Pallavi U. Nehete![]() | Deepak S. Dharrao*
| Deepak S. Dharrao*![]() | Priya Pise
| Priya Pise![]() | Anupkumar Bongale
| Anupkumar Bongale![]()
Copyright: ©2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Rescue efforts might be significantly complicated in flooded areas. In this study, we examine and evaluate the state-of-the-art in object detection and image enhancement techniques in flooded situations for the purpose of human rescue operations using various image processing, object detection, and low light image enhancement approaches. Partial visible images are difficult due to poor light, low contrast, and scattering. Faster R-CNN, YOLO (You Only Look Once), and SSD (Single Shot Detector) are just a few of the popular object identification methods. Advanced deep learning-based low-light enhancement approaches increase image quality by amplifying faint features, decreasing noise, and correcting color imbalances. These models use auto encoders, generative adversarial networks, and attention processes to rebuild images better than classic enhancement methods, making them useful for rescue pre-processing. The findings emphasized the role of real-time data analysis and communication systems in improving response times and operational efficiency. The application of Generative Adversarial Networks significantly improved the clarity and color accuracy of underwater images. These methods address water's refractive characteristics, floating debris, and human occlusion. For efficient and complete disaster management throughout all phases, subsequent attempts should focus on blending disaster management expertise, image processing techniques, and machine learning tools, as outlined by our study. This research can improve flood monitoring systems and disaster preparedness, response, and recovery.
human rescue operations, object detection, low light image enhancement, convolutional neural networks (CNN), disaster management
Applications ranging from autonomous driving to cyber security and human rescue all rely heavily on object detection and classification. However, there is a lack of data on how well machine learning algorithms perform in detecting. Accurate identification and detection of items, especially humans, is key to effective rescue operations, making this research gap especially important for human rescue systems.
Worldwide, natural disasters pose a persistent risk to human life and physical structures. More frequent and more powerful floods, hurricanes, and earthquakes have caused many fatalities and substantial economic damage in recent years. In example, floods are one of the earth's most frequent natural catastrophes, affecting tens of millions of people annually around the world. The danger of floods isn't restricted to drowning, but also includes the inability to obtain food, water, and medical care. In this respect, rescue activities are crucial in reducing the loss of life and damage caused by floods. In the wake of recent advancements in imaging technology, new tools and procedures have been developed to aid with human rescue operations in the event of floods. Object detection and low-light image enhancement are only two of the many image processing algorithms that have showed promise in locating people in flooded areas, which is essential for efficient rescue efforts. In this research, we'll go over how image processing can be used for rescue missions in flooded areas, focusing on object identification and image enhancing methods.
The current study presents a detailed examination of numerous methods that are utilized for the detection of humans in flooded regions, with a special focus on the integration of drones and unmanned aerial vehicles (UAVs) for the gathering and analysis of data. The research takes a critical look at the difficulties that arise when utilizing these methods for human rescue operations. These difficulties include doing an exhaustive analysis of the data's trustworthiness and determining whether or not required resources are available. The study not only provides an insightful review of the technologies that were explored, but it also emphasizes the essential for future research attempts to synergistically integrate knowledge in crisis management, advanced image processing techniques, and state-of-the-art Deep Learning tools. This is because the study not only offers an overview of the technologies that were investigated, but it also offers an overview of the technologies that were investigated. Because of this integration, a comprehensive and powerful approach to catastrophe management will be possible throughout all phases of operational activity.
To recognize and locate things of interest in an image is known as object detection. Humans in flooded regions can be located with the help of object detection during rescue operations. Faster R-CNN, YOLO (You Only Look Once), and SSD (Single Shot Detector) are just a few of the popular object identification methods utilized in image processing today. In flood-affected areas, this technique improves visibility of submerged or partially submerged objects. Faster R-CNN is a two-stage object detection system that employs a Region Proposal Network (RPN) to generate region proposals and a classifier to identify the objects. RPN, in conjunction with Faster R-CNN, can accurately localize objects such as vehicles, debris, or people within a flooded scene, which is critical for rescue and relief efforts. YOLO, on the other hand, does not require any intermediate steps and instead predicts the bounding boxes and class probabilities of the objects right away. The most recent versions of YOLO (such as YOLOv4 and YOLOv5) have demonstrated improved accuracy in detecting small objects, which can be useful for identifying individuals or smaller debris in flooded environments. convolutional neural networks (CNNs), for example, have shown promising results in enhancing images from flooded scenarios by automatically adjusting various parameters for optimal image quality. A multi-scale feature map is used in SSD, another one-stage object detection approach [1, 2].
Clear photographs are difficult to acquire when the rescue efforts carried out in the night. The quality of photos taken in poor lighting can be enhanced using various methods. Image fusion, deep learning, and techniques based on the Retinex theory are some of the most used approaches to enhancing low-light images in the processing of digital photographs. Methods based on the Retinex theory attempt to enhance image quality by decomposing it into its component parts (illumination and reflectance). On the other hand, image fusion is a technique that combines multiple photos of the same scene taken in different lighting conditions to produce an image of high quality. Because of the suspended particles, floodwaters are often murky, making visibility difficult. This turbidity can make objects difficult to see and detect. A variety of debris, including plants, furniture, and building materials, are frequently carried by floods and may show up in pictures at random. Debris complicates the visual scene, making it more difficult for algorithms to discern between relevant and irrelevant objects (such as people or cars). In these circumstances, standard object detection algorithms might have trouble correctly identifying objects. Low-light photo quality can also be enhanced by using deep learning techniques such as generative adversarial networks (GANs).
The research demonstrates the potential of aerial platforms in the collection of real-time data from flooded settings by utilizing the capabilities of unmanned aerial vehicles (UAVs) and drones. These platforms provide useful insights that can be used to recognize humans in an effective and precise manner. The authors stress how important it is to incorporate knowledge in disaster management in order to effectively use the capabilities offered by these technologies. In addition, the study examines the difficulties that are linked with the trustworthiness of data and the availability of resources, both of which are essential components in the effective execution of human rescue operations. The study motivates future research efforts to develop solutions that enhance the dependability of data and optimize the allocation of necessary resources because it identifies these problems. Figure 1 shows the general steps for object detection in flood rescue operations.
