Samson Ebenezar Uthirapathy* | Domnic Sandanam
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Modern society has a great influence on social networks which have been used to share user’s opinions and ideologies. Opinions discussed in social media about any emergency public event happenings. However, analyzing the opinion proliferation, producing interesting facts, which helps to enhance public security in emergencies. A lot of approaches are available to analyze the problem but suffer to achieve higher performance. This paper presents a real-time opinion prediction method. It analyzes the influence or hit rate of opinion in any case. This method first generates the network with several nodes where each user has been considered as a node. With the trace of social chat, the method classifies and groups the users under different categories of interest. The interest detection is performed according to the Class Level Post Measure (CLPM) which represents the interest of the user under a specific category. Using the actors identified, the method generates an Opinion Hit Matrix (OHM) based on the events and opinions posted. Using the matrix, the method computes the opinion support measure (OSM) to select a subset of opinions to generate recommendations. The proposed algorithm improves the performance of the recommendation generation.
public event, social media, user groups, interest identification, opinion hit matrix, class level post measure
Nowadays, the development of information technology supports the modern society to engage with each other at any point in time. Social media like Facebook, twitter provide the ground for people to share their opinion about any issue, concept, or anything. As human beings have the greatest influence on such social media, they spend more time on that. They perform chat about personal, private, and public issues. For example, the statement made by any celebrity has been tagged by various social network users. It may be about anything like acceptance or condemnation. However, the opinion of any social network user has been posted on social media.
In social media. the conversations made by different users have been used in various problems. Consider a product manufacturer who looks to track the changing interest of users. Then, the product manufacturers can use the traces of social chat. The social network user shares the product purchased by the users of his group. Upon visiting the tag, the users of the group would post a comment on that. So, by maintaining the logs of social chat, the product which is trending can be identified. This would help the product manufacturer in making decisions about the design and the features of the product as well as its cost.
Similar to the above corollary, the public event has been used in solving different problems. The public event is nothing but any activity performed by a group of people who is subject to the conversation. The users of social groups have been allowed to tag the opinion about the event. Each user of social networks has their own opinions about the event. Some of them would tag positive opinions and a few of them would produce negative opinions. However, in a crucial issue, making decisions based on their ideology will not be effective. So, by considering the opinion of various users the problem can be approached effectively. For example, consider a patient X, who has been affected by some cardiac disease. If the medical practitioner decides on the type of treatment pre-provided, then the success rate will be less. The concept of public events can be applied to this issue. By identifying the opinion of various medical practitioners and using their previous chats, similar interested users can be identified. Based on the user group, we can get an effective opinion about the issue to provide efficient treatment.
The effect of opinion in any public event is highly dependent on the number of opinions and the number of similar interested users. So it is necessary to identify with user groups with similar interests. To identify the interests of any user, there are several approaches available in general and it performs by using the frequency of chats on any concept. However, a single user may have some interest and there is no restriction for the same. So it is essential to identify the user groups, whose interests are also similar. By identifying the user groups, the set of tags generated by them can be obtained from the trace. Using the traces, the tags related to the problem can be separated. Using the traces of obtained opinion which has higher occurrence or higher influence can be identified. Also, the opinions can be ranked according to the frequency or using any other algorithm, but the ultimate aim of a public event is to identify an effective opinion.
Consider there is a network N, which has an M number of actors. When a administer tries to decide to issue I based on the trace T. Then, he can identify a subset of actors A and can collect the list of chats performed by A. From the trace, the list of chats related to the issue I can be collected. From the trace, the list of opinions can be identified, and based on that the most popular opinion can be selected. There are algorithms namely Probabilistic latent semantic analysis (PLSA), Topic and location-aware probabilistic matrix factorization (TL-PMF) and Latent Dirichlet allocation (LDA) that have discussed for public events and each algorithm uses various features and measures to identify an effective opinion. However, they suffer to achieve higher performance in generating public event opinions. This paper presents a recommendation system for public events in social media using the opinion hit matrix (OHM). The OHM approach consists of three phases, namely user group identification, OHM generation, and Opinion ranking. It identifies the user group based on the opinion discussed via tracing of the social chats. Next, it generates OHM to identify the number of opinions discussed. Finally, it ranks the opinions for recommendations.
