochemistry pictures, moreover division of mass within mammograms (Razavian et al., 2014; Cerwall & Report, 2016; Rosado et al., 2003; Kittler et al., 2002; Gutman et al., 2016; Menzies & Gruijl, 1997; Schindewolf et al., 1993; Ramlakhan & Shang, 2011).
For to getting optimal and accurate results we combine use deep learning with CNN as Deep CNNs. These are automatically learning standard and great level perceptions acquired through raw data (e.g., images).
Novel results designate that standard descriptors mined from CNNs were tremendously operational within object gratitude and also localization in natural images.
Medical imagining is a most important aspect previously medical images are manually processed and take the results by doctors. But that was may not produces accuracy over all the aspects.
Restorative picture investigation bunches over the globe were rapidly entering the field also applying CNNs furthermore other deep learning (LeCun et al., 2015; Silver & Huang, 2016) strategies to a huge assortment of utilizations (Stern, 2010). Propitious outcomes were rising. In medicinal imaging, that exact finding and also additionally appraisal for an ailment relies upon both pictures obtaining and picture translation. Picture securing has enhanced generously over late years, with gadgets getting information at quicker rates and expanded goals. The picture understanding procedure, be that as it may, has as of late profit by PC innovation. Most elucidations of restorative pictures are performed by doctors; in any case, picture understanding by people is restricted because of its subjectivity, extensive varieties crosswise over translators, and weakness. Numerous demonstrative undertakings require an underlying pursuit procedure to recognize irregularities, and to evaluate estimations and changes after some time (Russakovsky et al., 2015). Electronic devices, particularly picture investigation also the machine learning, were the key empowering agents towards enhance analysis, encouraging recognizable proof of the discoveries that require treatment and to help the master's work process. Among these apparatuses, deep learning is quickly turned out to be the cutting edge establishment, prompting enhanced exactness (Ioffe & Szegedy, 2015). This has additionally opened up recent wildernesses within information investigation within the rates of advancement not previously well-versed.
In this paper we are going to propose a Deep learning based CNN’s named as deep CNN architecture. Which is a generic architecture and it accepts input as medical image data and produces the class or type of the decease (Masood & Al-Jumaily, 2013; Szegedy et al., 2015).
The remaining part about paper was stacked as seen section-2 gives a view about state-of art of Deep learning and CNN’s used in medical image analysis. Section-3 describes the proposed methodology of deep CNN architecture and its working. Section-4 refer to the experimental estimation of proposed work and lastly section-5 finalizes the paper.
Shin et al. investigated about effect of CNN models also exchange learning upon recognizing the nearness of expanded thoraco-stomach lymph hubs, moreover characterizing interstitial lung infection on CT sweeps, and observed exchange figuring out how to be advantageous, regardless of normal pictures being different from restorative pictures.
Ravishankkar et al. took a gander at the undertaking of consequently confining the nearness of kidney upon ultrasound pictures (Burroni et al., 2004). Utilizing CNN pre-prepared upon Imagenet, demonstrated such more prominent level for exchange taking in, the best the CNN functioned.
Tajbakhhsh et al. considered the viability about move learning within 4 distinct applications crosswise over three imaging modes: polyp recognition upon colonoscopy recordings, colonoscopy video outline characterization, pneumonic embolus discovery upon CT aspiratory angiograms, moreover division of parts of dividers of carotid course upon ultrasound checks (Clark et al., 1989) see their exchanged pre-prepared weights on the basis of
Krizhevvsy et al. towards likewise a couple ('shallow tuning') also number of ('profound tuning') levels within CNN. By and large, their set up the exchange adapting more levels enhanced this CNN execution, contrasted with preparing a CNN sans preparation. As opposed to numerous PC vision errands the shallow tuning for the final pair of parts is sufficient, restorative picture investigation needs a profound tuning of many parts. They likewise noticed the quantity of ideal levels prepared changed between various applications.
RNNs have customarily been utilized in dissecting consecutive information, for example, the words in a sentence. Because of their capacity to produce content, RNNs have been utilized in content investigation undertakings, similar to machine interpretation, discourse acknowledgment, dialect displaying, content forecast and picture inscription age.
