Ashraf Rafa Mohmed*![]() | Yüksel Çelik
| Yüksel Çelik![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Medical image classification is an increasingly important area of research, with the need to represent images computationally often posing significant challenges due to the large amounts of data and processing power required. A new approach for image classification in the healthcare domain has been developed in this study, called ASPS_HC, which seeks to obtain higher discrimination among different classes by identifying the most impactful features within the data's Upper and Lower Limit outlier regions. This is achieved through the use of various statistical measures, including the Coefficient of Variance (CV), to create 48 features that represent each image. An experiment was conducted on a dataset of 5,540 diabetic retinopathy images in the Gaussian formula, acquired from Kaggle. The proposed ASPS_HC approach yielded three main advantages over the previous ASPS method for feature extraction: the average rank of the features was increased by 200%, the run time was reduced by 23.30%, and the number of features required was decreased by 50%. As a result, the features extracted using ASPS_HC produced significantly higher accuracy in both the Artificial Neural Network and Random Forest models, with an increase of 1.91% for the former and 1.36% for the latter.
ASPS approach, classification medical images, diabetic retinopathy, features extraction, features selection, healthcare
Artificial intelligence and machine learning have revolutionized digital image analysis, improved accuracy and expanding applicability to a wide range of tasks. In particular, these methods have helped provide insights for decision-making in computer vision, storage, and image analysis technologies.
The primary goal of ML is to enable computers to learn without human assistance, and it is categorized into three approaches: supervised, unsupervised, and semi-supervised learning, along with application studies [1]. One prominent application of ML is computer-assisted intelligent diagnosis, which aims to reduce the number of features required for accurate image classification. However, most rating software relies on many features, which can be costly in terms of equipment and specifications.
Extracting the best features for classifying medical images is challenging due to their complex, effective characteristics [2]. In recent years, deep learning has become a crucial research area in computer science and applications. As a result, researchers have attempted to apply these developments to medical images, including non-medical images, for diagnostic purposes. Nonetheless, algorithms still require human input, output, and feedback on prediction accuracy during the training process.
Medical imaging data is a common source of information about patients, but it can also be complex. Therefore, innovative models with increased accuracy and fewer characteristics are required to obtain optimal results. This is essential for early disease detection, which can reduce treatment costs and increase the chance of full recovery. Additionally, multiple sources of images are necessary, which may differ in focus area, contrast, and white balance. Medical images often have internal structures of different textures and pixel densities, as exemplified by retinal diseases in this case and study.
Diabetes is a significant public health problem that affects 463 million people globally, and this number is expected to rise to 700 million by 2045. Diabetic retinopathy (DR) is an eye disease caused by diabetes, with progression being its hallmark. Chronic hyperglycemia can cause abnormalities in the blood vessels in the retina, which can affect any person with diabetes. DR is the leading cause of obesity among working adults worldwide, affecting an estimated 93 million individuals worldwide [1]. These numbers are expected to rise further, mainly due to the increased prevalence of polygenic diseases in emerging Asian countries and China [2].
The extraction of relevant information from fundus imaging is essential for assessing the correct arrangement and understanding of the knowledge processes required for trait extraction and classification tasks [3, 4]. Several feature extraction methods, including time-domain, frequency-domain, and wave features of dependent transformation (WT), have been reported for DR. Advances in biomedical imaging with signal processing and ML algorithms have made it easier to predict DR.
Pre-processing techniques and morphological processes, such as image histogram analysis, contribute to the detection of statistical features. Discrete wavelet transform (DWT) is used to extract dependent or exact features of an image on the histogram, which are then categorized using a machine learning approach (e.g., SVM, artificial neural network) to predict DR accurately and efficiently following a cross-validation approach. Specific machine learning algorithms are used to train feature understanding, such as SVM and CNN [2].