This research paper is organized as follows: In section 2, the literature review elaborates various recommendation systems proposed in the past. In section 3, a detailed explanation of our proposed opinion hit matrix-based recommendation generation steps are presented. The result and discussion are presented in section 4.
There are number approaches discussed for the problem of recommendation generation in public events. This section discusses a few related to the problem.
Liu et al. [1] developed a recommender system that uses propagation dynamics. Initially, the method analyses and designs the public emergency information communication system. Then, it considers various factors like intimacy, conformity, interest, and influence, and viewpoint value. Consequently, the information diffusion and dynamics propagation model has been used to generate recommendations. Meng et al. [2] considered data from Microblog which is similar to twitter being used in China. The event recommendation system designed focuses on the actions to be carried out at the emergencies. The evaluation is carried out with the incident that happened at “Shifang” a city in China in the year 2012. It was a protest against the environmental condition. The method reviewed the set of posts submitted to the official site of Shifang and analyzed the microblog with big data analytics tools.
Yang et al. [3] presented an online video recommendation system based on multi-modal fusion and relevance feedback mechanism. It does not consider the user profile to identify the preference of users instead of title, tag, query, and other surrounding information related to the video is considered. Here textual, visual, and aural effects are considered as modalities, each modality has different weight relevance, intra-weights within a modality, and inter-weight between modalities, relevance weights are adjusted using relevance feedback and multimodal fusion technique.
Zhang et al. [4] proposed a framework to identify the spams and to generate recommendations. First, the method identifies the list of accounts that posted similar tweets and then identifies whether they are spam producers or promotion motivators by classifying them. The classification is performed with Shannon's information theory. Anandhan et al. [5] performed a detailed review of social media recommendation approaches based on the articles in the year of 2011 to 2015. Also, the author discussed various data sets and recommender systems and different data mining techniques. Tang and Liu [6] considered the feedback received on various social events. They present a representation model that is jointly developed by considering the users and events of the project. The classification is performed using a convolution neural network and semantic meanings. Chen and Sun [7] presented a social event recommendation system that generates recommendations based on the interactions and their relations. The relationship between the users has been identified based on the behavior of any user in tweeting.
Liu and Xiong [8] presented a location-based recommendation system with a point of interest. The method uses both textual and contextual information. The LDA (Latent Dirichlet Allocation) model has been used to identify the user interest based on text mining. The recommendation is generated using the probability matrix factorization approach. The similarity of events based on the content of chat and interest between the users has been used by Zhang et al. [9] for recommendation generation. The LDA algorithm has been used to identify the distribution of interest or topic at different events among the users. Based on the distribution the method generates recommendations. Bogaert et al. [10] proposed an event attendance prediction system that uses the Facebook data of various users who have an interest in the soccer team of Europe. They developed a baseline model that uses different data mining algorithms. The augmented model uses different data from users and their friends.
Khrouf and Troncy [11] developed a hybrid semantic model that uses web content. The method combines both users, data with weblink content. The content was filtered using collaborative techniques to make decisions. Bronson [12] proposed a social graph-based approach for recommendation generation. The Facebook data have been used to generate the social graph and their conversation has been used to generate recommendations. Gräßer et al. [13] presented a decisive support system for therapy, which uses collaborative and demographic recommendation systems. The models generate recommendations according to the different therapy options given to various patients at different time windows. Tiroshi et al. [14] developed a mapping model that uses different users’ data and service constraints.
Ricci et al. [15] analyzed various recommendation systems on their precision of generating accurate recommendations and evaluated for their efficiency. Diaby et al. [16] proposed a recommendation system which can generate job notifications to the users of Facebook according to their interest. The method uses the content of their resume available on Facebook and performs analysis of the content and generates notifications to the users. Song et al. [17] presented a machine learning-based tag recommendation generation algorithm. The tag recommendations are generated using the data set available which uses the documents. The tags generated are used to generate the graph which has been used for the classification of documents.