Figure 1. General steps for object detection
Deep learning object detection has transformed visual data interpretation and analysis. The method begins with the acquisition of a massive dataset of annotated photographs with tagged items of interest and bounding boxes. This dataset is separated into training and validation subsets. Training begins with convolutional neural networks (CNNs), deep learning architectures that handle picture data. These networks recognize patterns and features by convolving filters over the input image and passing the outputs through activation functions. Deepening the network helps it recognize more complicated features. The network can predict object class and location in a new image after training. Region-based CNNs (R-CNNs) and You Only Look Once (YOLO) improve object detection by proposing regions in the image where objects may occur and classifying them, making detection faster and more accurate. The model's predictions on the validation set are compared to annotations to measure accuracy and dependability in the final stage, fine-tuning and validation.
The seminal advancement in contemporary object detection research occurred in 2014 with the introduction of the inaugural deep neural network for object detection by Girshick et al. [3]. Convolutional neural networks (CNNs) were initially discovered by LeCun et al. [4]. However, their potential was not widely recognized at the time because to limitations in processing capacity. The successful outcome of the ImageNet Large Scale Visual Recognition Challenge in 2012 marked a significant milestone when Krizhevsky et al. [5] emerged as winners by employing a convolutional neural network (CNN) named AlexNet. The utilisation of graphic processing units (GPUs) for training purposes enabled the harnessing of the learning capabilities of convolutional neural networks (CNNs), so marking the inception of the deep learning era.
Performance assessment in these scenarios is conducted using the following key metrics: Precision, Recall, F1-Score, and Intersection over Union (IoU). In the context of flood scenarios, the detection of accurate objects (such as people or safe pathways) requires a high degree of precision. A high recall rate is essential in a rescue scenario to ensure that the maximum number of pertinent objects (such as stranded people) are identified. Omission of a detection could result in the loss of a life requiring rescue. The harmonic mean of Precision and Recall constitutes the F1-Score. F1-Score is essential in flood rescue for striking a balance between recall and the need to identify the greatest number of victims (precision versus correct identification of victims). Rapidly changing conditions necessitate real-time data for effective decision-making during flood rescue operations, where the capability to process images at a high frame rate (FPS) can potentially save lives. The combination of these metrics offers a thorough evaluation of the effectiveness of an object detection model in situations involving flood rescue.
Following flooding disasters, the inherent difficulties associated with partial visible image provides a substantial obstacle to expeditious and efficient rescue operations. Various factors such as insufficient lighting, diminished contrast, and light scattering sometimes result in the inadequacy of standard imaging techniques. Conventional methods for enhancing images, while effective in less challenging situations, encounter difficulties when confronted with the subtle complexity inherent in submerged scenes. Given the identified deficiency, there exists a pressing necessity to utilize sophisticated deep learning methodologies, specifically auto encoders, generative adversarial networks (GANs), and attention mechanisms. The aforementioned advanced techniques demonstrate the ability to enhance subtle details, significantly diminish background noise, and effectively rectify color discrepancies, resulting in improved visibility of previously obscured elements.
Autoencoders can help identify stranded people, assess structural damage, and navigate through debris-filled waters in flood scenarios. Convolutional autoencoders are promising at extracting relevant image features and reducing noise. They improve image quality under difficult conditions like floodwaters by learning to compress input data and reconstruct the output. GANs transformed image synthesis and enhancement. GANs can improve images by training a generator and a discriminator neural network simultaneously. For flood disaster management, GANs can create clearer, more detailed images from low-quality, distorted inputs. Clearer and more detailed imagery can help disaster management teams make better decisions and avoid missing critical areas in need.
Nevertheless, image improvement constitutes only a single component of the overall framework. After obtaining more distinct visual representations, the formidable undertaking of discerning and pinpointing probable individuals who may have been affected within the extensive flooded landscapes persists. The significance of object detection approaches, particularly those utilizing convolutional neural networks (CNNs) and region-based algorithms, becomes evident in this context. These algorithms, which have been trained using large datasets, have exhibited their capability to accurately identify human subjects even in challenging scenarios, such as situations involving the refractive nature of water and obstacles caused by floating debris.
Finally, it is important to note that this issue extends beyond the realm of technology in isolation. The implementation of a comprehensive disaster management strategy requires the integration of knowledge and skills from experienced specialists in the field of on-site rescue operations, together with the utilization of technical advancements. The objective of this study is to establish a connection between practical knowledge and technology improvements in order to facilitate a fundamental change in our approach to addressing and handling flood-related catastrophes. This will result in a complete, efficient, and more human-centered response.
2.1 Research questions
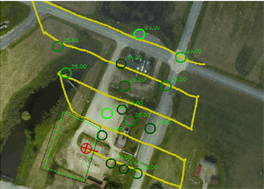
Thermal and Color imaging, Rudol and Doherty [6] devised a method for recognizing human bodies on the ground in natural outdoor settings. Using two video inputs (thermal and color), the presented system can recognize humans at greater distances while maintaining a classification rate of up to 25 Hz. As part of a larger, fully autonomous mission, the method was tried out on the UAVTech 1 unmanned helicopter platform. Human bodies are pinpointed on a map so aid can be strategically distributed.
The report stresses the need for rapid processing speeds for UAV-captured footage in order to prevent crucial details from being overlooked. Target coordinate computation (a) and flight route and geolocated body positions (b) are depicted in Figure 2.
3.1 Object detection techniques
In image processing, person detection is a common application of object detection techniques. Object detection is the action of seeking for and defining the boundaries of things of interest in an image. Traditional approaches like Haar cascade and HOG+SVM, as well as more modern methods like YOLO and Faster R-CNN, are just two examples of the many variations on object detection that have been created and refined over the years. These techniques have found use in many different fields, including self-driving cars, surveillance systems, and medical imaging. Object detection methods can be used to locate people who are lost or in need of assistance during rescue operations in flooded areas. Here, we'll examine the literature on the topic of human rescue operations in flooded areas, with a special emphasis on the various object identification techniques employed in image processing.
(a) Calculation of a target coordinates [6]
(b) Positioning of geolocated body and tracing of flight [6]
Figure 2. Target coordinate computation and flight route and geolocated body positions
An improved version of the Tiny YOLOv3 (you look only once) is capable of locating things efficiently [7]. The upgraded Tiny YOLOv3 makes use of the K-means clustering technique in order to provide an estimate of the size of the anchor boxes for the dataset. Pooling and convolution layers were added to the network in order to increase feature fusion and cut down on the total amount of parameters.