The goal of this study is to investigate the quality of detection in individuals with acquired retinal diseases and develop disease-specific patient-reported outcome instruments with a limited number of features that can involve the most significant and hidden attributes of each object within the dataset to conduct classification more efficiently and accurately. To achieve this, a retinal diseases classification detection technique is presented that utilizes a novel version of ASPS called Automated Sensor and Signal Processing Selection Approach Health care (ASPS_HC). ASPS_HC is adapted from the original Automated Sensory and Signal Processing System (ASPS) approach, which is a systemic method to extract the most valuable features used later in the ML to build the required artificial neural network [4]. The ASPS_HC approach is applied for the first time in extracting features from medical images, having previously been used only in the engineering field.
Several extensive research studies have been conducted on automated methods for detecting diabetic retinopathy and retinopathy, with promising results. A hybrid model based on ANN and SVM was employed to classify DR, resulting in a sensitivity and specificity of 88.4% and 83.5%, respectively. To achieve this, a small set of approximately 200 images was used in this study, and each image was fragmented. The clinician was then asked to classify the feature corrections before SVM implementation.
Artificial neural networks were used in the study of Nayak et al. [5] to classify three classes of diabetic retinopathy (DR). The proposed scheme [5] incorporates exudate, vascular, and tissue parameters as input features in the artificial neural network for classification. The features are categorized into three types: typical, non-proliferative, and proliferative retinopathy. To validate the detection results, they were compared with scores from expert ophthalmologists. The classification accuracy of the proposed method was found to be 93%, with a sensitivity of 90% and a specificity of 100%. However, feature extraction on a dataset of 140 images was required for all images in training and testing, which added to the overall complexity of the method.
In the study of Acharya et al. [6], an automated approach was proposed to classify five classes of diabetic retinopathy, utilizing a SVM. The SVM approach achieved an average accuracy of 82%, a sensitivity of 82%, and a specificity of 88%. The model used feature regions to generate a five-group classification, which was obtained from raw images through image processing and then fed into the SVM. This method achieved a sensitivity of 82%, a specificity of 86%, and an accuracy of 85.9%. However, the feature extraction process applied to two systems created by the authors in the study of Nayak et al. [5] and Archarya et al. [7] on a dataset of images before feeding into the SVM classifier can be time-consuming. Moreover, since these models were implemented on relatively small images, the decrease in sensitivity and specificity may be due to the complex nature of the five classes [8].
To address the challenges in previous models in the study of Nayak et al. [5], Acharya et al. [6], Archarya et al. [7], Pratt et al. [8] and Gardner et al. [9] presented a CNN model for five-class classification of diabetic retinopathy from digital fundus images. The classification of the classes corresponds to five levels of diabetic retinopathy and is categorized by intensity precision. The CNN model does not require feature extraction as an earlier stage, as in artificial neural networks or SVM. In addition, the CNN model is trained by a large dataset of 80,000 benthic images, achieving 95% sensitivity and 75% accuracy when validating 5000 images. However, one limitation of this model is the need to improve accuracy and select the best method, model, and parameters for the CNN architecture.
Furthermore, in Saeedi et al. [1], the authors proposed a CNN architecture for automatic diagnosis of diabetic retinopathy (DR). The image preprocessing involved resizing the images to a uniform size and converting them to grayscale. The network was then fed with these images to identify whether the patient had diabetes or not. The dataset used in the experiments consisted of 30 high-resolution fundus images of the retina, classified into two categories: 15 images marked as healthy and 15 marked as diabetic. The results showed that 22 of 24 images were correctly classified, with two misclassified images, achieving a training accuracy of 91.67%. Moreover, the validation accuracy was 100%, indicating that all six images were classified correctly. The sensitivity/recall and precision for each class were both 100%. However, this scheme was performed on a relatively small dataset and only used to classify images into two classes. Therefore, generalizing the results may lead to inaccurate classification when used for the classification of more than two classes due to the complex nature of the multi-class task.
