Venkatesulu Dondeti* | Jyostna Devi Bodapati | Shaik Nagur Shareef | Veeranjaneyulu Naralasetti
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
A machine learning model is introduced to recognize the severity level of the Diabetic Retinopathy (DR), a disease observed in the people suffering from diabetes for a long time and is one of the causes of vision loss and blindness. Major objective of this approach is to generate an effective feature representation of the fundus images so that the level of severity can be identified with less effort and using limited number of samples for training. Color fundus images of the retina are collected, preprocessed and deep features are extracted by feeding them to a deep Convolutional Network, Neural Architecture Search Network (NASNet) which searches for the best convolutional layer (or “cell”) in NASNet search space. The representations of retinal images in deep space are given as input to the classification model to get the severity level of the disease. The proposed model is applied on the benchmark APTOS 2019 retinal fundus image dataset to evaluate the performance of the proposed model. Our experimental studies indicate that ⱱ-Support Vector Machine (ⱱ-SVM) when trained using the projected deep features leads to an improvement in accuracy compared to other machine learning models for fundus image classification. In addition, from the experimental studies we understand that deep features from NASNet give better representation compared to the handcrafted features and features obtained using other projections. We observe that deep features transformed using t-distributed stochastic neighbor embedding (t-SNE) gives more discriminative representations of retinal images and help to achieve an accuracy of 77.90%.
Diabetic Retinopathy (DR), Radial Basis Kernel (RBF), Neural Architecture Search Network (NASNet) features, deep features, ⱱ-Support Vector Machine (SVM), t-SNE
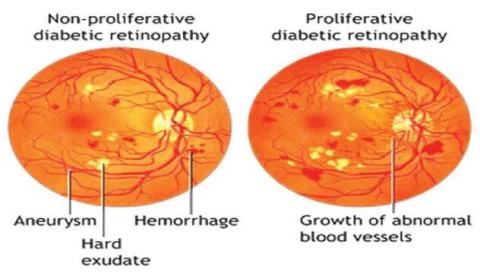
Diabetic Retinopathy (DR) is one of the prevalent diseases found in Asian countries in humans who maintain high blood glucose levels for more than 10 years. Diabetic Mellitus (DM) is a group of metabolic disorders mostly seen in the people who suffer from high blood sugar levels for a long time [1]. As per the statistics [2], DR is the leading cause of global blindness in the recent past. According to a published by WHO in 2013, around 382 million people are suffering from DR and by 2015 this number will increase to 592 million. So, it should be detected in the early stages to prevent blindness. Small lesions are observed in the eyes of affected people which leads to irreversible blindness. Depending on the type of lesion, the severity of the disease varies, including irregular retinal blood vessels, MicroAneurysms (MAs), cotton wool spots, Hard Exudates (HE), and haemorrhages. Figure 1 indicates the types of lesions that could be developed in the eyes of people affected by DR.
DR is not found in all the people with diabetes and is commonly observed in those who suffer from diabetes for more than ten years [3]. Depending on the extent of the disease, DR can be classified into one of the four types: mild (R1), moderate (R1), moderately severe (R2), severe (R2), and proliferative (R3). Micro aneurysms can be observed in the eyes during the early stages of DR. This early stage is known to be mild DR. As the disease progresses to a moderate level, it is possible to experience swelling in the blood vessels that causes blurred vision. Again, extreme stages are graded into Non-Proliferative (NPDR) and Proliferative (PDR). Abnormal growth of blood vessels may be observed during the NPDR stage. This stage is serious due to the severe blockage of blood vessels. In addition to the wide retinal rupture leading to complete vision loss, PDR is the advanced stage of DR retinal detachment that can be observed [4]. Figure 1 shows the retinal samples with different severity levels of DR.
Before the implementation of automation in DR diagnosis tools, the patient’s retinal scan is taken during the treatment of the disease and is manually examined by experts to ascertain if the person is affected by DR. If the patient is affected by DR, further tests must be carried out to determine the extent of the disease. Before the advent of AI and ML algorithms, all this process used to be done manually and it is very helpful to ophthalmologists if the process is automated.
In recent years, several tools have been developed to automate DR detection based on algorithms for machine learning. The first level of DR detection automation focuses on detecting the hard exudates (HE) provided with retinal scan images of diabetic patients. Long [5] has developed a method for automating the HE spots by using SVM and dynamic thresholding methods. An approach that uses a combination of fuzzy C-means and SVM is used to detect HE from the given retinal photographs in question. In addition to detecting HE from the retinal image, the severity level of the disease is also incorporated to make the system more sophisticated [6], SVM based classifiers are adapted to find cotton wool spots on the retinal image.
