Lakshmi Tulasi Ravulapalli*![]() | Rama Krishna Paladugu
| Rama Krishna Paladugu![]() | Venkata Krishna Rao Likki
| Venkata Krishna Rao Likki![]() | Radha Mothukuri
| Radha Mothukuri![]() | Naveen Mukkapati
| Naveen Mukkapati![]() | Srikanth Kilaru
| Srikanth Kilaru![]()
© 2023 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Heart disease persistently remains a paramount health concern globally, necessitating early and precise detection for effective therapeutic intervention, particularly within the realm of cardiology. This study proposes a predictive model for heart failure, utilizing six distinct machine learning classification algorithms—Stochastic Gradient Descent (SGD), Logistic Regression (LR), Decision Tree (DT), AdaBoost, Support Vector Machine (SVM), and Random Forest (RF)—and assesses their performance on an imbalanced heart failure clinical record dataset obtained from Kaggle. Consisting of 299 observations, the dataset comprises 32.11% of instances resulting in death and 67.89% marking recovery or survival, thereby presenting a significant imbalance. This imbalance potentially contributes to a suboptimal prediction of the non-death instances. To address this issue, the Synthetic Minority Oversampling Technique (SMOTE) is employed. The performance of each classifier is evaluated using measures such as accuracy, precision, recall, and F-score. Experiments are conducted on the complete feature set and a selected subset of features, focusing particularly on highly correlated features. The results from these experiments are then juxtaposed with those derived using the comprehensive feature set. The outcome of these comparative analyses reveals superior performance by the RF algorithm over other tree-based and statistical-based models, thereby achieving enhanced accuracy. This study, therefore, presents an in-depth evaluation of machine learning algorithms in predicting heart disease, contributing significantly to the ongoing research in cardiology and machine learning.
CVD, classification techniques, heart failure prediction, relevant features, SMOTE
Over the past two decades, Cardiovascular Disease (CVD), also known as heart disease, has emerged as the leading cause of death globally, claiming more lives annually than any other disease. The term "Cardiovascular Disease" encompasses a range of heart and circulatory system disorders. As the World Health Organization (WHO) reported, Cardiovascular Disease (CVD) was responsible for 17.3 million, or 30% of all global deaths in 2008. Among these, coronary heart disease led to 7.3 million deaths while stroke was responsible for 6.2 million fatalities. The urgent need to tackle this issue underscores the necessity for a system capable of effectively predicting heart failure, potentially saving countless lives.
Key factors such as high blood pressure, cholesterol level, and diabetes are instrumental in detecting heart disease. With the rapid rise in heart disease cases, there is an increasing demand for the incorporation of machine learning techniques for effective decision support. This could help in reducing the increasing prevalence of heart disease by enabling early detection. However, the imbalance between benign and malignant observations in heart failure prediction datasets poses a significant challenge in machine learning-based heart failure prediction.
Heart failure prediction is essentially a binary classification problem, where an observation falls into one of two categories: malignant or benign. However, in real-world scenarios, non-death instances tend to outnumber death instances, resulting in a greater number of benign observations in datasets than malignant ones. This imbalance in the dataset makes it challenging for machine learning algorithms, leading to inaccurate predictions for the minority class (malignant). Because the majority class is learned more frequently by the machine learning algorithm, traditional models tend to predict the majority class (benign) with greater accuracy, resulting in a bias.
To address this issue, this study proposes the development of a system using machine learning that could aid professionals in the early detection of heart disease, thereby reducing the associated risks. Six machine learning models were utilized: Random Forest (RF), Stochastic Gradient Descent (SGD), Decision Tree (DT), AdaBoost, Logistic Regression (LR), and Support Vector Machine (SVM) [1-2].
To address the problem of class imbalance, the Synthetic Minority Over-sampling Technique (SMOTE) was employed. This is a data augmentation technique used in machine learning to balance the differences in instances between classes.
The objectives of this study were as follows:
The structure of this paper is as follows: Section 2 discusses the literature review, Section 3 outlines the dataset and the research methodology used, Section 4 presents the experimental results and their analysis, and Section 5 concludes the paper and discusses future work.
