Liqiong Zhang* | Min Li | Xiaohua Qiu | Ying Zhu
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This paper aims to develop an efficient, robust and reliable infrared detection method for small targets. Firstly, the data structure of infrared images with small targets was analyzed in details. Then, the infrared small target detection was converted into the decomposition of the robust principal component analysis (RPCA), and the objective function was constructed with the idea of variation. Next, a regularization term called four-direction overlapping group sparse total variation (OGSTV) was created, and a TV4OGS-RPCA model was designed for infrared small target detection. Experimental results prove that our model can effectively separate small targets from the background, and accurately pinpoint the small targets in infrared images.
infrared small target detection, robust principal component analysis (RPCA), total variation (TV), four-direction overlapping group
Capable of enhancing human vision, infrared technology has been widely applied to imaging and detection tasks in both civil and military fields, such as infrared remote sensing, infrared monitoring, medical image detection, faults detection, to name but a few [1-3]. In computer vision, infrared target detection has long been a research hotspot. However, it is a challenging task to develop an efficient, robust, and reliable infrared target detection method.
At present, infrared detection methods for small targets are based on either single-frame images (SFIs) or multi-frame images (MFIs) [4]. When the background is stationary, the MFIs-based methods boast better detection effect than the SFIs-based methods, because they fully utilize the space-time information in the image sequence. In actual scenes, however, the imaging background of the detection system often changes rapidly, due to the fast motions of the targets or the rapid relative motion between the targets and the imager. In this case, the MFIs-based methods, which assume that the background is static, cannot work properly.
As a result, the SFIs-based methods are the mainstream of infrared small target detection, laying the basis for the sequence-based image method. Traditionally, the SFIs-based detection methods are grounded on spatial filters, namely, two-dimensional least mean square (TDLMS) filter [5], Top-hat filter [6], and maximum mean (max-mean) and maximum medium (max-median) filters [7, 8], as well as their improved versions. This type of methods relies on background estimation to suppress background clutter and enhance small targets. But their performance is poor if the background in the scene in not uniform.
Different from spatial filter-based methods, transform domain-based methods process high and low frequencies separately in the transform domain, separate high- and low-frequency components that respectively correspond to the target and background, and detect the targets through inverse transform. The common transform domain-based methods are wavelet transform [9], Contourlet transform [10], and non-subsampling Contourlet transform (NSCT) [11]. Compared with spatial filter-based methods, this type of methods faces a high complexity and a huge computing load, during the conversion of the spatial domain and the transform domain.
Human visual saliency (HVS) detection is another type of methods to detect small targets. In HVS detection, each small target is highlighted in the saliency map, which is plotted based on the local contrast of an area and its neighborhood. The main bases of HVS detection methods are Laplacian of Gaussian (LoG) operator [12, 13], Difference of Gaussian (DoG) operator [14], and local contrast measurement (LCM) [15, 16]. The defect of HVS detection methods lies in the limitation of the saliency assumption. In the real world, some small targets are insignificant, and overshadowed by interfering sources of radiation, making them difficult to be identified by HVS detection methods.
In an actual infrared detection system, each small target only has a limited imaging area, owing to the long imagining distance. The target exists as a light spot in the entire image, lacking structural features like edge, texture or corner. The only distinctive feature of such a small target is grayscale, whose intensity has little to do with background radiation. In typical infrared scenes, the image background is usually nonuniform and unsmooth, featuring a low signal-to-noise ratio (SNR), serious background clutter, and weak texture levels. This is attributable to the limitations of imaging techniques. In military scenes, the infrared backgrounds are about the sky, the ground or the sea. All these backgrounds are complicated by the dynamic changes: random clouds in the sky, terrain relief on the ground, and waves and illumination on the sea. Since these changes tend to be slow and regular, the pixels in the infrared backgrounds must have strong correlations.
In recent years, the data structure of the image has been considered in the infrared detection of small targets [17, 18]. Through sparse representation, Wan et al. [19] established a dictionary about the correspondence between background and target components, and reconstructed the component matrix to pinpoint the targets. Gao et al. [20] proposed an infrared patch image (IPI) model, which converts infrared small target detection into low-rank sparse decomposition, that is, robust principal component analysis (RPCA) [21]. Since then, the IPI model has been repeatedly improved by adding new constraints [22-24]. The improved IPI models could accurately depict the low-rank and sparse features of background images and target images. All the above methods differentiate between targets and background, and regard noise as part of the background. However, background noise is very similar to small targets. In complex and changeable scenes, it is easy to misinterpret sparse background components as small targets, causing false alarms that negatively affect subsequent processing.
Considering the features of infrared imaging, it is difficult to detect small targets in infrared images based on a single feature (e.g. grayscale) alone. Therefore, multiple features are integrated in many emerging methods. Then, the detection effect depends on the types and extraction methods of features. This paper attempts to extract stable features from infrared images, and detect small targets based on image data structure. To utilize low-rank sparse model, the RPCA model was introduced to modify the constraints of the small target matrix. In addition, a regularization term called the four-direction overlapping group sparse total variation [25] (OGSTV) was added to highlight the sparse features of real targets in the noisy and sparse background.
The remainder of this paper is organized as follows: Section 2 introduces the data structure of infrared images and the basic framework of RPCA, and converts infrared small target detection into a RPCA-based model; Section 3 improves the low-rank and sparse features of the background and the small targets; Section 4 designs an infrared small target detection model based on four-direction OGSTV; Section 5 verifies the performance of the designed model through experiments; Section 6 puts forward the conclusions and looks forward to the future research.
2.1 RPCA
The classic principal component analysis (PCA) assumes that the noise or singular value is weak and subject to Gaussian distribution. Once the assumption becomes invalid, the matrix correlations decomposed by the PCA will not hold. To solve the problem, the RPCA [21] was developed to identify the best features of high-dimensional data in low-dimensional space.
Without considering the noise intensity, the RPCA only hypothesizes that the noise or singular value is sparse. That is why the RPCA is much more robust than the classic PCA. The RPCA algorithm can fully consider the relevant features in the original data as well as the noise or singular value. The basic idea of the RPCA is detailed as follows:
The input of an m´n order signal matrix M can be decomposed into three parts:
$\mathbf{M}=\mathbf{L}+\mathbf{S}+\mathbf{N}$ (1)
where, L is a low-rank data matrix with strong linear correlations, containing many repeated rows or columns; S is a sparse data matrix with most elements being zeros; N is a random noise matrix. The size of L and S can be arbitrary.
