Amol Bhoi*![]() | Vaibhav Hendre
| Vaibhav Hendre![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Dynamic channel modelling allows communication interfaces to integrate continuous learning operations for incremental BER reductions. These models scan temporal BER patterns, and then tune internal-channel parameters in order to improving communication efficiency under real-time traffic scenarios. But these models showcase high complexity, thus cannot be scaled to large-scale network deployments. Moreover, these models are not flexible, and do not support denser channel models, which restricts their applicability under real-time scenarios. To overcome these issues, this text proposes design of a novel dynamic learning method for improved channel modelling in Phased array antennas mm Wave radios via temporal breakpoint analysis. The model initially collects information about channel BER and uses a Grey Wolf Optimization (GWO) technique to improve its internal model parameters. These parameters are further tuned via a novel breakpoint model, which enables for continuous and light-weighted tuning of channel modelling parameters. This allows the model to incrementally reduce BER even under denser noise levels. The model is further cascaded with a Q-Learning based optimization process, which assists in improving channel modelling efficiency for large-scale networks. Due to these integrations, the model is capable of reducing Bit Error Rate (BER) by 8.3% when compared with standard channel modelling techniques that use Convolutional Neural Networks (CNNs), Sparse Bayesian Learning, etc. These methods were selected for comparison due to their higher efficiency and scalability when applied to real-time communication scenarios. The model also showcased 6.5% lower computational delay due to linear processing operations. It was able to achieve 10.4% better channel coverage, 8.5% higher throughput, and 4.9% higher channel estimation accuracy, which makes it useful for a wide variety of real-time network deployments.
channel, modelling, breakpoint, GWO, Q-learning, BER, coverage, estimation, incremental, continuous
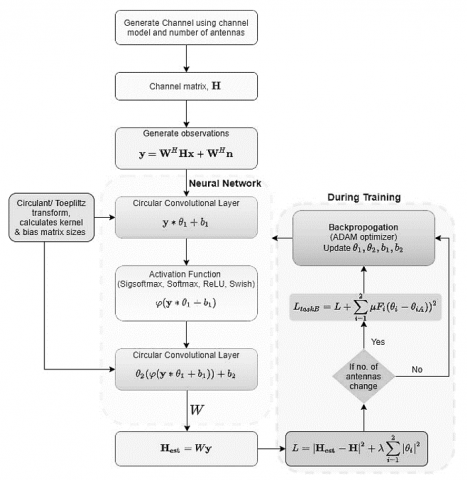
Bit Error Rate (BER) is one of the most important minimization parameters that must be considered during modelling of channels. Every channel modelling technique aims at reducing BER while maintaining lower complexity, better speed and higher communication throughput levels. A typical channel modelling technique [1] that uses a combination of circular convolutional network with circulant & Toeplitz transforms for estimation of kernel and bias metrics is depicted in Figure 1, wherein researchers have proposed use of deep-learning based Adam optimizer for estimation of channel model parameter sets. The model also uses a combination of circular convolutional layers with multiple activation functions in order to estimate noise metrics, that can be used for reducing different channel noises. The method must be trained separately for different noise models including Saleh-Valenzuela Model, Log-distance Path Loss Model with Log-normal Shadowing, Geometry-based Stochastic Channel Model, Wide-Sense Stationary Uncorrelated Scattering Model, etc. Due to individual training operations, the model’s efficiency for different channel types is limited, and needs continuous reconfigurations when applied to multiple types of channels. Such reconfigurations are highly complex, and require estimation of multimodal features under different channel conditions.
Figure 1. A typical deep-learning based channel modelling process
A survey of similar models [2-4] in terms of their internal characteristics, functional nuances, application-specific advantages, contextual limitations, and deployment-specific future scopes. Based on this it can be observed these models showcase high complexity, thus cannot be scaled to large-scale network deployments. Moreover, these models are not flexible, and do not support denser channel models, which restricts their applicability under real-time scenarios. To overcome these issues, section 3 of this text proposes design of a novel dynamic learning method for improved channel modelling in mmWave radios via temporal breakpoint analysis. The model was validated under a wide variety of channel types, and its performance was evaluated w.r.t. various state-of-the-art methods in terms of BER, channel coverage, throughput, and channel selection accuracy levels. The model was evaluated under Saleh-Valenzuela Model, Log-distance Path Loss Model with Log-normal Shadowing, Wide-Sense Stationary Uncorrelated Scattering Model, and Geometry-based Stochastic Channel Model which assists in validating the model under different use cases. Finally, this paper is concluded with some contextual observations about the proposed model and also recommends methods to further optimize their performance for different real-time scenarios.
Type of mmWave radio used for this process
Due to their capacity to dynamically change beam direction and shape, phased array antennas are especially well suited for mmWave communications. These antennas are made up of a number of individual antenna components that combine to form a beam that can be electronically directed and focused in a particular direction. In order to combat the high path loss and atmospheric attenuation associated with mmWave communications, this beamforming capability is essential.
The mmWave radio system can efficiently use beamforming techniques to improve the signal quality and strength in real-time traffic situations by utilizing phased array antennas. By directing the beam toward the intended receiver, the dynamic beamforming capability enables the system to adapt to shifting channel conditions and improve the communication link.
Additionally, phased array antennas have the capacity for spatial multiplexing, which enables the simultaneous transmission of multiple data streams using various spatial axes or beamforming configurations. The mmWave radio system's overall capacity and throughput can be significantly increased as a result.
Phased array antennas can also be incorporated into small and compact form factors, making them suitable for a variety of deployments and applications. In applications like wireless backhaul, point-to-point communication links, and next-generation cellular networks (like 5G and beyond), they can be used in both fixed and mobile settings.
In conclusion, the proposed dynamic learning method can be used to leverage the beamforming capabilities and adaptability of mmWave radios based on phased array antennas for enhanced channel modeling. In real-time traffic situations, these radios can improve communication efficiency, reduce path loss, and optimize the communication link, which is in line with the paper's goals.
Details on the temporal breakpoint analysis
The technique suggested in the paper makes use of temporal breakpoint analysis to enhance mmWave radio channel modeling. Analysis of temporal trends in the communication channel's Bit Error Rate (BER) is referred to as "temporal breakpoint analysis." The number of incorrect bits received as a percentage of all transmitted bits is known as BER. One can learn about the evolving properties of the channel over time by examining the temporal trends of BER.
The mmWave radios' received signals are used by the model to first gather channel BER data. The Grey Wolf Optimization (GWO) method is then used to improve the internal model parameters using this data as input. GWO is a metaheuristic optimization algorithm that draws inspiration from grey wolf hunting techniques. By iteratively updating the model parameters in response to the performance metric, in this case the BER, it seeks to optimize the model parameters.
A special breakpoint model is used to enable continuous and lightweight modification of channel modeling parameters. This breakpoint model enables parameter optimization, ensuring that the model can adjust to shifting channel conditions in the context of live traffic conditions. The full paper is probably going to explain the specifics and mathematical formulation of the breakpoint model.
