Ruifang Xing | Yayun Fan | Wei Liu*
OPEN ACCESS
Most community detection algorithms for complex networks are focused on nonoverlapping communities. However, there are many overlapping communities in real-world complex networks. To solve the contradiction, this paper develops a novel overlapping community detection algorithm based on Markov chain. First, the input adjacency matrix was expanded to guide the information flow. Then, the inflation operation was implemented to enhance the weakening boundary of communities. After that, an adaptive threshold was introduced to reconstruct the matrix. The network corresponding to the reconstructed matrix displays the overlapping communities in the original network. The proposed algorithm was compared with several popular community detection algorithms on artificial and real-world networks. The results show that our algorithm achieved higher recognition accuracy and faster convergence than the contrastive algorithms.
complex networks, overlapping community detection, Markov chain, random walk
Complex networks are extremely common in the world, ranging from protein interaction, biological organization to food chain. In a complex network, the cluster structure of nodes is known as the community structure [1]. The nodes in the same community are linked closer than those in different communities. It is necessary to fully understanding the cluster structure, before exploring the structure, evolution and predictive control of a complex network.
To analyze a complex network, an important basis is community detection [2], a.k.a. community discovery, which refers to the clustering of network nodes by algorithms. Unlike common clustering algorithms, community detection aims to find communities in the network graph. Community detection can be applied to various fields, including but not limited to knowledge mining, social network recommendation, and traffic flow optimization.
Judging by the formation of communities in complex networks, there are four types of community detections, namely, agglomerative detection, splitting detection, search detection and other detection. Specifically, agglomerative detection constructs the community gradually based on each network node; splitting detection considers all network nodes as a large community, and gradually split the large community into smaller ones; search detection integrates the previous two methods and pursues gradual optimization of the community structure.
Considering the above, this paper develops a novel overlapping community detection algorithm based on Markov chain. First, the input adjacency matrix was expanded and inflated to optimize the information flow and highlight the community boundary. Next, the matrix was normalized to obtain the transition probabilities of its elements. Then, an adaptive threshold was introduced to reconstruct the transition probability matrix. The reconstructed matrix was normalized column by column and used to detect the overlapping communities based on random walk and Markov chain.
The community detection of complex networks is a problem with non-deterministic polynomial-time (NP) hardness [3]. Nonoverlapping community detection provides a way to judge whether a node belongs to a community. The existing nonoverlapping community detection algorithms utilize either topology analysis or flow analysis [4]. The topology analysis assumes that the inner edges of a community are linked tightly but the communities are linked loosely with each other. The basis of topology analysis is graph segmentation, a mature method of graph mining. To find the best partition of the graph, Borkar and Meyn [5] proposed the Oja’s algorithm that optimizes the gain function and constantly exchanges the node pairs in different preset communities. Chen et al. [6] segmented the graph with preset parameters through intelligent optimization. Newman and Girvan [7] developed the Girvan–Newman (GN) algorithm for community division, which measures the edge importance or node pair similarity based on the centrality of intermediate number. Newman and Girvan [8] also put forward a fast algorithm for detecting community structure in networks, in which communities are merged in the direction of maximum modular increment. Both the GN and the fast algorithm divides the hierarchical tree with the objective function of maximum modularity. Ashrafi Payaman and Kangavari [9] mapped the geodesic distance of network node pair to high-dimensional space and performed sparse linear coding to achieve spectral clustering. Jarukasemratana et al. [10] judged the number of communities by node distance and density. Zhou et al. [11] realized community detection in the light of the density reachable between core nodes.