Preliminary analysis of the experimental results indicated that the RandomForest model performed well on both imbalanced and balanced datasets.
2.1 Preliminary concepts
2.1.1 Machine learning: A synopsis
Machine learning, a subset of artificial intelligence, operates on three fundamental learning paradigms: supervised, unsupervised, and reinforcement.
In supervised learning, often referred to as predictive learning, information related to the class labels is provided a priori. This allows a machine to predict the class of unknown objects. This paradigm is further divided into classification and regression, with various techniques like Naïve Bayes, k-NN, decision trees, and SVM applied to numerous machine learning problems.
Contrarily, unsupervised learning does not rely on labeled data. Instead, it evaluates unclassified and unlabeled data to unearth hidden knowledge. This process aids the machine in identifying patterns, groupings, and various intriguing knowledge processes.
These machine learning paradigms have been applied to heart failure classification by numerous researchers. Some researchers used data mining and Map Reduce algorithms [3-6]. Some of the researchers applied various machine learning algorithms to create a predictive model for heart failure classification [7-12]. This section highlights some of the key studies and their limitations in the context of heart failure classification.
2.2 Survey of previous work
Chicco and Jurman [13] proposed a model that utilizes machine learning techniques to predict patient survival based on ejection fraction and serum creatinine alone. They scrutinized a dataset comprising medical records of 299 heart failure patients collated at Faisalabad in 2015.
Tama et al. [14] designed a two-tier ensemble paradigm, employing certain classifiers as the base classifiers and others as the ensemble ones. The class labels predicted by GBM, RF, and XGBoost were amalgamated to create the proposed architecture. The PSO algorithm was utilized for feature selection, and four distinct kinds of datasets were employed for model assessment. Their proposed technique exhibited superior performance in 10-fold cross-validation.
Melillo et al. [15] developed an automated classifier that differentiates between high-risk and low-risk patients. In their study, CART yielded the best results, with a sensitivity and specificity of 93% and 65%, respectively. However, their study only evaluated 34 high-risk patients and 12 low-risk ones. Thus, a larger dataset must be evaluated to ascertain the effectiveness of their proposed methodology.
Parthiban and Srivatsa [16] aimed their research at patients with diabetes-induced heart tissue damage. Using the SVM classifier, they attained an accuracy of 94.60%. However, they did not address the imbalance in the dataset.
Shah et al. [17] proposed a model based on various supervised learning methods such as Naive Bayes, k-NN, and random forest algorithms. They used the Cleveland database of heart disease patients at UCI, utilizing only 14 out of 76 attributes in the dataset for testing. K-nearest neighbor yielded the best accuracy score.
Ambuselvan [18] applied the Naïve Bayes, LR, K-NN, SVM, and RF algorithms to the Cleveland heart dataset from the UCI machine learning repository. The RF outperformed the other algorithms in their experiment involving 303 instances with 14 attributes, out of which eight were categorical and six were numeric.
Repaka et al. [19] applied all machine learning models and classified the results of DT, AdaBoost, RandomForest, LR, SGD, GBM, ETC, GNB, and SVM using all features without SMOTE. Experimental results indicated that the Extra Tree Classifier was superior to the other methods without Synthetic Minority Technique (SMOTE).
Otoom et al. [20] suggested a model based on AdaBoost ensemble methods with Naïve Bayes and ANN for heart disease prediction on three different datasets. Bagging performed well compared to AdaBoost and RF on the Switzerland dataset with 123 instances and the Long Beach dataset with 200 instances. However, on the Statlog dataset, Bagging achieved 83.3% accuracy, slightly outperforming AdaBoost and RF.
Otoom et al. [21] constructed an intelligent classifier capable of detecting heart failure based on clinical data using machine learning techniques. They achieved an accuracy of approximately 85% by applying SVM, Bayes net, and functional tree algorithms on real-time data.
Vembandasamy et al. [22] achieved an accuracy of approximately 86.419% by using the Naive Bayes classifier on the Cleveland heart dataset from the UCI machine learning repository for heart disease detection.
