Gulnara Bektemyssova![]() | Aidos Sabdenov*
| Aidos Sabdenov*![]()
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
This research focuses on developing effective algorithms for semantic knowledge graph searches in the context of finding causal answers, which is highly relevant due to the widespread use of semantic networks. The study's primary goal is to examine the construction principles of a semantic knowledge graph search model tailored for causal answers, with a focus on deep neural semantic search characteristics. The research methodology combines system analysis methods for building knowledge graphs with an analytical investigation of deep neural semantic search aspects. The results provide insights into the construction of a semantic knowledge graph search model for causal answers, addressing the challenges and methodologies involved in building such a model. It underscores the significance of knowledge graphs in modern information systems and their potential applications in various domains. However, further scientific research is essential to explore the practical applications of deep neural semantic search knowledge graphs in various information systems, which are used across different aspects of everyday life. The practical significance of this research extends to various applications in information retrieval, knowledge management, and problem-solving, making it a valuable contribution to the advancement of technology and understanding of natural language text.
semantic network, question type, semantic knowledge graph, graph search model, semantic analysis, algorithm for constructing a causal response
Modern information systems contain a large amount of textual information. Therefore, various tasks of constructing a semantic knowledge graph model for finding answers to questions are very relevant today. At the same time, one of the main tools for processing text without losing its meaning is the semantic network. It is an oriented graph that is able to correctly reflect the key concepts and the relationships between them [1]. The vertices of a graph contain concepts, while its connections are relations between these concepts. The types of links in the semantic network graph can be selected by its creator in accordance with specific goals.
Semantic networks are data structures that encode knowledge in a graph-like format, comprising nodes (vertices) that symbolise concepts or entities and edges (arcs) that symbolise relationships or connections between these concepts. Semantic networks are primarily designed to capture and organise semantic information, thereby facilitating machines in comprehending, rationalising, and deducing insights about the world.
Recently, there has been notable advancement in tackling these difficulties through the development of machine learning, deep learning, and natural language processing methods. Scientists are consistently striving to enhance algorithms for semantic networks to enhance their resilience, efficiency, and ability to handle practical applications in diverse fields. Moreover, the advancement of knowledge graphs and ontologies has been pivotal in organising and standardising knowledge, thereby enhancing its accessibility for artificial intelligence systems.
The high level of development of the sphere of modern information technologies against the background of their high dynamism determines the continuous emergence of many effective methodologies for the development of software systems, and the need for their continuous improvement [2, 3]. Methodologies can be attributed to one or more stages of the life cycle of a particular software. Each of the existing methodologies may have several different modifications. Flexible methodologies are in high demand, which are actively used today in software development. Methodologies of continuous integration of development, testing, deployment of software systems, etc. are of great interest. Basically, these methodologies are focused on creating typical product-level software systems [4, 5]. In general, existing methodologies allow quickly creating and modifying information systems when new requirements arise, conditions for setting tasks and finding solutions change. Regularly occurring changes are often caused by the need to support the created application models, methods and tools. Most of them can rightfully be considered innovative and need special training to further their effective practical use [6, 7].
Over the past few decades, the paradigm of network thinking has been actively forming in the depths of multiple areas of scientific research. Research projects are being carried out that contribute to the formation of a network picture of the modern world and mean concrete attempts to create its image. Today, many scientists reduce descriptions of natural and life phenomena exclusively to representations of various forms of referential connectedness of elements of the modern structure of the world, which has many levels of display. Reality is presented as a complexly organised mobile discursive field, formed through the development of interrelations of spatial structures. It is no exaggeration to say that the ideas of the network approach become the basis of the theory and practice of various interrelated natural and social sciences [8, 9].
A graph is a data structure that includes two components, - edges and vertices. Graph (G) can be described by a large number of edges (E) and vertices (V), which it includes G= f(E, V). Graph neural network (Eng. Graph Neural Network (GNN)) is a type of neural network that works directly with the graph structure. Node classification is a typical example of using a graph neural network [10]. It is most convenient to present any information data in the form of graphs when working with languages, when performing image analysis and processing, building various functional models of web networks, and in other applied tasks of a wider spectrum.
The practical application of a graph neural network allows working with graph data without preprocessing. The principle of operation of a graph neural network is to use the mechanism of information dissemination. At the learning stage, modules update their states and carry out information exchange until the modules reach a stable equilibrium state. The output of a graph neural network is calculated based on the state of the module at each node [11, 12].
The justification for employing deep neural semantic search is rooted in its capacity to augment the accuracy, retrieval, and pertinence of search outcomes by comprehending the semantics of human language, rendering it an enticing option for contemporary information retrieval systems and Natural Language Processing (NLP) applications. Deep neural semantic search offers several benefits that make it an appealing choice for various applications.