Overlapping community detection is a strategy to evaluate whether a node can be allocated to more than one community. Zhang et al. [12] presented an algorithm based on the well-known clique percolation method (CPM), which looks for overlapping communities using the clique overlap matrix. Shahmoradi et al. [13] presented a new definition for multilayer community and a comprehensive definition for overlapping multilayer community. Mirzaei et al. [14] introduced Non-negative Tensor Factorization (NTF) methods to identify the overlapping communities in brain networks using resting-state functional Magnetic Resonance Imaging (rs-fMRI) data. Zhang et al. [15] generated the hierarchical tree through maximum clustering, divided the tree by the extended module degree, and then searched for the overlapping and hierarchical communities. Jonnalagaddaa et al. [16] greedy community detection algorithm to disclose the underlying community structure of the given network. Huang et al. [17] used ant colony optimization (ACO) to detect overlapping communities in the network. Chen et al. [18] extended the GN algorithm by using nodes with high intermediate number in split network, and thus realized the detection of overlapping communities. Ding and Fu [19] transformed network nodes into points in Euclidean space, and performed fuzzy clustering in complex networks, using fuzzy C-means (FCM) algorithm. In search of overlapping communities, Binesh and Rezghi [20] created a fuzzy clustering algorithm based on nonnegative matrix decomposition. Li et al. [21] locally extended spectral clustering for overlapping community detection. Based on the mixed probability model, Ngonmang et al. [22] set up an overlapping community detection algorithm, capable of identifying the community structure with the maximum expectation. Wu et al. [23] detected overlapping communities in social network through label propagation. Zhang et al. [24] performed community detection by measuring node importance and adopting the seed expansion method.
3.1 Markov clustering (MCL) algorithm
The MCL [25] is a graph clustering method based on random walk and Markov chain. It is assumed that any walker that randomly enters a community is very unlikely to leave that community.
In the MCL, the random walk is essentially a process of changing the transition probability matrix of the Markov chain through expansion and inflation. The expansion operation is the limit distribution of the transition probability matrix. During the operation, the matrix is multiplied continuously to reach a stable state, that is, the information flows evenly in different regions of the network.
Meanwhile, the inflation operation is to perform power multiplication on each element of the matrix and then normalize the elements column by column. In this way, the strong correlations between the elements become stronger, and the weak ones become weaker. In other words, the information flows toward the attractor.
Through the alternation between the two operations, more and more information flows to the attractor, leading to the state convergence of transition probability matrix.
The basic process of MCL algorithm is as follows:
|
MCL algorithm |
|
Input: Undirected and unweighted network G (V, E), expansion parameter e, and inflation parameter i. Output: Community structure in the complex network. |
|
1. Add self-loop: Set the diagonal of adjacency matrix to 1. 2. Normalize the matrix: Normalize the matrix column by column. 3. Perform expansion: Calculate the e power of the matrix. 4. Perform inflation: Calculate the power r for every element of the matrix. 5. Repeat (3) and (4) until the state convergence of the matrix. 6. Output the result: Convert the resulting matrix to clustering. |
The MCL algorithm is suitable for weighted graphs, without needing the number of network communities. However, it cannot be directly applied to detect overlapping communities in large diameter networks.
To solve the problem, this paper reconstructs the transition probability matrix with an adaptive threshold, normalizes the reconstructed matrix column by column, and then adopts the normalized matrix to detect the overlapping communities based on random walk and Markov chain. The reconstructed transition probability matrix represents the complete graph, in which each overlapping node is displayed in its corresponding community. In other words, our approach ensures that the same community node has the same nonzero element position, rather than determine the nonoverlapping communities based on the nonzero element positions in the rows of the matrix.
3.2 Improved MCL based on random walk
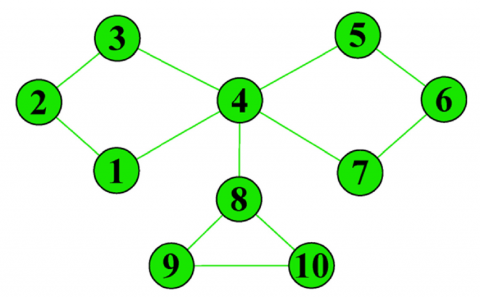
To improve the MCL, the first step is to clearly define the random walk. As shown in Figure 1, the random walk is a process that a walker randomly moves from the starting point in a graph to any neighboring node. Then, the neighboring node becomes the new starting point for the next random movement. The random walk can be illustrated as a transition probability matrix, in which each element represents the state transition probability from row node i to column node j, and the total probability of each row adds up to one.
