Shaoxia Mou* | Shan Zhang | Jiawei Chen | Haiyan Zhai | Yuandi Zhang
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The diagnosis of students’ pre-class hands-on operation capacity helps to group the students scientifically to facilitate the teaching for experimental training of skill training courses, and benefits the capacity complementation and team spirit cultivation. Practically speaking, the relevant results have rarely been implemented in the practical teaching of skill training courses. No literature has analyzed the correlation between grouped teaching for experimental training, and the key competences of students for skill training courses. To solve the problem, this paper constructs a grouped teaching strategy for experimental training based on deep learning. The key competences of students for skill training courses were evaluated from four aspects, namely, general training objective, thinking training, practical training, and scientific literacy training. The evaluation results were used to diagnose the students’ pre-class hands-on operation capacity, and reasonably group the students participating in experimental training. The deep learning model was called to group students of different majors for experimental training courses. The attention mechanism was added to prevent over fitting, when there are a few samples for capacity diagnosis. The proposed model was proved effective through experiments.
deep learning, student grouping, experimental training
Experimental teaching underpins skill training courses. The teaching for experimental training of skill training courses is an essential link of improving students’ skills, abilities, and key competencies [1-6]. It directly relies on group teaching of the students. Grouped teaching for experimental training facilitates students to understand the concepts and teaching rules of skill training courses [7-14]. The diagnosis of students’ pre-class hands-on operation capacity helps to group the students scientifically to facilitate the teaching for experimental training of skill training courses, and benefits the capacity complementation and team spirit cultivation [15-22]. The main difficulty of the diagnosis is how to accurately judge the key competencies of different types of students in the experimental training of skill training courses, and to divide these students into reasonable groups [23, 24].
The traditional experimental teaching of management emphasizes teaching over learning, and stresses knowledge over practice. It no longer meets the development needs of innovative society in the context of new media. In the new media environment, the experimental courses of management are badly in need of collaborative innovation of the teaching system. Drawing on the new media environment, Xia et al. [25] carried out collaborative innovative design of the teaching system for the experimental courses of management, from the aspects of overall design, teaching method, and teaching evaluation. Through practice and application, the experience and shortcomings were summarized, and the improvement measures were presented. Wen et al. [26] put forward a lightweight collaborative experimental teaching method, including computer simulation, teaching guidance, and class reflection. Thirty-three grade 8 students were recruited to explore how the teaching method affects the exploratory scores and scientific knowledge of students. However, further research is needed to verify whether a series of lightweight experiments can improve student performance. Girouard and Kang [27] created an innovative usability training called collaborative learning of usability experiences program for students majoring in human-computer interaction (HCI) of different grades, and detailed the components of the unique experiential training, namely, internship, short-term courses, symposium, and knowledge transfer. In addition, the employment and academic performance of graduates were evaluated, and the five key skills of interns were checked. Kerpen et al. [28] proposed a problem-based lab-centered college course. The course teaching has a high demand for virtual collaboration. The students used various tools to draw a preliminary design plan, which could be realized in future physical prototypes.
The existing literature shows that grouped learning and pre-class hands-on operation capacity are necessary and important to the teaching for experimental training of skill training courses. Practically speaking, the relevant results have rarely been implemented in the practical teaching of skill training courses. No literature has analyzed the correlation between grouped teaching for experimental training, and the key competences of students for skill training courses. To make up for the gap, this paper constructs a grouped teaching strategy for experimental training based on deep learning. The main contents are as follows: Section 2 evaluates the key competences of students for skill training courses from four aspects, namely, general training objective, thinking training, practical training, and scientific literacy training. The evaluation results can be used to diagnose the students’ pre-class hands-on operation capacity, and reasonably group the students participating in experimental training. Section 3 calls the deep learning model to group students of different majors for experimental training courses, combined meta learning with transfer learning, and introduced the attention mechanism to prevent over fitting, when there are a few samples for capacity diagnosis. The proposed model was proved effective through experiments.
