Kutlucan Gorur* | Mehmet Recep Bozkurt | Muhammet Serdar Bascil | Feyzullah Temurtas
© 2019 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The tongue is one of the few organs with high mobility in the case of severe spinal cord injuries. However, most tongue-machine interfaces (TMIs) require the patient to wear obtrusive and unhygienic devices in and around the mouth. This paper aims to develop a TMI based on the glossokinetic potentials (GKPs), i.e. the electrical signals generated by the tongue when it touches the buccal walls. Ten patients were recruited for this research. The GKP patterns were classified by convolutional neural network (CNN) and support vector machine (SVM). It was observed that the CNN outperformed the SVM in individual and average scores for both raw and preprocessed datasets, reaching an accuracy of 97~99%. The CNN-based GKP processing method makes it easy to build a natural, appealing and robust TMI for the paralyzed. Being the first attempt to process GKPs with the CNN, our research offers an alternative to the traditional brain-computer interfaces (BCIs), which suffers from the instability and low signal-to-noise ratio (SNR) of electroencephalography (EEG).
glossokinetic potential signals (GKPs), tongue-machine interface (TMI), convolutional neural network (CNN), support vector machine (SVM), brain-computer interface (BCI)
The spinal cord injuries (SCIs) and neuromuscular disorders are the main problems for the paralyzed individuals. Most of the disabled population needs special cares and continuous help via assistive technologies [1]. The tongue has complex muscles that enable any movement with poor fatigue. The tip of the tongue has a negative charge with respect to the root. Glossokinetic potential responses are generated via discharging bioelectric signals due to the tip of the tongue touching inside the mouth. GKP occurs in low frequencies (mostly in the delta bands rarely in theta bands) and originates from the noncerebral region [2-6]. Therefore, it is incurred less deterioration and does not easily interfere with the alpha and beta bands arisen by the active brain signals. Moreover, the tongue is directly innervated to the brain via cranial nerves. Hence, it is slowly affected organ by the SCIs and degenerative neuromuscular disorders, such as amyotrophic lateral sclerosis (ALS) [3]. The purpose of this paper is to offer a natural, easy-to-use, cosmetically acceptable and reliable 1-D tongue-machine interface model implementing CNN architecture and SVM algorithm by investigating GKPs measured over the scalp. Tracking tongue movements via touching the buccal walls with the tip of the tongue has the potential of the proper and accurate direction to control the ATs and therefore to enhance the quality of life (QoL) for disabled people. This research study also consists of the ongoing investigation and comparison of the machine learning algorithms on GKPs [5, 6].
Furthermore, psychophysical papers regarding the sensitivity and discrimination exhibit that some oral structures, including the tongue tip, are more sensitive than the fingertip and may provide promising results for a tongue-machine interface [7-9]. Traditional synchronous EEG-based BCIs have loss of control (LoC) and degrees of freedom (DoF) problems emerged from the nonstationarity of EEG signals, highly cognitive workload and the mental state of the user. In turn, the influence of user performance such as self-efficacy might form positive or negative feedback in BCIs [10, 11]. On the other hand, long training time is needed to gain adequate control for BCI usage [12, 13].
Various assistive technologies operated by tongue have been developed utilizing the stated advantages above in recent years. A tongue-drive system named as “Tongue Rudder” was designed by Nam et.al. In this work, glossokinetic potentials and electromyography (EMG) signals of the clenching jaw were used together to control the real-time wheelchair. GKPs were acquired in special electrode placement on the scalp. The linear features of the measured GKP signals were determined to gain the 1-D movement and clenching the jaw was handled as stop/resume calibration on the system [3]. The other study called "GOM-Face" by the same researchers consisted of the electrooculogram (EOG) signals beside the GKPs and EMG signals to develop a 2-D humanoid robot control in real-time. In the reported work, 1-D control was made by GKP signals and the other 1-D control was implemented by EOG signals to obtain 2-D control channel [4]. However, as our best knowledge, applying state-of-the-art-one method (convolutional neural network) and the shallow classifier (support vector machine) with maximum-peak value (MPV) and shape factor (SF) over the glossokinetic potential responses is the first attempt in a tongue-machine interface research.
Conceptually, numerous ongoing studies based on tongue-drive systems have pieces of equipment inside and around the mouth. Huo et al. have employed a small permanent magnet fixated on the tongue as a tracer. Then the array of magneto-inductive sensors assembled in the oral cavity on a dental retainer or outside like an orthodontic brace on a headset perceives induced magnetic variations due to the tongue motions. The signals of intentions are transmitted in the wireless communication to the smartphones or computers to be decoded and processed [1, 14-16]. Electrotactile interface pressured by the tongue on the roof of the mouth is another experimental system [5]. This type of physical concepts is irritating, aesthetically unappealing and unhygienic solutions for paralyzed individual satisfaction. Besides these, the user’s speech, ingestion, and breathing may be influenced by bulky components inside the oral cavity. Vaidyanathan et al. have developed the approach of the airflow pressure changes due to the tongue movements in the ear canal. Although the classification accuracy of 97 % was achieved with decision fusion classification algorithm in the study, the ear listening performances and comforts might be degraded for the patients due to the microphone attached in the ear canal [17-19]. However, in our study, glossokinetic potential based approach has simple tongue contacts on the buccal walls and does not affect listening fulfillments. Moreover, the classification accuracy was also reached up to the 100 % with CNN architecture.
The leftovers of this paper are structured as it follows: Section 2 presents theoretical method, the results obtained are presented in Section 3, the Section 4 and 5 reviews the discussion and conclusion, respectively.
In this research study, ten subjects, aged 22 to 34 years, participated in three offline experimental setups to be measured glossokinetic potential responses related to the tongue touchings to the buccal walls as shown in Figure 1. International 10-20 electrode placement system was implemented with nineteen channels in acquisition the signals [20]. Left-right earlobes (A1-A2) were described as reference and left-eyebrow assigned as ground. EEG frequency bands and the monopolar placement for EEG electrodes are shown in Table 1 and 2, respectively.
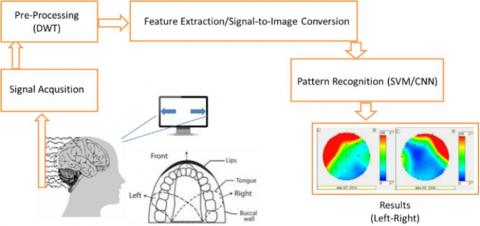
Figure 1. The workflow presentation of the tongue-machine interface using glossokinetic potential responses
GKP responses were measured by EEG signal acquisition device benefiting the Micromed SAM32RFO and all impedances were kept below 10kΩ. Each channel was sampled at 1024 Hz and filtered between 0.5-100 Hz. Moreover, a 50-Hz notch filter was carried out to eliminate the power line noise. After that, for the part of the SVM algorithm process, 10th order infinite impulse response (IIR) Butterworth low-pass filter was applied with a 40 Hz cut-off frequency [21]. After filtering operation and discrete wavelet transform technique, the raw data set for SVM is normalized according to Eq. (1) in the range 0-1.