The transition probability matrix for the random walk in Figure 1 can be expressed as:
$P_{i j}=\left[\begin{array}{cccccc}{0} & {\frac{1}{2}} & {0} & {\frac{1}{2}} & {0} & {0} & {0}& {0} & {0} & {0} \\ {\frac{1}{2}} & {0} & {\frac{1}{2}} & {0} & {0}& {0} & {0} & {0} & {0} & {0}\\ {0} & {\frac{1}{2}} & {0} & {\frac{1}{2}} & {0} & {0}& {0} & {0} & {0} & {0} \\ {\frac{1}{5}} & {0} & {\frac{1}{5}} & {0} & {\frac{1}{5}} & {0}& {\frac{1}{5}}& {\frac{1}{5}} & {0}& {0} \\ {0} & {0} & {0} & {\frac{1}{2}} & {0} & {\frac{1}{2}} & {0}& {0}& {0} & {0} \\ {0} & {0} & {0} & {0}& {\frac{1}{2}} & {0}& {\frac{1}{2}} & {0} & {0} & {0} \\ {0} & {0} & {0} & {\frac{1}{2}} & {0} & {\frac{1}{2}} & {0}& {0}& {0} & {0} \\ {0} & {0} & {0} & {0} & {\frac{1}{3}}& {0}& {0} & {0} & {\frac{1}{3}} & {\frac{1}{3}}\\ {0} & {0}& {0} & {0} & {0} & {0} & {0} & {\frac{1}{2}} & {0} & {\frac{1}{2}} \\ {0} & {0}& {0} & {0} & {0} & {0} & {0} & {\frac{1}{2}} & {0} & {\frac{1}{2}}\end{array}\right]$
Figure 1. An example of random walk
As shown in Figure 1 and the above matrix, a random walker at node 2 will move to node 3 or node 1 at the probability of 50%. The probability for him/her to move to any other node is 0. If the walker is at node 4, he/she will move to nodes 1, 3, 5, 7 or 8 at the probability of 20%. The probability for him/her to move to any other node is 0.
The next step is to clearly understand the Markov chain. The Markov chain is a stochastic process that satisfies the Markov property. The state of Markov chain at any moment only depends on that at the previous moment. Therefore, the future state is only related to the current state, rather than the past state, i.e. the past and the future states are independent of each other. The Markov property can be defined as:
$P\left(X_{t+1}=x | X_{1}=x_{1}, X_{2}=x_{2}, \ldots, X_{t}=x_{t}\right)=P\left(X_{t+1}=\right.\left.x | X_{t}=x_{t}\right)$ (1)
In actual practice, the input adjacency matrix cannot be directly used for expansion and inflation. Here, a self-loop is added to eliminate the influence of even and odd power on random walk. Besides, the nonzero matrix was normalized to determine the probability for a node by column number to transform into a node represented by row number.
The transition probability matrix thus obtained was expanded by e power. Then, each element in the matrix was inflated by r power. The expansion helps to complete the random walk, such as to spread the information carried by the network flow to the distance. The inflation attempts to enhance the intra-cluster correlation, and weaken the inter-cluster correlation, enabling the communities to separate from the network automatically.
If the matrix is directly normalized after expansion and inflation, the influence of overlapping nodes will be ignored. In fact, overlapping nodes with a large degree may act as attractors and affect community detection results. Therefore, a new network graph was generated by reconstructing the adjacency matrix through adaptive thresholding:
$e_{i j}=\left\{\begin{array}{ll}{1} & {e_{i j}>\operatorname{mean}(e)} \\ {0} & {e_{i j} \leq \operatorname{mean}(e)}\end{array}\right.$ (2)
After matrix reconstruction, the community structure in the network become clearer, and the community boundary become more obvious.
The final matrix was obtained through iterations until reaching the convergence state: the reconstructed matrices before and after the current iteration are consistent with each other. The final matrix is a 0-1 symmetric block matrix, which implies the community structure of the network. This matrix can be interpreted as follows:
The node represented by the row number of any diagonal nonzero element belongs to the same community as the node represented by the column number of other nonzero elements in the row vector.
If the community of the node represented by the column numbers of other non-zero elements in the row vector is not unique, the node belongs to different communities, that is, the node is an overlapping node.
If the other elements in the row vector are all zeros, then the node is an outlier.
Therefore, the final matrix obtained by our algorithm clearly reflects the partition of overlapping nodes. The vector of overlapping nodes in the matrix can be decomposed into the vector form of their communities.