Within a plain RNN, yield of a level is added to the following information, and was encouraged once more into level, bringing about the limit with regards to relevant 'memory'. To abstain from vanishing angle issues within back propagation by means of time, plain RNNs has advanced in the Long-Short-Term-Memory (LSTM) systems moreover also Gated-Recurrent-Units (GRUs). Those were adjustments of RNNs for holding huge haul conditions, also to dispose of or overlook a portion for collected data.
Within therapeutic picture examination space, RNNs has utilized primarily in the division. Chen et al. consolidated CNN also RNN towards portion neuronal further more parasitic structures from three-dimensional electron magnifying lens images.
Utilizing a multidimensional LSTM, Stollnga et al. divided the two three-dimensional electron magnifying lens pictures for neurons and in addition MRI mind examines. Shin et al. depict explaining X-beam pictures within the inscriptions prepared on radiology reports.
One precedent is Denoising Autoencoder announced through Vincnt et al., where the Gaussian commotion was further towards initial concealed layers. Employing withdraw i.e., haphazardly killing a portion of neurons within early shrouded layers, achieves a similar objective, by constraining the model to learn helpful codings for creating back commotion free contributions through the yield layer.
A next precedent are Sparse Auto encoders, whereby the characterized extent of neurons within the concealed layers were deactivated or sets to zero. This was refined by having the price work which punishes the model when there were dynamic neurons past characterized edge (Mnih, 2015)) method of reasoning behind this, was as Bengio states, for given perception, just a little division of the conceivable components are significant, implying that a great part of these highlights removed through information would be spoken to and been fixed to 0.
Kallnberg et al. joined unconfirmed convolution layers prepared like auto encoders, and also directed levels for characterize mammograms to various densities and also surfaces. The surface grouping undertaking was utilized to attribute if a mammogram was typical or delineated bosom growth. They utilized 2700 mammograms on the basis of Dutch Breast Cancer Screening Condition, Dutch Breast Cancer Screening data sets, also Mayo Mammography Health Study. We see the utilization of eager auto encoder by taking in the constraints through component extricating convolution layers, Previously the information used to bolster to a softmax classifier (Pan & Yang, 2010). For, disease characterization errand, the Convolution stacked autoencoder (CSAE) show acquired AUC score of the 0.57, what kind of the creators announced as per best in class.
VariationalAutoencoders (VAEs) were a developing and mainstream unsupervised learning engineering portrayed by Kingkma, Welling. VAEs the generative model, for comprising of Bayesian deduction encoder organize moreover decoder arrange, which can be prepared within stochastic angle drop. The encoder organize ventures input information into idle space factors, whose genuine dispersion is approximated utilizing a Gaussian dissemination. The decoder arranges and then maps the idle space once again to the yield information, prepared and directed by two cost works: a reproduction misfortune work and the Kulback– Leibler difference.
Boltzmann machines are imagined by Ackley et al. in 1985, and are altered as Restricted Boltzmann Machines (RBMs) after a period by Smolensky. RBMs were generative, stochastic, probabilistic, bidirectional graphical patterns comprising the unmistakable more over also concealed layers. The layers were associated with one another yet there are no associations inside the layers themselves. RBMs utilize the regressive go of information to create a remaking, and gauge the likelihood circulation of the first information.
van Tullder et al. altered RBMs to something were portrayed like the convolutional RBMs towards the group lung tissue to typical, emphysematous, fibrosed, micronodular, and also to ground glass tissue. To undertake these, they utilized CT chest outputs of about 128 patients within interstitial lung infection on the basis of ILD database. Convolutional RBMs are prepared within the simple discriminating, absolutely generative, or blended discriminative moreover generative learning targets towards know channels. These channels were used for performing highlight extraction, also make include actuation maps, before characterization utilizing an arbitrary woodland classifier.
Arrangement correctness of between 41% to 68% were acquired, contingent upon the extent of generative learning and also information fix measure. They additionally found channels created from blended discriminative moreover generative learning played out the better, inferring such discriminative learning would benefit unsupervised component extractors learn channels streamlined to characterization errands.
