Zhihua Xu
© 2020 IIETA. This article is published by IIETA and is licensed under the CC BY 4.0 license (http://creativecommons.org/licenses/by/4.0/).
OPEN ACCESS
Thanks to the rapid development of information technology, it is now possible to mine out and fully utilize the valuable information from the big data on talent training quality (TTQ), using artificial intelligence and big data analysis. This paper develops a TTQ prediction model based on random forest (RF)-artificial neural network (ANN), aiming to improve and optimize the TTQ evaluation index system (EIS) in the big data environment, and realize efficient and accurate prediction of TTQ. Firstly, a scientific TTQ EIS was built up, including four primary indies (background evaluation, process evaluation, input evaluation, and result evaluation), and a number of secondary and tertiary indices. Through association matching, a data reconstruction model was constructed for the key evaluation indices of TTQ, the features of the data structure were analyzed, and the key features of each index were extracted and optimized intelligently. Finally, the backpropagation neural network (BPNN) was integrated with the RF algorithm into our prediction model. Experimental results demonstrate the accuracy and effectiveness of the proposed TTQ prediction model. The research findings provide a reference for applying the RF-ANN prediction model in other fields.
random forest (RF), data mining, talent training quality (TTQ), data reconstruction
Talent training quality (TTQ), which determines the employment rate, has always been a social concern. Therefore, most colleges have recently shifted their focus from improving the employment rate of talents to the methods of talent training [1-4]. Traditionally, the TTQ is evaluated against survey data on the expertise and career development of previous graduates. The data are mainly collected by conventional methods like questionnaire survey, interview, seminar, and employer survey. These methods face a variety of inevitable problems: the sample size is generally very small, the collected data are greatly affected by the subjective factors of the respondents, the surveyed items are not sufficiently diverse, and the statistical summary is a heavy work [5-8]. The development of big data technology has made it possible to mine out and fully utilize the valuable information from the massive data related to talent training, namely, occupational psychology test, job information, training plan, social demand, and recruitment, laying a solid basis for TTQ prediction models [9-11].
The prediction results of TTQ directly affect the model of talent training, as well as the philosophy and orientation of college management. The existing studies on TTQ evaluation mainly focus on the construction of evaluation index system (EIS) [11-14]. For example, Bloom [15] set up an EIS for the innovative TTQ in colleges, and compared the EIS with the traditional TTQ EISs, in terms of talent quality features, evaluation principles, subjects, and indices. Luo and Wang [16] combined the context, input, process, and product (CIPP) teaching evaluation model wand the data platform into a TTQ EIS for three-year higher vocational colleges. Drawing on the philosophy of outcome-based education (OBE), Mitrofanova et al. [17] reverse engineered the talent training ideas of engineering colleges, refined the graduation requirements on the talents as per the curriculum standards, and finalized a TTQ evaluation plan based on the graduation requirements, curriculum standards, and the matching matrix between knowledge and skill indices.
The TTQ is affected by factors in various aspects. It is difficult to simulate the intricate relationship between these factors by traditional evaluation and prediction models. The difficulty can be overcome by artificial neural networks (ANNs) [18-23], which have been applied in many fields of education and teaching, such as psychological prediction, performance prediction, and employment quality evaluation. For example, Shi and Xu [24] preprocessed the massive data on talents in China with big data analysis techniques, including machine learning and clustering optimization, and sorted out the evaluation indices for the ability of talents in different specialties. Zhu [25] empirically analyzed the TTQ of the previous graduates from the mechatronics department of a college, created a TTQ prediction model for vocational and technical education based on fuzzy neural network (FNN), and improved the prediction accuracy through data supplementation and grayscale whitening of the equipotential dynamic model.