$X_{S}^{\text {norm}}=\frac{X_{S}-X_{\min }}{X_{\max }-X_{\min }}$ (1)
XS represents the sth value, Xmax and Xmindefine the maximum and minimum value in the raw data set, respectively [22].
Table 1. EEG frequency bands [11-12]
|
Delta |
1-4 Hz |
|
Teta |
4-8 Hz |
|
Alpha |
8-12 Hz |
|
Beta |
13-30 Hz |
|
Gamma |
30 Hz ≤ |
Table 2. The list of EEG electrodes for monopolar placement.
|
Channel Number |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
|
Channel Name |
Fp2 |
Fp1 |
F7 |
F3 |
Fz |
F4 |
F8 |
T3 |
C3 |
Cz |
C4 |
T4 |
T5 |
P3 |
Pz |
P4 |
T6 |
O1 |
O2 |
Then, the feature extraction operations were implemented from the raw signal to feature vector for highlighting essential data. In this study, maximum-peak value and shape factor were used for SVM algorithm as feature extraction processes, both of them is in the time domain [23-24]. In the part of the proposed study related to CNN, firstly the signal-to-image conversion method was handled to convert 1-D time series of the raw signals to 2-D time series grayscale images to be classified in CNN structure [25-27]. DWT is also employed for the part of the CNN study before the signal-to-image conversion to investigate the effect of extraction delta and theta frequencies [2, 28].
2.1 Data collection
Eight male and two female naive healthy subjects participated in this study, who did not have any nervous system impairment. The participants were seated in front of the LCD monitor and instructed not to move any part of the body except tongue motions during the tasks of the trials. A total of twelve trials were obtained for each participant, with four trials for each experimental setup. The greatest trial of each participant was selected by comparing the accuracy results in machine learning (ML) algorithms. Then, this relevant trial is used to produce the results for the process of the SVM algorithm. However, CNN needs to use more data set for reliability and higher results. Hence, twelve trials for each subject were used for CNN.
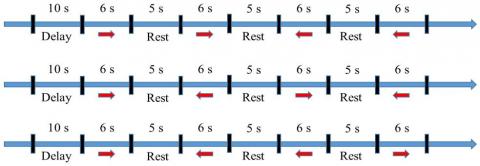
The recorded trial of each consists of 98 seconds and starts after the 10 s delay. Distinct mental activities and short response time are required to provide satisfactory recognition accuracy in BCI signals [29-30]. The user is instructed to perform multiple distinct touchings via tongue on the buccal walls. Therefore better patterns of GKPs on the scalp can be produced for the machine learning algorithms. The time of the task was determined as the 6 s for the GKP signals. Then, the resting intervals last 5 s between the 6 s durations of tongue contacts and expected no motion between these resting intervals. All participants were expected to make four right and four left tongue movements properly according to the experimental sequences represented in Figure 2. There are nearly ten multiple distinct contacts on the buccal walls during each 6 s duration.
Figure 2. Sequences of the three experimental setups for tongue motions in the study
2.2 Discrete wavelet transform
To analyze and extract useful information from the non-stationary signals, discrete wavelet transform (DWT) is a powerful tool in signal processing applications [31]. DWT is employed to separate the different frequency bands of the signal, especially EEG [32]. Hence, classification accuracy can be enhanced by extracting different features of the signal [32-33]. In this study, a discrete wavelet transform technique was applied for the extraction of delta and theta frequency bands of the glossokinetic potential signals to obtain better results in classification. The recorded data signals x(n) with a sampling frequency of 1024 Hz, the wavelet type ($\psi^{*}$) of db10 (Daubechies) at the 6th level was used to extract the delta and theta bands of GKP responses.
$D W T(a, b)=\frac{1}{\sqrt{a}} \sum_{n} x(n) \psi^{*}\left(\frac{n-b}{a}\right)$ (2)
The mathematical relation of DWT is in Eq. (2), where a and b are translation and scaling parameters, respectively [34].
2.3 Feature extraction and signal-to-image conversion
In order to highlight to the feature set from the raw data set, feature extraction operations are employed in traditional classifiers. Time domain feature extraction methods, involving the maximum-peak value (MPV) and shape factor (SF) were applied in this study for the shallow classifier SVM. The mathematical relations for the MPV and SF are in Eqns. (3)-(4), respectively.
$x_{p}=\max |x(n)|$ (3)
$S F=\frac{x_{r m s}}{\frac{1}{N} \sum_{n=1}^{N} \sqrt{|x(n)|}}$ (4)
where, x(n), n= 1,2, N denote a time series signal and N means the number of data points [23]. The recorded data sets are (6×8×1024)×19 dimension for each participant, in which 6 means six second duration for multiple contacts in a trial, 8 means the number of total direction of the tongue movements to the buccal walls (4 right and 4 left) shown in experimental setup sequences, 1024 stands for the sampling frequency and 19 are the recording channel numbers. Since it covers all EEG frequencies along feature extraction, 100 ms was selected to generate the feature vector. If 1 second of data is determined as 1024 / 100ms = 10 parts (approx.), then (6x8x10) equals the data length of 480 (approx.). However, some participants were unable to begin and end sessions at definite times during the experiments. For this reason, the data set had been cut out and defined it for each participant as 400x19 dimension.
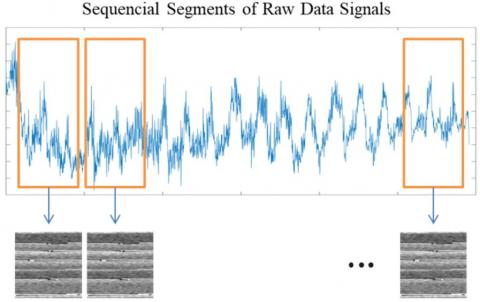
In CNN architecture, converted images of the 2-D time series of GKP signals are needed to be classified as right / left direction. In this signal-to-image conversion method, 1-D time series of the raw data signals fulfill the pixels of the image by the sequence of 2-D time series in grayscale images represented in Figure 3. The segments of the raw data signals are extracted sequentially in the length of M2 to have an M×M pixel size of image. The mathematical equation of the conversion is shown in Eq. (5).
$P(j, k)=$round$\left\{\frac{L((j-1) \times M+k)-\operatorname{Min}(L)}{\operatorname{Max}(L)-\operatorname{Min}(L)} \times 255\right\}$ (5)
where, L(i), i=1, …M2 indicate the value of the segment signals and P (j, k), j=1, …M, k=1, …M. Each pixel value of the grayscale image is normalized by round function from 0 to 255 [27].
Figure 3. The signal-to-image conversion method for GKP signals (Each image is in the 102×102 pixel size)
CNN's advantage is that the feature extraction and feature selection operations are unnecessary. However, the main drawback of CNN is the need of the high rate of a data set to have robust and great results [35]. Therefore, twelve trials for each participant has been used to have 2-D time series images as shown in the procedure of the Figure 3. Then, 100 ms was decided to form the 102×102 pixel size of square images from the 1-D time series. Hence, each trial consisting of nineteen channels can produce 38 square images for each direction (right or left). Finally, twelve trials have achieved to provide 12×38=456 images for each direction/class. Then, the eleven channels results were found in the same procedure, and 22 square images were generated. Therefore, in twelve trials 12×22=264 images were obtained totally for each direction.