3.1 Dataset used
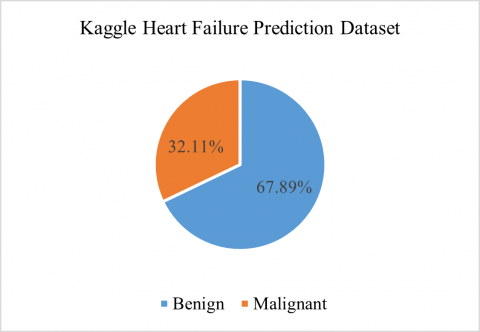
The Kaggle heart failure dataset considered in our work comprises 299 observations and 13 features like Age, Anemia, Diabetes, etc. A list of observations classified as malignant (death) and benign (non-death) can be found in the considered heart failure prediction dataset [23]. Out of the 299 observations, 203 are benign (non-death) and 96 are malignant (death). Figure 1 lists the proportion of malignant and benign records present in the dataset. This indicates 32.11% of the observations consists of death due to heart failure and 67.89% of the observation is non-death due to heart failure. There are no missing feature values in the dataset.
Figure 1. Analysis of the Kaggle heart failure prediction dataset
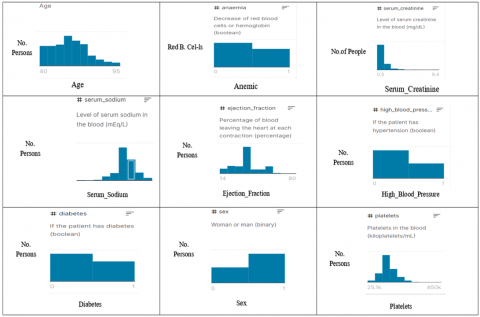
The features of the heart failure dataset are summarized in Table 1. In our experimental work, 70% of the dataset observations are used in training, whereas 30% are used in testing. The heart failure prediction dataset values features are shown in Figure 2, where benign observations are more than malignant observations.
Table 1. Features of Kaggle heart failure prediction dataset
|
S. No |
Feature |
Description |
|
1 |
Age |
Age of a person, Integer |
|
2 |
Anemia |
Anemic/Not anemic, Boolean |
|
3 |
Creatinine phosphokinase |
Creatinine phosphokinase (CPK) is an enzyme in the body, Integer |
|
4 |
Diabetes |
the body’s ability to produce or respond to the hormone insulin is impaired, Boolean |
|
5 |
Ejection Fraction |
Percentage of blood leaving your heart each time it squeezes or contracts, Integer Integer |
|
6 |
High_blood_pressure |
The force of circulating blood on the walls of the arteries, Boolean |
|
7 |
Platelets |
Platelets count in the blood, Integer |
|
8 |
Sex |
Male/Female, Boolean |
|
9 |
Serum Creatinine |
Amount waste product generated by creatinine, Integer |
|
10 |
Serum Sodium |
Sodium levels, Integer |
|
11 |
Smoking |
Smoking, Boolean |
|
12 |
Follow-up Time |
Number of days follow-up the patient, Integer |
|
13 |
DEATH_EVENT |
Class label (0=Benign, 1=Malignant) |
Figure 2. Analysis of the heart failure dataset features
3.2 Classifiers and techniques used
In this work, the proposed model is trained and tested using the heart failure prediction data from the Kaggle repository. We used the Python programming language to implement our algorithms and for testing the results. To identify and summarize the relationship among various classes and features of the observations present in the considered dataset we used the correlation coefficient proposed by Pearson and the results are analyzed. We also used the feature relationship measures to identify and analyze the heart failure data repository. The prediction model is built using a Decision Tree (DT), AdaBoost, Linear Regression (LR), SGD, Support Vector Machine (SVM), and Random Forest (RF) classifiers.
Decision Tree: This can be learned by splitting the source dataset into subsets based on the attributed value test. This can be repeated on each derived dataset in an iterative manner. This can be completed when the subset at a node all has the same value of the target variable.
Adaptive Boosting: We applied the Adaboost algorithm on the decision tree with the initial weight of 1/N to all the data points, where N represents the number of samples. Calculated the Gini Index for all the features. The performance of the stump(α) is calculated using $\frac{1}{2} \log e \frac{1- { TotalError }}{ { TotalError }}$. New weights can be calculated using $NewSampleWeight$ $=$ $OldWeight$ $* e^{ \pm {AmountofSay }(\alpha)\,\,\,\,}$.
