Mohamed Chakraoui* | Naoual Mouhni | Abderrafiaa Elkalay | Mohamed Nemiche
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
If pandemics kill humans and spread too quickly, misinformation is another scourge that puts people in danger. Health is what a person needs the most in the world to strive for great wealth and a bright future. The novel Coronavirus Disease (COVID-19) outbreak has threatened massively human health in the 21 century (precisely in 2020). The spreading of COVID-19 pandemic press specialists to do more efforts to find a cure. The same reason makes people perform billions of queries on search engines and social networks about comprehending the origin of the virus, the spread mechanisms and existent cures. The virus that causes the pandemic is the new Coronavirus appeared in a unique market in Wuhan, in China in December 2019. This new Coronavirus is named coronavirus (COVID-19). Throughout the ages, mankind has experienced many epidemics, but the distinction of the 21 century is technology development. The spread of misinformation is faster than that of the pandemic. With the advent of big data, we can analyze the huge information shared in a second in social networks and it contains millions of misinformation. In this current, we analyze the belief frequency of misinformation in three languages, English, French and Arabic shared on Twitter users’ timelines. Misinformation urges people against vaccination in different ways; many people are spreading misinformation to be famous or make money through views and sharing. Scientists and Journalists are concerned to reduce the likelihood of susceptibility to misinformation by complying with WHO guidance measures in social networks.
COVID-19, sentiment analysis, misinformation, social networks, rumors about COVID-19
There is quite a bit of research that has discussed the problem of fake news. These are mainly limited to the context of the 2016 US presidential election, concluding that exposure to fake news was quite limited among the population. Likewise, large-scale analyses of Facebook data in the context of anti-covid vaccine reluctance also find that anti-vaccination groups are growing. In the context of COVID-19, recent research demonstrated on YouTube videos found that more than 27% of the most viewed English videos contained fake news and exceeded 60 million views [1, 2]. This is why we predict more flow of misinformation concerning the progress of the vaccination [3, 4].
A study made by Ofcom precises that half of UK online adults came across false or misleading information about the coronavirus (Covid-19). 35% of UK online adults have seen false information that claims that drinking more water can flush out the infection, and 24% of them have seen misinformation that states coronavirus can be treated by gargling with salt water or avoiding cold food and drink. Our survey in Morocco about covid-19 misinformation spread make on evidence that:
Billions of information about health care are shared on the Internet via social media. This information contains 70% of rumors, conspiracies and misleading information versus 30% of WHO and public health guidelines regarding COVID-19 information [5, 6].
Social structures and social relations can be modeled into social networks composed of multiple connections between individuals (which can perform a group of persons) are used as a pattern issue. Social relations can be made by particular individuals or by groups, Facebook as an example. Institutional individual forms social organizations with consideration to macro-level pattern [7].
Facebook, Instagram and Twitter are the most frequently used social networks around the world. In China, they use WeChat, Sina, Weibo and other platforms as well. In this paper, we use Twitter due to its wide use and openness to researchers to get public data through Twitter API. 63% of Twitter users are between 35 and 65 years old, 71% of Twitter users are surfing in the platform to look for news according to the Pew Research Center. 80% of Twitter clients log in via mobile devices or smartphones. According to OMNICORE official website, 93% of users watch Twitter videos using mobile devices. Any data scientist who gets data from Twitter, asks this question: how many active users are on Twitter?
The response is that Twitter active users are more than 330.000.000 per month. Of this figure, more than 40% (more than 166.000.000), are using the platform at least one time a day (Twitter, 2020). After the peak of Twitter active users in January 2018, Twitter team accounts that monthly active user have raised in the first quarter of 2020. These statistics give us great reliability regarding this platform.
The WHO has announced that to slow the spread of the pandemic, people must respect the social distancing measures (one-meter minimum) by stopping transmissions of COVID-19 around the world. Then preventing new novel coronaviruses from appearing. WHO has announced later that mask-wearing is another important measure which can stop the spread of COVID-19 [8]. Avoiding contact with contaminated persons and surfaces to stop the spreading of COVID-19 [9]. Teachers can perform video conferences with students via Ms Teams or ZOOM meetings for example. Consumers can buy their needs through many existent and trusted online sales websites. Teleworking (work from home) is a good measure to avoid crowding and reduce pollution emitted by vehicles.