This enabled the network to function more effectively. Because of the topology of the network, there is an increase in both the upsampling and the downsampling of the data, which contributes to an improvement in the multi-scale fusion. The detection results have been greatly improved as a result of an update to the loss function that include the entire intersection over union. Hyperspectral Imaging Systems (HIS) is used in search-and-rescue operations by locating small items on the ocean's surface, including people [8]. HIS provides a method for analyzing images that uses object segmentation, spectral definition via a linear unmixing approach, and object classification to identify tiny objects. HIS method improves hyperspectral photographs, is more sensitive to minute items on the sea surface than humans are, and is less affected by sun glint. Unmanned Aerial Vehicles (UAVs) or drones are used to discover and locate injured, lost, and trapped humans during and after a crisis, employing cutting-edge technical equipment and artificial intelligence (AI) methodologies, shown in Figure 3 [9]. UAV system processes video sequences acquired by the drones and transmits detection results in real time to the ground station using AI-based object detection methods.
Refined method for detecting tiny objects with the Faster R-CNN uses two-stage detection strategy, the research proposed an enhanced loss function for bounding box regression based on Intersection over Union (IoU) [10]. As a result of the enhanced loss function and RoI pooling operation, bounding box regression and positioning deviation were enhanced, and overlapping object loss was prevented by the NMS algorithm. An accurate NMS strategy combined with substantially overlapping detections in an iterative fashion obtains the highest score [11]. Overlapping detections are clustered together throughout each iteration with a stricter threshold to regress for a new proposal based on the detection. After that is done, there is a slight dampening of the group's scores. The experimental results suggest that, compared to the state-of-the-art NMS methodologies, this strategy, which is simple to implement and doesn't need human supervision, may yield considerable gains in performance on the vast majority of classes.
(a) Samples of the obtained detection results in test videos [9]
(b) Samples of the obtained detection results in live video sequences [9]
Figure 3. Video sequences acquired by the drones [9]
Search and rescue (SAR) missions becomes stronger with the deployment of unmanned aerial vehicles (UAVs) equipped with real-time computer vision and deep learning algorithms for detecting and saving humans [12]. The system was evaluated using data from open-water swimmers, and its 67% mAP proves the efficacy of deep learning in the assessment of actual performance. The Nvidia Jetson TX1's real-time processing capacity is discussed, as is the system's hardware and software setup, and delays in processing are avoided. Since the suggested method is so effective in detection and classification, the research concludes that it can be used in any number of SAR missions. Automatic object detection with SAR efforts were used to aid the United States Coast Guard (USCG) in locating targets like people who had gone overboard, they developed an automatic target detection system using unmanned aerial vehicles (UAVs) and fixed surveillance cameras [13]. The detection time for small targets was drastically cut with the use of image segmentation, enhancement, and convolution neural networks. The findings suggest that the technique could aid emergency personnel in swiftly carrying out search and rescue missions. However, there are caveats to the study, such as the use of a single dataset; more work is needed to verify the system's efficacy across a variety of settings.
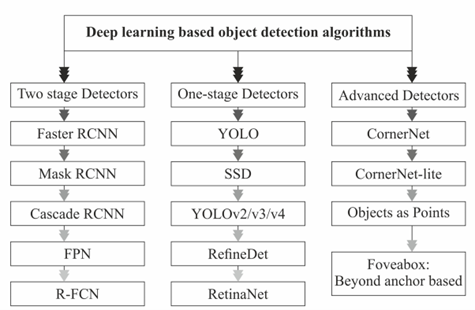
Additional research publications were reviewed in order to provide a detailed overview of the object detection algorithms utilized in image processing for human rescue operations in flooded situations. Researchers from all over the world have also come up with hybrid models, which combine the best features of different models into one superior system capable of yielding the most reliable results. Real-time human detection has been the subject of extensive study, with data including pictures and geolocation information being used in a variety of settings. The results demonstrate that these methods can be used in human rescue operations and are successful at recognizing items and people in flooded environments. Figure 4 mentions the various deep Learning based object detection techniques. Researchers can use the table as a reference to determine which of the several object identification approaches employed in image processing for human rescue operations in flooded situations is most suited their needs.
Figure 4. Deep learning based object detection techniques
3.1.1 YOLO
Diwan et al. [14] developed an object detection system suitable for implementation in production systems. You Only Look Once (YOLO) models have been widely embraced across many applications primarily due to their expedited inference times, prioritising speed over detection accuracy. The study demonstrates enhanced speed and accuracy in comparison to its predecessors. Liu et al. [15] suggested a brand-new Image-Adaptive YOLO (IA-YOLO) framework that allows for the adaptive enhancement of each image for improved detection performance. For the YOLO detector, whose parameters are predicted by a tiny convolutional neural network (CNN-PP), a differentiable image processing (DIP) module is specifically introduced to account for the unfavourable weather conditions. Our end-to-end learning of CNN-PP with YOLOv3 assures that CNN-PP can learn a suitable DIP to improve the image for detection in a weakly supervised way. In both good and bad weather, our suggested IA-YOLO technique can analyse photos adaptively.
3.1.2 Faster R-CNN
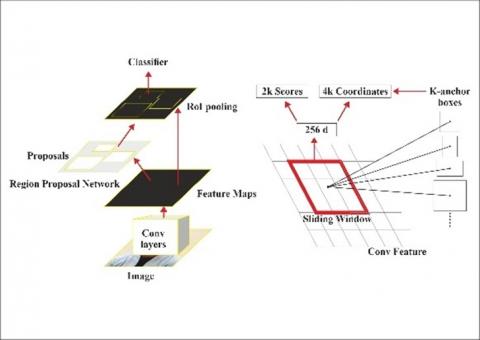
Girshick [16] used an enhanced network from the R-CNN termed as Fast R-CNN. In lieu of executing the Convolutional Neural Network (CNN) on each of the 2,000 area proposals, the input image has been modified. As shown in Figure 5, the process involves passing the input data through a convolutional neural network (CNN) in order to build a feature map. The calculation of the Region of Interest (RoI) remains reliant on the input image through the utilisation of selective search. Despite the notable advancements made by Fast R-CNN in terms of enhancing the efficiency of training and testing durations in region proposal techniques, the generation of proposals continued to pose a substantial obstacle to the network's overall performance. Ren et al. [17] introduced a further adaptation of the R-CNN network. Instead of employing selective search for proposal calculation, Faster R-CNN incorporates an auxiliary tiny convolutional neural network to perform region proposal computation.
Figure 5. Faster R-CNN architecture and Region Proposal Network (RPN)
3.1.3 Single Shot Detector (SSD)
Liu et al. [18] introduced a more efficient Single Shot MultiBox Detector (SSD) network that accomplishes both classification and localization tasks in a single forward pass. Simonyan and Zisserman [19] constructed the network in question using the VGG-16 object categorization network as its foundation. The object detection process in the SSD framework involves the utilisation of convolutional maps that are extracted by the VGG-16 model. The network comprises six layers, with five of these layers dedicated to making predictions. Notably, three of these prediction layers deviate from the standard practise of generating four forecasts, instead producing six predictions. SSD, like to the Faster R-CNN anchor box methodology, use default boxes as a means to generate predictions.