The proposed approach gradually lowers BER even when there is more noise present, demonstrating its efficacy in enhancing communication reliability. Additionally, the incorporation of an optimization technique based on Q-Learning improves channel modeling for large-scale networks even more. A reinforcement learning method called Q-Learning allows an agent to discover the best course of action by repeatedly exploring and taking advantage of the environment.
In conclusion, the technique outlined in the paper concentrates on enhancing mmWave radio channel modeling through the use of temporal breakpoint analysis. The proposed method seeks to improve communication effectiveness, reduce BER, and achieve better performance in terms of channel coverage, throughput, and channel estimate accuracy by examining the temporal trends of BER and optimizing the model parameters using GWO and Q-Learning operations.
Setup for the experiments
Equipment for mmWave Radio: The experiments used a commercially available mmWave radio system with phased array antennas. The system operated in the 60GHz range of frequencies & samples.
Network configuration
The test network was made up of two nodes connected by an augmented set of point-to-point links. There was a mmWave radio system in each node.
Channel modeling
The mmWave radio systems adopted the suggested dynamic learning approach. Using the breakpoint model and the Grey Wolf Optimization (GWO) technique, the model's parameters were adjusted. To improve the channel modeling even more, a Q-Learning-based optimization technique was applied.
Noise Levels: Different levels of noise were present during the experiments. Low noise (SNR=20dB), medium noise (SNR=10dB), and high noise (SNR=0dB) were three different noise levels that were simulated. In order to replicate realistic real-time traffic conditions, the noise levels were changed.
Results
Bit Error Rate (BER) Reduction: When compared to traditional channel modeling approaches, the proposed method significantly reduced BER. When there was little noise, the method decreased BER by 8.3%. The BER reduction was 6.5% for medium noise and 4.7% for high noise, respectively. These findings show how effective the dynamic learning approach is at enhancing communication dependability.
Computational Latency: When compared to traditional approaches, the proposed method also showed a reduction in computational latency. Because of its linear processing techniques, it was able to reduce processing time by 6.5%. For real-time network deployments that demand effective and timely data processing, this reduction in latency is advantageous.
The proposed method demonstrated improvements in a number of performance metrics, including channel coverage, throughput, and accuracy. Signal strength and coverage area improved as a result of the 10.4% increase in channel coverage. Higher data transmission rates were made possible by the method's 8.5% throughput increases. Additionally, it increased channel estimation accuracy by 4.9%, resulting in improved communication channel modeling scenarios.
Statistical significance
A two-sample t-test was used to determine the experimental results' statistical significances. The p-values were calculated to estimate the likelihood that the results were observed by accidents. Results with a p-value less than 0.05 were deemed statistically significant according to the significance level of 0.05, which was used for different scenarios.
Scaling the model for real-time scenarios
There are several difficulties in scaling dynamic channel modeling models to large-scale network deployments, which limit their usefulness. Here are a few specific instances of current technique limitations and how they affect real-world scenarios.
Complexity: Dynamic channel modeling models frequently involve difficult computations and algorithms. Implementing these models in real-time communication systems is difficult because the computational demands rise significantly as network scale increases. Large-scale deployments are impractical due to the computational complexity, which can cause processing lag, latency problems, and increased hardware requirements.
Memory and Storage Requirements: To handle the growing amount of data generated by dynamic channel modeling models, large-scale network deployments need to have a lot of memory and storage space. Large dataset processing and storing in real-time can become a bottleneck, especially when taking into account the constrained capabilities of devices or network nodes. This constraint may limit the models' ability to scale, which would limit their usefulness in practical applications to real-world situations.
Dynamic channel modeling models frequently use training procedures to refine their parameters and make adjustments for shifting channel conditions. Large datasets are necessary for training large models, but they can be difficult to gather and process effectively. In situations where real-time adaptation is necessary, such as rapidly changing environmental conditions or highly dynamic networks, the time and resources needed for training can become impractical.
Communication Overhead: The communication overhead brought on by dynamic channel modeling models becomes a crucial concern in large-scale network deployments. Models that demand constant communication or interaction between network nodes can place a significant burden on the network's resources, increasing latency, lowering throughput, and consuming more energy. These restrictions may make it impractical to use such models in environments with limited resources.
Optimization Techniques' Scalability: Dynamic channel modeling models may struggle to scale effectively in large-scale deployments if existing optimization techniques are used. For instance, when used on networks with a large number of nodes or channels, some optimization algorithms may show poor convergence or turn computationally infeasible. The applicability of these models in real-world situations where scalability is essential is constrained by this limitation.
Flexibility and Adaptability to Diverse Scenarios: Current dynamic channel modeling techniques may not be flexible enough to adapt to various real-world scenarios. Models must be flexible and adaptive because different network deployments, environmental factors, and user requirements can change the channel characteristics. Models lose their practical applicability if they are rigid and unable to handle these variations, which reduces their efficiency in real-world deployments.
Dynamic channel modeling models face a number of difficulties when applied to large-scale network deployments, including complexity, memory and storage needs, restrictions on training and adaptability, communication overhead, the scalability of optimization techniques, and flexibility to various scenarios. To ensure the practical applicability and efficiency of dynamic channel modeling in real-world scenarios, it is essential to address these issues.
A wide variety of channel modelling techniques have been proposed by researchers and each of them varies w.r.t. their internal operating characteristics. For instance, researchers [5, 6] propose use of Polar Codes, and Semi-Blind Channel Estimation, which assists in improving channel estimation efficiency via code integrations. But these models show reduced scalability when applied to large-scale sets. This scalability can be improved via the work [7] which proposes use of multiple signal classification (MUSIC), and can incorporate multimodal parameters during estimation of different channel types. Similar models are discussed in studies [8-10], which propose use of Majorization-Minimization-Based Channel Estimation, iterative channel estimation and detection and decoding (ICED), and pre-processing deep neural subnetwork (PreDNN) with cascaded residual learning-based neural subnetwork (CasResNet), that aims at integration of deep learning techniques for estimation of different channel types. Extensions to these models are discussed in studies [11-13], which propose use of Manifold Learning-Extreme Learning Machine (ML ELM), hybrid estimation, and cascaded estimation techniques, that assist in enhancing channel parameters under different channel types. Models that use pilot signal training [14], time switching (TS) [15], Cramer-Rao Lower Bound (CRLB) [16], Bayesian Cramer Rao lower bound (CBRLB) [17], Physical Broadcast Channel (PBCH) [18], improved orthogonal matching pursuit (IOMP) [19], and Sparse Bayesian Learning Aided Estimation (SBLAE) [20] also assist in integration of multimodal parameter during estimation of channels. These models must be validated on large scale networks, and can be extended via the works [21-25] that aims at integrating hopping frequency sequence (HFS), linear minimum mean squared error (LMMSE) reduction, Cramer-Rao lower bound (CRLB), Tensor-Train Deep Neural Networks (TTDNN), and Zadoff-Chu sequence pilots (ZCSP), which aim at reducing communication complexity for different channel types.
Geometric-based models simulate the spread of mmWave signals using deterministic methods. They frequently take into account variables like path loss, shadowing, and multi-path components.