RBMs will proficiently prepared within Contrast-Divergence calculations also stacked in Deep Belief Networks (DBNs) (Hou et al., 2015; Binder et al., 1998; Deng et al., 2009), shrouded layer yield for RBM turns into contribution for the unmistakable layer of next RBM was placed upon it. DBNs are depicted by the Hinton et al. in 2006 out of original paper, which was to a great extent in charge for renaissance within profound learning. Knowledge from the Hinnton et al. were DBNs would prepare within voracious, layer by-layer mold, within least layers adapting least level highlights, and also logically higher layers adapting abnormal state highlights, reflecting certifiable information order. DBNs can likewise be coupled to layers of directed RBMs to create the semi supervised profound learning design. A use of RBMs was accounted for by
Khatammi et al., utilized DBNs to group x-beam pictures into the 5 classes of anatomic territories and introductions.
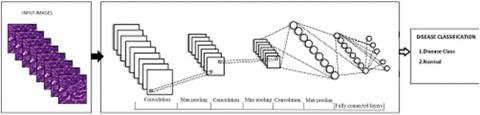
Choose of self-structured CNN engineering was simply managed feed forward system appeared, Figure 1. Comprises of 9 phases, where initial 6 phases involve convolution and pooling tasks, and the last 3 phases were completely associated layers.
Figure 1. CNN architecture
For info pictures, group size of 8 is utilized amid preparing stage and 10 amid sending stage to enhance proficiency utilizing cluster handling. Picture mean qualities are ascertained and subtracted from the pictures amid the two stages, for example, in the Alex Net system. The itemized portrayals of the different layers are as per the following.
3.1. Convolutional layer
Within every convolutional layer, output of before layers was convolved within many learned weight matrices known as filter masks or as learned kernels. Then result is processed by the non-linear operation for generating layer output. The linear operation in ath convolution layer, where input was denoted by ak 1 (output of the [a 1]th layer) comprises of the two-dimensional convolution (Song, 2018).
For our estimates, three convolutional layers were utilized within filter sizes 7, 5, 3 also 24, 16 and 16 highlight maps individually. Measure for scholarly channels ought to be like the span of examples to be detected. This choice is assignment subordinate and in our characterization issues, subtler points of interest in tissue locales should be settled, subsequently, littler channel sizes are chosen. Next, the weight instatement was performed utilizing Gaussian capacities within standard deviation of 0.01, and inclination is kept steady at 0.1. Yields dk were connected for activity that enhances learning procedure by expanding non-direct properties about system, also amended straight units (ReLU) also chosen because of advantages clarified. These are non-immersing enactment capacities where piece-wise straight tiling can accomplish. The course about tasks within convolutional layer were delineated in Figure 5.
3.2. Pooling layer
A pooling layer executing max-pooling is connected next to each convolutional layer. Max-pooling includes part of channel yield network in non-covering lattices also using the most extreme incentive in every framework as the incentive in the lessened grid. Consequently, it consolidates reactions at various areas and adds heartiness to little spatial varieties, in this manner expanding translational invariance, alongside diminishing spatial goals. We utilize a part measure 2 and walk two for max pooling activity next to each convolutional layer.
3.3. Fully-connected layer
Within completely associated layer, neurons were associated within neurons in past to following layers, for example, in ordinary neural systems. In the proposed CNN, three completely associated layers are utilized within 256, 128 also three (or two) yields individually, quantity of yields in keep going layer relies upon the arrangement issue within reach. Predisposition is set to 0.01. Dropout technique helps with lessening over fitting, particularly when the accessible preparing information is restricted, for example, the WSI information. Amid every emphasis, singular hubs alongside approaching and active edges were expelled from system, also were later returned alongside the underlying weights. In our methodology, next to everyrst 2 completely associated layers, dropout proportion i.e. likelihood of dropping any contribution of the two phases is set to 0.25.
3.4. Learning properties
Learning of the convolutional neural system depends upon estimating a misfortune work additionally known target work, mistake work, cost work) that shows the blunder of scholarly system parameters. The learning objective was towards figure the parameters for limiting misfortune work. Softmax work is the likelihood of class ei given info X, where yi speaks to value for ith class within aggregate e classes. Softmax misfortune E is figured by negative log probability for softmax work, N means the length about vector class.