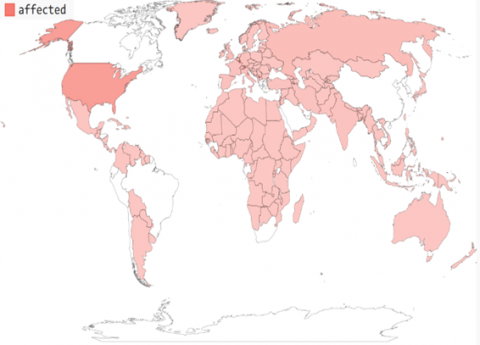
Figure 1. Affected countries and territories around the world by COVID-19
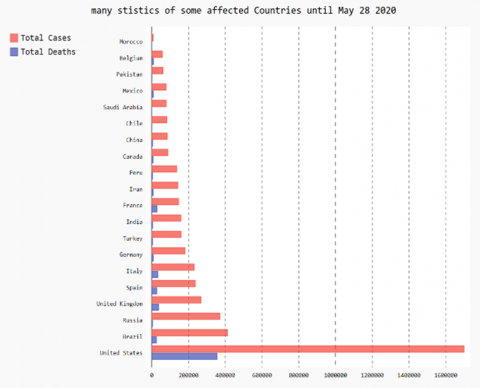
Figure 2. COVID-19 total death and total cases for some countries
Technologies, especially machine learning is involved deeply to stop the spread of the disease by encouraging researchers to engage in projects related to COVID-19 to end this pandemic. Enterprises, universities, schools changed the method of working by adopting Tele-working and tele-schooling (study-from-home). However, the enterprises, which provide daily needs and medical supplies-, should respect some working protocols such as social distancing and mask-wearing. Connections between familial, personal and professional communities must be established by technology and virtual communications [10]. New Technologies, radio, televisions and mobile phones have to raise awareness by streaming videos and documents about the danger of COVID-19. Figure 1 presents a world map of all affected countries by COVID-19 and Figure 2 presents a histogram of the total cases and death rate of some affected countries until May 28 2020, according to the European Centre for Disease Prevention and Control (ECDC). This pandemic keeps spreading across the world firstly and ruins people’s lives. Therefore, conducting such a study makes it possible to highlight the danger of this disease, the means of its propagation, the methods of prevention from it. It could also highlight the means of propagation of misinformation, conspiracies and rumors about this pandemic that people share in social networks leading to a lot of human damage. So, preventing the dissemination of misinformation, misleading information and conspiracies about COVID-19 in social networks could save our lives.
This study shades light on misinformation, misleading information and conspiracies about COVID-19 published through Twitter in three languages (English, French and Arabic) to schematize and compare them. The results obtained from the study are in favour of the public health services and the World Health Organization (WHO) which remain the main and official actors for decision-making in all matters relating to COVID-19.
2.1 The damage that rumors and misinformation has caused to the economy
As COVID-19 affects the health on an international scale, its affection is parallel to the spread of misinformation around the world, especially on the economic side [11]. A systematic approach to identify assess and reduce the risks of this disaster, is called disaster risk reduction (DRR). After weeks the fall of the economy caused by rumors about the disease is more than $20 trillion which is greater in number and size than the loss of 2008-2009 Great Recession [12]. For example, a study carried out by the Israeli cybersecurity company CHEQ and the University of Baltimore has revealed that the total cost of fake news just 2019 accounted for 78 billion dollars. This impact is distributed as follows: 39 billion dollars in stock market losses directly caused by the effects of false information, 17 billion dollars associated with financial misinformation, 9 billion dollars related to the health sector, 9 billion dollars to compensate for the damage to the reputation (of a person, a party, a company), 3 billion dollars invested by platforms and websites to control false information and 235 million dollars in advertising losses for brands following misinformation. To these direct costs, the researchers add the indirect economic costs -confusion, loss of confidence in large institutions, slowdown in innovation, damage to the reputation of people, institutions and brands. The total reaches 100 billion dollars over the same year. In the same respect, the World Economic Forum has also pointed out that the dissemination of fake news is among the main global economic risks [13]. We can also take Morocco's economy as a victim of fake news that has been already affected by the global economic collapse. Consequently, the EN, which is a principal trading partner, has been affected as well. Moreover, the lockdown measures to control the spread of the pandemic have been demonstrated negative effects on the Moroccan economy. According to the Hight Commissariat of Planning (HCP), economic growth did not exceed 0.1% in the first quarter of the year. In the second quarter of 2020, the Moroccan economy, under strict lockdown of the population for nearly 10 weeks out of 13, was faced with a drop in domestic demand. Household consumption would have responded by 6.7%. Under these conditions, the decline in Gross Domestic Product (GDP) would have reached -13.8% compared to the same period of 2019. The tertiary sector would have shrunk by 11.5%. Briefly, this situation would have penalized the activities of very small and medium-sized enterprises [14].