This paper attempts to improve and optimize the TTQ EIS in the big data environment, and realize scientific prediction of TTQ with the aid of advanced techniques like artificial intelligence, and big data analysis. To this end, a TTQ prediction model was established based on random forest (AF)-ANN. Firstly, a scientific TTQ EIS was built up, including four primary indies (background evaluation, process evaluation, input evaluation, and result evaluation), and a number of secondary and tertiary indices. Through association matching, a data reconstruction model was constructed for the key evaluation indices of TTQ, the features of the data structure were analyzed, and the key features of each index were extracted and optimized intelligently. In this way, the information of the key indices was mined out from the big data, and subject to intelligent learning and training. To improve the efficiency and accuracy of TTQ prediction, the backpropagation neural network (BPNN) was integrated with the RF algorithm into our prediction model. The proposed model was proved accurate and effective through experiments.
To effectively predict the TTQ, it is essential to build a scientific TTQ EIS in the first place. Referring to the existing studies on employment quality system and talent training model, a four-layer TTQ EIS was developed based on the multi-source data on education and teaching resources, job hunting, and recruitment, which evaluates the TTQ with four primary indices, namely, background evaluation, process evaluation, input evaluation, and result evaluation. The four primary indices reflect the goal construction, implementation process, resource allocation, and outcome/performance of the TTQ, respectively. Each primary index covers a number of secondary and tertiary indices. The hierarchical EIS is detailed as follows:
The first layer (TTQ evaluation goal): U={TTQ evaluation results};
The second layer (evaluation items): U={U1, U2, U3, U4}={background evaluation, process evaluation, input evaluation, and result evaluation};
The third layer (secondary indices):
U1={U11, U12, U13}={social recognition, social impact, government input};
U2={U21, U22, U23, U24}={expenditure, course evaluation, college governance, specialty construction};
U3={U31, U32}={college facilities, faculty};
U4={U41, U42, U43}={achievements, graduate development, social satisfaction}.
The fourth layer (tertiary indices):
U11={U111, U112, U113}={college type, number of students, enrollment};
U12={U121, U122, U123, U124}={social service, received awards, radiation effect, quality project };
U13={fund input};
U21={U211, U212, U213}={teaching reform expenditure, daily expenditure, faculty construction expenditure};
U22={course resources}
U23={U231, U232, U233, U234}={administrative staff, teacher management system, talent management system, teaching quality monitoring};
U24={U241, U242, U243}={college-enterprise cooperation, pilot specialties of "1+X certificate" program, specialty construction situation};
U31={U311, U312, U313, U314, U315}={infrastructure, teaching facilities, training base, book resources, informatization};
U32={U321, U322, U323}={team structure, scientific research level, team building };
U41={achievements};
U42={U421, U422}={employment, knowledge and vocational skills};
U43={employer satisfaction}.
3.1 Data reconstruction
The intelligent extraction of key TTQ evaluation indices is to extract the key features of the evaluation indices with artificial intelligence and cloud data processing. The prerequisites for the intelligent extraction include big data mining and intelligent learning and training.
In this paper, the association matching is adopted to build the data reconstruction model of the key TTQ evaluation indices. During the feature extraction of such indices, an autocorrelation function was defined for each feature point:
$r\left( a,b \right)=\sum{_{E}}{{\left[ L\left( {{a}_{i}},{{b}_{i}} \right)-L\left( {{a}_{i}}+\Delta a,{{b}_{i}}+\Delta b \right) \right]}^{2}}$ (1)
where, (Δa, Δb)T is the sampling interval of key TTQ evaluation indices; (ai, bi) is the extreme point of window function E. Then, the feature partitions were accessed frequently to mine out the optimal information from the massive data in the teaching and education resource center, which is the data carrier of the EIS. Through fuzzy C-means (FCM) clustering, the objective function for the classification and query of TTQ evaluation key indicators can be constructed as:
$\begin{align} & p=\underset{y}{\mathop{\max }}\,|\int{u}\left( t \right)\frac{1}{\sqrt{{{x}'}}}{{h}^{*}}\left( \frac{t-y}{{{x}'}} \right)dt|=\underset{y}{\mathop{\max }}\,|{{E}_{h}}\left( {x}',y \right)|, \\ & \text{ }{{W}_{1}}>{{\gamma }_{2}}<{{W}_{0}} \\\end{align}$ (2)
To realize the in-depth mining of the information of key TTQ evaluation indices on each layer, fuzzy feature extraction was adopted to scan the frequent pattern set on each layer of the data reconstruction model.
