Sindhe Phani Kumar* | R Anandan
© 2022 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
The security problem is critical and forestalls the rapid development of Cloud Computing. Cloud computing is gaining enormous enthusiasm and its information security has been gradually taken into account. Parallel security is the mechanism for data processing to directly take advantage of dynamic storage along with data security. Cloud computing shifts software and databases to vast centers where service and data management cannot be completely trusted. To isolate the regular computing challenges, cloud computing is a new design which usage is getting gradually increased. Cloud Storage is a virtual resource pool that also provides customers with assets through a web interface. Cloud Computing has more focal points, such as vast measurement of scope, storing of information, virtualization, high unwavering efficiency and low cost. In this framework, security of cloud data storage, which has become a significant feature of service quality is considered. The proposed model introduced a strong user validation model and User Priority based Accurate Resource Allocation (UPbARA) to the authorized users for performance enhancement. A comprehensive analysis is provided in this paper on user validation and resource allocation with secure data storage. The proposed model is compared with various traditional methods and the results show that the proposed model performance is better than the existing models.
cloud computing, resource allocation, privacy, confidentiality, security, integrity, user validation, performance enhancement
A single Internet-related data service is the most crucial dispersed storage method. A client, i.e. a PC connected to a disseminated storage entity, sends copies of its reports to the data server, which records the information over the Internet. It is not known to the end client how and where the data is recorded. The customer gets to the remote cloud server through a web-based interface to access the data stored on the cloud side. The server may then either give the records back to the client or receive the client's licenses and specifically store them on the server. In the world, ideas to get ready in the cloud are stretched out and business circumstances begin late.
Resource management is an overwhelming problem today because of the size and complexity of modern data centers, the heterogeneity of resources, the interdependency of these resources, the instability and unpredictability of load, and the variety of priorities of various actors in a cloud environment. Resource allocation and scheduling is the mapping, allocation, and execution of workloads depending on the resources selected during the planning process. Mapping user's job is to select the necessary resources to meet the Service Level Agreement (SLA) requirements as defined by users. Finding the list of available resources is referred to as resource identification, while the method of selecting the best resource from the list is known as resource selection.
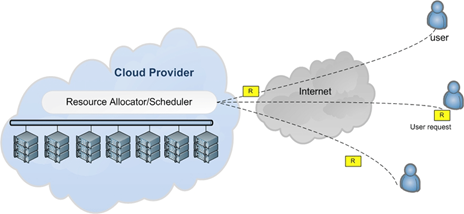
Management of resources includes the allocation of computer, storage, networking and energy resources and accounts for the needs of consumers and service providers. The cloud resource allocation paradigm is shown in Figure 1. Providers are committed to efficient use of resources to meet the service requirements as defined in service level agreements. Virtualization will assist clients to make productive use of resources in this scenario. Cloud customers prefer to focus on quality apps, cost-effective resource scaling and application efficiency.
The cloud resource allocation is designed to ensure efficient computational resources. At the same time, the cloud consumer manages virtual infrastructure applications. Cloud providers can automatically modify infrastructure rates, and customers can change application output and usage volume. Therefore, the cloud user is not responsible for the capacity of either the server or the user.
In cloud computing, an internet-based and the use of computer technology for development, several trends are opening. The cheaper and more powerful computer software processors (SaaS) transform data centres into large-scale pools of computer service. The rising network capacity and stable network connections allow internet users to subscribe to high-quality data and software services that are available at remote centres.
Moving data into the cloud storage offers great benefit to users since they don’t have to care about the difficulties of direct hardware management. From the perspective of data security, which has always been an important part of quality of service, cloud computing poses new challenging security threats for number of reasons. Such as traditional cryptographic system for the purpose of data security protection cannot be directly adopted due to the user’s loss control of data under cloud storage. Therefore, verification of correct data stored in the cloud must be conducted without knowledge of the whole data. Considering various kinds of data for each user stored in the cloud and the demand of continuous assurance of their data safety, the problem of verifying correctness of data storage in the cloud becomes even more challenging.