The key competences of students for skill training courses can be evaluated from four aspects: general training objective, thinking training, practical training, and scientific literacy training. The evaluation results can be used to diagnose the students’ pre-class hands-on operation capacity, and reasonably group the students participating in experimental training.
If a student possesses the key competencies of skill training courses, he/she should be able to construct the knowledge system of skill training courses, design the experimental training plan based on the learned basic knowledge or experimental principles, participate in grouped experimental training, and finally acquire valuable experimental conclusions or experience of skill training. The mastery of course knowledge and experimental conclusions measures the degree of realization of the general training objective of the courses. Therefore, the general training objective of skill training courses was further divided into basic knowledge or experimental principles, and valuable experimental conclusions or experience of skill training.
To evaluate the key competences of students for skill training courses, it is necessary to examine the student capacity for problem analysis, reasoning, innovative thinking, and problem solving in the skill training course scenes closely associated with practical application. Grouped discussion can effectively optimize or renovate the ideas. Therefore, the thinking training of skill training courses was further split into problem analysis, reasoning, innovative thinking, and problem solving.
The key competences of students for skill training courses highlight that the students must be able to combine, control, and operate experimental training equipment, and to generate experimental data. The entire flow cannot be completed by one student. Normally, the experiments are carried out collaboratively by several groups of students. Each group is assigned a specific task. Therefore, the practical training of skill training courses was further divided into combination training (grouped), control training (grouped), operation training (grouped), experimental phenomenon observation, data collation, as well as communication and discussion.
The key competences of students for skill training courses also require students to have a good research spirit and learning attitude. Therefore, the scientific literacy training of skill training courses is further divided into the curiosity about training topics, scientific reasoning, and sustained scientific spirit.
Based on deep learning model, this paper groups students in different majors for experimental training courses. The students in different majors need to complete different skill training courses, and acquire different key competencies. As a result, there are a few samples for the diagnosis of students’ pre-class hands-on operation capacity.
The small sample set can be improved by data enhancement, transfer learning, or meta learning. This paper combines meta learning with transfer learning, and introduces the attention mechanism to prevent over fitting, when there are a few samples for capacity diagnosis.
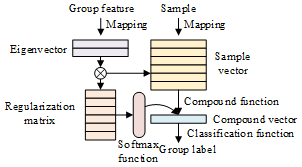
As shown in Figure 1, the overall framework of our model consists of a dense residual module, an attention module in global channel and local space, and an attention module between spatial channels. Firstly, the proposed model is trained by the set of original capacity diagnosis samples. The weights of the trained model are finetuned to adapt to the grouping of students for experimental training courses, in the presence of a small sample set.
Figure 1. Learning structure of our model
To overcome vanishing or exploding gradients, this paper introduces a skip connection to the ResNet in the dense residual module of our model. Then, the nonlinear operation can be skipped, once the optimal solution is obtained. Let Fk(ak-1) be the residual obtained through nonlinear operation; ak-1 be the optimal solution before executing the nonlinear operation. Then, we have:
${{a}_{k}}={{F}_{k}}\left( {{a}_{k-1}} \right)+{{a}_{k-1}}$ (1)
The DenseNet in the dense residual module adopts a new connection mode to promote the gradient transmission between layers, i.e., the output of each layer is directly transmitted to all subsequent layers. That is, the input of the k-th layer contains the feature maps from the 0-th layer to the k-1-th layer. Let [a0,a1,...,ak-1] be the splicing of the eigenvectors from the 0-th layer to the k-1-th layer. Then, we have:
${{a}_{k}}={{g}_{k}}\left( \left[ {{a}_{0}},{{a}_{1}},\cdots ,{{a}_{k-1}} \right] \right)$ (2)
To enhance the feature transfer of capacity diagnosis samples in network training, this paper embeds the dense connection mode of DenseNet to ResNet. Let ak-10, and ak-11 be the medians of each dense residual block. Taking the residual block structure of ResNet as the basis, the dense residual blocks can be calculated with skip connection as network mapping:
$\begin{align} & {{a}_{k}}=G\left( {{a}_{k-1}} \right)+{{a}_{k-1}} \\ & G\left( {{a}_{k-1}} \right)=G\left( \left[ {{a}_{k-1}},{{a}_{k-10}},{{a}_{k-11}} \right] \right) \\\end{align}$ (3)
The purpose of the attention module in global channel and local space, and the attention module between spatial channels is to improve the quality of feature representation, i.e., highlight the features of important capacity diagnosis samples, and weaken the features of unimportant samples. Figure 2 illustrates the structure of an attention module.