Inspired by the theory on formal concept analysis (FCA), suppose F1=(O1α, D1β, R1) and F2=(O2α, D2β, R2) are the nodes in the concept lattice set of the feature extraction interval of multi-source talent training data. Then, the data structure of a single index accessing to unified education and teaching resource center satisfies F1⊆F2⇔R1⊆R2. Hence, the big data reconstruction of key TTQ evaluation indices can be expressed as:
$l\left( t \right)=\frac{1}{\sqrt{T}}rect\left( \frac{t}{T} \right){{e}^{-j\left[ 2\pi N\ln \left( 1-\frac{t}{{{t}_{0}}} \right) \right]}}$ (3)
where, rect(t) is a rectangular function (rect(t)=1 and 0.5≤t≤0.5); N=fminfmaxT/B is the mean sampling frequency; t0=f0T/B is the initial sampling time.
On this basis, the intelligent extraction algorithm for key TTQ evaluation indices can be developed through the data reconstruction of key TTQ evaluation indices, coupled with data mining algorithm.
3.2 Feature analysis on data structure
Through association rule mining, this paper mines the data structure features of the big data on key TTQ evaluation indices. Let c be the critical state of the data features in the education and teaching resource center. Then, the big data distribution of key TTQ evaluation indices can be described by the following mathematical model:
$c=f\left( c,l \right)$ (4)
where, l is the nondimensional distributed time series in the standardized data storage model:
$l=\left[ {{l}_{1}},{{l}_{2}},...,{{l}_{N}} \right]$ (5)
Let G(xi, Mj(U)), i=1, 2, …, I, j=1, 2, …, J, be the cluster centers for data association query. Then, the attribute set of the big data on key TTQ evaluation indices can be obtained as:
$c_{j}^{i}=f_{j}^{i}\left( c_{j}^{i},{{l}_{i}},{{l}_{j}} \right){{F}_{3}}=\left( O_{3}^{a},D_{3}^{\beta },{{R}_{3}} \right)$ (6)
According to the power set of the above formula, the feature extraction return parameter c0 of the big data on key TTQ evaluation indices could be obtained. The corresponding distributed nonlinear time series can be expressed as:
$l\left( k,{{t}_{0}} \right)=0,k\in \left[ {{t}_{0}},{{t}_{1}} \right]$ (7)
Through the above analysis, the set of auxiliary information feature set $S=S_{1} \cup S_{2} \cup S_{3}$ was obtained for the key TTQ evaluation indices. The parameters in the feature set can be expressed as:
${{S}_{1}}=\left\{ \left( l,q \right)\in Q\times Q|l\left[ k+t:1 \right]=q\left[ k+t:1 \right],{{l}_{0}}\ne {{q}_{0}} \right\}$ (8)
$\begin{align} & {{S}_{2}}=\{\left( l,q \right)\in Q\times Q|\text{ }l\left[ k+t:t+\text{1} \right]=q\left[ k+t:t+1 \right], \\ & \text{ }W\left( l\left[ t:1 \right],q\left[ t:1 \right] \right)=1,{{l}_{0}}={{q}_{0}}=1\} \\\end{align}$ (9)
3.3 Intelligent extraction and optimization of key indices
After the feature analysis on data structure, the deep learning of multi-source data was carried out through natural language processing, aiming to construct a reasonable intelligent extraction model for key TTQ evaluation indices. Let β be the minimum support threshold for the adjustment of user feedback. Then, the minimum support minSUP can be expressed as:
$\min SUP=\beta \times |C|$ (10)
For any key TTQ evaluation index, the extraction duration Dur can be expressed as:
$Dur=\underset{j=1}{\overset{J}{\mathop{\max }}}\,\left( \sum\limits_{i=1}^{I}{\left( Ext(i),Dis(j) \right)} \right)$ (11)
where, Ext(i) is the extraction task of the i-th key TTQ evaluation index; Dis(j) is the time needed to assign the extraction task to the i-th task processing unit. To improve the adaptability and reduce error of feature extraction, the eigenvalue must meet the following equation:
$C\left( k \right)=1+\frac{\omega {{e}^{-{{U}_{m}}}}}{\left( {{\gamma }_{2}}+{{U}_{m}} \right)k}=0$ (12)
where, ω is the weight coefficient of learning.