In cloud computing, any resource can be a service that cloud users / cloud consumers consume. Resource management is a basic feature of every cloud system and improper resource management directly affects performance and costs, whereas indirectly affecting system functioning, becoming excessively expensive or ineffective owing to bad performance. There are numerous obstacles in allocating resources. The following are some of the problems discovered. It is difficult to locate financial, physical and people resources. Companies generally experience problems in the procurement of finances. Cloud computing resources are easy for cloud customers to access if they are demanding. The cloud computing infrastructure is dynamic in nature and resources are appropriately allocated. Like any other model resource management, these resources are shared in cloud computing. The provision of all demanding resources is highly tough, as the number of shared resources available increases.
Cloud computing is not just a third party data warehouse. The data stored in the cloud may be updated by the validated users. However, this dynamic feature also makes traditional integrity insurance techniques. The deployment of cloud computing is powered by data centres running in a simultaneous, cooperated and distributed manner. Individual user’s data is redundantly stored in multiple locations to further reduce the data integrity threats. Therefore, distributed protocols for storage correctness assurance will be of most importance in achieving a robust and secure cloud data storage system in the real world. In this paper, a resource allocation model for validated users are introduces that improves the performance by allocating resources to authorized users without any delay. The proposed work focuses on protection and secure data transmission.
Figure 1. Cloud resource allocation
Resource Scheduling is accomplished by dispatching resources from the point of benefits so that resources allocated to one user are locked and residual resources offered by multiple physical machines are allotted to other users. Although simultaneous processing of virtual machines may result in more overhead, this type of computing resource management may be more efficient. The suggested approach is compared to the standard paradigm in terms of Encryption Time Levels, Decryption Time Levels, Number of VMs vs CPU Utilization, Key Generation and Verification Time Levels, User Registration Level, User Validation Rate, Accuracy Level, and Resource Allocation Delay.
The remaining section of the paper includes, section 2 briefly provides the literature survey, section 3 represents the proposed model, section 4 includes the comparison results of the proposed and traditional methods and section 5 concludes the manuscript.
Cloud computing provides infinite storage and execution services for company data and applications. They can easily enter, possessing only the requisite infrastructures that perform their tasks. Cloud Computing is used as a method to control technology. It talks about conventional methods of cloud computing along with its forms and impacts. Risk assessments were conducted in order to measure the efficiency of cloud services and compare cost savings. Cloud computing has put a dramatic shift in the relationship between the IT sectors and the global economy.
Rehman et al. [1] developed a modified RR strategy for resource allocation in cloud computing. Cloud computing is a computer model that allows for the distribution of resources on an as-needed basis. Cloud computing means that customers may access their data and applications from any location. Outsourcing cloud computing solutions allows a corporation to obtain access to computing resources. The system of a modified RR resource allocation is successful since it reduces the client waiting period [2].
Kumar et al. [3] developed a resource allocation model for cloud-scale software-as-a-service utilities. The Cloud infrastructure provides the necessary tools at reasonable prices, as well as access to simple business models. The VMs and instances were created to fit the needs of the application. A service model can aid in the scaling up or scaling down of application service capacity.
Mingprasert and Masuchun [4] created a hybrid form of double auction resource allocation technique for balanced cloud computing. In the investment strategy, suppliers and customers have different criteria and meaning. Clients pay as little as possible but relatively specific levels of administration in this method, and suppliers get to work on greater and more advantage for their endeavours. This is the industry standard asset management approach for both clients and service providers, especially in web-based administrations [5].
An analytical model was developed by Chang and Ramachandran [6] to decide tasks and jobs to assign and utilize resources in the cloud world. Capital distribution is not easy in computer systems provided that there are a number of discretionary clients. The goal of this model is to establish a model for promoting asset sharing in the cloud. Resource Allocation undertaking by the Gene Sparse network approach and the Analytic Hierarchy Method gives the open properties and client inclinations [7].