In the study of Chakrabarty [10], Samanta et al. [11], a CNN architecture employing the DenseNet model was used on color fundus photography. The performance of the model was evaluated on a relatively small dataset consisting of 3050 training images and 419 validation images. The model performed well in recognizing diabetic retinopathy classes falling between hard exudate, vascular, and texture. This indicator shows that the model can learn well with real-time applications on devices with limited computing power. However, the model was trained on images classified into only four categories: no-DR, light-DR, moderate DR, and proliferative DR, and the experiment outcomes demonstrated a validation accuracy of 84.10%. Nonetheless, the CNN architecture employing the DenseNet model was only verified on data classified into four classes with a small dataset, and the accuracy was not as high as the results in the study of Saeedi et al. [1].
Another CNN architecture was developed using a hybrid optimization algorithm to classify diabetic retinopathy based on extracted features using a principal-component-analysis-based deep neural network [2]. The new hybrid scheme used the Grey Wolf Optimization algorithm (GWO) to optimize the parameters for training the CNN architecture. The process started with employing a standard scaler normalization method to standardize the dataset, which included removing outliers, transforming, and normalizing the data. Then, PCA was applied for dimensionality reduction, followed by GWO to choose the optimal hyperparameters. Finally, the CNN architecture model was trained using the dataset consisting of 1151 images with 20 attributes [12]. In the study of Amin et al. [2], the researchers conducted a comparative analysis between their model and other machine learning algorithms. The results showed that the proposed scheme outperformed other machine learning algorithms that participated in the experiments, with an accuracy, precision, recall, sensitivity, and specificity of 97.3%, 96.5%, 97%, 91%, and 97%, respectively. However, the small dataset of 1151 images may not accurately indicate the scheme's performance. Additionally, the model may not work well with real-time applications on machines with limited computing power due to multitasks applied in this scheme.
To achieve the best AI diagnosis of diabetic retinal disease, it is necessary to investigate the impact of different ethnic and image differences on the determination of DR using automated screening algorithms. However, few previous studies have evaluated the effect of different ethnic and picture differences in determining DR, such as Saleh et al. [13].
Saleh et al. [13] proposed a new mechanism for testing the retina through digital fundus images to detect DR. They conducted a comprehensive and controlled retrospective study based on images, assessing 17850 digital fundus photographs of patients from six countries for DR through an automated system and human grading. The system's performance was compared across digital fundus images from all countries/ethnic groups, and the sensitivities for detecting DR by the automated system were found to be Kenya 92.8%, Botswana 90.1%, Norway 93.5%, Mongolia 91.3%, China 91.9%, and the United Kingdom 90.1%. The specificities were Kenya 82.7%, Botswana 83.2%, Norway 81.3%, Mongolia 82.5%, China 83.0%, and the United Kingdom 79%. Although there was a slight variation in the sensitivities and specificities calculated across the six countries contributing to the study, the results showed a promising potential for the automated system to detect DR in various ethnic groups.
More recently, in the study of Al-Turk et al. [14], the possibility of a DR classification system based on AI features that are not limited to a classification scheme was demonstrated. The system was evaluated with images rated according to two different classification systems: the International Clinical Diabetes Mellitus Macular Edema Severity Scale and the UK National Screening Group Guidelines. An external evaluation of the data sets collected was performed for three countries [13]. At the reference DR level, there was no significant sensitivity difference between the different DR score plots (91.2-94.2.0%), and there were excellent values above 93% in all images. Many studies have been published that classify diabetic retinal images, using both traditional machine learning and deep learning classification algorithms. In the literature, time, frequency dependence, and wave-dependent feature extraction techniques have been reported when classifying EEG signals [2].