4.1 Construction of neural network (NN) model
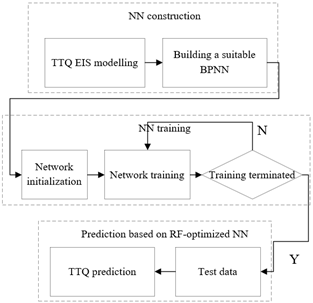
The talents from different specialties differ in knowledge structure and training plan. To train high-level talents, the key TTQ evaluation indices obtained through selective feature extraction must be classified accurately for TTQ prediction. Here, the BPNN is combined with RF algorithm into a TTQ prediction model (Figure 1).
Figure 1. The workflow of RF-ANN TTQ prediction model
The proposed NN has an input layer, three hidden layers, and one output layer. The dimensions of the three kinds of layers are 1,500, 1,300, and 1,000, respectively. Let ωij be the connection weight between the j-th input layer node and the k-th node on the first hidden layer; xij be the j-th eigenvalue of the i-th training data. Then, the linear transform φ2-k of every node on the first hidden layer can be implemented by:
${{\phi }_{\text{2-}k}}=\sum\limits_{j=1}^{M}{{{\omega }_{ij}}\cdot {{x}_{ij}}}+{{\varepsilon }_{k}}$ (13)
where, ԑk is the bias of the k-th node on the first hidden layer. The output data of the second and third hidden layers, and the output layer can be designed similarly as formula (13). To enhance the classification ability of the BPNN model for TTQ prediction results, the sigmoid function was adopted as the activation function:
$Sig\left( {{\phi }_{k}} \right)=\frac{1}{1+{{e}^{-{{\phi }_{k}}}}}$ (14)
The sigmoid function normalizes the results of linear transform. Let yi be the results of linear transform of the i-th output layer node. Then, the output of the output layer can be obtained through softmax regression:
$Soft\left( {{y}_{k}} \right)=\frac{{{e}^{{{y}_{k}}}}}{\sum\limits_{k=1}^{K}{{{e}^{{{y}_{j}}}}}}$ (15)
The results yi of linear transform of the i-th output layer node correspond to the probabilities for the training data of secondary indices to be assigned to one of the four primary indices.
The learning process of the NN relies on the forward transmission of information and the backpropagation of error. For the proposed NN model, the cross-entropy function was adopted as the cost function:
$H\left( X \right)=-\sum\limits_{i=1}^{n}{p\left( {{x}_{i}} \right)\log \left( g\left( {{x}_{i}} \right) \right)}$ (16)
where, p(xi) is the true distribution of training data; g(xi) is the probability distribution after BPNN prediction. For a BPNN with N samples, the total loss can be calculated by:
$Loss=\frac{1}{N}\sum\limits_{i=1}^{N}{\Phi \left( p\left( {{x}_{i}} \right),g\left( {{x}_{i}} \right) \right)}$ (17)
To minimize the loss, the weight and bias of the BPNN must be continuously adjusted. Then, the output of each node should be calculated at the minimum loss. The connection weight ωij and bias ԑk can be respectively updated by:
${{\omega }_{ij}}(t+1)={{\omega }_{ij}}(t)-\frac{\alpha }{N}\sum\limits_{i=1}^{N}{\frac{\partial Loss}{\partial {{\omega }_{ij}}(t)}}$ (18)
${{\varepsilon }_{k}}(t+1)={{\varepsilon }_{k}}(t)-\frac{\alpha }{N}\sum\limits_{i=1}^{N}{\frac{\partial Loss}{\partial {{\varepsilon }_{k}}(t)}}$ (19)
As shown in formulas (18) and (19), the connection weight ωij and bias ԑk can be updated iteratively by finding their partial derivatives relative to the loss function of the training data on each secondary index.