2.4 Performance measurement criteria and machine learning methods
In the classification of glossokinetic potentials, we have used the classification accuracy (ACC), sensitivity (SENS), specificity (SPEC) and information transfer rate (ITR) values to test the performance of proposed methods. k-fold cross-validation technique was also applied to survey the stability of the results, and then 10-fold was chosen in the processing of the shallow method SVM. However, the traditional 50 % training and 50 % test data set separation technique was selected for CNN. The represented mathematical equations for the correctness of the classification in Eqns. (6)-(8).
Accuracy$(T S)=\frac{\sum_{i=1}^{|TS|} estimate_ { }\left(n_{i}\right)}{|T S|}, \quad \quad n_{i} \in T S$ (6)
Estimate$(n)=\left\{\begin{array}{l}{1, \text { if estimate }(n)=\mathrm{cn}} \\ {0, \text { otherwise }}\end{array}\right.$ (7)
Classification accuracy $=\frac{\sum_{i=1}^{|k|} \operatorname{accuracy}\left(T S_{i}\right)}{|k|}$ (8)
where, TS refers the test data set to be classified, while n∈TS, cn is the class of n. Moreover, estimate(n) means for the classification result of n, k is the k-fold cross validation number [36, 37]. True positive (TP), true negative (TN), false positive (FP), and false negative (FN) are the fundamental evaluation parameters provided for the sensitivity (SENS) and specificity (SPEC) in receiver operating characteristic (ROC) analysis [37], shown in Eqns. (9)-(10).
Sensitivity $=\frac{T P}{T P+F N}$ (9)
Specificity$=\frac{T N}{T N+F P}$ (10)
Most of the EEG-based BCI systems, information transfer rate (ITR) is a characteristic parameter discovering the transmitted data information per trial or time. In our study, ITR was utilized to measure the system performance of tongue-machine interface using the GKP signals. The mathematical equation for ITR is in Eq. (11).
$B=\log _{2} N+P \log _{2} P+(1-P) \log _{2} \frac{(1-P)}{(N-1)}$ (11)
where, B defines the number of bits per trial, N stands for different types of classes, and the correctness of classification is named as P. When the number of various mental functions in a BCI system increases, the ITR increases in value (0-1) [38-39].
2.4.1 Support vector machine
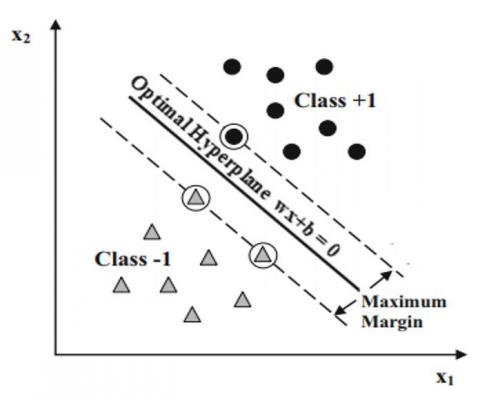
Support vector machine (SVM) is a kernel-based machine learning algorithm and is used in bio-signal classification. SVM determines the support vectors to discriminate the decision boundary (hyperplane). The distance from the hyperplane to the nearest support vectors to both sides is called as the margin. Thus the goal is to maximize the margin and find the optimal hyperplane for generalization ability [36, 40], as shown in Figure 4.
$X\{t\}=\left\{\begin{array}{l}{r^{t}=+1, x^{t} \in C 1} \\ {r^{t}=-1, x^{t} \in C 2}\end{array}\right.$ (12)
$g(x)=\left\{\begin{array}{l}{w^{T} x^{t}+w_{0} \geq+1, x^{t} \in C 1} \\ {w^{T} x^{t}+w_{0} \leq-1, x^{t} \in C 2}\end{array}\right.$ (13)
$r^{t}\left(w^{T} x^{t}+w_{0}\right) \geq+1$ (14)
where, in the Eqns. (12)-(14), the hyperplane is defined by g(x), w0 localizes the hyperplane and w stands for the orientation. SVM does not need to carry out the parameters such as learning rate, initializations and checking for convergence [40].
Figure 4. SVM and maximizing the hyperplane margin for 1-D time series of the GKP signals [36]
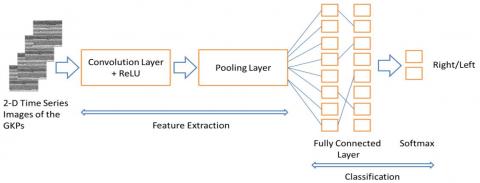
2.4.2 Convolutional neural network
Convolutional neural network (CNN) is the state-of-art technique for computer vision, speech recognition, and natural language processing. Meanwhile, CNN has also shown remarkable performance in multi-channel EEG signal processing with challenging data sets with considerable inter-and intra-subject variability [25]. The CNN structure has three major layers consisting of the convolutional layer, pooling layer, and a fully connected layer [27, 35]. The convolutional layer has filters (kernels) which are the matrix to be convolved with the pixels of image-based 2-D time series signals. Convolutional layers aim to extract different features involving the edges, lines, and corners [41]. The mathematical relation of the convolutional operator is as follows in Eq. (15).
$y_{k}=\sum_{n=0}^{N-1} x_{n} h_{k-n}$ (15)
where, x is time series of a signal, h means the kernel, N stands for the number of data of x, and y is the feature map or output vector [35]. The pooling layer is used for reducing the dimension of the feature maps and is named as the down-sampling layer. Hence, overfitting and computational complexity are alleviated by pooling layer operation. Then fully layers determine the class score. There are two types of activation functions in this study: (1) Rectified Linear Activation Unit (2) Softmax.
Rectified Linear Activation Unit (ReLU): There is common practice to apply an activation function after each convolutional layer. ReLU provides nonlinearity to the network structure, represented in Eq. (16) [35, 41].
$f(x)=\left\{\begin{array}{cc}{x,} & {x \geq 0} \\ {0,} & {x<0}\end{array}\right.$ (16)
Softmax: This function is used to compute the probability of the k output class. The related equation of softmax is shown in Eq. (17).
$p_{j}=\frac{e^{x_{j}}}{\sum_{1}^{k} e^{x_{k}}} \quad j=1, \ldots k$ (17)
where, x is the input of the net. The values of the output are in the range of 0 and 1 and their summation is 1 [35].
In our study, the CNN architecture has included one convolution layer with the kernel size as 5 in different number of kernel numbers from 5 to 20. Moreover, the maximum pooling layer kernel size was 2 and the stride number was chosen as 5.
Figure 5. The structure of the CNN model
The main aim of this research study is to lead developing a tongue-machine interface via investigating and comparing the state-of-the-art method (convolutional neural network) and the shallow algorithm performances (support vector machine) on glossokinetic potential responses. Maximum-peak value and shape factor were utilized in feature extraction algorithm for SVM. Moreover, the signal-to-image conversion method was employed for CNN architecture. Furthermore, discrete wavelet transform was also applied in preprocessing to extract delta and theta frequencies. The data set of the 11-channel (Frontal + Temporal region) signals were also calculated for SVM and CNN methods. All the results in the whole article were processed by machine learning algorithms from the data sets and gray-scale images below:
The best and worst participants were highlighted by the results of the raw and preprocessed data sets indicated in Table 3 to distinguish and compare easily throughout the article. Then, the statements and implications of findings were stated according to the best and worst participants in the paper. All the results obtained are presented in the decimal base and percentage expression (%), excluding ITR results.
