Batool Ali Majeed*![]() | Ammar Yasir Hardan
| Ammar Yasir Hardan![]() | Batool Yasir Hardan
| Batool Yasir Hardan![]() | Dunya Faeq Munaf
| Dunya Faeq Munaf![]()
(This article is part of the Special Issue Machine Learning and Artificial Intelligence for Context-Aware Network Optimization)
© 2024 The authors. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Early diagnosis of heart disorders is an essential issue since they might be life-threatening conditions that call for urgent medical care. Chatbots as a user-friendly technology can be used to deliver general assistance and information anywhere anytime. However, the decision-making accuracy is one of the key challenges of Chatbots. In this paper, a medical Chatbot is developed for the purpose of early cardiac disease diagnosis based on given symptoms. An approved dataset known as the Cleveland Heart Disease dataset is utilized in this work. Hence, for accurate decision-making, three machine learning algorithms Support Vector Machine (SVM), and Logistic Regression (LR), and Extreme Gradient Boosting (XGBoost) are compared and tested to nominate the best algorithms for heart health disorders detection. Three simulation scenarios are applied to test the performance of each algorithm using first all features of the dataset, then the k-best feature selection method, and the application of Grid Search (GS) optimization algorithms. The performance evaluation shows that the prediction accuracy of the proposed XGBoost algorithm outweighs other algorithms.
heart diseases, Chatbot, AI, machine learning, SVM, LR, XGBoost, grid search, k-best feature selection
In the era of AI, the smartness of machines is continuously increased by many folds. Consequently, this paved the way for human to interact with and consults machine to solve problems. [1]. Diagnosing heart conditions as soon as feasible is crucial since they can be potentially fatal diseases. It is crucial to recognize cardiac conditions as soon as possible because they might be fatal ailments [2]. According to the World Heart Federation (WHF) report in 2023, cardiovascular disease deaths were 20.5 million in only the year 2021, which is approximately one-third of all fatalities worldwide and a general rise in the 121 million estimated deaths from cardiovascular disease (CVD) [3]. Hence, early and correct diagnosis of cardiac disease is essential to preventing further harm and preserving the lives of patients. Though there is high respect for doctors in hospitals for their undeniable help and proficiency. On the other hand, AI has emerged strongly to the scene, which might be applied to every aspect of life. By leveraging Natural Language Processing (NLP) algorithms, Chatbots can revolutionize the process of collecting symptoms and conducting interviews by making it more convenient for users compared to traditional questionnaire methods. Originally, chatbots were meant to be applications for gathering patient health data [3]. By utilizing AI algorithms, Chatbot can significantly aid in the patient interview process for gathering health symptoms and providing self-care [4].
In the context of chatbots that offer information on cardiac problems in humans, precision is not only vital but also vital for the users' welfare. For a chatbot to be helpful or informative about heart problems in humans, accuracy is crucial. Health-related information is delicate, and people looking for advice on their health may suffer grave consequences if they are misinformed. It will soon be feasible to predict any life-threatening diseases early on thanks to breakthroughs in artificial intelligence. While they may not take the role of a doctor, these technologies can help patients.
In this paper, an accurate Chatbot system is proposed for heart disease diagnosis. The foundation of chatbots is artificial intelligence. For this, the performance of three ML techniques XGBoost, SVM, and LR are compared and then the XGBoost model is elected to be the key algorithm in the proposed Chatbot system.
This paper's primary contributions are as follows:
The structure of the paper is as follows. Section 2 discusses prior research studies. Section 3 presents the main components of the research. Section 4 presents the XGBoost algorithm that is suggested. Section 5 presents the results and comments. Section 6 concludes the paper.
Those more pertinent contributions to the discipline are briefly introduced in this section. Researchers have a lot of emphasis on the use of chatbots in medical systems, which is specifically believed to be a significant issue for individualized diagnosis based on symptoms.
Divya et al. [5] developed an AI-powered medical chatbot that can identify a problem and deliver basic information about it before contacting a doctor. Mishra et al. [6] dsigned a virtual doctor chatbot and enable patient-doctor communication. This chatbot was created using a pattern-matching algorithm and natural language processing. It shows that up to 80% of the answers provided by the chatbot are accurate.
Pradhan et al. [7] suggested a system by concentrating on creating a substitute utilizing the Decision Tree Algorithm where users can communicate with chatbots that identify more symptoms, diagnose the ailment, and gauge patient trust before recommending a specialist doctor.
Hsu and Yu [8] suggested creating a machine learning and natural language processing medical chatbot. They used the Random Forest (RF) and decision tree methods.
Rahman et al. [9] offered Disha (Direction), a closed-domain Bangla healthcare chatbot powered by machine learning. The knowledge base as well as the interactions with users are employed via conversation.