The lack of knowledge, non-based-science, poor coordination and uncertainty soon form the main wheel towards crisis and wrong decision-making. Reducing the economic activity and slump of capital markets caused by the immediate stop of activity have a direct negative impact on the economy. COVID-19 becomes a very costly lesson of RDD to save initial investments taking into consideration the medical infrastructure. To fight incoming diseases and mitigate future emergencies, supplies for at least some critical items must be in local production. Illiterate disaster economic policy tends to view redundancy as ineffective [15].
2.2 Mobilize social actors to get involved in avoiding risk depending on incoming disasters
The history of humanity has known a significant number of diseases outbreaks, among these the Spanish flu, which is known as the 1918 flu pandemic, pandemic H1N1/09 virus and COVID-19 pandemic. This later can be considered as the pandemic of the 21st century. A world health emergency is announced by WHO to contain COVID-19. Commitments, partnerships and collaborations have been established by several concerned parties to combat the risks of pandemics and disasters everywhere, especially in vulnerable countries. For example, an International Federation of Red Cross and Red Crescent Societies (IFRC) specializing in disaster risk management, limiting illness is one of its priorities, fighting discrimination and violence, human rights and migrant helps issued “GLOBAL: COVID-19 outbreak” appeal [16]. The IFRC, UNICEF and WHO have published good documents as new guidelines for protecting children and schools from COVID-19 propagation [15].
2.3 Medical statistics about COVID-19
Since WHO office in China announced pneumonia detected in Wuhan, on 31 December 2019 and no one knows its origin. WHO is working day and night and collaborating with their partners to get more helpful data, to help people by providing them advice and increasing medical supplies. The number of affected people grows exponentially, it is declared as a Public Health Emergency on 30 January 2020 [17]. 11 days later, WHO labelled it as COVID-19 and one day after, WHO reported it as a pandemic (March 12 2020).
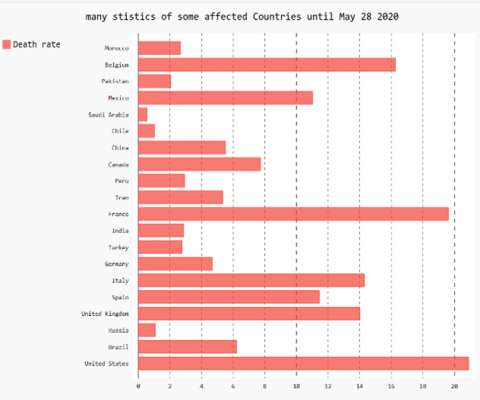
The overall death rate is less than 2.3% and can increase to 8.0% with senior patients between 70 and 79 years old and 14.8% for those with age more than 80 years, Figure 3 gives an overview of COVID-19 death rate by country.
Figure 3. Covid-19 death rate for some countries
Hydroxychloroquine shows higher safety than Chloroquine and admitted to increase of the dose of the day depending on the patient condition and less worry medication-medication interactions [18].
Zhou et al. [19] constructed a decision-making information system through significant subjects that take challenges. Analyses of geographic and spatiotemporal information systems make it possible to prevent and contain incoming diseases and epidemics by making decisions at the right time.
With the development of a calculation engine, which makes it possible to describe, diagnose, predict diseases, the GIS, which is developed, is able to make a decision about diseases through straightforward queries. Programing a real-time spatiotemporal visualization platform scaled on multi-dimensions to get a visualization on levels of state, region, town, section and community to allow management and analysis of curves of multidimensional epidemic data under normalized GIS data. New technologies with cloud architecture are taken over to set up a structure, which includes the management of the GIS. The masses of spatiotemporal data and interface of disease, will eliminate some problems like the too congested relationships, the complexity and poor optimization of code linked to traditional information systems, all this makes it possible to have a GIS adapted to emergency cases linked to epidemics [19].