The ASPS approach is an engineering optimization method that uses image processing and signal processing to build a cost-effective and efficient system. This approach has been applied in various engineering domains to solve problems and overcome challenges. However, in healthcare, classifying images can be challenging due to the small differentiation between different classes. Therefore, it is necessary to extract specific and distinct features to distinguish between classes. The ASPS method was chosen as it converts the image into six formats, including grayscale, binary scale, and applying Fast Fourier Transform and Discrete Wavelet Transform on both grayscale and binary scale. This leads to the extraction of features from six different formats, helping to extract hidden features and strengthen weak features.
To better understand the ASPS approach, the general idea can be summarized as follows:
(1) The image is read in RGB matrix.
(2) Image processing techniques are applied.
(3) The image is converted into grayscale and binary scale vectors.
(4) Fast Fourier Transform and Discrete Wavelet Transform are applied on grayscale to obtain cA1 and cD1 vectors, respectively.
(5) Fast Fourier Transform and Discrete Wavelet Transform are applied on binary scale to obtain cA2 and cD2 vectors.
(6) Sixteen features are extracted for each matrix (GS, BS, cA1, cD1, cA2, and cD2).
(7) Feature selection is applied.
(8) The model is built using an Artificial Neural Network.
Overall, the ASPS approach is a powerful tool that can help to extract features from images, particularly in the healthcare field, where accurate classification is crucial (Figure 1).
Figure 1. Hybridization of ASPS with ANN
3.1 Enhancement of the ASPS approach
In this study, an improvement was made to the ASPS approach by adapting it to build a healthcare model, which, to the authors' knowledge, is the first time it has been used in the healthcare domain. Traditional supervised learning for healthcare image classification requires minimum and robust features that can provide high performance and efficiency. The differentiation of medical images of diseases mainly depends on the contrast and concentration of colors. Therefore, the region of the disease will most likely be contained in both edge sides of the data distribution (less than Q1 and higher than Q3). The alternative value of Upper Limit Outlier (ULO) and Lower Limit Outlier (LLO) was used to determine the appropriate level of outliers according to the nature of the data distribution [15]. Although outlier values cannot be computed according to statistical laws in the data extracted from images, especially in medical images, outliers can be considered distributed in the first and fourth quartiles (bottom edge sides of data distribution). Figure 2 illustrates the parameters used to calculate outlier values. Q1 represents the lower quartile (25%), and Q3 is the upper quartile (75%). The Interquartile range (IQR) represents the data between Q1 and Q3 and can be calculated as follows:
$\mathrm{IQR}=(\mathrm{Q} 1+\mathrm{Q} 2) / 2$ (1)
The Upper and Lower Limit Outlier can be calculated using Eq. (1) and Eq. (2), respectively:
$\mathrm{ULO}=\mathrm{Q} 3+(1.5 * \mathrm{IQR})$ (2)
$\mathrm{LLO}=\mathrm{Q} 1-(1.5 * \mathrm{IQR})$ (3)
To simulate LLO and ULO, Q1 and Q3 are modified by adjusting the percentage to the range of 15% to 85%, which primarily includes values that may contain the disease. This is done instead of using the standard range of 25% to 75%.
Figure 2. The parameters of outlier
3.2 The proposed approach
The proposed approach is essentially the same as the Automated Sensory and Signal Processing Selection System (ASPS), with the exception of the sixth step, where eight features are extracted from each matrix instead of 16. Five of the features are calculated from the entire dataset, while the remaining three are calculated on both edge sides. In medical images, the differentiation between classes mainly depends on the contrast of the concentration of color, whereas in other domains, it may depend on image shape. The features calculated for all matrices are: (1) Variance (V), (2) Interquartile range (IQR), (3) Mean (µ)1, (4) Standard Deviation (c)1, and (5) Coefficient of Variation (CV)1. The remaining three features, (6) Mean (µ)2, (7) Standard Deviation ($\boldsymbol{\sigma}$)2, and (8) Coefficient of Variation (CV)2, are calculated in the ULO and LLO ranges. Some of these coefficients are well-known, while others require further explanation. For instance, the variance of a set of numbers is the distance between each value and the mean, and hence between each other, and is equal to the square of the standard deviation. The Coefficient of Variation (CV) is a scale that quantifies relative dispersion and is used to assess the relative dispersion and homogeneity of various datasets. It can be calculated using the following equation:
$\mathrm{CV}=\sigma / \mu * 100$ (4)
Figure 3 illustrates the additions made to the ASPS approach to achieve improvement. In each generated matrix, five features from the ASPS approach are retained, and three additional features, namely (μ)2, (σ)2, and (CV)2, are added.