Table 3. The support vector machine results of the raw data set and preprocessed data set by DWT (400x19)
|
C .Fea/S. |
.. |
Sub_1 |
Sub_2 |
Sub_3 |
Sub_4 |
Sub_5 |
Sub_6 |
Sub_7 |
Sub_8 |
Sub_9 |
Sub_10 |
Aver. |
|
MPV (RAW) |
Acc |
79 |
97,25 |
77,05 |
80,06 |
88,32 |
94,15 |
86,19 |
79,70 |
79,48 |
96,07 |
85,73 |
|
Sens |
84,6 |
97,5 |
80,45 |
80,56 |
91,25 |
96,63 |
84,52 |
78,52 |
78,32 |
97,39 |
86,97 |
|
|
Spec |
71,55 |
97,04 |
72,57 |
79,34 |
84,40 |
90,68 |
88,38 |
81,39 |
81,36 |
94,42 |
84,11 |
|
|
ITR |
0,259 |
0,819 |
0,223 |
0,279 |
0,480 |
0,678 |
0,421 |
0,272 |
0,268 |
0,761 |
0,446 |
|
|
SF (RAW) |
Acc |
80,03 |
97,02 |
74,10 |
80,02 |
90,59 |
94,64 |
86,16 |
78,15 |
75,33 |
95,03 |
85,11 |
|
Sens |
86,78 |
97,50 |
82,23 |
82,23 |
90,78 |
96,63 |
85,93 |
77,59 |
75,80 |
95,69 |
87,12 |
|
|
Spec |
70,67 |
96,59 |
63,32 |
76,97 |
90,15 |
91,54 |
86,47 |
78,81 |
74,85 |
94,06 |
82,34 |
|
|
ITR |
0,279 |
0,806 |
0,175 |
0,279 |
0,550 |
0,699 |
0,420 |
0,243 |
0,194 |
0,715 |
0,436 |
|
|
MPV (DWT) |
Acc |
81,12 |
98,01 |
79,52 |
76,32 |
93,02 |
96,07 |
89,05 |
73,23 |
79,19 |
97,02 |
86,25 |
|
Sens |
85,93 |
98,00 |
83,95 |
78,37 |
94,58 |
97,07 |
85,43 |
66,03 |
77,01 |
98,26 |
86,46 |
|
|
Spec |
74,82 |
98,00 |
73,80 |
73,62 |
89,84 |
94,62 |
93,00 |
82,56 |
82,03 |
95,34 |
85,76 |
|
|
ITR |
0,301 |
0,859 |
0,269 |
0,210 |
0,635 |
0,761 |
0,502 |
0,162 |
0,262 |
0,807 |
0,477 |
|
|
SF (DWT) |
Acc |
79,32 |
98,00 |
78,02 |
73,83 |
91,24 |
96,01 |
86,16 |
73,26 |
78,01 |
97,05 |
85,09 |
|
Sens |
82,79 |
98,00 |
84,33 |
76,61 |
92,45 |
97,01 |
83,98 |
75,89 |
79,62 |
96,96 |
86,76 |
|
|
Spec |
74,54 |
97,99 |
69,69 |
69,68 |
89,08 |
94,80 |
88,66 |
70,21 |
75,75 |
97,16 |
82,76 |
|
|
ITR |
0,265 |
0,859 |
0,240 |
0,171 |
0,572 |
0,758 |
0,420 |
0,162 |
0,240 |
0,808 |
0,449 |
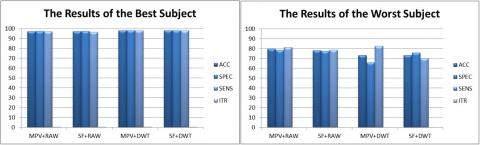
The results in Table 3 have shown that Subject_2 has achieved with the highest accuracy performance of 98.01 % in the MPV+DWT method. Meanwhile, the lowest accuracy result (73.23 %) was obtained by Subject_8 in MPV+DWT. Therefore, according to this raw data set results, the best and worst subjects were observed as Subject_2 and Subject_8 respectively, as shown in Figure 6. The accuracy difference between the best and worst participant is relatively high and is about 24.78 value. Hence, the inter-subject variability among the participants was observed significantly. Moreover, concerning the average scores, MPV+DWT has provided 86.25 % classification accuracy for the shallow SVM algorithm. Furthermore, DWT has advanced the outcomes around 0.52 % for MPV extraction method.
In Table 4, frontal and temporal region signals were presented in eleven-channels extracted from the raw data set. These results explicitly show that the best participant has achieved almost the same performance (98.03 %) compared to the accuracy of the raw data set results (98.01 %). However, the performance of the worst subject has declined in either extraction methods and DWT preprocessing outcomes. The highest accuracy value (79.02 %) of the worst subject decreased in 0.68 accuracy in MPV+RAW. Then, MPV+DWT has provided the greatest score (84.70 % accuracy) in average, as well as in the raw data set results.
The state-of-the-art machine learning algorithm CNN has outperformed results compared to the shallow classifier SVM for raw and preprocessed data sets in all subjects, as shown in Table 5. The best (99.78 %) and worst (97.37 %) participants have close results for the highest accuracy in the raw data sets. Moreover, the other subjects' scores are around 97-99 %, as well as the average results (98.71) for the raw data set. Discrete wavelet transform was used to preprocess the raw data set before the signal-to-image conversion in the gray-scale images. Then, the effect of the DWT on the CNN architecture may have disturbed the pattern of the 2-D time series images. Hence, inter-subject variability (95-99 %) and the highest average score (97.02 %) are higher than the raw data set results in CNN architecture.
In Table 6, eleven channel signals measured from the frontal and temporal regions have provide 100 % accuracy for four subjects in CNN architecture. In comparative achievement with the SVM for the eleven channel results (84.70 %), CNN has improved the highest average score (97.40 %) as 12.70 accuracy.
The breakthrough success on recognizing the pattern of the glossokinetic potential responses on the scalp was observed powerful performance via CNN structure employing the 2-D time series gray-scale images.