Kartit et al. [8] presented a Berg model for cloud computing resource scheduling. This proposition is based on the social construct of equal resource allocation. This had resulted in better efficiency of task execution by the consumer and general fairness in the marketplaces. Chang and Wills [9] incorporated ontology theory into the cloud computing process [10]. Shen et al. [11] proposed a multidimensional functional objective feature that enhanced the distribution of resource scheduling framework based on quantifying users' application expectations and findings from user effectiveness studies.
Wang et al. [12] proposed an air sharing scheduling method that uses the fewest resources in a team-defined time frame. Several scholars are also concentrating on resource scheduling optimization using fuzzy logic and expert system theory. To solve the expert scheduling problem in a resource-constrained ensemble system [13]. Kimpan and Kruekaew [14] presented an architecture called EES management. Experiment results reveal that with EES manager programmed, experts in resource-constrained ensemble systems provide system outputs that are comparable to those generated with ample resources [15-18]. Gupta and Ghrera [19] used fuzzy clustering to increase resource utilisation in a complicated hardware/software system. The method was tested in a real-time embedded device and found to be efficient in producing timings. The literature review was performed on 20 research articles, and the disadvantages that must be overcome were found [20].
Allocation of resources can be static or dynamic based on policies. In the static process, the cloud user requests fixed amount of resources beforehand. In static allocation there is underutilization of resources. The users request services in dynamic allocation are at on demand. In multi-server dependent Virtual Machine VM method, the resource-consumption parameters are accounted for in VM allocation. It doesn't really consider the workload forecasts or resource planning. In addition, the deadlines for assignments were not considered. When high priority job came, low priority job ran in its own assets based on the priority. Any of cloud computing's capabilities may assist in user scheduling requirements. Because of its continuous use, users' needs are able to forecast. By using proposed model, it is possible to estimate resource use.
The Cloud Services provide loads of information, stored in various servers. The creation of information to the servers for storing the records in the cloud, could improve protection and access. The trustworthiness of the information is checked by verifying the information authority and also authenticating users those require cloud resources. A novel Logical Pk-Anonymization approach for verifying information in the cloud is introduced and a key generation technique is utilized for storing the essential information in the cloud. Information indexes are stored on the cloud, which allows for further processing for larger quantities of data via Map Reduce, which stores all data as new data that joins over time, while anonymizing and protecting it from being lost or overwritten, since changes happen in the background, data loss and refreshing time is less for large amounts of data.
The emphasis on protection agreements is essentially on protecting an individual's information from unauthorized users, but there has emerged a problem with client information sharing. The data that is stored in the cloud needs to be checked before providing access to the users. A powerful Two Level Multi User Validation Method is used for validating users in the cloud and then ensuring the data is only accessible by retaining protection to the data. The proposed approach uses machine learning techniques to detect malicious activities in the cloud. A malicious user detection mode (MUDM) is implemented to continuously track the cloud users for preventing malicious activities in the cloud platform. The authorized users are only involved to request for resources and the resource allocation is based on the priority and task level for improving the system performance. The User Priority based Accurate Resource Allocation (UPbARA) model is used in the proposed work to allocate resources to the authorized users. The proposed model for resource allocation is illustrated in Figure 2.
Figure 2. Proposed model for resource allocation
Figure 3. Flow of the proposed model
The Figure 2 process in discussed in detail in Figure 3. The process of user request resources, the request handler and user information verification, resource allocation is explained clearly.
Resource allocation is an important problem in Cloud setting. Allocating various resources such as memory, server, and bandwidth to different applications in the Cloud is an incredibly complex process. The estimation of the resources needed by a user is verified and resources are arranged accordingly for a fixed level time interval. Based on the tasks to be performed and time required, the servers are divided into categories. Each resource allocation strategy and user verification method is monitored by the server groups.