2.4 Using natural language understanding to extract misinformation about COVID-19
There are many kinds of NLI, the most solicited NLI is Natural Language Interfaces to Databases (NLIDB), which allow structured information to be stored in a relational database [20]. The disadvantage of this type of NLI is that of SQL which is not easy to use by end-users. Then, we are looking for an interface that can be interpreted by RDBMS as well as by humans [21]. Otherwise, we can appeal to ontologies to treat information by using Natural Language Interfaces to Knowledge Bases (NLIKB) [20]. Natural language Interfaces can communicate with all RDBMS, and use a close algorithm for interpretations of NLI queries and mapping them to RDBMS queries. Requests in database systems are optimized using parallel index partitioning [22].
3.1 Natural language processing
Text data, Meta data are available in plenty on the Internet through social media networks. Natural language processing can be defined to be a branch of artificial intelligence that deals with interactions between machine and human using the natural language understanding as English, French, Arabic and other languages [23]. Natural language processing which is usually shortened as NLP brings powerful technologies to help researchers derive immense value from that data.
The most solicited issues in Big Data Analytics fields are that of efficiency, speed, reliability and optimization. Many papers have discussed these topics as well as to object-oriented databases and other databases architectures [24, 25].
At masses of data era, big data analysis, sentiment analysis, and cloud computing brought new methods of decision making by discarding the old methods, which are no longer valid.
“Opinion mining” widely known as sentiment analysis is a branch of data mining, which is interested in processing and interpreting text mining through natural language processing (NLP). NLP extracts the user's emotion or sentiment which is extracted by analyzing the subjective context of the text and can be positive, negative or neutral [26].
Data generated from social networks like Facebook conversations, publications or status, tweets, timelines and messages are part of unstructured data through the web. These datasets cannot be translated to traditional rows and columns (tables). Structured data (relational data) is widely used on the web because of its mathematical based theory and its straightforwardness. Unstructured data is difficult to process because it is generally inhomogeneous and disordered, it can be texts, messages or tweets. Nevertheless, due to NLP, other fields are born like text information retrieval, which allows us to understand the meaning behind those words in the phrase syntax (its cognitive sense). To do this we have used many algorithms as follow:
The first step consists of taking off stop words using a priori toolkit list. The next step consists of the processing of root word extraction for the other words. The meaningful words are extracted using the syntactic parsing phase that is consisting of a top-down parser [28].
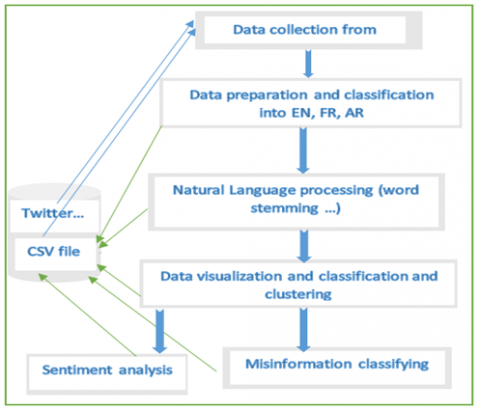
As illustrated in Figure 4, we collect data tweets from Twitter and perform our NLP algorithm to preprocess these data then prepare them, after that, we extract clean text out of URLs, special characters and no meaning words filtration. English, French and Arabic are three languages widely written and spoken on social networks and can be a powerful bank of data to get profit in this paper to catch and classify misinformation, misleading information and rumors spread about the virus. Through the last step, which is data visualization we extract statistics of sentiments of adult connected people about this information in concern of COVID-19 pandemic. These extractions are done for tweets of English, French and Arabic separately. In the second step, we did the same statistics by continent, then by some countries. This can allow us to learn more about the spread of COVID-19 as well as its rate of transmission and mastering the situation.
Figure 4. Misinformation classification architecture
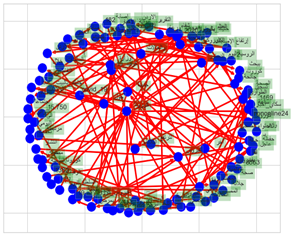
Figure 5. Networked Arabic words for positive sentiment
Many tools are used as python 3.7.6, Pandas 1.0.1, Numpy 1.18.1, Pip 20.0.2, Pygal 2.4.0, Sklearn.
Moreover, other packages running on an Intel® Core™ i7-4500 CPU @ 1.80GHz 2.40GHz Asus Laptop with 8GB of RAM, 64-bit operating system, x64-based processor.