If the spatial information of L and S is unknown, the RPCA can be employed to reconstruct L and detect S from M. In this case, the solution to the RPCA is to find the low-rank matrix and the sparse matrix. Then, the variation idea was introduced to transform the solving process into an optimization problem, that is, minimizing the objective function:
$\min _{\mathbf{L}, \mathbf{S}} \operatorname{rank}(\mathbf{L})+\lambda\|\mathbf{S}\|_{0}$ s.t. $\frac{1}{2}\|\mathbf{M}-\mathbf{L}-\mathbf{S}\|_{F}^{2} \leq \varepsilon$ (2)
where, rank(•) is the rank of the matrix; $\|\cdot\|_{0}$ is the L0 norm reflecting the number of nonzero elements in the matrix; $\|\bullet\|_{F}$ is the Frobenius norm $\|X\|_{F}=\sum_{i=1}^{m} \sum_{j=1}^{n}\left(\left|a_{i, j}\right|^{2}\right)^{\frac{1}{2}}$ that constrains the noise; ε is a very small noise threshold; λ is the weight factor that adjusts the proportions of L and S in the objective function.
By incorporating the constraints to the objective function, the optimization problem can be rewritten as:
$\min _{\mathbf{L}, \mathbf{S}} \frac{1}{2}\|\mathbf{M}-\mathbf{L}-\mathbf{S}\|_{F}^{2}+\alpha \operatorname{rank}(\mathbf{L})+\beta\|\mathbf{S}\|_{0}$ (3)
where, α and β are weight coefficients reflecting the contributions of L and S to the objective function, respectively. By changing the values of α and β, it is possible to adjust the rank of L and sparsity of S.
Since (3) is a non-convex function, the constraints can be relaxed and replaced. Here, the calculation of the matrix rank is replaced by the nuclear norm $\|\cdot\|_{*}$, and the L0 norm is replaced by the L1 norm. In this way, the optimization problem is relaxed into an easy-to-solve convex programming problem:
$\min _{\mathbf{L}, \mathbf{S}} \frac{1}{2}\|\mathbf{M}-\mathbf{L}-\mathbf{S}\|_{F}^{2}+\alpha\|\mathbf{L}\|_{*}+\beta\|\mathbf{S}\|_{1}$ (4)
The nuclear norm and L1 norm can be respectively defined as:
$\|\mathbf{X}\|_{*}=\sum_{i=1}^{r} \sigma_{i}\|\mathbf{X}\|_{1}=\sum_{i=1}^{m} \sum_{j=1}^{n}\left|x_{i j}\right|$ (5)
where, r is the rank of matrix X; $\sigma_{i}, i=1,2, \ldots, r$ are the nonzero singular values in X. According to its definition, the nuclear norm is equivalent to the L1 norm of the singular values in X:
$\|\mathbf{X}\|_{*}=\|\sigma(\mathbf{X})\|_{1}, \sigma(\mathbf{X})=\left[\sigma_{1}, \sigma_{2}, \cdots, \sigma_{r}\right]^{T}$ (6)
Hence, the model in formula (4) can be regarded as a typical variation problem. The L and S can be obtained by finding the optimal solution.
The robustness of the RPCA is also demonstrated by its ability to recover the L and S in the following scenarios: the rank of L increases with the dimension of M; the input matrix is polluted by a noise proportional to the size of the data, i.e. M is positively correlated with S [21].
2.2 Infrared image model
For an infrared image with small targets, each part has independent statistical features. Thus, the grayscale of pixel (x,y) in the original image can be expressed as:
$f_{I}(x, y)=f_{T}(x, y)+f_{B}(x, y)+f_{N}(x, y)$ (7)
where, fT(x,y) and fB(x,y) are the grayscales of a target pixel and a background pixel, respectively; fN(x,y) is a random noise.
The key of infrared small target detection is to find effective features and differentiate between target pixels, background pixels and random noise. In special scenes, infrared backgrounds bear high resemblances, such as sky background, desert background and sea background. The pixels in these backgrounds are strongly correlated. Thus, such a background can be regarded as a low-rank signal. Meanwhile, a small target, which occupies a few pixels, can be considered as a singular value (sparse signal) in the background signal. By regularizing the low-rank and sparse data, the RPCA can be employed to separate the background and the target based on data structure. Of course, the noise constraint must also be considered, because the background data and target data are stochastically disturbed by the random changes of clouds and illumination in the complex background.
Based on the RPCA, an infrared image with uniform background and sparse small targets can be modelled as M=L+S+N, where M is fI(x,y); L is the background image fB(x,y); S is the target image fT(x,y); N is the random noise.
Considering the low rank of the background and the sparsity of small targets, the above model can be rewritten as formula (4), according to the RPCA theory. Under the constraint of the regularization term, the infrared small target detection model is a variation model, which can be solved as a RPCA model with specific constraints. The basic solution is to build a variation model, and reversely derive the target components from the degraded input infrared image.
3.1 Background reconstruction
The model (4) assumes that the row or column vectors in the background matrix have strong correlations, that is, the background is uniform and slowly changing. However, the assumption does not hold in many actual scenes. The background of infrared images often contains distinctive texture features, such as clouds in the sky, building contours against the ground, and waves on the sea. These features directly determine the type of background. With an invalid assumption, the model (4) solution will carry a large error. For example, the texture features in the background will be blurry, and local details like corners will be mistaken as sparse small targets, increasing the false alarm rate.
Some scholars [20, 26, 27] have attempted to increase the low-rank of the infrared background matrix, and reconstruct the nonuniform and unsmooth backgrounds in SFIs and MFIs. By these methods, the image background is reconstructed based on the correlations between background image blocks. In this way, the edges or clutters in the background are viewed as part of the background, rather than singular values of targets.
If the original image is an SFI, the low rank will disappear should the background contain some texture features. The blocks partitioned from the infrared background will have similar information. Then, a new low-rank matrix can be established by rearranging these blocks, and used to detect small targets through RPCA decomposition. The above process can be detailed as follows: Firstly, the original image matrix is divided into small overlapping or nonoverlapping blocks. The grayscales of pixels in each block constitute a column vector pi. Next, the column vectors of all blocks are cascaded into a new matrix of the image: $\boldsymbol{M}=\left\{p_{1}, p_{2}, \ldots, p_{n}\right\} \in \mathbb{R}^{m \times n}$, where pi is the column vector of a block; m is the number of pixels in a block; n is the number blocks. Then, the new matrix is decomposed by the RPCA, producing the optimal solution of model (4) [20].