Although deep neural semantic search offers distinct benefits, it is important to recognise that it also presents challenges, including the requirement for substantial quantities of annotated training data, computational resources, and model interpretability. Furthermore, the selection of methodology relies on the particular application and the demands of the user. Occasionally, conventional keyword-based search or alternative methods may still be suitable.
The purpose of this article is to investigate the significance and potential of deep neural semantic search models in the context of Natural Language Processing (NLP) and knowledge retrieval. It aims to provide an in-depth exploration of the principles and methodologies involved in constructing semantic knowledge graph search models for finding causal answers in textual data.
The basis of the methodological approach in this scientific study is a combination of methods of system analysis of the principles of building knowledge graphs in the analytical study of the features of building a deep neural semantic search. The main research is preceded by the creation of a theoretical base, which is the generalised results of the analysis of available scientific research by a number of domestic and foreign authors devoted to the application of knowledge graphs for deep neural semantic search. This study was carried out in several stages:
This research project, employing a multi-staged methodology, enhances our comprehension of knowledge graphs and their incorporation into the realm of deep neural semantic search. It provides valuable information about the practical applications and ability to bring about significant changes of these models in electronic computing devices.
Automatic extraction of causal relationships from natural language texts is a complex and urgent problem in the creation of artificial intelligence systems. Most of the first attempts to solve it used manually constructed linguistic and syntactic rules for small and data sets for a specific area. However, with the advent of databases of considerable volume, increasing the availability of modern high-power computing equipment and taking into account the growing popularity of machine learning techniques, the paradigm for solving this kind of problem has gradually shifted. In the near future, machines will be able to master the general rules for extracting causal relationships from marked-up data, provided that their actions are completely autonomous and regardless of the domain [14, 15].
The term “knowledge graph” has recently been used relatively often in scientific research, in business, as a rule, in close connection with semantic web technologies, arrays of related data, and with cloud computing. The evolution of the understanding of the meaning of this term has been significantly hindered conditioned upon the presence of a large number of its interpretations. The key prerequisite for the broad acceptance of the scientific concept is the development of a common understanding of the term, devoid of any ambiguity. The graph of a semantic network is the key form of its representation [16]. In essence, the entire semantic network is an information model of the subject area, presented in the form of an oriented graph, the vertices of which correspond to the objects of this area, and the arcs determine the relationships formed between them. Thus, the semantic network is one of the numerous options for displaying knowledge of any kind. A semantic knowledge graph is a knowledge base that uses a graphical data model or topology to integrate them. Knowledge graphs are often used to store events, situations, or concepts of abstract content that have arbitrary semantics. The sequential construction of the semantic knowledge graph search model for the search for a causal answer assumes compliance with a certain sequence of operations performed:
The development of the semantic knowledge graph search model followed a carefully orchestrated procedure comprising multiple discrete stages. The process commenced with the gathering of data, in which an extensive collection of natural language texts and documents pertaining to the research field was assembled. This dataset was fundamental in building the semantic knowledge graph. This entailed performing several tasks, including tokenization, which involves breaking down text into individual words or phrases, eliminating stop words that have minimal semantic significance, and applying stemming or lemmatization to reduce words to their fundamental forms.
The construction of the model also included an important aspect called entity recognition. Named Entity Recognition (NER) models were utilised to detect and categorise entities present in the text. These models played a crucial role in differentiating and classifying entities, such as individuals, institutions, geographical areas, and others, present in the text. Dependency parsing was crucial in extracting the grammatical structure of sentences. This step was pivotal in comprehending the connections between words and phrases in the text. It facilitated the identification of word associations and their relationships within sentences. After performing dependency parsing, the model proceeded to extract semantic relationships between entities and concepts in the text. For instance, its objective was to ascertain the connection between “John” and “XYZ Company” by extracting the relationship. The citation is from Mouromtsev et al. [17].
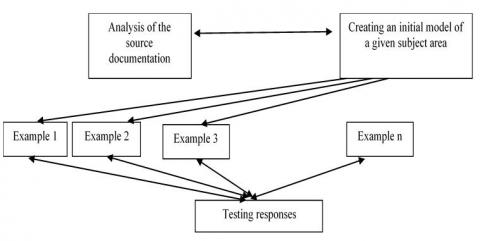
Afterwards, utilising the identified entities, concepts, and relationships, the model created a semantic knowledge graph. The graph depicted entities or concepts as nodes and their relationships as edges. This graph formed the basis for knowledge inference (Figure 1).