Figure 6. The raw data set and preprocessed data set classification performances the best subject with SVM (left), the worst subject with SVM (right)
Table 4. The support vector machine results of the raw data set and preprocessed data set by DWT related to the extracted frontal and temporal region signals (400x11)
|
C.Fea/S. |
.. |
Sub_1 |
Sub_2 |
Sub_3 |
Sub_4 |
Sub_5 |
Sub_6 |
Sub_7 |
Sub_8 |
Sub_9 |
Sub_10 |
Aver. |
|
MPV (RAW) |
Acc |
78,08 |
97,01 |
77,03 |
71,06 |
88,52 |
93,06 |
86,13 |
79,02 |
73,03 |
95,07 |
83,80 |
|
Sens |
85,53 |
98,00 |
81,88 |
80,13 |
91,25 |
94,47 |
83,12 |
76,28 |
67,54 |
96,11 |
85,43 |
|
|
Spec |
68,22 |
95,99 |
70,79 |
57,88 |
84,37 |
91,50 |
89,41 |
82,31 |
80,14 |
93,74 |
81,44 |
|
|
ITR |
0,241 |
0,806 |
0,223 |
0,132 |
0,486 |
0,636 |
0,419 |
0,259 |
0,159 |
0,716 |
0,408 |
|
|
SF (RAW) |
Acc |
78,02 |
96,24 |
73,06 |
70,07 |
87,27 |
93,17 |
85,08 |
77,24 |
74,57 |
95,18 |
82,99 |
|
Sens |
83,36 |
97,50 |
78,08 |
79,22 |
89,11 |
95,40 |
82,73 |
79,45 |
71,79 |
96,97 |
85,36 |
|
|
Spec |
70,91 |
94,88 |
66,56 |
57,68 |
84,19 |
89,73 |
87,83 |
74,23 |
78,10 |
92,53 |
79,66 |
|
|
ITR |
0,240 |
0,769 |
0,159 |
0,120 |
0,450 |
0,641 |
0,392 |
0,226 |
0,182 |
0,721 |
0,390 |
|
|
MPV (DWT) |
Acc |
81,19 |
98,02 |
78,3 |
70,12 |
92,01 |
95,00 |
88,31 |
72,27 |
75,30 |
96,44 |
84,70 |
|
Sens |
86,4 |
98,5 |
83,08 |
77,05 |
93,73 |
96,20 |
86,39 |
72,25 |
70,60 |
97,41 |
86,16 |
|
|
Spec |
74,01 |
97,57 |
72,33 |
60,75 |
89,73 |
93,21 |
90,64 |
72,21 |
81,76 |
95,14 |
82,74 |
|
|
ITR |
0,303 |
0,860 |
0,245 |
0,120 |
0,598 |
0,714 |
0,480 |
0,148 |
0,194 |
0,778 |
0,444 |
|
|
SF (DWT) |
Acc |
79,48 |
98,03 |
79,07 |
67,37 |
90,04 |
94,03 |
85,96 |
70,40 |
74,72 |
96,02 |
83,51 |
|
Sens |
84,07 |
98,5 |
83,93 |
77,55 |
92,08 |
95,38 |
83,48 |
71,03 |
75,29 |
96,11 |
85,74 |
|
|
Spec |
74,39 |
97,59 |
73,12 |
54,27 |
87,22 |
92,30 |
88,56 |
69,58 |
73,92 |
95,94 |
80,69 |
|
|
ITR |
0,268 |
0,86 |
0,26 |
0,089 |
0,532 |
0,674 |
0,415 |
0,124 |
0,184 |
0,758 |
0,416 |
Table 5. The convolutional neural network results of the gray-scale images of the raw data set and preprocessed data set by DWT for both direction (456x2)
|
C.Fea/S. |
.. |
Sub_1 |
Sub_2 |
Sub_3 |
Sub_4 |
Sub_5 |
Sub_6 |
Sub_7 |
Sub_8 |
Sub_9 |
Sub_10 |
Aver. |
|
CNN (RAW) |
Acc |
99,56 |
99,78 |
98,46 |
99,12 |
99,34 |
97,37 |
97,81 |
97,37 |
99,12 |
99,12 |
98,71 |
|
Sens |
99,12 |
99,56 |
99,12 |
99,56 |
99,56 |
98,68 |
97,81 |
95,61 |
99,12 |
100 |
98,82 |
|
|
Spec |
100 |
100 |
97,81 |
98,68 |
99,12 |
96,05 |
97,81 |
99,12 |
99,12 |
98,25 |
98,60 |
|
|
ITR |
0,959 |
0,977 |
0,886 |
0,927 |
0,943 |
0,824 |
0,847 |
0,824 |
0,927 |
0,927 |
0,904 |
|
|
CNN (DWT) |
Acc |
98,46 |
98,46 |
96,05 |
98,25 |
99,12 |
95,39 |
95,61 |
95,83 |
95,83 |
97,15 |
97,02 |
|
Sens |
99,12 |
99,12 |
96,93 |
98,68 |
100,0 |
96,49 |
98,68 |
95,18 |
96,93 |
96,93 |
97,81 |
|
|
Spec |
97,81 |
97,81 |
95,18 |
97,81 |
98,25 |
94,30 |
92,54 |
96,49 |
94,74 |
97,37 |
96,23 |
|
|
ITR |
0,886 |
0,886 |
0,760 |
0,873 |
0,927 |
0,730 |
0,740 |
0,750 |
0,750 |
0,813 |
0,811 |
Table 6. The convolutional neural network results of the gray-scale images of the raw data set related to the extracted frontal and temporal region signals (11-channels) for both direction (264x2)
|
C.Fea/S. |
.. |
Sub_1 |
Sub_2 |
Sub_3 |
Sub_4 |
Sub_5 |
Sub_6 |
Sub_7 |
Sub_8 |
Sub_9 |
Sub_10 |
Aver. |
|
CNN (RAW) |
Acc |
98,61 |
100 |
100 |
100 |
99,24 |
93,56 |
95,08 |
92,05 |
95,45 |
100 |
97,40 |
|
Sens |
100 |
100 |
100 |
100 |
100 |
94,70 |
96,21 |
92,42 |
93,94 |
100 |
97,73 |
|
|
Spec |
97,22 |
100 |
100 |
100 |
98,48 |
92,42 |
93,94 |
91,67 |
96,97 |
100 |
97,07 |
|
|
ITR |
0,894 |
1 |
1 |
1 |
0,936 |
0,655 |
0,716 |
0,599 |
0,733 |
1 |
0,853 |
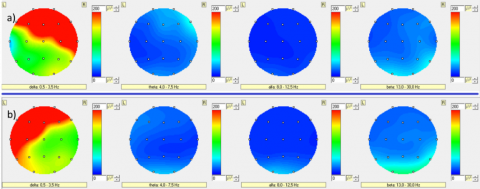
Figure 7. Brain mapping presentation of Subject_2 (the best participant) related the tongue movements (a- frequency bands’ intensities for right buccal wall touchings b- frequency bands’ intensities for left buccal wall touchings)
The best participant has provided distinguishable and clear brain mapping results, presented in Figure 7. The delta frequency bands have high-intensity power distribution over the scalp for both directions of the tongue contact position.
Frontal and temporal regions have significantly exposed to the glossokinetic potential responses in the proper hemisphere of scalp extending to the T5 and T6 electrode leads. Moreover, the theta, alpha, and beta frequency bands have consisted of small magnitudes changes of the GKP responses.
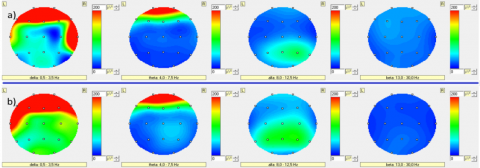
Figure 8. Brain mapping presentation of Subject_8 (the worst participant) related the tongue movements (a- frequency bands’ intensities for right buccal wall touchings b- frequency bands’ intensities for left buccal wall touchings)
The spatial pattern of the glossokinetic potential responses over the scalp for the worst subject was not generated explicitly to be observed the trace of the tongue position in the oral cavity as shown in Figure 8. The magnitude of the power signal variations has occurred high and moderate density on frontal regions including the leads of the Fp1-Fp2 and F7-F8 respectively. Hence, the major difference between the success of the best and worst participant may be the temporal region’s contribution to the delta band activities. Furthermore, theta band intensity of the worst subject was acceptable level on the frontal region, unlike the best subject. The time-frequency analysis using the continuous wavelet transform and scatter plot presentation of the best subject were shown in Figure 9.