Figure 1. Sample retinal images effected by diabetic retinopathy representing different types of lesions
Another class of methods focuses on the identification of microaneurysms (MAs) in the retinal images. The presence of MA indicates the severity of the DR disease, a lot of work has been done to identify MA from the given retinal images. Eftekheri [7] has implemented a deep learning-based approach to spot MA in the retinal scan images of diabetic patients.
Van Grinsven et al. [8] suggest another deep learning approach to hemorrhage detection. In their work, they have introduced a sampling method to speed up training of Convolution neural network (CNN) as an application with the aid of DR. Srivastava et al. [9] introduced a bounding box method to identify the region of interest in the retinal image. A deep neural-based method for finding MA is introduced in [10], a max-out activation method is introduced that enhances the efficiency of the model. According to the study [11], among the deep architectures, Neural Architecture Search network (NASNet) outperforms other deep convolution networks.
All current methods for DR use hand-crafted features that are domain dependent. The efficiency of these models depends largely on the knowledge of the domain. We establish a machine learning based approach to identify severity level of DR in diabetic patients by leveraging transfer learning approaches for feature extraction and existing machine learning algorithms for severity level identification. Prominent features of retinal images are obtained in the proposed approach by sending the fundus images via a deep CNN model. Then, to obtain a compact representation of the retinal images, these deep representations are transformed into a different dimensional space. The final representations are transferred to the classification algorithms to obtain the severity levels of DR. NASNet, a pre-trained CNN is used to extract features in the deep space and the directions of projection are obtained using t-SNE. We obtain the most discriminatory features as t-SNE projects the deep features in the most discriminatory directions. As t-SNE projects the deep features in the most discriminatory directions, the proposed produces the most discriminatory features. A machine learning model is trained on these projected features to get the severity level of DR. Our experimental studies on Asia Pacific Tele-Ophthalmology Society (APTOS) 2019 dataset shows that ⱱ-SVM trained using the t-SNE features leads to an improved accuracy of 77.90%.
Our model is different from the existing in the way how the features are provided. As we know, none of the existing models explore the projection of deep features in a lower-dimensional space using t-SNE to get an improved representation of the fundus images. The proposed model produces non-linear features suitable for DR classification.
The principal contributions of the work proposed are as follows:
This paper is organized as follows: Section 2 gives a brief review of various methods used for diabetic retinopathy with special focus on the models that use feature projection techniques; The proposed model is described in Section 3; The dataset used to evaluate the performance of the model along with the discussion on Experimental results is provided in Section4; We give a conclusion with few insights on the future directions at the end of this article.
This section reviews the traditional models for the task of DR severity identification. An easy to remember the scientific approach for DR severity identification has been implemented [12]. Akram et al. [13] introduced a hybrid classifier by using both GMM and SVM as an ensemble model to boost the accuracy of the model. The same approach has been modified by augmenting the feature set with shape, intensity, and statistics of the affected region [14]. A random forest-based solution is proposed in the studies [15, 16]. Segmentation based approaches were proposed by Welikala [17]. A genetic algorithm-based feature extraction method is introduced by Roychowdhury et al. [18]. Numerous shallow Classifiers, such as the Gaussian Mixture Models (GMM), K-Nearest Neighborhood (KNN), Support Vector Machine (SVM), and AdaBoost are analyzed [19] to differentiate lesions from non-lesions. A hybrid feature extraction-based approach has been proposed in the study [20].
Recently the research focus has shifted to deep learning models for the identification of DR severity tasks. A large dataset consisting of 1,28,175 retinal images is used and trained using deep CNN [21]. The data augmentation approach is used to generate data on CNN architecture [22]. Fuzzy models are used as part of their framework [23], a hybrid model based on fuzzy logic, Hough transform, and other techniques for dimension reduction. A mixture of fuzzy C-means and deep CNN architectures are used in the study [24].