Figure 3. Feature extraction using the ASPS_HC approach
3.3 Feature analysis of medical and non-medical images
Figure 4. Comparison of Features Extracted using ASPS and ASPS_HC using ANOVA
One-Way ANOVA was used to investigate the distribution in the given dataset [15]. Figure 4 shows the differences in discrimination between the features extracted using ASPS_HC and ASPS for non-medical and medical images. In the first row, shapes (a) and (b) show the ANOVA representation, respectively, using ASPS_HC and ASPS of pigeon and wolf images, where the differentiation is significant and precise within the non-medical images. In contrast, in the second row, the discrimination within shape (c) is greater than the discrimination in shape (d). ASPS_HC can extract discriminative features between uninfected and infected medical images, which makes classification easier.
3.4 Analysis of ASPS_HC
This work achieved three main goals:
(1) Using the ASPS approach in the healthcare domain for the first time.
(2) Applying two criteria for enhancement, including the statistical measure of the Coefficient of Variation (CV) and three features calculated in the outlier's region, namely μ, σ, and CV.
(3) Using ANOVA to compare the features produced from the ASPS and ASPS_HC approaches in terms of their efficiency in building models.
3.5 Mathematical formulas
Let Img be a medical image matrix with a size of (nxnx3), where n represents the resolution of the image. When the image is divided into its primary components, three rank matrices Rimg, Gimg and Bimg with a size of (nxn) are produced, representing the colors red, green, and blue, respectively. Let P be the number of elements in each of these matrices, while 3*p is the total number of elements in Img. Img belongs to R^(n.n.3), while Rimg, Gimg, and Bimg belong to R^(n.n). Each matrix is divided according to the Median, resulting in two extra matrices derived from each one.
Img $_{\text {up }}$, Img $_{d n}$, Rimg $_{u p}$, Rimg $_{d n}$, Gimg $_{u p}$, Gimg $_{d n}$, Bimg $_{u p}$, Bimg $_{d n}$
Three measures are calculated for the original matrix Img as follows:
$\begin{aligned} & \mu_{(\operatorname{Img})}=\left(\frac{1}{3 \mathbf{p}}\right) \sum_{p=1}^p \operatorname{Img}(3 p) \\ & \sigma_{(\operatorname{Img})}=\left(\frac{1}{3 \mathbf{p}}\right) \sum_{p=1}^p\left(\operatorname{Img}(3 \mathbf{p})-\mu_{(\operatorname{Img})}\right)^2 \\ & C V_{(I m g)}=\frac{\sigma_{(\mathrm{Img})}}{\mu_{(\mathrm{Img})}} \\ & \end{aligned}$
The following equations are used to find the tree features of Img up