Davoodi et al. [18] presented a behavior analysis model for the problem of recommendation generation. The method uses semantic meanings to identify user relations and performs behavior tracking to identify user interest. According to that, the recommendation has been generated. Also, it has been used to identify the user community in generating recommendations. Ludwig et al. [19] adopted a recommendation generation approach to the problem of generating personalized routes. To support mobile application in providing route orient recommendations, the method uses the public notes. Moore et al. [20] considered and identified different issues managed by the service providers to handle the casualty happens in Ontario. The feedback obtained at the stage has been used to generate recommendations to the modern conditions and issues. Smirnov et al. [21] modeled a proactive recommender system that supports tourism. The method has been developed to support the people in planning their tourism, which has been provided through their mobile devices. Macedo et al. [22] presented a probabilistic model for classification and ranking of recommendation. The method used Facebook data to handle event recommendations and classifies them using a probabilistic model. The recommendations have been ranked according to the opinion and feedback obtained. Daly and Geyer [23] proposed a method using location information and social data to generate event recommendations. They classify the events at local, social, global as dependent or independent nature. According to the category, the attendance on each has been monitored and according to that, the recommendations have been generated.
Fleder and Hosanagar [24] presented an analytical model that enables the user to explore the path-dependent effects and produce recommendations to the user. Aivazoglou et al. [25] developed a fine-grained level content recommendation system for social network users to recommend kinds of music, videos, and online clips.
Ravi and Vairavasundaram [26] proposed a travel recommendation system that uses location information. The method also uses the user interest prediction model and user group identification model. The method uses a Petri net to track on the social network to identify the related users of the network. According to that, the recommendations have been generated. Garcia et al. [27] developed a travel recommendation support that using the time domain data achieved to support the tourism plan. Lucas et al. [28] proposed a hybrid approach for the classification and recommendation generation. Besides, the above-mentioned method employs association mining for the recommendation generation and classification. Huang and Bian [29] developed a Bayesian network-based personalized model for the recommendation generation towards tourism support. Similarly, Garcia et al. [30] introduced an interest-based recommender system. This method uses taxonomy in identifying the user interest and generates a recommendation to the user groups.
Wang et al. [31] proposed a group recommendation system for IoT-based trusted social network users, it involves a three-step process to calculate the user preferences on trusted social networks using matrix factorization then to calculate the user preferences on item similarity and item popularity for group recommendations. Manoharan and Senthilkumar [32] developed a personalized news recommendation system based on intelligent fuzzy-rule, which recommends personalized news articles based on user profile and interest categories in social media like Facebook and Twitter. Sun et al. [33] proposed a competitive diffusion model to analyze and study the competing information diffusion in social networks. This model analyzes the competing information like positive, neutral, and negative information about a product, topic, or any events to affect the scope of the diffusion information. Zhou et al. [34] proposed a context-aware framework and graph-based model called content–context interaction graph-based real-time recommendation method for shared community users in the social network to analyze the social metadata content and contexts. This utilizes the social media characteristics of content and context.
The research works carried out in the research papers [1-28] have generated recommendations using various techniques and features in various domains. Particularly, the research works done in the researches [7-9, 18] have focused on the recommendation generation for public events. However, they suffer to achieve higher performance in recommendation generation and introduce a higher false ratio. Hence, in this work, we have proposed a method to generate recommendations based on opinion discussed over any particular topic using an opinion hit matrix (OHM).
The proposed recommendation generation algorithm takes the social network data set as input and splits them according to the users.
For each user trace, the method applies language preprocessing techniques to obtain the tokens. Then, this method estimates the Class level Post Measure (CLPM) on various interest classes considered.
For each user, the method generates Opinion Hit Matrix (OHM) using which the method estimates opinion support measure (OSM) to group the user under various groups within each class to perform opinion selection for a recommendation.
Figure 1 shows the general block diagram of the proposed opinion hit matrix-based recommendation system on public events and shows various stages.
Figure 1. Block diagram of the proposed OHM system
3.1 Basic terminologies
Definition 1: Opinion Hit Matrix (OHM): OHM is a matrix that contains a set of rows and columns; each row has the value of several opinions, the number of relevant opinions, and the opinion relevancy measure of each class. In this research, support, against and neutral are considered as classes.
Definition 2: Opinion Relevancy Measure (ORM): ORM is a measure of each opinion class calculated using Eq. (1).
$\mathrm{ORM}=\frac{\sum_{i=1}^{s i z e(e)} E(i) \in O c(\text {meta data})}{\operatorname{size}(O c)}$ (1)
In Eq. (1) [31, 35], each user entry is denoted as E and Opinion class is denoted using the term Oc.