Let $A \in R^{F^{*} Q^{*} Z}$ be the eigenvector outputted by the convolutional layer after the input capacity diagnosis sample passes through that layer; [a1,a2,...,aZ] be channels a1-aZ; $A_{i} \in R^{F^{*} Q^{*} 1}$ be the feature information in the i-th channel; U=[a1,a2,...,aZ] be the filter group for learning; ui be the i-th filter; Fk be the function of the deep convolutional layer; ui be the two-dimensional (2D) spatial convolutional filter. The spatial statistics in a channel can be generated by Fk, and used to generate the output eigenvector Bk:Bk=[bk,1,bk,2,...,bk,z]:
${{b}_{k,i}}={{F}_{k}}\left( {{a}_{i}},{{u}_{i}} \right)={{a}_{i}}*{{u}_{i}}$ (4)
Let Fh be the modeling of the correlation between global channel features; ξ be the rectified linear unit (ReLU). Suppose parameters T1 and T2 satisfy $T_{1} \in R^{1^{*} 1^{*} Z^{*} Z / 4}$, and $T_{2} \in R^{1^{*} 1^{*} Z / 4^{*} Z}$, respectively. Then, the output eigenvector $B_{h} \in R^{F^{*} Q^{*} Z}$ can be obtained by:
${{B}_{h}}={{F}_{h}}\left( A,Q \right)={{T}_{1}}*\xi \left( {{T}_{2}}*A \right)$ (5)
The compression mechanism and the relationship between global channel indices can be obtained through the dimensionality reduction of channels with T1. Let Fhk be element-by-element multiplication. By sigmoid function, Bk and Bh derive the activation value for re-calibration or activating the feature information:
${{B}_{hk}}={{F}_{hk}}\left( A,\varepsilon \left( {{B}_{k}} \right),\varepsilon \left( {{B}_{h}} \right) \right)=A\bullet \varepsilon \left( {{B}_{k}} \right)\bullet \varepsilon \left( {{B}_{h}} \right)$ (6)
Let $b \in R^{Z}$ be the feature of each capacity diagnosis sample passing through the global average pooling. The channel attention mechanism can be given by:
$\theta =\varepsilon \left( Q*b \right)$ (7)
Let Q be the Z*Z parameter matrix; Ql be the band matrix. The band matrix provides the basis for the learning of channel information attention. The matrix can be expressed as:
$\left[ \begin{matrix} {{q}^{1,1}} & \cdots & {{q}^{1,l}} & 0 & 0 & \cdots & \cdots & 0 \\ 0 & {{q}^{1,2}} & \cdots & {{q}^{2,l+1}} & 0 & \cdots & \cdots & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \vdots \\ 0 & \cdots & 0 & 0 & \cdots & {{q}^{Z,Z-l+1}} & \cdots & {{q}^{Z,Z}} \\\end{matrix} \right]$ (8)
Formula (25) shows that Ql contains l*Z parameters. It is only necessary to consider the interaction between bi and its l adjacent channels. Let Ψli be the set of bi and its l adjacent channels. Then, the weight of bi can be calculated by:
${{\theta }_{i}}=\varepsilon \left( \sum\limits_{j=1}^{l}{q_{i}^{j}b_{i}^{j}} \right),b_{i}^{j}\in \Psi _{i}^{l}$ (9)
To improve the effectiveness of model learning, the learning parameters of all channels should be unified. Thus, formula (26) can be updated as:
${{\theta }_{i}}=\varepsilon \left( \sum\limits_{j=1}^{l}{{{q}_{i}}b_{i}^{j}} \right),b_{i}^{j}\in \Psi _{i}^{l}$ (10)
To keep the learning parameters of all channels consistent, a fast one-dimensional (1D) convolution CONFO-l can be implemented with a kernel size of l:
$\theta =\varepsilon \left( CO{{N}_{FO-l}}\left( b \right) \right)$ (11)
The above formula is the way to compute the attention between channels, and to effectively capture the local information exchange between channels. The computation is of a low complexity, involving only l parameters.