Initially, users are authenticated by the cloud service provider and the users who want to access cloud resources will send resource requests (RREQ) to the service provider (SP). The SP considers a server group as request handlers for handling all kinds of requests from various cloud resources and assigns a priority to every user based on the time of resource usage request, time for task completion. The request handler holds all the information of the authenticated cloud users and distributes the valid requests to priority verification and resource monitoring module who in turn verifies the allocated priorities and then this server group will monitor the resource usage and resource idle timings.
The priority of a user is verified and the requested resources are allotted to the user to complete the task successfully. The resource allocation module verifies the resource usage time levels of every user and allots the free resources to low priority users to keep the system busy and to improve the system performance. The resources are deallocated and allotted to a new server group after a threshold time interval to avoid delays in the system.
Let C = (P, Q, R) be the cloud system S = {s1, s2, …, sn} be the set of servers interconnected by the communication network ( CN ) $\forall$ Sn (C) $\in$ CN This indicates that s1 and s2 communicate with each other.
Let Pi or Qi. Let Ri be the amount of resources required by VM $\alpha \in \delta$. Each server owns number of resources that are capable of running multiple VMs.
Based on the authorized user requests, VM allocation {$\delta\left(\mathrm{s}_{1}\right), \delta\left(\mathrm{s}_{2}\right), \ldots \ldots, \delta\left(\mathrm{s}_{\mathrm{n}}\right)$ is defined as mapping of server to set a set of VMs. The mapping of VMs is done as
$\forall C(i) \Theta\left(s_{i}\right)=\Theta+P_{n}$
$\Theta\left(s_{i}\right) \cap \Theta\left(s_{j}\right)=\phi, \forall 1 \leq i, j \leq N, i \neq j$
The user initially requests for a resource to complete the tasks assigned and for each server, the total resource requirements of its hosted VM does not exceed its available resources that is calculated as
$\sum_{\text {if } \in \Theta(s i)} s_{j} \leq w_{i}, \forall 1 \leq i \leq N$
The user task timing is calculated based on the resources required and the task time is calculated as
$\left(\operatorname{Tn}\left[s_{x}, s_{y}\right]\right)=\sqrt{\sum_{l=l_{i}}^{M_{N}} p(i)+\left(T-l_{i}\left(I\left[l_{s}, l_{f}\right]\right)\right)^{2} \times P_{l}^{I\left[l_{i}, l_{j}\right]}}$
The resources are allotted to the tasks that are completed in a short time if there are multiple tasks with low time interval $\mu$ and high time interval $\lambda$. The Resource allocation is done to the users after calculating the estimated time ET for resource usage as
$E T(S)=\frac{\lambda+N_{a v g}+\max \left(\sum_{p(i)}(\mu=0, s=1)\right)}{\max \left(\sum_{A .}\right) * T}$
Algorithm User Priority based Accurate Resource Allocation (UPbARA)
{
Step 1: Input the number of servers and VMs to form a server groups.
Step 2: Perform user validations at the registry level for all kinds of users.
Step 3: Registered users can send resource requests RREQ to the service provider.
Step 4: The users requests are handled by the request handler by considering the authenticated users information
If (user information = = valid) then
{
If (Ri $\in$ R & Ti<Th with Req status (Ri) = True) then
{
Resource is allotted to the cloud user and the resource is locked with that user that is calculated as
$R_{i, j}(T(i))=\sum_{i=1}^{N} R(i)+P(i)+\left\{\frac{|| i_{j}-T i_{i}||}{|| j_{j}-T_{K}||}\right\}^{-\frac{2}{m}-1}+T h_{a v g}$
where, R is the resource id allotted, P is the priority of the cloud user, T is the time interval for resource allotted and Th is the Threshold time.