Feature reduction plays a significant role in reducing the feature dimensions of the input data while preserving details on discrimination [25]. Principal Component Analysis (PCA) is an unsupervised dimensional reduction technique, in which features are projected in high variance directions. There is a risk of losing class discrimination knowledge when we project the data onto these high variance directions [26]. Linear Discriminant Analysis (LDA) is a supervised dimensional reduction technique that requires class information of the samples and the data can be projected to a maximum of n-1 directions where n is the number of classes. In the case of LDA, the number of directions for projection may not be sufficient, especially when the number of classes is small, and the original feature size is large [27]. Visualization is helpful to understand the nature of data, but it is not possible to visualize data of higher dimensions especially it is not possible to visualize data with more than 3 dimensions.
Figure 2. Architectural details of the proposed system, representing different stages of the proposed method
In the recent past, a non-linear dimension reduction called t-SNE has been widely used to visualize high-dimensional data [28]. It is extensively used in various applications such as facial expression recognition, text classification and tumor identification in Magnetic Resonance (MR) images. In the proposed model we use t-SNE based transformations for reduction of deep features that are huge without loss of class discrimination information. Different from existing methods deep features from retinal images are extracted and then ⱱ-SVM is used for classification. Deep features are projected using t-SNE transformations to enhance the discrimination in the features.
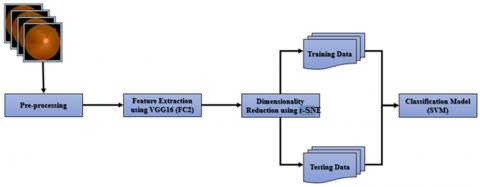
Main objective of this work is to establish a robust model to find the severity of retinopathy given the retinal fundus images as input. As the pre-processing of the images increases the time to generate the result during testing, we avoid too much pre-processing of the retinal images. Rather than applying complex pre-processing steps, we focus on extracting the features that are most appropriate for classification. Figure 2 shows the detailed architecture of the proposed model.
Pre-processing fundus images: All the fundus images collected may not have the same shape but during the next stage, feature extraction module expects all the images in a fixed size. To satisfy this requirement all the fundus images are reshaped so that all the images are of the same size.
Deep Feature extraction: After pre-processing of the images, they are ready to extract features. NASNet, one of the deep convolution architectures, is used to extract deep features of size 4032. Since the number of features in the deep feature space is vast, there is a possibility that the machine learning models will over-fit when we train the models using deep features. t-SNE is used to transform deep features to reduce dimensional space to avoid overfitting of the models.
t-SNE converts the Euclidean distance between the data points in higher dimensional space to conditional probabilities in the lower dimensional space. By doing this t-SNE can retain both local and global structure of the data in the lower dimensional representation.
The conditional probability, P(xj|xi), represents the similarity between the two samples xi and xj in the high dimensional space and is computed as follows:
$P\left(x_{i} \mid x_{j}\right)=\frac{\exp \left(-\frac{-\left|x_{i}-x_{j}\right|^{2}}{2 \sigma^{2}}\right)}{\sum_{k \neq l} \exp \left(-\frac{-\left|x_{k}-x_{l}\right|^{2}}{2 \sigma^{2}}\right)}$ (1)
Let the yi and yj be the samples in the lower dimensional space that are corresponding to data points xi and xj in the higher dimensional space and Q(yj|yi), is then computed as follows:
$Q\left(y_{j} \mid y_{i}\right)=\frac{\left(1+\left|y_{i}-y_{j}\right|^{-1}\right)}{\sum_{k \neq l}\left(1+\left|y_{k}-y_{l}\right|^{-1}\right)}$ (2)
In Eq. (2), Q(yj|yi) represents Student t-distribution with 1-degree of freedom.
The measure of similarity between the joint probability distributions P and Q indicates how well the data points yi and yj model the similarity between the high-dimensional data points xi and xj in lower dimension space and is referred to as symmetric neighborhood embedding. Kullback-Leibler (KL) divergence is a good measure to indicate similarity between the distributions P and Q and the cost function of t-SNE can be formulated as:
$C=K L(P \| Q)=\sum_{i} \sum_{j} P_{j i} \log \frac{P_{j i}}{q_{j i}}$ (3)
This transformation produces mappings that are invariant to changes in the scale in the lower dimensions. Deep features of 4032 dimensions are projected to three dimensions using t-SNE transformation.