Quantitative results from different test sets can be used to compare underwater image enhancement methods, including the Fusion Water-GAN (FW-GAN). FW-GAN had the highest SSIM (Structural Similarity Index) and PSNR (Peak Signal-to-Noise Ratio) scores, 0.86 and 27.18 dB, respectively. UGAN, Water-Net, and Ucolor performed well but were less effective than FW-GAN. UGAN had 0.81 SSIM and 23.70 dB PSNR. Ucolor had the second-best SSIM and PSNR at 0.88 and 20.93 dB, respectively. FW-GAN performed better overall. The highest scores were for FW-GAN in Perception Score (PS), UCIQE, UIQM, and Twice Mixing. FW-GAN scored 2.93 in PS, 0.598 in UCIQE, 2.84 in UIQM, and 1.49 in Twice Mixing for Test-C60. Test-S16 scored 3.28 in PS, 0.593 in UCIQE, 2.47 in UIQM, and 7.68 in entropy, the highest. FW-GAN performs better at improving underwater images across metrics and test sets. In SSIM, PSNR, and other underwater image quality metrics like UCIQE and UIQM, it excels.
3.2 Low light image enhancement techniques
Low light is a major obstacle in the realm of image processing for human rescue missions. Disaster-stricken locations often have poor lighting, making it difficult for rescue workers to find survivors. Researchers have worked hard to develop a variety of low light image enhancement approaches to help overcome this difficulty. These methods are an attempt to remedy the difficulty of human identification in photos taken in dim light. We will examine the various studies conducted in this field that have led to the creation of several low light picture enhancement methods in the upcoming literature review section.
Low light images can be improved by estimating the lighting at each pixel [20]. The original illumination map is refined to produce the final illumination map, which is then effectively enhanced by imposing a preceding structure on it. The studies the authors ran on difficult low-light photos proved the efficacy of their proposed method and showed that it was more effective and efficient than numerous state-of-the-art solutions. Refined Retinax theory is also another method for enhancing images with low light, based and to solve the challenge of identifying lane markings [21]. Experiments show that the proposed method effectively extracts lane-line edges and reduces noise in low-light regions where lane-line illumination is weak. In addition, it may increase the detection accuracy of a system designed to help motorists.
The publication titled ‘Visual Information Processing Group’ at NASA's Langley Research Center details their work on a visual servo-based technique for improving images [22, 23]. It shows how limited current imaging technologies are in low-visibility environments including precipitation, fog, smoke, and smog. An example of enhanced image has been given in Figure 6. In this publication, the applications including perimeter surveillance, military/security/law enforcement operations, port security, and air/sea rescue services, this technology has been shown to significantly increase the range and effectiveness of imaging systems, hence enhancing public safety.
Figure 6. Original image (left) compared with the enhanced image (right) [23]
DPIENet is a revolutionary deep learning network that can fix photographs that have poor lighting, plenty of noise, and inaccurate colors [24]. The network exploits exposure variation to reconstruct pictures by synthesizing numerous exposures from a single image. As the results of the study showed, DPIENet beat state-of-the-art approaches on benchmark datasets and user studies, suggesting its potential in consumer photography and intelligent systems like automated driving and video surveillance. RNet framework, which has multiresolution branches that can gather local and global context through several streams, leading to a deeper comprehension of specifics at varying levels [25]. The proposed technique may find use in a number of contexts, such as environmental monitoring, agriculture, and emergency management. The study gives a viable method for improving low-light aerial photographs and emphasizes the significance of applying deep learning techniques for this purpose.
Researchers have used deep learning models to improve image quality, as seen by studies showing reduced noise, enhanced contrast, and generally improved image quality. Researchers have developed hybrid/fusion models, which combine different models to create a more effective hybrid system, to boost the reliability of the results. Underwater picture enhancement with multi-scale fusion is the focus of models like the Generative Adversarial Network (FW-GAN), the Parametric Fuzzy Transform for image contrast enhancement with Homomorphic Filtering, and the Low-light picture Enhancement with Deep Blind Denoising. In order to increase the quality of low light photographs and the accuracy of object detection, the models have been trained and evaluated using images taken from a variety of various sources and lighting circumstances.
Low-light picture enhancement improves image contrast globally and locally in a given gray area based on the original image pixels' gray values. The augmented image should have good image quality for human visual perception, noise suppression, image entropy maximization, brightness maintenance, etc [26]. Low-light image enhancement (LIME) technology is simple but effective [27]. Each pixel's illumination is evaluated by determining the greatest value in R, G, and B channels. The final illumination map is the original illumination map with a structure preceding. A well-constructed lighting map allows for enhancement. Using multi-peak histogram equalization along with local data, this method enhances the global histogram equalization [28]. This approach borrows characteristics from other approaches. Additionally, it entirely controls the degree of the improvement. Regardless of their brightness, experimental data demonstrate that it is highly successful in boosting low-contrast images. When the correct features (local information) can be recovered, the multi-peak GHE approach is particularly effective at enhancing a variety of photos. Hu et al. [29] studied new technologies used and evaluates the imaging principle of underwater photos as well as the causes of their deterioration in quality. Second, it emphasizes the widely used deep learning technology for improving underwater images. Underwater video enhancement methods are also discussed. Additionally, it introduces several common video image assessment indexes, underwater picture-specific indexes, and standard underwater data sets. A quick method of improvement for underwater image color correcting can handle scenes with uneven lighting since it is based on the gray-world assumption and used in the Ruderman-opponent color space [30]. The suggested solution uses integral pictures to quickly fix colors while accounting for locally changing brightness and chrominance. For the purpose of obtaining the desired corrected image (right), our approach can be thought of as an adaptive image-dependent filter (center). Reduced noise levels, greater dark-area exposure, and higher overall contrast are the hallmarks of enhanced photos and films, while the smallest details and edges are noticeably improved [31]. When dealing with photos of extremely dark settings taken with a subpar strobe and artificial light, the technique has limits. An automatic algorithm for pre-processing underwater photographs enhances the quality of the images and lessens underwater disturbances [32]. It is made up of multiple independent processing steps that are done in succession to rectify uneven lighting, reduce noise, boost contrast, and modify colors. An edge detection robustness criterion will be used to evaluate the filtering's effectiveness. In addition to not requiring parameter adjustments or prior knowledge of the acquisition conditions, this algorithm is automatic. A self-calibrated module that realizes the convergence between results at each level, delivering gains that only employ the computationally lightest stages of the cascaded pattern the one fundamental building block for inference, which significantly reduces the need for further research cost of calculation [33]. Then, in order to improve the model's ability to adapt generic scenes. An improved Lagrange multiplier based alternating direction minimization approach without logarithmic transformation to successfully address the optimization problem [34]. The usefulness of the suggested strategy for improving low-light images is shown by experimental findings. The suggested approach can also be expanded to address a variety of related issues, including image improvement for remote sensing or underwater applications as well as in foggy or dusty environments. A reinforcement-net also improves the output image's color and contrast [35]. Extensive tests on numerous datasets show that our method can deliver high fidelity enhancement results for lowlight photographs and performs significantly better than the state-of-the-art techniques both numerically and aesthetically.