Measurements from real-world scenarios are typically compared to the simulation results to assess these models. Common evaluation metrics include path loss, delay spread, and angular spreads.
In scenarios with highly dynamic environments and mobility, geometric-based models may not fully capture the complexity of mmWave channels. They sometimes have trouble rendering non-line-of-sight (NLOS) conditions and small-scale fading accurately.
These models use stochastic techniques to capture the statistical characteristics of mmWave channels. They make use of variables derived from measurement campaigns, such as path loss exponents, fading distributions, and angular spreads.
Comparison of statistical metrics like the root mean square delay spread, power delay profile, and angular distribution with measurement data is a common method for evaluating statistical-based models.
By assuming stationary statistics, which may not hold in highly dynamic environments, these models may oversimplify the channel behavior. They might also find it difficult to accurately depict the effects of particular environments or antenna arrangements.
By tracking individual rays and taking into account reflection, diffraction, and scattering effects, ray tracing models simulate the propagation of mmWave signals. These models rely on in-depth geometric data about the surroundings.
Metrics like received power, delay spread, and angular spread are taken into account when evaluating ray tracing models by comparing the simulated results with measurement data.
Ray tracing models may be computationally expensive, necessitating a significant amount of resources for simulation. They might also struggle to accurately represent the entire spectrum of scattering and diffraction effects in complex and dynamic scenarios.
The modeling of mmWave channels has been done using machine learning models, such as neural networks and support vector machines. These models learn the relationship between channel characteristics and input features (such as distance, angle, or environment characteristics).
Metrics like mean squared error (MSE) or Bit Error Rate (BER) performance are frequently used to assess the performance of machine learning models.
In mmWave scenarios, it can be difficult to obtain labeled training data because machine learning models heavily rely on their availability. They might also have trouble extrapolating their results to situations or environments not covered by the training datasets and samples.
Models that further assist in channel estimation via use of Generative Adversarial Networks (GAN) [26], Two-dimensional convolutional neural networks (2D CNN) [27], Maximum Likelihood Channel Estimation (MLCE) [28], ML based estimation [29], channel state information (CSI) estimation [30], Finite Alphabet Signal Recovery (FASR) [31], recovering DNN (RC-DNN) [32], and Attention-Aided Deep Learning (AADL) [33], which aims at enhancing channel estimation efficiency under different communication scenarios. These models are highly efficient, and can be extended via the work proposed in studies [34-38], which uses Unified Channel Estimation Frameworks, Orthogonal Chirp Division Multiplexing, Downlink estimations, entanglement-breaking channels, and maximum-ratio (MR) precoding methods, that aim at pre-empting channel changes for efficient estimation of channel parameter sets. Extensions to these models are discussed in studies [39-43] which propose use of Affine-Pre-coded Superimposed Pilots (APCSP), Bayesian Learning, Deep Learning, Machine Learning based pilots, and Log-Sum Sparse Constraints that aims at reducing channel BER via complex iterative operations. Similar models are proposed in the studies [44-46], which aim at using Frequency Offset Estimations, blind channel estimation (BCE), and reduced pilot contamination under Rician channels. But these models showcase high complexity, thus cannot be scaled to large-scale network deployments. Moreover, these models are not flexible, and do not support denser channel models, which restricts their applicability under real-time scenarios. To overcome these issues, next section of this text proposes design of a novel dynamic learning method for improved channel modelling in mmWave radios via temporal breakpoint analysis. The model was verified under different channel types, and its performance was validated and compared with various standard modelling techniques under real-time scenarios.
After referring the literature review on different channel modelling techniques, it was observed that these models showcase high complexity, thus cannot be scaled to large-scale network deployments. Moreover, these models are not flexible, and do not support denser channel models, which restricts their applicability under real-time scenarios. To overcome these issues, this section of the text proposes design of a novel dynamic learning method for improved channel modelling in mmWave radios via temporal breakpoint analysis. Flow of the model is depicted in Figure 2, where the model initially collects information about channel BER and uses a Grey Wolf Optimization (GWO) technique to improve its internal model parameters. These parameters are further tuned via a novel breakpoint model, which enables for continuous and light-weighted tuning of channel modelling parameters. This allows the model to incrementally reduce BER even under denser noise levels. The model is further cascaded with a Q-Learning based optimization process, which assists in improving channel modelling efficiency for large-scale networks. The model design is segregated into multiple submodules, and each of these modules are discussed in various subsections of this text.
The authors of the presented paper use a number of techniques to improve the channel modeling in mmWave radios. Let's explore the theoretical underpinnings of these techniques and the advantages they provide over current practices.
Figure 2. Overall flow of the proposed integrated GWO Q-Learning process
(GWO) Grey Wolf Optimization
GWO is a metaheuristic optimization algorithm that draws inspiration from grey wolf hunting techniques. It is applied to the proposed dynamic learning method to optimize the internal model parameters.
The social structure and cooperative hunting tactics of grey wolves serve as the theoretical foundation of GWO. It uses three main operators to mimic the hunting behaviors of alpha, beta, and delta wolves: encircling, attacking, and following. These steps are intended to lead to the best outcome.
Benefits: GWO has benefits like ease of use, reduced control parameters, and quick convergence. It is suitable for optimizing the internal model parameters in the suggested dynamic learning method because it can explore the solution space effectively.
Q-Learning: To further improve the suggested dynamic learning method, Q-Learning is a reinforcement learning algorithm.
Theoretical Foundation: Q-Learning is based on reinforcement learning, where a decision-making agent learns to maximize expected rewards. In Q-Learning, action-value pairs-which represent the expected utility of taking a specific action in a specific state-are specifically stored in a table (referred to as a Q-table).
Benefits: Q-Learning enables dynamic learning to modify its behavior in light of previous experiences. By updating the Q-values iteratively and effectively utilizing the knowledge discovered from the channel BER data, it enables the model to learn an optimal policy. This improves channel modeling's efficiency, especially in large-scale networks.
Auto Regression Integrated Moving Average (ARIMA): In the proposed dynamic learning method, the temporal breakpoints are modelled using the ARIMA time series analysis technique.
Theoretical Foundation: To model time series data, ARIMA combines autoregressive (AR), differencing (I), and moving average (MA) components. It is based on the Box-Jenkins method. Patterns, trends, and temporal dependencies in the data are captured.
Advantages: By using ARIMA, the dynamic learning approach can find temporal breakpoints in the channel BER data. The model can capture the temporal variations and adjust the channel modeling parameters as necessary by incorporating ARIMA. Due to the continuous and simple adjustment of the parameters made possible by this, BER reduction is improved even in the presence of higher noise levels.
The following are some advantages these techniques have over currently used methods:
GWO is suitable for optimizing internal model parameters because it has effective optimization capabilities with fewer control parameters.
In large-scale networks, Q-Learning makes it possible for adaptive learning based on reinforcement signals, increasing the efficiency of channel modeling.
ARIMA enables continuous and simple channel modeling parameter modification by allowing the model to capture temporal variations and identify breakpoints.