Figure 1. Development of a semantic model for finding a causal response
The development of a semantic model involves the analysis of primary documents to form an idea about the subject area, as well as the information presented in the documents. The practical application of the semantic knowledge graph search model for determining the causal response involves the allocation of the following information contexts from the text documents under study:
key terms;
metadata;
structure;
the main linguistic characteristics of the text.
From the standpoint of the implementation of deep neural semantic search, the key knowledge is the construction of a semantic search knowledge graph, which is a collection of facts interconnected by certain connections. In addition, knowledge graphs include information about the main types of neural network concepts and the connections between them. This is a key factor determining the effectiveness of building knowledge graphs when implementing deep neural semantic search in the case of practical implementation of these technological solutions in modern electronic computing devices.
To create an effective algorithm for understanding the meaning of a text in a natural language using the capabilities of modern digital computing, it is necessary to use a formal language to describe the meaning [18]. This method is the basis of the principle of constructing a semantic knowledge graph model for deep neural network search. A formal language is a set of specific methods that allow for the description and processing of the meaning of a natural language. The formal language allows you to describe the meaning of the text, as well as algorithms for its processing in a form that can be used later in a computing device during automatic processing, and the sufficiency criterion is of paramount importance in this context. When processing, it should be avoided without loss of performance when performing inefficient operations, in other words, the construction of a semantic value graph model should occur exclusively on real data. Processing the meaning of sentences implies the need to work with a huge amount of information, which means that there is no need for manual processing of the formal language [19].
The construction of a knowledge graph of deep neural semantic search presupposes the possibility of processing the meaning of text fragments using certain algebraic functions. At the same time, the neural network itself can also be considered as an algebraic function of a higher order. For this reason, the implementation of the construction of a graph of semantic knowledge of a neural network using the capabilities of modern computing technology requires solving the problem of synchronisation of a huge amount of data processing processes. A qualitative solution to this kind of problem involves the construction of the principles of network semantic search, based on synchronised and non-synchronised neurons. The differences are in the principles of data processing and the discontinuity of the output of the results obtained. Modern neural networks can be modelled using the capabilities of modern computer systems, and in terms of constructing semantic knowledge graphs, their capabilities significantly exceed the real possibilities of practical application of other methods of constructing semantic networks. The semantic display of a text array, its formalised language for isolating its meaning can be combined into a neural network as the main physical entity. The construction of a semantic knowledge graph search model for finding a causal response in a neural network can be successfully implemented using the capabilities of modern computing technology with a minimum of errors, based on a formal language for describing the meaning of sentences in natural language. The practical application of this model contributes to achieving a high degree of accuracy in the search for causal answers while observing the key principles of building knowledge graph models of deep neural semantic search.
The development of the semantic knowledge graph search model encountered various difficulties. Due to its inherent nature, natural language is characterised by ambiguity, frequently featuring words or phrases that possess multiple interpretations. Significant effort was necessary to disambiguate terms and ensure the model accurately identified context-specific meanings. The accurate identification of entities, particularly in specialised domains, posed a challenge. Continuing to refine NER models and resolving challenges associated with entities that are not adequately captured in pre-trained models were ongoing responsibilities. The management of extensive datasets and the construction of comprehensive knowledge graphs have raised concerns regarding scalability. Optimal algorithms and data structures were crucial in handling the graph's magnitude and intricacy. The determination of causal relationships from the knowledge graph occasionally depended on heuristic techniques and statistical models. These methods may not consistently yield accurate outcomes.
To customise the model for various domains or topics, it is necessary to possess domain-specific expertise and training data. Extending the model's scope to encompass a broad array of subjects proved to be a difficult task. Evaluating the precision and efficacy of the model's ability to infer knowledge required appropriate assessment criteria and standardised datasets for comparison. Creating these benchmarks may require a significant allocation of resources.
To summarise, the creation of the semantic knowledge graph search model required a series of complex procedures, ranging from data gathering to knowledge deduction. The execution of these steps necessitated meticulous scrutiny of details and faced difficulties associated with language ambiguity, scalability, domain specificity, and knowledge inference accuracy. Conquering these obstacles was essential in order to develop a strong and efficient model for deep neural semantic search.
Conclusively, the creation of a semantic knowledge graph search model for deep neural semantic search signifies a notable progress in the realm of artificial intelligence. This model, developed using a methodical approach that includes gathering data, preparing it for analysis, identifying entities, parsing dependencies, and constructing a knowledge graph, has the potential to automatically extract causal relationships from texts written in natural language. This research highlights the potential of machines to autonomously acquire general rules for extracting causal relationships from large and diverse datasets, despite facing challenges such as language ambiguity, scalability, and domain specificity. The utilisation of formal language-based methodology, in conjunction with contemporary computational capacities, is crucial for attaining precise and effective searches for causal responses within the context of deep neural networks. In essence, this work enhances the continuous advancement of AI systems based on knowledge graphs and their utilisation in diverse fields.