If the original image is an MFI, the backgrounds of adjacent frames are almost identical and strongly correlated, due to the high frame frequency. The grayscales of pixels in each frame constitute a column vector. Then, the n frames become n column vectors, forming a new matrix $\boldsymbol{M}=\left\{I_{1}, \ldots, I_{n}\right\} \in \mathbb{R}^{m \times n}$, where m is the number of pixels in a frame; n is the number of frames [27]. In this way, the infrared small target detection of the MFI is incorporated into the RPCA framework, and turned into a variation optimization problem.
3.2 Constraint modification
When a reconstructed SFI is subject to RPCA-based low-rank and sparse decomposition, the L0 norm about matrix sparsity is replaced with the L1 norm, which the sum of nonzero elements of the matrix. The locally linear L1 norm makes the grayscale of each pixel converge to the mean grayscale in the local area. The convergence undermines the structure of target pixels in the neighborhood, failing to reflect the spatial aggregation of the target pixels.
To solve the problem, the small target detection model (4) was improved by changing the L1 norm of the previously constrained sparse terms into L21 norm:
$\min _{\mathbf{L}, \mathbf{S}} \frac{1}{2}\|\mathbf{M}-\mathbf{L}-\mathbf{S}\|_{F}^{2}+\alpha\|\mathbf{L}\|_{*}+\beta\|\mathbf{S}\|_{21}$ (8)
where, α and β are weight coefficients that balance low-rank item with sparse item; $\|S\|_{21}=\sum_{j=1}^{n} \sqrt{\sum_{i=1}^{m}\left(S_{i, j}\right)^{2}}=\sum_{j}^{n}\left\|S_{j}\right\|_{2}$ is the L21 norm of the matrix, with S(i,j) being the grayscale of pixel (i,j), and Sj being the j-th column of S.
The L21 norm is defined as the sum of the L2 norms of all column vectors of the matrix. In sparse regularization, using L21 norm is to make the L2 norm of most column vectors in S as small as possible, that is, to maximize the number of zero elements in S. This operation keeps the data sparse and ensures the sparsity of column vectors. The non-zero column vectors are image blocks with candidate small targets. The replacement makes the model more in line with the actual situation of image blocks, facilitating the detection of small targets [26].
In the improved model (8), the minimum of random noise is constrained by the Frobenius norm, which has a limited suppression ability. Similar to small targets, the random noise may be mistaken as a sparse component. To better constrain the noise, a regularization term called four-direction OGSTV was proposed to restrain the target matrix in the model.
4.1 Four-direction TV
In the traditional TV model, the gradient of the pixels only reflects the changes in the horizontal and vertical directions. Therefore, the gradient constraint only suppresses the noise in these two directions. Here, two more directions, namely, 45° and 135° relative to pixels, are added to form a four-direction gradient [28, 29]. The gradient operators in the two additional directions can be respectively expressed as: $\boldsymbol{K}_{45^{\circ}}=\left[\begin{array}{cc}0 & -1 \\ 1 & 0\end{array}\right]$ and $\boldsymbol{K}_{135^{\circ}}=\left[\begin{array}{cc}-1 & 0 \\ 0 & 1\end{array}\right]$.
Then, the L1 norm was adopted to regularize the pixel gradient in horizontal, vertical, 45° and 135° directions. In this way, the noise can be suppressed in all four directions, improving the quality of image restoration. The four-direction TV regularization term can be written as:
$R_{Q T V}\left(\boldsymbol{U}_{0}\right)=\left\|\boldsymbol{K}_{h} * \boldsymbol{U}_{0}\right\|_{1}+\left\|\boldsymbol{K}_{v} * \boldsymbol{U}_{0}\right\|_{1}$
$+\left\|\boldsymbol{K}_{45^{\circ}} * \boldsymbol{U}_{0}\right\|_{1}+\left\|\boldsymbol{K}_{135^{\circ}} * \boldsymbol{U}_{0}\right\|_{1}$ (9)
4.2 OGSTV
To control target sparsity, this paper designs a structured regular constraint called OGSTV [30, 31]. Apart from the gradient of image pixels, this regularization term also regularizes the neighborhood difference at each pixel, pushing up the local sparsity of the image [32]. By overlapping gradients, the block difference can be increased, and the probability of staircase effect can be reduced.
The OGSTV regularization term $R_{O G S T V}\left(\boldsymbol{U}_{0}\right)$ can be defined as [30]:
$R_{\text {OGSTV}}\left(\boldsymbol{U}_{0}\right)=\varphi\left(\boldsymbol{K}_{h} * \boldsymbol{U}_{0}\right)+\varphi\left(\boldsymbol{K}_{v} * \boldsymbol{U}_{0}\right)$ (10)
Then, $\varphi(\boldsymbol{A})=\sum_{i=1} \sum_{j=1}\left\|\tilde{\boldsymbol{A}}_{i, j, k, k}\right\|_{2}$ was adopted to solve the L2 norm of the combined gradient, where the $\widetilde{\boldsymbol{A}}_{i, j, k, k}$ can be defined as:
$\widetilde{A}_{i, j, k, k}=\left[\begin{array}{cccc}A_{i-k_{l}, j-k_{l}} & A_{i-k_{l}, j-k_{l}+1} & \cdots & A_{i-k_{l}, j+k_{r}} \\ A_{i-k_{l}+1, j-k_{l}} & A_{i-k_{l}+1, j-k_{l}+1} & \cdots & A_{i-k_{l}+1, j+k_{r}} \\ \vdots & \vdots & \ddots & \vdots \\ A_{i+k_{r, j-k_{l}}} & A_{i+k_{r, j-k_{l}+1}} & \cdots & A_{i+k_{r, j+k_{r}}}\end{array}\right] \in \mathbb{R}^{k \times k}$ (11)
where, $k_{l}=\left|\frac{k}{2}-1\right|$;$k_{r}=\left|\frac{k}{2}\right|$; ⌊ ⌋ is the largest integer smaller than or equal to the value in parentheses; $\widetilde{\boldsymbol{A}}_{i, j, k, k}$ is the local gradient of an image gradient matrix; $\varphi(\boldsymbol{A})=\sum_{i=1} \sum_{j=1}\left\|\tilde{\boldsymbol{A}}_{i, j, k, k}\right\|_{2}$ is the regularization of combined local gradient matrix.