$\begin{aligned} & \mu_{\left(\operatorname{Img}_{u p}\right)}=\left(\frac{1}{\mathbf{p}}\right) \sum_{p=1}^p \operatorname{Img}_{\text {up }}(p) \\ & \sigma_{\left(\operatorname{Img}_{\text {up }}\right)}=\left(\frac{1}{\mathbf{p}}\right) \sum_{p=1}^p\left(\operatorname{Img} \text { up }(\mathbf{p})-\mu_{\left(\operatorname{Img}_{\text {up }}\right)}\right)^2 \\ & C_{\left(\mathbf{I m g}_{\text {up }}\right)}=\frac{\sigma_{\left(\operatorname{Img}_{\mathrm{up}}\right)}}{\mu_{\left(\operatorname{Img}_{\mathrm{up}}\right)}} \\ & \mu_{\left(\operatorname{Img}_{\mathrm{dn}}\right)}=\left(\frac{1}{\mathbf{p}}\right) \sum_{p=1}^p \operatorname{Img}_{\mathrm{dn}}(\mathbf{p}) \\ & \sigma_{\left(\operatorname{Img}_{\mathrm{dn}}\right)}=\left(\frac{1}{\mathbf{p}}\right) \sum_{p=1}^p\left(\operatorname{Img}_{\mathrm{dn}}(\mathbf{p})-\mu_{\left(\operatorname{Img}_{d n}\right)}\right)^2 \\ & C V_{\left(\mathbf{I m g}_{d n}\right)}=\frac{\sigma_{\left(\mathbf{I m g}_{d n}\right)}}{\mu_{\left(\mathbf{I m g}_{d \mathbf{n}}\right)}} \\ & \end{aligned}$
Then all other features are calculated, and as a result 48 features of Img, Rimg, Gimg, Bimg.
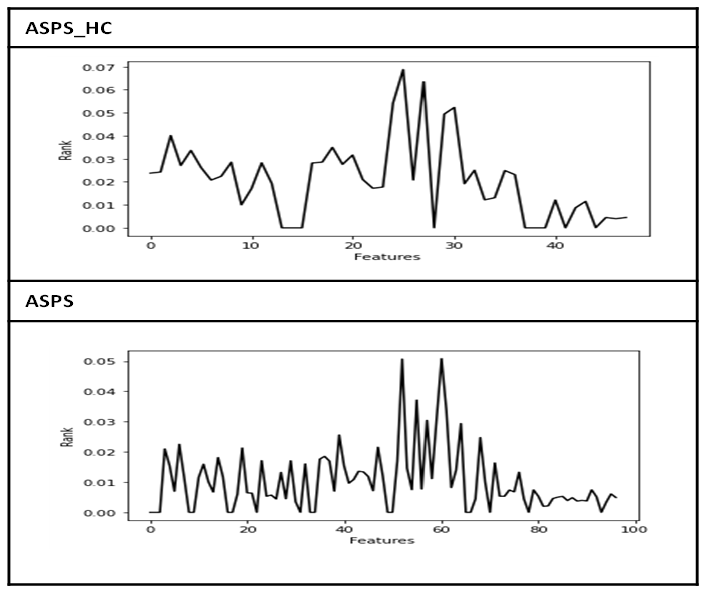
Many previous studies have relied on building Computer Vision models using a specific type of Neural Network, mainly due to the high cost of the large number of images that the model needs to learn and the large amount of data that every image needs to represent. This requires expensive equipment, such as high-performance servers (GPU), distributed systems, or cloud computing. ASPS_HC was designed to improve performance and efficiency, reducing the time required to extract minimum effective features that lead to building high-accuracy models. Diabetic retinopathy was chosen as a case study to test and evaluate the ASPS_HC approach, as diagnosing diabetic retinopathy is one of the most challenging diagnoses in healthcare. The dataset used in the study consists of 5,540 images with 2,834 infected images and 2,706 uninfected images in the Gaussian formula [16], which does not include redundant colors or lights. Additionally, data augmentation techniques were used to increase the number of images. Both ASPS and ASPS_HC were applied to obtain features from this dataset, as shown in Figure 5. The ranks of features using ASPS_HC are higher than those obtained using ASPS, indicating better performance of the ASPS_HC approach.
Figure 5. Features rank using ASPS_HC and ASPS
In the study, a few image processing techniques were applied, such as resizing the images to a size of (400x400) and filtering. The results of applying ASPS and ASPS_HC approaches to extract features are shown in Table 1. Three main achievements were obtained by using the ASPS_HC approach instead of ASPS to extract features. Firstly, the average rank of features increased by two times (200%). Secondly, the run time decreased by 23.30%, and finally, the number of features was halved (50%).