This study explores the importance of semantic knowledge graphs in information retrieval, with a particular focus on their relevance for providing causal answers. It emphasises their function in automating data processes and their significance in areas such as IoT and e-health for improving semantic interoperability and biomedical data analysis. The study recognises the difficulties in processing natural language and the complexities of modelling syntax and semantics. Although providing valuable theoretical insights, additional empirical research is necessary to fully exploit the potential of these models in practical applications. The limitations of the study underscore the intricacies involved in implementing extensive semantic knowledge graphs on a large scale. This emphasises the necessity of addressing challenges related to scalability, computational requirements, and practical implementation in knowledge-intensive fields.
A simple semantic network can be considered as a strictly oriented graph having labeled arcs and vertices, in which the vertices perform the function of semantic facts, and the arcs are relations between these vertices. The subjects of semantic facts should be considered certain concepts, facts, processes, including models and signs. This means that a simple kind of semantic network acts as a definition of the connections between all its vertices [20].
Information technologies at the current level of development can be characterised by the widespread acceleration of the processes of intellectualisation of information systems with different directions. There are actual opportunities to automate the processes of collecting, storing, processing and searching information, as well as its provision and generation, the development of new classification principles, in relation to new types of information arrays obtained based on the previously developed knowledge base of information systems [21]. At the same time, there are a number of problems associated with a gradual improvement in the quality of their functioning. In particular, problems of this kind are associated with increasing the transparency of the functioning of such information systems, the need for a more accurate analysis of the stored information and an assessment of its reliability. The solution of such problems requires further research in the direction of studying issues related to the storage of information in databases.
The rapid increase in information data arrays in various fields of modern science and manufacturing industries, taking place against the background of the rapid obsolescence of this information, necessitates continuous training for a long time [22]. This, in turn, determines the need for the development of a high-quality information base capable of meeting the needs of the educational process for up-to-date information and solving the issues of finding the necessary information at a certain point in time [23, 24]. This task can be successfully solved only through the development and implementation of a methodology for finding the necessary educational materials, functioning on the basis of a semantic model for the presentation of materials of this kind.
Semantic models in Internet of Things (IoT) and e-health applications explore the key role of semantic web modelling in e-health technologies, including remote monitoring, mobile healthcare, cloud data, and biomedical ontologies. To date, it is of fundamental importance to study such problems through the prism of various case studies of health systems, where semantic web technologies are currently being introduced. The active development of concepts of semantic interoperability in the context of the healthcare model will be introduced, and research is also being conducted on the possibilities of semantic representation as a key to the classification, analysis and understanding of huge volumes of biomedical data generated by connected medical devices [25].
Causal latent semantic analysis (cLSA) is a modification and thus derived from traditional latent semantic analysis. Besides: To identify hidden factors, cLSA establishes causal relationships between these factors based on the input data and the output operators contained in the factors. cLSA performs latent semantic analysis (LSA) for a corpus consisting of input and output data. statements derived from excerpts of the text. The I/O operator (also called the XY operator) is defined as a pair of operators in which the output operator (operator Y) is a consequence of the input operator (operator X) [26]. In the 1980s, researchers from the University of Groningen and the University of Twente in the Netherlands initially introduced the term knowledge graph in order to formally describe a system that they based on knowledge combining information from various sources of natural language representation. The authors of this theory proposed knowledge graphs with a limited set of relationships and focused exclusively on qualitative modelling, including human interaction, which clearly contrasts with the idea of knowledge graphs, which was widely discussed in several previous years.
The knowledge graph is a popular modern technology that has been adopted by many companies to describe a variety of knowledge representation applications. Considering this kind of applications, the knowledge graph has an abstract structure rather than a mathematical one. At the same time, the knowledge graph is not synonymous with the knowledge base, which is often used by itself as a synonym for ontology [27].
Automatic extraction of knowledge from the natural language of texts is one of the many open tasks of artificial intelligence today. Effective imitation of the human brain's ability to understand written texts entails the development of complex modelling, which allows us to actively and fruitfully study various aspects of the interaction of syntax, semantics, and constantly develop vocabulary and increase the variability of the use of ambiguous constructions in the lexicon, such as figurative expressions, metaphors, rhetoric, sarcasm and slang. In fact, even such a relatively simple task as the definition of implicit negations in a sentence remains a complex and completely unsolved problem. Nevertheless, the computer science and computational linguistics communities have made significant progress in this field over the past three decades and continue to work more efficiently, reliably and scale methods specifically designed to successfully solve textual problems of extracting the necessary information [14].