The OGSTV considers the pixel gradient in different blocks, and constrains it with the L2 norm. Through OGSTV regularization, the image blocks become sparser and smoother, making it easier to distinguish the random noise from edges. This obviously promotes the robustness of the smoothing algorithm.
4.3 Model construction
To improve the accuracy of infrared small target detection, this paper designs a new regularization constraint called the four-direction OGSTV:
$T V_{4 O G S}\left(\mathbf{U}_{0}\right)=\varphi\left(\mathbf{K}_{h} * \mathbf{U}_{0}\right)$
$+\varphi\left(\mathbf{K}_{v} * \mathbf{U}_{0}\right)+\left\|\mathbf{K}_{45^{\circ}} * \mathbf{U}_{0}\right\|_{1}+\left\|\mathbf{K}_{135^{\circ}} * \mathbf{U}_{0}\right\|_{1}$ (12)
The four-direction OGSTV was combined with the RPCA-based model into:
$\min _{\mathbf{L}, \mathbf{S}} \frac{1}{2}\|\mathbf{M}-\mathbf{L}-\mathbf{S}\|_{F}^{2}+\alpha\|\mathbf{L}\|_{*}$
$+\beta\|\mathbf{S}\|_{21}+\gamma \mathrm{TV}_{4 O G S}(\mathbf{S})$ (13)
where, α, β and γ are nonnegative weights (regularization factors) of background, target, and noise, respectively; the first term uses the Frobenius norm to control the noise on a sufficiently small level, i.e. suppress random noise; the second term minimizes the nuclear norm to output the background with the highest correlation; the third term minimizes the L21 norm of the target matrix to differentiate between small targets and non-target singular values, and to obtain an accurate sparse small target matrix with aggregation features; the last term constrains the target matrix with four-direction OGSTV.
The combined model enhances the sparsity of the target matrix, and distinguishes the random noise from local features accurately, in the light of the gradient directions of each pixel and the gradients in its neighborhood. In this way, the background will not be over-blurred, and the background noise will be suppressed.
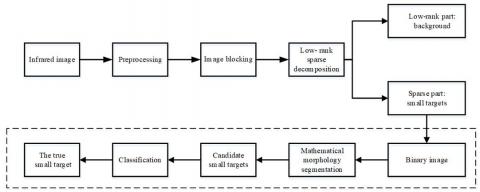
Figure 1. The workflow of TV4OGS-RPCA model
Based on the input image, the objective function (13) can output the low-rank matrix and sparse matrix of the reconstructed image. The two matrices represent the background image and the small target image, respectively. However, the combined model stops at the decomposition of the reconstructed image. To separate the background and the targets, the blocks should be further restored to the original position, realizing the accurate detection of small targets. After adding block restoration to the combined model, our infrared small target detection model was completed based on four-direction OGSTV and RPCA, which was denoted as the TV4OGS-RPCA model. (Figure 1).
4.4 Solving algorithm
To solve our model, formula (13) was firstly converted into an augmented Lagrangian function:
$\begin{aligned} L(\boldsymbol{S}, \boldsymbol{L}, \boldsymbol{Y})=\alpha\|\boldsymbol{L}\|_{*} &+\beta\|\boldsymbol{S}\|_{21}+\gamma T V_{40 G S}(\boldsymbol{S}) \\ &+\langle\boldsymbol{Y}, \boldsymbol{M}-\boldsymbol{S}-\boldsymbol{L}\rangle \\ &+\frac{\mu}{2}\|\boldsymbol{M}-\boldsymbol{S}-\boldsymbol{L}\|_{F}^{2} \end{aligned}$ (14)
where, $\boldsymbol{Y} \in \mathbb{R}^{m \times n}$ is the Lagrange multiplier; $\langle\cdot\rangle$ is the inner product of the matrices.
Then, the classic solving algorithm, alternating direction multiplier method (ADMM) was introduced to solve our model. The ADMM excels in solving convex optimization problems with separable structure. The basic idea is to update image blocks alternatively, rather than update the entire image all at once. In other words, matrices L and S plus multiplier Y should be minimized, and updated right after the solution [26]:
$\mathbf{S}_{k+1}=\arg \min _{\mathbf{S}} L\left(\mathbf{S}, \mathbf{L}_{k}, \mathbf{Y}_{k}, \mu\right)$ (15a)
$\mathbf{L}_{k+1}=\arg \min _{\mathbf{L}} L\left(\mathbf{S}_{k+1}, \mathbf{L}_{k}, \mathbf{Y}_{k}, \mu\right)$ (15b)
$\mathbf{Y}_{k+1}=\mathbf{Y}_{k}+\mu\left(\mathbf{M}-\mathbf{S}_{k+1}-\mathbf{L}_{k+1}\right)$ (15c)
Formula (15a) is equivalent to:
$\min _{s}\left\{\lambda\|\boldsymbol{S}\|_{21}+\gamma T V_{40 G S}(\boldsymbol{S})+\frac{\mu}{2}\left\|\frac{1}{\mu} \boldsymbol{Y}_{k}+\boldsymbol{M}-\boldsymbol{L}_{k}-\boldsymbol{S}\right\|_{F}^{2}\right\}$ (16)
Then, the error of sparse matrix S can be minimized based on Lemma 1.