To realize the attention mechanism between channels, it is necessary to determine the kernel size l, and obtain a relatively suitable coverage of adjacent channels. The possible mappings Φ between l and Z can be nonlinearized:
$Z=\Phi \left( l \right)={{2}^{\alpha *l-y}}$ (12)
Let |x|odd be the odd number the closest to x. If the channel dimension Z is given, then l can be adaptively calculated by:
$l=\Omega \left( Z \right)={{\left| \frac{lo{{g}_{2}}\left( Z \right)}{\alpha }+\frac{y}{\alpha } \right|}_{odd}}$ (13)
To prevent our model from over fitting, meta learning was integrated with transfer learning, which contains lightweight operations like scaling and translation, to initialize neural network parameters on deep layers. The integration enables meta learning to converge quickly facing a few capacity diagnosis samples, thereby reducing the computing load. Figure 3 shows the flow of the proposed meta-transfer learning model.
During model learning, the first step is to train the capacity diagnosis sample set on multiple task levels. Let TT be the training task; δ1, δ2 and δ{1,2} be the scaling operation, translation operation, and the combination between the two operations, respectively. Facing a small set of diagnosis samples, the student grouping classifier can be optimized by:
$\omega '=\omega -\gamma {{\nabla }_{\omega }}{{K}_{TT}}\left( \left[ \Pi ,\omega \right],{{\delta }_{\left\{ 1,2 \right\}}} \right)$ (14)
δ1 and δ2 can be iteratively updated by:
${{\delta }_{i}}={{\delta }_{i}}-\alpha {{\nabla }_{{{\delta }_{i}}}}{{K}_{TT}}\left( \left[ \Pi ,\omega \right],{{\delta }_{\left\{ 1,2 \right\}}} \right)\left( i=1,2 \right)$ (15)
Let Π be the trained feature extractor of capacity diagnosis samples. Suppose the network layer of Π contains n pairs of weights and thresholds {(Qi,n,yi,n)}. Let $\oplus$ be the point multiplication operation. Then, the combined operation of scaling and translation can be expressed as:
$RR\left( A,Q,y;{{\delta }_{\left\{ 1,2 \right\}}} \right)=\left( Q\oplus {{\delta }_{1}} \right)A+\left( y+{{\delta }_{2}} \right)$ (16)
Figure 2. Structure of an attention module
Figure 3. Flow of meta-transfer learning model
This paper evaluates the key competences of students for skill training courses from four main aspects: general training objective, thinking training, practical training, and scientific literacy training. The proposed method was verified experimentally on the evaluation dataset of students from different majors and colleges. The results can be applied to diagnose students’ pre-class hands-on operation capacity, and group the students participating in experimental training scientifically. The grouping rule is to allocate the students with different levels of pre- class hands-on operation capacity to the same group.
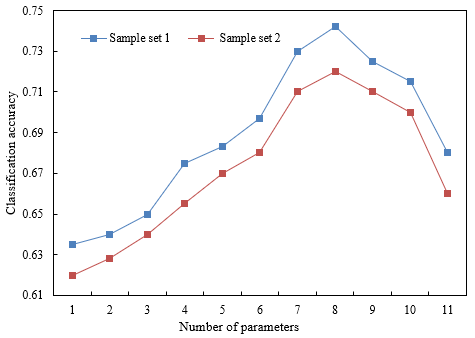
A comparative experiment of feature extraction effects was designed to verify the effectiveness of our model. Figure 4 reports the experimental results. The proposed model was tested at different number of parameters. In the absence of the attention mechanism, the transfer learning effect was significantly affected by the number of parameters. Our model converged faster and achieved better results than the traditional transfer learning model. As shown in Figure 4, when the sample set of students’ pre-class hands-on operation capacity was very small, the mean classification accuracy on sample set 2 was slightly lower (-5%) than that on sample set 1, for many group features and samples are missing in that sample set. Therefore, our model has a high robustness in the student grouping for experimental training.