Figure 9. Time-frequency analysis presentation of the continuous wavelet transform while touching the right buccal wall of the best participant during 6 s duration in a trial (left) Scatter plot presentation of the classification of the best participant including Channel-1 versus Channel-4 (right)
In this study, the shallow classifier SVM with the MPV+DWT has achieved great results reaching up to the 98 % accuracy in the raw data set, as well as in our previous work obtaining as 94 % accuracy in the mean-value feature extraction method [5]. Moreover, another previous article including the other shallow classifiers, traditional multi-layer neural network (97 % accuracy) with Levenberg Marquardt (LM) and probabilistic neural network (95.29 % accuracy) has not provided greater outcomes than SVM with the MPV+DWT for the maximum value of the raw data set results [6]. On the other hand, even when the number of data increases via using all the trials, there was an expected situation in our research about the breakthrough performance of the CNN that outperformed shallow classifier not only for subject-specific performances but also for the average scores yielding upper the 98.71 % recognizing accuracy. Moreover, the success of the many shallow classifiers depends on the selection of the preprocessing, dimensionality reduction and special feature extraction methods which whole steps require the time-consuming process. However, CNN can realize automatic and influential feature extraction operations via deeper convolution operators without overfitting and preprocessing [42-45].
Furthermore, the discrete wavelet transform technique was applied to extract the delta and theta frequency bands to improve the classification accuracy [28, 46]. Whereas expected improvement for the shallow classifier was realized, the CNN has not achieved better results than the raw data sets before the signal-to-image conversion, as shown in Table 5. This may be occurred from the deterioration of the pattern of the GKP signals by DWT to be recognizable for CNN architecture.
Multidisciplinary research efforts are necessary for the development of the modern brain-machine interface (BMI). These researches unite a variety of information system engineering, statistical signal processing, machine learning, control theory, and information theory [47, 48]. Hence, the remarkable investigation of our research was the contribution and assessment of the frontal + temporal (11-channels) region signals due to the high exposure of glossokinetic potential responses, as represented in Figure 7. The success of the tongue-machine interface with fewer electrodes of the channel selection methods may lead wearable and easy-to-use systems [49, 50]. Then, fewer electrodes can mean less assisted-living help via caregiver for disabled persons in a reliable manner [10, 11]. Moreover, it is worth to note that the success of the frontal + temporal region signals is very close to the raw and preprocessed data set results, represented in Tables 3 and 4 for the SVM algorithm. Then, the performance of the CNN is almost the same with raw and preprocessed data set results for the 11-channel signals, as shown in Tables 5 and 6. Because the CNN has reached almost the peak values. Furthermore, corticomuscular coupling analysis investigates the interaction between the brain regions and ongoing muscular activities (EMG). However, as our best knowledge, the coherence of brain cortex potentials and glossokinetic potential responses in delta and theta bands during the tongue-muscle motor functions were revealed for the first time study in a tongue-machine interface using glossokinetic potential signals [51-52].
In our work, occurring of glossokinetic potential responses symmetrically on the scalp was an unexpected situation according to the related articles observing unsymmetrically on the brain mappings. Because negatively charged tongue tip creating potentially increased and decreased changes on the non-contact and contact surfaces respectively [2-4]. However, the same researchers noted that GKP responses from different spatial and temporal patterns on brain mappings during tongue movements due to the contacting other articulators such as teeth or palate. Furthermore, pronouncing the retroflex consonants cause a strong potential increase over the frontal region during the tongue bending concerning to the language and phonetic research [53]. For this reason in our study, distinct movements when the tongue touches to the buccal walls during experimental tasks might have suppressed an antisymmetric event, as indicated in Fig.7. In the mentioned study, electrode placements, reference point, and experimental procedure were also structured differently from the general manner to observe easier the glossokinetic potential responses. In their research, the tongue was acted in a continuous motion over the right-front-left path to touch the buccal walls [2-4]. However, there are multiple distinct contacts in the same duration of 6 s task in our study. Thus, all these differences can support the assumption of symmetrical results on brain mappings of our article.
Motivation is accepted as a key factor in BCI research. Motivated participants perform much better than participants who are bored of their experimental tasks [54]. This admission may reflect that the best subject was highly motivated and made proper motions via the tongue in distinct and regular in our study. On the other hand, the worst subject has acceptable concentration and might have not correctly done instructed movements via tongue. Inter-trial and inter-subject instability are a significant challenge for the robustness of the BCI system and named as transfer learning techniques [47]. The same situation has been observed for each participant and session-to-session performances of the same subject in our research. Hence, to yield high classification accuracy in large inter and intra-subject variability, more effective and powerful signal processing algorithm must be needed [25, 29]. In this research, CNN has achieved maximum performances for individual and average results in a highly challenging data sets, as indicated in Tables 5 and 6.
Millions of individuals in the world suffer from the spinal cord injuries or motor-related neurological disorders [48]. Voluntary tongue touchings modify the contact surface of the buccal walls and scalp activity generated by the GKPs. Then, using glossokinetic potential responses in a natural, reliable and easy-to-use tongue-machine interface technology can provide a direct communication and control channel for 1-D extraction. This study may extend and serve the literature by implementing the CNN and SVM algorithms with the signal-to-image conversion (gray-scale image) and feature extraction methods (maximum-peak value and shape factor), respectively, in processing GKP biosignals of the tongue-machine interface. The convolutional neural network is a machine learning algorithm that breaks records of the pattern recognition and signal processing applications in the recent years. In addition, comparison with the method using SVM verifies that CNN has much better performance reaching up to the around 100 % classification accuracy for subject-specific and average scores in raw and preprocessed data sets via DWT. The tongue is directly connected to the brain by hypoglossal nerves and generally maintain intact in severe damages of the spinal cord injuries [1, 3]. Hence, the nature of the GKP responses and CNN offer many significant advantages to be implementable in control of assistive devices compared to the EEG-based BCIs.
The authors would like to thank the students of the University of Bozok for providing the participation for this research. The authors declare that they have no conflict of interest.
The study was approved by the Ethical Committee of Sakarya University. All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee. Informed consent was obtained from all individual participants included in the study.