Astya et al. [10] proposed a machine learning-based medical chatbot using SVM and KNN algorithms, the prediction accuracy is up to 94.7%.
Hussain et al. [11] applied the NLP, machine learning, and Optical Character Recognition (OCR) concepts to implement a disease prediction chatbot and report analyzer with an accuracy of 95.74%.
Sivaraj et al. [12] developed Medibot, which is a voice-based AI medical chatbot with a smartwatch. Convolutional Neural Networks (CNN) are used with a prediction accuracy of around 95%.
Fernandes et al. [13] suggested a Chatbot system to detect and by comparing models such as SVM, Naive Bayes, KNN, and Decision Tree with the heart illness dataset, one can accurately predict the presence of heart disease. SVM performs better than the other algorithms.
Nanaware et al. [14] developed a method for forecasting the heart disease by ML and Chatbots. Three ML algorithms KNN, LR, and Decision Tree are tested to select the best-performing model. To predict diseases, logistic regression is used with an accuracy of up to 85%.
A system with an intelligent dialog health chatbots in telemedicine has been suggested by Vasileiou and Maglogiannis [15]. Two types of datasets are trained including heart disease and Covid-19 with accuracy of 82% and 98.3% respectively.
A ML-based decision assistance system for the prediction of heart disease is designed by Rani et al. [16]. The applied algorithms involve SVM, Naive Bayes, LR, Random Forest, and Adaptive Boosting (AdaBoost) classifiers have all been employed in this study. They obtained 86.6% accuracy.
A Medical Chatbot with text and voice Instruction for Machine Learning is proposed by Pachauri et al. [17].
Chow et al. [18] designed a radiotherapy educational chatbot using artificial intelligence. The chatbot's design makes use of AI capabilities like Natural Language Processing (NLP) and is guided by communication tactics for the intended audience.
Gori et al. [19] suggested a chatbot that uses the user's symptoms to predict likely ailments. Several technologies, including Deep Learning, NLP, and Long Short-Term Memory (LSTM) algorithms, are used to deploy the chatbot. Based on linear regression, a chatbot is employed to monitor daily health by Wongpatikaseree et al. [20]. To track the geriatric population's blood pressure trend, linear regression was designed. Consequently, users can avoid or treat various diseases thanks to chatbot warnings and health care.
A chatbot for psychiatric therapy in mental healthcare services was proposed by Oh et al. [21] and is based on emotional interaction analysis and phrase production.
A summary of the applied methods in the related literature is shown in Table 1.
Table 1. A brief summary of the most related literature
|
Ref. |
ML Method |
Use of Chatbot |
|
[4] |
Rule based approach |
√ |
|
[5] |
Pattern matching and NLP |
√ |
|
[6] |
Decision Tree Algorithm |
√ |
|
[7] |
Decision Tree and RF |
√ |
|
[8] |
ML and natural language |
√ |
|
[9] |
SVM and KNN algorithms |
√ |
|
[10] |
NLP, machine learning |
√ |
|
[11] |
CNN |
√ |
|
[12] |
SVM, Naive Bayes, KNN, Decision Tree |
√ |
|
[14] |
KNN, LR, Decision Tree |
√ |
|
[15] |
Intelligent dialog system |
√ |
|
[16] |
SVM, Naive Bayes, LR, Random Forest |
√ |
In this work, the XGBoost, SVM, and LR algorithms are employed with the application of the feature selection method (k-best) and the Grid Search (GS) optimization algorithm. The main purpose is to maintain high accuracy classifier used for the medical chatbot.
The proposed chatbot is developed based on several components including the dataset, ML algorithms, feature selection method, and optimization algorithm. This section includes a brief description of each component of the proposed chatbot.
3.1 Heart disease dataset description
The dataset includes several heart disease-related variables, including demographic data, test results, and markers of heart diseases. Heart disease is either present or absent according to the target variable. In this work, the Cleveland Clinic Heart Disease dataset [22], also known as the "Cleveland Heart Disease dataset," is a familiar dataset used for machine learning and data mining tasks related to heart disease prediction. It was originally collected and created by researchers at the Cleveland Clinic Foundation in the late 1980s. The collection of the dataset involves 303. It covers cases of people with cardiac disease as well as those who are healthy. The number of males was 207 and 96 females the rest were females. This dataset has been commonly applied in the field of ML to build predictive models for diagnosing the occurrence of heart disease based on the given attributes. The details of the dataset are as follows.
Number of Instances: 303
Number of Attributes: 14
Attribute Information:
Patient's age expressed in years
Sex: The patient's gender (1 being male and 0 being female).
Types of chest pain (CP): 1 represents classic angina, 2 atypical angina, 3 non-anginal pain, and 4 asymptomatic.