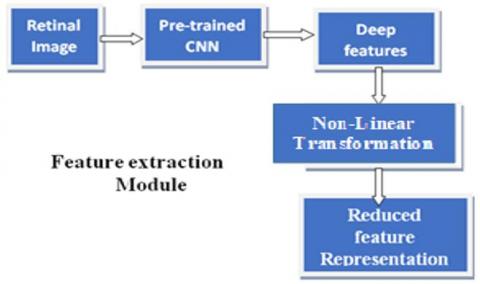
Model training and evaluation module: The features in the reduced space are fed to the classification models for the identification of severity levels in DR. Figure 3 shows the details of the feature extraction module and Figure 4 shows the details of the classification module.
The proposed model uses ⱱ-SVM to classify the retinal images. The advantage of using ⱱ-SVM over the C-SVM for classification is that finalizing the parameters in the case of the ⱱ-SVM is much simpler [29]. In the case of C-SVM, the value of C can take any value from 0 to infinity and can be a bit hard to estimate and use [30]. A modification to the C-SVM objective and the addition of the ⱱ parameter in the objective makes the parameter tuning simple [31]. The value of C can take the values within 0-1 as the search space is much smaller compared to the value of 0 to infinity in the case of C-SVM. The value of ⱱ indicates the lower and upper bounds on the number of data points that lie on the wrong side of the hyperplane.
Figure 3. Stages of non-linear feature projection module
Figure 4. Model training and performance evaluation module
In this section, we address the effectiveness of the proposed model with the supporting experimental results.
Summary of the dataset: For experimental studies, we use APTOS 2019 blindness detection dataset available on the Kaggle website [32] to demonstrate the performance of the proposed model. The dataset is a large array of retinal fundus images under various imaging conditions. The images are manually graded into one of the severity levels. The images were collected over an extended period from several clinics using a range of cameras to add further variations.
The dataset comprises of a total of 3662 retinal images belonging to the affected and unaffected images. Out of the total images 1805 are not affected, there are 370, 999, 193, 295 images are available in mild, moderate, severe and proliferate severity levels among the affected images in each severity level. From each class 80% of the fundus images are used for training and the remaining 20% are used for testing. Table 1 summarizes the dataset used for the model evaluation.
Our initial experiments are carried out to check the effect of hand-crafted features such as Histogram Of oriented Gradients (HoG), Linear Binary Patterns (LBP), and Gist on the classification of DR severity. We use conventional machine learning models such as logistic regression, KNN, Naïve Bayes, C-SVM, and ⱱ-SVM to model the hand-crafted features extracted from retinal images. Different evaluation metrics such as accuracy, precision, recall, and F-scores of the models are reported to assess the performance of the models.
Table 2 shows the performance of various machine learning models trained using hand-crafted features. Table 2 shows that HoG features give a worse performance, while LBP and Gist models are comparable. Gist representations are better with an accuracy of 74.49%, and an F1 score of 70. As a result, we understand that handcrafted features require domain knowledge, and lack of such knowledge results in poor performance. SVM outperforms other models, regardless of the type of features used.
Table 1. Summary of the dataset
|
Dataset Summary |
||
|
Unaffected (No DR) |
1805 |
|
|
Affected (DR) |
Mild DR |
370 |
|
Moderate DR |
999 |
|
|
Severe DR |
193 |
|
|
Proliferative DR |
295 |
|
|
Total |
3662 |
|
Table 2. Performance of various machine learning models trained using handcrafted features
|
Feature type |
Model |
Accuracy |
Precision |
Recall |
F1 Score |
|
HoG |
Logistic Regression |
68.21 |
64 |
68 |
66 |
|
K-NN |
68.08 |
62 |
68 |
62 |
|
|
Naive Bayes |
50.89 |
59 |
51 |
47 |
|
|
Decision Tree |
59.75 |
60 |
60 |
60 |
|
|
C-SVM |
69.58 |
66 |
70 |
67 |
|
|
ⱱ-SVM |
69.58 |
66 |
70 |
67 |
|
|
LBP |
Logistic Regression |
49.52 |
36 |
50 |
38 |
|
K-NN |
71.9 |
66 |
72 |
67 |
|
|
Naive Bayes |
35.06 |
43 |
35 |
35 |
|
|
Decision Tree |
67.8 |
68 |
68 |
68 |
|
|
C-SVM |
70.4 |
66 |
70 |
66 |
|
|
ⱱ-SVM |
73.94 |
74 |
75 |
73 |
|
|
Gist |
Logistic Regression |
60.3 |
57 |
69 |
62 |
|
K-NN |
73.81 |
70 |
74 |
70 |
|
|
Naive Bayes |
49.39 |
65 |
49 |
49 |
|
|
Decision Tree |
64.67 |
65 |
65 |