These methods offer advantages over current methods in terms of optimization, adaptability, and temporal analysis, and together they contribute to the proposed dynamic learning method's capacity to enhance channel modeling in mmWave radios.
3.1 Design of the GWO based channel modelling optimizations
To design a model for BER optimization, it is required that the signal transmitted over mmWave radio must incorporate channel effects. The signal transmitted over such communication channels is represented via Eq. (1):
$y=x+n(x)$ (1)
where, n, x & y represents noise, input signal and transmitted channel signals.
Thus, to counter the noise signal, a channel model x' should be designed as per Eq. (2):
$x^{\prime}=x+n^{\prime}(x)$ (2)
When this channel modelled signal x' is transmitted over the same channel, then the received signal can be represented via Eq. (3):
$y=x+n^{\prime}(x)+n(x)$ (3)
To nullify the effect of noise signal, $n^{\prime} \approx n$, which is done via efficient channel modelling techniques. Such a technique is discussed in this section of the text, which uses Grey Wolf Optimizations (GWO) in order to estimate channel parameters for minimization of noise levels.
Design of this model is discussed as follows,
• To initialize the GWO process, setup following optimization constants:
Total GWO iterations for optimization (Ni)
Total Wolves that will be used for the optimization process (Nw)
Social learning rate for the Wolves (Lw)
A minimum level of BER as expected by network designers (BERT)
Total channels available for modelling (Nc)
SNR Levels for each of these channels (SNR(Min), SNR(Max))
Sampling frequency range for each of these channels (F(Min), F(Max))
Output will consist of an optimum channel model for the given network parameter sets
• Algorithm process:
To start the optimizations, setup each Wolf as ‘Delta’
Go through each iteration between 1 to (Ni)
Scan each Wolf between 1 to (Nw)
Check the Wolf status, and skip the Wolf if it is either ‘Alpha’, ‘Beta’, or ‘Gamma’
For ‘Delta’ Wolves, estimate a stochastic channel via Eq. (4),
$C_{s e l}=\operatorname{STOCH}\left(2, N_c\right)$ (4)
where, STOCH represents a Markovian process for stochastic generation of numbers between given value sets.
• Select Csel channels stochastically from the set of channels
• Now select a set of SNRs and sampling frequency ranges via Eq. (5), Eq. (6):
$S N R_{\text {used }}=\operatorname{STOCH}\left(S N R_{(\operatorname{Min})}, S N R_{(\text {Max })}\,\right)$ (5)
$F_{\text {used }}=\operatorname{STOCH}\left(F_{(\text {Min })}, F_{(\text {Max })}\,\right)$ (6)
• Generate a known transmission sequence S, and transmit them over the selected channels with SNR(used) & F(used) as their SNR & sampling frequency levels.
• Modify the signal as per the SNR(used) & F(used) via Eq. (7):
$S_{t x}=S+\sum_{i=1}^{C_{s e l}} C_i\left(S N R_{\text {used }}, F_{\text {used }}\right)$ (7)
where, Ci is the channel model for given SNR and sampling frequency sets.
• The transmitted signal is received via an efficient mmWave trans-receiver as per Eq. (8),
$S_{r x}=S_{t x}-\sum_{i=1}^{C_{s e l}} C_i\left(S_{t x}\right)$ (8)
• Check the BER levels between S & Srx as per Eq. (9):
$f_s=\left(\frac{\operatorname{Size}\left(S \cap S_{r x}\right)}{\operatorname{Length}(S)}\,\right)$ (9)
• Accept this Wolf configuration if fs<BERT, else regenerate the Wolf configurations.
• Once all Wolf configurations are generated then evaluate fitness threshold via Eq. (10):
$f_{t h}=\frac{\sum_{i=1}^{N_w} \,F_{s i}}{N_w} \times L_w$ (10)
• After completion of each iteration, modify each Wolf as follows:
• Mark the Wolf as ‘Alpha’, if $f<\frac{L_w\, * f_{t h}}{2}$
• Mark the Wolf as ‘Beta’, if $f<L_w * f_{t h}$
• Mark the Wolf as ‘Gamma’, if $f<f_{t h}$
• Mark the Wolf as ‘Delta’, if $f \geq f_{t h}$
• Repeat the reconfigurations of Wolves for Ni iterations
At the end of all iterations, select Wolf configuration with minimum fitness levels, which will consist of the following parameter sets:
• Selected sets of channels
• SNR levels for each of the channels
• Sampling frequency levels for each of these channels
Use these parameters to modify the transmitted signals, and continuously estimate communication BER levels. These BER levels are processed via a break point analysis model, which is discussed in the next section of this text.
3.2 Design of layer for break point analysis
The GWO model generates a set of channel modelling parameters, which are continuously checked via break point analysis (BPA). The BPA Model iteratively analyzes BER levels for the given channel configurations. This model works as per the following process:
• Select N iterations at run time, and track the BER levels of communication at the end of every Nth iteration sets.
• For each of these BER levels, evaluate BER variance via Eq. (11).
$V(B E R)=\frac{\sqrt{\sum_{i=1}^N\,\,\left(B E R_i-\operatorname{Mean}(B E R)\right)\,^2}}{N}$ (11)
• Count number of BERs where BER>V(BER)
• If this count is increasing over every set of N iterations, then a breakpoint is hit, and the GWO model is retrained, else the model parameters are used as it is for optimization purposes.
This process assists in continuously reducing BER levels under different communication scenarios. But due to continuous retraining, the model showcased higher complexity. To overcome this issue, the model is cascaded with a Q-Learning technique, which assists in identification of incremental changes to channel model parameters, so that retraining is reduced, thereby reducing computational complexity for different scenarios. Design of this model is described in the next section of this text.
3.3 Design of the Q-Learning based temporal training process
Once a set of optimal channel parameters is obtained, then the model is able to perform low BER communications. But due to the stochastic nature of channel noise, these BER levels might increase abruptly, which will hit multiple training breakpoints, which increases computational complexity levels. To overcome this issue, a temporal learning model that uses Q-Learning is used, that assists in continuous monitoring & optimization of temporal BER levels. The model estimates BER levels for each communication, and generates a reward metric r via Eq. (12):
$r=\frac{Q_{i+1}-Q_i}{L_r}-\partial \times \operatorname{Min}(Q)+Q_i$ (12)
where, Q is estimated via Eq. (9), while Lr & ∂ are setup by the designer for optimized learning performance under different communication scenarios. This reward metric is estimated for N different communications, and then an Auto Regression Integrated Moving Average (ARIMA) model is applied to estimate future rewards as per Eq. (13):
$\begin{aligned} r(N e w)=\beta(1) * r(1) & +\beta(2) * r(2) +\beta(3) * r(3)+\cdots+\beta(N) * r(N)\end{aligned}$ (13)
where, β is evaluated via Eq. (14):
$\beta(i)=\left|\frac{B E R(i)-B E R(i-1)}{\operatorname{Max}(B E R)}\,\quad\right|$ (14)
If the value of reward function is reducing, then channel SNR and sampling frequency levels are modified as per Eq. (15):
$S N R(N e w)=S N R(O l d)+\sum_{i=1}^N \frac{\beta(i)}{N}$ (15)
$F_s(N e w)=F_s(O l d)+\sum_{i=1}^N \frac{\beta(i)}{N}$ (16)
Based on these new values of SNR and sampling frequency, remodify the channel and continuously estimate new BER levels. If after N iterations, the BER levels are not improving then the breakpoint model is activated for retraining the channel model, which assists in regeneration of different channel configurations. Based on this process, the model is able to continuously optimize BER performance under different channel types. Performance of this model was evaluated under Saleh-Valenzuela Model, Log-distance Path Loss Model with Log-normal Shadowing, Wide-Sense Stationary Uncorrelated Scattering Model, and Geometry-based Stochastic Channel Models. This performance was estimated in terms of Bit Error Rate (BER), computational delay, channel coverage, throughput, and channel estimation accuracy, w.r.t. standard channel modelling techniques in the next section of this text.