Resting blood pressure (in millimeter-Hg) upon hospital admission is known as Trestbps.
Chol: The amount of serum cholesterol (mg/dl) > 120 mg/dl of fasting blood sugar is considered false (true if 0 = 0).
Restecg: Electrocardiogram results at rest (0 = normal; 1 = aberrant ST-T wave; 2 = likely or definitely left ventricular hypertrophy).
Thalach: Heart rate attained maximum
Exang: Angina brought on by exercise (1 = yes; 0 = no).
Oldpeak: Exercise-induced ST depression in comparison to rest.
Slope: The peak exercise's slope ST segment 1 is slope-up, 2 is flat, and 3 is slope-down.
Ca: Fluoroscopy-colored main vessels (0–3) in number
Thal: thalassemia (3 regular; 6 deformity; 7 reversible defect).
Target: Presence of heart disease (1 = presence; 0 = absence)
3.2 ML classifiers algorithms
In this section, the theoretical description of the proposed ML classifiers of the medical chatbot is demonstrated as follows.
3.2.1 XGBoost algorithm
The XGBoost method's primary goal was to provide distributed gradient boosting with a focus on scalability and portability. Additionally, the XGBoost could be implemented in parallel according to boosted tree structures, which allowed it to model complex problems with the highest level of precision and speed. As a result, the XGBoost method has piqued the interest of many ML researchers and developers [23]. Recently, the XGBoost algorithm has received praise for its performance in many situations, and this praise is a result of the development of additive models. Let $c_k(x)$ is a function of base learners. The additive model is hence the total of the fundamental learners [24] as follows.
$g(x)=\sum_{l=1}^n c_k(x)$ (1)
where, n represents the total number of the base learners, l=1,2,...n.
To minimize the risk $R=g(x, y)$ of the base learners $c_k(x)$ in (1) is expressed as follows.
$\hat{c}_k(x)=\operatorname{argmin} \sum_u R\left(g_{l-1}(x)+c_k(x), y\right)$ (2)
where, $u=\{(\mathrm{x}, \mathrm{y})\}$ refers to the dataset. Thus, using the boosting technique, the additive model represented in Eq. (1) is iteratively updated as shown in Eq. (3).
$(x)=\operatorname{argmin} \sum_u R\left(g_{l-1}(x)+c_k(x), y\right)$ (3)
The pseudocode of the XGBoost algorithm is demonstrated in Algorithm 1 [24].
It is important to note that XGBoost supports additional advanced features like feature importance analysis, which sheds light on the relative importance of various features in the model's predictions, and early stopping, which can automatically determine the ideal number of boosting rounds based on the performance of the validation set.
|
Algorithm 1: XGBoost Algorithm |
|
|
Input: Dataset; Hyperparameters; Initialize $f_0(x)$ |
|
|
Output: |
|
|
1: |
For j = 1, 2, ... N do |
|
2: |
Calculate $g_j=\frac{\partial L(y, f)}{\partial f}$ |
|
3: |
Calculate $h_j=\frac{\partial^2 L(y, f)}{\partial f^2}$ |
|
4: |
The structure is determined via selecting splits with maximized gain |
|
5: |
$\mathrm{A}=\frac{1}{2}\left[\frac{G_L^2}{H_L}+\frac{G_R^2}{H_R}-\frac{G^2}{H}\right]$ |
|
6: |
Determine the leaf weights $w^*=-\frac{G}{H}$ |
|
7: |
Determine the base learner $\hat{b}(x)=\sum_{j=1}^H w I$ |
|
8: |
Add trees $f_k(x)=f_{k-1}(x)+\hat{b}(x)$ |
|
9: |
End |
|
10: |
Results: $f_k(x)=\sum_{k=0}^M f_k(x)$ |
3.2.2 Support Vector Machines algorithm
One of the most popular supervised learning methods for solving regression and classification problems is Support Vector Machines (SVM). However, machine learning classification problems are its primary use.
The SVM method aims to discover the optimum line or decision boundary to divide n-dimensional space into classes in order to quickly categorize new data points in the future. This ideal decision boundary is known as a hyperplane [25]. SVM is used to choose the extreme vectors and points that will help create the hyperplane. Support vectors, the foundation of the SVM approach, are used to represent these extreme circumstances. The main principle behind SVM is to use a hyperplane to partition the dataset into several classes. The SVM employs a non-linear kernel to implicitly transform the input space into a high-dimensional feature space. The best hyperplane in the feature space is then established by maximizing the margins of class borders. Examine the following diagram, which uses a decision boundary or hyperplane to divide two categories into two groups. Eqs. (4) and (5) display the mathematical representation of SVM..