[1] Huo, X., Ghovanloo, M. (2012). Tongue drive: A wireless tongue-operated means for people with severe disabilities to communicate their intentions. IEEE Communication Magazine, 50(10): 128-135. https://doi.org/10.1109/MCOM.2012.6316786
[2] Nam, Y., Koo, B., Cichocki, A., Choi, S. (2016). Glossokinetic potentials for a tongue-machine interface. IEEE Systems, Man, & Cybernetics Magazine, 2(1): 6-13. https://doi.org/10.1109/MSMC.2015.2490674
[3] Nam, Y., Zhao, Q., Cichocki, A., Choi, S. (2012). Tongue-rudder: A glossokinetic-potential-based tongue-machine interface. IEEE Transaction on Biomedical Engineering, 59(1): 290-299. https://doi.org/10.1109/TBME.2011.2174058
[4] Nam, Y., Koo, B., Cichocki, A., Choi, S. (2014). GOM-Face: GKP, EOG, and EMG-Based multimodal interface with application to humanoid robot control. IEEE Transaction on Biomedical Engineering, 61(2): 453-462. https://doi.org/10.1109/TBME.2013.2280900
[5] Gorur, K., Bozkurt, M.R., Bascil, M.S., Temurtas, F. (2018). Glossokinetic potential based tongue–machine interface for 1-D extraction. Australasian Physical & Engineering Sciences in Medicine, 41(2): 379-391. https://doi.org/10.1007/s13246-018-0635-x
[6] Gorur, K., Bozkurt, M.R., Bascil, M.S., Temurtas, F. (2018). Glossokinetic potential based tongue-machine interface for 1-D extraction using neural networks. Biocybernetics and Biomedical Engineering, 38(3): 745-759. https://doi.org/10.1016/j.bbe.2018.06.004
[7] Tang, H., Beebe, D.J. (2006). An oral tactile interface for blind navigation. IEEE Trans On Neural System and Rehabilitation Engineering, 14(1): 116-123. https://doi.org/10.1109/TNSRE.2005.862696
[8] Bao, X., Wang, J., Hu, J. (2009). Method of individual identification based on electroencephalogram analysis. International Conference on New Trends in Information and Service Science, pp. 390-393. https://doi.org/10.1109/NISS.2009.44
[9] Miller, K.J., Shenoy, P., Nijs, M., Sorensen, L.B., Rao, R.J.P., Ojemann, J.G. (2008). Beyond the Gamma Band: The role of high-frequency features in movement classification. IEEE Transaction on Biomedical Engineering, 55(5): 1634-1637. https://doi.org/10.1109/TBME.2008.918569
[10] Reuderink, B., Poel, M., Nijholt, A. (2011). The impact of loss of control on movement BCIs. IEEE Trans on Neural Systems and Rehabilitation Engineering, 19(6): 628-637. https://doi.org/10.1109/TNSRE.2011.2166562
[11] Jeunet, C., N’Kaoua, B., Lotte, F. (2016). Advances in user-training for mental-imagery-based BCI control: Psychological and cognitive factors and their neural correlates. Progress in Brain Research, 228: 3-35. https://doi.org/10.1016/bs.pbr.2016.04.002
[12] Rupp, R., Rohm, M., Schneiders, M., Kreilinger, A., Müller-Putz, G.R. (2015). Functional rehabilitation of the paralyzed upper extremity after spinal cord injury by noninvasive hybrid neuroprostheses. Proceedings of the IEEE, 103(6): 954-968. https://doi.org/10.1109/JPROC.2015.2395253
[13] Alonso-Valerdi, L.M., Sepulveda, F. (2014). Development of a simulated living environment platform: Design of BCI assistive software and modelling of a virtual dwelling place. Computer Aided Design, 54: 39-50. https://doi.org/10.1016/j.cad.2013.07.005
[14] Huo, X., Wang, X., Ghovanloo, M. (2007). Using magneto-inductive sensors to detect tongue position in a wireless assistive technology for people with severe disabilities. IEEE Sensor Conference, pp. 732-735. https://doi.org/10.1109/ICSENS.2007.4388504
[15] Huo, X., Wang, J., Ghovanloo, M. (2007). A wireless tongue-computer interface using stereo differential magnetic field measurement. Proceedings of the 29th Ann. Inter Conference of the IEEE EMBS, Cité Internationale, Lyon, France, pp. 5723-5726. https://doi.org/10.1109/IEMBS.2007.4353646
[16] Huo, X., Wang, J., Ghovanloo, M. (2007). A magnetic wireless tongue-computer interface. Proceed of the 3rd Inter. IEEE EMBS Conference on Neural Engineering, pp. 322-326. https://doi.org/10.1109/CNE.2007.369676
[17] Vaidyanathan, R., Chung, B., Gupta, L., Kook, H., Kota, S., West, J.D. (2007). Tongue-movement communication and control concept for hands-free human–machine interfaces. IEEE Transaction on Systems Man and Cybernetics, 37(4): 533-546. https://doi.org/10.1109/TSMCA.2007.897919
[18] Vaidyanathan, R., James, C.J. (2007). Independent component analysis for extraction of critical features from tongue movement ear pressure signals. Proceeding of the 29th Annual International Conference of the IEEE EMBS, pp. 5481-5483. https://doi.org/10.1109/IEMBS.2007.4353586
[19] Vaidyanathan, R., Gupta, L., Kook, H., West, J. (2006). A decision fusion classification architecture for mapping of tongue movements based on aural flow monitoring. Proceedings of the IEEE International Conference on Robotics and Automation, pp. 3610-3617. https://doi.org/10.1109/ROBOT.2006.1642253
[20] Klem, G.H., Lüders, H.O., Jasper, H.H., Elger, C. (1999). The ten-twenty electrode system of the international federation Electroencephalography. Clin Neurophysiology, 52: 3-6.