Lemma 1. Let $\boldsymbol{Q} \in \mathbb{R}^{m \times n}$ and Qj be the j-th column of the matrix. If $\boldsymbol{Q}=\frac{1}{\mu} \boldsymbol{Y}_{k}+\boldsymbol{M}-\boldsymbol{L}_{k}$, then formula (16) can be rewritten as:
$\min _{s}\left\{\lambda\|S\|_{21}+\gamma T V_{4 O G S}(S)+\left(\frac{\mu}{2}\right)\|S-Q\|_{F}^{2}\right\}$ (17)
The optimal solution of the above formula is S*. Then, the j-th column of S* can be expressed as:
$\left[S^{*}\right]_{j}=Q_{j} \max \left(\frac{1-\lambda \mu^{-1}}{\left\|Q_{j}\right\|_{2^{\prime}} 0}\right)$ (18)
The subproblem (15b) can be rewritten as:
$\mathbf{L}_{k+1}=\min _{\mathbf{L}}\left\{\|\mathbf{L}\|_{*}+\frac{\mu}{2}\left\|\frac{1}{\mu} \mathbf{Y}_{k}+\mathbf{M}-\mathbf{S}_{k+1}-\mathbf{L}_{k}\right\|_{F}^{2}\right\}$ (19)
Formula (19) can be solved with a soft threshold operator, $\boldsymbol{L}_{k+1}=\boldsymbol{U} \boldsymbol{S}_{\tau}[\boldsymbol{\Sigma}] \boldsymbol{V}^{t}$. Then, singular value decomposition is performed for the terms corresponding to the nuclear norm: $(\boldsymbol{U}, \boldsymbol{\Sigma}, \boldsymbol{V})=\operatorname{SV} D\left(\frac{1}{\mu} \boldsymbol{Y}_{k}+\boldsymbol{M}-\boldsymbol{S}_{k+1}\right)$. The soft threshold operator can be defined as $\boldsymbol{S}_{\tau}(\boldsymbol{\Sigma})=\operatorname{diag}\left\{\left(\sigma_{i}-\tau\right)_{+}\right\}$, where σiis the i-th singular value; diag is the extraction of diagonal elements; t+ is the positive part of t, i.e. $t_{+}=\max (t, 0)$.
Algorithm 1 illustrates the specific steps of the ADMM-based solving process.
|
Algorithm 1. Infrared small target detection based on TV4OGS-RPCA model |
|
Inputs: Reconstruction matrix M and weight parameters α, β and γ Outputs: Low-rank background matrix L and sparse small target matrix S Step 1. Initialization Initialize the low rank matrix $\boldsymbol{L}_{0}$, sparse matrix $\boldsymbol{S}_{0}$, and Lagrange multiplier $\boldsymbol{Y}_{0}$: $k=0 ; \boldsymbol{L}_{0}=\boldsymbol{M} ; \boldsymbol{S}_{0}=0$; $\boldsymbol{Y}_{0}=\frac{\operatorname{sign}(M)}{I}(\boldsymbol{M}), \mu_{0}>0, \rho>0$ where, $J(\boldsymbol{D})=\max \left(\|\boldsymbol{D}\|_{2},\|\boldsymbol{D}\|_{\infty}\right)$ is the matrix dual norm. |
|
Step 2. Find $\boldsymbol{S}_{k+1}$ and fix matrix $\boldsymbol{L}_{k}$, that is, solve formula (15a) for the sparse contraction operator by Lemma 1: $\boldsymbol{S}_{k+1}=\operatorname{CSVT}_{\frac{\lambda}{\mu_{k}}}\left(\frac{1}{\mu_{k}} \boldsymbol{Y}_{k}+\boldsymbol{M}-\boldsymbol{L}_{k}\right)$. |
|
Step 3. Fix matrix $\boldsymbol{S}_{k+1}$ and solve matrix $\boldsymbol{L}_{k+1}$, that is, solving formula (15b): $(\boldsymbol{U}, \boldsymbol{\Sigma}, \boldsymbol{V})=S V D\left(\frac{1}{\mu_{k}} \boldsymbol{Y}_{k}+\boldsymbol{M}-\boldsymbol{S}_{k+1}\right)$. |
|
Step 4. Perform soft threshold contraction: $\boldsymbol{L}_{k+1}=\boldsymbol{U} \boldsymbol{S}_{\left(\frac{1}{\mu_{k}}\right)}[\Sigma] \boldsymbol{V}^{T}$. |
|
Step 5. Update multiplier $\boldsymbol{Y}_{k+1}=\boldsymbol{Y}_{k}+\mu_{k}\left(\boldsymbol{M}-\boldsymbol{L}_{k+1}-\boldsymbol{S}_{k+1}\right), \mu_{k+1}=\rho \mu_{k}$. Step 6. Repeat Steps 2-5 until the convergence condition tol$=\frac{\left\|M-S_{k}-L_{k}-N_{k}\right\|}{\|M\|_{F}} \leq 10^{-7}$, where k is the number of iterations, is satisfied, or when the maximum number of iterations $\max I$ ter $=500$ is reached. |
|
Step 7. Output the optimal solution: $\boldsymbol{L}_{k} \rightarrow \boldsymbol{L} *, \boldsymbol{S}_{k} \rightarrow \boldsymbol{S} *$ |
5.1 Evaluation metrics
The SNR, also known as signal-to-clutter ratio, is an important performance indicator of image processing algorithms [33]. In image target detection, the SNR is generally defined as:
$\mathrm{SNR}=\frac{\left|\mu_{T}-\mu_{B}\right|}{\sigma_{B}}$ (20)
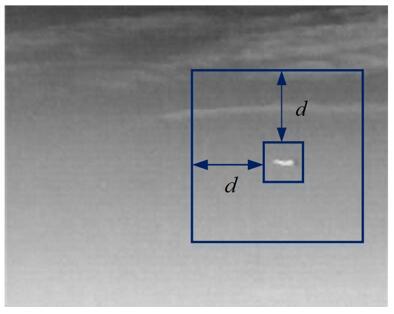
where, μT is the mean grayscale of the target area; μB and σB are the mean and standard deviation of the grayscales of the background neighborhood, i.e. the area containing d pixels around the target area, respectively. Figure 2 illustrates the target area and background neighborhood. For our experiments, the SNR was selected as an evaluation metric with d=20.
Figure 2. The target area and background neighborhood
To reflect the performance gain, the SNR gain index was also introduced [33]:
$\mathrm{G}_{\mathrm{SNR}}=\frac{\mathrm{SNR}_{o u t}}{\mathrm{SNR}_{i n}}$ (21)
where, SNRout and SNRin are the SNRs of the input and output images, respectively. The ratio between them manifests the degree of target enhancement and noise suppression.
Another evaluation metric adopted in our experiments is the background suppression factor (BSF) [33]:
$\mathrm{BSF}=\frac{\sigma_{i n}}{\sigma_{\text {out}}}$ (22)
where, σinand σout are the standard deviations of the global background of the input and output images, respectively. The ratio between them demonstrates the change of standard deviation through the processing.