$\mathrm{CLPM}(\mathrm{p}, \mathrm{O} \mathrm{c})=\frac{O H M(O c) \cdot {NORP}}{O H M(O c) \cdot {Nop}} \times O R M$ (2)
In Eq. (2), [35] NORP (Number of Relevant Opinions) ≥ 1 and ORM ≥ 1.
For example, consider the tag “I hate demonetization and it is wrong or stupid” as input to the proposed method. In the next step, after removing the stop words like ‘is’, ‘was’, ‘not’, ‘a’ etc., with stemming and tokenization processes have been applied in the preprocessing step, the tokens like hate, wrong, stupid, and demonetization are obtained. Using these tokens, the hit value of the post towards opinion classes like “support or against” have been measured. If the post belongs to the opinion class “against”, then the number of occurrences and match in the list will be calculated to generate OHM. With the help of the opinion hit matrix generated in the previous step, the opinion relevancy measure (ORM) is calculated. For every post, the opinion relevancy measure (ORM) is obtained from its term set for each opinion class.
3.2 Data preprocessing
|
Algorithm 1: Data Preprocessing |
|
Input: Social data set Sds // Sd – social data set Output: Pre-processed data set Pds // Pd – Preprocessed data set Start Read Sds. Initialize Pds. For each entry E Term set Tes = Split(E,’’) // Tes – Term Set For each term T If $\int T \in$ stop word set then Tes = Tes $\in T$ End T = Perform stemming (T) T = Apply Pos Tagger (T) If T = Noun then Tes = Tes ∪ T End End Generate feature vector fv = $\sum T \in T e s$ // fv – Feature vector Add to Pds. End Stop |
The social data set has been used to generate recommendations on a public event that perform various activities like decision making. The data set has several textual information that belongs to various conversations. Each conversation has been read and split into textual terms. The terms generated have been applied to stop word removal. The remaining terms have been used to identify the root words by applying the stemming process. The root words identified have been tagged using POS (Part of Speech) Tagger. Identified nouns have been used to perform the rest of the action.
The algorithm 1 in section 3.2 illustrates how preprocessing is performed. The preprocessed data set has been used to perform interest identification. The input data has been read and from the post, the terms have been obtained by splitting them. The terms identified are available with the term set. From the term set, the presence of stop words which has no meaning has been identified and removed. Similarly, each word is stemmed to identify the root word. Identified words are tagged with parts of speech tagger to identify the nouns. Only nouns are used for the remaining part.
3.3 OHM generation
|
Algorithm 2: OHM Generation algorithm |
|
Input: Preprocessed data set Pds Output: OHM. Start Read Pds. Initialize OHM. Initialize opinion set Os // Os – Opinion Set. For each user U Identify the user set $\mathrm{Us}=\int_{i=1}^{\operatorname{size}(\mathrm{Pd} s)} U S \cup \sum P d s(i) . u s e r==U$ // U – User, Us – User set. For each opinion class Oc For each entry E Compute opinion relevancy measure ORM. $\mathrm{ORM}=\frac{\sum_{i=1}^{\operatorname{size}(e)} E(i) \in O c(\text {meta data})}{\operatorname{size}(O c)}$ // ORM – Opinion relevancy measure If ORM > TH then Add Oc to the opinion set. End End End Opinion class Oc= Opinion class with maximum ORM. Compute number of opinions NOP = Size (Os) Compute number of relevant opinion NORP = $\sum_{i=1}^{\operatorname{size}(O s)} O s(i)==O c$ Add to OHM = {NOP, NORP, ORM} End Stop |
The preprocessed data set has been used to generate an opinion hit matrix. For each class of opinion, the method computes an opinion relevancy measure. Based on the opinion relevancy measure, a single opinion with a higher relevancy measure has been selected. For each class of opinion, a single row has been generated in the opinion hit matrix. It contains information like the number of opinions posted, number of opinions related to the class, and opinion score. The generated OHM has been used to identify the user’s interest.