4.2 RF optimization of the NN
The TTQ evaluation aims to select the talent with the best overall quality, based on the results of secondary and tertiary indices. The evaluation is a typical classification of unbalanced dataset.
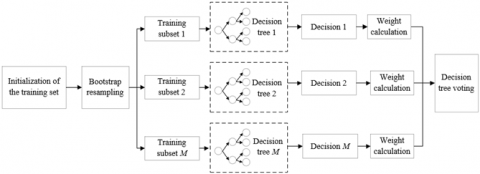
Therefore, it is necessary to reduce the influence of the balance between evaluation indices on different layers over the prediction model, and control the impact of the average voting mechanism on the final classification results. For these purposes, the ranking method was employed to sort and weight the feature importance of indices at different layers, and the F-score algorithm was introduced to compute the weighted harmonic mean of the classifier. Figure 2 explains the workflow of optimizing the BPNN with RF algorithm, which requires data resampling through bootstrapping.
Figure 2. The workflow of optimizing the BPNN with RF algorithm
The original training set on TTQ secondary indices, which contains N samples, was subject to automatic Bootstrap aggregation (bagging). Then, training subsets were created by sample extraction with replacement. The probability of a sample in the training set not being extracted can be calculated by:
${{P}_{nd}}={{\left( 1-\frac{1}{N} \right)}^{N}}$ (20)
If the sample size tends to infinity, the misalignment rate OOBerror of the out-of-bag RF samples for error estimation and feature importance analysis is about 37%. In this paper, the feature importance of an index is computed based on the importance of its data samples (formula 12). The samples with relatively high importance were selected through the following steps:
Step 1. Add a random nose to the eigenvalue C of the data samples of evaluation indices, create an out-of-bag data sample set, and record the out-of-bag error as OOBˊerror. Suppose there are M decision trees in the RF. Then, the importance of eigenvalue C can be computed by:
$I_{C}=\frac{\sum_{i}^{M}\left(O O B_{e r r o r-i}^{\prime}-O O B_{e r r o r-i}\right)}{M}$ (21)
Step 2. Sort the training data on TTQ secondary indices by importance, select the top 70% features, and eliminate the last 30% features.
Step 3. Repeat Steps 1 and 2 until the total number of eigenvalues reaches the preset value, forming the final feature set of TTQ secondary indices.
The F-score algorithm was employed to compute the weighted harmonic average of Precision and Recall. The Precision, Recall, and Accuracy can be respectively calculated by:
$PRE=\frac{{{N}_{H}}}{{{N}_{H}}+{{N}_{error1}}}$ (22)
$REC=\frac{{{N}_{H}}}{{{N}_{H}}+{{N}_{error2}}}$ (23)
$ACC=\frac{{{N}_{H}}+{{N}_{L}}}{{{N}_{L}}+{{N}_{error1}}+{{N}_{H}}+{{N}_{error2}}}$ (24)
where, NH is the number of correct predictions of high-quality talents; NH is the number of correct predictions of low-quality talents; Nerror1 is the number of incorrect predictions of high-quality talents; Nerror2 is the number of incorrect predictions of low-quality talents.
The F-score of the decision trees in the classifier can be calculated by:
$F=\frac{2\times REC\times PRE}{REC+PRE}$ (25)
For verification, the test set on the TTQ secondary indices was imported to each decision tree. Then, the predicted classes of the decision trees were compared with the actual classes.
Two 200 decision trees were set up for the RF-ANN TTQ prediction model. The BPNN parameters were configured as follows: the adjustment speed of connection weight was set to 0.01, and the maximum number of iterations to 1,200.
Figure 3 shows the RF ranking of TTQ secondary indices by feature importance. The last 30% of features in the ranking were removed, forming feature subsets. Each subset was imported to the BPNN prediction model.