Random Forest: This is an extension of the decision tree learning model that combines numerous weak learners to achieve precise predictions. This model trains multiple decision trees with different subsets of samples and the bagging technique. This is obtained by replacing a subset of the training dataset with a sample whose size is equal to that of the training dataset.
Support Vector Machine: It is a method of supervised learning that is based on models from mathematics. It is used for regression and classification. It constructs high-dimensional hyperplanes, also known as decision planes to do categorization.
Linear Regression: It solves classification-related issues.
It is a statistical model and method for predictive analysis based on probability. It is typically applied to binary data analysis, where one or more variables are employed to determine the outcome. It uses a logistic regression sigmoid function to approximate the probability of the association between the categorical dependent variable and one or more independent variables.
Stochastic Gradient Descent: The basic idea behind SGD is to randomly sample a subset of a few records of the training data at each iteration and update the parameters based on the gradient of the loss function with respect to those samples. This helps to make the optimization process more efficient, as it avoids the computational cost of calculating the gradient over the entire training set at each iteration. SGD has been shown to generalize well, even when the training set is noisy or when there is a large number of features
SMOTE (Synthetic Minority Oversampling Technique): It is a technique used in data preprocessing for imbalanced datasets. It involves creating synthetic samples from the minority class by generating new examples that are similar to the existing minority class samples. Synthetic samples are then generated by interpolating between the minority class sample and its k nearest neighbors. The interpolation is performed in feature space, so the new samples are combinations of existing feature vectors, but the values of the features may be altered to create new, plausible examples.
The experimental results and the heart patients’ survival prediction of the proposed model are explained in this section. We first provide the results using the whole set of features, then the results using the relevant set of features. The dataset contains a total of 13 features related to clinical, and lifestyle. Some of these features like high blood pressure, anemia, ejection_fraction, age, serum_creatinine, diabetes, and gender. The target class (Death_Event) in this binary classification task tells whether the patient survived or not. As the given dataset is imbalanced, SMOTE is used to balance it. Now on the obtained dataset, various machine learning models are trained and then assessed the performance. The performance evaluation is done by using the metrics given in the following equations.
The steps followed for the proposed model are:
Step 1: Consider the heart disease clinical records dataset.
Step 2: Apply the SMOTE to balance the dataset.
Step 3: Perform the feature selection.
Step 4: Split the dataset for both training and testing.
Step 5: Apply different machine learning classifiers and validate the data.
Step 6: Predict the result with the test data.
|
Accuracy =$\frac{\text {Number of correctly classified predictions}}{\text{Total Predictions}}$ |
|
Precision =$\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}}$ |
|
Recall =$\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}$ |
|
F-Score =$2 * \frac{\text { precision.recall }}{\text { precision }+ \text { recall }}$ |
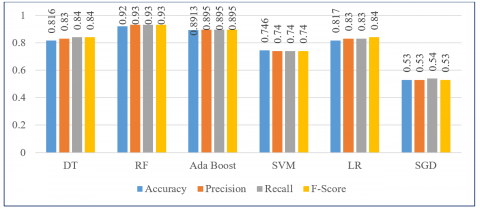
Different supervised machine learning algorithms are applied to heart failure clinical records, initially by considering all the features, the performance of various classifiers is analyzed. It is observed that some methods performed well but some may not. In order to predict heart failure survival, this work employed tree-based, regression-based, and statistical-based models. The DT and RF ensemble models are tree-based. AdaBoost is the tree-based boosting method. The statistical-based method includes SVM, whereas the regression-based methods applied are LR and SGD. The performance assessment of various machine learning classifiers across the full feature set is shown in Table 2.