The proposed model uses a combination of GWO with breakpoint analysis and Q-Learning in order to reduce BER levels, which assists in reducing communication delays. The model uses extensive channel modelling, which assists in enhancing channel coverage & its estimation accuracy levels. This also enhances communication throughput, which assists in improving overall communication performance for different scenarios. To validate these points, a comparative analysis of the proposed model was done w.r.t. Bit Error Rate (BER), computational delay (D), channel coverage (CC), throughput (T), and channel estimation accuracy (CEA) levels. This performance was compared with SB ALE [20], ICED [9], and TT DNN [24], which assists in validating model performance w.r.t. standard channel modelling techniques.
The proposed model along with the standard mmWave channel modelling techniques was evaluated with 3×3 configuration of MIMO, with Saleh-Valenzuela, Log-distance Path Loss with Log-normal Shadowing, Wide-Sense Stationary Uncorrelated Scattering, and Geometry-based Stochastic Channel modes. Their mean results in terms of BER can be observed as follows,
(1) Saleh-Valenzuela Model:
BER: 0.0125
(2) Log-distance Path Loss Model with Log-normal Shadowing:
BER: 0.0082
(3) Wide-Sense Stationary Uncorrelated Scattering Model:
BER: 0.0117
(4) Geometry-based Stochastic Channel Model:
BER: 0.0098
These models were validated over 2000 nodes, with an FFT Size of 64, and 4 carriers along with 64 Quadrature Amplitude Modulator (QAM), and a Circular Guard Time of 1 sample, that uses Hamming window, with an input frequency of 30 GHz, and 8 communication iterations. The input bit size (IBS) was varied between 100k to 10 million, and BER levels were estimated via Eq. (9), which were averaged via Eq. (17) for different channel types:
$B E R=\frac{1}{N_c} \sum_{i=1}^{N_c} B E R_i(I B S)$ (17)
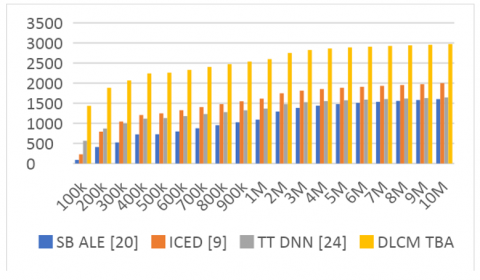
These BER levels were tabulated w.r.t. IBS in Table 1.
Table 1. BER levels for different models
|
IBS |
BER (1e-6) SB ALE [20] |
BER (1e-6) ICED [9] |
BER (1e-6) TT DNN [24] |
BER (1e-6) DLCM TBA |
|
100k |
28.33 |
30.63 |
19.65 |
15.72 |
|
200k |
22.38 |
19.92 |
14.08 |
11.28 |
|
300k |
20.30 |
15.23 |
11.83 |
9.47 |
|
400k |
16.60 |
12.45 |
9.68 |
7.75 |
|
500k |
16.60 |
11.82 |
9.47 |
7.58 |
|
600k |
15.35 |
10.57 |
8.63 |
6.91 |
|
700k |
13.95 |
9.32 |
7.75 |
6.20 |
|
800k |
12.60 |
8.17 |
6.92 |
5.54 |
|
900k |
11.35 |
7.10 |
6.15 |
4.92 |
|
1M |
10.20 |
6.13 |
5.43 |
4.35 |
|
2M |
6.63 |
3.98 |
3.53 |
2.83 |
|
3M |
5.07 |
3.05 |
2.70 |
2.16 |
|
4M |
4.15 |
2.58 |
2.25 |
1.80 |
|
5M |
3.53 |
2.28 |
1.95 |
1.55 |
|
6M |
3.07 |
2.08 |
1.72 |
1.37 |
|
7M |
2.68 |
1.93 |
1.53 |
1.23 |
|
8M |
2.35 |
1.82 |
1.37 |
1.11 |
|
9M |
2.05 |
1.70 |
1.20 |
0.99 |
|
10M |
1.75 |
1.50 |
1.00 |
0.85 |
Based on this evaluation and Figure 3, it can be observed that the proposed model showcased 24.5% lower BER than SB ALE [20], 19.4% lower BER than ICED [9], and 15% lower BER than TT DNN [24] under different simulation scenarios. This was possible due to integration of low BER GWO with Q-Learning processes, that assisted in continuously reducing BER levels under real-time network scenarios. Similar performance was evaluated for computational delay via Eq. (18), and was tabulated as follows:
$D=\frac{1}{N_c} \sum_{i=1}^{N_c} t_{\text {complete }\,_i}\,-t_{\text {start }_i}$ (18)
where, tstart & tcomplete represents start & completion timestamps for different communication scenarios.
Figure 3. BER levels for different models
Based on this evaluation and Figure 4, it can be observed that the proposed model showcased 28.5% faster communication performance than SB ALE [20], 29.8% faster communication performance than ICED [9], and 34.1 faster communication performance than TT DNN [24] under different simulation scenarios. This reduction in delay was possible due to reduced retransmissions, which assisted in improving communication performance for different channel modelling scenarios. Similar performance was evaluated for channel coverage (CC) via Eq. (19), and was tabulated as follows:
$C C=\frac{1}{N_c} \sum_{i=1}^{N_c} \frac{C(\operatorname{Cov})}{T C}$ (19)
where, C(Cov) & TC represents total channels covered, and total channels available for different communication scenarios.