3.3 Algorithm instance
From the network structure of Figure 1, the adjacency matrix of the network can be obtained as:
$\left[\begin{array}{llllllllll}{0} & {1} & {0} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {0} & {1} & {0} & {0} & {0} & {0} & {0} & {0} & {0} \\ {0} & {1} & {0} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {0} & {1} & {0} & {1} & {0} & {1} & {1} & {0} & {0} \\ {0} & {0} & {0} & {1} & {0} & {1} & {0} & {0} & {0} & {0} \\ {0} & {0} & {0} & {0} & {1} & {0} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {0} & {1} & {0} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {0} & {0} & {0} & {0} & {1} & {1} \\ {0} & {0} & {0} & {0} & {0} & {0} & {0} & {1} & {0} & {1} \\ {0} & {0} & {0} & {0} & {0} & {0} & {0} & {1} & {1} & {0}\end{array}\right]$
After setting the diagonal element of the adjacency matrix to 1, it is assumed that a node can stay in the local area with a certain probability without moving. For simplicity, the matrix is normalized column by column so that the sum of transition probabilities of any column is 1. Through normalization, the transition probability matrix can be obtained as:
$\left[\begin{array}{ccccccc}{\frac{1}{3}} & {\frac{1}{3}} & {0} & {\frac{1}{6}} & {0} & {0} & {0} & {0} & {0} & {0}\\ {\frac{1}{3}} & {\frac{1}{3}} & {\frac{1}{3}} & {0} & {0} & {0} & {0} & {0} & {0} & {0}\\ {0} & {\frac{1}{3}} & {\frac{1}{3}} & {\frac{1}{6}}& {\frac{1}{3}} & {0} & {0} & {0}& {0} & {0} \\ {\frac{1}{3}} & {0} & {\frac{1}{3}} & {\frac{1}{6}}& {0}& {\frac{1}{3}} & {\frac{1}{4}} & {0} & {0} & {0} \\ {0} & {0} & {0} & {\frac{1}{6}} &{\frac{1}{3}} & {\frac{1}{3}}& {0} & {0} & {0} & {0} \\ {0} & {0}& {0} & {0} & {\frac{1}{3}} & {\frac{1}{3}} & {\frac{1}{3}} & {0} & {0} & {0}\\{0}& {0}& {0}& {\frac{1}{6}}& {0}& {\frac{1}{3}}& {\frac{1}{3}}& {0}& {0}& {0} \\ {0} & {0} & {0} & {\frac{1}{6}} & {0} & {0}& {0} & {\frac{1}{4}} & {\frac{1}{3}} & {\frac{1}{3}} \\ {0} & {0} & {0}& {0} & {0} & {0} & {0} & {\frac{1}{4}} & {\frac{1}{3}} & {\frac{1}{3}} \\ {0} & {0} & {0} & {0} & {0}& {0} & {0} & {\frac{1}{4}} & {\frac{1}{3}} & {\frac{1}{3}}\end{array}\right]$
The expansion parameter was set to 2, that is, the random walker only moves by one step in the network. The expansion was carried out by multiplying the transition probability matrix. The inflation parameter was set to 1, indicating that the matrix does not change but directly goes to the reconstruction phase. The reconstructed matrix can be expressed as:
$\left[\begin{array}{lllllllll}{1} & {1} & {1} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {1} & {1} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {1} & {1} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {1} & {1} & {1} & {1} & {1} & {1} & {1} & {0} & {0} \\ {0} & {0} & {0} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {0} & {0} & {0} & {1} & {1} & {1} \\ {0} & {0} & {0} & {0} & {0} & {0} & {0} & {1} & {1} & {1} \\ {0} & {0} & {0} & {0} & {0}& {0} & {0} & {1} & {1} & {1}\end{array}\right]$
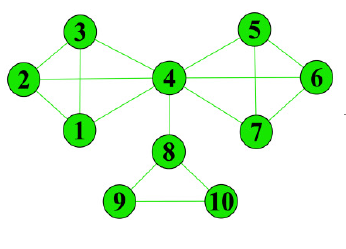
Figure 2. Reconstructed network structure
The mean of all elements of the reconstructed matrix was taken as the adaptive threshold, and used to compare and reset the elements of that matrix. In this way, a new adjacency matrix was obtained, which corresponds the network structure in Figure 2.
In the reconstructed network, the intra-cluster connections are denser than the original network, while the inter-cluster connections are sparser than before. Hence, the information of the overlapping nodes is well preserved.