The resource scheduling time is calculated as
$\mathrm{T}(\mathrm{R}(\mathrm{i}))=\min \sum_{r=1}^{N} \mathrm{P}(\mathrm{i})|s i=0|+F(T h)$
where, F is the fixed time interval to hold the resource to avoid delay.
else if (Ri $\in$ R & Ti<Th with Req status (Ri) = False) then
{
Deallocate the allocated resource and repeat the process
The deallocation is performed as
$D(R(i))=\frac{1}{R} \sum_{i=1}^{N} \mathrm{P}|s i=0|$
}
}
else
Request is rejected;
}
Step 5: The resource idle time is calculated for every user to identify the delay levels and the users resources whose delay level is more; the resources are reallocated to the low priority users to improve the system performance. The delay is calculated as
$D(R(i))=\frac{f_{i}}{\sum_{n=1}^{s} f i_{n}}+\sum_{s=1}^{N_{n}}(\hat{P}(x, y)-Q(x, y))^{2}+T h$
Fi is considered as $\left\{\begin{array}{cc}\frac{1}{1+V M_{i}} & \text { if } s_{i} \geq 0 \\ 1+a b s\left(V M_{i}\right)^{\prime} & \text { if } s_{i}<0\end{array}\right.$
Step 6: Allot all the available resources and then after task is completed reschedule the resources to perform the user tasks.
}
With the increasing popularity of cloud computing, especially the development of virtualization technology, scheduling of computing resources can be no longer confined to restriction that users’ tasks should be allocated to single physical machine using available resources. Resource Scheduling can be achieved through dispatching resources from the point of benefits so that resource allocated to one user is locked and remaining resources provided by multi physical machines are allotted to other users. Although parallel processing of virtual machines may generate additional overhead, this kind of computing resources management could be more effective. The proposed model considers the dataset from the URL http://eforexcel.com/wp/downloads-16-sample-csv-files-data-sets-for-testing/. The proposed User Priority based Accurate Resource Allocation (UPbARA) model is implemented in python simulated in ANACONDA. The available resources are scheduled to the cloud authorized users based on the priority assigned to the users. The types of priorities assigned to users are indicated in Table 1.
Table 1. Resources priority levels
|
S.No |
Resources Priority |
|
1 |
Users of High Priority |
|
2 |
Users of Low Priority |
|
3 |
Users of No Priority |
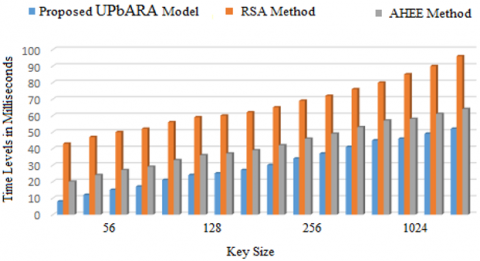
The proposed model validates the users and provides a cloud environment for secure data transmission. The proposed model performs data encryption before transmitting the data to the cloud. The time taken for encryption of data in the proposed model is less when compared to the traditional methods. The Figure 4 depicts the encryption time levels of the proposed and traditional methods based on the key size considered for performing encryption.
Figure 4. Encryption time levels
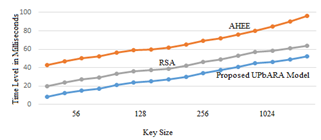
The data after encryption is stored in cloud and based on the authorized cloud user requests the data can be accessed. The cloud user when requests for data stored in cloud the data has to be decrypted before allowing accessing permissions. The decryption time levels are represented in Figure 5.
Figure 5. Decryption time levels
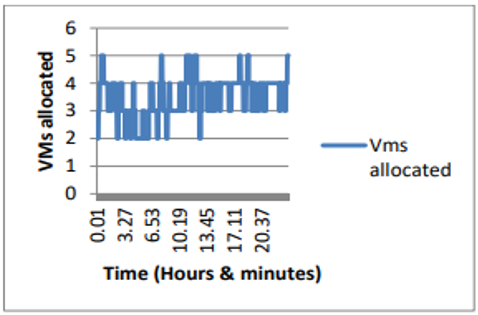
The cloud user after authorization, resource requests should be placed to access cloud resources. The VMs are used for allocating the resources and processing user tasks with the allocated resources. The resources are allocated based on the priority of users and the tasks are processed accordingly. The VMs processing time intervals are indicated in Figure 6.