$\begin{array}{r}\min \theta(\delta, q, v)=\left(\frac{1}{2}\right)\|\delta\|^2+\beta \sum_{i=1}^n v_i \\ \text { s.t. }\left\{\begin{array}{l}y_i\left(\delta . x_i-q\right)+v_i \geq 1 \\ v_i \geq 0 \quad \forall_i=1,2, \ldots, n\end{array}\right.\end{array}$ (4)
where, the margin size with mistakes can be adjusted using the positive constant parameter represented by the $\beta$. The plane $(\delta, q)$ is obtained by resolving a quadratic programming problem. Next, Eq. (4) is used to derive the classification function of Eq. (5) for the new data point (x). the pseudocode of the SVM algorithm is shown in Algorithm 2 [26].
$\operatorname{Classify}(x)=\operatorname{sign}(\delta . x-q)$ (5)
|
Algorithm 2: SVM Algorithm |
|
|
Input: Dataset x (attribute) and y (label) |
|
|
Output: Decision Surface /Equation (5) |
|
|
1: |
For all $\left\{x_i, y_i\right\},\left\{x_j, y_j\right\}$ do |
|
2: |
Optimizing support vector //Equation (4) |
|
3: |
End for |
|
4: |
Retain support vectors // Equation (5) |
|
5: |
End for |
|
6: |
End Function |
3.2.3 Logistic regression algorithm
Logistic regression is a well-known ML technique in the field of supervised learning. The category-dependent variable is predicted using a set of independent parameters in this method.
Using logistic regression, the outcome of a dependent categorical variable is predicted. As a result, a discrete or categorical value must be the outcome. It returns probabilistic values between 0 and 1, rather than a precise number between 0 and 1. True or false, 0 or 1, yes or no, and so on. Despite having different uses, logistic regression and linear regression have many similarities. Logistic regression is used to solve problems involving classification, while linear regression is used to handle problems requiring regression. Algorithm 3 displays the LR pseudocode [27, 28].
|
Algorithm 3: LR Algorithm |
|
|
Input: data for training |
|
|
Output: Best classification data |
|
|
1: |
For j = 1, 2, ... k do |
|
2: |
each instance of training and testing data $d_j$ |
|
3: |
The desired value for the regression is set to$V_j=\frac{y_j-P\left(1-d_j\right)}{\left[P\left(1-d_j\right)\left(1-P\left(1-d_j\right)\right)\right]}$ |
|
4: |
Initialization for the weight of instance $d_j$ to $P\left(1 \mid d_j\right) \cdot P(1-P) \cdot\left(1 \mid d_j\right)$ |
|
5: |
finalization the $f(j)$ to data with the class value $V_j$ with weights $W_j$ decision classification label. |
|
6: |
Assign: if $P\left(1 \mid d_j\right)>0.5$ then (class lable1) |
|
10: |
else (class label 2) |
3.3 K-best feature selection method
When you have irrelevant features in your data, these characteristics behave as noise, which causes the machine learning models to perform badly. Feature Selection (FS) enhances model performance by relocating the current features into a domain with fewer dimensions. Faster machine learning models are the result. By avoiding overfitting, it improves the generalizability of the model. a formal version of the wrapper-based k-best FS and FR problem using a dataset represented by X and Y, where Y is the response vector of length n and X is the n p data matrix with p features (where k p) and n instances. Recall that Y is distinct from y, which was described as the noisy measurements of the loss function in Eq. (1).
If $X_j$ is the jth feature in $\mathrm{X}$, then let $X:=X_1, X_2, \ldots . X_p$ be the feature set. To a wrapper classifier $\mathrm{C}$, a k-dimensional subset $\mathrm{X}^{\prime}, L_C\left(\mathrm{X}^{\prime}, \mathrm{Y}\right)$ is defined as the real value of a particular performance criterion on the dataset. The anticipated classification accuracy used as an example was obtained using 5 -fold cross-validation on the whole population that this dataset was sampled from. Due to the lack of universal knowledge regarding $\mathrm{LC}$, the $\mathrm{C}$ classifier is trained on the dataset and measures the value of $y_C\left(\mathrm{X}^{\prime}, \mathrm{Y}\right)$, where $y_C=L_C$ plus. The non-empty feature set $\mathrm{X}$ is specified as the solution to the wrapper-based FS problem [29].