Table 1. Comparison of results obtained using ASPS_HC and ASPS approaches
|
Exp_No |
ASPS |
ASPS_HC |
% |
|
No_of_features |
16x6 = 96 |
8x6 = 48 |
50.00% |
|
Run time |
4982 Sec |
1161 Sec |
23.30% |
|
Avg of rank |
0.0102 |
0.0204 |
200.00% |
Based on the data size, i.e., 5,540×8 and 5,540×16 for ASPS and ASPS_HC, respectively, traditional machine learning algorithms are more suitable than Convolutional Neural Networks or any other deep learning algorithms. Two datasets were prepared to apply binary classification algorithms to test and compare the extracted features using each approach. Two well-known classification algorithms, ANN and RF, were used. The accuracy results of each algorithm are as follows.
Table 2. Comparison of model accuracy using ASPS_HC and ASPS approaches
|
Algorithm |
ASPS |
ASPS_HC |
% |
|
ANN |
91.36% |
93.27% |
1.91% |
|
RF |
95.76% |
97.12% |
1.36% |
Table 2 shows an improvement in the accuracy of both the ANN and RF models, with an increase of 1.91% and 1.36%, respectively, when using features extracted by the ASPS_HC approach compared to those extracted by the ASPS approach. These results demonstrate that with a smaller dataset size, it is more appropriate to use traditional machine learning algorithms rather than deep learning algorithms, which often require a large amount of data in its original form, such as in the RGB formula or other formats.
In the field of machine learning, obtaining a high-accuracy model depends mainly on the data distribution and pre-processing techniques, such as Feature Selection and Feature Extraction. In this study, a novel approach to Feature Extraction from medical images in the healthcare domain is proposed, called ASPS_HC. This approach relies on an Automated Sensory and Signal Processing Selection System (ASPS), which uses Upper and Lower Limit Outliers to determine a region that can help recognize diseases within classes, in addition to statistical measures such as mean, standard deviation, and Coefficient of Variance. Compared to the ASPS approach, ASPS_HC extracted only eight features instead of sixteen, resulting in three advantages: the average ranking of features doubled, the uptime was reduced by almost a quarter, and the number of features was halved. These advantages were reflected in the efficiency of the classification models. The proposed approach was tested on a diabetic retinopathy (DR) dataset, and it resulted in a higher accuracy of 1.91% in the Artificial Neural Network model and 1.36% in the Random Forest model. This demonstrates the effectiveness of ASPS_HC in Feature Extraction from medical images and its potential in improving the accuracy of classification models in healthcare applications.
[1] Saeedi, P., Petersohn, I., Salpea, P., Malanda, B., Karuranga, S., Unwin, N., Colagiuri, S., Guariguata, L., Motala, A.A., Ogurtsova, K., Shaw, J.E., Bright, D., Williams, R., IDF Diabetes Atlas Committee. (2019). Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas. Diabetes Research and Clinical Practice, 157: 107843. http://dx.doi.org/10.1016/j.diabres.2019.107843.