The procedure explained in Algorithm 2 is used for generating an opinion hit matrix. The generated OHM has been used to identify the user groups. The method maintains several opinion classes and, for each of them; a separate opinion set has been maintained and the method calculates the opinion relevancy measure for each class. If the ORM is higher than the threshold, then the opinion is identified as relevant to the opinion class. Now, the class with higher ORM has been identified and the feature vector has been generated to add in the OHM.
3.4 User group identification
A similar interested user group in the social network at any public event has been identified using the OHM generated. For each opinion class, the method estimates class level post measure (CLPM). It has been measured according to the number of opinions posted, the number of posts relevant to the opinion class, and the opinion relevancy value. Using all these values the method computes the CLPM value. According to the CLPM value, the user interest has been identified. Users with similar interests have been grouped.
|
Algorithm 3: User Group Identification Algorithm |
|
Input: OHM, opinion class Oc Output: User group Ug. Start Read OHM. Initialize user group Ug. For each user U Compute CLPM $=\frac{O H M(O c) \cdot N O R P}{O H M(O c) \cdot \text { Nop }} \times O R M$ IF CLPM >Th then // Th – Threshold value Add to user group Ug = $\Sigma(u \operatorname{ser} \in U g) \cup U$ End End Stop |
Algorithm 3 identifies similar interested users to generate user groups. The Generated user group has been used to populate opinions and recommendations. For each user group, the method estimates the CLPM value for the user identified. If the value of CLPM is higher than Th then the user has been added to the user group.
3.5 Opinion ranking
The ranking of opinion performs according to the opinion support measure (OSM). The value of OSM is estimated based on the number of occurrences of any opinion in the conversation of all the users in the group. To perform this, the method accesses the opinion hit matrix and the preprocessed data set. From there processed data set, the method extracts all the feature vectors of users in the group relevant to the opinion. Now for each opinion, the method estimates OSM value. According to the value of OSM, they are ranked to produce recommendations.
The algorithm explained in Algorithm 4. is used for ranking the opinions to produce recommendations. Once the opinion class is identified, then the opinions of the class have been selected. For the input and opinion, the method estimates the opinion support measure (OSM). Based on that, the list of opinions is ranked and populated to the user.
|
Algorithm 4: Opinion Ranking Algorithm |
|
Input: Preprocessed data set Pds, OHM matrix ohm, user group Ug. Output: Opinion set Os Start Read ohm, Pds Initialize opinion set Os. For each user in Ug Extract all features from Pds. Us = $\int_{i=1}^{\operatorname{size}(P d s)} \sum P d s(i) . u \operatorname{ser} P d s(i) .$ opinion $=O c$ If Oc ∄Os then Os = Os ∪ Oc End End For each opinion O Compute OSM $=\frac{\text {number of occurrence }(0)}{ {size }(U s)}$ End Sort opinion set according to OSM. Stop |
The proposed opinion hit matrix-based recommendation generation algorithm has been implemented, evaluated for its efficiency in different dimensions. This method has been implemented using advanced Java. The result of the performance analysis has been presented below.
Table 1. Experimental setup
|
Parameter |
Value |
|
Data set |
|
|
Number of tweets |
Two million |
|
Number of opinion class |
20 |
|
Tool used |
Advanced java |
The tweets are collected from the UCI machine repository. The Twitter data set has been web crawled and converted into UCI data set which is an open-source available in the UCI machine learning repository. The data set from the UCI repository has been collected and used for evaluation purposes.
Table 1 reflects the details of the experimental setup to be used for the evaluation of proposed recommendation generation algorithms. The proposed method has been measured for its accuracy in the following factors:
$Precision=\frac{\text { True Positive(TP) }}{\text { True Positive(TP) }+\text { FalsePositive(FP) }}$ (3)
Eq. (3) demonstrates how the performance of the algorithms has been measured towards the recommendation generated. In Eq. (3), precision is the ratio between the number of accurate recommendations generated and the total number of recommendations generated.
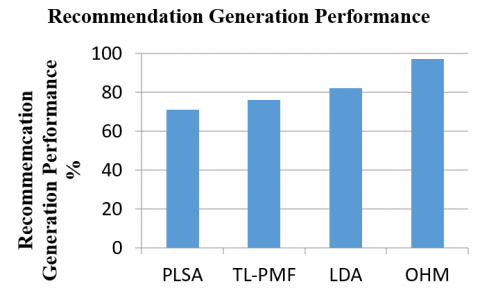
Figure 2 presents the performance results on recommendation generation produced by various methods namely Probabilistic latent semantic analysis (PLSA) [7], Topic and location-aware probabilistic matrix factorization (TL-PMF) [8]) and Latent Dirichlet allocation (LDA) [9] methods are compared with the proposed approach opinion hit matrix. The proposed OHM approach has produced higher recommendation performance than other methods as shown in Figure 2.