3.4 Grid search hyperparameter optimization
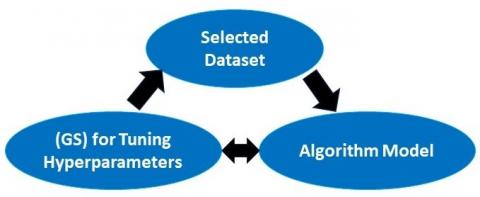
An optimization method called Grid Search (GS) aims to identify the best hyperparameter values. A comprehensive search is performed on a set of exact values for the model parameters as shown in Figure 1. The model is frequently called an estimator. Time, effort, and resources can be saved by using GS exercises. One of the simplest techniques is GS, which assesses each combination of the discrete parameter spaces that are given. Discrete parameters must be created first [30]. The GS technique is also the easiest to use and understand, but it is incredibly inefficient when there are numerous factors. It is also a method that extensively utilizes a manually selected portion of the hyperparameter space of the algorithm. For ease of understanding, the analytical components can be divided into three steps. The initial step would be centered on gathering the required data and designing the features. Selecting the proper machine learning model would be the focus of the second step. The third portion would be the best hyperparameter selection.
Figure 1. The general process of designing the proposed model
3.5 Common chatbot operation process
Using methods like NLP, chatbots are entities that mimic human conversation in their specific accepted setting while using text or vocal language. The goal of the system is to mimic a conversation. Creating a user interface to send input and obtain responses can be used for the development of Chatbot applications. Hence, it is a system to interact with users, by keeping track of interaction and remembering previous commands so that it can provide functionality. The Chatbot can initially start with the rule-based mode for straightforward questions (frequent questions) [31]. However, the rule-based primarily based totally competencies each in know-how and responding to textual content activities are restricted typically to the scope of the script, even though they may be programmed to reply to particular keywords [32]. Therefore, using conversational AI and rule-based Chatbots can attain a lot of extra advantages because of their better ranges of sophistication. Figure 2 shows the generic process of the Chatbot to reach the final decision-making.
Figure 2. The general process of the Chatbot system
Three ML algorithms are used in this work to obtain the best classification model in the decision-making of the heart disease chatbot system. The design is arranged into three phases, which are the first application of the standard algorithm without modification. Then the second scenario includes the feature selection technique. The final phase is represented by using the Grid Search (GS) optimization technique to determine whether applied algorithms' hyperparameters are optimal.
4.1 Design scenario of the first phase
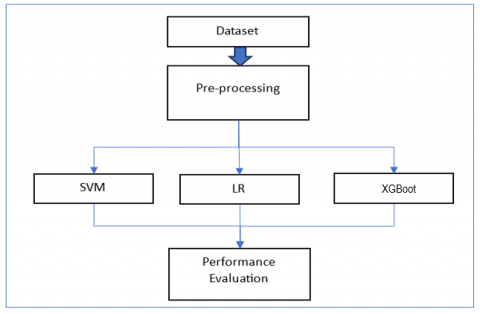
In this scenario, the SVM, LR Logistic Regression, and XGBoost models are used with the total number of the features. as illustrated in Figure 3. In this scenario, the default parameters of LR, SVM, and XGboost are selected.
Figure 3. The evaluation structure of the first phase
4.2 Design scenario of the second phase
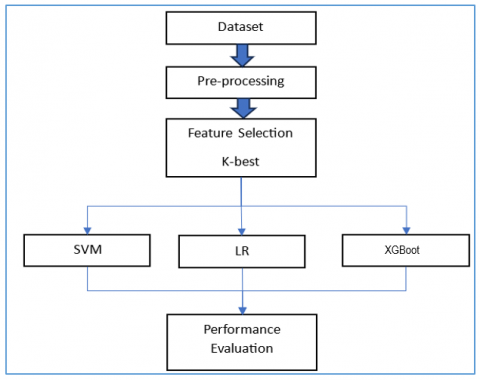
Unlike the first phase, the second phase is achieved with k-best feature selection for the similar ML algorithms SVM, LR, and the XGBoost model. The structure of the evaluation is illustrated in Figure 4.
Figure 4. The evaluation structure of the second phase
4.3 Design scenario of the third phase
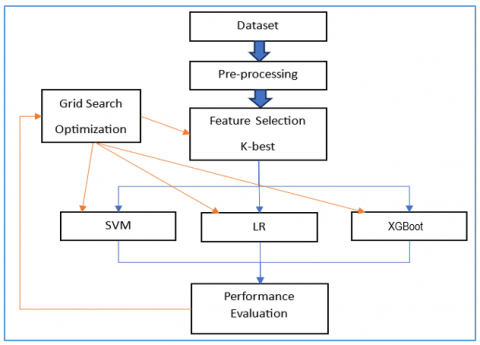
This scenario combines both the K-best feature selection and GS optimization algorithm to gain the best evaluation performance between the applied ML algorithms; SVM, LR, and XGBoost models. Figure 5 shows the corresponding design structure.