Graphs are structures that map relations between objects (words in this current). The objects are referred to as nodes and the connections between them as edges. Edges and nodes are commonly referred to by several names that mean the same sentiment. The purpose of using graph manipulation and analysis (python NetworkX) is that concepts and terminology are generally intuitive. Figure 5 presents a Networkx of Arabic sentiments, it covers many connections between the negative most shared information about COVID-19 on Twitter. We made the same network in English then in French. We sub-graph our connected and undirected graph using a spanning tree algorithm to get many trees and connects all the vertices. Unless the graph of the Spanning Tree is connected, undirected and weighted, the Minimum Spanning Trees (MST) can be the Spanning Tree of the weight, which is the minimum on a number of other Spanning Trees. This weight is calculated by performing addition of edges weights.
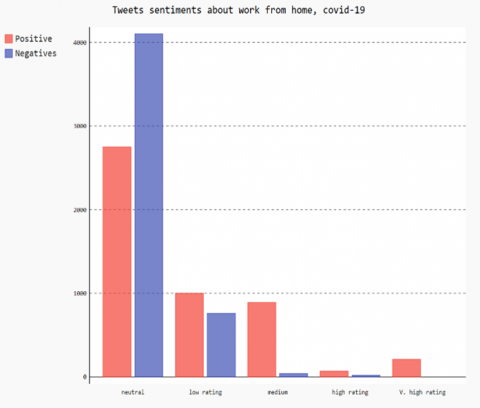
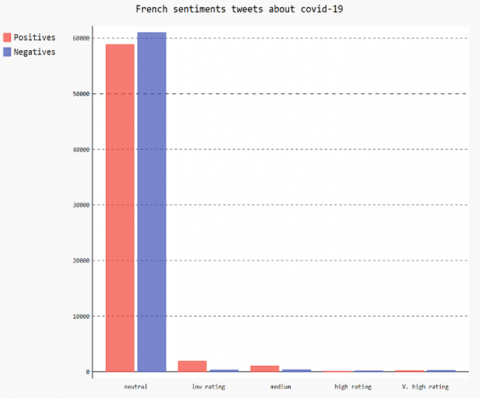
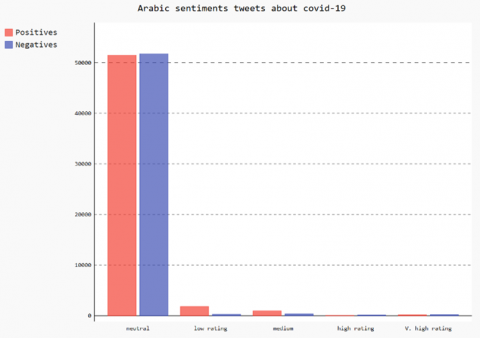
The reason for choosing Twitter as the social media for this study is that it can allow developers to access public shared information through APIs. Twitter REST API is used to collect tweets, then picked up by tweepy library after cleaning and filtering these tweets we etiquette them by neutral, positive or negative. Each kind of category was sub labeled with neutral, low rating, medium, high rating or very high rating. Phrases (tweets) are clustered into five categories following their polarities. Document Frequency and Inverse Document Frequency are evaluated. Figure 6 plots a Pygal histogram of misinformation sentiments about working from home English tweets as well as Figure 7 presents French misinformation sentiments about the covid-19 pandemic and Figure 8 shows Arabic misinformation sentiments about wearing masks. These sentiments are rated from 1 to 5 stars, one star is very low and 5 stars is very high. This rating is calculated by the polarity of the phrase. Each rating is assigned an interval of polarity. As expected, English tweets show a negative attitude towards misinformation reaching up to 65% of English tweets. French tweets show a negative attitude towards misinformation reaching up to 63% of tweets. Arabic tweets show a negative attitude towards misinformation reaching up to 74% of tweets. English tweets show a negative attitude towards misinformation reaching up to 53% of total tweets. The misunderstanding of ethical standards by connected people and the delay of cybercrime law have contributed to the huge volume of misinformation in the large flow of information about COVID-19.