To further verify its effectiveness, our model was compared with 9 models, including k-nearest neighbors (KNN), Bayesian, decision tree, random forest, support vector machine (SVM), logistic probability regression, discriminant analysis, neural network, and ensemble boosting. The KNN is only applicable to easily explainable models, sensitive to abnormal values, and susceptible of data imbalance. Bayesian works well on the data with weak correlations between dimensions, and gains popularity in the handling of spam emails. Decision tree can handle different types of data simultaneously, but is vulnerable to attacks. Random forest is not so vulnerable to attacks, and suitable for high accuracy recognition of low-dimensional data. The SVM can withstand attacks effectively. As a linear classifier, logistic probability regression does not apply to strongly correlated features. Discriminant analysis is usually adopted as a dimensionality reduction tool. The neural network is fit for large volumes of data. Ensemble boosting can automatically detect effective features, facilitating the understanding of high-dimensional data.
Table 1 compares the classification accuracies of different models. Obviously, discriminant analysis, neural network, ensemble boosting, and our model achieved relatively good classification results. The best results were realized by our model, because the attention mechanism is suitable for the diagnosis of a few capacity samples.
In addition, the losses of discriminant analysis, neural network, ensemble boosting, and our model after 300 iterations were counted. As shown in Figure 5, our model outperformed the other three models: the loss dropped by 0.6 at the most. The result further confirms that our model can highlight the features of important capacity samples, thanks to the introduction of the attention mechanism. During the training, our model saw a faster decline of the loss function, i.e., a faster convergence, than the other three models. Figure 6 visually displays the grouping effect of experimental training on the sample sets. The effectiveness of our grouped teaching strategy for experimental training was further validated.
Table 1. Classification accuracies of different models
|
|
KNN |
Bayesian |
Decision tree |
Random forest |
SVM |
|
Dataset 1 |
82.05±0.02 |
86.58±0.63 |
81.47±0.14 |
80.85±0.38 |
87.62±0.32 |
|
Dataset 2 |
85.14±0.75 |
88.51±0.49 |
86.39±0.41 |
83.68±1.35 |
81.48±0.74 |
|
|
Logistic probability regression |
Discriminant analysis |
Neural network |
Ensemble boosting |
Our model |
|
Dataset 1 |
86.83±0.53 |
91.48±0.42 |
96.52±0.19 |
91.71±0.62 |
93.68±0.47 |
|
Dataset 2 |
89.28±0.38 |
97.42±0.24 |
91.36±0.18 |
96.58±0.36 |
97.42±0.51 |
Figure 4. Feature extraction effects on different capacity evaluation samples
Figure 5. Losses of different models
Figure 6. Grouping effect of experimental training on the sample sets
This paper tries to build a grouped teaching strategy for experimental training based on deep learning. The key competences of students for skill training courses were evaluated from four aspects, namely, general training objective, thinking training, practical training, and scientific literacy training. The evaluation results can be used to diagnose the students’ pre-class hands-on operation capacity, and reasonably group the students participating in experimental training. Based on the deep learning model, the students of different majors were grouped for experimental training courses, and the attention mechanism was introduced to prevent over fitting in the face of a sample set. Then, the feature extraction effects on different capacity evaluation samples were compared experimentally. The results show that our model has a high robustness in the student grouping for experimental training. In addition, our model was compared with 9 models, including KNN, Bayesian, decision tree, random forest, SVM, logistic probability regression, discriminant analysis, neural network, and ensemble boosting. It was observed that discriminant analysis, neural network, ensemble boosting, and our model achieved relatively good classification results. The best results were realized by our model. In addition, the losses of discriminant analysis, neural network, ensemble boosting, and our model after 300 iterations were counted. During the training, our model saw a faster decline of the loss function, i.e., a faster convergence, than the other three models. Finally, the authors displayed the grouping effect of experimental training on the sample sets.