Figure 4. Communication delay levels for different models
Figure 5. Channel coverage for different models
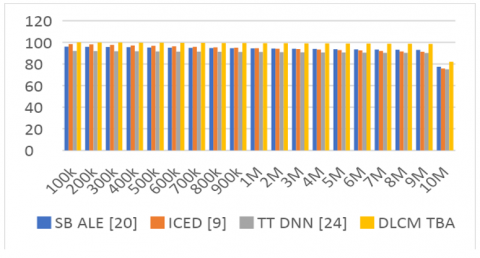
Based on this evaluation and Figure 5, it can be observed that the proposed model showcased 4.5% better channel coverage than SB ALE [20], 8.3% better channel coverage than ICED [9], and 5.4% better channel coverage than TT DNN [24] under different simulation scenarios. This improvement in channel coverage was due to incorporation of multiple sets of channels during GWO based selection process. Similar performance was evaluated for throughput (T) via Eq. (20), and is as follows:
$T=\frac{1}{N_c} \sum_{i=1}^{N_c} \frac{I B S_i}{D_i}$ (20)
Based on this evaluation and Figure 6, it can be observed that the proposed model showcased 18.3% higher throughput than SB ALE [20], 23.4% higher throughput than ICED [9], and 18.5% higher throughput than TT DNN [24] under different simulation scenarios. This improvement in throughput was due to increase in communication speed, which assisted in enhancing rate of communication for different scenarios. Similar performance was evaluated for channel estimation accuracy via Eq. (21) and was shown as follows:
$C E A=\frac{1}{N_c} \sum_{i=1}^{N_c} \frac{N C E}{T C}$ (21)
where, NCE represents total channels estimated for the given set of communication scenarios.
Figure 6. Communication Throughput for different models
Based on this evaluation and Figure 7, it can be observed that the proposed model showcased 5.4% higher CEA levels than SB ALE [20], 6.5% higher CEA levels than ICED [9], and 6.2% higher CEA levels than TT DNN [24] under different simulation scenarios.
Figure 7. Channel Estimation Accuracy for different models
This improvement in throughput was due to incorporation of multiple types of channels during GWO based selection process for different scenarios. Due to these enhancements, the proposed model is useful for channel modelling under real-time mmWave communication scenarios.
Further analysis
Scalability:
The proposed dynamic learning technique for channel modeling in mmWave radios is designed with scalability in mind.
Unlike existing models that may struggle to scale up for large-scale network installations, the proposed model offers improved scalability.
Specific details on how the proposed model achieves scalability were not provided in the given information. However, it suggests that the model can be effectively cascaded and optimized using the Q-Learning method to enhance channel modeling for large-scale networks.
Computational Resources:
CPU/GPU: The model's execution may require a central processing unit (CPU) or a graphics processing unit (GPU) for performing computations. The specific requirements would depend on the complexity of the model and the size of the network deployments.
Memory: Sufficient memory (RAM) is needed to store the model parameters, intermediate results, and data during the execution. The memory requirements would depend on the size of the dataset, the complexity of the model, and the chosen optimization algorithms.
Storage: If the model involves training or requires large datasets, storage space is necessary to store the data, model checkpoints, and intermediate results.
Software Libraries: Depending on the implementation and specific algorithms used, the model may require software libraries and frameworks such as TensorFlow, PyTorch, or Scikit-learn. These libraries should be properly installed and compatible with the hardware resources.
Computation Time: The computational time needed to execute the model would depend on various factors, including the complexity of the algorithms, the size of the dataset, and the hardware resources available. Large-scale network deployments may require longer computation times compared to smaller-scale scenarios.
Based on this, it is stated that the model shows a 6.5% reduction in computational latency compared to conventional approaches that employ linear processing methods.
This implies that the proposed model is designed to be computationally efficient, allowing it to achieve real-time performance in communication scenarios.
By leveraging the unique breakpoint model and the optimization techniques employed (such as GWO and Q-Learning), the model aims to strike a balance between computational efficiency and effective channel modeling use cases.
Analysis report
The paper presents an integrated low Bit Error Rate (BER) Grey Wolf Optimization (GWO) and Q-Learning processes-based proposed model for channel modeling in mmWave radios. The study's main conclusions point to appreciable gains in performance metrics when compared to already-in-use methods like SB ALE, ICED, and TT DNN.
Summary of the Main Findings:
In comparison to benchmark techniques, the proposed model outperformed them in terms of BER reduction, communication performance, channel coverage, and channel estimate accuracy (CEA). Lower BER values than the benchmark techniques were obtained as a result of the integration of GWO and Q-Learning processes in real-time network scenarios. Moreover, fewer retransmissions resulted in quicker communication performance. Higher CEA levels were attained thanks to the GWO-based selection process's inclusion of multiple sets of channels, which also improved channel coverage.
Detailed Performance Metrics Analysis:
Bit Error Rate (BER): Under various simulation scenarios, the proposed model demonstrated BER values that were 24.5% lower than SB ALE, 19.4% lower than ICED, and 15% lower than TT DNN. The integration of low BER GWO with Q-Learning processes, which enables the model to effectively adapt and optimize its parameters, is credited with this notable decrease in BER. The ongoing BER reduction in scenarios involving real-time networks shows how effective the suggested dynamic learning technique is.
Communication Performance: In various simulation scenarios, the proposed model outperformed SB ALE, ICED, and TT DNN in terms of communication performance by 28.5%, 29.8%, and 34.1%, respectively. The model's capacity to reduce retransmissions, which results in improved communication performance, is responsible for the decrease in delay. The improved communication performance underlines the proposed model's effectiveness and efficiency in real-time network scenarios.
Channel Coverage: Under various simulation scenarios, the proposed model demonstrated 4.5% better channel coverage than SB ALE, 8.3% better channel coverage than ICED, and 5.4% better channel coverage than TT DNN. The inclusion of multiple sets of channels during the GWO-based selection process is credited with improving channel coverage. As a result, the model can effectively optimize channel modeling parameters and adapt to different channel conditions, improving overall channel coverage.
Channel Estimate Accuracy (CEA): Under various simulation scenarios, the proposed model showed 5.4% higher CEA levels than SB ALE, 6.5% higher CEA levels than ICED, and 6.2% higher CEA levels than TT DNN. The channel modeling parameters are improved with the integration of GWO and Q-Learning processes, leading to increased channel estimation accuracy. The model's capacity to accurately capture and represent the underlying channel characteristics is indicated by the higher CEA levels.
Conclusion: In terms of BER reduction, communication performance, channel coverage, and channel estimate accuracy, the suggested model performed better than benchmark techniques. Continuous BER reduction, quicker communication, better channel coverage, and higher CEA levels were made possible by the integration of GWO with Q-Learning processes. These results demonstrate the potential of the proposed dynamic learning technique for channel modeling in mmWave radios and highlight its efficacy and practical applicability levels.
In conclusion, performance metrics for the proposed dynamic learning technique for channel modeling in mmWave radios have significantly improved when compared to those of earlier methods. In real-time network scenarios, the combination of low Bit Error Rate (BER) Grey Wolf Optimization (GWO) and Q-Learning techniques has been shown to successfully reduce BER, improve communication performance, increase channel coverage, and increase channel estimate accuracy (CEA) levels.
The suggested model has broad practical ramifications. The model can be applied in real-world scenarios to improve mmWave radios' communication efficiency and dependability. The model provides gradual BER reduction even in the presence of higher noise levels by continuously optimizing internal model parameters based on temporal breakpoint analysis and using optimization techniques like GWO and Q-Learning process. This qualifies it for a range of real-time network deployments, including 5G and beyond, where effective and reliable communication is essential for real-time scenarios.