Procedure used to optimize the loss minimization known as Stochastic Gradient Descent within Momentum. For the tth step, update process is defined, where[φ]t signifies the current weight refresh, φ_(t-1) was past weigh refresh, w speaks about weighs, G was normal misfortune towards dataset, rG(w) was negative slope, and learning period also speaks to force utilized for accelerating the assembly of inclination and forestalling motions.
In learning stage, dual parameters ν, η were required to be likely chosen. By correct examination orchestrate, η was 0.001 at first, and was reduced by a factor of 0.1 next to each 20,000 accentuations, also ν is settled as 0.9. Considering eight planning ages 330 were done in the midst of every readiness organize in the wake of beginning test examination of getting ready curves on our datasets.
Convolutional neural network for image classification is implemented victimization python language in Ubuntu operative system. Tensor flow that is Associate in nursing open supply library focused on machine learning applications is employed. Open CV that is Associate in nursing open supply library for pc vision is employed to scan the photographs from the dataset. Figure 3: Flow Chart of the projected System Python could be a high level, understood, object orientating scripting language that's straightforward to be told, read and maintain. It supports each practical and object orientating programming. It is simply integrated with different programming languages. One in all the explanations why python is mostly used for machine learning applications is its syntax. Since the syntax of python is mathlike, it is easy for programmers to specific their concepts mathematically. It has explicit tools that ar terribly useful in developing machine learning applications. Frameworks, libraries and extensions like NumPy build python to accomplish the tasks simply. Languages like Java, Ruby would like exhausting coding thanks to their quality whereas python is considered as a toy language thanks to its easy syntax and lots of options. Since python will do loads things simply, that helps for complicated set of machine learning tasks it's thought of as a best language for implementing machine learning tasks. Tensorflow is Associate in Nursing open supply software system library developed by google brain team (Hinton, 2005; Roger et al., 2015) for numerical computations victimization data flow graphs. it's a symbolic science library used for machine learning applications like deep neural networks. The nodes of the graph represent operations whereas the sides of the graph represent multidimensional knowledge arrays. Tensorflow provides flexibility to deploy the computation on quite one GPU or CPU.
577 tissue picture ROIs were separated from 2 TMAs through the pathologist. Within those, 243 were non-tumor tissues, 334 were tumor tissues. Measure of the picture ROI was 300x300 pixels. For estimating execution of DCNN, huge preparing information tests are favored. To create all the more preparing information, we trimmed littler patches from every picture ROI. These trimmed patches are then pivoted and turned to in the long run make 21,349 picture fixes altogether. All these picture patches were reshaped to 32x32 pixels previously nourishing within suggested methods also the spatial size for info layer is 32x32 pixels. 21,349 pictures were haphazardly part within preparing, approval also testing datasets within 4:1:1 proportion, individually (i.e., every dataset contains 14,233 preparing tests, 3,558 approval tests, also 3,558 testing tests). To estimate execution of SVM, ELM, significant highlights should be chosen and extricated as contribution for the classifiers. Following our past examination, 43 highlights (6 shading highlights and 37 surface highlights) are extricated from each picture fix. As beforehand featured, the component extraction methodology isn't required for the proposed models.
4.1. Evaluation metrics
Expecting that the tumor class was "sure" also non-tumor class was "-ve", at that point, without loss of consensus, each arranged (anticipated) example will have a place with one of accompanying four classifications:
Genuine positive (TP): the example was anticipated to "certain" while it was really positive; False positive (FP): the example was anticipated being "sure" while it was really -ve; True -ve (TN): Hence example was anticipated towards "negative" such that when it was really -ve; and False -ve (FN): example was anticipated being "negative" while it was really positive.