[2] Amin, H.U., Malik, A.S., Ahmad, R.F., Badruddin, N., Kamel, N., Hussain, M., Chooi, W.T. (2015). Feature extraction and classification for EEG signals using wavelet transform and machine learning techniques. Australasian Physical & Engineering Sciences in Medicine, 38: 139-149. http://dx.doi.org/10.1007/s13246-015-0333-x
[3] Tsiknakis, N., Theodoropoulos, D., Manikis, G., Ktistakis, E., Boutsora, O., Berto, A., Marias, K. (2021). Deep learning for diabetic retinopathy detection and classification based on fundus images: A review. Computers in Biology and Medicine, 135: 104599. http://dx.doi.org/10.1016/j.compbiomed.2021.104599
[4] Al-Habaibeh, A., Gindy, N. (2000). A new approach for systematic design of condition monitoring systems for milling processes. Journal of Materials Processing Technology, 107(1-3): 243-251. http://dx.doi.org/10.1016/S0924-0136(00)00718-4
[5] Nayak, J., Bhat, P.S., Acharya U, R., Lim, C.M., Kagathi, M. (2008). Automated identification of diabetic retinopathy stages using digital fundus images. Journal of Medical Systems, 32: 107-115. http://dx.doi.org/10.1007/s10916-007-9113-9
[6] Acharya U, R., Chua, C.K., Ng, E.Y.K., Yu, W., Chee, C. (2008). Application of higher order spectra for the identification of diabetes retinopathy stages. Journal of Medical Systems, 32: 481-488. http://dx.doi.org/10.1007/s10916-008-9154-8
[7] Acharya, U.R., Lim, C.M., Ng, E.Y.K., Chee, C., Tamura, T. (2009). Computer-based detection of diabetes retinopathy stages using digital fundus images. Proceedings of the Institution of Mechanical Engineers, Part H: Journal of Engineering in Medicine, 223(5): 545-553. http://dx.doi.org/10.1243/09544119JEIM486
[8] Pratt, H., Coenen, F., Broadbent, D. M., Harding, S.P., Zheng, Y. (2016). Convolutional neural networks for diabetic retinopathy. Procedia Computer Science, 90: 200-205. http://dx.doi.org/10.1016/j.procs.2016.07.014
[9] Gardner, G.G., Keating, D., Williamson, T.H., Elliott, A.T. (1996). Automatic detection of diabetic retinopathy using an artificial neural network: A screening tool. British Journal of Ophthalmology, 80(11): 940-944. http://dx.doi.org/10.1136/bjo.80.11.940
[10] Chakrabarty, N. (2018). A deep learning method for the detection of diabetic retinopathy. In 2018 5th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), pp. 1-5. http://dx.doi.org/10.1109/UPCON.2018.8596839
[11] Samanta, A., Saha, A., Satapathy, S.C., Fernandes, S.L., Zhang, Y.D. (2020). Automated detection of diabetic retinopathy using convolutional neural networks on a small dataset. Pattern Recognition Letters, 135: 293-298. http://dx.doi.org/10.1016/j.patrec.2020.04.026
[12] Gadekallu, T. R., Khare, N., Bhattacharya, S., Singh, S., Maddikunta, P. K. R., & Srivastava, G. (2020). Deep neural networks to predict diabetic retinopathy. Journal of Ambient Intelligence and Humanized Computing, 1-14. http://dx.doi.org/10.1007/s12652-020-01963-7
[13] Saleh, G.M., Wawrzynski, J., Caputo, S., Peto, T., Al Turk, L.I., Wang, S., Tang, H. L. (2016). An automated detection system for microaneurysms that is effective across different racial groups. Journal of Ophthalmology, 2016. http://dx.doi.org/10.1155/2016/4176547
[14] Al-Turk, L., Wawrzynski, J., Wang, S., Krause, P., Saleh, G.M., Alsawadi, H., Tang, H.L. (2022). Automated feature-based grading and progression analysis of diabetic retinopathy. Eye, 36(3): 524-532. http://dx.doi.org/10.1038/s41433-021-01415-2.
[15] Kuwil, F.H., Atila, Ü., Abu-Issa, R., Murtagh, F. (2020). A novel data clustering algorithm based on gravity center methodology. Expert Systems with Applications, 156: 113435. http://dx.doi.org/10.1016/j.eswa.2020.113435.
[16] Rath, S.R. (2021). Diabetic retinopathy 224x224 gaussian filtered. https://www.kaggle.com/sovitrath/diabetic-retinopathy-224x224-gaussian-filtered.