65 |
|
|
C-SVM |
71.9 |
66 |
72 |
67 |
|
|
ⱱ-SVM |
74.49 |
73 |
74 |
70 |
Table 3. Performance of various machine learning models trained using deep features
|
Model |
Accuracy |
Precision |
Recall |
F1 Score |
|
Logistic Regression |
77.22 |
76 |
77 |
76 |
|
K-NN |
70.12 |
69 |
70 |
66 |
|
Naive Bayes |
59.21 |
66 |
59 |
60 |
|
Decision Tree |
65.08 |
65 |
65 |
65 |
|
C-SVM |
76.94 |
76 |
77 |
76 |
|
ⱱ-SVM |
75.17 |
74 |
75 |
74 |
Table 4. Performance of SVM model trained using features projected on to different spaces
|
Feature space |
Accuracy |
Precision |
Recall |
F1 Score |
|
Deep space |
75.17 |
74 |
75 |
74 |
|
LDA space |
75.17 |
74 |
75 |
74 |
|
PCA space |
77.22 |
76 |
77 |
76 |
|
t-SNE space |
77.90 |
76 |
77 |
75 |
In the next experiment, we compare the performance of deep feature representations extracted using transfer learning. NASNet is used as a pre-trained model to extract the deep features of every retinal image. For each image, we have 4032 features, which are fed to the classification models to get the level of severity. The logistic regularization with C value is set to 4 and L2 regularization is used. In KNN the value of K is set to 10. The decision criteria used in decision tree models is the Gini index. C-SVM is used, with C value as 50, and gamma value is set to 0.001 while in ⱱ-SVM, the value of ⱱ is set to 0.15.
From Table 3, we can see that logistic regression outperforms the rest of the models. The performance of SVM is comparable to logistic regression. Using deep features, the accuracy is increased from 74.49% to 77.22% which is significantly better.
In the next experiment, we will check the performance of deep features projected onto different spaces. For feature projections, we use PCA, LDA, and t-SNE. In all the cases, ⱱ-SVM with RBF kernel is used as a classification model and ⱱ-value is set to 0.15.
From Table 4, we can observe that deep features when projected onto other dimensional spaces can improve the performance of the models. After projection, the performance of the model either improved or did not change without deterioration in accuracy. Projections using t-SNE are superior representations for retinal images.
Figure 5 shows the performance of the DR identification model when the NASNet features are projected onto different feature spaces like LDA, PCA and t-SNE. From the experiments we carried out in this section we understand that the deep features extracted from NASNet offer discriminatory features compared to hand-crafted features. Such features become more discriminatory when the transformation of t-SNE is used to project them.
In support of our arguments, we present the visualizations of features in various projection spaces, such as PCA, LDA, and t-SNE.
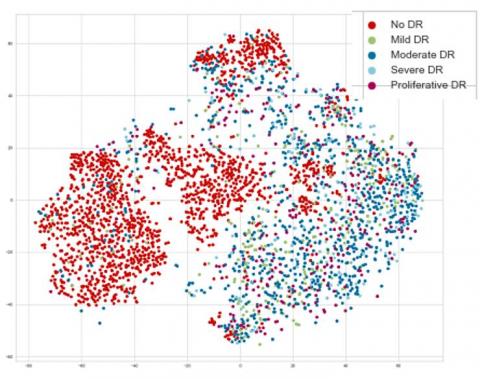
Figure 6 shows that, in 2-D space, the features are discriminatory, especially the DR affected images are well separable from those that are not affected. These features are obtained by setting the number of components as 2, perplexity as 30.0, and using Euclidean as a distance metric.
Figure 5. Accuracy of the DR recognition model after projection onto different spaces
Figure 6. Deep features transformed to two-dimensional space using t-SNE
Major objective of this work is to establish an automated DR severity level prediction model based on the retinal images of diabetic patients. We focus on extracting appropriate features from the retinal images as the feature representations impact the performance of the machine learning models to a greater extent. In this work the deep features extracted from the NASNet are projected onto the t-SNE space to obtain lower dimensional representations. As these features undergone several non-linear operations, they can better learn the lesions present in the retinal images and hence helps to improve the performance of the models. Our experimental studies on the APTOS benchmark dataset show that the proposed features result in better accuracy, precision recall and F1-scores compared to the representations in the PCA and LDA space. The power of deep learning and compact representation together with the robustness of the SVM models, make the proposed approach more powerful with reduced misclassifications.