[1] Shen, X.G. (2020). Design and application of a virtual simulation teaching system based on cloud service. Ingénierie des Systèmes d’Information, 25(5): 699-707. https://doi.org/10.18280/isi.250518
[2] Li, S.L., Chai, H.Q. (2021). Recognition of teaching features and behaviors in online open courses based on image processing. Traitement du Signal, 38(1): 155-164. https://doi.org/10.18280/ts.380116
[3] Cao, Z.Q. (2020). Classification of digital teaching resources based on data mining. Ingénierie des Systèmes d’Information, 25(4): 521-526. https://doi.org/10.18280/isi.250416
[4] Si, T., Bagchi, J., Miranda, P.B. (2022). Artificial neural network training using metaheuristics for medical data classification: An experimental study. Expert Systems with Applications, 116423. https://doi.org/10.1016/j.eswa.2021.116423
[5] Grabowski, A. (2021). Practical skills training in enclosure fires: An experimental study with cadets and firefighters using CAVE and HMD-based virtual training simulators. Fire Safety Journal, 125: 103440. https://doi.org/10.1016/j.firesaf.2021.103440
[6] Ho, A., Citrin, J., Bourdelle, C., Camenen, Y., Casson, F.J., van de Plassche, K.L. (2021). Neural network surrogate of QuaLiKiz using JET experimental data to populate training space. Physics of Plasmas, 28(3): 032305. https://doi.org/10.1063/5.0038290
[7] Rajesh, L., Mohan, H.S. (2022). Adaptive group teaching based clustering and data aggregation with routing in wireless sensor network. Wireless Personal Communications, 122(2): 1839-1866. https://doi.org/10.1007/s11277-021-08971-6
[8] Zheng, Y., Chen, Y., Sarem, M. (2020). Group-teaching: Learning robust CNNs from extremely noisy labels. IEEE Access, 8: 34868-34879. 10.1109/ACCESS.2020.2974779
[9] Zhang, Y., Jin, Z. (2020). Group teaching optimization algorithm: A novel metaheuristic method for solving global optimization problems. Expert Systems with Applications, 148: 113246. https://doi.org/10.1016/j.eswa.2020.113246
[10] Wang, Y., Liao, Q., Chen, J., Huang, W., Zhuang, X., Tang, Y., Guo, X. (2020). Teaching an old anchoring group new tricks: Enabling low-cost, eco-friendly hole-transporting materials for efficient and stable perovskite solar cells. Journal of the American Chemical Society, 142(39): 16632-16643. https://doi.org/10.1021/jacs.0c06373
[11] Gao, Y., Du, Y., Sun, B., Liang, H. (2018). The Large-small group-based consensus decision method and its application to teaching management problems. IEEE Access, 7: 6804-6815. https://doi.org/10.1109/ACCESS.2018.2885706
[12] Balamurugan, A., Janakiraman, S., Priya, D.M. (2022). Modified African buffalo and group teaching optimization algorithm‐based clustering scheme for sustaining energy stability and network lifetime in wireless sensor networks. Transactions on Emerging Telecommunications Technologies, 33(1). https://doi.org/10.1002/ett.4402
[13] Sreethar, S., Nandhagopal, N., Karuppusamy, S.A., Dharmalingam, M. (2022). A group teaching optimization algorithm for priority-based resource allocation in wireless networks. Wireless Personal Communications, 123(3): 2449-2472. https://doi.org/10.1007/s11277-021-09249-7
[14] Zhu, S., Wu, Q., Jiang, Y., Xing, W. (2021). A novel multi-objective group teaching optimization algorithm and its application to engineering design. Computers & Industrial Engineering, 155: 107198. https://doi.org/10.1016/j.cie.2021.107198
[15] Zhou, N., Zhang, Z.F., Li, J. (2020). Analysis on course scores of learners of online teaching platforms based on data mining. Ingénierie des Systèmes d’Information, 25(5): 609-617. https://doi.org/10.18280/isi.250508
[16] Abidin, Z. (2019). Leveraging technology for teaching practices: What teachers learnt from the Facebook group. In Journal of Physics: Conference Series, 1321(3): 032026.