As per the obtained results, the SGD classifier performed very poorly and gives an accuracy of 0.667, precision of 0.64, 0.68 recall, and 0.65 recall. The decision tree performed better than SGD with 0.779 accuracy. The classifiers LR, Adaboost, and SVM classifiers performed admirably. SVM ranks second among classifiers with an accuracy of 0.8667 and an F-Score of 0.868. Among all six classifiers Random Forest classifier, outperformed which achieved 0.878 accuracy and 0.892 values for precision, recall, and F-Score. Figure 3 gives the graphical representation and the performance comparison of all models when we consider the whole feature set. It shows that Random Forest performed very well out of all the models whereas SGD performed poorly for all the metrics. The DT, SVM, LR, and Adaboost are in decreasing order.
Table 2. Comparison of various machine learning models using the whole feature set without using SMOTE
|
Model |
Accuracy |
Precision |
Recall |
F-Score |
|
DT |
0.779 |
0.802 |
0.8 |
0.8 |
|
RF |
0.878 |
0.892 |
0.892 |
0.892 |
|
Ada Boost |
0.8334 |
0.854 |
0.845 |
0.845 |
|
SVM |
0.875 |
0.879 |
0.879 |
0.868 |
|
LR |
0.856 |
0.84 |
0.85 |
0.84 |
|
SGD |
0.667 |
0.64 |
0.68 |
0.65 |
Figure 3. Performance analysis of classifiers with all features
Figure 4. Performance of various classifiers on the whole set of features using SMOTE
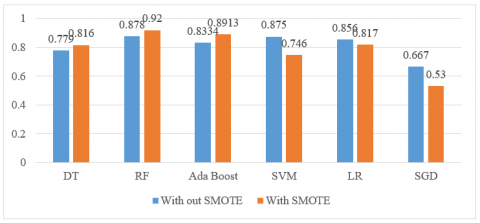
SMOTE is a potent remedy for the class imbalance issue and has shown reliable outcomes across a variety of fields. To create a balanced dataset, the SMOTE method adds fake data to the minority class. Table 3 displays the outcomes of SMOTE-based machine learning classifiers applied to all 13 characteristics in the heart failure record dataset. Table 4 shows that the SMOTE greatly improves the performance of tree-based classifiers.
The performance of the SGD reduced from 0.667 to 0.53. The SVM and LR performed poorly when compared with the results without SMOTE. DT accuracy improved from 0.779 to 0.816 by using SMOTE. AdaBoost exhibited enhanced performance and attained an accuracy of 0.8913, precision of 0.895, recall of 0.895, and F-Score of 0.895 with the balanced dataset. The RF outperformed all the models, achieved 0.92 accuracy and precision, recall, and F-score values of 0.93, and improved results with SMOTE.
Boosting algorithms create trees by minimizing errors made by previously constructed weak learners. Similar data upsampling does not appear to have any effect on the quality of the outcomes. Figure 4 displays the results of a performance evaluation of machine learning models using SMOTE.
Tree-based classifiers like Random Forest performed best with SMOTE to perform heart failure prediction and survival. The performances of all six classifiers with and without SMOTE are given in Figure 5.
Experimental results on more correlated features:
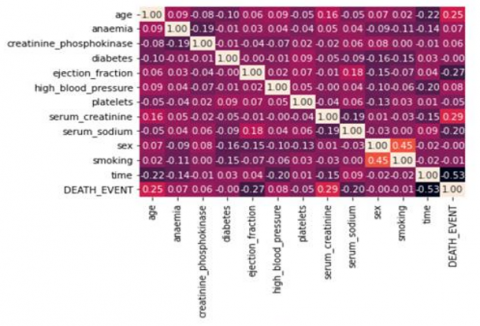
Correlation analysis: conducted a Pearson correlation analysis on the features of the heart failure prediction dataset. This is useful to identify the strongly related features of the data repository. The correlation analysis matrix of the heart failure prediction dataset is shown in the following Figure 6. This shows that heart failure prediction is highly influenced by Sex, serum creatinine, ejection_fraction, and age features.