Here we utilize precision (Test Efficiency) of characterization execution assessment. Here exactness (ACC) of the classifier is likelihood that classifier arranges an arbitrarily chose test to the right class. It is controlled by utilizing the accompanying condition:
4.2. Results and discussions
Figure 2. Training accuracy
Here Figure-2 describes the different models with their training accuracy by varying the number of sample images. Here SVM, ELM and DNN are compared with each other. SVM having low training accuracy over ELM because of its inefficacy over handling the image data. ELM is somewhat better than the SVM but this is also under performed compared proposed DNN training because DNN learns from past mistakes if the more the training data it produces the more accuracy by learning all possible features.
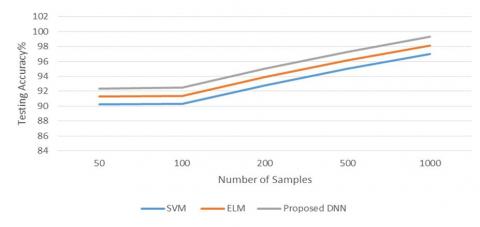
Figure 3. Testing accuracy
Here Figure-3 describes the different models with their testing accuracy by varying the number of sample images. Here SVM, ELM and DNN are compared with each other. SVM having low testing accuracy over ELM because of its inefficacy over handling the image data. ELM is somewhat better than the SVM but this is also under performed compared proposed DNN testing because DNN learns from past mistakes if the more the training data it produces the more accuracy by learning all possible features.
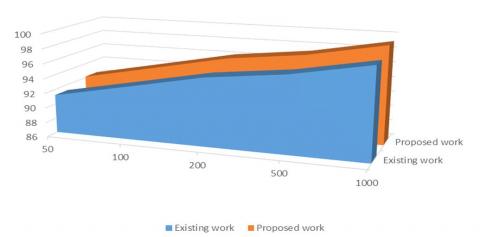
Figure 4. Accuracy of proposed and existing models
Here Figure-4 describes the overall performance of handling the image data with existing model of machine learning. DNN outperformed clearly because it has a capability more careful handling of inputs and it can able to learn all features.
Here we proposed a deep learning based CNN which aims at classification of medical images. Since the suggested methodology do not include highlight extraction furthermore determination by area specialists to particular application, it tends to effortlessly reached out to other biomedical () or organic picture grouping assignments. The performance results show that more promising results and highest accuracy when compared to the existing works.
Abadi M. (2016). TensorFlow: large-scale machine learning on heterogeneous distributed systems. https://arxiv.org/abs/1603.04467
Binder M., Kittler H., Seeber A., Steiner A., Pehamberger H., Wolff K. (1998). Epiluminescence microscopy-based classification of pigmented skin lesions using computerized image analysis and an artificial neural network. Melanoma Res, Vol. 8, 261–266. https://doi.org/10.1097/00008390-199806000-00009
Burroni M., Corona R., Dell'Eva G., Sera F., Bono R., Puddu P., Perotti R., Nobile F., Andreassi L., Rubegni P. (2004). Melanoma computer-aided diagnosis: Reliability and feasibility study. Clin. Cancer Res, Vol. 10, pp. 1881–1886. https://doi.org/10.1158/1078-0432.CCR-03-0039
Cerwall P., Report E. M. (2016). Ericssons mobility report. https://www.ericsson.com/res/docs/2016/ericsson-mobility-report-2016.pdf
Ciresan D. C., Giusti A., Gambardella L. M., Mitosis S. J. (2013). De-tection in breast cancer histology images with deep neural networks. In: Medical Image Computing and Computer-Assisted Intervention, MICCAI 2013, Springer, pp. 4118.
Clark W. H. (1989). Model predicting survival in stage I melanoma based on tumor progression. J. Natl Cancer Inst, Vol. 81, pp. 1893–1904. https://doi.org/10.1093/jnci/81.24.1893
Cosatto E., Laquerre P. F., Malon C., Graf H. P., Saito A., Kiyuna T. (2013). Automated gastric cancer diagnosis on H&E-stained sections; ltraining a classier on a large scale with multiple instance machine learning. In: SPIE Medical Imaging. International Society for Optics and Photonics, pp. 86-76. https://doi.org/10.2145/isop.21414
Cruz-Roa A., Basavanhally A., Gonzalez F., Gilmore H., Feldman M., Ganesan S. (2014). Automatic detection of invasive ductal carcinoma in whole slide images with convolutional neural networks. In: SPIE Medical Imaging, International Society for Optics and Photonics, pp. 904103. https://doi.org/10.1117/12.2043872
Deng J. (2009). Imagenet: A large-scale hierarchical image database. IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 (CVPR,). https://doi.org/10.1109/CVPR.2009.5206848
Deng L. (2012). Three classes of deep learning architectures and their applications: A tutorial survey. APSIPA Transactions on Signal and Information Processing.