A feedforward convolutional neural network with various Gaussian convolution kernels is equal to a multi-scale Retinex which considers a convolutional neural network (MSR-net) that immediately learns an end-to-end mapping between dark and bright images as a result of this feature [36]. Low-light picture enhancement is viewed as a machine learning problem, which is fundamentally different from prior methods. The majority of the parameters in this model are optimized using back-propagation, whereas the values in conventional models depend on an artificial environment. A cutting-edge enhancement technique that makes use of camera reaction characteristics to reduce distortion [37]. To create a precise camera response model, first looked into the correlation between two photos taken at various exposures. The exposure ratio map is then estimated using the lighting estimation methods. Finally, based on the estimated exposure ratio map, we utilize our camera response model to set each pixel to the appropriate exposure. A new self-attention module has been added to the SNRaware transformer [38]. Numerous tests, including user studies, show that our framework regularly outperforms other solutions using the same network structure on meaningful benchmarks. A unique Deep Lighting Network (DLN) that takes advantage of convolutional neural networks' (CNNs') is a most recent technological advancements [39]. Several Lightening BackProjection (LBP) blocks make up the planned DLN. To learn the residual for normal-light estimations, the LBPs iteratively carry out the brightening and darkening procedures. The Feature Aggregation (FA) block, an extension of the squeeze-and-extension structure that looks at both the spatial and channel-wise dependencies among different feature maps, is used to fuse the feature maps with various receptive fields in order to increase the representational power of the input of the lightening process. A very straightforward and efficient technique called LIME to improve low-light photos [40]. In more detail, the greatest value in the R, G, and B channels is used to determine the illumination of each individual pixel. By applying a structure beforehand as the final illumination map, we further improve the initial illumination map. With a carefully created illumination map, the augmentation can be carried out as intended.
For improving low-light images, a unique Retinex-based Real-low to Real-normal Network (R2RNet) is used [41]. This network has three subnets: a Decom-Net, a Denoise-Net, and a Relight-Net. These three subnets are utilized for decomposing, denoising, enhancing contrast, and preserving detail, in that order. R2RNet uses frequency information in addition to spatial information from the image to maintain fine details while improving contrast. Extensive tests using publicly accessible datasets showed that the suggested network, which consists of three subnetworks called the Decom-Net, Denoise-Net, and Relight-Net, performs better than the current state-of-the-art methods both numerically and visually. The architecture has the strength and adaptability to train on both paired and unpaired data [42]. On the one hand, the suggested network is well suited to extract a number of coarse-to-fine band representations, whose estimations are advantageous to one another in a recursive process. However, the extracted band representation of the enhanced image in the first step of DRBN (recursive band learning) fills the gap between the perceptual preference for real high-quality images and the restoration knowledge of matched data. Through adversarial learning, its second stage (band recomposition) learns to recompose the band representation in order to meet the perceptual characteristics of high-quality images. With paired low/normal-light images, the DRBN reconstructs a linear band representation of an enhanced normal-light image. To maintain the color consistency for LLIE, a new DCC-Net deep color consistent network can be used [43]. A novel "divide and conquer" cooperative technique is put forth that can retain color information and improve lighting simultaneously. The color histogram is useful for maintaining color constancy and is used to construct appropriate structures and textures from grayscale images. In other words, they are both used to work together to fulfill the LLIE task. A gradient-based approach for improving low-light images can be used [44]. Enhancing dark region gradients is crucial since they are more perceptible to the human visual system than absolute values. The intensity-range restrictions are also taken into account for the image integration. The intensity-range limitation for the picture integration with the improved gradients has also been added. The experiments show that the low-light photos can be effectively improved by using our straightforward approach. The design a two-stream estimation system with reflectance and illumination estimation networks [45]. This uses the physical concept to create a context-sensitive decomposition connection to bridge the two-stream mechanism. For edge-aware smoothness, spatially-varying lighting guidance is included. To evaluate the architecture, CSDNet (paired supervision) and CSDGAN (unpaired supervision) were built using different training patterns. Color and structural information can be recovered best by using contextual spatial scale dependencies.
3.2.1 Autoencoders
Kumar and Goel [46] proposed approach involves the use of an autoencoder that possesses the ability to encode and decode the structural characteristics of images, with the aim of improving their resolution. The model exhibits a tendency to acquire knowledge about the lower-dimensional characteristics of ambiguous images and subsequently generate a higher resolution representation by making predictions and improving their dimensions. The schematic of an autoencoder is shown in Figure 7. The proposed model effectively addresses the constraints inherent in current denoising filter approaches and offers a superior level of augmentation in image quality. The application of autoencoders in the study of low light resolution enhancement has been explored, specifically in the context of improving the illumination of images with poor lighting conditions.
Figure 7. Schematic of an autoencoder
3.2.2 Generative Adversarial Networks (GANs)
Yan et al. [47] developed an approach for enhancing low-light images by utilising a Generative Adversarial Network (GAN) that incorporates an optimised enhanced network module. The objective was to develop an improved network module that can effectively optimise Generative Adversarial Networks (GANs) for the purpose of enhancing low illumination images. This enhancement in depth enhances the network's capacity to effectively model image enhancement tasks, particularly those involving low illumination conditions. Figure 8 shows the enhanced network optimized generative adversarial network for image enhancement.