The idea of automatic extraction of information from texts in natural languages became popular in the 80s of the last century, following the gradual increase in the availability of computing systems and the growing popularity of machine learning. In the specified time interval, scientific research was published on the topic of the complexity of developing automatic systems for acquiring causal knowledge based on natural language. The researchers emphasised that a good causal analyser must necessarily be an integral part of the knowledge representation model, which includes a semantic basis. At the same time, knowledge of the subject area must be present, to accurately identify significant cause-and-effect relationships from any text fragments. In addition, it was argued that the tool should be able to draw a conclusion about any unmentioned direct component between the causal factor and the result obtained, which will contribute to the creation of the most accurate and complete chain of causes and effects. In addition, it should be able to eliminate the ambiguity of any causal ambiguous statements.
A knowledge graph is often defined as a semantic graph consisting of nodes (vertices) and edges, where nodes represent concepts. Referring to the general categories of objects and edges, represent semantic relationships between entities. Some of the observed nodes can be connected to each other and form structured knowledge that can help use, manage and understand information. Knowledge graphs are mainly constructed from a knowledge base (KB), which refers to an intelligent database for managing, storing and retrieving complex structured and unstructured information [28, 29]. Knowledge bases collect it from free text on web pages, databases, audio and video content. If the graphical representation of knowledge is more related to the graphical structure, the knowledge base focuses on storing information in the database [30, 31].
To date, natural language processing is the most common direction of creating artificial intelligence systems and mathematical linguistics, involving the study of problems of natural language synthesis and computer analysis. Modern speech recognition technologies are based on the principles of natural language processing, they are also actively used in the search for necessary information, spell checking, etc. At the same time, significant difficulties in processing natural language arise conditioned upon its ambiguity, and such problems manifest themselves at all stages of processing, including phonetic and semantic levels [32, 33].
In real, practical conditions, it is always easy to determine that understanding the basic meaning of a text is not a continuous or instantaneous process. Understanding the meaning of text is a time-stretched process and at the same time clarification of the understood meaning can be achieved through the introduction of new, additional data. Any new sentence, as well as any separate part of the text, can have its own meaning. You can easily verify this by reading all the words in the sentence sequentially, one after the other. Even each letter has its own meaning, different from the meaning of all other letters. The state of a neural network at a certain point in time assumes a snapshot of a large number of neurons, and the multiple connections existing between them and the internal states of neurons. It can be concluded that the meaning of the text, which is described using a neural network, is the state of this neural network [19]. Therefore, the successful implementation of algorithms for understanding the meaning of text in natural language using sequential digital computing devices implies the mandatory use of a formal language for describing sentences. Such a language means a certain set of methods, through the practical use of which it becomes possible to automatically describe and process the meaning of a natural language [34]. At the same time, in determining the formal language, one should be guided primarily by the criterion of sufficiency, since any formal language only describes the essence of the text, and the algorithm of its processing in a form that is suitable for performing subsequent automatic processing using computing devices.
The semantic knowledge graph collects and integrates information into an ontology and applies a reasoning algorithm in order to gain new knowledge. In this context, the question often arises about determining the difference that exists between the knowledge graph and the semantic network. Knowledge graphs of a relatively small scale, in particular corporate knowledge graphs, may differ significantly from the entire semantic network conditioned upon the presence of domain restrictions [35]. All existing search engines consistently scan and process the information available on the Internet today, which leads to the expanded use of semantic search technology [36].
In modern information analytical systems that are focused on processing large amounts of information presented in the form of texts in natural languages, various methods of formalization of language constructions are used. The applied formalisation procedures are based on a combination of linguistic and semantic analyses, and the approaches to their implementation have a direct impact on the effectiveness of the functioning and speed of information and analytical systems. In the current situation, the consistent construction of a semantic knowledge graph search model is necessary to increase the efficiency of modern information and analytical systems, as well as to accelerate the processes of searching for causal answers when working with semantic networks containing large amounts of data.
To date, semantic networks are among the most common models for providing and preserving information, therefore, issues of improving the quality of their functioning and the formation of transparency of the systems themselves are of particular relevance, which implies increasing the accuracy of analysis, clustering, ordering information, and assessing the degree of its reliability. A qualitative solution to these and a number of other problematic issues requires further research in the direction of studying ways to store information in databases [21]. The key issues in this context are the provision of various units of natural language, as well as information of various kinds presented in digital form, the creation of appropriate database structures, etc. The methods of practical resolution of the listed problematic issues may be different, which causes a wide variability of scientific approaches to their study.