Moreover, the detection results on multiple targets were divided into four categories: the number of true positives (TP), the number of false negatives (FN), the number of false positives (FP), and the number of true negatives (TN). By this classification, the probability of detection (Pd) and false alarm rate (Fa) can be respectively defined as:
$\mathrm{P}_{d}=\mathrm{TPR}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}$ (23)
$\mathrm{F}_{a}=\mathrm{FPR}=\frac{\mathrm{FP}}{\mathrm{FP}+\mathrm{TN}}$ (24)
With Pd as the vertical axis and Fa as the horizontal axis, the receiver operating characteristic (ROC) curve was plotted to test the model performance. The ROC curve shows the trend of Pd at different Fa values. Different thresholds were set for different algorithms.
5.2 Experimental environment
In our model, α, β and γ are the weight factors that balance low-rank item, sparse item, and TV item. For our experiments, the weight factors were configured as $\alpha=0.1 \sqrt{\max (m, n)}$, β=0.05, and γ=0.5. In addition, block size m×n was defined as 50×50 pixels, and the step size as 10 pixels.
Our experiments were conducted on MATLAB R2016b and a computer with an Intel® Core™ i5 Processor (CPU: 2.6Hz; memory: 4GB).
5.3 Results analysis
Our experiments compare the proposed model with popular image target detection methods, including TH filter, max-mean filter, max-median filter, and RPCA algorithm. Through repeated tests, the size of max-mean filter and max-median filter was set to 9×9 pixels.
5.3.1 Single target detection experiment
Six groups of MFIs were selected to test multiple methods in our experiments. As shown in Table 1, Group 1 is a complex indoor scene with one person (target) and a bright light (noise). Group 2 is an outdoor scene with a horse (target) and a building in the background (noise). Group 3 is a jungle scene with a small animal (target) and trees in the background (noise). Groups 4 and 5 are both sky scenes with a small target against a few clouds (noise). Group 6 is a sky scene with a small target against heavy clouds (noise).
One frame was selected from each group to display the effect of the five contrastive methods. The six selected frames are presented in Figure 3 (a). Columns (b)-(f) of Figure 3 are the detection results of TH filter, max-mean filter, max-median filter, RPCA algorithm, and TV4OGS-RPCA model, respectively.
As shown in Figure 3, the Top-hat filter was ineffective in detecting small targets, for it is a binarization method based on mathematical morphology. The max-mean filter outputted blurry backgrounds and produced vague and scattered edges of targets. The max-median filter achieved relatively good detection results, but did not fully filter the noise in complex backgrounds. By contrast, RPCA and our model (TV4OGS-RPCA model) effectively suppressed the background noise and separated small targets, through low-rank sparse matrix decomposition.
Table 1. Image sets for single target detection experiment
|
Group number |
Number of frames |
Image size (unit: pixel) |
Background type |
Background description |
Number of targets |
Target size (unit: pixel) |
|
1 |
30 |
263×210 |
Indoor |
Light |
1 |
89×27 |
|
2 |
50 |
324×256 |
Outdoor |
Houses |
1 |
51×53 |
|
3 |
100 |
320×256 |
Jungle |
Trees |
1 |
22×38 |
|
4 |
30 |
256×200 |
Sky |
Partly cloudy |
1 |
23×30 |
|
5 |
40 |
256×200 |
Sky |
Partly cloudy |
1 |
5×13 |
|
6 |
30 |
256×200 |
Sky |
Overcast |
1 |
5×6 |
Figure 3. The detection results of the five methods on six different images
To quantify the effects of different methods, the SNRs before and after processing were computed. Then, the mean SNR gain of each method on each image group was obtained (Table 2). The mean SNR gains are dimensionless, and the best mean SNR gain on each image group is in bold font. It can be seen that max-mean filter and max-median filter realized good results on Groups 1-3. This is because the SNR mainly reflects the mean grayscale of the target and the complexity of the background, which are affected by the size of the target area and the stationarity of the background. Meanwhile, RPCA and our model outperformed the other methods on the last three groups, which contain small targets in a relatively stable and uniform background.
The RPCA and TV4OGS-RPCA model both perform low-rank sparse decomposition on images, making the background image and small target image decomposable. Then, the two methods were further compared in terms of background restoration and noise suppression. As shown in Figure 4, the two methods performed relatively poor in Groups 1-3, in which the images have complex nonuniform backgrounds and large targets. The scenes in these images are not low-rank or sparse. On the contrary, the two methods accurately separated background from target in the latter three groups of stable scenes with small targets.
Table 3 compares the mean BSF of each of the five methods on every image group. The mean BSFs are dimensionless, and the best mean BSF on each image group is in bold font. Obviously, our model had fewer cutters and residual noise than the contrastive methods in each image group. Under the same detection probability, our model boasted the lowest false alarm rate. Hence, our model is good at background restoration. This strength is very useful in many applications. For instance, the restored background can be used to classify the scene or estimate the reliability of detection results.
Table 2. Mean SNR gains of the five methods on six image groups
|
Group number |
Top-hat |
Max-mean filter |
Max-median filter |
RPCA algorithm |
TV4OGS-RPCA model |
|
1 |
0.393 |
1.0806 |
0.972 |
0.2386 |
0.0503 |
|
2 |
0.6921 |
1.0349 |
0.9558 |
0.6789 |
0.2048 |
|
3 |
0.1306 |
0.8485 |
0.8577 |
0.7687 |
0.3261 |
|
4 |
0.3120 |
0.8402 |
0.856 |
1.0224 |
1.2561 |
|
5 |
0.1317 |
0.3331 |
0.6129 |
1.4703 |
1.9429 |
|
6 |
1.0774 |
1.2426 |
3.0407 |
7.2687 |
9.7686 |
Figure 4. Background restoration of RPCA and TV4OGS-RPCA model on six different images
Table 3. Mean BSFs of the five methods on six image groups
|
Group number |
Top-hat |
Max-mean filter |
Max-median filter |
RPCA algorithm |
TV4OGS-RPCA model |
|
1 |
0.4463 |
0.9390 |
0.9586 |
1.1191 |
1.0338 |
|
2 |
0.3786 |
0.9851 |
1.0030 |
1.0254 |
1.1513 |
|
3 |
0.8532 |
0.9648 |
1.0138 |
1.0053 |
1.4302 |
|
4 |
1.3102 |
0.9801 |
0.9970 |
1.0161 |
1.5553 |
|
5 |
0.5217 |
0.9615 |
0.9682 |
1.0329 |
1.3848 |
|
6 |
0.3307 |
0.9406 |
0.9958 |
1.0517 |
1.6592 |
The next experiment was performed to verify the detection effect of our model on multiple small targets in infrared images. Considering the unavailability of multi-target infrared image set, multi-target images for our experiment were generated by embedding small targets into real infrared images [20].