[21] Bascil, M.S., Tesneli, A.Y., Temurtas, F. (2016). Spectral feature extraction of EEG signals and pattern recognition during mental tasks of 2-D cursor movements for BCI using SVM and ANN. Australasian Physical Engineering Science in Medicine, 39(3): 665-676. https://doi.org/10.1007/s13246-016-0462-x
[22] Yalcın, N., Tezel, G., Karakuzu, C. (2015). Epilepsy diagnosis using artificial neural network learned by PSO. Turkish Journal Electrical Engineering & Computer Science, 23: 421-432. https://doi.org/10.3906/elk-1212-151
[23] Gunes, S., Dursun, M., Polat, K., Yosunkaya, S. (2011). Sleep spindles recognition system based on time and frequency domain features. Expert Systems with Applications, 38: 2455-2461. https://doi.org/10.1016/j.eswa.2010.08.034
[24] Rechy-Ramirez, E.J., Hu, H. (2015). Bio-signal based control in assistive robots: A survey. Digital Communications and Networks, 1(2): 85-101. https://doi.org/10.1016/j.dcan.2015.02.004
[25] Teo, J., Hou, C.L., Mountstephens, J. (2017). Deep learning for EEG-Based preference classification. 2nd International Conference on Applied Science and Technology, pp. 1-6. https://doi.org/10.1063/1.5005474
[26] Liu, Y., Liu, Q. (2017). Convolutional neural networks with large-margin softmax loss function for cognitive load recognition. Proceedings of the 36th Chinese Control Conference, pp. 4045-4049. https://doi.org/10.23919/ChiCC.2017.8027991
[27] Wen, L., Li, X., Gao, L., Zhang, Y. (2018). A new convolutional neural network-based data-driven fault diagnosis method. IEEE Transactions on Industrial Electronics, 65(7): 5990-5998. https://doi.org/10.1109/TIE.2017.2774777
[28] Yin, Z., Zhang, J. (2018). Task-generic mental fatigue recognition based on neurophysiological signals and dynamical deep extreme learning machine. Neurocomputing, 283: 266-281. https://doi.org/10.1016/j.neucom.2017.12.062
[29] Jia, Y., Xie, J., Xu, G., Li, M., Zhang, S., Luo, A., Han, X. (2017). A separated feature learning based DBN structure for classification of SSMVEP signals. 39th Annual Inter Conf of the IEEE Engin in Medicine and Biology Society (EMBC), pp. 3356-3359. https://doi.org/10.1109/EMBC.2017.8037575
[30] Dias, N.S., Kamrunnahar, M., Mendes, P.M., Schiff, S.J., Correia, J.H. (2007). Customized linear discriminant analysis for brain-computer interfaces. Proceedings of the 3rd International IEEE EMBS Conference on Neural Engineering, pp. 430-433. https://doi.org/10.1109/CNE.2007.369701
[31] He, H., Tan, Y., Liu, X. (2013). Feature extraction of ECG signals in meridian systems using wavelet packet transform and clustering algorithms. 10th IEEE Internatıonal Conference on Networking, Sensing and Control, pp. 183-187. https://doi.org/10.1109/ICNSC.2013.6548733
[32] Hamad, A., Houssein E.H., Hassanien, A.E., Fahmy, A.A. (2012). Feature extraction of epilepsy EEG using discrete wavelet transform. 12th International Computer Engineering Conference, pp. 191-195. https://doi.org/10.1109/icenco.2016.7856467
[33] Lolure, A., Thool, V.R. (2015). Wavelet transform based EMG feature extraction and evaluation using scatter graphs. International Conference on Industrial Instrumentation and Control, pp. 1273-1277. https://doi.org/10.1109/IIC.2015.7150944
[34] Patel, T.K., Panda, P.C., Swain, S.C., Mohanty, S.K. (2017). A fault detection technique in transmission line by using discrete wavelet transform. 2nd Int. Conf on Electrical, Computer and Communication Technology. https://doi.org/10.1109/ICECCT.2017.8118052
[35] Acharya, U.R., Oh, S.L., Hagiwara, Y., Tan, J.H., Adeli, H. (2018). Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Computers in Biology and Medicine, 100: 270-278. https://doi.org/10.1016/j.compbiomed.2017.09.017
[36] Bascil, M.S., Tesneli, A.Y., Temurtas, F. (2015). Multi-channel EEG signal feature extraction and pattern recognition on horizontal mental imagination task of 1-D cursor movement for brain computer interface. Australasian Physical Engineering Science in Medicine, 38(2): 229-239. https://doi.org/10.1007/s13246-015-0345-6
[37] Şen, B., Peker, M. (2013). Novel approaches for automated epileptic diagnosis using FCBF selection and classification algorithms. Turkish Journal Electrical Engineering & Computer Science, 21: 2092-2109. https://doi.org/10.3906/elk-1203-9
[38] Obermaier, B., Neuper, C., Guger, C., Pfurtscheller, G. (2001). Information transfer rate in a five-classes brain–computer interface. IEEE Transaction on Neural Systems, and Rehabilitation, 9(3): 283-288. https://doi.org/10.1109/7333.948456
[39] Sengelmann, M., Engel, A.K., Maye, A. (2017). Maximizing information transfer in SSVEP-based brain–computer interfaces. IEEE Transaction on Biomedical Engineering, 64(2): 381-394. https://doi.org/10.1109/TBME.2016.2559527
[40] Alpaydın, E. (2010). Introduction to Machine Learning. MIT Press, Cambridge, Massachusetts, Second Edition.
[41] Wang, Z., Cao, L., Zhang, Z., Gong, X., Sun, Y., Wang, H. (2018). Short time Fourier transformation and deep neural networks for motor imagery brain computer interface recognition. Concurrency Computation Practice Experience. https://doi.org/10.1002/cpe.4413
[42] Yang, B., Duan, K., Fan, C. (2018). Automatic ocular artifacts removal in EEG using deep learning. Biomedical Signal Processing and Control, 43: 148-158. https://doi.org/10.1016/j.bspc.2018.02.021
[43] Zhang, J., Li, S. (2017). A deep learning scheme for mental workload classification based on restricted Boltzmann machines. Cognition Technology Work, 19: 607-631. https://doi.org/10.1007/s10111-017-0430-6
[44] Li, J., Zhang, Z., He, H. (2018). Hierarchical convolutional neural networks for EEG-based emotion recognition. Cognitive Computation, 10: 368-380. https://doi.org/10.1007/s12559-017-9533-x
[45] Cılasun, M.H., Yalcın, H. (2016). A deep learning approach to EEG based epilepsy seizure determination. 24th Signal Processing and Communication Application Conference. https://doi.org/10.1109/SIU.2016.7496054
[46] Cao, Y., Guo, Y., Yu, H. (2017). Epileptic seizure auto-detection using deep learning method. 4th International Conf on Systems and Informatics, pp. 1076-1081. https://doi.org/10.1109/ICSAI.2017.8248445
[47] Jayaram, V., Alamgir, M., Altun, Y., Schölkopf, B., Grosse-Wentrup, M. (2016). Transfer learning in brain-computer interfaces. IEEE Computational Intelligence Magazine, pp. 20-31. https://doi.org/10.1109/MCI.2015.2501545
[48] Kao, J.C., Stavisky, S.D., Sussillo, D., Nuyujukian, P., Shenoy, K.V. (2014). Information systems opportunities in brain–machine interface decoders. Proceedings of the IEEE, 102(5): 666-682. https://doi.org/10.1109/JPROC.2014.2307357
[49] Cerutti, S. (2009). In the Spotlight: Biomedical signal processing. IEEE Reviews in Biomedical Engin, 2: 9-11. https://doi.org/10.1109/RBME.2010.2082710
[50] Zeng, W.L., Liu, W., Lu, Y., Lu, B.L., Cichocki, A. (2018). EmotionMeter: A multimodal framework for recognizing human emotions. IEEE Transactions on Cybernetics, pp. 1-13. https://doi.org/10.1109/TCYB.2018.2797176
[51] Chen, X., He, C., Wang, Z.J., McKeown, M.J. (2013). An IC-PLS framework for group corticomuscular coupling analysis. IEEE Transactions on Biomedical Engineering, 60(7): 2022-2033. https://doi.org/10.1109/TBME.2013.2248059
[52] Vanhatalo, S., Voipio, J., Dewaraja, A., Holmes, M.D., Miller, J.W. (2013). Topography and elimination of slow EEG responses related to tongue movements. NeuroImage, 20(2): 1419-1423. https://doi.org/10.1016/S1053-8119(03)00392-6
[53] Nam, Y., Bonkon, K., Choi, S. (2014). Language-related glossokinetic potentials on scalp. IEEE International Conference on Systems, Man, and Cybernetics, San Diego, USA, pp. 1063-1067. https://doi.org/10.1109/SMC.2014.6974054
[54] Leeb, R., Lee, F., Keinrath, C., Scherer, R., Bischof, H., Pfurtscheller, G. (2007). Brain-computer communication: Motivation, aim, and impact of exploring a virtual apartment. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 15(4): 473-481. https://doi.org/10.1109/TNSRE.2007.906956