Figure 6. Time Vs VMs allocated
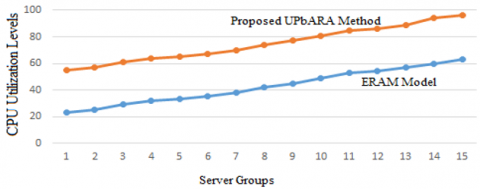
The performance of the system will be improved when the CPU utilization is more. The tasks of the user should be completed in time and the resources are allotted only for a fixed time interval and then will be de allocated and re allocated to new users based on priority level. The CPU utilization based on the number of VMs handling the resources and processing the tasks are represented in Figure 7.
Figure 7. No. of VMs Vs CPU utilization
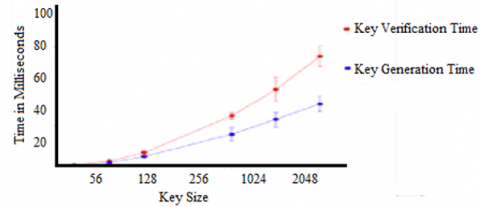
The proposed model considers the key generation and verification time levels for performing encryption and decryption of data. The key generation and verification time levels are indicated in Table 2.
Table 2. Key generation and verification time levels
|
File size (bytes) |
Key generation time (sec) |
Verification time(sec) |
|
16 |
1.23 |
1.2 |
|
32 |
1.98 |
2.9 |
|
128 |
6.85 |
8.76 |
|
256 |
15.56 |
17.23 |
|
512 |
23.36 |
28.66 |
|
1031 |
45.76 |
34.57 |
The key generation and verification time levels are analyzed and compared with the traditional methods. The proposed model key generation and verification time is less when compared to the traditional models. The key generation and verification time levels are represented in Figure 8.
Figure 8. Key generation and verification time levels
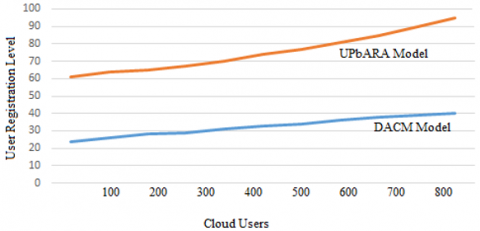
After the cloud was created, the users registered with the cloud and average effective registered times are shown in Figure 9. Based on the users requirement, the registration of the cloud will be performed and the load balancing need to be maintained after user registrations. The proposed model user registration is more as the load balancing is also done effectively.
Figure 9. User registration level
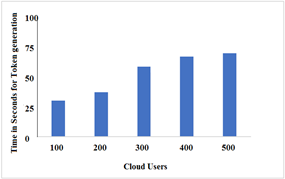
Figure 10. UIDT generation time level
Users are assigned a personal data identifier called UDID, which is important for authenticating data access. The period of the generation of UIDT is shown in Figure 10.
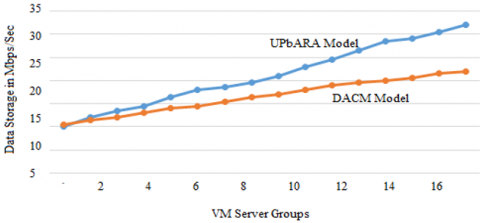
Figure 11 depicts the time taken to move data from device to the cloud. This can be achieved quickly and conveniently as well as in the cloud as part of the process.
Figure 11. Data storage level
The user validation standard for accessing the data has been completed and the proposed approach offers significantly higher validation rate. Users are verified after they have keys for having data access rights. We are establishing a smart system which can detect malicious users and deny them from granting any data access. The user's level of loyalty is depicted in Figure 12.
Figure 12. User validation rate
The grade of accuracy of this proposed method is high compared to the conventional DACM method. The proposed method reliably recognizes users and validates them and give them access to the data based on the registered users only. The level of accuracy is represented in Figure 13.