Figure 6. Tweet sentiments about work from home English tweets
Figure 7. Tweet sentiments about covid-19, French tweets
If covid-19 pandemic spreads between people because of the non-respect of social distancing, non-mask wearing in public areas and lockdown, misinformation can be the worst virus people can suffer from. Millions of people around the world are been exposed to the dissemination of dangerous claims relative to covid-19 existence that affect negatively the reluctance to vaccination, which flatters the vaccination rate so the collective immunity cannot be compromised. The theory of conspiracy is that the virus is produced in a laboratory to destroy half of humanity or to make profits. There is a mass of information in social media that spread fear, hate phobia, and on the other hand, causes people not to respect the lockdown imposed by the authorities to limit the spread of COVID-19 [29]. We cannot see that our virtual spaces circulate traffic, lies, fear and hate without reacting. Misinformation spread online and messaging apps and headlines. Many surveys and papers have been published for this purpose but there are still a lot of efforts to be performed against these behaviors.
Figure 8. Arabic sentiments about wearing masks
WHO did an initiative with verified (double-checked) to fight lies of conspiracies and live saving and advice 8 speech with solidarity. They spare hope and solutions to recover better. Good communication saves lives [10].
We have used some metrics to calculate the similarity between phrases and classify each phrase as a vector of words then perform the Jaccard distance for every couple of phrases.
4.1 Jaccard distance
Jaccard distance can be extracted by calculating the similarity between sets of samples; it is reciprocal to the Jaccard coefficient and is picked up by minus the Jaccard coefficient from 1.
The Jaccard index also studied as intersection over union see Eq. (1).
$J(V 1, V 2)=\frac{|V 1 \cap V 2|}{V 1 \cup V 2}=\frac{|V 1 \cap V 2|}{|V 1|+|V 2|-|V 1 \cap V 2|}$ (1)
If V1 and V2 are both empty then J(V1, V2) is null. This measure is between 0 and 1. Then we can get the Jaccard distance through Jaccard index as shown in Eq. (2):
$J D=1-J(V 1, V 2)=\frac{|V 1 \cup V 2|-|V 1 \cap V 2|}{|V 1 \cup V 2|}$ (2)
The Jaccard distance gets a small value if tweets w1 and w2 are similar. Distance gets larger when they are not similar. JD = 0 if they are the same. Finally, JD = 1 means they are different at all.
Every cleaned tweet can be considered as an unordered set of words such as (set (w1), set (w2)).
Users may write incomprehensible tweets that can cause a false positive or false negative. Ambiguous information is among the disadvantages of natural language analysis [30]. This section validates some ambiguous tweets by evaluating them through labelling them to calculate some measures such as precision, recall and metrics.
The precision measures the percentage of the relevant content results. It can be calculated by Eq. (3):
Precision $=\frac{\text { relevant retrieved tweets }}{\text { retrieved tweets }}$ (3)
Recall is equal to the percentage of total relevant tweets correctly classified by our system. It can be calculated by Eq. (4):
Recall $=\frac{\text { relevant retrieved tweets }}{\text { relevant tweets }}$ (4)
We can also calculate accuracy, which tells us immediately whether our system is being trained correctly and how it may perform generally. It can be calculated by Eq. (5):
Accuracy $=\frac{\text { True Positive }+\text { True Negative }}{\text { Total }}$ (5)
We can end up with a model where either Precision is high and Recall is low or vice versa. It becomes a little difficult with their two metrics to evaluate our model and say which is better. It would be a lot easier if we had a single value to measure performance, and that metric is F1 score. F1 score is defined as the harmonic mean of Precision and Recall (because the general average does not penalize the extreme values). F1 Score is given by Eq. (6):
$F 1=2 * \frac{\text { Precision } * \text { Recall }}{\text { Precision }+\text { Recall }}$ (6)
Indeed, this concept is widely applied to information retrieval algorithms. In this current, we used unsupervised learning, then these measures were established just for hundreds of tweets to test the ability of the system to get good precision and it was the case as well as good accuracy measures.