Figure 2. Performance on recommendation generation
According to the demonetization tweet, the users have been grouped under three categories like support, against, and neutral. The tweets are grouped under the three categories and the opinions are ranked accordingly. The clustering performance has been measured based on the accuracy of grouping the users under different groups. It has been measured as follows:
Accuracy $=\frac{\text { Number of the correct grouping of users }}{\text { Total number of users grouped }}$ (4)
According to Eq. (4), the user grouping or clustering performance has been measured for different algorithms and presented in Figure 3.
Figure 3. Performance on user clustering
Figure 3 proves that the proposed OHM algorithm has higher clustering performance than any other method.
The relevancy in opinion generation has been measured and presented in Figure 4. The relevancy in opinion generation has been measured based on the Eq. (5).
Opinion relevancy $=\frac{\text { Number of relevant opinions generated }}{\text { Total number of opinion generated }}$ (5)
The ratio is a relevant opinion generation that has been measured and compared with the result of other methods. Obtained results have been presented in Figure 4. The proposed OHM algorithm has achieved higher relevancy than other algorithms.
Figure 4. Performance on opinion relevancy
False Classification Ratio = $\frac{\text { Number of false classification or grouping or identification produced }}{\text { Total number of users considered }} $ (6)
The performance of algorithms in producing false classification has been measured and presented in Figure 5.
Figure 5. Performance on the false classification
The false classification ratio is used to examine the ratio of false identification of user groups and false identification of opinions. The proposed OHM algorithm has achieved a less false ratio compare to other methods as shown in Figure 5.
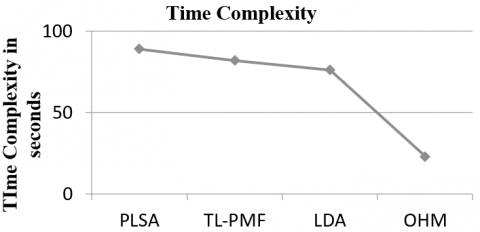
The time complexity of algorithms in generating recommendations has been measured and presented in Figure 6. It has been measured as follows:
Time Complexity = Total amount of time taken for generating results. (7)
The time complexity has been measured for different algorithms and presented in Figure 6.
Figure 6. Performance of time complexity
The result of time complexity measured for different algorithms is presented in Figure 6. The proposed OHM algorithm has achieved less time complexity compared to other methods.
In this paper, the opinion hit matrix-based recommendation generation algorithm in the public event of social networks has been exposed. The method uses the data set obtained from twitter which contains numerous entries of a tweet posted by various social network users. The user interest and user group have been identified according to the value of CLPM estimated. Each opinion of different users in the user group has been measured using opinion support measure OSM. According to the value of OSM, the opinions of various users have been ranked. The ranked opinions are used to generate recommendations to the user concerned. The proposed method improves the performance on recommendation generation up to 96% and reduces the false ratio up to 3% where time complexity has been reduced to O(n).