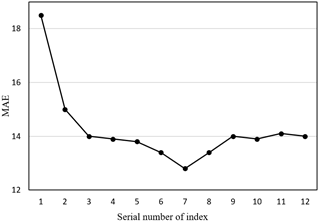
Figure 4 provides the mean absolute error (MAE) between the prediction outputted from each feature subset and the actual value. It can be seen that the MAE first decreased to the minimum and then gradually increased. This means the prediction and classification performance of our model can be improved by removing redundant features, but suppressed by eliminating important features. Therefore, the proposed model can effectively extract features intelligently and recognize their importance.
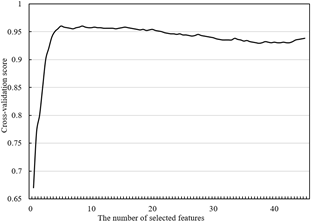
The established TTQ EIS consists of 4 primary indices, 12 secondary indices, and 31 tertiary indices. The key features of each index were extracted intelligently. To verify the RF-optimization of the NN, the redundant features were removed recursively by the RF until the required number of features was reached. The cross-validation score of the optimized NN is displayed in Figure 5.
The established BPNN has three hidden layers. The number of nodes in each hidden layer directly bears on the distributed expression of the index features. Besides, the valuable information might be lost after noise addition. To reveal the effect of the number of hidden layer nodes on the prediction and classification accuracy of our model, the number of hidden layer nodes in the BPNN was adjusted as shown in Table 1. According to the prediction and classification results, the performance of our model was not desirable, when the hidden layers had relatively few nodes. This is manifested by the accuracies in Lines 2-5 of Table 1.
Figure 3. The RF ranking of TTQ secondary indices by feature importance
Figure 4. The MAE trend of our model
Figure 5. The cross-validation score of the RF-optimization of the NN
Table 1. The prediction and classification results at different number of hidden layer nodes
|
Number of hidden layer nodes |
Precision |
Recall |
F-Score |
Accuracy |
TP |
FN |
FP |
TN |
|
{15, 15, 20} |
38.89% |
27.93% |
31.11% |
96.78% |
7 |
21 |
10 |
457 |
|
{18, 18, 15} |
41.18% |
27.93% |
31.82% |
95.99% |
5 |
19 |
11 |
464 |
|
{12, 12, 15} |
87.26% |
35.41% |
13.79% |
92.19% |
3 |
23 |
2 |
474 |
|
{15, 18, 12} |
33.53% |
61.11% |
16.67% |
93.99% |
2 |
25 |
5 |
462 |
|
{18, 15, 12} |
34.33% |
36.41% |
17.12% |
93.19% |
2 |
24 |
5 |
463 |
|
{15, 12, 18} |
78.43% |
17.52% |
19.41% |
93.29% |
4 |
21 |
3 |
478 |
|
{15, 28, 12} |
54.24% |
36.81% |
28.86% |
96.69% |
6 |
22 |
3 |
458 |
|
{18, 25, 15} |
87.50% |
14.81% |
28.86% |
96.51% |
5 |
24 |
5 |
462 |
|
{18, 28, 18} |
34.25% |
19.52% |
27.26% |
97.31% |
6 |
23 |
10 |
453 |
|
{15, 30, 25} |
75.86% |
25.32% |
28.27% |
97.14% |
7 |
20 |
7 |
462 |
Note: TP, FN, FP, and FN are short for true positive, false negative, false positive, and false negative, respectively.
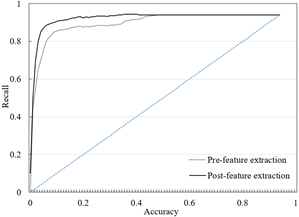
Figure 6. The ROCs before and after the extraction of key features
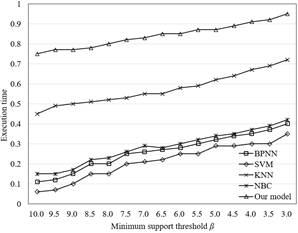
Figure 7. The comparison of execution time
Note: KNN, SVM, CART, and NBC are short for k-nearest neighbors, support vector machine, classification & regression trees, and neighborhood-based clustering, respectively.