Figure 8. Enhanced network optimized generative adversarial network for image enhancement
The numerous image processing approaches that can be used for human rescue operations in flooded situations are highlighted in this study's literature evaluation. The evaluated works demonstrate the utility of machine learning and deep learning models for human detection in flood-affected areas through the use of different types of enhancing techniques and object detection. The accuracy of human recognition in flooded areas has also been improved by the use of object detection methods as Faster R-CNN, You Only Look Once (YOLO), and Single Shot Detector (SSD). Improving the visibility of photographs acquired in low light circumstances was another topic covered in the literature study. Several hybrid and fusion models based on deep learning for image enhancement, image contrast, and denoising have been reported in the reviewed research. These models have been shown to be useful for enhancing the object detection accuracy of photos obtained from a wide range of sources, in a variety of locations and lighting situations.
Large volumes of labeled training data, which can be challenging to obtain, particularly in a variety of dynamic flood scenarios, are needed for CNNs. R-CNN and its early variants can be slow even though they are accurate, which makes them less suitable for real-time applications in flood scenarios. When speed is crucial, use more modern and effective versions like SSD or YOLO. Substantial computational resources are needed for advanced image processing techniques like FW-GAN, and these resources may not always be available, particularly in rural or resource-constrained areas impacted by flooding. Real-time or nearly real-time data processing is frequently required for flood disaster management, but this can be difficult for complicated models like FW-GAN. The deployment of CNNs, R-CNNs, and GANs in flood disaster management can be made more practical and effective by addressing these limitations with targeted strategies, which will ultimately improve preparedness and response in flood scenarios.
The need of deploying drones and UAVs to collect data in the disaster zone and analyze it for human detection has been emphasized in the evaluated studies as well. These UAVs have been crucial in gaining access to previously inaccessible areas and gathering data that would have been impossible to obtain in any other way. Drones and other unmanned aerial vehicles (UAVs) may help humans discover flooded areas more precisely and quickly.
Integration of drones or UAVs with machine learning models for real-time flood image processing and analysis is a rapidly evolving field. Drones with high-resolution cameras and other sensors like infrared or thermal cameras are sent over flood-ravaged areas. This step may involve image correction for lighting, camera angle distortion, or movement blur. Segmenting images into machine learning model-friendly sizes or formats may also be necessary. The models could use CNNs, R-CNNs, GANs, or other architectures. These models detect people, animals, and critical objects, segment flooded areas, and classify images.
The difficulties of employing such methods in the context of human rescue operations were, however, addressed in the reviewed literature. The biggest problems are still the accessibility of resources and the trustworthiness of data. Another issue is that setting up and maintaining these systems requires specialized knowledge and skills. Solving these problems and enhancing the performance of these systems is crucial for human detection in flooded areas.
The research analyzed here show that image processing techniques have the potential to aid in human rescue efforts during floods. The literature evaluation highlighted the importance of further study to enhance the reliability and performance of human detection. Human rescue efforts can benefit greatly from the use of drones and UAVs in conjunction with machine learning and deep learning models. In order for these methods to be useful in the context of human rescue operations, we must work to overcome the obstacles in their way and enhance their dependability and efficiency. The article centered on the implementation of deep learning models for image processing tasks. According to the research, these models cannot guarantee top-notch results on their own. To ensure optimal performance, hyperparameters like learning rates, regularization, number of hidden layers, etc. must be fine-tuned in addition to the model's development.
Low light improvement techniques help overcome illumination issues in photography, surveillance, astronomy, and other fields. In low-light conditions, these methods improve image quality and visibility. To improve image quality, low light imaging requires specialized techniques to reduce noise, contrast, detail loss, and color distortion. With deep learning, low light enhancement has changed. U-Net and Pix2Pix use convolutional neural networks to map low-light photos to their better versions. GANs train on paired data to create realistic low-light images. Balance between augmentation and naturalness is still a challenge. Over-enhancement and illumination adaptation are continuing areas of research. Multi-frame fusion techniques combine photos to improve low light. Exposure bracketing, picture stacking, and super-resolution fusion increase resolution, dynamic range, and noise reduction, respectively. These methods use redundancy between frames to create a single high-quality image.
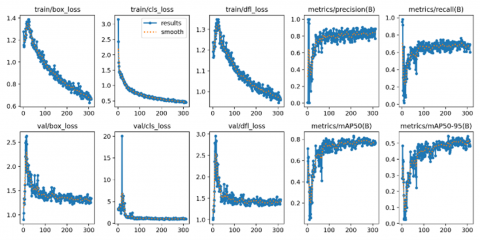
After reviewing various algorithms for Object detection (human recognition) in flooded areas for improved human detection we have developed fine-tuned model of YOLOv8. By training the YOLOv8 on a dataset containing images of flood scenarios annotated with human presence, the model can effectively learn to identify and localize individuals amidst the scene. We have used dataset total of 500 images which are distributed, with 350 images allocated for training, 50 for testing, and 100 for validation. Training, the model's performance is assessed using the test set, measuring its ability to generalize to unseen data. Additionally, the validation set aids in fine-tuning the model's parameters and assessing its performance during training iterations, ensuring robustness and reliability in real-world applications. Following Figure 9 shows the results of our fine-tuned YOLOv8 model.
In Figure 9 "train/box_loss" metric tracks the loss in bounding box regression during object detection model training. Lower values indicate better performance, showing closer alignment with ground truth bounding boxes. The "train/cls_loss" metric tracks classification loss in object detection model training, indicating its accuracy in identifying object classes. Lower values reflect better alignment with actual classes, improving as the model learns. The "train/dfl_loss" metric measures regression loss in object detection training, focusing on bounding box prediction accuracy. Lower values indicate better alignment with actual bounding box coordinates, improving as the model learns. The "metrics/precision(B)" metric measures the accuracy of positive predictions for class B in object detection. The "metrics/recall(B)" metric measures an object detection model's ability to correctly identify instances of class B. Below Figure 10 shows the how fine-tuned YOLOv8 model detects the human objects.
In future we are also trying to implement various improved object detection algorithms for human dection in flood-prone areas, encompassing various lighting conditions encountered in such environments.
Figure 9. Fined-Tuned YOLOv8 model results
(a) Trained image for human detection
(b) Predicted image for human detection
Figure 10. Human prediction fined-tuned YOLOv8 model results
Cutting-edge deep learning methodologies, including autoencoders, generative adversarial networks (GANs), and attention mechanisms, hold significant promise for augmenting image quality in underwater settings typified by diminished illumination, reduced contrast, and scattering phenomena. This innovation has the potential to significantly enhance visibility and object detection skills, particularly in the context of identifying individuals during rescue operations. The implications of this technological innovation encompass a range of potential consequences and effects.