[17] Burch, M., Melby, E. (2019). Teaching and evaluating collaborative group work in large visualization courses. In Proceedings of the 12th International Symposium on Visual Information Communication and Interaction, pp. 1-8. https://doi.org/10.1145/3356422.3356447
[18] Gordenko, M., Beresneva, E. (2019). A project-based learning approach to teaching software engineering through group dynamics and professional communication. Proceedings of the 6th International Conference Actual Problems of System and Software Engineering, pp. 278-288.
[19] Kommadath, R., Kotecha, P. (2019). Optimization of stirling engine systems using single phase multi-group teaching learning based optimization and genetic algorithm. In Smart Innovations in Communication and Computational Sciences, Springer, Singapore, 669: 447-458. https://doi.org/10.1007/978-981-10-8968-8_38
[20] Wong, K.T., Goh, P.S.C. (2019). A cross examination of the intention to integrate MOOCs in teaching and learning: An application of multi-group invariance analysis. International Journal of Emerging Technologies in Learning, 14(19): 106-116.
[21] Zhang, M., Yang, S.X., Zhu, J.H. (2018). Teaching-learning-based optimization algorithm with group collaboration for job shop scheduling problem. Kongzhi yu Juece/Control and Decision, 33(8): 1354-1362. https://doi.org/10.13195/j.kzyjc.2017.0482
[22] Bodner, G.M., Ferguson, R., Çalimsiz, S. (2017). Doing the research that informs practice: A retrospective view of one group's attempt to study the teaching and learning of organic chemistry. Chemistry–An Asian Journal, 12(13): 1413-1420. https://doi.org/10.1002/asia.201700441
[23] He, J., Hoyano, A. (2011). Experimental study of practical applications of a passive evaporative cooling wall with high water soaking-up ability. Building and Environment, 46(1): 98-108. https://doi.org/10.1016/j.buildenv.2010.07.004
[24] Wu, T.Q., Xu, N.C., Huang, L.Q. (2013). Research experimental teaching system based on innovative practice ability. In Advanced Materials Research, 671: 3248-3252. https://doi.org/10.4028/www.scientific.net/AMR.671-674.3248
[25] Xia, Z.M., An, Y.L., Yu, X. (2020). Practice and application of collaborative innovation design of management experiment teaching system under new media environment. In 2020 International Conference on Modern Education and Information Management (ICMEIM), pp. 94-97. https://doi.org/10.1109/ICMEIM51375.2020.00028
[26] Wen, C.T., Chang, C.J., Huang, S.C., Chang, M.H., Chiang, S.H.F., Liu, C.C., Yang, C.W. (2019). An analysis of student inquiry performances in computer supported light-weighted collaborative experiment. In International Cognitive Cities Conference, pp. 316-322. https://doi.org/10.1007/978-981-15-6113-9_36
[27] Girouard, A., Kang, J. (2021). Reducing the UX skill gap through experiential learning: description and initial assessment of collaborative learning of usability experiences program. In IFIP Conference on Human-Computer Interaction, pp. 481-500. https://doi.org/10.1007/978-3-030-85616-8_28
[28] Kerpen, D., Juresa, Y., Forte, S., Conrad, J., Göbel, J.C., Wallach, D.P. (2021). Combining collaborative user experience design with crowd engineering: A problem-based lab course for (Under-) graduate students. In DS 110: Proceedings of the 23rd International Conference on Engineering and Product Design Education (E&PDE 2021), VIA Design, VIA University in Herning, Denmark. https://doi.org/10.35199/EPDE.2021.51