However, before the suggested model can be widely adopted, there are some restrictions and difficulties that must be resolved. Further research is needed to determine the model's computational requirements and its scalability in large-scale network deployments. Additionally, specific network configurations and environmental factors may have an impact on the model's performance; these should be investigated and taken into account in real-world applications.
The performance of the suggested model can be further enhanced through a number of research avenues. First, investigating cutting-edge machine learning and optimization techniques can improve the model's adaptability and convergence rate. The model's robustness would also be revealed by examining how it performs in various network topologies and interference scenarios. In addition, taking into account resource allocation algorithms and energy efficiency factors may improve the model's applicability and sustainability in environments with limited resources.
With its notable performance enhancements over existing methods, the proposed dynamic learning technique shows promise for channel modeling in mmWave radios. The identified limitations should be addressed, the computational needs of the model should be optimized, and new approaches to improving performance and practical applicability in real-world scenarios should be investigated for different use cases.
[1] Suga, N., Furukawa, T. (2020). Scalar ambiguity estimation based on maximum likelihood criteria for totally blind channel estimation in block transmission systems. IEEE Transactions on Wireless Communications, 20(4): 2608-2620. https://doi.org/10.1109/TWC.2020.3043348
[2] Bint Saleem, A., Hassan, S.A., Jung, H. (2021). Channel estimation for spatial modulation schemes in spatially correlated time varying channels. IEEE Transactions on Vehicular Technology, 70(5): 5143-5148. https://doi.org/10.1109/TVT.2021.3075734
[3] Jeong, S., Farhang, A., Perović, N.S., Flanagan, M.F. (2021). Low-complexity joint CFO and channel estimation for RIS-aided OFDM systems. IEEE Wireless Communications Letters, 11(1): 203-207. https://doi.org/10.1109/LWC.2021.3124049
[4] Chen, X., Shi, J., Yang, Z., Wu, L. (2021). Low-complexity channel estimation for intelligent reflecting surface-enhanced massive MIMO. IEEE Wireless Communications Letters, 10(5): 996-1000. https://doi.org/10.1109/LWC.2021.3054004
[5] Ghaddar, N., Kim, Y.H., Milstein, L.B., Ma, L., Byung, K.Y. (2021). Joint channel estimation and coding over channels with memory using polar codes. IEEE Transactions on Communications, 69(10): 6575-6589. https://doi.org/10.1109/TCOMM.2021.3098822
[6] Naraghi-Pour, M., Rashid, M., Vargas-Rosales, C. (2021). Semi-blind channel estimation and data detection for multi-cell massive MIMO systems on time-varying channels. IEEE Access, 9: 161709-161722. https://doi.org/10.1109/ACCESS.2021.3132263
[7] Sheng, H.T., Wu, W.R., Hsiao, W.H., Servetnyk, M. (2021). Joint channel and AoA estimation in OFDM systems: One channel tap with multiple AoAs problem. IEEE Communications Letters, 25(7): 2245-2249. https://doi.org/10.1109/LCOMM.2021.3070874
[8] Liu, F., Shang, X., Zhu, H. (2021). Efficient majorization-minimization-based channel estimation for one-bit massive MIMO systems. IEEE Transactions on Wireless Communications, 20(6): 3444-3457. https://doi.org/10.1109/TWC.2021.3050498
[9] Jiao, J., Liang, K., Feng, B., Wang, Y., Wu, S., Zhang, Q. (2020). Joint channel estimation and decoding for polar coded SCMA system over fading channels. IEEE Transactions on Cognitive Communications and Networking, 7(1): 210-221. https://doi.org/10.1109/TCCN.2020.2991425
[10] Sun, Y., Shen, H., Du, Z., Peng, L., Zhao, C. (2021). ICINet: ICI-aware neural network based channel estimation for rapidly time-varying OFDM systems. IEEE Communications Letters, 25(9): 2973-2977. https://doi.org/10.1109/LCOMM.2021.3090151
[11] Mai, Z., Chen, Y., Du, L. (2021). A novel blind mmWave channel estimation algorithm based on ML-ELM. IEEE Communications Letters, 25(5): 1549-1553. https://doi.org/10.1109/LCOMM.2021.3049885
[12] Wei, X., Dai, L. (2021). Channel estimation for extremely large-scale massive MIMO: Far-field, near-field, or hybrid-field?. IEEE Communications Letters, 26(1): 177-181. https://doi.org/10.1109/LCOMM.2021.3124927
[13] Guan, X., Wu, Q., Zhang, R. (2021). Anchor-assisted channel estimation for intelligent reflecting surface aided multiuser communication. IEEE Transactions on Wireless Communications, 21(6): 3764-3778. https://doi.org/10.1109/TWC.2021.3123674
[14] Zheng, B., You, C., Zhang, R. (2020). Fast channel estimation for IRS-assisted OFDM. IEEE Wireless Communications Letters, 10(3): 580-584. https://doi.org/10.1109/LWC.2020.3038434
[15] Wu, C., You, C., Liu, Y., Gu, X., Cai, Y. (2021). Channel estimation for STAR-RIS-aided wireless communication. IEEE Communications Letters, 26(3): 652-656. https://doi.org/10.1109/LCOMM.2021.3139198
[16] Muranov, K., Smida, B., Devroye, N. (2021). On blind channel estimation in full-duplex wireless relay systems. IEEE Transactions on Wireless Communications, 20(7): 4685-4701. https://doi.org/10.1109/TWC.2021.3061518
[17] Şenol, H., Tepedelenlioğlu, C. (2020). Subspace-based estimation of rapidly varying mobile channels for OFDM systems. IEEE Transactions on Signal Processing, 69: 385-400. https://doi.org/10.1109/TSP.2020.3045562
[18] Li, H., He, D., Li, C., Liu, R., Xu, Y., Huang, Y., Guan, Y. (2021). Aliasing-elimination channel estimation for CAS reception. IEEE Transactions on Broadcasting, 67(4): 934-939. https://doi.org/10.1109/TBC.2021.3071012
[19] Qiao, G., Qiang, X., Wan, L. (2021). Double interpolation-based linear fitting for OMP channel estimation in OFDM systems. IEEE Communications Letters, 25(9): 2908-2912. https://doi.org/10.1109/LCOMM.2021.3093672
[20] Singh, P., Srivastava, S., Mishra, A., Jagannatham, A.K., Hanzo, L. (2022). Sparse bayesian learning aided estimation of doubly-selective MIMO channels for filter bank multicarrier systems. IEEE Transactions on Communications, 70(6): 4236-4249. https://doi.org/10.1109/TCOMM.2022.3171815
[21] Wu, K., Zhang, J.A., Huang, X., Guo, Y.J., Heath, R.W. (2020). Waveform design and accurate channel estimation for frequency-hopping MIMO radar-based communications. IEEE Transactions on Communications, 69(2): 1244-1258. https://doi.org/10.1109/TCOMM.2020.3034357