While this study has provided valuable insights into the construction of a semantic knowledge graph search model for finding causal answers, it is important to acknowledge its limitations. Firstly, the study primarily focuses on the theoretical framework and conceptual aspects of semantic knowledge graphs, and it does not delve into the practical implementation or real-world applications of such models. Secondly, the challenges and difficulties encountered in building the semantic knowledge graph model are discussed in a general sense, but a more in-depth analysis of these challenges and potential solutions is required for practical deployment. Thirdly, the study does not provide specific case studies or empirical results to demonstrate the model's effectiveness in real-world scenarios. Lastly, the study does not address the scalability and computational resource requirements of deploying large-scale semantic knowledge graphs. Further research and empirical validation are needed to address these limitations and provide a more comprehensive understanding of the practical implications and challenges of utilizing semantic knowledge graphs for causal answer retrieval.
The semantic knowledge graph is a highly effective tool for solving a wide range of tasks related to recommendation and intellectual search. Its effectiveness stems from its intricate structure and its ability to store a vast amount of semantic information. Simultaneously, there is a lack of clarity regarding the final outcome, making it challenging to comprehend the appropriate construction of such an architectural design and the requisite technological solutions to be employed. However, the semantic knowledge graph is currently regarded as a highly promising technological solution that has demonstrated its effectiveness in addressing a wide range of natural language processing challenges. This study presents the key elements and steps involved in constructing a semantic network knowledge graph, which is used to address the issue of identifying a causal response. Furthermore, it is important to acknowledge that the utilisation of existing databases for analysis and application of the information they contain can be beneficial in implementing the knowledge graph. The semantic knowledge graph is a specific type of knowledge base that utilises a graphical data storage model or topology to effectively integrate into a particular system. Semantic knowledge graphs primarily serve as repositories for events, situations, and various abstract concepts, which are represented in a flexible semantic format [37].
The study's investigation into the development of a search model for a semantic knowledge graph, specifically designed to identify causal answers, has noteworthy practical implications and provides guidance for future research endeavours. First and foremost, it highlights the significant importance of semantic knowledge graphs in recommendation systems, intellectual search, and knowledge management because of their capacity to retain and leverage extensive semantic information. Furthermore, it emphasises the necessity for additional investigation to tackle the difficulties of constructing intricate semantic architectures and choosing suitable technological solutions. Furthermore, it highlights the significance of implementing practical uses in different fields, utilising pre-existing databases for analysis and improving the process of retrieving information. Future research should prioritise the improvement of semantic knowledge graph construction, scalability, real-world implementation, advanced querying techniques, interdisciplinary collaboration, and user-friendly design. These areas need to be further developed in order to fully utilise the potential of knowledge structures for addressing complex causal questions and other related matters.
[1] Potaraev, V.V., Serebryanaya, L.V. (2020). Automatic construction of a semantic network for obtaining answers to questions. Reports of the Belarusian State University of Informatics and Radioelectronics, 4(18): 44-52. https://doi.org/10.35596/1729-7648-2020-18-4-44-52
[2] Potii, O., Poluyanenko, N., Stelnyk, I., Revak, I., Kavun, S., Kuznetsova, T. (2019). Nonlinear-feedback shift registers for stream ciphers. In 2019 IEEE 2nd Ukraine Conference on Electrical and Computer Engineering, UKRCON 2019 – Proceedings, Lviv, Ukraine, pp. 906-911. https://doi.org/10.1109/UKRCON.2019.8879786
[3] Zhong, H., Loukides, G., Pissis, S.P. (2022). Clustering sequence graphs. Data & Knowledge Engineering, 138: 101981. https://doi.org/10.1016/j.datak.2022.101981
[4] Tonkin, E., Tourte, G. (2017). Working with Text. Oxford: Chandos Publishing. https://books.google.com.ua/books?hl=en&lr=&id=gLyUAwAAQBAJ&oi=fnd&pg=PP1&ots=8d9jCCfurJ&sig=UHtheOisLPXAYEHbsDjGwP6Ph8E&redir_esc=y#v=onepage&q&f=false.
[5] Djuric, P., Richard, C. (2018). Cooperative and Graph Signal Processing. London: Academic Press. https://books.google.com.ua/books?id=8ZBYDgAAQBAJ&printsec=frontcover&hl=uk&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false.
[6] Navrotsky, M.A., Zhukova, N.A., Muromtsev, D.I., Mustafin, N.G. (2018). Methodology for designing, developing and maintaining domain semantic portals of scientific and technical information. Scientific and Technical Bulletin of Information Technologies, Mechanics and Optics, 2(18): 286-298. https://cyberleninka.ru/article/n/metodologiya-proektirovaniya-razrabotki-i-soprovozhdeniya-domennyh-semanticheskih-portalov-nauchno-tehnicheskoy-informatsii.