Deng L., Yu D. (2014). Deep learning: Methods and applications. Foundations and Trends in Signal Processing, Vol. 7, No. 3, pp. 197. https://doi.org/10.1561/2000000039
Ficsor L., Varga V., Berczi L., Miheller P., Tagscherer A., Wu M.L.C., Tulassay Z., Molnar B. (2006). Automated virtual microscopy of gastric biopsies. Cytometry Part B: Clinical Cytometry, Vol. 70, No. 6, pp. 423-31. https://doi.org/10.1342/cpb.12451
Gutman D. A., Codella N., Celebi M. E., Halpern A. (2016). Skin lesion analysis toward melanoma detection. International Symposium on Biomedical Imaging (ISBI), (International Skin Imaging Collaboration (ISIC).
He K., Zhang X., Ren S., Sun J. (2015). Deep residual learning for image recognition. Computer Vision and Pattern Recognition. https://arxiv.org/abs/1512.03385
Hinton G. E. (2005). What kind of graphical model is the brain. In: IJCAI, Vol. 5, pp. 176575. https://doi.org/10.1109/ICSENG.2005.72
Hou L., Samaras D., Kurc T. M., Gao Y., Davis J. E., Saltz J. H. (2015). Ecient Multiple instance convolutional neural networks for gigapixel resolu-tion image classication. arXiv preprint arXiv, pp. 1-9. http://arxiv.org/abs/1504.07947
Ioffe S., Szegedy C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. Proc. 32nd Int. Conference on Machine Learning, pp. 448–456.
Kittler H., Pehamberger H., Wolff K., Binder M. (2002). Diagnostic accuracy of dermoscopy. Lancet Oncol, Vol. 3, pp. 159–165. https://doi.org/10.1016/S1470-2045(02)00679-4
Krizhevsky A., Sutskever I., Hinton G. E. (2012). Imagenet classication with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097105. https://doi.org/10.1145/3065386
Krizhevsky A., Sutskever I., Hinton G. E. (2012). Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process, Syst, Vol. 25, pp. 1097–1105. https://doi.org/10.1145/3065386
LeCun Y., Bengio Y., Hinton G. (2015). Deep learning. Nature, Vol. 521, No. 7553, pp. 43644.
LeCun Y., Boser B., Denker J. S., Henderson D., Howard R. E., Hubbard W. (1989). Backpropagation applied to handwritten zip code recognition. Neural Computation, Vol. 1, No.4, pp. 54151. https://doi.org/10.1162/neco.1989.1.4.541
Masood A., Al-Jumaily A. A. (2013). Computer aided diagnostic support system for skin cancer: A review of techniques and algorithms. Int. J. Biomed. Imaging 2013, pp. 323268. https://doi.org/10.1155/2013/323268
Menzies S. W., Gruijl F. R. (1997). In skin cancer and UV radiation. (eds Altmeyer P., Hoffmann K., Stücker M.), pp. 1064–1070. https://doi.org/10.1038/366023a0
Mnih V. (2015). Human-level control through deep reinforcement learning. Nature, Vol. 518, pp. 529–533. https://doi.org/10.1038/nature14236
Najafabadi M. M., Villanustre F., Khoshgoftaar T. M., Seliya N., Wald R., Muharemagic E. (2015). Deep learning applications and challenges in big data analytics. Journal of Big Data 2015, Vol. 2, No. 1, pp. 121. https://doi.org/10.1186/s40537-014-0007-7
Pan S. J., Yang Q. (2010). A survey on transfer learning. IEEE Trans. Knowl. Data Eng, Vol. 22, pp. 1345–1359. https://doi.org/10.1109/TKDE.2009.191
Ramlakhan K., Shang Y. (2011). A mobile automated skin lesion classification system. 23rd IEEE International Conference on Tools with Artificial Intelligence (ICTAI), pp. 138–141. https://doi.org/10.1109/ICTAI.2011.29
Razavian A., Azizpour H., Sullivan J., Carlsson S. (2014). CNN features o -the-shelf: an astounding baseline for recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Work-shops, pp. 80613.