4.2 Misinformation tweets similarity clustering
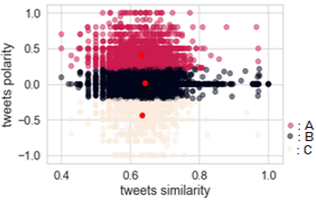
Figure 9. Dissemination of negative COVID-19 information via English social networks
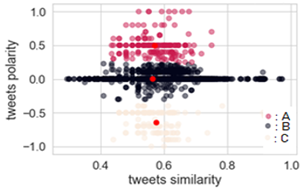
Figure 10. Dissemination of negative COVID-19 information via French social networks
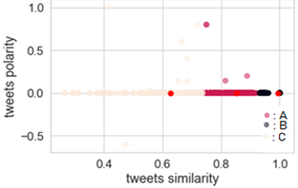
Figure 11. Dissemination of negative COVID-19 information via Arabic social networks
Clustering is a fundamental classification method which is frequently used to group together unlabeled (unsupervised learning) data with similar properties. It can be used in different fields such as pattern recognition (observations, data items feature vectors…), data mining, machine learning and statistics [31]. Figures 9, 10 and 11 cluster three different tweets: misinformation (A), conspiracy theory (B) and rumors(C) for English tweets (Figure 9), French tweets (Figure 10) and Arabic tweets (Figure 11).
The Internet is the most popular source of information, it produces a large amount of information in different languages. The misinformation called into question the COVID-19 and which led to the reluctance to vaccination and to push people not to comply with the advice of the WHO and the public health service. Do not follow unknown sources of information. Governments must develop algorithms to regularize the access and disposal of information relating to public health, especially when it comes to a disease like COVID-19.
We take into account the role that the scientists play as influencers. The services of public health have to collaborate with activists in social networks and sensitize them to disseminate accurate information as regards COVID-19. This can positively influence a wide range of followers and marginalize misinformation throughout the world and will play an important role in increasing public involvement in WHO measures and standing together against this pandemic.
[1] Gupta, L., Gasparyan, A.Y., Misra, D.P., Agarwal, V., Zimba, O., Yessirkepov, M. (2020). Information and misinformation on COVID-19: A cross-sectional survey study. Journal of Korean Medical Science, 35(27): e256. https://doi.org/10.3346/jkms.2020.35.e256
[2] Roozenbeek, J., Schneider, C.R., Dryhurst, S., et al. (2020). Susceptibility to misinformation about COVID-19 around the world. Royal Society Open Science, 7(10): 201199. https://doi.org/10.1098/rsos.201199
[3] Cuan-Baltazar, J.Y., Muñoz-Perez, M.J., Robledo-Vega, C., Pérez-Zepeda, M.F., Soto-Vega, E. (2020). Misinformation of COVID-19 on the internet: infodemiology study. JMIR Public Health and Surveillance, 6(2): e18444. https://doi.org/10.2196/18444
[4] Tasnim, S., Hossain, M.M., Mazumder, H. (2020). Impact of rumors and misinformation on COVID-19 in social media. Journal of Preventive Medicine and Public Health, 53(3): 171-174. https://doi.org/10.3961/jpmph.20.094
[5] Ahinkorah, B.O., Ameyaw, E.K., Hagan Jr, J. E., Seidu, A.A., Schack, T. (2020). Rising above misinformation or fake news in Africa: Another strategy to control COVID-19 spread. Frontiers in Communication, 5: 45. https://doi.org/10.3389/fcomm.2020.00045
[6] Scott, J., Stokman, F.N. (2015). Social networks. International Encyclopedia of the Social & Behavioral Sciences, 2: 473-477.
[7] Ricard, J., Medeiros, J. (2020). Using misinformation as a political weapon: COVID-19 and Bolsonaro in Brazil. Harvard Kennedy School Misinformation Review, 1(2). http://misinforeview@hks.harvard.edu/.
[8] Erku, D.A., Belachew, S.A., Abrha, S., Sinnollareddy, M., Thomas, J., Steadman, K.J., Tesfaye, W.H. (2021). When fear and misinformation go viral: Pharmacists' role in deterring medication misinformation during the'infodemic'surrounding COVID-19. Research in Social and Administrative Pharmacy, 17(1): 1954-1963. https://doi.org/10.1016/j.sapharm.2020.04.032
[9] WHO (2020). Coronavirus disease 2019 (COVID-19)Situation Report –72, World Health Organization.
[10] Hossain, M. (2021). The effect of the Covid-19 on sharing economy activities. Journal of Cleaner Production, 280: 124782. https://doi.org/10.1016/j.jclepro.2020.124782
[11] Gupta, M., Abdelmaksoud, A., Jafferany, M., Lotti, T., Sadoughifar, R., Goldust, M. (2020). COVID-19 and economy. Dermatologic Therapy, 33(4): e13329-e13329. https://doi.org/10.1111/dth.13329
[12] CHEQ and U. o. Baltimore. (2019). THE ECONOMIC COST OF BAD ACTORS ON THE INTERNET. https://cheq.ai/wp-content/uploads/2021/12/Economic-cost-of-affiliate-fraud-2020-Report-12.pdf.