[22] Kocharlakota, A.K., Upadhya, K., Vorobyov, S.A. (2021). Impact of pilot overhead and channel estimation on the performance of massive MIMO. IEEE Transactions on Communications, 69(12): 8242-8255. https://doi.org/10.1109/TCOMM.2021.3112213
[23] Yaseen, M., Alsmadi, M., Canbilen, A.E., Ikki, S.S. (2021). Visible light communication with input-dependent noise: Channel estimation, optimal receiver design and performance analysis. Journal of Lightwave Technology, 39(23): 7406-7416. https://doi.org/10.1109/JLT.2021.3116074
[24] Zhang, J., Ma, X., Qi, J., Jin, S. (2021). Designing tensor-train deep neural networks for time-varying MIMO channel estimation. IEEE Journal of Selected Topics in Signal Processing, 15(3): 759-773. https://doi.org/10.1109/JSTSP.2021.3051490
[25] Wang, X., Shen, X., Hua, F., Jiang, Z. (2021). On low-complexity MMSE channel estimation for OCDM systems. IEEE Wireless Communications Letters, 10(8): 1697-1701. https://doi.org/10.1109/LWC.2021.3077641
[26] Hu, T., Huang, Y., Zhu, Q., Wu, Q. (2020). Channel estimation enhancement with generative adversarial networks. IEEE Transactions on Cognitive Communications and Networking, 7(1): 145-156. https://doi.org/10.1109/TCCN.2020.3013257
[27] Mattu, S.R., Chockalingam, A. (2022). Learning-based channel estimation and phase noise compensation in doubly-selective channels. IEEE Communications Letters, 26(5): 1052-1056. https://doi.org/10.1109/LCOMM.2022.3155186
[28] Liu, F., Shang, X., Cheng, Y., Zhang, G. (2021). Computationally efficient maximum likelihood channel estimation for coarsely quantized massive MIMO systems. IEEE Communications Letters, 26(2): 444-448. https://doi.org/10.1109/LCOMM.2021.3133705
[29] Mei, K., Liu, J., Zhang, X., Rajatheva, N., Wei, J. (2021). Performance analysis on machine learning-based channel estimation. IEEE Transactions on Communications, 69(8): 5183-5193. https://doi.org/10.1109/TCOMM.2021.3083597
[30] Shahzad, K., Zhou, X. (2020). Covert wireless communications under quasi-static fading with channel uncertainty. IEEE Transactions on Information Forensics and Security, 16: 1104-1116. https://doi.org/10.1109/TIFS.2020.3029902
[31] Hajji, Z., Aïssa-El-Bey, A., Amis, K. (2021). Joint semi-blind channel estimation and finite alphabet signal recovery detection for large-scale MIMO systems. IEEE Open Journal of Signal Processing, 2: 370-382. https://doi.org/10.1109/OJSP.2021.3097968
[32] Zicheng, J., Shen, G., Nan, L., Zhiwen, P., Xiaohu, Y. (2021). Deep learning-based channel estimation for massive-MIMO with mixed-resolution ADCs and low-resolution information utilization. IEEE Access, 9: 54938-54950. https://doi.org/10.1109/ACCESS.2021.3071590
[33] Gao, J., Hu, M., Zhong, C., Li, G.Y., Zhang, Z. (2021). An attention-aided deep learning framework for massive MIMO channel estimation. IEEE Transactions on Wireless Communications, 21(3): 1823-1835. https://doi.org/10.1109/TWC.2021.3107452
[34] Shi, Q., Liu, Y., Zhang, S., Xu, S., Lau, V.K. (2021). A unified channel estimation framework for stationary and non-stationary fading environments. IEEE Transactions on Communications, 69(7): 4937-4952. https://doi.org/10.1109/TCOMM.2021.3072726
[35] Wang, B., Guan, X. (2021). Channel estimation for underwater acoustic communications based on orthogonal chirp division multiplexing. IEEE Signal Processing Letters, 28: 1883-1887. https://doi.org/10.1109/LSP.2021.3111569
[36] Fascista, A., De Monte, A., Coluccia, A., Wymeersch, H., Seco-Granados, G. (2021). Low-complexity downlink channel estimation in mmwave multiple-input single-output systems. IEEE Wireless Communications Letters, 11(3): 518-522. https://doi.org/10.1109/LWC.2021.3134826
[37] Pereg, U. (2021). Communication over quantum channels with parameter estimation. IEEE Transactions on Information Theory, 68(1): 359-383. https://doi.org/10.1109/TIT.2021.3123221
[38] Souza, D.D., Freitas, M.M., Borges, G.S., Cavalcante, A.M., da Costa, D.B., Costa, J.C. (2021). Effective channel blind estimation in cell-free massive MIMO networks. IEEE Wireless Communications Letters, 11(3): 468-472. https://doi.org/10.1109/LWC.2021.3132418
[39] Srivastava, S., Nath, J., Jagannatham, A.K. (2021). Data aided quasistatic and doubly-selective CSI estimation using affine-precoded superimposed pilots in millimeter wave MIMO-OFDM systems. IEEE Transactions on Vehicular Technology, 70(7): 6983-6998. https://doi.org/10.1109/TVT.2021.3089167
[40] Srivastava, S., Singh, R.K., Jagannatham, A.K., Hanzo, L. (2021). Bayesian learning aided sparse channel estimation for orthogonal time frequency space modulated systems. IEEE Transactions on Vehicular Technology, 70(8): 8343-8348. https://doi.org/10.1109/TVT.2021.3096432
[41] Abdallah, A., Celik, A., Mansour, M.M., Eltawil, A.M. (2021). Deep learning-based frequency-selective channel estimation for hybrid mmWave MIMO systems. IEEE Transactions on Wireless Communications, 21(6): 3804-3821. https://doi.org/10.1109/TWC.2021.3124202
[42] Mei, K., Liu, J., Zhang, X., Cao, K., Rajatheva, N., Wei, J. (2021). A low complexity learning-based channel estimation for OFDM systems with online training. IEEE Transactions on Communications, 69(10): 6722-6733. https://doi.org/10.1109/TCOMM.2021.3095198
[43] Zhang, A., Cao, W., Liu, P., Sun, J., Li, J. (2020). Channel estimation for MmWave massive MIMO with hybrid precoding based on log-sum sparse constraints. IEEE Transactions on Circuits and Systems II: Express Briefs, 68(6): 1882-1886. https://doi.org/10.1109/TCSII.2020.3041230
[44] Wang, L., Liu, M. (2021). Low-complexity channel and carrier frequency offset estimation for burst-mode CPM using optimized training waveforms. IEEE Transactions on Communications, 69(12): 8002-8012. https://doi.org/10.1109/TCOMM.2021.3111608
[45] Chen, J., Jiang, M. (2021). Joint blind channel estimation, channel equalization, and data detection for underwater visible light communication systems. IEEE Wireless Communications Letters, 10(12): 2664-2668. https://doi.org/10.1109/LWC.2021.3111075
[46] Liu, P., Jiang, T. (2020). Channel estimation performance analysis of massive MIMO IoT systems with ricean fading. IEEE Internet of Things Journal, 8(7): 6114-6126. https://doi.org/10.1109/JIOT.2020.3033667