[7] Fernandez, D., Dastane, O., Omar Zaki, H., Aman, A. (2023). Robotic process automation: Bibliometric reflection and future opportunities. European Journal of Innovation Management. https://doi.org/10.1108/EJIM-10-2022-0570
[8] Nurgaleeva, L.V. (2012). Semantics of networks in the experience of developing the concepts of artificial intelligence. Humanitarian Informatics, 6: 76-94. https://cyberleninka.ru/article/n/semantika-setey-v-optye-razvitiya-kontseptsiy-iskusstvennogo-intellekta.
[9] Velampalli, S., Jonnalagedda, M.V. (2017). Graph based knowledge discovery using MapReduce and SUBDUE algorithm. Data & Knowledge Engineering, 111: 103-113. https://doi.org/10.1016/j.datak.2017.08.001
[10] Fomin, O., Speranskyy, V., Krykun, V., Tataryn, O., Litynskyi, V. (2023). Models of dynamic objects with significant nonlinearity based on time-delay neural NETWORKS. Bulletin of Cherkasy State Technological University, 3: 97-112. https://doi.org/10.24025/2306-4412.3.2023.288284
[11] Saurabh, S., Madria, S., Mondal, A., Sairam, A.S., Mishra, S. (2020). An analytical model for information gathering and propagation in social networks using random graphs. Data & Knowledge Engineering, 129: 101852. https://doi.org/10.1016/j.datak.2020.101852
[12] Andersen, T., Bulskov, H., Jensen, P.A., Nilsson, J.F. (2020). Natural logic knowledge bases and their graph form. Data & Knowledge Engineering, 129: 101848. https://doi.org/10.1016/j.datak.2020.101848
[13] Gryzun, L., Shcherbakov, O., Parfonov, Y., Bodnar, L. (2022). Visualization of algorithms on graphs with a large number of vertices: The features of applications design. Development Management, 20(4): 36-44. http://doi.org/10.57111/devt.20(4).2022.36-44
[14] Asghar, N. (2016). Automatic extraction of causal relations from natural language texts: A comprehensive survey. School of Computer Science University of Waterloo, 5: 1-10. https://doi.org/10.48550/arXiv.1605.07895
[15] Sytnyk, O., Kyselov, V., Kyselova, H., Kostiuchenko, V. (2022). Mathematical model of computer equipment reliability. Bulletin of Cherkasy State Technological University, 4: 48-57. https://doi.org/10.24025/2306-4412.4.2022.269282
[16] O'Reilly, J. (2016). Network storage. Burlington: Morgan Kaufmann. https://www.oreilly.com/library/view/network-storage/9780128038659/.
[17] Mouromtsev, D.I., Shilin, I.A., Plyukhin, D.A., Baimuratov, I.R., Khaidarova, R.R., Dementeva, Yu.Yu., Ozhigin, D.A., Malysheva, T.A. (2021). Construction of knowledge graphs of normative documentation based on semantic modeling and automatic extraction of terms. Scientific and Technical Bulletin of Information Technologies, Mechanics and Optics, 2(21): 256-266. https://cyberleninka.ru/article/n/postroenie-grafov-znaniy-normativnoy-dokumentatsii-na-osnove-semanticheskogo-modelirovaniya-i-avtomaticheskogo-izvlecheniya/viewer.
[18] Shan, Y., Li, M., Chen, Y. (2017). Constructing target-aware results for keyword search on knowledge graphs. Data & Knowledge Engineering, 110: 1-23. https://doi.org/10.1016/j.datak.2017.02.001
[19] Dudar, Z.V., Shuklin, D.E. (2000). Semantic neural network as a formal language for describing and processing the meaning of texts in natural language. Radioelectronics and Informatics, 3: 72-76. https://cyberleninka.ru/article/n/semanticheskaya-neyronnaya-set-kak-formalnyy-yazyk-opisaniya-i-obrabotki-smysla-tekstov-na-estestvennom-yazyke.
[20] Jain, S., Jain, V., Balas, V. (2021). Web semantics. London: Academic Press. https://books.google.com.ua/books?hl=en&lr=&id=sBkIEAAAQBAJ&oi=fnd&pg=PP1&dq=Jain,+S.,+Jain,+V.,+%26+Balas,+V.+E.+(Eds.).+(2020).+Web+semantics+%E2%80%93+Cutting+edge+and+future+directions+in+health+care.+Elsevier.+ISBN:+9780128224687.&ots=sX-vqekDdI&sig=HIF7CNfoq56jj57K8VwyjgLFThE&redir_esc=y#v=onepage&q&f=false.