[13] Haut-Commissariat au Plan, Système des Nations Unies au Maroc , and B. mondiale, "IMPACT SOCIAL & ECONOMIQUE DE LA CRISE DU COVID-19 AU MAROC," Les Cahiers du Plan, 2020. https://reliefweb.int/report/morocco/impact-social-conomique-de-la-crise-du-covid-19-au-maroc.
[14] Djalante, R., Shaw, R., DeWit, A. (2020). Building resilience against biological hazards and pandemics: COVID-19 and its implications for the Sendai Framework. Progress in Disaster Science, 6: 100080. https://doi.org/10.1016/j.pdisas.2020.100080
[15] IFRC (2020). Global: COVID-19 outbreak.
[16] Organization, W.H. (2020). COVID-19, WHO.
[17] Gautret, P., Lagier, J.C., Parola, P., et al. (2020). Early diagnosis and management of COVID-19 patients: A real-life cohort study of 3,737 patients, Marseille, France. International Journal of Antimicrobial Agents, 20 march 2020. https://doi.org/10.1016/j.ijantimicag.2020.105949
[18] Zhou, C., Su, F., Pei, T., et al. (2020). COVID-19: challenges to GIS with big data. Geography and Sustainability, 1(1): 77-87. https://doi.org/10.1016/j.geosus.2020.03.005
[19] Zhu, Y., Yan, E., Song, I.Y. (2017). A natural language interface to a graph-based bibliographic information retrieval system. Data & Knowledge Engineering, 111: 73-89. https://doi.org/10.1016/j.datak.2017.06.006
[20] Li, F., Jagadish, H. V. (2014). Constructing an interactive natural language interface for relational databases. Proceedings of the VLDB Endowment, 8(1): 73-84. https://doi.org/10.14778/2735461.2735468
[21] Chakraoui, M., Elkalay, A. (2016). Efficiency of indexing database systems and optimising its implementation in NAND flash memory. International Journal of Systems, Control and Communications, 7(3): 221-239.
[22] O'CONNOR, J. (2013). NLP WORKBOOK. Conari Press, pp. 6-8. http://www.josephoconnor.com.
[23] Chakraoui, M., El Kalay, A. (2016). Optimization of local parallel index (LPI) in parallel/distributed database systems. GEOMATE Journal, 11(27): 2755-2762.
[24] Chakraoui, M., El Kalay, A., Mouhni, N. (2016). TUNING different types of complex queries using the appropriate indexes in parallel/distributed database systems. GEOMATE Journal, 11(24): 2267-2274.
[25] Bhardwaj, A., Narayan, Y., Dutta, M. (2015). Sentiment analysis for Indian stock market prediction using Sensex and nifty. Procedia Computer Science, 70: 85-91. https://doi.org/10.1016/j.procs.2015.10.043
[26] Hardeniya, N., Perkins, J., Chopra, D., Joshi, N., Mathur, I. (2016). Natural Language Processing: Python and NLTK. Packt Publishing.
[27] Sujatha, B., Raju, S.V. (2016). Ontology based natural language interface for relational databases. Procedia Computer Science, 92: 487-492. https://doi.org/10.1016/j.procs.2016.07.372
[28] Brindha, D., Jayaseelan, R., Kadeswaran, S. (2020). Social media reigned by information or misinformation about COVID-19: A phenomenological study. Social Sciences & Humanities Open. https://doi.org/10.2139/ssrn.3596058
[29] Wachtel, A., Weigelt, S., Tichy, W.F. (2016). Initial implementation of natural language turn-based dialog system. Procedia Computer Science, 84: 49-56. https://doi.org/10.1016/j.procs.2016.04.065
[30] Jain, A.K., Murty, M.N., Flynn, P.J. (1999). Data clustering: a review. ACM Computing Surveys (CSUR), 31(3): 264-323. https://doi.org/10.1145/331499.331504
[31] Likas, A., Vlassis, N., Verbeek, J.J. (2003). The global k-means clustering algorithm. Pattern Recognition, 36(2): 451-461. https://doi.org/10.1016/S0031-3203(02)00060-2