Table 3. Result of various machine learning algorithms with complete features using SMOTE
|
Model |
Accuracy |
Precision |
Recall |
F-Score |
|
DT |
0.816 |
0.83 |
0.84 |
0.84 |
|
RF |
0.92 |
0.93 |
0.93 |
0.93 |
|
Ada Boost |
0.8913 |
0.895 |
0.895 |
0.895 |
|
SVM |
0.746 |
0.74 |
0.74 |
0.74 |
|
LR |
0.817 |
0.83 |
0.83 |
0.84 |
|
SGD |
0.53 |
0.53 |
0.54 |
0.53 |
Table 4. Performance of various classifiers with and without SMOTE
|
Model |
Without SMOTE |
With SMOTE |
|
DT |
0.779 |
0.816 |
|
RF |
0.878 |
0.92 |
|
Ada Boost |
0.833 |
0.891 |
|
SVM |
0.875 |
0.746 |
|
LR |
0.856 |
0.817 |
|
SGD |
0.667 |
0.53 |
Figure 5. Performance of various algorithms with SMOTE and without SMOTE
Figure 6. Correlation of heart failure features
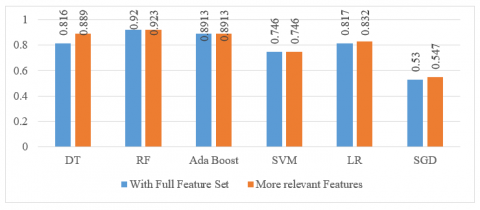
Figure 7. Performance with full set and more relevant features
Table 5. Performance comparison of different classifiers
|
Model |
With full feature set |
More relevant features |
|
DT |
0.816 |
0.889 |
|
RF |
0.92 |
0.923 |
|
Ada Boost |
0.891 |
0.891 |
|
SVM |
0.746 |
0.746 |
|
LR |
0.817 |
0.832 |
|
SGD |
0.53 |
0.547 |
In our research work, the most correlated features selected are investigated by generating a correlation matrix and tested on various machine learning algorithms with SMOTE. Anemia, Sex, Smoking, and Diabetes are removed and tested on the remaining features. The accuracy of the results after removing is given in Table 5. The accuracy of machine learning classifiers with a full set and after removing some of the features is given in Figure 7.
The importance of the heart should not be overemphasized. So, proper care should be taken and prior treatment is required. So that many lives can be saved. On the heart failure prediction dataset taken from the Kaggle repository, we proposed the heart failure prediction model with six classifiers like SVM, Linear Regression, Random Forest, SGD, Decision Tree, and Adaboost algorithms. SMOTE technique is used in the proposed methodology to tackle the problem of biased classification on imbalanced datasets. On the test set, various metrics like accuracy, precision, recall, and F-score are used to evaluate the proposed model's predictive performance before applying the SMOTE on the actual dataset and after applying the SMOTE. The attributes with more correlation are identified using Pearson correlation and predicted based on those correlated attributes with and without applying SMOTE. The limitation of this work is that we considered only the features given in the dataset and applied some traditional and ensembled machine learning techniques for heart failure prediction. In the future, we will extend this work by considering the values obtained through ECG reports along with the given features, and we can apply neural networks for better predictions.
[1] Gudadhe, M., Wankhade, K., Dongre, S. (2010). Decision support system for heart disease based on support vector machine and artificial neural network. In 2010 International Conference on Computer and Communication Technology (ICCCT), Allahabad, India, pp. 741-745. https://doi.org/10.1109/ICCCT.2010.5640377
[2] Kahramanli, H., Allahverdi, N. (2008). Design of a hybrid system for the diabetes and heart diseases. Expert Systems with Applications, 35(1-2): 82-89. https://doi.org/10.1016/j.eswa.2007.06.004
[3] Nagamani, T., Logeswari, S., Gomathy, B. (2019). Heart disease prediction using data mining with mapreduce algorithm. International Journal of Innovative Technology and Exploring Engineering (IJITEE), 8(3): 944-950.
[4] Bou Rjeily, C., Badr, G., Hajjarm El Hassani, A., Andres, E. (2019). Medical data mining for heart diseases and the future of sequential mining in medical field. In: Tsihrintzis, G., Sotiropoulos, D., Jain, L. (eds) Machine Learning Paradigms. Intelligent Systems Reference Library, vol 149. Springer, Cham. https://doi.org/10.1007/978-3-319-94030-4_4
[5] Thomas, J., Princy, R.T. (2016). Human heart disease prediction system using data mining techniques. In 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, pp. 1-5. https://doi.org/10.1109/ICCPCT.2016.7530265
[6] Palaniappan, S., Awang, R. (2008). Intelligent heart disease prediction system using data mining techniques. In 2008 IEEE/ACS International Conference on Computer Systems and Applications, Doha, Qatar, pp. 108-115. https://doi.org/10.1109/AICCSA.2008.4493524
[7] Golande, A., Pavan Kumar, T. (2019). Heart disease prediction using effective machine learning techniques. International Journal of Recent Technology and Engineering, 8(1): 944-950.