Figure 5. The evaluation structure of the third phase
The proposed models are trained using the Cleveland Heart Disease dataset using 70% of samples and 30% allocated for testing the accuracy. The conducted simulation tests are focused on the classification accuracy that is achieved in the proposed chatbot system. Hence, three types of results are produced from the three phases of the design as follows. Table 2 shows that the XGBoost algorithm has higher performance compared to the LR and SVM. The following definitions apply to the metrics:
Accuracy $=\frac{(\beta+\delta)}{(\beta+\delta+\alpha+\theta)}$ (6)
Precision $=\frac{\delta}{(\beta+\theta)}$ (7)
Recall $=\frac{\delta}{(\beta+\alpha)}$ (8)
F1-score $=\frac{\beta}{\beta+\frac{1}{2}(\alpha+\theta)}$ (9)
where, $\beta$ is true positive; $\delta$ is true negative; $\alpha$ is false negative; $\theta$ is false positive
Table 2. The evaluation metrics of the phase one
|
Method |
Accuracy |
Precision |
Recall |
F1-Score |
|
LR |
0.79 |
0.80 |
0.79 |
0.79 |
|
SVM |
0.69 |
0.69 |
0.68 |
0.68 |
|
XGBoost |
0.97 |
0.97 |
0.97 |
0.97 |
The simulation results of the second evaluation phase started with K-Best feature selection as demonstrated in Figure 6, where the threshold is selected as 100 so that the value of k is 6.
It is worth stating that in this scenario the default parameters of LR, SVM, and XGboost are selected. Hence, the corresponding result is shown in Table 3. The XGBoost also outperforms the LR and the SVM.
Figure 6. Feature scores using the K-best method
Table 3. The evaluation metrics of phase two (with the k-best feature selection)
|
Method |
Accuracy |
Precision |
Recall |
F1-Score |
|
LR |
0.81 |
0.80 |
0.81 |
0.82 |
|
SVM |
0.66 |
0.66 |
0.67 |
0.66 |
|
XGBoost |
0.98 |
0.97 |
0.98 |
0.98 |
In the final simulation, two factors are enhanced regarding the applied algorithms including number of the features minimization along with the selection of the best hyperparameters of the applied ML algorithms. The Hyperparameter search range for LR is shown in Table 4.
Table 4. Optimized parameters of LR using GS algorithm
|
Parameter |
Range |
Best Value with GS |
|
K for k-best |
1-13 |
11 |
|
C |
0.1, 1, 10, 100 |
10 |
|
penalty |
'l1', 'l2' |
L1 |
|
solver |
'liblinear', 'lbfgs' |
liblinear |
Likewise, the best hyperparameter search range for the SVM algorithm is illustrated in Table 5.
Table 5. Optimized parameters of SVM using GS algorithm
|
Parameter |
Range |
Best Value with GS |
|
K for k-best |
1-13 |
5 |
|
C |
0.1, 1, 10, 100 |
1 |
|
kernel |
'linear', 'rbf' |
'rbf' |
|
gamma |
''scale', 'auto' |
'auto' |
Then the obtained hyperparameters of the search range for the XGBoost algorithm is shown in Table 6.
Table 6. Optimized parameters of SVM using GS algorithm
|
Parameter |
Range |
Best Value with GS |
|
K for k-best |
1-13 |
12 |
|
learning_rate |
0.1, 0.01, 0.001 |
0.1 |
|
max_depth |
3, 5, 7 |
5 |
|
n_estimators |
50, 100, 200 |
100 |
|
subsample |
0.8, 1.0 |
1.0 |
Now the results of classification are enhanced for all algorithms as illustrated in Table 7. However, still the XGBoost algorithm has superior performance compared to others.
Table 7. The evaluation metrics of phase three (with both of the k-best feature selection and GS)
|
Algorithm |
Accuracy |
Precision |
Recall |
F1-Score |
|
LR |
0.82 |
0.82 |
0.83 |
0.83 |
|
SVM |
0.79 |
0.78 |
0.78 |
0.78 |
|
XGBoost |
0.99 |
0.99 |
0.99 |
0.99 |
A concise comparison with the related literature in terms of the obtained accuracy is demonstrated in Table 8.
Table 8. comparison of the Performance with related work
|
Work |
Method |
Results (Accuracy) |
|
[5] |
pattern matching algorithm and NLP |
80% |
|
[9] |
SVM and KNN algorithms |
94.7% |
|
[10] |
NLP, machine learning |
95.74% |
|
[11] |
CNN |
95% |
|
[14] |
KNN, LR, Decision Tree |
85% |
|
[15] |
Intelligent dialog system |
98.3% |
|
[16] |
SVM, Naive Bayes, LR, Random Forest |
86.6% |
|
Proposed work |
XGBoost |
99% |
It is worth stating that the impact of using the k-best feature selection with GS optimization led to a significant improvement in the overall proposed method performance.