Figure 6 presents the receiver operating characteristic (ROC) curves of our model before and after the extraction of key features. The area under the curve (AUC) can reflect the quality of the classifier. As shown in Figure 6, the AUC of the ROC after feature extraction was much larger than that of the original AUC, indicating that the extraction of key features greatly improves the accuracy of our model.
Figure 7 compares the execution time of our model with four other models. Obviously, our model had better real-time performance on TTQ prediction than the contrastive models.
Table 2 compares the prediction and classification effects of our model with the same four models. The results show that the accuracy of our model surpassed 98% on average. Overall, our model achieved high results on Precision, Recall, Accuracy, and F-score, revealing its effectiveness and advantage in TTQ prediction and classification.
Table 2. The comparison of prediction and classification effects
|
Algorithms |
Precision |
Recall |
Accuracy |
F-score |
|
KNN |
92.35% |
97.80% |
97.04% |
96.44% |
|
3-layer BPNN |
94.42% |
86.13% |
90.36% |
87.78% |
|
SVM |
96.62% |
92.80% |
96.20% |
94.67% |
|
CART |
97.39% |
95.39% |
94.39% |
95.33% |
|
NBC |
83.24% |
87.14% |
85.28% |
86.67% |
|
Our method |
98.81% |
98.05% |
98.40% |
97.89% |
This paper mainly puts forward an RF-ANN TTQ prediction model. Firstly, a scientific four-layer hierarchical EIS was established, involving 4 primary indices and numerous secondary and tertiary indices. Through association matching, a data reconstruction model was constructed by key TTQ evaluation indices, followed by the feature analysis of data structure, as well as intelligent extraction and optimization of key features. Experimental results demonstrate that our model can extract key features of evaluation indices accurately, and achieve high robustness, reliability, and generalization ability. To predict TTQ accurately and efficiently, the BPNN was combined with RF algorithm into our prediction model. The proposed model was found to greatly outperform the traditional prediction models through experiments.
This paper was Supported by Program for Chongqing Scholars and Innovative Research Team in University.
[1] Lu, D. (2015). Mobile Internet talent needs and status analysis of mobile Internet personnel training in colleges. Modern Communication, 37(6): 141-146. https://doi.org/10.3969/j.issn.1007-8770.2015.06.029
[2] Verkhova, G.V., Akimov, S.V. (2017). Electronic educational complex for training specialists in the field of technical systems management. 2017 IEEE II International Conference on Control in Technical Systems (CTS), St. Petersburg, pp. 26-29. https://doi.org/10.1109/CTSYS.2017.8109479
[3] Yu, H., Li, T. (2014). Demand research and professional training of China's network and new media talents. Modern Communication, 36(2): 134-138. https://doi.org/10.3969/j.issn.1007-8770.2014.02.028
[4] Tsang, E., Yuen, K., Cheung, P., Yuen, K.S., Lee, K.C. (2014). Effective instructional design for mobile learning. Emerging Modes and Approaches in Open and Flexible Education, 59-80.
[5] Intraraprasit, M., Phanpanya, P., Jinjakam, C. (2017). Cognitive training using immersive virtual reality. 2017 10th Biomedical Engineering International Conference (BMEiCON), Hokkaido, pp. 1-5. https://doi.org/10.1109/BMEiCON.2017.8229126
[6] Zhao, G.L., Mi, J., Ma, K. (2018). Project heuristic course teaching which integrating with engineering ability training under the view of emerging engineering education: A case study of internet of things teaching. Journal of Higher Education, (19): 96-99.
[7] Katkalo, V., D.L. Moehrle, M., Volkov, D. (2017). Corporate Training for the Digital World. Corporate University of Sberbank.
[8] Shi, Y., Yan, Y.P. (2018). Research on talents cultivation mode of new engineering in local high-level universities. The Theory and Practice of Innovation and Entrepreneurship, (19): 96-99.