The reconstruction was carried out through continuous normalization, expansion and inflation operations until two successive iterations output the same reconstructed matrices. Hence, the final matrix can be expressed as:
$\left[\begin{array}{llllllllll}{1} & {1} & {1} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {1} & {1} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {1} & {1} & {1} & {0} & {0} & {0} & {0} & {0} & {0} \\ {1} & {1} & {1} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {1} & {1} & {1} & {1} & {0} & {0} & {0} \\ {0} & {0} & {0} & {0} & {0} & {0} & {0} & {1} & {1} & {1} \\ {0} & {0} & {0} & {0} & {0} & {0} & {0} & {1} & {1} & {1} \\ {0} & {0} & {0} & {0} & {0} & {0} & {0} & {1} & {1} & {1}\end{array}\right]$
For any element in the final matrix that equals 1, the nodes represented by the row and column of that element belong to the same community. Obviously, if there is a block in which all elements are 1 in the final matrix, then the corresponding nodes all belong to a community. If there is an intersection of such blocks, the nodes in the intersection are the overlapping nodes belonging to different communities.
As shown in Figure 3, the different color regions represent different communities in the new network. The node (4) covered by more than one color region is an overlapping node that belong to two public communities.
Figure 3. Results of overlapping community detection
To verify its effectiveness, our algorithm was compared with several well-known overlapping community detection algorithms on three artificial networks (Table 1) and six real-world networks (Table 3). The community structure of each artificial network is listed in Table 2.
The contrastive algorithms include the balanced multi-label propagation algorithm (BMLPA), speaker-listener label propagation algorithm (SLPA), conditional pseudonym resolution algorithm (CoPRA), order statistics local optimization method (OSLOM) algorithm, fast algorithm for detecting community structure in networks (Fast-Newman), and Markov clustering (MCL).
Among them, the BMLPA is an overlapping community detection algorithm based on the balanced attribution coefficient, the SLPA is an overlapping community detection algorithm based on historical tags, the CoPRA is an overlapping community detection algorithm based on membership degree of nodes to communities, the OSLOM is a local optimal overlapping community detection algorithm based on fitness function, the Fast-Newman is a greedy nonoverlapping community detection algorithm based on modular increment, and the MCL is an nonoverlapping community detection algorithm based on Markov chain and random walk.
The output of each algorithm was evaluated by four metrics, namely, extended module degree (EMD) [26] and extended partition density (EPD) [27], aiming to reflect the reasonability and quality of community detection.
Table 1. The topological features of the artificial networks
|
Network |
Number of nodes |
Number of edges |
Number of communities |
Overlapping node |
|
A |
9 |
15 |
3 |
2 |
|
B |
16 |
43 |
4 |
3, 4 |
|
C |
23 |
65 |
4 |
10, 17, 18, 19 |
|
Network |
Community structures |
|
A |
[1, 2, 3, 4], [2, 5], [6, 7, 8, 9] |
|
B |
[1, 2, 3, 4, 5], [3, 6, 7, 8], [3, 4, 9, 10, 11, 12], [4,13,14,15,16] |
|
C |
[1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12, 13], [10, 14, 15, 16, 17, 18, 19], [17, 18, 19, 20, 21, 22, 23] |
|
Network |
Number of nodes |
Number of edges |
Mean degrees of nodes |
Mean clustering coefficients |
|
Karate |
34 |
78 |
4.59 |
0.257 |
|
Dolphin |
62 |
159 |
5.13 |
0.308 |
|
Jazz |
221 |
2759 |
26.97 |
0.521 |
|
Net-Sci |
388 |
926 |
4.872 |
0.369 |
|
Les |
85 |
257 |
6.618 |
0.485 |
|
Books |
109 |
455 |
8.389 |
0.246 |
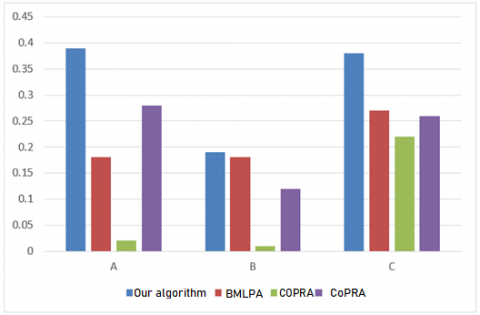
Figure 4. EMD comparison of different algorithms on artificial networks
Figures 4 and 5 show the EMDs and EPDs of our algorithm, the BMLPA, the SLPA, and the CoPRA on artificial networks, respectively. Obviously, our algorithm achieved the best overall performance in all three artificial networks, as evidenced by the highest EMD and EPD values.