[8] Alotaibi, F.S. (2019). Implementation of machine learning model to predict heart failure disease. International Journal of Advanced Computer Science and Applications, 10(6): 261-268.
[9] Alarsan, F.I., Younes, M. (2019). Analysis and classification of heart diseases using heartbeat features and machine learning algorithms. Journal of Big Data, 6(1): 1-15. https://doi.org/10.1186/s40537-019-0244-x
[10] Lutimath, N.M., Chethan, C., Pol, B.S. (2019). Prediction of heart disease using machine learning. International Journal of Recent Technology and Engineering, 8(2S10): 474-477. https://doi.org/10.17577/IJERTV9IS040614
[11] Alzubi, J., Nayyar, A., Kumar, A. (2018). Machine learning from theory to algorithms: An overview. In Journal of Physics: Conference Series, 1142: 012012. https://doi.org/10.1088/1742-6596/1142/1/012012
[12] Weng, S.F., Reps, J., Kai, J., Garibaldi, J.M., Qureshi, N. (2017). Can machine-learning improve cardiovascular risk prediction using routine clinical data? PloS One, 12(4): e0174944. https://doi.org/10.1371/journal.pone.0174944
[13] Chicco, D., Jurman, G. (2020). Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Medical Informatics and Decision Making, 20(1): 1-16. https://doi.org/10.1186/s12911-020-1023-5
[14] Tama, B.A., Im, S., Lee, S. (2020). Improving an intelligent detection system for coronary heart disease using a two-tier classifier ensemble. BioMed Research International, 2020: 9816142. https://doi.org/10.1155/2020/9816142
[15] Melillo, P., De Luca, N., Bracale, M., Pecchia, L. (2013). Classification tree for risk assessment in patients suffering from congestive heart failure via long-term heart rate variability. IEEE Journal of Biomedical and Health Informatics, 17(3): 727-733. https://doi.org/10.1109/JBHI.2013.2244902
[16] Parthiban, G., Srivatsa, S.K. (2012). Applying machine learning methods in diagnosing heart disease for diabetic patients. International Journal of Applied Information Systems, 3(7): 25-30.
[17] Shah, D., Patel, S., Bharti, S.K. (2020). Heart disease prediction using machine learning techniques. SN Computer Science, 1: 345. https://doi.org/10.1007/s42979-020-00365-y
[18] Ambuselvan, P. (2020). Heart disease prediction using machine learning techniques. International Journal of Engineering Research and Technology, 9(11): 515-518. https://doi.org/10.17577/IJERTV9IS110259
[19] Repaka, A.N., Ravikanti, S.D., Franklin, R.G. (2019). Design and implementation heart disease prediction using natives Bayesian. In International conference on trends in electronics and information, pp. 292-297.
[20] Olatunde, Y., Omotosho, L., Akanbi, C. (2019). Comparison of adaboost and bagging ensemble method for prediction of heart disease. Anale. Seria Informatică, 17(1): 268-279.
[21] Otoom, A.F., Abdallah, E.E., Kilani, Y., Kefaye, A., Ashour, M. (2015). Effective diagnosis and monitoring of heart disease. International Journal of Software Engineering and Its Applications, 9(1): 143-156. http://dx.doi.org/10.14257/ijseia.2015.9.1.12
[22] Vembandasamy, K., Sasipriya, R., Deepa, E. (2015). Heart diseases detection using Naive Bayes algorithm. International Journal of Innovative Science, Engineering & Technology, 2(9): 441-444.
[23] UCI, Heart Disease Data Set. (2020). https://www.kaggle.com/datasets/andrewmvd/heart-failure-clinical-data