It is crucial to recognize cardiac conditions as soon as possible because they might be fatal ailments. With the help of the given symptoms, the suggested Chatbot helps the user create a diagnosis of possible diseases. With little human labor, a chatbot can keep track of a user's health and alert them to any potential risks. This will significantly affect the users' quality of life. The performance evaluation reveals that the XGBoost algorithm outweighs the SVM and LR algorithms which have a notable increase in the precision of decision-making with an accuracy of 99%. Different datasets can be considered for more performance evaluation of the proposed ML algorithm to deal with different features. Furthermore, more work can be achieved with the application of other types of optimization and feature selection algorithms. additionally, the IoT protocols can be added to the proposed system to support anywhere-anytime service.
[1] Liu, F., Damen, N., Chen, Z., Shi, Y., Guan, S., Ergu, D. (2023). Identifying smart city leaders and followers with machine learning. Sustainability, 15(12): 9671. https://doi.org/10.3390/su15129671
[2] Moulson, N., Isserow, S., McKinney, J. (2022). Lifestyle considerations in genetic cardiac conditions associated with sudden cardiac death. Canadian Journal of Cardiology, 38(4): 544-548. https://doi.org/10.1016/j.cjca.2021.12.014
[3] George, A.S., George, A.H. (2023). A review of ChatGPT AI's impact on several business sectors. Partners Universal International Innovation Journal, 1(1): 9-23. https://doi.org/10.5281/zenodo.7644359
[4] Dammavalam, S.R., Chandana, N., Rao, T.R., Lahari, A., Aparna, B. (2022). AI based chatbot for hospital management system. In 2022 3rd International Conference on Computing, Analytics and Networks (ICAN), Rajpura, Punjab, India, pp. 1-5. https://doi.org/10.1109/ICAN56228.2022.10007105
[5] Divya, S., Indumathi, V., Ishwarya, S., Priyasankari, M. Devi, S.K. (2018). A self-diagnosis medical chatbot using artificial intelligence. Journal of Web Development and Web Designing, 3(1): 1-7.
[6] Mishra, S.K., Bharti, D., Mishra, N. (2017). Dr. Vdoc: a medical chatbot that acts as a virtual doctor. Journal of Medical Science and Technology, 6(3).
[7] Pradhan, R., Shukla, J., Bansal, M. (2021). ‘K-bot’ knowledge enabled personalized healthcare chatbot. IOP Conference Series: Materials Science and Engineering, 1116(1): 012185. https://doi.org/10.1088/1757-899X/1116/1/012185
[8] Hsu, I.C., Yu, J.D. (2022). A medical chatbot using machine learning and natural language understanding. Multimedia Tools and Applications, 81(17): 23777-23799. https://doi.org/10.1007/s11042-022-12820-4
[9] Rahman, M.M., Amin, R., Liton, M.N.K., Hossain, N. (2019). Disha: An implementation of machine learning based Bangla healthcare chatbot. In 2019 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, pp. 1-6. https://doi.org/10.1109/ICCIT48885.2019.9038579
[10] Astya, R., Kumari, P., Goswami, A., Senapati, A. (2021). MAAC-medicare at a click a medical chatbot using machine learning algorithm. International Research Journal of Modernization in Engineering Technology and Science, 3(4): 957-963. https://www.irjmets.com/uploadedfiles/paper/volume3/issue_4_april_2021/8352/1628083343.pdf.
[11] Hussain, H., Aswani, K., Gupta, M., Thampi, G.T. (2020). Implementation of disease prediction chatbot and report analyzer using the concepts of NLP, machine learning and OCR. International Research Journal of Engineering and Technology (IRJET), 7(4): 1814-1819.
[12] Sivaraj, K., Jeyabalasuntharam, K., Ganeshan, H., Nagendran, K., Alosious, J., Tharmaseelan, J. (2021). Medibot: End to end voice based AI medical chatbot with a smart watch. International Journal of Creative Research Thoughts, 9(1): 201-206.
[13] Fernandes, S., Gawas, R., Alvares, P., Fernandes, M., Kale, D., Aswale, S. (2020). Doctor Chatbot: Heart disease prediction system. Information Technology & Electrical Engineering, 9(5): 89-99.
[14] Nanaware, C., Deshmukh, A., Chougala, N., Patil, J. (2021). An approach to heart disease prediction with machine learning using Chatbot. In: Pawar, P.M., Balasubramaniam, R., Ronge, B.P., Salunkhe, S.B., Vibhute, A.S., Melinamath, B. (eds) Techno-Societal 2020. https://doi.org/10.1007/978-3-030-69921-5_89
[15] Vasileiou, M.V., Maglogiannis, I.G. (2022). The health ChatBots in telemedicine: Intelligent dialog system for remote support. Journal of Healthcare Engineering, 2022: 4876512. https://doi.org/10.1155/2022/4876512
[16] Rani, P., Kumar, R., Ahmed, N.M.S., Jain, A. (2021). A decision support system for heart disease prediction based upon machine learning. Journal of Reliable Intelligent Environments, 7(3): 263-275. https://doi.org/10.1007/s40860-021-00133-6
[17] Pachauri, A., Surana, S., Deshmukh, S., Khangare, B., Dagade, R. (2022). Medical chatbot using machine learning through text and voice instruction. IJARSCT, 2(5). https://ijarsct.co.in/Paper4123.pdf.