Figure 5. EPD comparison of different algorithms on artificial networks
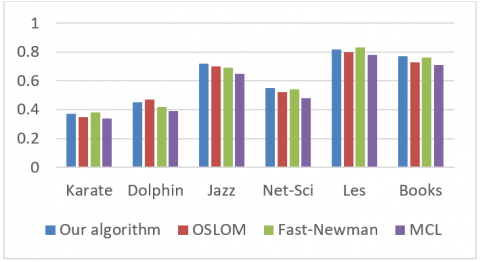
Figure 6. EMD comparison of different algorithms on real-world networks
Figures 6 and 7 compares the EMDs and EPDs of our algorithm, the OSLOM, Fast-Newman, and the MCL on real-world networks, respectively. Judging by the EMD, Fast-Newman performed the best in Karate and Les, the OSLOM performed the best in Dolphin, while our algorithm performed the best in Jazz, Net-Sci and Books. Judging by the EPD, our algorithm outperformed the other algorithms in all networks except Les. The results fully demonstrate the effectiveness of our algorithm.
Figure 7. EPD comparison of different algorithms on real-world networks
This paper puts forward a random walk algorithm based on Markov chain for overlapping community detection in complex networks. The proposed algorithm transfers information, enhances intra-cluster connections and highlights the community boundary through expansion and inflation. The adaptive threshold was introduced to reconstruct the network to facilitate the mining of overlapping communities. The effectiveness of our algorithm was fully demonstrated through experiments on artificial and real-world networks. The future research will further enhance the applicability of our algorithm to real-world complex networks.
This work is supported by Special Research Project of Shaanxi Provincial Department of Education (No. 19JK0631), all support is gratefully acknowledged.
[1] Rozum, J.C., Albert, R. (2018). Identifying (un)controllable dynamical behavior in complex networks. Plos Computational Biology, 14(12): e1006630. https://doi.org/10.1371/journal.pcbi.1006630
[2] Gupta, P., Jindal, R., Sharma, A. (2018). Community trolling: An active learning approach for topic based community detection in big data. Journal of Grid Computing, 16(4): 553-567. https://doi.org/10.1007/s10723-018-9457-z
[3] Nascimento, M.C.V., Pitsoulis, L. (2013). Community detection by modularity maximization using GRASP with path relinking. Computers & Operations Research, 40(12): 3121-3131. https://doi.org/10.1016/j.cor.2013.03.002
[4] Shi, C., Cai, Y., Fu, D., Dong, Y.X., Wu, B. (2013). A link clustering based overlapping community detection algorithm. Data & Knowledge Engineering, 87: 394-404. https://doi.org/10.1016/j.datak.2013.05.004
[5] Borkar, V., Meyn, S.P. (2012). Oja’s algorithm for graph clustering, Markov spectral decomposition, and risk sensitive control. Automatica, 48(10): 2512-2519. https://doi.org/10.1016/j.automatica.2012.05.016
[6] Chen, D.B., Feng, Z., Lu, R.Q., Lei, Y., Li, Z. Wang, J.T. (2016). Multi-objective optimization of community detection using discrete teaching–learning-based optimization with decomposition. Information Sciences, 369(3): 402-418. https://doi.org/10.1016/j.ins.2016.06.025
[7] Newman, M.E.J., Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review E, 69(2): 026113. https://doi.org/10.1103/PhysRevE.69.026113
[8] Newman, M.E.J. (2004). Fast algorithm for detecting community structure in networks. Physical review E, 69(6): 066133. https://doi.org/10.1103/PhysRevE.69.066133
[9] Ashrafi Payaman, N., Kangavari, M. (2017). GSSC: Graph summarization based on both structure and concepts. International Journal of Information and Communication Technology Research, 9(1): 33-44.