[1] Liu, X., He, D., Liu, C. (2019). Information diffusion nonlinear dynamics modeling and evolution analysis in online social network based on emergency events. IEEE Transactions on Computational Social Systems, 6(1): 8-19. https://doi.org/10.1109/TCSS.2018.2885127
[2] Meng, Q., Zhang, N., Zhao, X., Li, F., Guan, X. (2016). The governance strategies for public emergencies on social media and their effects: A case study based on the microblog data. Electron Markets, 26: 15-29. https://doi.org/10.1007/s12525-015-0202-1
[3] Yang, B., Mei, T., Hua, X.S., Yang, L.J., Yang, S.Q., Li, M.J. (2007). Online video recommendation based on multimodal fusion and relevance feedback. ACM international conference on Image and video retrieval (CIVR ’07). Association for Computing Machinery, New York, USA, pp. 73-80. https://doi.org/10.1145/1282280.1282290
[4] Zhang, X., Li, Z., Zhu, S., Liang, W. (2016). Detecting spam and promoting campaigns in Twitter. ACM Transactions on the Web, 10(1). https://doi.org/10.1145/2846102
[5] Anandhan, A., Shuib, L., Ismail, M.A., Mujtaba, G. (2018). Social media recommender systems: Review and open research issues. IEEE Access, 6: 15608-15628. https://doi.org/10.1109/ACCESS.2018.2810062
[6] Tang, L., Liu, E.Y. (2017). Joint user-entity representation learning for event recommendation in social network. IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, pp. 271-280. https://doi.org/10.1109/ICDE.2017.86
[7] Chen, C.C., Sun Y.C. (2016). Exploring acquaintances of social network site users for effective social event recommendations. Information Processing Letters, 116(3): 227-236. https://doi.org/10.1016/j.ipl.2015.11.013
[8] Liu, B., Xiong, H. (2013). Point-of-interest recommendation in location-based social networks with topic and location awareness. Proceedings of the 2013 SIAM International Conference on Data Mining, pp. 396-404. https://doi.org/10.1137/1.9781611972832.44
[9] Zhang, Y., Wu, H., Sorathia, V., Prasanna V. (2013). Event recommendation in social networks with linked data enablement. Proceedings of the 15th International Conference on Enterprise Information Systems, ser. ICEIS ’13’, pp. 371-379.
[10] Bogaert, M., Ballings, M., Van den Poel, D. (2016). The added value of Facebook friends data in event attendance prediction. Decision Support System, 82: 26-34. https://doi.org/10.1016/j.dss.2015.11.003
[11] Khrouf, H., Troncy, R. (2013). Hybrid event recommendation using linked data and user diversity. Proceedings of the 7th ACM Conference on Recommender Systems, New York, NY, USA, pp. 185-192. https://doi.org/10.1145/2507157.2507171
[12] Bronson, N., Amsden, Z., Cabrera, G., Chakka, P., Dimov, P., Ding, H., Ferris, J., Giardullo, A., Kulkarni, S., Li, H.C. (2013). Tao: Facebook’s distributed data store for the social graph. USENIX Annual Technical Conference, pp. 49-60.
[13] Gräßer, F., Beckert, S., Küster, D., Schmitt, J., Abraham, S., Malberg, H., Zaunseder, S. (2017). Therapy decision support based on recommender system methods. Journal of Healthcare Engineering, 2017: 8659460. https://doi.org/10.1155/2017/8659460
[14] Tiroshi, A., Kuflik, T., Kay, J., Kummerfeld, B. (2011). Recommender systems, and the social Web. International Conference on Advances in User Modeling, Berlin, Germany, pp. 60-70. https://doi.org/10.1007/978-3-642-28509-7_7
[15] Ricci, F., Semeraro, G., de Gemmis, M., Lops, P. (2012). Decision making and recommendation acceptance issues in recommender systems. Advances in User Modeling. UMAP 2011. Lecture Notes in Computer Science, 7138: 86-91. https://doi.org/10.1007/978-3-642-28509-7_9
[16] Diaby, M., Viennet, E., Launay, T. (2014). Exploration of methodologies to improve job recommender systems on social networks. Social Network Analysis and Mining, 4: 227. https://doi.org/10.1007/s13278-014-0227-z
[17] Song, Y., Zhang, L., Giles, C.L. (2011). Automatic tag recommendation algorithms for social recommender systems. ACM Transactions on Computational Logic, 1-35.