[18] Chow, J.C., Sanders, L., Li, K. (2023). Design of an educational chatbot using artificial intelligence in radiotherapy. AI, 4(1): 319-332. https://doi.org/10.3390/ai4010015
[19] Gori, K., Ahmed, Y., Chikane, S., Mathur, A. (2021). Medbot: a chatbot for determining the probable diseases Based on the user's symptoms. International Research Journal of Modernization in Engineering, Technology and Science, 3(5): 3438-3442.
[20] Wongpatikaseree, K., Ratikan, A., Damrongrat, C., Noibanngong, K. (2020). Daily health monitoring chatbot with linear regression. In 2020 15th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Bangkok, Thailand, pp. 1-5. https://doi.org/10.1109/iSAI-NLP51646.2020.9376822
[21] Oh, K.J., Lee, D., Ko, B., Choi, H.J. (2017). A chatbot for psychiatric counseling in mental healthcare service based on emotional dialogue analysis and sentence generation. In 2017 18th IEEE International Conference on Mobile Data Management (MDM), Daejeon, Korea (South), pp. 371-375. https://doi.org/10.1109/MDM.2017.64
[22] Detrano, R. (1989). Long Beach and Cleveland Clinic Foundation. VA Medical Center. http://archive.ics.uci.edu/dataset/45/heart+disease, accessed on 1 May 2023.
[23] Cao, J., Gao, J., Nikafshan Rad, H., Mohammed, A.S., Hasanipanah, M., Zhou, J. (2022). A novel systematic and evolved approach based on XGBoost-firefly algorithm to predict Young’s modulus and unconfined compressive strength of rock. Engineering with Computers, 38(Suppl 5): 3829-3845. https://doi.org/10.1007/s00366-020-01241-2
[24] Choi, D.K. (2019). Data-driven materials modeling with XGBoost algorithm and statistical inference analysis for prediction of fatigue strength of steels. International Journal of Precision Engineering and Manufacturing, 20: 129-138. https://doi.org/10.1007/s12541-019-00048-6
[25] Pham, B.T., Nguyen, M.D., Van Dao, D., et al. (2019). Development of artificial intelligence models for the prediction of compression coefficient of soil: An application of Monte Carlo sensitivity analysis. Science of The Total Environment, 679: 172-184. https://doi.org/10.1016/j.scitotenv.2019.05.061
[26] Pedersen, R., Schoeberl, M. (2006). An embedded support vector machine. In 2006 International Workshop on Intelligent Solutions in Embedded Systems, Vienna, Austria, pp. 1-11. https://doi.org/10.1109/WISES.2006.329117
[27] Ambrish, G., Ganesh, B., Ganesh, A., Srinivas, C., Mensinkal, K. (2022). Logistic regression technique for prediction of cardiovascular disease. Global Transitions Proceedings, 3(1): 127-130. https://doi.org/10.1016/j.gltp.2022.04.008
[28] Singh, D., Nigam, R., Mittal, R., Nunia, M. (2023). Information retrieval using machine learning from breast cancer diagnosis. Multimedia Tools and Applications, 82(6): 8581-8602. https://doi.org/10.1007/s11042-022-13550-3
[29] Akman, D.V., Malekipirbazari, M., Yenice, Z.D., Yeo, A., Adhikari, N., Wong, Y.K., Abbasi, B., Gumus, A.T. (2023). k-best feature selection and ranking via stochastic approximation. Expert Systems with Applications, 213: 118864. https://doi.org/10.1016/j.eswa.2022.118864
[30] Belete, D.M., Huchaiah, M.D. (2022). Grid search in hyperparameter optimization of machine learning models for prediction of HIV/AIDS test results. International Journal of Computers and Applications, 44(9): 875-886. https://doi.org/10.1080/1206212X.2021.1974663
[31] Oh, Y.J., Zhang, J., Fang, M.L., Fukuoka, Y. (2021). A systematic review of artificial intelligence chatbots for promoting physical activity, healthy diet, and weight loss. International Journal of Behavioral Nutrition and Physical Activity, 18: 1-25. https://doi.org/10.1186/s12966-021-01224-6
[32] Meshram, S., Naik, N., Megha, V.R., More, T., Kharche, S. (2021). Conversational AI: Chatbots. In 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, pp. 1-6. https://doi.org/10.1109/CONIT51480.2021.9498508