5.1 Implications
Using strong data security measures to keep private data safe from people who shouldn't have access to it or from being stolen. When using AI in rescue operations, it's important to think about ethical issues, especially when it comes to privacy and possible algorithmic biases. Following privacy laws and rules set by local privacy laws, which tell us how to handle data and protect people's rights. By addressing these problems ahead of time, AI can be used safely and effectively in rescue operations, getting the most out of it while minimizing the harm it could cause.
5.2 Limitations
The collaboration of hardware engineers, emergency responders, and AI researchers is essential to the development of practical, dependable, and efficient AI-driven rescue systems. By working together, we can make sure that technology development is in line with the practical requirements of disaster relief, which can result in innovations that greatly improve the efficacy of rescue operations.
The study's findings offer an overview of the various image processing techniques that can be applied to flood-related search and rescue operations. This paper discusses and analyzes the various enhancing and object detection approaches that have been used by researchers to search for people in flooded areas. Additionally, low-light picture enhancement techniques have been studied to improve the clarity of images captured in low light. Researchers have created a number of models, including the fully-connected generative adversarial network (FW-GAN) and the homomorphic filtering-based parametric fuzzy transform, to increase the accuracy of object detection in low-light photos.
Unmanned aerial vehicles (UAVs) can assist in gathering data in disaster areas and analyzing it to look for indications of human life, according to the research. Concerns about data integrity and resource availability that come up when using these techniques for human rescue operations were also covered in the study. Ongoing research and development in the field of image processing for rescue operations is necessary to ensure the efficacy and accuracy of human detection in flooded areas. Future research should concentrate on hybrid and fusion models, which incorporate components from different models that already exist, in order to develop the most effective and efficient systems. This will improve the effectiveness of rescue operations for residents in areas affected by flooding.
Low light enhancement techniques for flood object detection could be advantageous for flood monitoring systems. Due to inadequate lighting, traditional image capture methods may mask crucial information during floods. Event photos can be enhanced by multi-frame fusion, exposure enhancement, and noise reduction. The system's adaptability to various lighting conditions and object characteristics is enhanced by deep learning-based flood object identification. In flooded environments, neural networks are able to learn complex patterns that enhance object detection and decrease false positives. As floods become more common and severe, low light enhancement techniques for flood object detection will become more crucial. Systems for monitoring floods as well as preparedness, response, and recovery for disasters can be enhanced by this research. By improving these techniques, we can increase our resistance to floods.
[1] Ren, S., He, K., Girshick, R., Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. https://doi.org/10.48550/arXiv.1506.01497
[2] Redmon, J., Farhadi, A. (2017). YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 7263-7271. https://doi.org/10.1109/cvpr.2017.690
[3] Girshick, R., Donahue, J., Darrell, T., Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, pp. 580-587. https://doi.org/10.1109/cvpr.2014.81
[4] LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., Jackel, L.D. (1989). Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4): 541-551. https://doi.org/10.1162/neco.1989.1.4.541
[5] Krizhevsky, A., Sutskever, I., Hinton, G.E. (2012). Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25.
[6] Rudol, P., Doherty, P. (2008, March). Human body detection and geolocalization for UAV search and rescue missions using color and thermal imagery. In 2008 IEEE Aerospace Conference, Big Sky, MT, USA, pp. 1-8. https://doi.org/10.1109/AERO.2008.4526559
[7] Gai, W., Liu, Y., Zhang, J., Jing, G. (2021). An improved Tiny YOLOv3 for real-time object detection. Systems Science & Control Engineering, 9(1): 314-321. https://doi.org/10.1080/21642583.2021.1901156
[8] Yan, L., Noro, N., Takara, Y., Ando, F., Yamaguchi, M. (2015). Using hyperspectral image enhancement method for small size object detection on the sea surface. Image and Signal Processing for Remote Sensing XXI, 9643: 163-171. https://doi.org/10.1117/12.2194606
[9] Rizk, M., Slim, F., Charara, J. (2021). Toward AI-assisted UAV for human detection in search and rescue missions. In 2021 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, pp. 781-786. https://doi.org/10.1109/DASA53625.2021.9682412
[10] Cao, C., Wang, B., Zhang, W., Zeng, X., Yan, X., Feng, Z., Liu, Y.T., Wu, Z. (2019). An improved faster R-CNN for small object detection. IEEE Access, 7: 106838-106846. https://doi.org/10.1109/ACCESS.2019.2932731
[11] Qiu, S., Wen, G., Deng, Z., Liu, J., Fan, Y. (2018). Accurate non-maximum suppression for object detection in high-resolution remote sensing images. Remote Sensing Letters, 9(3): 237-246. https://doi.org/10.1080/2150704X.2017.1415473
[12] Lygouras, E., Santavas, N., Taitzoglou, A., Tarchanidis, K., Mitropoulos, A., Gasteratos, A. (2019). Unsupervised human detection with an embedded vision system on a fully autonomous UAV for search and rescue operations. Sensors, 19(16): 3542. https://doi.org/10.3390/s19163542
[13] Yun, K., Nguyen, L., Nguyen, T., Kim, D., Eldin, S., Huyen, A., Lu, T., Chow, E. (2019). Small target detection for search and rescue operations using distributed deep learning and synthetic data generation. https://doi.org/10.48550/arXiv.1904.11619
[14] Diwan, T., Anirudh, G., Tembhurne, J.V. (2023). Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimedia Tools and Applications, 82(6): 9243-9275. https://doi.org/10.1007/s11042-022-13644-y
[15] Liu, W., Ren, G., Yu, R., Guo, S., Zhu, J., Zhang, L. (2022). Image-adaptive YOLO for object detection in adverse weather conditions. Proceedings of the AAAI Conference on Artificial Intelligence, 36(2): 1792-1800. https://doi.org/10.1609/aaai.v36i2.20072
[16] Girshick, R. (2015). Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1440-1448.