Figure 13. Accuracy level
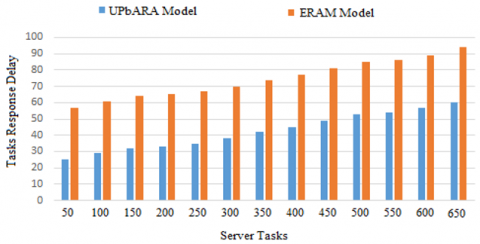
The proposed model efficiently schedules the provision of cloud services. The new model has the advantage of low reaction time relative to the old one. As shown in Figure 14, the response delay for some tasks varies.
Figure 14. Response delay for varying tasks
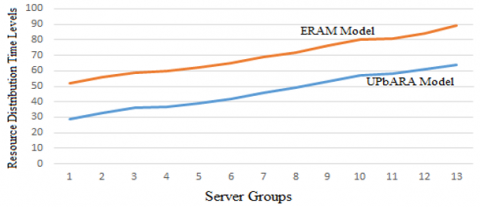
When cloud users request for a resource, the proposed cloud model efficiently schedules the services without delay or extra consuming energy. The proposed and conventional way of resource allocation is shown in Figure 15.
Figure 15. Distribution of resource time levels
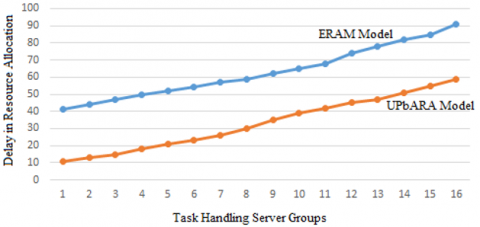
The suggested distribution of resources is depicted in Figure 16. The procedure is relatively simpler as compared to the conventional way.
Figure 16. Delay in resource allocation
Resource Allowance is the route in cloud computing to define assets for the cloud applications needed through the web. If this activity is not fully supervised, the performance of the system will be decreased as the delay will be more. The provision of assets solves this problem by enabling the master associations to control assets for each module. The Resource Allocation model involves the inclusion and allocation of unusual assets in cloud exercises to solve cloud computing problems. The role of assigning resources is more difficult because of the limited resources available and the rising demand for customers. Many unique models and strategies for efficient allocation of resources have therefore been proposed. Handling the resources adequately to manage the massive volume of traffic is a challenging task for the service providers to avoid delay and to increase the performance. Allocation of activities to one resource contributes to inefficient efficiency and user obstruction. Resource scheduling mechanism allocates tasks, so that system applications can effectively leverage resources which ultimately lead to scaling gain. The proposed model aims to provide a resource allocation model for the cloud model with assigning priorities to the users by the request handler method. The proposed model allocates the resources and manages the resources with 97% accuracy and with reduced delay to only 4% in the system. The proposed model verifies the users also before allocating the resources thus reduces the malicious actions in the cloud also and provides an environment for secured data transmission.
[1] Rehman, G.U., Ghani, A., Muhammad, S., Singh, M., Singh, D. (2020). Selfishness in vehicular delay-tolerant networks: A review. Sensors, 20(10): 3000. https://doi.org/10.3390/s20103000
[2] Wang, S., Yuan, J., Li, X., Qian, Z., Arena, F., You, I. (2019). Active data replica recovery for quality-assurance big data analysis in IC-IoT. IEEE Access, 7: 106997-107005. https://doi.org/1109/ACCESS.2019.2932259
[3] Kumar, A., Kumar, D., Jarial, S.K. (2017). A review on artificial bee colony algorithms and their applications to data clustering. Cybernetics and Information Technologies, 17(3): 3-28.