[9] Seman, Z.A., Ahmad, R., Haron, H.N. (2017). Module intervention for supporting students' problem solving skills in technical vocational education and training. 2017 7th World Engineering Education Forum (WEEF), pp. 197-01. https://doi.org/10.1109/WEEF.2017.8467156
[10] Ivanchenko, A., Kolomiets, A., Grinchenkov, D., Ngon, N. (2016). Optimization of the modular educational program structure. IProceedings of International Conference on Applied Innovation in IT, 4(1): 31-34. https://doi.org/10.13142/KT10004.06
[11] Yao, W.X., Li, S., Wang, W.L., Zhu, L.N. (2019). Curriculum system reform of IoT engineering specialty oriented to international talents training. Computer Education, (2): 82-85. https://doi.org/10.3969/j.issn.1672-5913.2019.02.021
[12] Ng, R.Y.K., Lam, R.Y.S. (2018). Using mobile and flexible technologies to enhance workplace learning in vocational education and training (VET). Innovations in Open and Flexible Education, 85-95. https://doi.org/10.1007/978-981-10-7995-5_8
[13] Ng, R.Y.K., Lam, R.Y.S., Ng, K.K., Lai, I.K.W. (2016). A cross-institutional study of vocational and professional education and training (VPET) students and teachers' needs of innovative pedagogical practices. 2016 International Symposium on Educational Technology (ISET), Beijing, pp. 101-105. https://doi.org/10.1109/ISET.2016.32
[14] Andreev, A.A. (2017). On-line training quality. Electronic Education in Non-stop Education, 1: 340-344.
[15] Bloom, B.S. (1984). The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring. Educational Researcher, 13(6): 4-16. https://doi.org/10.3102/0013189X013006004
[16] Luo, M., Wang, F. (2018). Research on the cultivation of applied undergraduate business and trade talent in Guangdong based on new business form. 2018 2nd International Conference on Management, Education and Social Science (ICMESS 2018), pp. 716-719. https://doi.org/10.2991/icmess-18.2018.158
[17] Mitrofanova, E., Kashtanova, E., Mezhevov, A. (2017). Formation of information system for personnel training. Conference Computer Science and Information Technologies, pp. 459-464.
[18] Zuo, Q.F. (2018). Analysis of the reform in the trinity innovative talents training program in mechanical design, manufacturing and automation under the background of new engineering. Journal of Hezhou University, 34(2): 148-152. https://doi.org/10.3969/j.issn.1673-8861.2018.04.028
[19] Kotova, Y.Y. (2015). Imitation studies of the process of training specialists using blended learning technologies (Blended Learning Technology). Planning and Providing Training for the Industrial-Economic Complex of The Region, 1: 252-258.
[20] Liu, J., Chen, Y.D., Wu, Y., Zhang, Y.Q. (2018). Research on the training mode of new engineering mechanics and electronic engineering. Jiangsu Science & Technology Information, 26: 75-77.
[21] Du, J., Yang, G. (2019). Research on research on training ways of cultivating innovation ability of engineering students under the background of “new engineering”. Journal of Shijiazhuang Tiedao University (Social Science), (2): 106-110.
[22] Zhu, D.J. (2018). Reform research and practice of new engineering talent training mode in local colleges and universities. Mechanical Management and Development, (5): 78-80.
[23] Zhang, Z.H., Zhou, Y.Q., Zhao, X.R., Qu, L.Y. (2018). Analysis and reflection on the idea of "new engineering" and training of china’s engineering majors. Higher Education of Sciences, (5): 94-102, 79. https://doi.org/10.3969/j.issn.1000-4076.2018.05.013
[24] Shi, X.Q., Xu, Y.Y. (2019). The construction of talent cultivation system driven by engineering education accreditation and production-education integration. Research in Higher Education of Engineering, (2): 33-39.
[25] Zhu, P.F. (2016). Research on the training mode of innovative IoT engineering talents - taking Nanjing University of posts and telecommunications as an example. Data of Culture and Education, (11): 120-121, 155. https://doi.org/10.3969/j.issn.1004-8359.2016.11.054