[18] Davoodi, E., Kianmehr, K., Afsharchi, M. (2013). A semantic social network-based expert recommender system. Applied Intelligence, 39: 1-13. https://doi.org/10.1007/s10489-012-0389-1
[19] Ludwig, B., Zenker, B., Schrader, J. (2009). Recommendation of personalized routes with public transport connections. Intelligent Interactive Assistance and Mobile Multimedia Computing, pp. 97-107. https://doi.org/10.1007/978-3-642-10263-9_9
[20] Moore, K.M., Papadomanolakis-Pakis, N., Hansen-Taugher, A., Guan, T.H., Schwartz, B., Stewart, P., Leece, P., Bochenek, R. (2017). Recommendations for action: A community meeting in preparation for a mass-casualty opioid overdose event in Southeastern Ontario, BMC Proceeding, 11(7): 8. https://doi.org/10.1186/s12919-017-0076-7
[21] Smirnov, A., Kashevnik, A., Ponomarev, A., Shilov, N., Teslya, N. (2014). Proactive recommendation system for m-tourism application. Perspectives in Business Informatics Research. Lecture Notes in Business Information Processing, pp. 113-127 https://doi.org/10.1007/978-3-319-11370-8_9
[22] Macedo, A.Q., Marinho, L.B., Santos, R.L. (2015). Context-aware event recommendation in event-based social networks. Proceedings of the 9th ACM Conference on Recommender Systems, pp. 123-130. https://doi.org/10.1145/2792838.2800187
[23] Daly, E.M., Geyer, W. (2011). Effective event discovery: Using location and social information for scoping event recommendations. Proceedings of the Fifth ACM Conference on Recommender Systems, pp. 277-280. https://doi.org/10.1145/2043932.2043982
[24] Fleder, D., Hosanagar, K. (2009). Blockbuster culture's next rise or fall: The impact of recommender systems on sales diversity. Management Science, 55(5): 697-712. https://doi.org/10.1287/mnsc.1080.0974
[25] Aivazoglou, M., Roussos, A.O., Margaris, D., Costas, V., Sotiris, I., Jason, P., Dimitris, S. (2019). A fine-grained social network recommender system. Social Network Analysis Mining, 10: 8. https://doi.org/10.1007/s13278-019-0621-7
[26] Ravi, L., Vairavasundaram, S. (2016). A collaborative location based travel recommendation system through enhanced rating prediction for the group of users. Computational Intelligence and Neuroscience, 2016: 1291358. https://doi.org/10.1155/2016/1291358
[27] Garcia, A., Vansteenwegen, P., Arbelaitz, O., Souffriau, W., Linaza, M.T. (2013). Integrating public transportation in personalized electronic tourist guides. Computers & Operations Research, 40(3): 758-774. https://doi.org/10.1016/j.cor.2011.03.020
[28] Lucas, J.P., Luz, N., Moreno, M.N., Anacleto, R., Figueiredo, A.A., Martins, C. (2013). A hybrid recommendation approach for a tourism system. Expert Systems with Applications, 40(9): 3532-3550. https://doi.org/10.1016/j.eswa.2012.12.061
[29] Huang, Y., Bian, L. (2009). A Bayesian network and analytic hierarchy process based personalized recommendations for tourist attractions over the Internet. Expert Systems with Applications, 36(1): 933-943. https://doi.org/10.1016/j.eswa.2007.10.019
[30] Garcia, I., Sebastià, L., Onaindia E. (2011). On the design of individual and group recommender systems for tourism. Expert Systems with Applications, 38(6): 7683-7692. https://doi.org/10.1016/j.eswa.2010.12.143
[31] Wang, X.S., Su, L., Zhou, Q.H., Wu, L.P. (2020). Group recommender systems based on member’s preference for trusted social networks. Security and Communication Networks, 2020: 1924140. https://doi.org/10.1155/2020/1924140
[32] Manoharan, S., Senthilkumar, R. (2020). An intelligent fuzzy rule-based personalized news recommendation using social media mining. Computational Intelligence and Neuroscience, 2020: 3791541. https://doi.org/10.1155/2020/3791541
[33] Sun, Q., Li, Y., Hu, H., Cheng, S. (2019). A model for competing information diffusion in social networks. IEEE Access, 7: 67916-67922. https://doi.org/10.1109/ACCESS.2019.2918812
[34] Zhou, X., Qin, D., Chen, L. Zhang, Y. (2019). Real-time context-aware social media recommendation. The VLDB Journal, 28: 197-219. https://doi.org/10.1007/s00778-018-0524-7
[35] Cheng, W., Ni, X.C., Sun, J.T., Jin, X.M., Kum, H.C., Zhang, X., Wang, W. (2011). Measuring opinion relevance in latent topic space. IEEE Third International Conference on Privacy, Security, Risk, and Trust and IEEE Third International Conference on Social Computing, Boston, MA, pp. 323-330. https://doi.org/10.1109/PASSAT/SocialCom.2011.45