[4] Mingprasert, S., Masuchun, R. (2017). Adaptive artificial bee colony algorithm for solving the capacitated vehicle routing problem. In 2017 9th International Conference on Knowledge and Smart Technology (KST), pp. 23-27. https://doi.org/10.1109/KST.2017.7886072
[5] Aslanpour, M.S., Ghobaei-Arani, M., Toosi, A.N. (2017). Auto-scaling web applications in clouds: A cost-aware approach. Journal of Network and Computer Applications, 95: 26-41. https://doi.org/10.1016/j.jnca.2017.07.012
[6] Chang, V., Ramachandran, M. (2015). Towards achieving data security with the cloud computing adoption framework. IEEE Transactions on Services Computing, 9(1): 138-151. https://doi.org/10.1109/TSC.2015.2491281
[7] Li, Q., Ma, J., Li, R., Liu, X., Xiong, J., Chen, D. (2016). Secure, efficient and revocable multi-authority access control system in cloud storage. Computers & Security, 59: 45-59. https://doi.org/10.1016/j.cose.2016.02.002
[8] Kartit, Z., Azougaghe, A., Idrissi, H.K., El Marraki, M., Hedabou, M., Belkasmi, M., Kartit, A. (2015). Applying encryption algorithm for data security in cloud storage. In International Symposium on Ubiquitous Networking, 366: 141-154. https://doi.org/10.1007/978-981-287-990-5_12
[9] Chang, V., Wills, G. (2016). A model to compare cloud and non-cloud storage of big data. Future Generation Computer Systems, 57: 56-76. https://doi.org/10.1016/j.future.2015.10.003
[10] Li, Q., Ma, J., Li, R., Liu, X., Xiong, J., Chen, D. (2016). Secure, efficient and revocable multi-authority access control system in cloud storage. Computers & Security, 59: 45-59. https://doi.org/10.1016/j.cose.2016.02.002
[11] Shen, J., Liu, D., Liu, Q., Wang, B., Fu, Z. (2016). An authorized identity authentication-based data access control scheme in cloud. 2016 18th International Conference on Advanced Communication Technology (ICACT), pp. 56-60. https://doi.org/10.1109/ICACT.2016.7423272
[12] Wang, W., Jiang, Y., Wu, W. (2016). Multiagent-based resource allocation for energy minimization in cloud computing systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(2): 205-220. https://doi.org/10.1109/TSMC.2016.2523910
[13] Choi, Y., Lim, Y. (2016). Optimization approach for resource allocation on cloud computing for IoT. International Journal of Distributed Sensor Networks, 12(3): 3479247. https://doi.org/10.1155/2016/3479247
[14] Kimpan, W., Kruekaew, B. (2016). Heuristic task scheduling with artificial bee colony algorithm for virtual machines. In 2016 Joint 8th International Conference on Soft Computing and Intelligent Systems (SCIS) and 17th International Symposium on Advanced Intelligent Systems (ISIS), pp. 281-286. https://doi.org/10.1109/SCIS-ISIS.2016.0067
[15] Rastkhadiv, F., Zamanifar, K. (2016). Task scheduling based on load balancing using artificial bee colony in cloud computing environment. IJBR, 7(5): 1058-1069.
[16] Sun, X., Qu, S., Zhu, X., Zhang, M., Ren, Z., Yang, C. (2015). Cloud storage architecture achieving privacy protection and sharing. Applied Mathematics & Information Sciences, 9(3): 1639.
[17] Saraswathi, A.T., Kalaashri, Y.R., Padmavathi, S. (2015). Dynamic resource allocation scheme in cloud computing. Procedia Computer Science, 47: 30-36. https://doi.org/10.1016/j.procs.2015.03.180
[18] Veeramallu, G. (2014). Dynamically allocating the resources using virtual machines. International Journal of Computer Science and Information Technologies, 5(3): 4646-4648.
[19] Gupta, P., Ghrera, S.P. (2016). Power and fault aware reliable resource allocation for cloud infrastructure. Procedia Computer Science, 78: 457-463. https://doi.org/10.1016/j.procs.2016.02.088
[20] Hesabian, N., Haj, H., Javadi, S. (2015). Optimal scheduling in cloud computing environment using the bee algorithm. Int J Comput Netw Commun Secur, 3: 253-258.