In future we would like to test the representation power of various deep CNN architectures like GoogLeNet, ResNet and VGG. In addition, we also have plans to test the model performance on large scale datasets.
[1] Sayres, R., Taly, A., Rahimy, E., Blumer, K., Coz, D., Hammel, N., Krause, J., Narayanaswamy, A., Rastegar Z., Wu, D., Xu, S., Barb, S., Joseph, A. Shumski M., Smith, J., Sood, A.B., Corrado, G.S., Peng, L., Webster, D.R. (2019). Using a deep learning algorithm and integrated gradients explanation to assist grading for diabetic retinopathy. Ophthalmology, 126(4): 552-564. https://doi.org/10.1016/j.ophtha.2018.11.016
[2] Flaxman, S.R. (2017). Global causes of blindness and distance vision impairment 1990-2020: A systematic review and meta-analysis. The Lancet Global Health, 5(12): e1221-e1234. https://doi.org/10.1016/S2214-109X(17)30393-5
[3] Gulshan, V., Peng, L., Coram, M. (2016). Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. Jama, 316(22): 2402-2410. https://doi.org/10.1001/jama.2016.17216
[4] Williams, R., Airey, M., Baxter, H., Forrester, J., Kennedy-Martin, T., Girach, A. (2004). Epidemiology of diabetic retinopathy and macular oedema: A systematic review. Eye, 18(10): 963-983. https://doi.org/10.1038/sj.eye.6701476
[5] Long, S.C., Huang, X.X., Chen, Z.Q., Pardhan, S., Zheng, D.C. (2019). Automatic detection of hard exudates in color retinal images using dynamic threshold and SVM classification: Algorithm development and evaluation. Pattern Recognition in Medical Dicision Support, 2019: 3926930. https://doi.org/10.1155/2019/3926930
[6] Haloi, M., Samarendra, D., Rohit S. (2015). A Gaussian scale space approach for exudates detection, classification and severity prediction. arXiv preprint arXiv:1505.00737
[7] Eftekhari, N. (2019). Microaneurysm detection in fundus images using a two-step convolutional neural network. Biomedical Engineering Online, 18(1): 67. https://doi.org/10.1186/s12938-019-0675-9
[8] Van, G., Mark, J.J.P. (2016). Fast convolutional neural network training using selective data sampling: Application to hemorrhage detection in color fundus images. IEEE Transactions on Medical Imaging, 35(5): 1273-1284. https://doi.org/10.1109/TMI.2016.2526689
[9] Srivastava, R. Duan, L., Wong, D.W.K., Liu, J., Wong, T.Y. (2017). Detecting retinal microaneurysms and hemorrhages with robustness to the presence of blood vessels. Computer Methods and Programs in Biomedicine, 138: 83-91. https://doi.org/10.1016/j.cmpb.2016.10.017
[10] Haloi, M. (2015). Improved microaneurysm detection using deep neural networks. arXiv preprint arXiv:1505.04424.