[10] Jarukasemratana, S., Murata, T., Liu, X. (2014). Community detection algorithm based on centrality and node closeness in scale-free networks. Transactions of the Japanese Society for Artificial Intelligence, 29(2): 234-244. https://doi.org/10.1527/tjsai.29.234
[11] Zhou, X., Liu, Y., Wang, J., Li, C. (2017). A density based link clustering algorithm for overlapping community detection in networks. Physica A: Statistical Mechanics and its Applications, 486: 65-78. https://doi.org/10.1016/j.physa.2017.05.032
[12] Zhang, X.Y., Wang, C.T., Su, Y.S., Pan, L.Q., Zhang, H.F. (2017). A fast overlapping community detection algorithm based on weak cliques for large-scale networks. IEEE Transactions on Computational Social Systems, 4(4): 218-230. https://doi.org/10.1109/TCSS.2017.2749282
[13] Shahmoradi, M.R., Ebrahimi, M., Heshmati, Z., Salehi, M. (2019). Multilayer overlapping community detection using multi-objective optimization. Future Generation Computer Systems-The International Journal of Escience, 101: 221-235. https://doi.org/10.1016/j.future.2019.05.061
[14] Mirzaei, S., Soltanian-Zadeh, H. (2019). Overlapping brain Community detection using Bayesian tensor decomposition. Journal of Neuroscience Methods, 318: 47-55. https://doi.org/10.1016/j.jneumeth.2019.02.014
[15] Zhang, S.H., Wang, R.S., Zhang, X.S. (2007). Identification of overlapping community structure in complex networks using fuzzy-means clustering. Physica A Statistical Mechanics & Its Applications, 374(1): 483-490. https://doi.org/10.1016/j.physa.2006.07.023
[16] Jonnalagadda, A., Kuppusamy, L. (2018). Overlapping community detection in social networks using coalitional games. Knowledge and Information Systems, 56(3): 637-661. https://doi.org/10.1007/s10115-017-1150-1
[17] Huang, J.B., Sun, H.L., Han, H.W., Feng, B.Q. (2011). Density-based shrinkage for revealing hierarchical and overlapping community structure in networks. Physica A Statistical Mechanics & Its Applications, 390(11): 2160-2171. https://doi.org/10.1016/j.physa.2010.10.040
[18] Chen, L., Zhang, J., Cai, L.J. (2018). Overlapping community detection based on link graph using distance dynamics. International Journal of Modern Physics B, 32(3): 1850015. https://doi.org/10.1142/S0217979218500157
[19] Ding, Y., Fu, X. (2016). Kernel-based fuzzy C-means clustering algorithm based on genetic algorithm. Neurocomputing, 188: 233-238. https://doi.org/10.1016/j.neucom.2015.01.106
[20] Binesh, N., Rezghi, M. (2018). Fuzzy clustering in community detection based on nonnegative matrix factorization with two novel evaluation criteria. Applied Soft Computing, 69: 689-703. https://doi.org/10.1016/j.asoc.2016.12.019
[21] Li, Y.Y., Wang, Y., Chen, J., Jiao, L.C., Shang, R.H. (2015). Overlapping community detection through an improved multi-objective quantum-behaved particle swarm optimization. Journal of Heuristics, 21(4): 549-575. https://doi.org/10.1007/s10732-015-9289-y
[22] Ngonmang, B., Tchuente, M., Viennet, E. (2012). Local community identification in social networks. Parallel Processing Letters, 22(1): 1240004. https://doi.org/10.1142/S012962641240004X
[23] Wu, Z.H., Lin, Y.F., Gregory, S., Wan, H.Y., Tian, S.F. (2012). Balanced multi-label propagation for overlapping community detection in social networks. Journal of Computer Science and Technology, 27(3): 468-479. https://doi.org/10.1007/s11390-012-1236-x
[24] Zhang, J., Xu, X.K., Li, P., Zhang, K., Small, M. (2011). Node importance for dynamical process on networks: A multiscale characterization. Chaos: An Interdisciplinary Journal of Nonlinear Science, 21(1): 016107. https://doi.org/10.1063/1.3553644
[25] Hartuv, E., Shamir, R. (2000). A clustering algorithm based on graph connectivity. Information processing letters, 76(4-6): 175-181. https://doi.org/10.1016/S0020-0190(00)00142-3
[26] Tang, L.Y., Li, S.N., Lin, J.H., Guo, Q., Liu, J.G. (2016). Community structure detection based on the neighbor node degree information. International Journal of Modern Physics C, 27(4): 1650046. https://doi.org/10.1142/S0129183116500467
[27] You, T., Cheng, H.M., Ning, Y.Z., Shia, B.C., Zhang, Z.Y. (2016). Community detection in complex networks using density-based clustering algorithm and manifold learning. Physica A: Statistical Mechanics and its Applications, 464: 221-230. https://doi.org/10.1016/j.physa.2016.07.025