[21] Artyushina, L.A. (2020). Methods of information representation in simple semantic networks. Scientific and Technical Bulletin of Information Technologies, Mechanics and Optics, 3(20): 382-393. https://cyberleninka.ru/article/n/metody-predstavleniya-informatsii-v-prostyh-semanticheskih-setyah.
[22] Danchenko, A.L., Bybko, E.I. (2010). Automatic search for a learning path on semantic graphs of educational materials. East European Journal of Advanced Technologies, 4(46): 37-43. https://cyberleninka.ru/article/n/avtomaticheskiy-poisk-traektorii-obucheniya-na-semanticheskih-grafah-uchebnyh-materialov.
[23] Pak, N.I., Khegay, L.B., Akkasynova, Z.K., Bidaibekov, Y.Y., Kamalova, G.B. (2021). Preservice teacher training program for working with network mega-projects. Journal of Educators Online, 18(2): 1-13.
[24] Sakhipov, A., Yermaganbetova, M. (2022). An educational portal with elements of blockchain technology in higher education institutions of Kazakhstan: opportunities and benefits. Global Journal of Engineering Education, 24(2): 149-154.
[25] Tiwari, S., Rodriguez, F.O., Jabbar, M.A. (2022). Semantic Models in IoT and eHealth Applications. London: Academic Press.
[26] Hossain, M.M., Prybutok, V., Evangelopoulos, N. (2011). Causal latent semantic analysis (cLSA): An illustration. International Business Research, 2: 38-50. https://doi.org/10.25559/SITITO.15.201904.932-944
[27] Woss, W., Ehrlinger, L. (2018). Towards a definition of knowledge graphs. Semantics, 9: 73-77.
[28] Barlybayev, A., Sabyrov, T., Sharipbay, A., Omarbekova, A. (2017). Data base processing programs with using extended base semantic hypergraph. Advances in Intelligent Systems and Computing, 569: 28-37. https://doi.org/10.1007/978-3-319-56535-4_3
[29] Barlybayev, A., Sharipbay, A. (2015). An intelligent system for learning, controlling and assessment knowledge. Information (Japan), 18(5): 1817-1827.
[30] Robles, G., Méndez, J. (2018). Routley-Meyer Ternary Relational Semantics for Intuitionistic-Type Negations. London: Academic Press.
[31] Gurin, V.S., Kostrov, E.V., Gavrilenko, Yu.Yu., Saada, D.F., Ilyushin, E.A., Chizhov, I.V. (2019). Knowledge representation in the form of a graph: Basic technologies and approaches. Modern Information Technologies and IT Education, 4(15): 1-13. https://cyberleninka.ru/article/n/predstavlenie-znaniy-v-vide-grafa-osnovnye-tehnologii-i-podhody.
[32] Pozzi, F., Fersini, E., Messina, E., Liu, B. (2016). Sentiment analysis in social networks. Burlington: Morgan Kaufmann. https://www.researchgate.net/publication/303924235_Sentiment_Analysis_in_Social_Networks.
[33] Sandra, L., Heryadi, Y., Lukas, Suparta, W., Wibowo, A. (2021). Deep learning based facial emotion recognition using multiple layers model. In 2021 International Conference On Advanced Mechatronics, Intelligent Manufacture And Industrial Automation, ICAMIMIA 2021 – Proceeding, Surabaya, Indonesia, pp. 137-142. https://doi.org/10.1109/ICAMIMIA54022.2021.9809908
[34] Monte-Serrat, D.M., Cattani, C. (2021). The Natural Language for Artificial Intelligence. London: Academic Press. https://www.researchgate.net/publication/358749432_THE_NATURAL_LANGUAGE_FOR_ARTIFICIAL_INTELLIGENCE_-Pres_Intro.
[35] Sharp, B., Sedes, F., Lubaszewski, W. (2017). Cognitive Approach to Natural Language Processing. Oxford: ISTE Press.
[36] Medhi, D., Ramasamy, K. (2017). Network Routing. Burlington: Morgan Kaufmann. https://doc.lagout.org/science/0_Computer%20Science/2_Algorithms/Network%20Routing_%20Algorithms%2C%20Protocols%2C%20and%20Architectures%20%5BMedhi%20%26%20Ramasamy%202007-04-12%5D.pdf.
[37] Hakimov, Z.A., Medatov, A., Kotetunov, V., Kravtsov, Y., Abdullaev, A. (2023). Algorithm for the development of information repositories for storing confidential information. Proceedings on Engineering Sciences, 5(2): 227-238. https://doi.org/10.24874/PES05.02.005