Firstly, 100 images from Groups 4-6 were selected as the real background images, while the small targets in these images, whose size is 23´30 pixels, 5´13 pixels, and 5´6 pixels, were taken as the targets to be embedded. The target sizes were adjusted through bicubic interpolation into simulation target sizes: am×an pixels, where a is a random small positive number; am´anÎ[4,90]; m´n is the actual target size. For convenience, the grayscale of each target was normalized to (0, 1). In total, 744 simulation targets were generated.
Secondly, pÎ[2,8] small simulation targets were randomly embedded to each frame of each image. The embedding position was determined by [20]:
$f(x, y)=\left\{\begin{array}{cc}\max \left(r f_{T}\left(x-x_{0}, y-y_{0}\right), f_{B}(x, y)\right) & x \in\left(1+x_{0}, n+x_{0}\right), y \in\left(1+y_{0}, m+y_{0}\right) \\ f_{B}(x, y) & \text { otherwise }\end{array}\right.$ (25)
where, (x0, y0) are randomly generated coordinates of the upper left corner of the embedded target; $r \in[h, 255]$ is a random number (h is the maximum grayscale in the background image).
Finally, each embedded image was subject to Gaussian filtering to blur the edges of the simulation targets, making the image more realistic. The information of the multi-target images is specified in Table 4.
Table 4. Information of multi-target images
|
|
Group 4 |
Group 5 |
Group 6 |
|
Number of frames |
30 |
40 |
30 |
|
Number of targets |
204 |
312 |
228 |
|
Mean target size (unit: pixel) |
110.4 |
64.8 |
36.4 |
Table 5. Detection probabilities of the five algorithms on three image groups (false alarm rate: 2/frame)
|
|
|
Group 4 |
Group 5 |
Group 6 |
|
Pd |
Top-hat |
0.66 |
0.67 |
0.55 |
|
Max-mean filter |
0.74 |
0.73 |
0.63 |
|
|
Max-median filter |
0.77 |
0.74 |
0.72 |
|
|
RPCA algorithm |
0.88 |
0.88 |
0.91 |
|
|
TV4OGS-RPCA model |
0.89 |
0.93 |
0.95 |
Figure 5. ROC curves of the five methods on the three image groups
Figure 5 are the ROC curves of the five methods on the three image groups. It can be seen that the RPCA algorithm had a slightly higher detection probability than our model at Fa<0.75 in Group 4 and at Fa<0.5 in Group 5. At a very small false alarm rate, there was little difference between the five methods. With the growth in that rate, our model gradually achieved the highest detection ability and the largest area under the curve (AUC). This means our model outshines the other methods in multi-target detection in infrared images.
This paper presents a new infrared small target detection model called TV4OGS-RPCA. Based on the low-rank and sparse features of infrared images, our model transforms small target detection task into a variation optimization problem under the RPCA framework and improved TV regularization. Experimental results show that our model outperformed the traditional methods in detecting small targets in stable background, as evidenced by the suppression of background noise and enhancement of targets. In addition, the effectiveness of our model depends on the weight coefficients α, β and γ.
The future research will explore the effects of various parameters on model performance, namely, the weight factor of constraint, the size of background blocks, the step size, and the segmentation threshold. In actual practice, the parameter values should be determined according to the specific image. Therefore, more attention will be paid to select suitable parameters in an adaptive manner.
[1] Kim, S., Lee, J. (2012). Scale invariant small target detection by optimizing signal-to-clutter ratio in heterogeneous background for infrared search and track. Pattern Recognition, 45(1): 393-406. http://doi.org/10.1016/j.patcog.2011.06.009
[2] Coppo, P. (2015). Simulation of fire detection by infrared imagers from geostationary satellites. Remote Sensing of Environment, 162: 84-98. http://doi.org/10.1016/j.rse.2015.02.016
[3] Du, P., Hamdulla, A. (2019). Infrared small target detection using homogeneity-weighted local contrast measure. IEEE Geoscience and Remote Sensing Letters, 17(3): 514-518. http://doi.org/10.1109/LGRS.2019.2922347
[4] Seyed, M.F., Reza, M.M., Mahdi, N. (2018). Flying small target detection in IR images based on adaptive toggle operator. IET Computer Vision, 12(4): 527-534. http://doi.org/10.1049/iet-cvi.2017.0327
[5] Bae, T.W., Kim, Y.C., Ahn, S.H., Sohng, K.I. (2010). A novel Two-Dimensional LMS (TDLMS) using sub-sampling mask and step-size index for small target detection. IEICE Electron Express, 7(3): 112-117. http://doi.org/10.1587/elex.7.112
[6] Soundrapandiyan, R., Chandra Mouli, P.V.S.S.R. (2017). Adaptive pedestrian detection in infrared images using fuzzy enhancement and top-hat transform. International Journal of Computational Vision and Robotics, 7(1/2): 49. http://doi.org/10.1504/IJCVR.2017.10001816
[7] Roy, A., Singha, J., Manam, L., Laskar, R. H. (2017). Combination of adaptive vector median filter and weighted mean filter for removal of high-density impulse noise from colour images. IET Image Processing, 11(6): 352-361. http://doi.org/10.1049/iet-ipr.2016.0320
[8] Deshpande, S.D., Er, M.H., Ronda, V., Chan, P. (1999). Max-mean and max-median filters for detection of small targets. Proceedings of SPIE - The International Society for Optical Engineering, 3809: 74-83. http://doi.org/10.1117/12.364049
[9] Karali, A.O., Aytaç, T. (2013). A wavelet coefficients based dynamic range compression technique for infrared images. 21st Signal Processing and Communications Applications Conference (SIU), Haspolat, Turkey, pp. 1-4. http://doi.org/10.1109/SIU.2013.6531510