[17] Ren, S., He, K., Girshick, R., Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6): 1137-1149. https://doi.org/10.1109/TPAMI.2016.2577031
[18] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C. (2016). SSD: Single shot MultiBox detector. In European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, pp. 21-37. https://doi.org/10.1007/978-3-319-46448-0_2
[19] Simonyan, K., Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/arXiv.1409.1556
[20] Guo, X., Li, Y., Ling, H. (2016). LIME: Low-light image enhancement via illumination map estimation. IEEE Transactions on Image Processing, 26(2): 982-993. https://doi.org/10.1109/TIP.2016.2639450
[21] Ma, H., Lv, W., Li, Y., Liu, Y. (2021). Image adaptive contrast enhancement for low-illumination lane lines based on improved Retinex and guided filter. Applied Artificial Intelligence, 35(15): 1970-1989. https://doi.org/10.1080/08839514.2021.1997212
[22] Woodell, G., Jobson, D.J., Rahman, Z.U., Hines, G. (2005). Enhancement of imagery in poor visibility conditions. Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Security and Homeland Defense IV, 5778: 673-683. https://doi.org/10.1117/12.601965
[23] Wu, J., Liu, X., Lu, Q., Lin, Z., Qin, N., Shi, Q. (2022). FW-GAN: Underwater image enhancement using generative adversarial network with multi-scale fusion. Signal Processing: Image Communication, 109: 116855. https://doi.org/10.1016/j.image.2022.116855
[24] Panetta, K., KM, S.K., Rao, S.P., Agaian, S.S. (2022). Deep perceptual image enhancement network for exposure restoration. IEEE Transactions on Cybernetics, 53(7): 4718-4731. https://doi.org/10.1109/TCYB.2021.3140202
[25] Singh, A., Chougule, A., Narang, P., Chamola, V., Yu, F.R. (2022). Low-light image enhancement for UAVs with multi-feature fusion deep neural networks. IEEE Geoscience and Remote Sensing Letters, 19: 1-5. https://doi.org/10.1109/LGRS.2022.3181106
[26] Wang, W., Wu, X., Yuan, X., Gao, Z. (2020). An experiment-based review of low-light image enhancement methods. IEEE Access, 8: 87884-87917. https://doi.org/10.1109/ACCESS.2020.2992749
[27] Guo, X., Li, Y., Ling, H. (2016). LIME: Low-light image enhancement via illumination map estimation. IEEE Transactions on Image Processing, 26(2): 982-993. https://doi.org/10.1109/TIP.2016.2639450
[28] Cheng, H.D., Shi, X.J. (2004). A simple and effective histogram equalization approach to image enhancement. Digital Signal Processing, 14(2): 158-170. https://doi.org/10.1016/j.dsp.2003.07.002
[29] Hu, K., Weng, C., Zhang, Y., Jin, J., Xia, Q. (2022). An overview of underwater vision enhancement: From traditional methods to recent deep learning. Journal of Marine Science and Engineering, 10(2): 241. https://doi.org/10.3390/jmse10020241
[30] Neumann, L., Garcia, R., Jánosik, J., Gracias, N. (2018). Fast underwater color correction using integral images. Instrumentation Viewpoint, 2018(20): 53-54.
[31] Ancuti, C., Ancuti, C. O., Haber, T., Bekaert, P. (2012). Enhancing underwater images and videos by fusion. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, pp. 81-88. https://doi.org/10.1109/CVPR.2012.6247661
[32] Bazeille, S., Quidu, I., Jaulin, L., Malkasse, J.P. (2006). Automatic underwater image pre-processing. In CMM'06-Caracterisation Du Milieu Marin.
[33] Ma, L., Ma, T., Liu, R., Fan, X., Luo, Z. (2022). Toward fast, flexible, and robust low-light image enhancement. arXiv:2204.10137. https://doi.org/10.48550/arXiv.2204.10137
[34] Li, M., Liu, J., Yang, W., Sun, X., Guo, Z. (2018). Structure-revealing low-light image enhancement via robust Retinex model. IEEE Transactions on Image Processing, 27(6): 2828-2841. https://doi.org/10.1109/TIP.2018.2810539
[35] Lv, F., Li, Y., Lu, F. (2021). Attention guided low-light image enhancement with a large scale low-light simulation dataset. International Journal of Computer Vision, 129(7): 2175-2193. https://doi.org/10.1007/s11263-021-01466-8
[36] Shen, L., Yue, Z., Feng, F., Chen, Q., Liu, S., Ma, J. (2017). MSR-net: Low-light image enhancement using deep convolutional network. arXiv preprint arXiv:1711.02488. https://doi.org/10.48550/arXiv.1711.02488
[37] Ying, Z., Li, G., Ren, Y., Wang, R., Wang, W. (2017). A new low-light image enhancement algorithm using camera response model. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, pp. 3015-3022. https://doi.org/10.1109/ICCVW.2017.356
[38] Xu, X., Wang, R., Fu, C.W., Jia, J. (2022). SNR-aware low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, pp. 17714-17724. https://doi.org/10.1109/CVPR52688.2022.01719
[39] Wang, L.W., Liu, Z.S., Siu, W.C., Lun, D.P. (2020). Lightening network for low-light image enhancement. IEEE Transactions on Image Processing, 29: 7984-7996. https://doi.org/10.1109/TIP.2020.3008396
[40] Guo, X. (2016, October). LIME: A method for low-light image enhancement. In Proceedings of the 24th ACM International Conference on Multimedia, pp. 87-91. https://doi.org/10.1145/2964284.2967188
[41] Hai, J., Xuan, Z., Yang, R., Hao, Y., Zou, F., Lin, F., Han, S. (2023). R2rnet: Low-light image enhancement via real-low to real-normal network. Journal of Visual Communication and Image Representation, 90: 103712. https://doi.org/10.1016/j.jvcir.2022.103712
[42] Yang, W., Wang, S., Fang, Y., Wang, Y., Liu, J. (2020). From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 3063-3072. https://doi.org/10.1109/CVPR42600.2020.00313
[43] Zhang, Z., Zheng, H., Hong, R., Xu, M., Yan, S., Wang, M. (2022). Deep color consistent network for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, pp. 1899-1908. https://doi.org/10.1109/CVPR52688.2022.00194
[44] Tanaka, M., Shibata, T., Okutomi, M. (2019). Gradient-based low-light image enhancement. In 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, pp. 1-2. https://doi.org/10.1109/ICCE.2019.8662059
[45] Ma, L., Liu, R., Zhang, J., Fan, X., Luo, Z. (2021). Learning deep context-sensitive decomposition for low-light image enhancement. IEEE Transactions on Neural Networks and Learning Systems, 33(10): 5666-5680. https://doi.org/10.1109/TNNLS.2021.3071245
[46] Kumar, P., Goel, N. (2020). Image resolution enhancement using convolutional autoencoders. In Presented at the 7th Electronic Conference on Sensors and Applications, Chandipur, Balasore, India. https://doi.org/10.1109/ICORT52730.2021.9582015
[47] Yan, L., Fu, J., Wang, C., Ye, Z., Chen, H., Ling, H. (2021). Enhanced network optimized generative adversarial network for image enhancement. Multimedia Tools and Applications, 80: 14363-14381. https://doi.org/10.1007/s11042-020-10310-z