Rogers H. W., Weinstock M. A., Feldman S. R., Coldiron B. M. (2015). Incidence estimate of nonmelanoma skin cancer (keratinocyte carcinomas) in the US population, 2012. JAMA Dermatology 151.10, pp. 1081–1086 (2015). https://doi.org/10.1001/jamadermatol.2015.1187
Rosado B., Menzies S., Harbauer A., Pehamberger H., Wolff K., Binder M., Kittler H. (2003). Accuracy of computer diagnosis of melanoma: a quantitative meta-analysis. Arch. Dermatol, Vol. 139, pp. 361–367. https://doi.org/10.1001/archderm.139.3.361
Russakovsky O. (2015). Imagenet large scale visual recognition challenge. Int. J. Comput, Vis, Vol. 115, pp. 211–252. https://doi.org/10.1007/s11263-015-0816-y
Schindewolf T., Stolz W., Albert R. (1993). Classification of melanocytic lesions with color and texture analysis using digital image processing. Anal. Quant. Cytol. Histol, Vol. 15, pp. 1–11. https://doi.org/10.1016/1050-1738(93)90025-2
Sharma H., Zerbe N., Heim D., Wienert S., Behrens H. M., Hellwich O. (2015). A Multi-resolution approach for combining visual information using nuclei segmentation and classcation in histopathological images. In: Proceedings of the 10th International Conference on Computer Vision Theory and Applications (VISAPP 2015), Scitepress, pp. 37-46.
Sharma H., Zerbe N., Heim D., Wienert S., Lohmann S., Hellwich O. (2016). Cell nuclei attributed relational graphs for e cient representation a classication of gastric cancer in digital histopathology. In: SPIE Medical Imaging. International Society for Optics and Photonics, pp. 97910X.
Sharma H., Zerbe N., Klempert I., Lohmann S., Lindequist B., Hellwich O. (2015). Appearance-based necrosis detection using textural features and svm with discriminative thresholding in histopathological whole slide images. In: Bioinformatics and Bioengineering (BIBE), 2015 IEEE International Conference on, IEEE, pp. 16. https://doi.org/10.1109/BIBE.2015.7367702
Silver D., Huang A. (2016). Mastering the game of go with deep neural networks and treesearch. Nature, Vol. 529, pp. 484–489. https://doi.org/10.1038/nature16961
Song S. L. (2018). Application of gray prediction and linear programming model in economic management. Mathematical Modelling of Engineering Problems, Vol. 5, No. 1, pp. 46-50. https://doi.org/10.18280/mmep.050107
Stern R. S. (2010). Prevalence of a history of skin cancer in 2007: results of anincidence-based model. Arch, Dermatol, Vol. 146, pp. 279–282. https://doi.org/10.1001/archdermatol.2010.4
Szegedy C., Liu W., Jia Y. Q. Sermanet P., Reed S., Anguelov D., Erhan D., Vanhouche V., Rabinovich A. (2015). Going deeper with convolutions. Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–9. https://doi.org/10.1109/CVPR.2015.7298594
Szegedy C., Vanhoucke V., Ioffe S., Shlens J., Wojna Z. (2015). Rethinking the inception architecture for computer vision. https://arxiv.org/abs/1512.00567
Van der Maaten L., Hinton G. (2008). Visualizing data using t-SNE. J. Mach. Learn. Res, Vol. 9, pp. 2579–2605.
Zaitoun A., Mardini A. H., Record C. (1998). Quantitative assessment of gas- tric atrophy using the syntactic structure analysis. Journal of Clinical Pathology, Vol. 51, No. 12, pp. 895-900. https://doi.org/10.1136/jcp.51.12.895