[10] Heshmati, A., Gholami, M., Rashno, A. (2016). Scheme for unsupervised colour-texture image segmentation using neutrosophic set and non-subsampled contourlet transform. IET Image Processing, 10(6): 464-473. http://doi.org/10.1049/iet-ipr.2015.0738
[11] Liu, D.M., Chang, F.L. (2019). Coarse-to-fine saliency detection based on non-subsampled contourlet transform enhancement. Acta Optica Sinica, 39(1): 380-387. http://doi.org/10.3788/AOS201939.0115003
[12] Kim, S., Yang, Y.; Lee, J., Park, Y. (2009). Small target detection utilizing robust methods of the human visual system for IRST. Journal of Infrared, Millimeter, Terahertz Waves, 30(9): 994-1011. http://doi.org/10.1007/s10762-009-9518-2
[13] Jian, C.F., Lu, T., Xiang, X.Y., Zhang, M.Y. (2018). An improved mixed gaussian-based background modelling method for fast gesture segmentation of mobile terminals. Traitement du Signal, 35(3-4): 243-252. https://doi.org/10.3166/TS.35.243-252
[14] Lee, S., Lee, C. (2016). Illumination normalization and skin color validation for robust face detection. Electronic Imaging, 19: 1-6. http://doi.org/10.2352/ISSN.2470-1173.2016.19.COIMG-176
[15] Chen, C.L.P., Li, H., Wei, Y., Xia, T., Tang, Y.Y. (2013). A local contrast method for small infrared target detection. IEEE Transactions on Geoence & Remote Sensing, 52(1): 574-581. http://doi.org/10.1109/TGRS.2013.2242477
[16] Moradi, S., Moallem, P., Sabahi, M.F. (2018). A false-alarm aware methodology to develop robust and efficient multi-scale infrared small target detection algorithm. Infrared Physics & Technology, 89: 387-397. http://doi.org/10.1016/j.infrared.2018.01.032
[17] Shahid, N., Kalofolias, V., Bresson, X., Bronstein, M., Vandergheynst, P. (2015). Robust principal component analysis on graphs. 2015 IEEE International Conference on Computer Vision (ICCV), pp. 2812-2820. http://doi.org/10.1109/ICCV.2015.322
[18] Ibrahim, R., Alirezaie, J., Babyn, P. (2015). Pixel level jointed sparse representation with RPCA image fusion algorithm. International Conference on Telecommunications & Signal Processing, pp. 592-595. http://doi.org/10.1109/TSP.2015.7296332
[19] Wan, M.J., Gu, G.H., Qian, W.X., Ren, K., Chen, Q. (2016). Robust infrared small target detection via non-negativity constraint-based sparse representation. Applied Optics, 55(27): 7604-7612. http://doi.org/10.1109/TSP.2015.7296332
[20] Gao, C.Q., Meng, D.Y., Yang, Y., Wang, Y.T., Zhou, X.F., Hauptmann, A.G. (2013). Infrared patch-image model for small target detection in a single image. IEEE Transactions on Image Processing, 22(12): 4996-5009. http://doi.org/10.1109/TIP.2013.2281420
[21] Candès, E.J., Li, X.D., Ma, Y., Wright, J. (2011). Robust principal component analysis. Journal of the ACM (JACM), 58(3): 11-50. http://doi.org/10.1145/1970392.1970395
[22] He, Y.J., Li, M., Zhang J.L., An, Q. (2015). Small infrared target detection based on low-rank and sparse representation. Infrared Physics & Technology, 68: 98-109. http://doi.org/10.1016/j.infrared.2014.10.022
[23] Dai, Y.M., Wu, Y.Q., Song, Y., Guo, J. (2017). Non-negative infrared patch-image model: Robust target-background separation via partial sum minimization of singular values. Infrared Physics & Technology, 81: 182-194. http://doi.org/10.1016/j.infrared.2017.01.009
[24] Guo, J., Wu, Y.Q., Dai, Y.M. (2018). Small target detection based on reweighted infrared patch-image model. IET Image Processing, 12(1): 70-79. http://doi.org/10.1049/iet-ipr.2017.0353
[25] Rudin, L.I., Osher, S., Fatemi, E. (1992). Nonlinear total variation based noise removal algorithms. Physica D Nonlinear Phenomena, 60(1-4): 259-268. http://doi.org/10.1016/0167-2789(92)90242-F
[26] Liu, A., Zhou, D.H., Chen, M.Y. (2016). A robust crater detection and recognition method based on blocked principal components analysis. Journal of Beijing University of Posts and Telecommunications, 39(1): 63-67. http://doi.org/10.13190/j.jbupt.2016.01.011
[27] Wang, P.C. (2018). Research on key techniques of target detection and tracking in the ground scene. Nanjing: Nanjing University of Science & Technology.
[28] Sakurai, M., Kiriyama, S., Goto, T. (2011). Fast algorithm for total variation minimization. 18th IEEE International Conference on Image Processing (ICIP). Brussels, Belgium, pp. 1461-1464. http://doi.org/10.1109/ICIP.2011.6115718
[29] Liao, F., Coatrieux, J.L., Wu, J., Shu, H. (2015). A new fast algorithm for constrained four-directional total variation image denoising problem. Mathematical Problems in Engineering, (2): 1-11. http://doi.org/10.1155/2015/815132
[30] Chen, P.Y., Selesnick, I.W. (2014). Group-sparse signal denoising: non-convex regularization, convex optimization. IEEE Transactions on Signal Processing, 62(13): 3464-3478. http://doi.org/10.1109/TSP.2014.2329274
[31] Chen, P.Y., Selesnick, I.W. (2014). Translation-invariant shrinkage/thresholding of group sparse signals. Signal Processing, 94(1): 476-489. http://doi.org/10.1016/j.sigpro.2013.06.011
[32] Selesnick, I.W., Farshchian, M. (2017). Sparse signal approximation via nonseparable regularization. IEEE Transactions on Signal Processing, 65(10): 2561-2575. http://doi.org/10.1109/TSP.2017.2669904
[33] Hilliard, C.I. (2000). Selection of a clutter rejection algorithm for real-time target detection from an airborne platform. Proceedings of SPIE-The International Society for Optical Engineering, 4048: 74-84. http://doi.org/10.1117/12.392022