[11] Wu, L., Sauma, J., Hernandez-Bogantes, E., Masis, M.(2013). Classification of diabetic retinopathy and diabetic macular edema. World Journal of Diabetes, 4(6): 290. https://doi.org/10.4239/wjd.v4.i6.290
[12] Akram, M.U., Khan, S.A. (2013). Identification and classification of microaneurysms for early detection of diabetic retinopathy. Pattern Recognition, 46(1): 107-116. https://doi.org/10.1016/j.patcog.2012.07.002
[13] Akram, M.U., Khalid, S., Tariq, A., Khan, S.A., Azam, F. (2014). Detection and classification of retinal lesions for grading of diabetic retinopathy. Computers in Biology and Medicine, 45: 161-171. https://doi.org/10.1016/j.compbiomed.2013.11.014
[14] Casanova, R., Saldana, S., Chew, E.Y., Danis, R.P., Greven, C.M., Ambrosius, W.T. (2014). Application of random forests methods to diabetic retinopathy classification analyses. PLoS One, 9(6): e98587. https://doi.org/10.1371/journal.pone.0098587
[15] Verma, K., Deep, P., Ramakrishnan, A.G. (2011). Detection and classification of diabetic retinopathy using retinal images. 2011 Annual IEEE India Conference, Hyderabad, India, pp. 1-6. https://doi.org/10.1109/INDCON.2011.6139346
[16] Welikala, R.A. (2014). Automated detection of proliferative diabetic retinopathy using a modified line operator and dual classification. Computer Methods and Programs in Biomedicine, 114(3): 247-261. https://doi.org/10.1016/j.cmpb.2014.02.010
[17] Welikala, R.A (2015). Genetic algorithm-based feature selection combined with dual classification for the automated detection of proliferative diabetic retinopathy. Computerized Medical Imaging and Graphics, 43: 64-77. https://doi.org/10.1016/j.compmedimag.2015.03.003
[18] Roychowdhury, S., Koozekanani, D.D., Parhi, K.K. (2013). DREAM: Diabetic retinopathy analysis using machine learning. IEEE Journal of Biomedical and Health Informatics, 18(5): 1717-1728. https://doi.org/10.1109/JBHI.2013.2294635
[19] Mookiah, M.R.K. Acharya, U.R., Martis, R.J., Chua, C.K. (2013). Evolutionary algorithm-based classifier parameter tuning for automatic diabetic retinopathy grading: A hybrid feature extraction approach. Knowledge-Based Systems, 39: 9-22. https://doi.org/10.1016/j.knosys.2012.09.008
[20] Bodapati, J.D., Naralasetti, V., Shareef, S.N., Hakak, S. Bilal, M., Maddikunta, P.K.R., Jo, O. (2020). Blended multi-modal deep ConvNet features for diabetic retinopathy severity prediction. Electronics, 9(6): 914. https://doi.org/10.3390/electronics9060914
[21] Pratt, H. (2016). Convolutional neural networks for diabetic retinopathy. Procedia Computer Science, 90: 200-205. https://doi.org/10.1016/j.procs.2016.07.014
[22] Rahim, S.S., Palade, V., Shuttleworth, J., Jayne, C. (2016). Automatic screening and classification of diabetic retinopathy and maculopathy using fuzzy image processing. Brain Informatics, 3(4): 249-267. https://doi.org/10.1007/s40708-016-0045-3
[23] Dutta, S. (2018). Classification of diabetic retinopathy images by using deep learning models. International Journal of Grid and Distributed Computing, 11(1): 89-106. http://dx.doi.org/10.14257/ijgdc.2018.11.1.09
[24] Laurens van der, M., Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 2579-2605.
[25] Bianco, S., Cadene, R., Celona, L., Napoletano, P. (2018). Benchmark analysis of representative deep neural network architectures. IEEE Access, 6: 64270-64277. https://doi.org/10.1109/ACCESS.2018.2877890
[26] Bodapati, J.D., Naralasetti, V. (2019). Feature extraction and classification using deep convolutional neural networks. Journal of Cyber Security and Mobility, 8(2): 261-276. https://doi.org/10.13052/jcsm2245-1439.825
[27] Bodapati, J.D., Kishore, K.V.K., Veeranjaneyulu, N. (2010). An intelligent authentication system using wavelet fusion of K-PCA, R-LDA. International Conference On Communication Control And Computing Technologies, Ramanathapuram, India, pp. 437-441. https://doi.org/10.1109/ICCCCT.2010.5670591
[28] Bodapati, J.D., Veeranjaneyulu, N. (2016). Performance of different models in non-linear subspace. 2016 International Conference on Signal and Information Processing (IConSIP), Vishnupuri, pp. 1-4. https://doi.org/10.1109/ICONSIP.2016.7857483
[29] Bodapati, J.D., Veeranjaneyulu, N. (2017). Abnormal network traffic detection using support vector data description. Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications, Singapore. https://doi.org/10.1007/978-981-10-3153-3_49
[30] Bodapati, J.D., Naralasetti, V. (2019). Facial emotion recognition using deep CNN based features. International Journal of Innovative Technology and Exploring Engineering, 8(7): 1928-1931.
[31] Kaggle, APTOS Challenge Dataset. https://www.kaggle.com/c/aptos2019-blindness-detection, accessed on Dec. 30, 2019.
[32] Deepika, Kancherla, Jyostna Devi Bodapati, and Ravu Krishna Srihitha. (2019). An efficient automatic brain tumor classification using LBP features and SVM-based classifier. Proceedings of International Conference on Computational Intelligence and Data Engineering, Singapore, pp. 163-170. https://doi.org/10.1007/978-981-13-6459-4_17